 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stochastic Mirror Descent in Average Ensemble Models
Oct 27, 2022
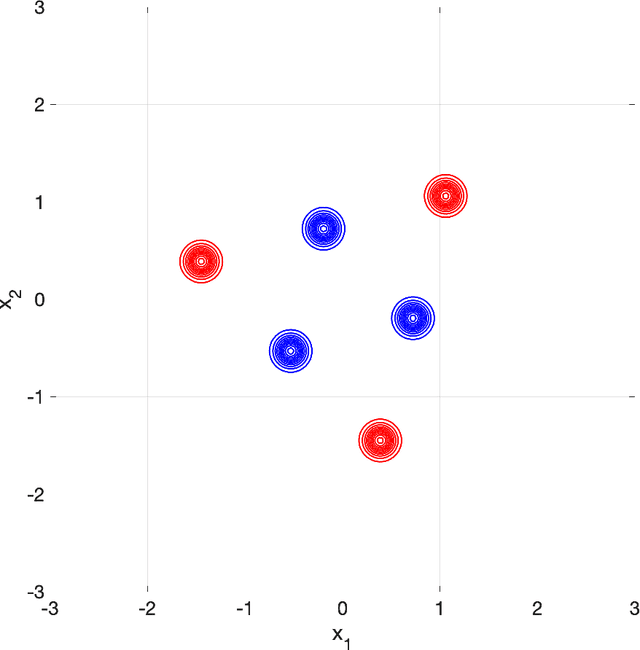
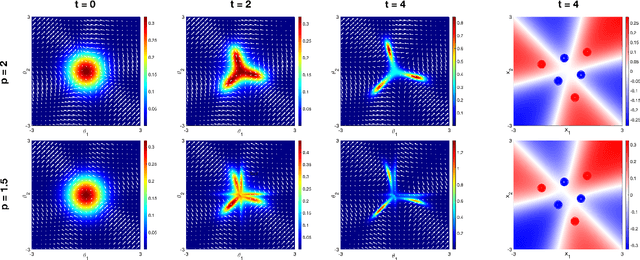
The stochastic mirror descent (SMD) algorithm is a general class of training algorithms, which includes the celebrated stochastic gradient descent (SGD), as a special case. It utilizes a mirror potential to influence the implicit bias of the training algorithm. In this paper we explore the performance of the SMD iterates on mean-field ensemble models. Our results generalize earlier ones obtained for SGD on such models. The evolution of the distribution of parameters is mapped to a continuous time process in the space of probability distributions. Our main result gives a nonlinear partial differential equation to which the continuous time process converges in the asymptotic regime of large networks. The impact of the mirror potential appears through a multiplicative term that is equal to the inverse of its Hessian and which can be interpreted as defining a gradient flow over an appropriately defined Riemannian manifold. We provide numerical simulations which allow us to study and characterize the effect of the mirror potential on the performance of networks trained with SMD for some binary classification problems.
