 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Explainable AI based Glaucoma Detection using Transfer Learning and LIME
Oct 07, 2022
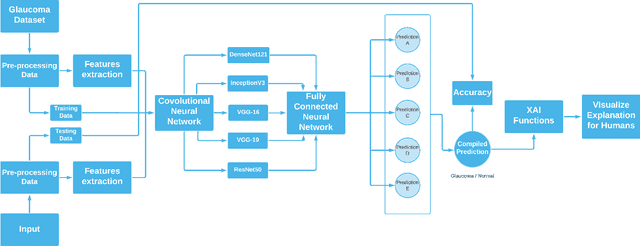

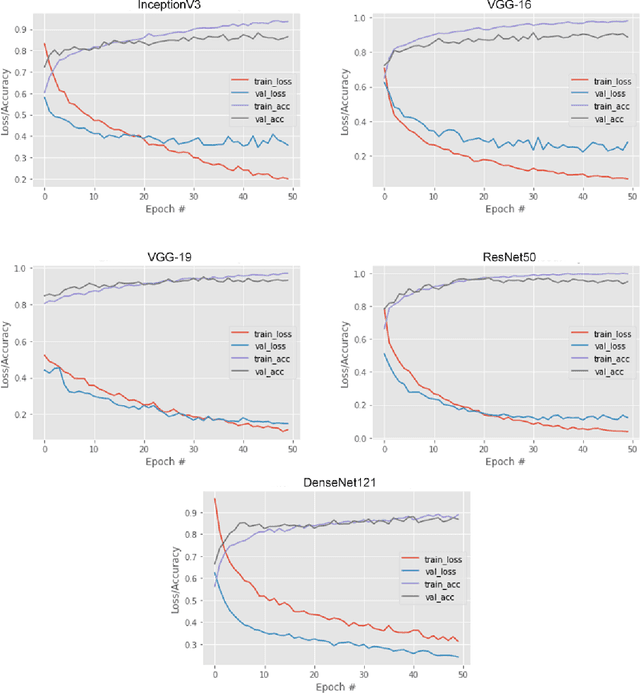
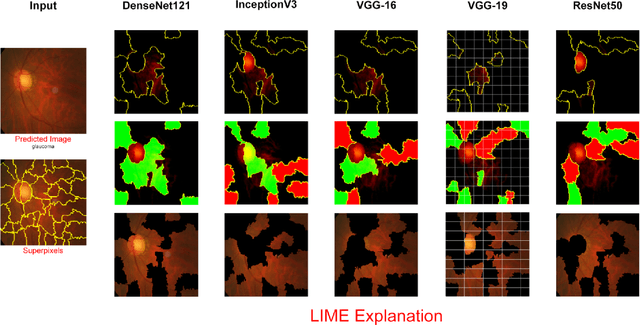
Glaucoma is the second driving reason for partial or complete blindness among all the visual deficiencies which mainly occurs because of excessive pressure in the eye due to anxiety or depression which damages the optic nerve and creates complications in vision. Traditional glaucoma screening is a time-consuming process that necessitates the medical professionals' constant attention, and even so time to time due to the time constrains and pressure they fail to classify correctly that leads to wrong treatment. Numerous efforts have been made to automate the entire glaucoma classification procedure however, these existing models in general have a black box characteristics that prevents users from understanding the key reasons behind the prediction and thus medical practitioners generally can not rely on these system. In this article after comparing with various pre-trained models, we propose a transfer learning model that is able to classify Glaucoma with 94.71\% accuracy. In addition, we have utilized Local Interpretable Model-Agnostic Explanations(LIME) that introduces explainability in our system. This improvement enables medical professionals obtain important and comprehensive information that aid them in making judgments. It also lessen the opacity and fragility of the traditional deep learning models.
