 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Benchmarking variational quantum circuits with permutation symmetry
Nov 23, 2022
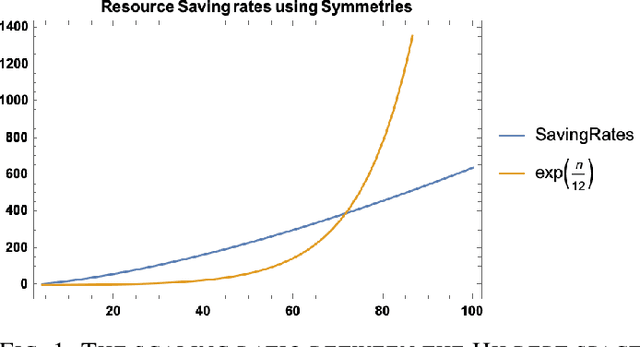
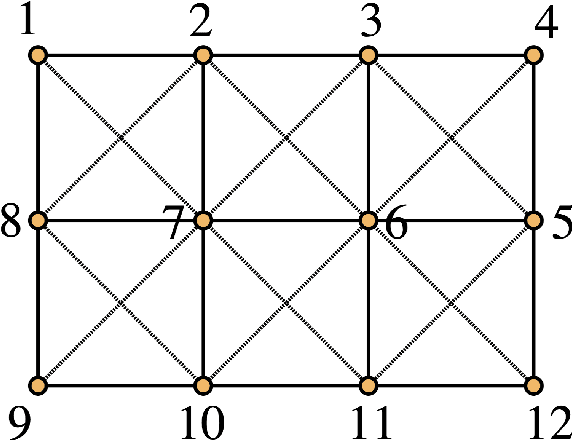
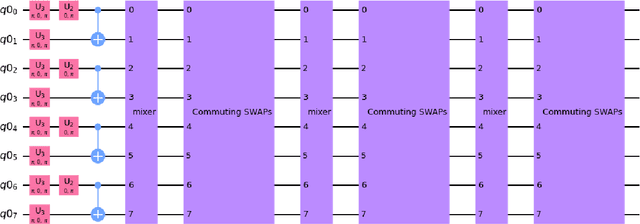
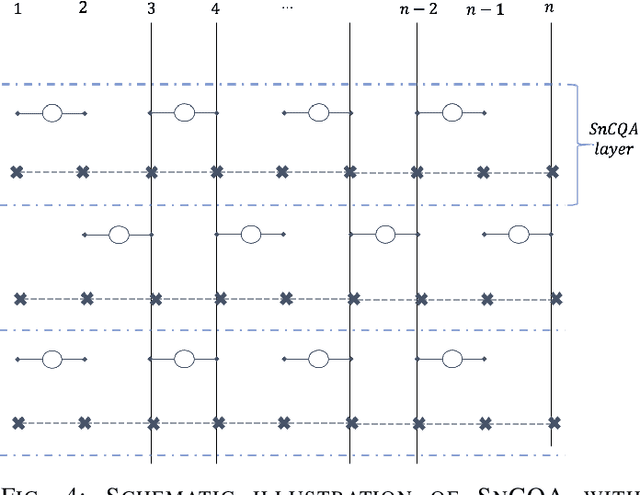
We propose SnCQA, a set of hardware-efficient variational circuits of equivariant quantum convolutional circuits respective to permutation symmetries and spatial lattice symmetries with the number of qubits $n$. By exploiting permutation symmetries of the system, such as lattice Hamiltonians common to many quantum many-body and quantum chemistry problems, Our quantum neural networks are suitable for solving machine learning problems where permutation symmetries are present, which could lead to significant savings of computational costs. Aside from its theoretical novelty, we find our simulations perform well in practical instances of learning ground states in quantum computational chemistry, where we could achieve comparable performances to traditional methods with few tens of parameters. Compared to other traditional variational quantum circuits, such as the pure hardware-efficient ansatz (pHEA), we show that SnCQA is more scalable, accurate, and noise resilient (with $20\times$ better performance on $3 \times 4$ square lattice and $200\% - 1000\%$ resource savings in various lattice sizes and key criterions such as the number of layers, parameters, and times to converge in our cases), suggesting a potentially favorable experiment on near-time quantum devices.