Differentiable Uncalibrated Imaging
Nov 18, 2022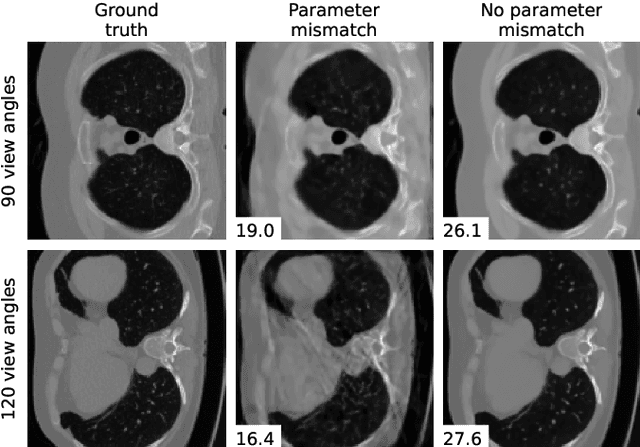
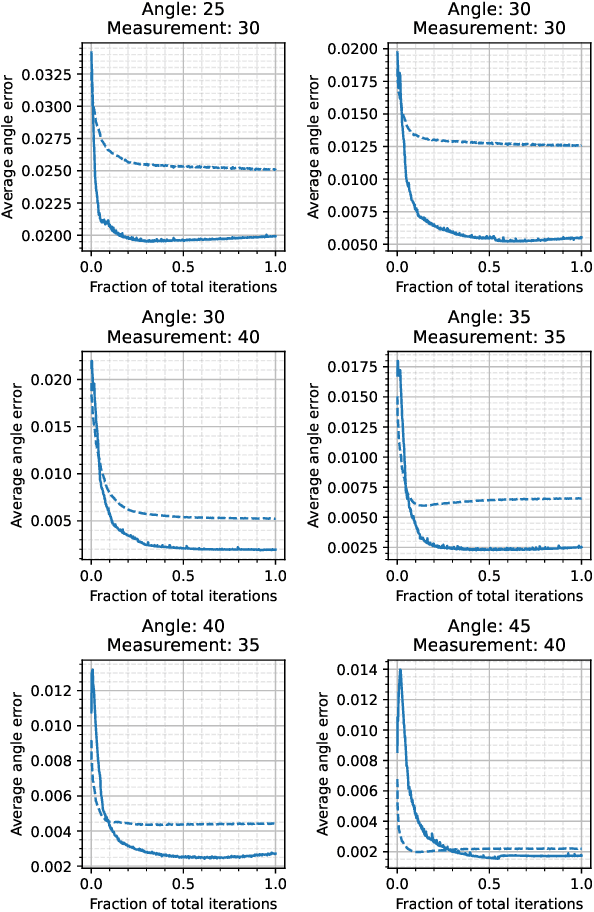
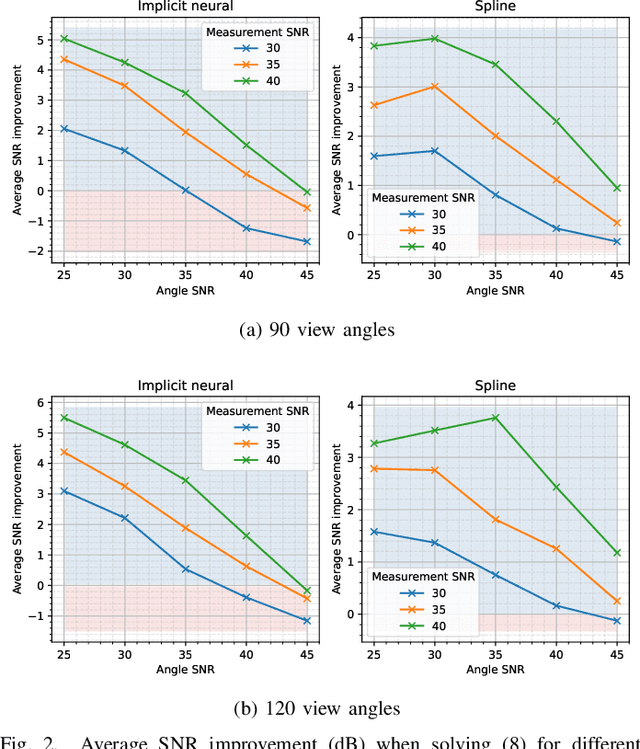
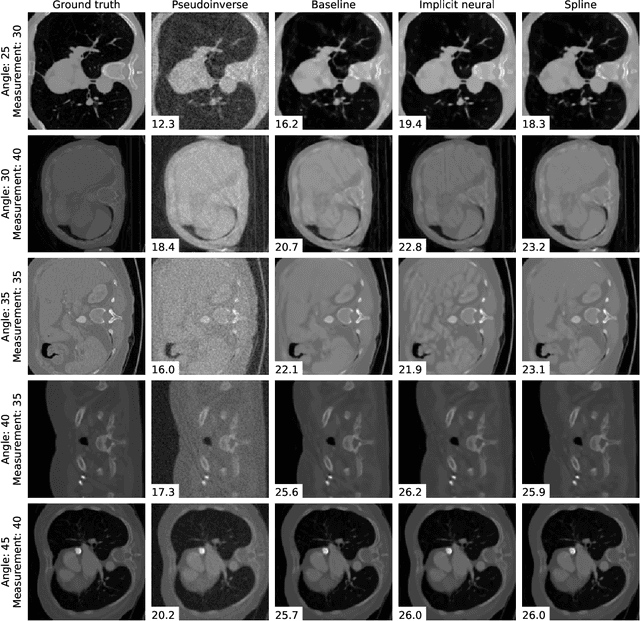
We propose a differentiable imaging framework to address uncertainty in measurement coordinates such as sensor locations and projection angles. We formulate the problem as measurement interpolation at unknown nodes supervised through the forward operator. To solve it we apply implicit neural networks, also known as neural fields, which are naturally differentiable with respect to the input coordinates. We also develop differentiable spline interpolators which perform as well as neural networks, require less time to optimize and have well-understood properties. Differentiability is key as it allows us to jointly fit a measurement representation, optimize over the uncertain measurement coordinates, and perform image reconstruction which in turn ensures consistent calibration. We apply our approach to 2D and 3D computed tomography and show that it produces improved reconstructions compared to baselines that do not account for the lack of calibration. The flexibility of the proposed framework makes it easy to apply to almost arbitrary imaging problems.
