 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeepFT: Fault-Tolerant Edge Computing using a Self-Supervised Deep Surrogate Model
Dec 02, 2022
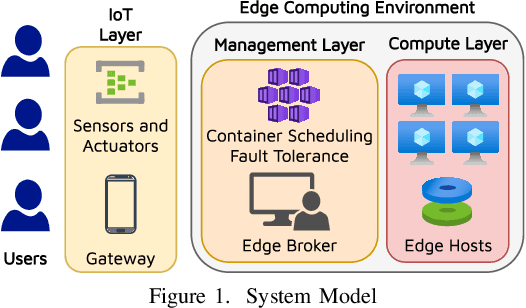


The emergence of latency-critical AI applications has been supported by the evolution of the edge computing paradigm. However, edge solutions are typically resource-constrained, posing reliability challenges due to heightened contention for compute and communication capacities and faulty application behavior in the presence of overload conditions. Although a large amount of generated log data can be mined for fault prediction, labeling this data for training is a manual process and thus a limiting factor for automation. Due to this, many companies resort to unsupervised fault-tolerance models. Yet, failure models of this kind can incur a loss of accuracy when they need to adapt to non-stationary workloads and diverse host characteristics. To cope with this, we propose a novel modeling approach, called DeepFT, to proactively avoid system overloads and their adverse effects by optimizing the task scheduling and migration decisions. DeepFT uses a deep surrogate model to accurately predict and diagnose faults in the system and co-simulation based self-supervised learning to dynamically adapt the model in volatile settings. It offers a highly scalable solution as the model size scales by only 3 and 1 percent per unit increase in the number of active tasks and hosts. Extensive experimentation on a Raspberry-Pi based edge cluster with DeFog benchmarks shows that DeepFT can outperform state-of-the-art baseline methods in fault-detection and QoS metrics. Specifically, DeepFT gives the highest F1 scores for fault-detection, reducing service deadline violations by up to 37\% while also improving response time by up to 9%.
Detecting Anomalies within Time Series using Local Neural Transformations
