 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning-Based Vehicle Speed Prediction for Ecological Adaptive Cruise Control in Urban and Highway Scenarios
Nov 30, 2022
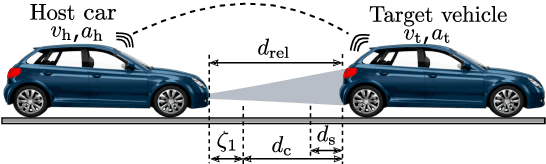

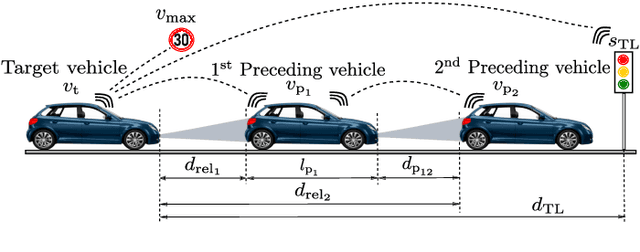
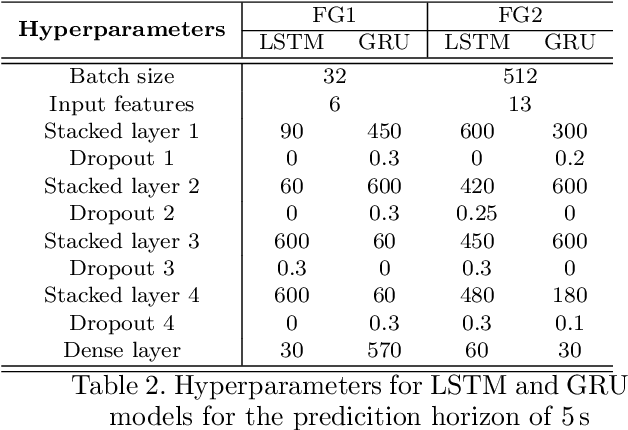
In a typical car-following scenario, target vehicle speed fluctuations act as an external disturbance to the host vehicle and in turn affect its energy consumption. To control a host vehicle in an energy-efficient manner using model predictive control (MPC), and moreover, enhance the performance of an ecological adaptive cruise control (EACC) strategy, forecasting the future velocities of a target vehicle is essential. For this purpose, a deep recurrent neural network-based vehicle speed prediction using long-short term memory (LSTM) and gated recurrent units (GRU) is studied in this work. Besides these, the physics-based constant velocity (CV) and constant acceleration (CA) models are discussed. The sequential time series data for training (e.g. speed trajectories of the target and its preceding vehicles obtained through vehicle-to-vehicle (V2V) communication, road speed limits, traffic light current and future phases collected using vehicle-to-infrastructure (V2I) communication) is gathered from both urban and highway networks created in the microscopic traffic simulator SUMO. The proposed speed prediction models are evaluated for long-term predictions (up to 10 s) of target vehicle future velocities. Moreover, the results revealed that the LSTM-based speed predictor outperformed other models in terms of achieving better prediction accuracy on unseen test datasets, and thereby showcasing better generalization ability. Furthermore, the performance of EACC-equipped host car on the predicted velocities is evaluated, and its energy-saving benefits for different prediction horizons are presented.
First Competitive Ant Colony Scheme for the CARP
Nov 19, 2022
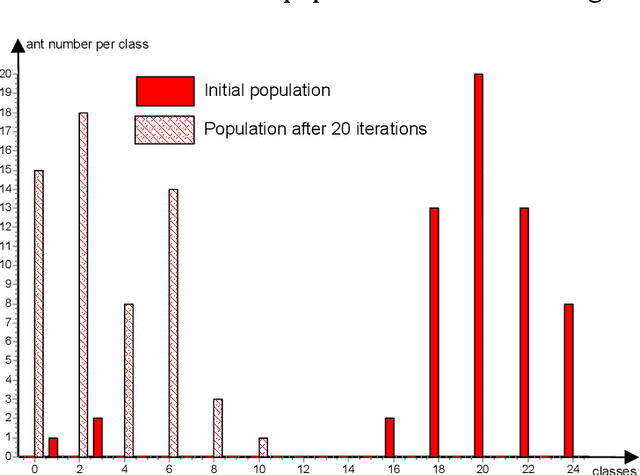
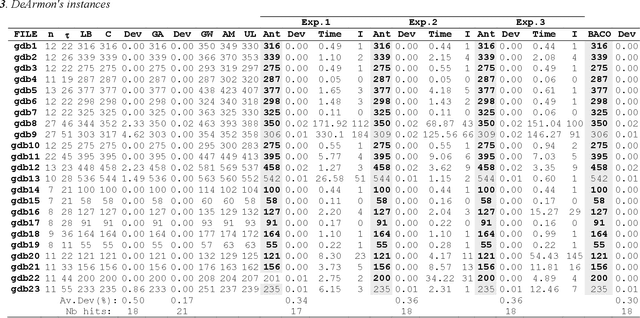
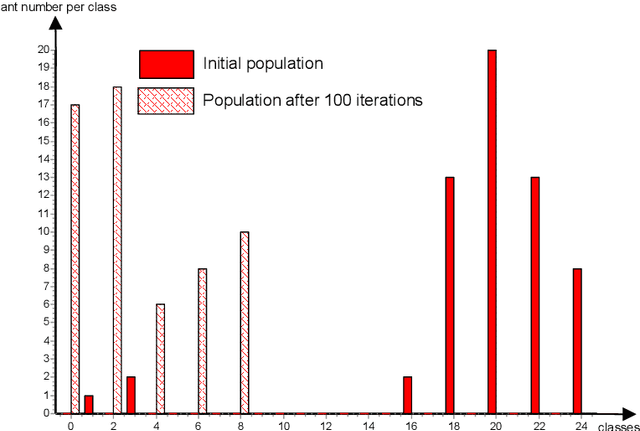