In-situ Model Downloading to Realize Versatile Edge AI in 6G Mobile Networks
Oct 07, 2022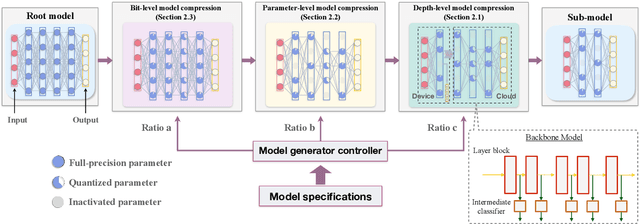
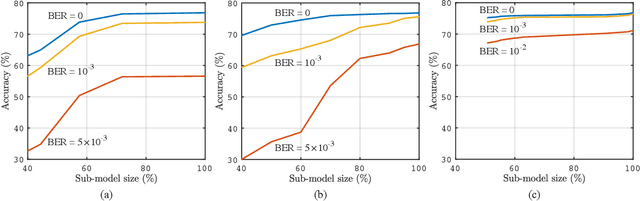
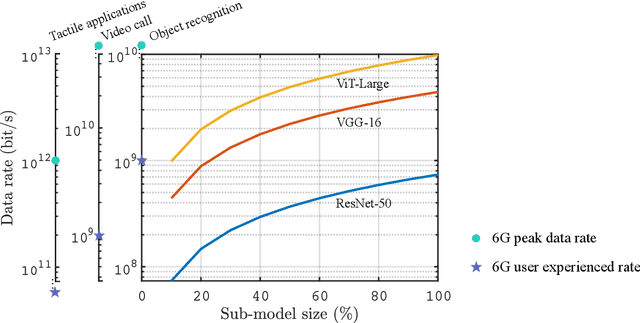
The sixth-generation (6G) mobile networks are expected to feature the ubiquitous deployment of machine learning and AI algorithms at the network edge. With rapid advancements in edge AI, the time has come to realize intelligence downloading onto edge devices (e.g., smartphones and sensors). To materialize this version, we propose a novel technology in this article, called in-situ model downloading, that aims to achieve transparent and real-time replacement of on-device AI models by downloading from an AI library in the network. Its distinctive feature is the adaptation of downloading to time-varying situations (e.g., application, location, and time), devices' heterogeneous storage-and-computing capacities, and channel states. A key component of the presented framework is a set of techniques that dynamically compress a downloaded model at the depth-level, parameter-level, or bit-level to support adaptive model downloading. We further propose a virtualized 6G network architecture customized for deploying in-situ model downloading with the key feature of a three-tier (edge, local, and central) AI library. Furthermore, experiments are conducted to quantify 6G connectivity requirements and research opportunities pertaining to the proposed technology are discussed.
Uniform Passive Fault-Tolerant Control of a Quadcopter with One, Two, or Three Rotor Failure
Nov 23, 2022
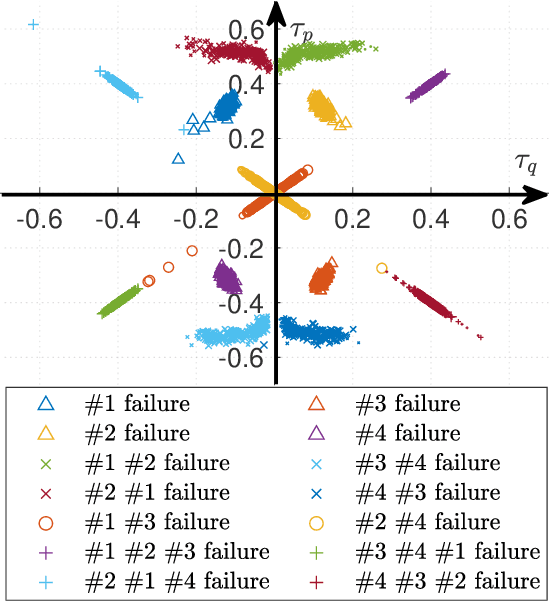
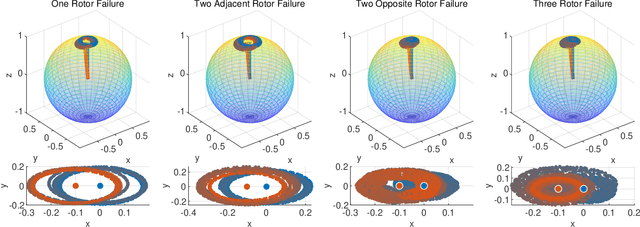
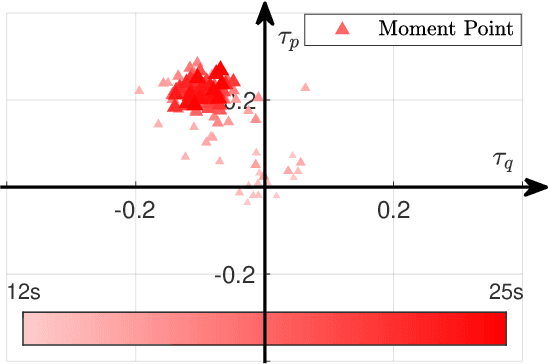
This study proposes a uniform passive fault-tolerant control (FTC) method for a quadcopter that does not rely on fault information subject to one, two adjacent, two opposite, or three rotors failure. The uniform control implies that the passive FTC is able to cover the condition from quadcopter fault-free to rotor failure without controller switching. To achieve the purpose of the passive FTC, the rotors' fault is modeled as a disturbance acting on the virtual control of the quadcopter system. The disturbance estimate is used directly for the passive FTC with rotor failure. To avoid controller switching between normal control and FTC, a dynamic control allocation is used. In addition, the closed-loop stability has been analyzed and a virtual control feedback is adopted to achieve the passive FTC for the quadcopter with two and three rotor failure. To validate the proposed uniform passive FTC method, outdoor experiments are performed for the first time, which have demonstrated that the hovering quadcopter is able to recover from one rotor failure by the proposed controller and continue to fly even if two adjacent, two opposite, or three rotors fail, without any rotor fault information and controller switching.