Feb 08, 2022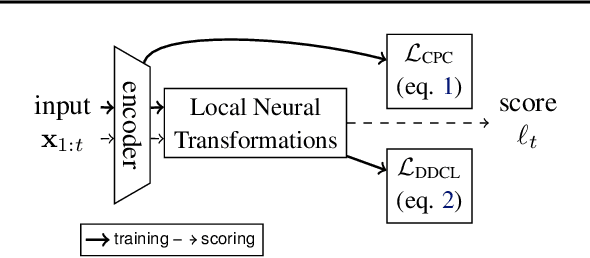
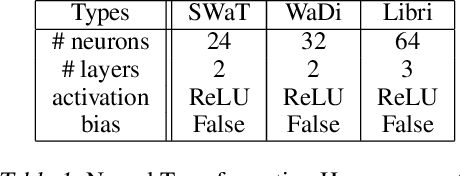
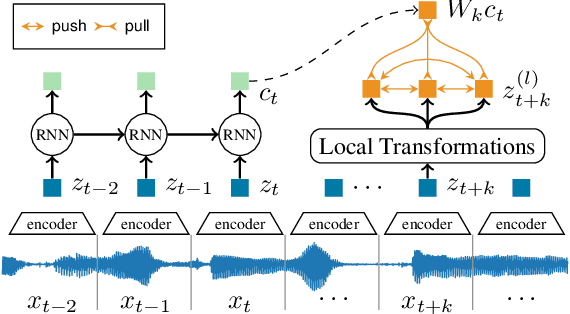
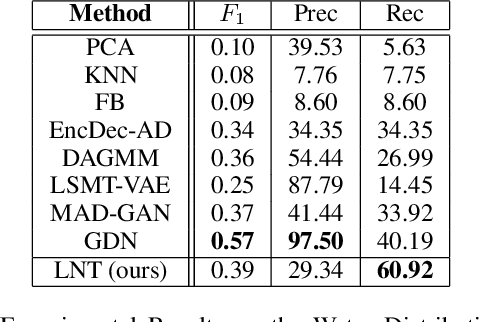
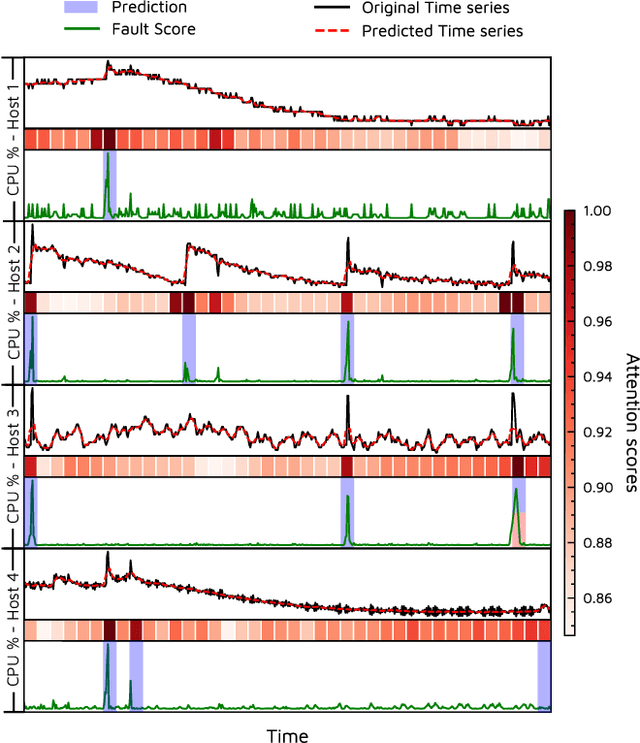
We develop a new method to detect anomalies within time series, which is essential in many application domains, reaching from self-driving cars, finance, and marketing to medical diagnosis and epidemiology. The method is based on self-supervised deep learning that has played a key role in facilitating deep anomaly detection on images, where powerful image transformations are available. However, such transformations are widely unavailable for time series. Addressing this, we develop Local Neural Transformations(LNT), a method learning local transformations of time series from data. The method produces an anomaly score for each time step and thus can be used to detect anomalies within time series. We prove in a theoretical analysis that our novel training objective is more suitable for transformation learning than previous deep Anomaly detection(AD) methods. Our experiments demonstrate that LNT can find anomalies in speech segments from the LibriSpeech data set and better detect interruptions to cyber-physical systems than previous work. Visualization of the learned transformations gives insight into the type of transformations that LNT learns.
Quality Assurance in MLOps Setting: An Industrial Perspective
Nov 24, 2022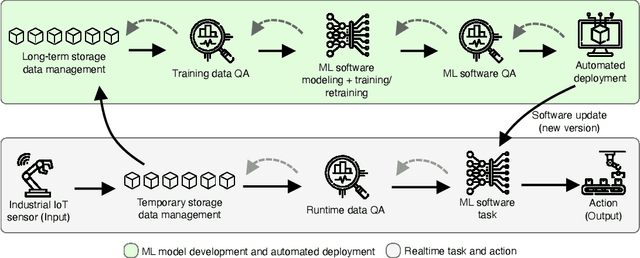
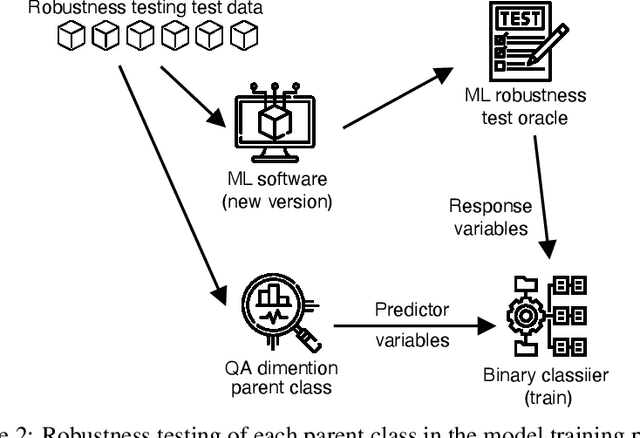
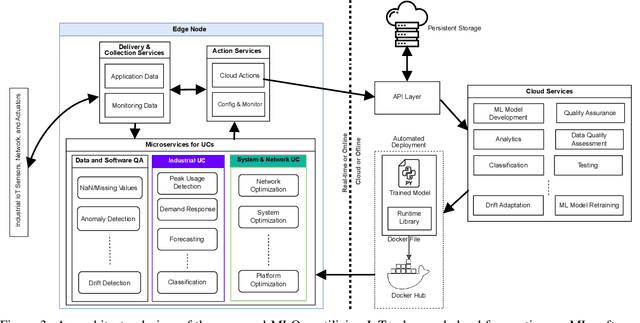
Today, machine learning (ML) is widely used in industry to provide the core functionality of production systems. However, it is practically always used in production systems as part of a larger end-to-end software system that is made up of several other components in addition to the