Reliable Robustness Evaluation via Automatically Constructed Attack Ensembles
Nov 23, 2022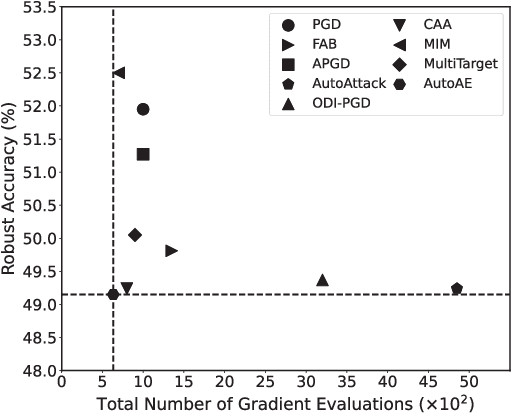
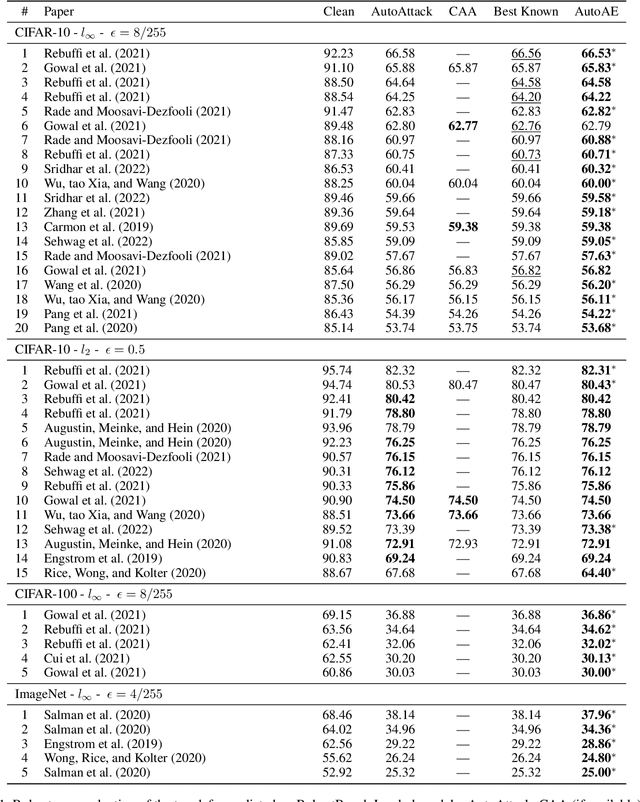
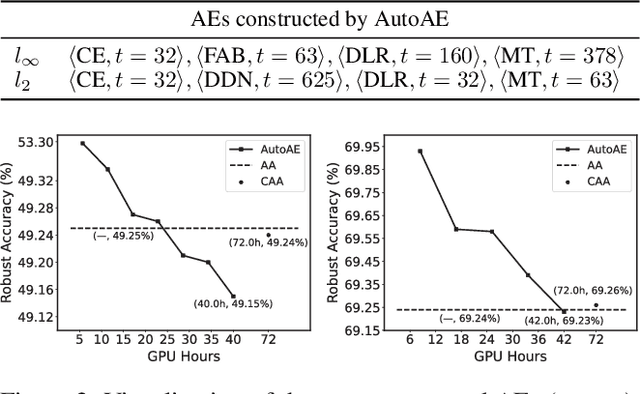
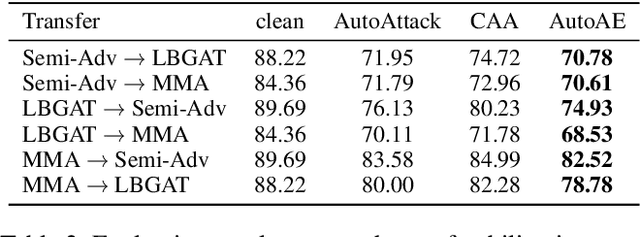
Attack Ensemble (AE), which combines multiple attacks together, provides a reliable way to evaluate adversarial robustness. In practice, AEs are often constructed and tuned by human experts, which however tends to be sub-optimal and time-consuming. In this work, we present AutoAE, a conceptually simple approach for automatically constructing AEs. In brief, AutoAE repeatedly adds the attack and its iteration steps to the ensemble that maximizes ensemble improvement per additional iteration consumed. We show theoretically that AutoAE yields AEs provably within a constant factor of the optimal for a given defense. We then use AutoAE to construct two AEs for $l_{\infty}$ and $l_2$ attacks, and apply them without any tuning or adaptation to 45 top adversarial defenses on the RobustBench leaderboard. In all except one cases we achieve equal or better (often the latter) robustness evaluation than existing AEs, and notably, in 29 cases we achieve better robustness evaluation than the best known one. Such performance of AutoAE shows itself as a reliable evaluation protocol for adversarial robustness, which further indicates the huge potential of automatic AE construction. Code is available at \url{https://github.com/LeegerPENG/AutoAE}.
Stackelberg Meta-Learning for Strategic Guidance in Multi-Robot Trajectory Planning
Nov 23, 2022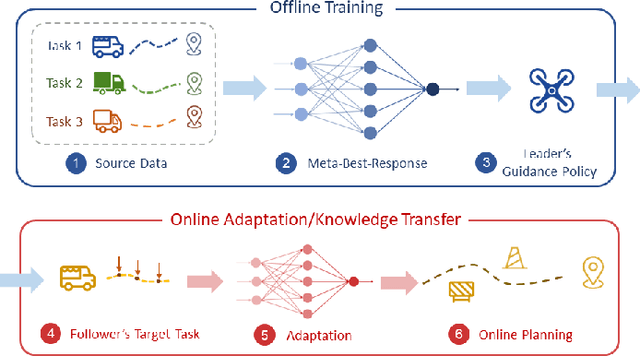

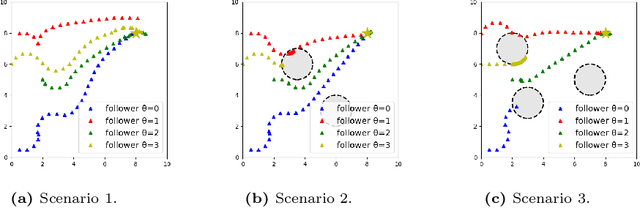
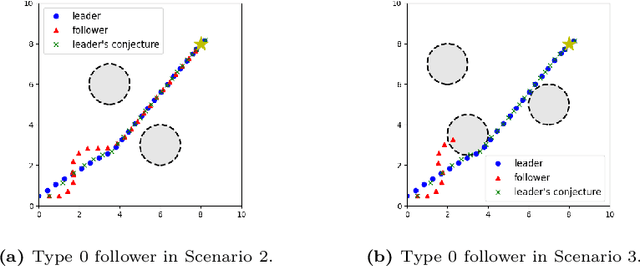
Guided cooperation is a common task in many multi-agent teaming applications. The planning of the cooperation is difficult when the leader robot has incomplete information about the follower, and there is a need to learn, customize, and adapt the cooperation plan online. To this end, we develop a learning-based Stackelberg game-theoretic framework to address this challenge to achieve optimal trajectory planning for heterogeneous robots. We first formulate the guided trajectory planning problem as a dynamic Stackelberg game and design the cooperation plans using open-loop Stackelberg equilibria. We leverage meta-learning to deal with the unknown follower in the game and propose a Stackelberg meta-learning framework to create online adaptive trajectory guidance plans, where the leader robot learns a meta-best-response model from a prescribed set of followers offline and then fast adapts to a specific online trajectory guidance task using limited learning data. We use simulations in three different scenarios to elaborate on the effectiveness of our framework. Comparison with other learning approaches and no guidance cases show that our framework provides a more time- and data-efficient planning method in trajectory guidance tasks.