Peekaboo: Text to Image Diffusion Models are Zero-Shot Segmentors
Nov 23, 2022
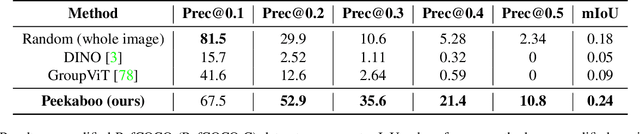


Recent diffusion-based generative models combined with vision-language models are capable of creating realistic images from natural language prompts. While these models are trained on large internet-scale datasets, such pre-trained models are not directly introduced to any semantic localization or grounding. Most current approaches for localization or grounding rely on human-annotated localization information in the form of bounding boxes or segmentation masks. The exceptions are a few unsupervised methods that utilize architectures or loss functions geared towards localization, but they need to be trained separately. In this work, we explore how off-the-shelf diffusion models, trained with no exposure to such localization information, are capable of grounding various semantic phrases with no segmentation-specific re-training. An inference time optimization process is introduced, that is capable of generating segmentation masks conditioned on natural language. We evaluate our proposal Peekaboo for unsupervised semantic segmentation on the Pascal VOC dataset. In addition, we evaluate for referring segmentation on the RefCOCO dataset. In summary, we present a first zero-shot, open-vocabulary, unsupervised (no localization information), semantic grounding technique leveraging diffusion-based generative models with no re-training. Our code will be released publicly.
Pruned Lightweight Encoders for Computer Vision
Nov 23, 2022
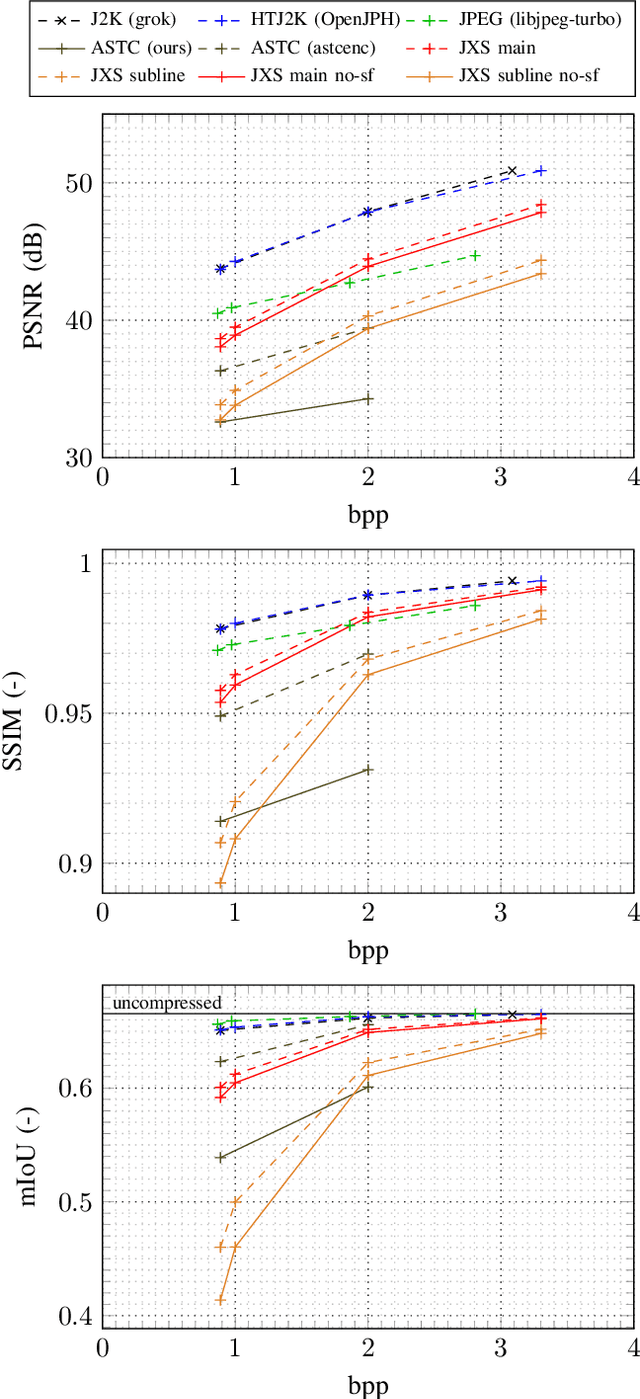

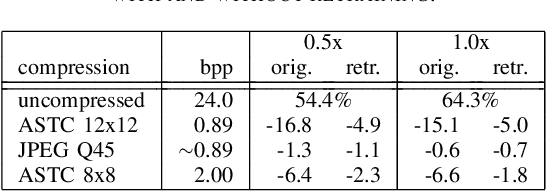
Latency-critical computer vision systems, such as autonomous driving or drone control, require fast image or video compression when offloading neural network inference to a remote computer. To ensure low latency on a near-sensor edge device, we propose the use of lightweight encoders with constant bitrate and pruned encoding configurations, namely, ASTC and JPEG XS. Pruning introduces significant distortion which we show can be recovered by retraining the neural network with compressed data after