ML model. Due to production demand and time constraints, automated software engineering practices are highly applicable. The increased use of automated ML software engineering practices in industries such as manufacturing and utilities requires an automated Quality Assurance (QA) approach as an integral part of ML software. Here, QA helps reduce risk by offering an objective perspective on the software task. Although conventional software engineering has automated tools for QA data analysis for data-driven ML, the use of QA practices for ML in operation (MLOps) is lacking. This paper examines the QA challenges that arise in industrial MLOps and conceptualizes modular strategies to deal with data integrity and Data Quality (DQ). The paper is accompanied by real industrial use-cases from industrial partners. The paper also presents several challenges that may serve as a basis for future studies.
ReFace: Improving Clothes-Changing Re-Identification With Face Features
Nov 24, 2022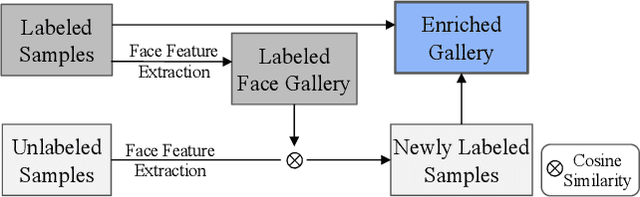
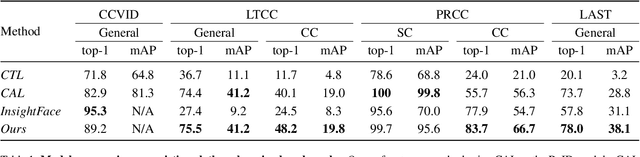
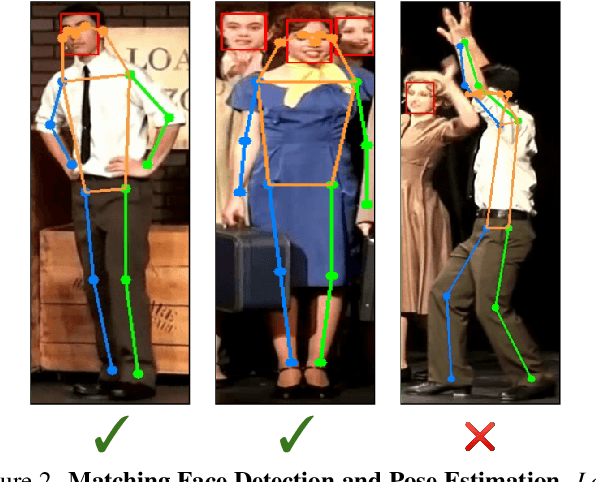
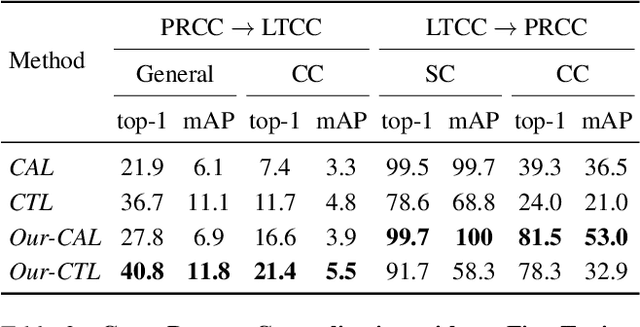
Person re-identification (ReID) has been an active research field for many years. Despite that, models addressing this problem tend to perform poorly when the task is to re-identify the same people over a prolonged time, due to appearance changes such as different clothes and hairstyles. In this work, we introduce a new method that takes full advantage of the ability of existing ReID models to extract appearance-related features and combines it with a face feature extraction model to achieve new state-of-the-art results, both on image-based and video-based benchmarks. Moreover, we show how our method could be used for an application in which multiple people of interest, under clothes-changing settings, should be