Impact of visual assistance for automated audio captioning
Nov 18, 2022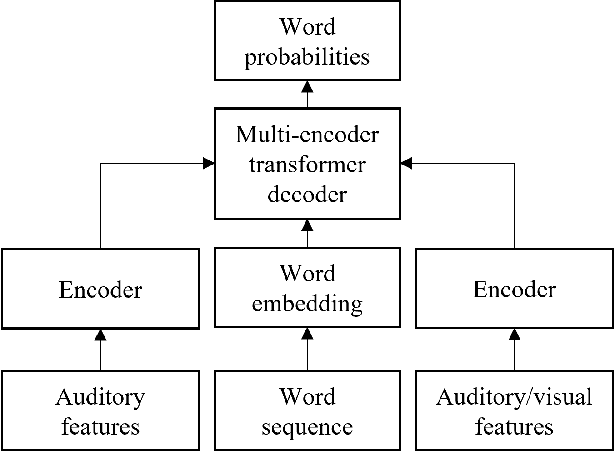
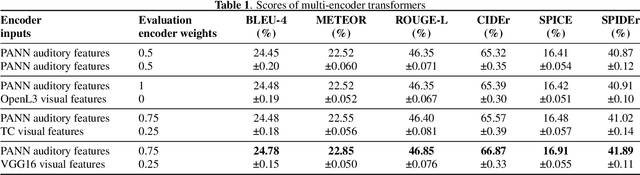
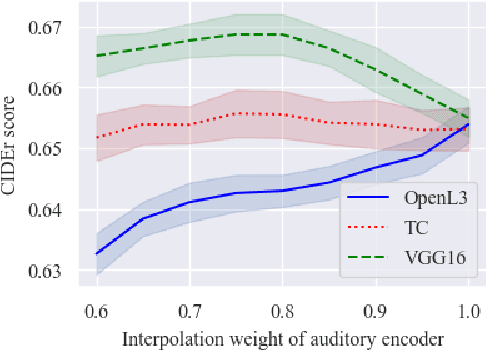
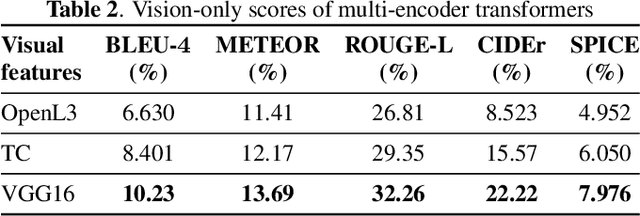
We study the impact of visual assistance for automated audio captioning. Utilizing multi-encoder transformer architectures, which have previously been employed to introduce vision-related information in the context of sound event detection, we analyze the usefulness of incorporating a variety of pretrained features. We perform experiments on a YouTube-based audiovisual data set and investigate the effect of applying the considered transfer learning technique in terms of a variety of captioning metrics. We find that only one of the considered kinds of pretrained features provides consistent improvements, while the others do not provide any noteworthy gains at all. Interestingly, the outcomes of prior research efforts indicate that the exact opposite is true in the case of sound event detection, leading us to conclude that the optimal choice of visual embeddings is strongly dependent on the task at hand. More specifically, visual features focusing on semantics appear appropriate in the context of automated audio captioning, while for sound event detection, time information seems to be more important.