Indian Commercial Truck License Plate Detection and Recognition for Weighbridge Automation
Nov 23, 2022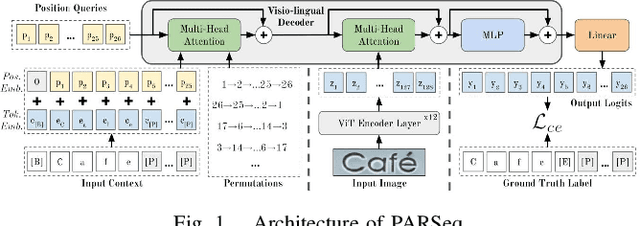



Detection and recognition of a licence plate is important when automating weighbridge services. While many large databases are available for Latin and Chinese alphanumeric license plates, data for Indian License Plates is inadequate. In particular, databases of Indian commercial truck license plates are inadequate, despite the fact that commercial vehicle license plate recognition plays a profound role in terms of logistics management and weighbridge automation. Moreover, models to recognise license plates are not effectively able to generalise to such data due to its challenging nature, and due to the abundant frequency of handwritten license plates, leading to the usage of diverse font styles. Thus, a database and effective models to recognise and detect such license plates are crucial. This paper provides a database on commercial truck license plates, and using state-of-the-art models in real-time object Detection: You Only Look Once Version 7, and SceneText Recognition: Permuted Autoregressive Sequence Models, our method outperforms the other cited references where the maximum accuracy obtained was less than 90%, while we have achieved 95.82% accuracy in our algorithm implementation on the presented challenging license plate dataset. Index Terms- Automatic License Plate Recognition, character recognition, license plate detection, vision transformer.