re-identified given an unseen video and a limited amount of labeled data. We claim that current ReID benchmarks do not represent such real-world scenarios, and publish a new dataset, 42Street, based on a theater play as an example of such an application. We show that our proposed method outperforms existing models also on this dataset while using only pre-trained modules and without any further training.
Learning-enhanced Nonlinear Model Predictive Control using Knowledge-based Neural Ordinary Differential Equations and Deep Ensembles
Nov 24, 2022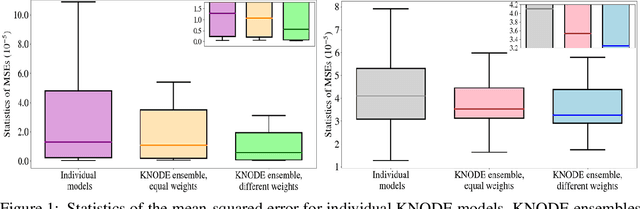
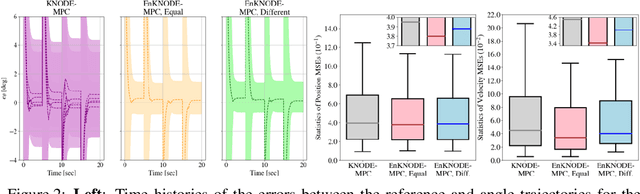
Nonlinear model predictive control (MPC) is a flexible and increasingly popular framework used to synthesize feedback control strategies that can satisfy both state and control input constraints. In this framework, an optimization problem, subjected to a set of dynamics constraints characterized by a nonlinear dynamics model, is solved at each time step. Despite its versatility, the performance of nonlinear MPC often depends on the accuracy of the dynamics model. In this work, we leverage deep learning tools, namely knowledge-based neural ordinary differential equations (KNODE) and deep ensembles, to improve the prediction accuracy of this model. In particular, we learn an ensemble of KNODE models, which we refer to as the KNODE ensemble, to obtain an accurate prediction of the true system dynamics. This learned model is then integrated into a novel learning-enhanced nonlinear MPC framework. We provide sufficient conditions that guarantees asymptotic stability of the closed-loop system and show that these conditions can be implemented in practice. We show that the KNODE ensemble provides more accurate predictions and illustrate the efficacy and closed-loop performance of the proposed nonlinear MPC framework using two case studies.