IEEE Big Data Cup 2022: Privacy Preserving Matching of Encrypted Images with Deep Learning
Nov 18, 2022
Smart sensors, devices and systems deployed in smart cities have brought improved physical protections to their citizens. Enhanced crime prevention, and fire and life safety protection are achieved through these technologies that perform motion detection, threat and actors profiling, and real-time alerts. However, an important requirement in these increasingly prevalent deployments is the preservation of privacy and enforcement of protection of personal identifiable information. Thus, strong encryption and anonymization techniques should be applied to the collected data. In this IEEE Big Data Cup 2022 challenge, different masking, encoding and homomorphic encryption techniques were applied to the images to protect the privacy of their contents. Participants are required to develop detection solutions to perform privacy preserving matching of these images. In this paper, we describe our solution which is based on state-of-the-art deep convolutional neural networks and various data augmentation techniques. Our solution achieved 1st place at the IEEE Big Data Cup 2022: Privacy Preserving Matching of Encrypted Images Challenge.
* Keywords: privacy preservation, privacy enhancing, masking, encoding, homomorphic encryption, deep learning, convolutional neural networks
Unsupervised Visual Defect Detection with Score-Based Generative Model
Nov 29, 2022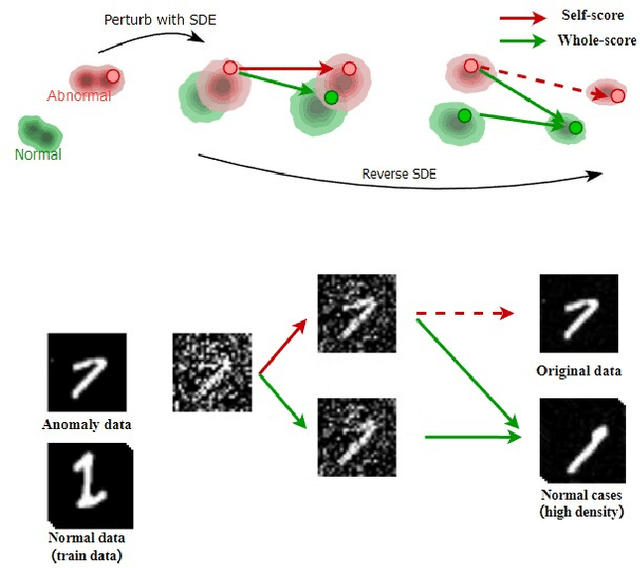

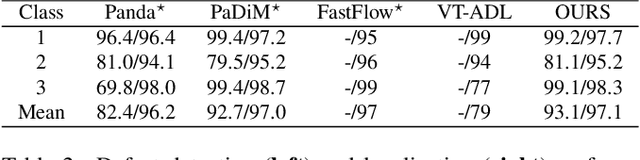
Anomaly Detection (AD), as a critical problem, has been widely discussed. In this paper, we specialize in one specific problem, Visual Defect Detection (VDD), in many industrial applications. And in practice, defect image samples are very rare and difficult to collect. Thus, we focus on the unsupervised visual defect detection and localization tasks and propose a novel framework based on the recent score-based generative models, which synthesize the real image by iterative denoising through stochastic differential equations (SDEs). Our work is inspired by the fact that with noise injected into the original image, the defects may be changed into normal cases in the denoising process (i.e., reconstruction). First, based on the assumption that the anomalous data lie in the low probability density region of the normal data distribution, we explain a common phenomenon that occurs when reconstruction-based approaches are applied to VDD: normal pixels also change during the reconstruction process. Second, due to the differences in normal pixels between the reconstructed and original images, a time-dependent gradient value (i.e., score) of normal data distribution is utilized as a metric, rather than reconstruction loss, to gauge the defects. Third, a novel $T$ scales approach is developed to dramatically reduce the required number of iterations, accelerating the inference process. These practices allow our model to generalize VDD in an unsupervised manner while maintaining reasonably good performance. We evaluate our method on several datasets to demonstrate its effectiveness.