decompression. Such an approach does not modify the network architecture or require coding format modifications. By retraining with compressed datasets, we reduced the classification accuracy and segmentation mean intersection over union (mIoU) degradation due to ASTC compression to 4.9-5.0 percentage points (pp) and 4.4-4.0 pp, respectively. With the same method, the mIoU lost due to JPEG XS compression at the main profile was restored to 2.7-2.3 pp. In terms of encoding speed, our ASTC encoder implementation is 2.3x faster than JPEG. Even though the JPEG XS reference encoder requires optimizations to reach low latency, we showed that disabling significance flag coding saves 22-23% of encoding time at the cost of 0.4-0.3 mIoU after retraining.
Cooperative data-driven modeling
Nov 23, 2022

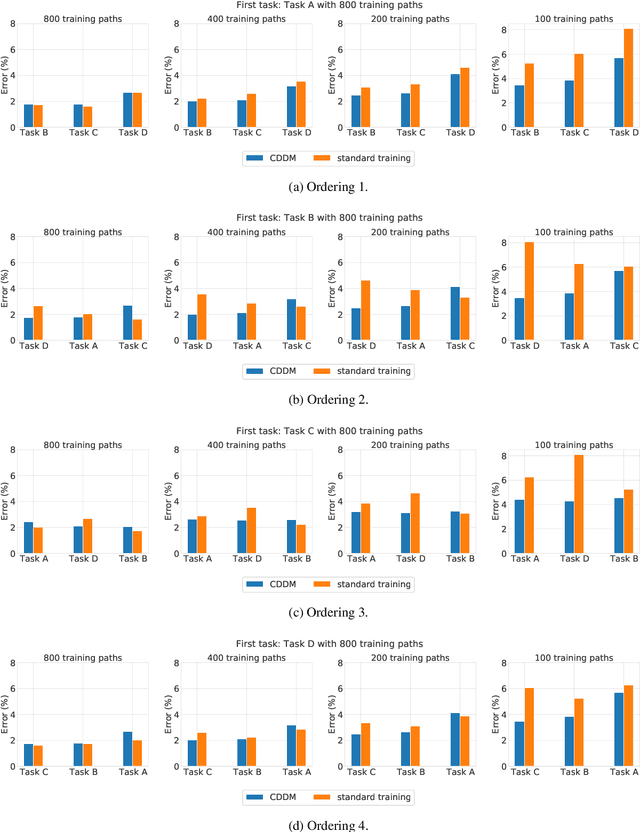
Data-driven modeling in mechanics is evolving rapidly based on recent machine learning advances, especially on artificial neural networks. As the field matures, new data and models created by different groups become available, opening possibilities for cooperative modeling. However, artificial neural networks suffer from catastrophic forgetting, i.e. they forget how to perform an old task when trained on a new one. This hinders cooperation because adapting an existing model for a new task affects the performance on a previous task trained by someone else. The authors developed a continual learning method that addresses this issue, applying it here for the first time to solid mechanics. In particular, the method is applied to recurrent neural networks to predict history-dependent plasticity behavior, although it can be used on any other architecture (feedforward, convolutional, etc.) and to predict other phenomena. This work intends to spawn future developments on continual learning that will foster cooperative strategies among the mechanics community to solve increasingly challenging problems. We show that the chosen continual learning strategy can sequentially learn several constitutive laws without forgetting them, using less data to achieve the same error as standard training of one law per model.