Attention-based Feature Compression for CNN Inference Offloading in Edge Computing
Nov 24, 2022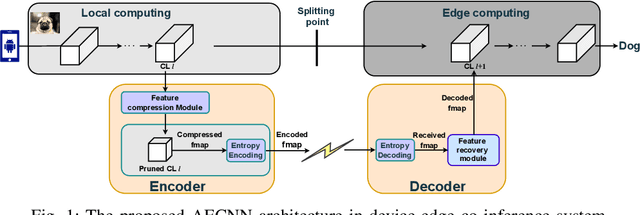
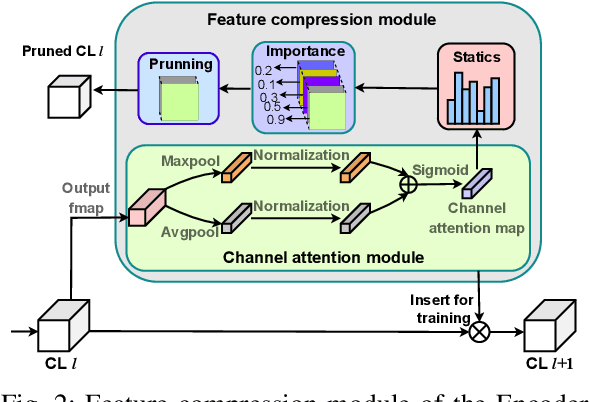
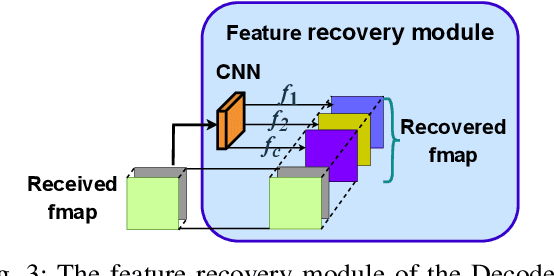
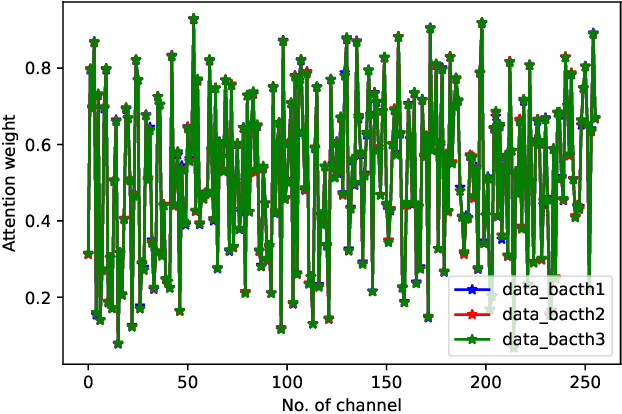
This paper studies the computational offloading of CNN inference in device-edge co-inference systems. Inspired by the emerging paradigm semantic communication, we propose a novel autoencoder-based CNN architecture (AECNN), for effective feature extraction at end-device. We design a feature compression module based on the channel attention method in CNN, to compress the intermediate data by selecting the most important features. To further reduce communication overhead, we can use entropy encoding to remove the statistical redundancy in the compressed data. At the receiver, we design a lightweight decoder to reconstruct the intermediate data through learning from the received compressed data to improve accuracy. To fasten the convergence, we use a step-by-step approach to train the neural networks obtained based on ResNet-50 architecture. Experimental results show that AECNN can compress the intermediate data by more than 256x with only about 4% accuracy loss, which outperforms the state-of-the-art work, BottleNet++. Compared to offloading inference task directly to edge server, AECNN can complete inference task earlier, in particular, under poor wireless channel condition, which highlights the effectiveness of AECNN in guaranteeing higher accuracy within time constraint.