Transcervical Ultrasound Image Guidance System for Transoral Robotic Surgery
Nov 29, 2022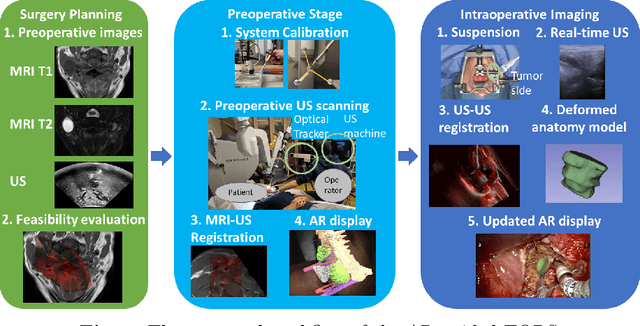
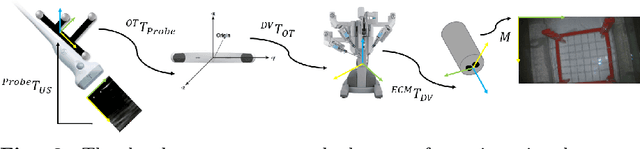


Purpose: Trans-oral robotic surgery (TORS) using the da Vinci surgical robot is a new minimally-invasive surgery method to treat oropharyngeal tumors, but it is a challenging operation. Augmented reality (AR) based on intra-operative ultrasound (US) has the potential to enhance the visualization of the anatomy and cancerous tumors to provide additional tools for decision-making in surgery. Methods: We propose and carry out preliminary evaluations of a US-guided AR system for TORS, with the transducer placed on the neck for a transcervical view. Firstly, we perform a novel MRI-transcervical 3D US registration study. Secondly, we develop a US-robot calibration method with an optical tracker and an AR system to display the anatomy mesh model in the real-time endoscope images inside the surgeon console. Results: Our AR system reaches a mean projection error of 26.81 and 27.85 pixels for the projection from the US to stereo cameras in a water bath experiment. The average target registration error for MRI to 3D US is 8.90 mm for the 3D US transducer and 5.85 mm for freehand 3D US, and the average distance between the vessel centerlines is 2.32 mm. Conclusion: We demonstrate the first proof-of-concept transcervical US-guided AR system for TORS and the feasibility of trans-cervical 3D US-MRI registration. Our results show that trans-cervical 3D US is a promising technique for TORS image guidance.
Building Resilience to Out-of-Distribution Visual Data via Input Optimization and Model Finetuning
Nov 29, 2022

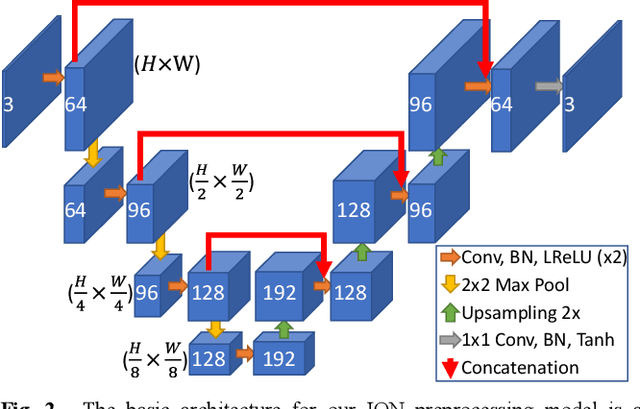

A major challenge in machine learning is resilience to out-of-distribution data, that is data that exists outside of the distribution of a model's training data. Training is often performed using limited, carefully curated datasets and so when a model is deployed there is often a significant distribution shift as edge cases and anomalies not included in the training data are encountered. To address this, we propose the Input Optimisation Network, an image preprocessing model that learns to optimise input data for a specific target vision model. In this work we investigate several out-of-distribution scenarios in the context of semantic segmentation for autonomous vehicles, comparing an Input Optimisation based solution to existing approaches of finetuning the target model with augmented training data and an adversarially trained preprocessing model. We demonstrate that our approach can enable performance on such data comparable to that of a finetuned model, and subsequently that a combined approach, whereby an input optimization network is optimised to target a finetuned model, delivers superior performance to either method in isolation. Finally, we propose a joint optimisation approach, in which input optimization network and target model are trained simultaneously, which we demonstrate achieves significant further performance gains, particularly in challenging edge-case scenarios. We also demonstrate that our architecture can be reduced to a relatively compact size without a significant performance impact, potentially facilitating real time embedded applications.