Differentiable Uncalibrated Imaging
Nov 18, 2022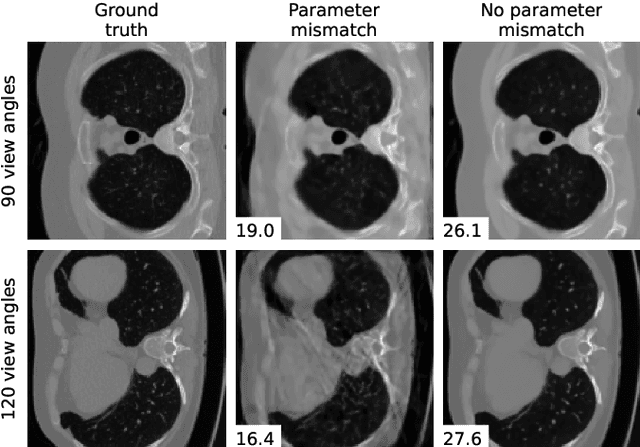
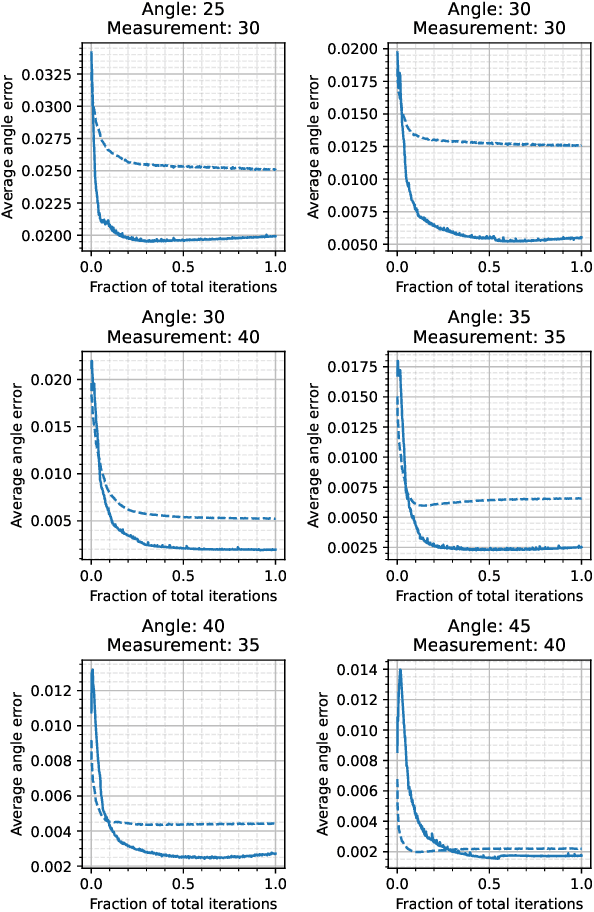
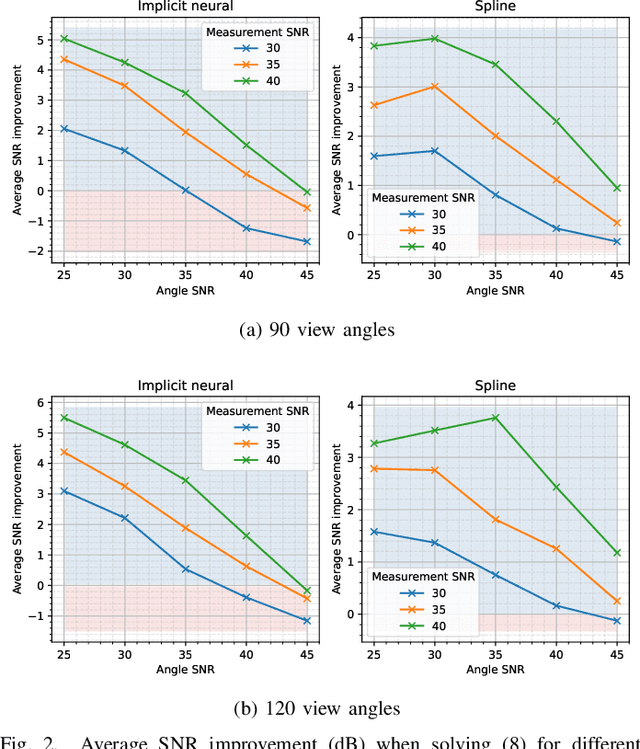
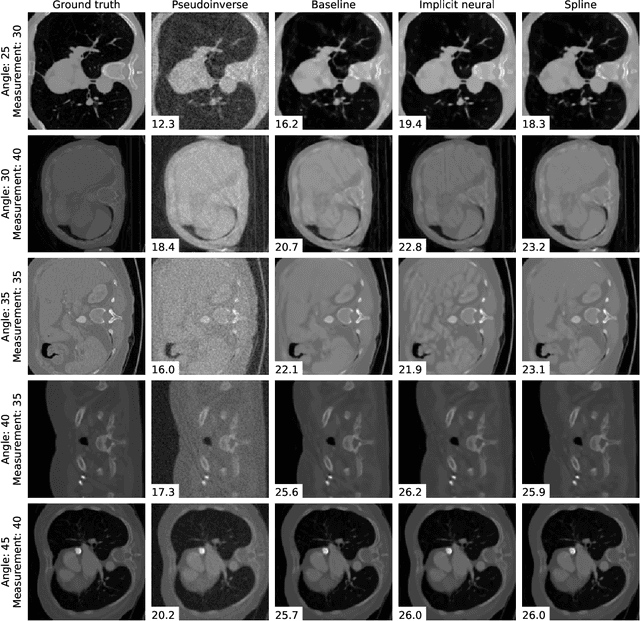
We propose a differentiable imaging framework to address uncertainty in measurement coordinates such as sensor locations and projection angles. We formulate the problem as measurement interpolation at unknown nodes supervised through the forward operator. To solve it we apply implicit neural networks, also known as neural fields, which are naturally differentiable with respect to the input coordinates. We also develop differentiable spline interpolators which perform as well as neural networks, require less time to optimize and have well-understood properties. Differentiability is key as it allows us to jointly fit a measurement representation, optimize over the uncertain measurement coordinates, and perform image reconstruction which in turn ensures consistent calibration. We apply our approach to 2D and 3D computed tomography and show that it produces improved reconstructions compared to baselines that do not account for the lack of calibration. The flexibility of the proposed framework makes it easy to apply to almost arbitrary imaging problems.