Lightweight Event-based Optical Flow Estimation via Iterative Deblurring
Nov 24, 2022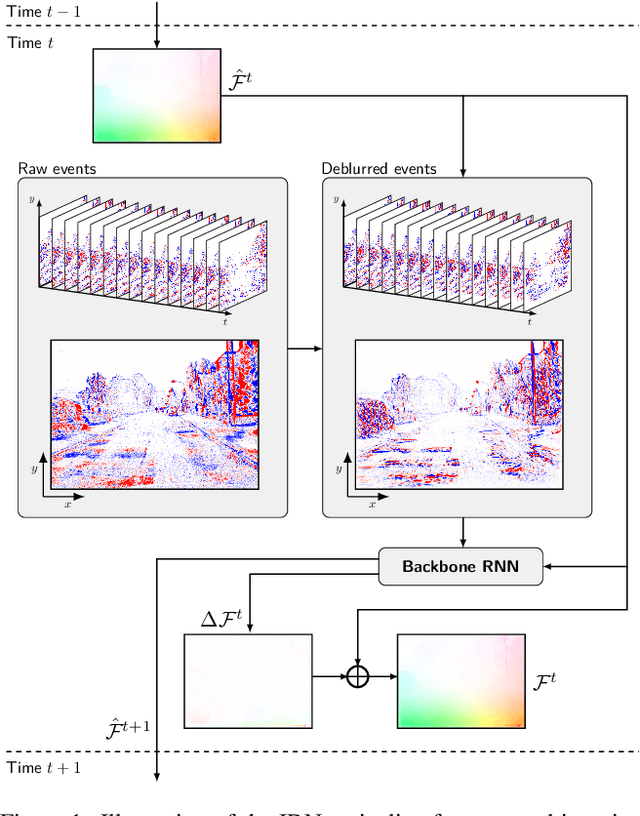
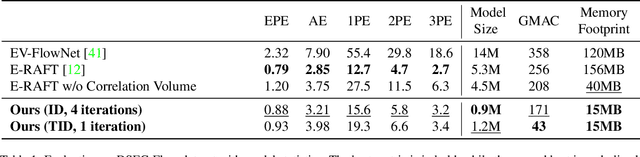
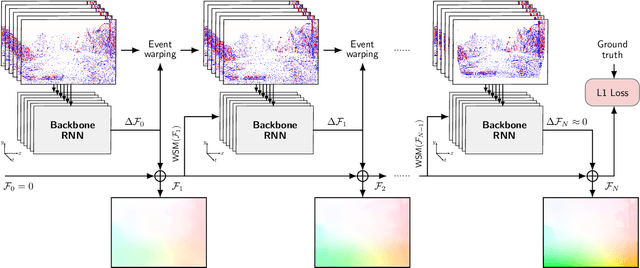

Inspired by frame-based methods, state-of-the-art event-based optical flow networks rely on the explicit computation of correlation volumes, which are expensive to compute and store on systems with limited processing budget and memory. To this end, we introduce IDNet (Iterative Deblurring Network), a lightweight yet well-performing event-based optical flow network without using correlation volumes. IDNet leverages the unique spatiotemporally continuous nature of event streams to propose an alternative way of implicitly capturing correlation through iterative refinement and motion deblurring. Our network does not compute correlation volumes but rather utilizes a recurrent network to maximize the spatiotemporal correlation of events iteratively. We further propose two iterative update schemes: "ID" which iterates over the same batch of events, and "TID" which iterates over time with streaming events in an online fashion. Benchmark results show the former "ID" scheme can reach close to state-of-the-art performance with 33% of savings in compute and 90% in memory footprint, while the latter "TID" scheme is even more efficient promising 83% of compute savings and 15 times less latency at the cost of 18% of performance drop.