SyncNet: Using Causal Convolutions and Correlating Objective for Time Delay Estimation in Audio Signals
Mar 28, 2022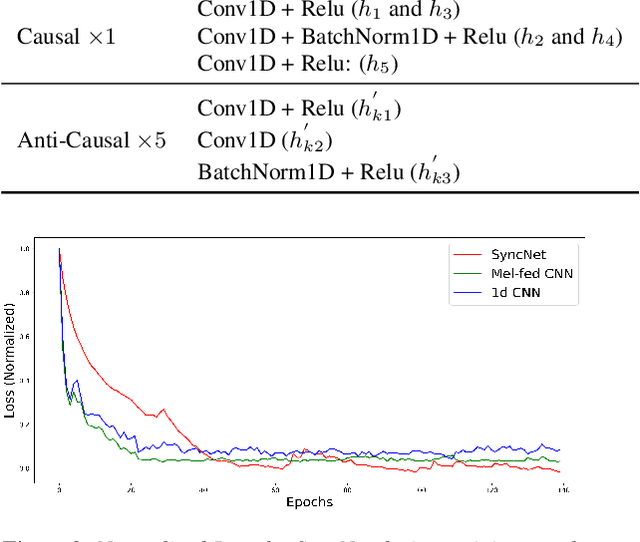
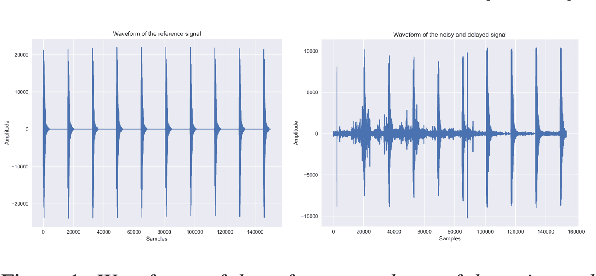
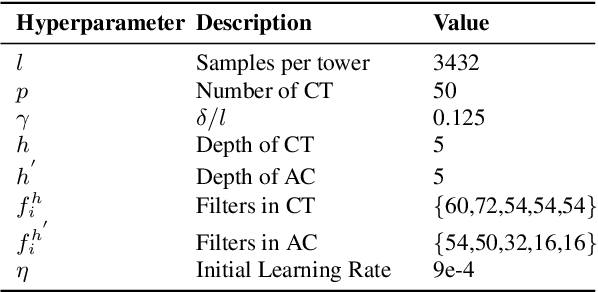
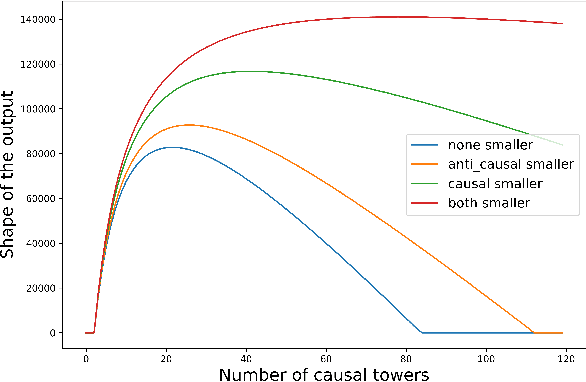
This paper addresses the task of performing robust and reliable time-delay estimation in audio-signals in noisy and reverberating environments. In contrast to the popular signal processing based methods, this paper proposes machine learning based method, i.e., a semi-causal convolutional neural network consisting of a set of causal and anti-causal layers with a novel correlation-based objective function. The causality in the network ensures non-leakage of representations from future time-intervals and the proposed loss function makes the network generate sequences with high correlation at the actual time delay. The proposed approach is also intrinsically interpretable as it does not lose time information. Even a shallow convolution network is able to capture local patterns in sequences, while also correlating them globally. SyncNet outperforms other classical approaches in estimating mutual time delays for different types of audio signals including pulse, speech and musical beats.
Travel Time, Distance and Costs Optimization for Paratransit Operations using Graph Convolutional Neural Network
May 21, 2022

The provision of paratransit services is one option to meet the transportation needs of Vulnerable Road Users (VRUs). Like any other means of transportation, paratransit has obstacles such as high operational costs and longer trip times. As a result, customers are dissatisfied, and paratransit operators have a low approval rating. Researchers have undertaken various studies over the years to better understand the travel behaviors of paratransit customers and how they are operated. According to the findings of these researches, paratransit operators confront the challenge of determining the optimal route for their trips in order to save travel time. Depending on the nature of the challenge, most research used different optimization techniques to solve these routing problems. As a result, the goal of this study is to use Graph Convolutional Neural Networks (GCNs) to assist paratransit operators in researching various operational scenarios in a strategic setting in order to optimize routing, minimize operating costs and minimize their users' travel time. The study was carried out by using a randomized simulated dataset to help determine the decision to make in terms of fleet composition and capacity under different situations. For the various scenarios investigated, the GCN assisted in determining the minimum optimal gap.