Impact of visual assistance for automated audio captioning
Nov 18, 2022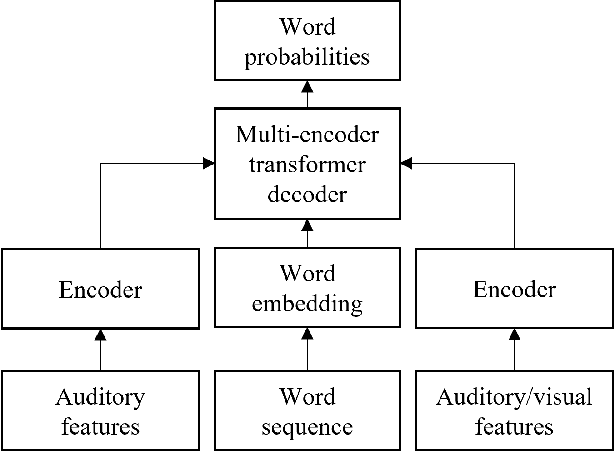
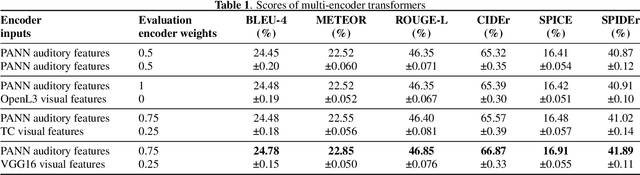
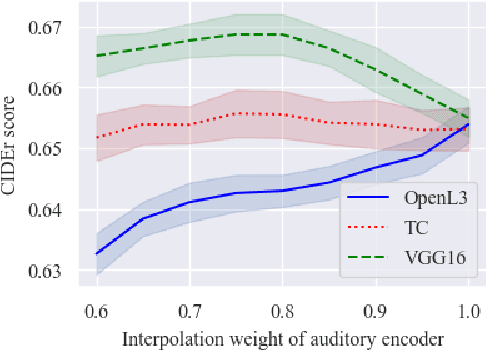
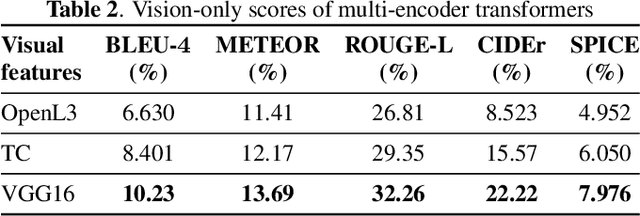
We study the impact of visual assistance for automated audio captioning. Utilizing multi-encoder transformer architectures, which have previously been employed to introduce vision-related information in the context of sound event detection, we analyze the usefulness of incorporating a variety of pretrained features. We perform experiments on a YouTube-based audiovisual data set and investigate the effect of applying the considered transfer learning technique in terms of a variety of captioning metrics. We find that only one of the considered kinds of pretrained features provides consistent improvements, while the others do not provide any noteworthy gains at all. Interestingly, the outcomes of prior research efforts indicate that the exact opposite is true in the case of sound event detection, leading us to conclude that the optimal choice of visual embeddings is strongly dependent on the task at hand. More specifically, visual features focusing on semantics appear appropriate in the context of automated audio captioning, while for sound event detection, time information seems to be more important.
IEEE Big Data Cup 2022: Privacy Preserving Matching of Encrypted Images with Deep Learning
Nov 18, 2022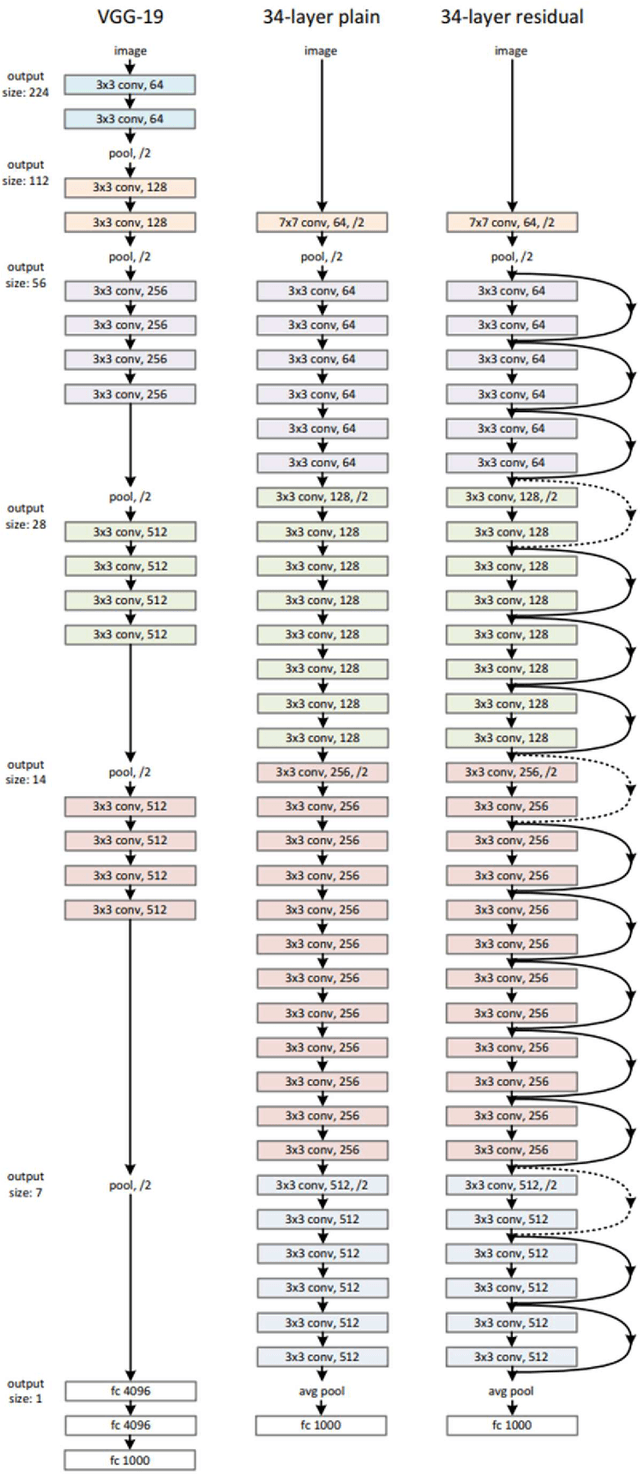
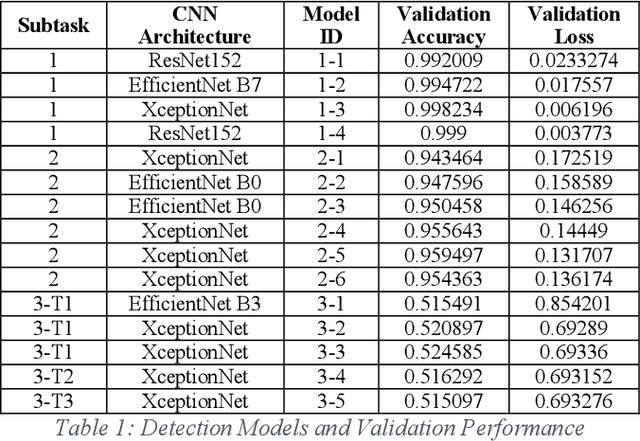
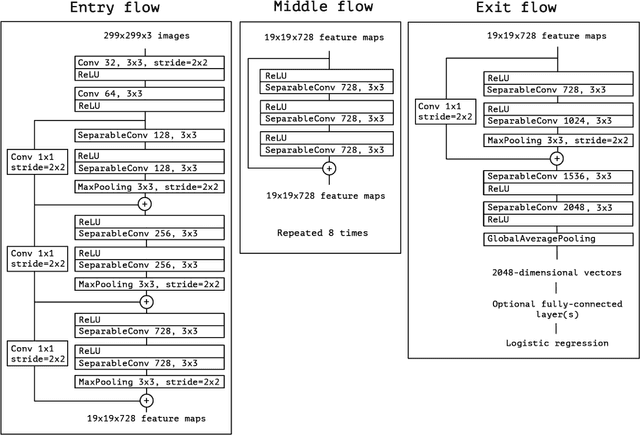
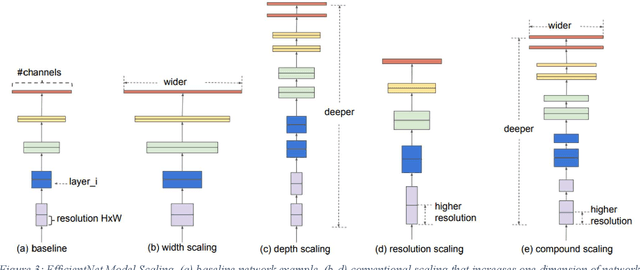
Smart sensors, devices and systems deployed in smart cities have brought improved physical protections to their citizens. Enhanced crime prevention, and fire and life safety protection are achieved through these technologies that perform motion detection, threat and actors profiling, and real-time alerts. However, an important requirement in these increasingly prevalent deployments is the preservation of privacy and enforcement of protection of personal identifiable information. Thus, strong encryption and