Ham2Pose: Animating Sign Language Notation into Pose Sequences
Nov 24, 2022
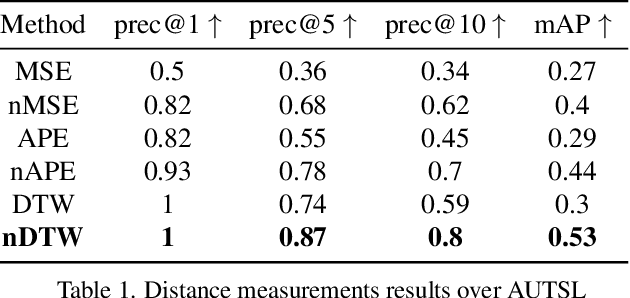

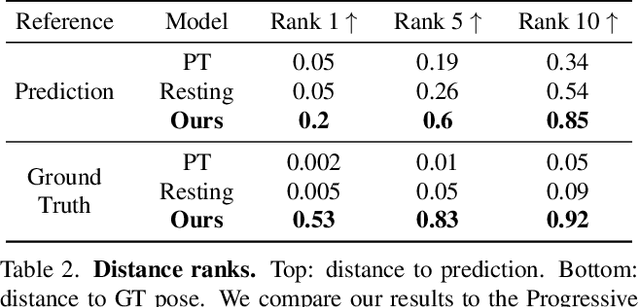
Translating spoken languages into Sign languages is necessary for open communication between the hearing and hearing-impaired communities. To achieve this goal, we propose the first method for animating a text written in HamNoSys, a lexical Sign language notation, into signed pose sequences. As HamNoSys is universal, our proposed method offers a generic solution invariant to the target Sign language. Our method gradually generates pose predictions using transformer encoders that create meaningful representations of the text and poses while considering their spatial and temporal information. We use weak supervision for the training process and show that our method succeeds in learning from partial and inaccurate data. Additionally, we offer a new distance measurement for pose sequences, normalized Dynamic Time Warping (nDTW), based on DTW over normalized keypoints trajectories, and validate its correctness using AUTSL, a large-scale Sign language dataset. We show that it measures the distance between pose sequences more accurately than existing measurements and use it to assess the quality of our generated pose sequences. Code for the data pre-processing, the model, and the distance measurement is publicly released for future research.
Playable Environments: Video Manipulation in Space and Time
Mar 15, 2022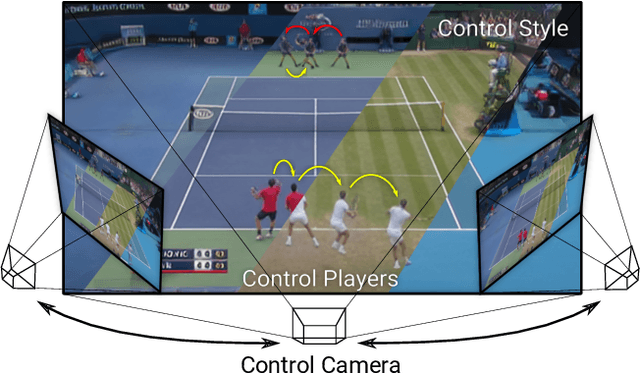

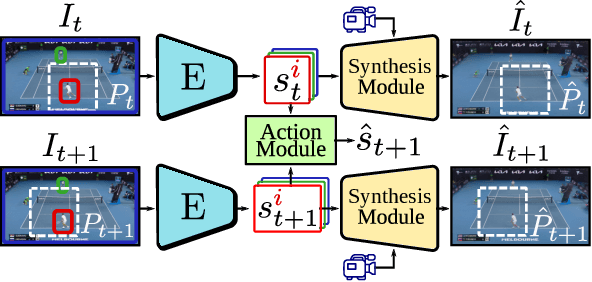
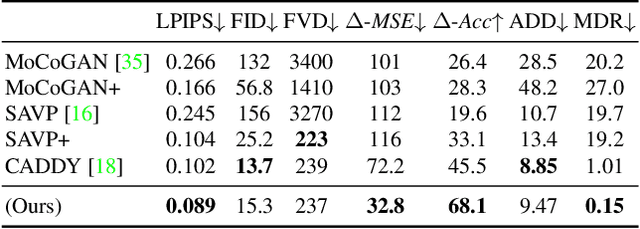
We present Playable Environments - a new representation for interactive video generation and manipulation in space and time. With a single image at inference time, our novel framework allows the user to move objects in 3D while generating a video by providing a sequence of desired actions. The actions are learnt in an unsupervised manner. The camera can be controlled to get the desired viewpoint. Our method builds