Towards Good Practices for Missing Modality Robust Action Recognition
Nov 25, 2022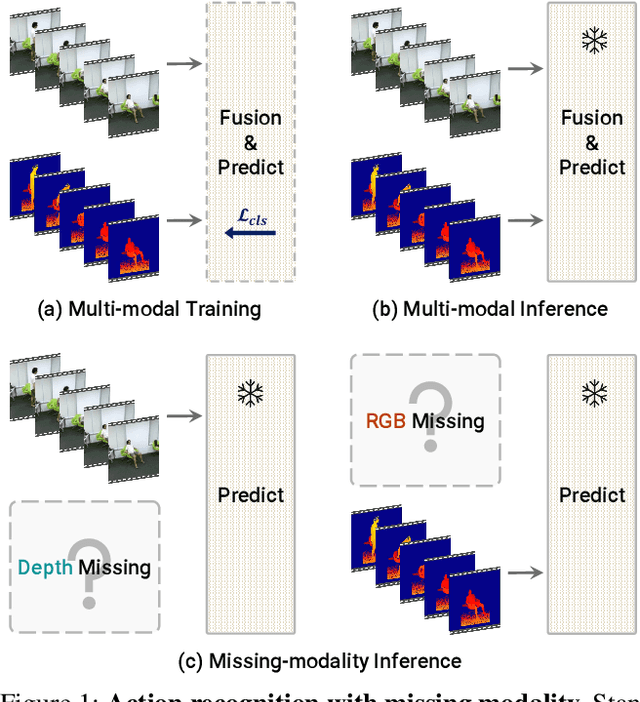
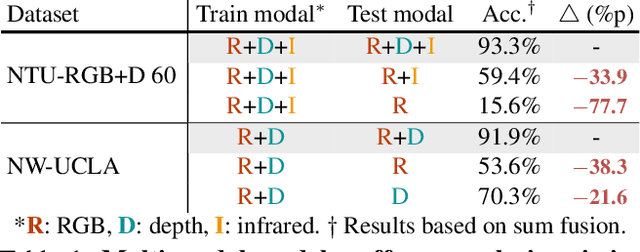
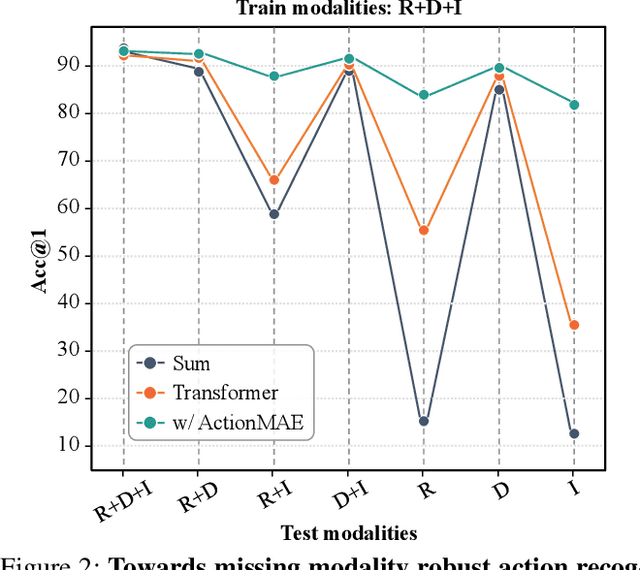

Standard multi-modal models assume the use of the same modalities in training and inference stages. However, in practice, the environment in which multi-modal models operate may not satisfy such assumption. As such, their performances degrade drastically if any modality is missing in the inference stage. We ask: how can we train a model that is robust to missing modalities? This paper seeks a set of good practices for multi-modal action recognition, with a particular interest in circumstances where some modalities are not available at an inference time. First, we study how to effectively regularize the model during training (e.g., data augmentation). Second, we investigate on fusion methods for robustness to missing modalities: we find that transformer-based fusion shows better robustness for missing modality than summation or concatenation. Third, we propose a simple modular network, ActionMAE, which learns missing modality predictive coding by randomly dropping modality features and tries to reconstruct them with the remaining modality features. Coupling these good practices, we build a model that is not only effective in multi-modal action recognition but also robust to modality missing. Our model achieves the state-of-the-arts on multiple benchmarks and maintains competitive performances even in missing modality scenarios. Codes are available at https://github.com/sangminwoo/ActionMAE.