anonymization techniques should be applied to the collected data. In this IEEE Big Data Cup 2022 challenge, different masking, encoding and homomorphic encryption techniques were applied to the images to protect the privacy of their contents. Participants are required to develop detection solutions to perform privacy preserving matching of these images. In this paper, we describe our solution which is based on state-of-the-art deep convolutional neural networks and various data augmentation techniques. Our solution achieved 1st place at the IEEE Big Data Cup 2022: Privacy Preserving Matching of Encrypted Images Challenge.
* Keywords: privacy preservation, privacy enhancing, masking, encoding, homomorphic encryption, deep learning, convolutional neural networks
Dynamic Time Slot Allocation Algorithm for Quadcopter Swarms
Feb 02, 2022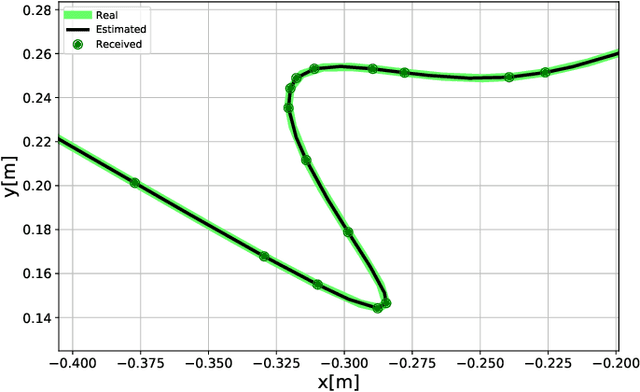
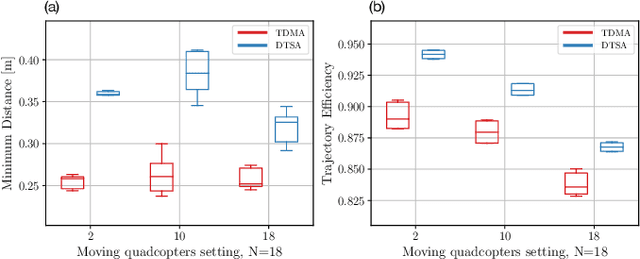
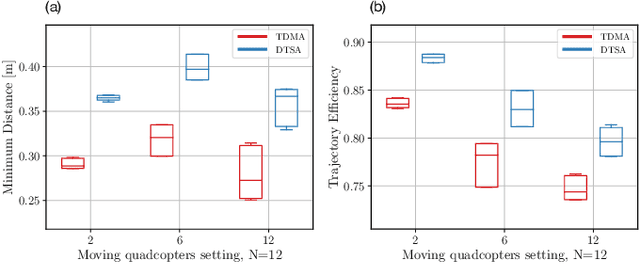
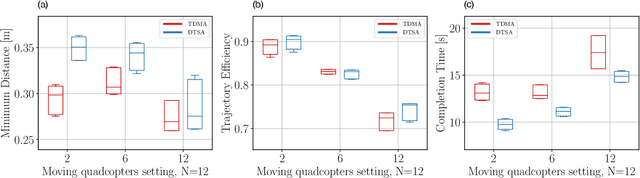
A swarm of quadcopters can perform cooperative tasks, such as monitoring of a large area, more efficiently than a single one. However, to be able to successfully work together, the quadcopters must be aware of the position of the other swarm members, especially to avoid collisions. A quadcopter can share its own position by transmitting it via radio waves and in order to allow multiple quadcopters to communicate effectively, a decentralized channel access protocol is essential. We propose a new dynamic channel access protocol, called Dynamic time slot allocation (DTSA), where the quadcopters share the total channel access time in a non-periodic and decentralized manner. Quadcopters with higher communication demands occupy more time slots than less active ones. Our dynamic approach allows the agents to adapt to changing swarm situations and therefore to act efficiently, as compared to the state-of-the-art periodic channel access protocol, time division multiple access (TDMA). Along with simulations, we also do experiments using real Crazyflie quadcopters to show the improved performance of DTSA as compared to TDMA.