Indian Commercial Truck License Plate Detection and Recognition for Weighbridge Automation
Nov 23, 2022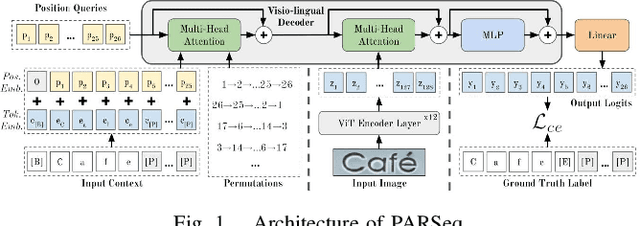



Detection and recognition of a licence plate is important when automating weighbridge services. While many large databases are available for Latin and Chinese alphanumeric license plates, data for Indian License Plates is inadequate. In particular, databases of Indian commercial truck license plates are inadequate, despite the fact that commercial vehicle license plate recognition plays a profound role in terms of logistics management and weighbridge automation. Moreover, models to recognise license plates are not effectively able to generalise to such data due to its challenging nature, and due to the abundant frequency of handwritten license plates, leading to the usage of diverse font styles. Thus, a database and effective models to recognise and detect such license plates are crucial. This paper provides a database on commercial truck license plates, and using state-of-the-art models in real-time object Detection: You Only Look Once Version 7, and SceneText Recognition: Permuted Autoregressive Sequence Models, our method outperforms the other cited references where the maximum accuracy obtained was less than 90%, while we have achieved 95.82% accuracy in our algorithm implementation on the presented challenging license plate dataset. Index Terms- Automatic License Plate Recognition, character recognition, license plate detection, vision transformer.
Benchmarking variational quantum circuits with permutation symmetry
Nov 23, 2022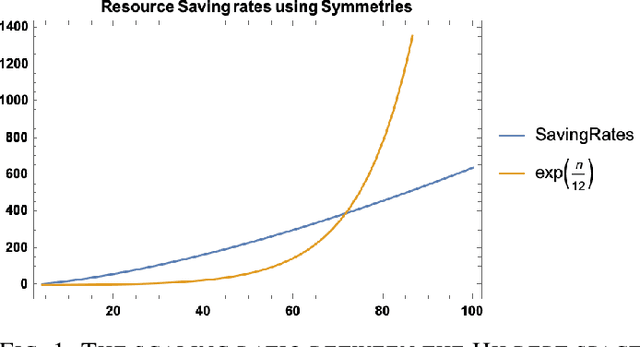
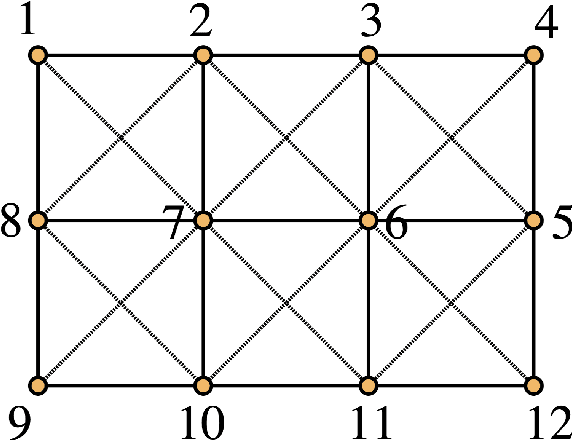
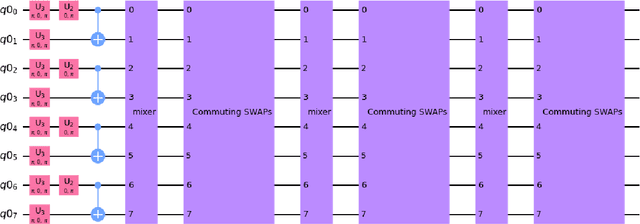
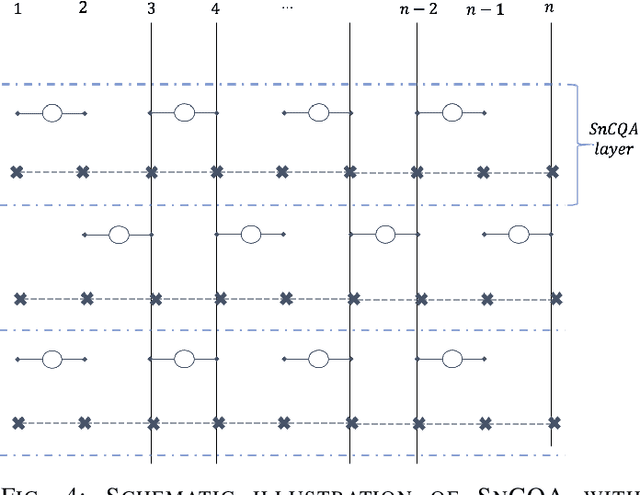