an environment state for each frame, which can be manipulated by our proposed action module and decoded back to the image space with volumetric rendering. To support diverse appearances of objects, we extend neural radiance fields with style-based modulation. Our method trains on a collection of various monocular videos requiring only the estimated camera parameters and 2D object locations. To set a challenging benchmark, we introduce two large scale video datasets with significant camera movements. As evidenced by our experiments, playable environments enable several creative applications not attainable by prior video synthesis works, including playable 3D video generation, stylization and manipulation. Further details, code and examples are available at https://willi-menapace.github.io/playable-environments-website
First Competitive Ant Colony Scheme for the CARP
Nov 19, 2022
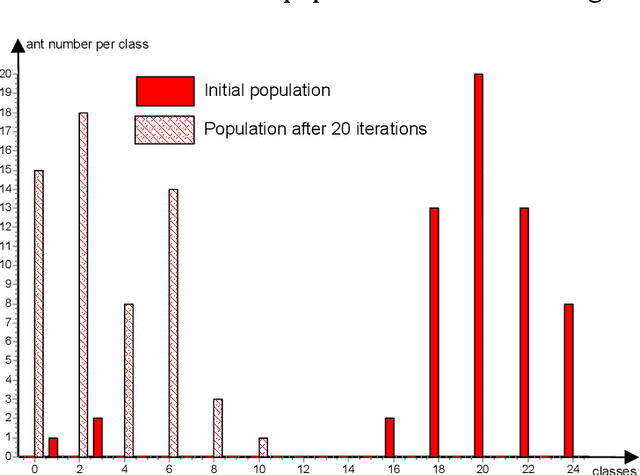
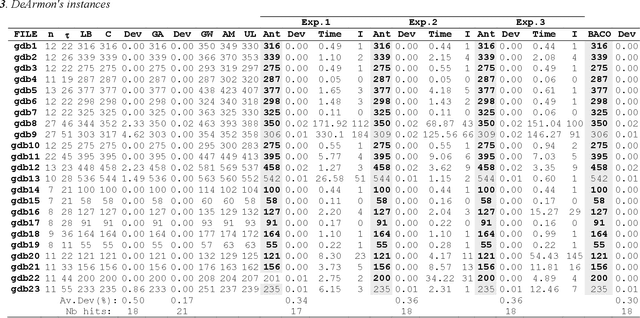
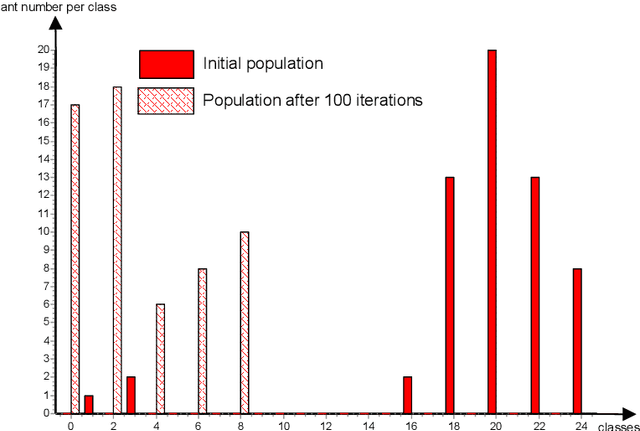
This paper addresses the Capacitated Arc Routing Problem (CARP) using an Ant Colony Optimization scheme. Ant Colony schemes can compute solutions for medium scale instances of VRP. The proposed Ant Colony is dedicated to large-scale instances of CARP with more than 140 nodes and 190 arcs to service. The Ant Colony scheme is coupled with a local search procedure and provides high quality solutions. The benchmarks we carried out prove possible to obtain solutions as profitable as CARPET ones can be obtained using such scheme when a sufficient number of iterations is devoted to the ants. It competes with the Genetic Algorithm of Lacomme et al. regarding solution quality but it is more time consuming on large scale instances. The method has been intensively benchmarked on the well-known instances of Eglese, DeArmon and the last ones of Belenguer and Benavent. This research report is a step forward CARP resolution by Ant Colony proving ant schemes can compete with Taboo search methods and Genetic Algorithms