Towards Energy-Efficient, Low-Latency and Accurate Spiking LSTMs
Oct 23, 2022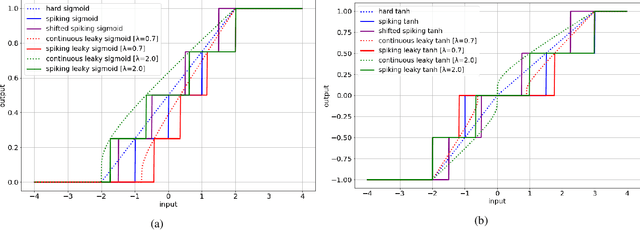
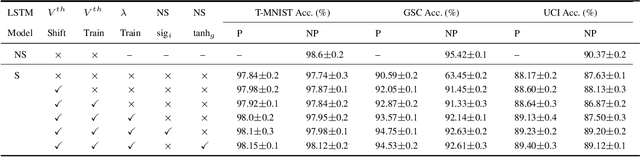

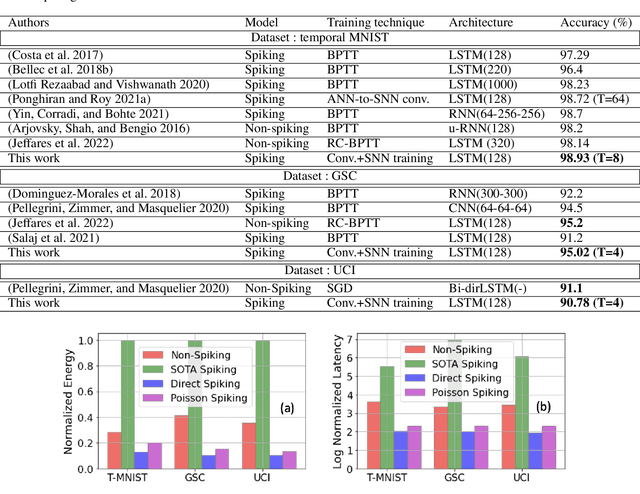
Spiking Neural Networks (SNNs) have emerged as an attractive spatio-temporal computing paradigm for complex vision tasks. However, most existing works yield models that require many time steps and do not leverage the inherent temporal dynamics of spiking neural networks, even for sequential tasks. Motivated by this observation, we propose an \rev{optimized spiking long short-term memory networks (LSTM) training framework that involves a novel ANN-to-SNN conversion framework, followed by SNN training}. In particular, we propose novel activation functions in the source LSTM architecture and judiciously select a subset of them for conversion to integrate-and-fire (IF) activations with optimal bias shifts. Additionally, we derive the leaky-integrate-and-fire (LIF) activation functions converted from their non-spiking LSTM counterparts which justifies the need to jointly optimize the weights, threshold, and leak parameter. We also propose a pipelined parallel processing scheme which hides the SNN time steps, significantly improving system latency, especially for long sequences. The resulting SNNs have high activation sparsity and require only accumulate operations (AC), in contrast to expensive multiply-and-accumulates (MAC) needed for ANNs, except for the input layer when using direct encoding, yielding significant improvements in energy efficiency. We evaluate our framework on sequential learning tasks including temporal MNIST, Google Speech Commands (GSC), and UCI Smartphone datasets on different LSTM architectures. We obtain test accuracy of 94.75% with only 2 time steps with direct encoding on the GSC dataset with 4.1x lower energy than an iso-architecture standard LSTM.