We propose SnCQA, a set of hardware-efficient variational circuits of equivariant quantum convolutional circuits respective to permutation symmetries and spatial lattice symmetries with the number of qubits $n$. By exploiting permutation symmetries of the system, such as lattice Hamiltonians common to many quantum many-body and quantum chemistry problems, Our quantum neural networks are suitable for solving machine learning problems where permutation symmetries are present, which could lead to significant savings of computational costs. Aside from its theoretical novelty, we find our simulations perform well in practical instances of learning ground states in quantum computational chemistry, where we could achieve comparable performances to traditional methods with few tens of parameters. Compared to other traditional variational quantum circuits, such as the pure hardware-efficient ansatz (pHEA), we show that SnCQA is more scalable, accurate, and noise resilient (with $20\times$ better performance on $3 \times 4$ square lattice and $200\% - 1000\%$ resource savings in various lattice sizes and key criterions such as the number of layers, parameters, and times to converge in our cases), suggesting a potentially favorable experiment on near-time quantum devices.
Join the High Accuracy Club on ImageNet with A Binary Neural Network Ticket
Nov 23, 2022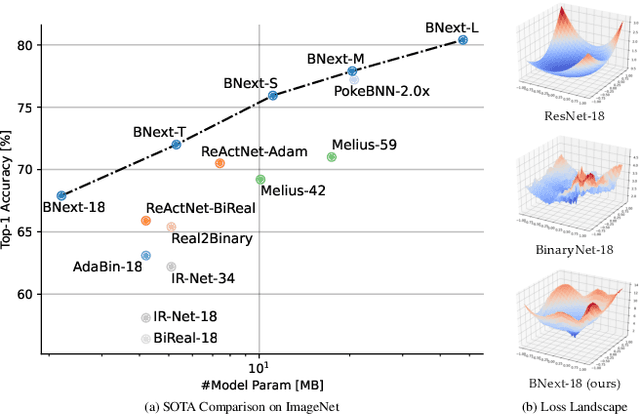
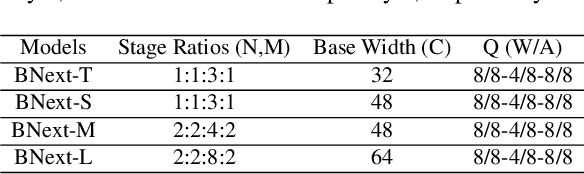

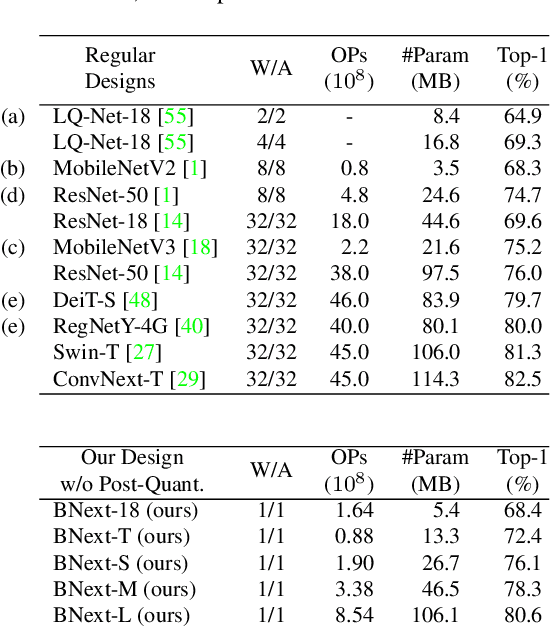
Binary neural networks are the extreme case of network quantization, which has long been thought of as a potential edge machine learning solution. However, the significant accuracy gap to the full-precision counterparts restricts their creative potential for mobile applications. In this work, we revisit the potential of binary neural networks and focus on a compelling but unanswered problem: how can a binary neural network achieve the crucial accuracy level (e.g., 80%) on ILSVRC-2012 ImageNet? We achieve this goal by enhancing the optimization process from three complementary perspectives: (1) We design a novel binary architecture BNext based on a comprehensive study of binary architectures and their optimization process. (2) We propose a novel knowledge-distillation technique to alleviate the counter-intuitive overfitting problem observed when attempting to train extremely accurate binary models. (3) We analyze the data augmentation pipeline for binary networks and modernize it with up-to-date techniques from full-precision models. The evaluation results on ImageNet show that BNext, for the first time, pushes the binary model accuracy boundary to 80.57% and significantly outperforms all the existing binary networks. Code and trained models are available at: (blind URL, see appendix).
Structural Knowledge Distillation for Object Detection
Nov 23, 2022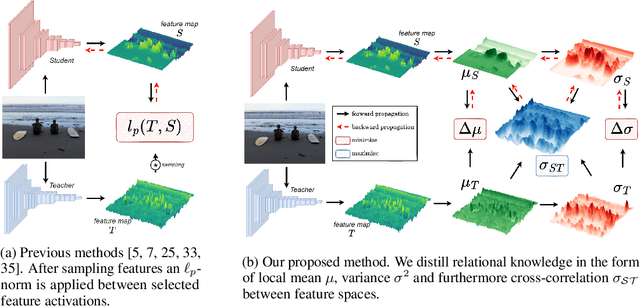
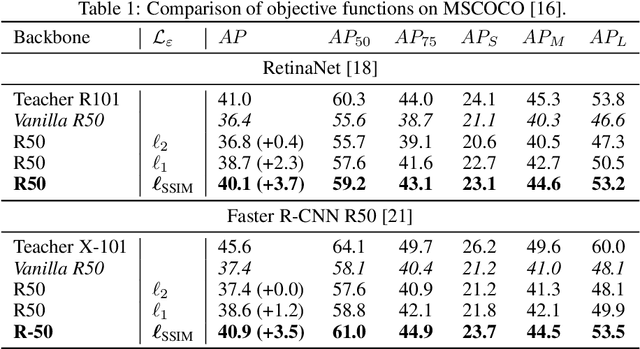

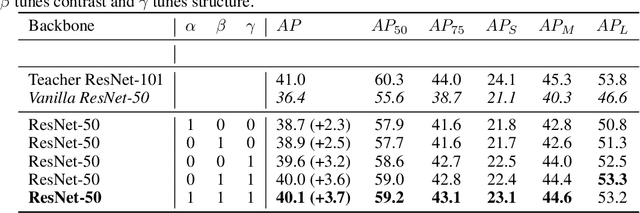
Knowledge Distillation (KD) is a well-known training paradigm in deep neural networks where knowledge acquired by a large teacher model is transferred to a small student. KD has proven to be an effective technique to significantly improve the student's performance for various tasks including object detection. As such, KD techniques mostly rely on guidance at the intermediate feature level, which is typically implemented by minimizing an lp-norm distance between teacher and student activations during training. In this paper, we propose a replacement for the pixel-wise independent lp-norm based on the structural similarity (SSIM). By taking into account additional contrast and structural cues, feature importance, correlation and spatial dependence in the feature space are considered in the loss formulation. Extensive experiments on MSCOCO demonstrate the effectiveness of our method across different training schemes and architectures. Our method adds only little computational overhead, is straightforward to implement and at the same time it significantly outperforms the standard lp-norms. Moreover, more complex state-of-the-art KD methods using attention-based sampling mechanisms are outperformed, including a +3.5 AP gain using a Faster R-CNN R-50 compared to a vanilla model.