Beyond the Limitation of Pulse Width in Optical Time-domain Reflectometry
Mar 14, 2022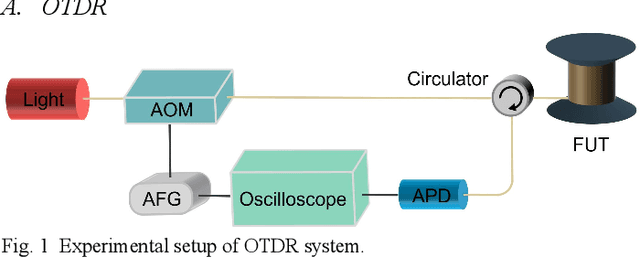
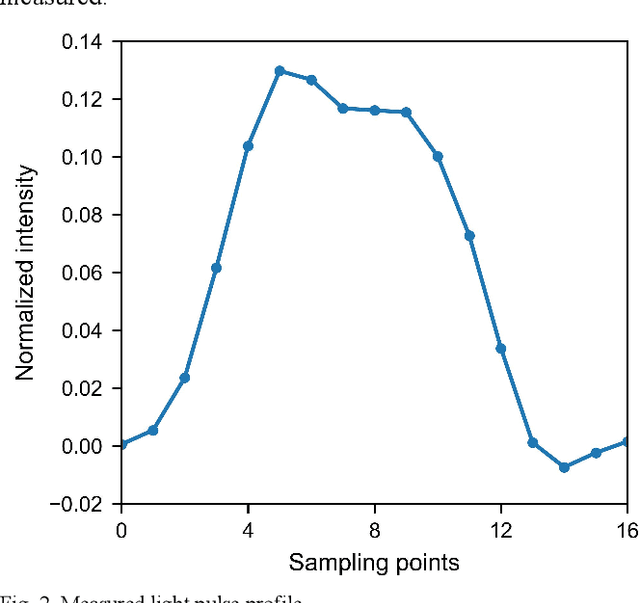
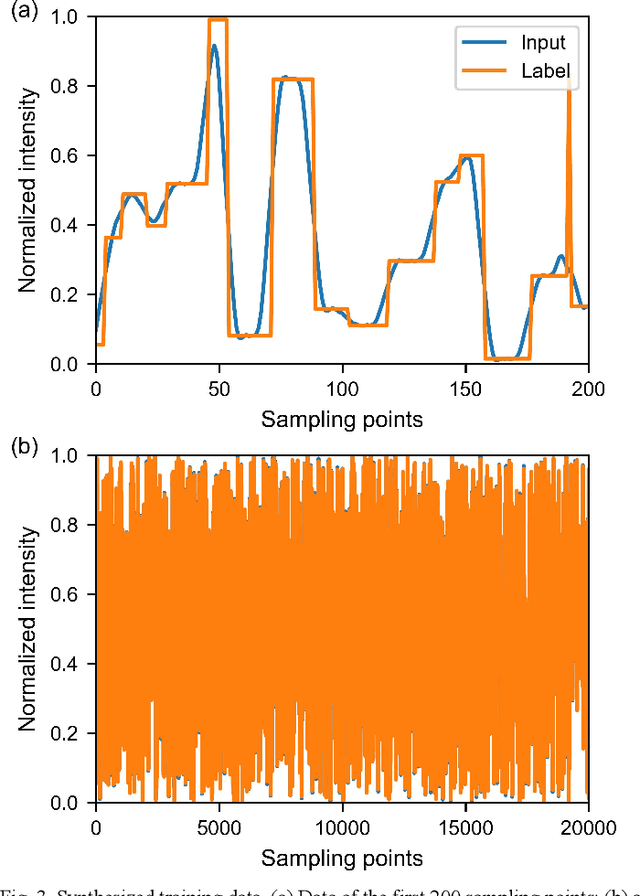
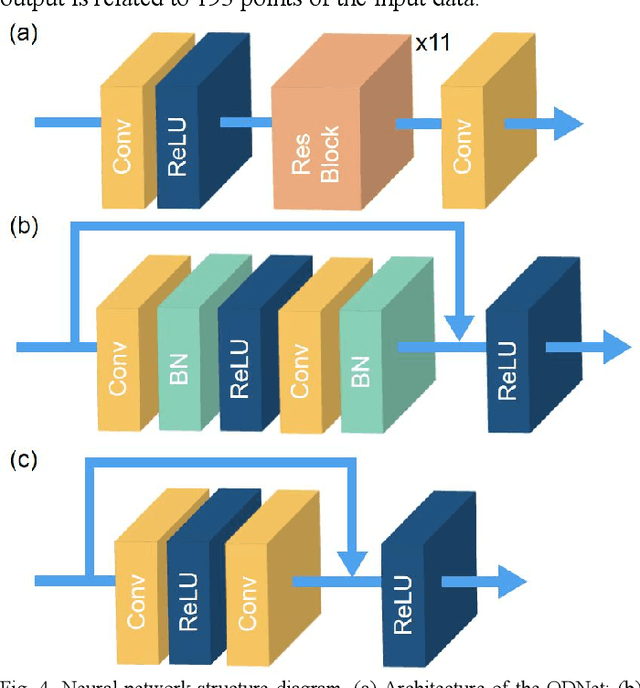
Optical time-domain reflectometry (OTDR) is the basis for distributed time-domain optical fiber sensing techniques. By injecting pulse light into an optical fiber, the distance information of an event can be obtained based on the time of light flight. The minimum distinguishable event separation along the fiber length is called the spatial resolution, which is determined by the optical pulse width. By reducing the pulse width, the spatial resolution can be improved. However, at the same time, the signal-to-noise ratio of the system is degraded, and higher speed equipment is required. To solve this problem, data processing methods such as iterative subdivision, deconvolution, and neural networks have been proposed. However, they all have some shortcomings and thus have not been widely applied. Here, we propose and experimentally demonstrate an OTDR deconvolution neural network based on deep convolutional neural networks. A simplified OTDR model is built to generate a large amount of training data. By optimizing the network structure and training data, an effective OTDR deconvolution is achieved. The simulation and experimental results show that the proposed neural network can achieve more accurate deconvolution than the conventional deconvolution algorithm with a higher signal-to-noise ratio.