This paper addresses the Capacitated Arc Routing Problem (CARP) using an Ant Colony Optimization scheme. Ant Colony schemes can compute solutions for medium scale instances of VRP. The proposed Ant Colony is dedicated to large-scale instances of CARP with more than 140 nodes and 190 arcs to service. The Ant Colony scheme is coupled with a local search procedure and provides high quality solutions. The benchmarks we carried out prove possible to obtain solutions as profitable as CARPET ones can be obtained using such scheme when a sufficient number of iterations is devoted to the ants. It competes with the Genetic Algorithm of Lacomme et al. regarding solution quality but it is more time consuming on large scale instances. The method has been intensively benchmarked on the well-known instances of Eglese, DeArmon and the last ones of Belenguer and Benavent. This research report is a step forward CARP resolution by Ant Colony proving ant schemes can compete with Taboo search methods and Genetic Algorithms
NVDiff: Graph Generation through the Diffusion of Node Vectors
Nov 19, 2022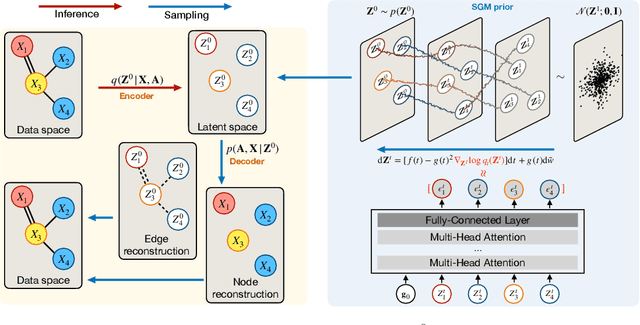
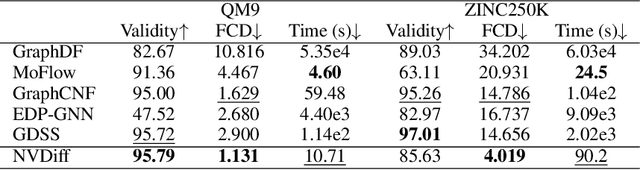
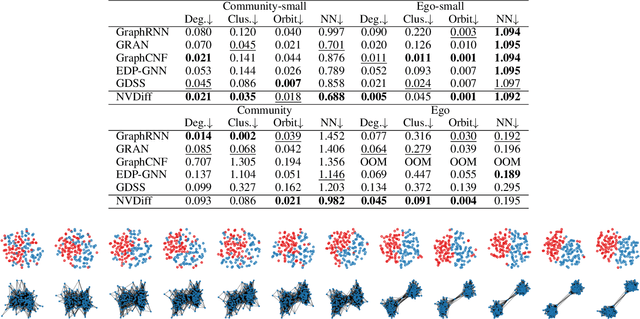
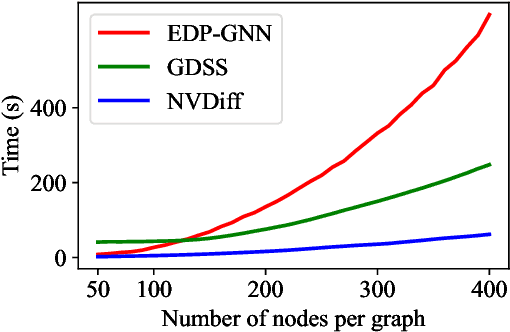
Learning to generate graphs is challenging as a graph is a set of pairwise connected, unordered nodes encoding complex combinatorial structures. Recently, several works have proposed graph generative models based on normalizing flows or score-based diffusion models. However, these models need to generate nodes and edges in parallel from the same process, whose dimensionality is unnecessarily high. We propose NVDiff, which takes the VGAE structure and uses a score-based generative model (SGM) as a flexible prior to sample node vectors. By modeling only node vectors in the latent space, NVDiff significantly reduces the dimension of the diffusion process and thus improves sampling speed. Built on the NVDiff framework, we introduce an attention-based score network capable of capturing both local and global contexts of graphs. Experiments indicate that NVDiff significantly reduces computations and can model much larger graphs than competing methods. At the same time, it achieves superior or competitive performances over various datasets compared to previous methods.
Multimodality Multi-Lead ECG Arrhythmia Classification using Self-Supervised Learning
Sep 30, 2022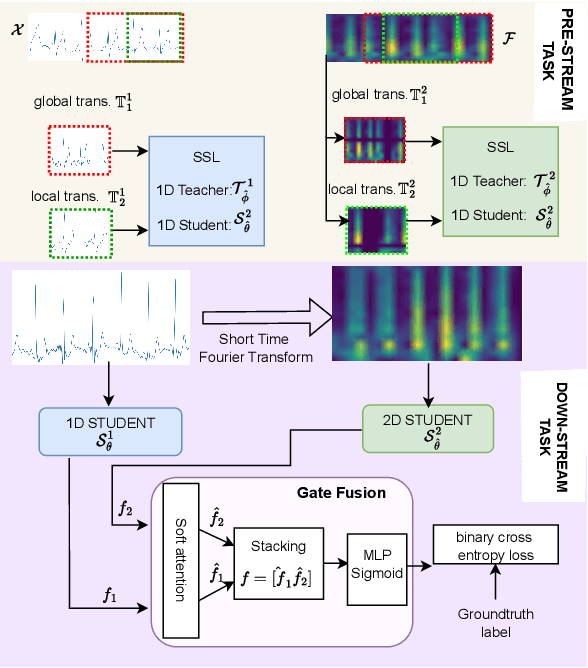
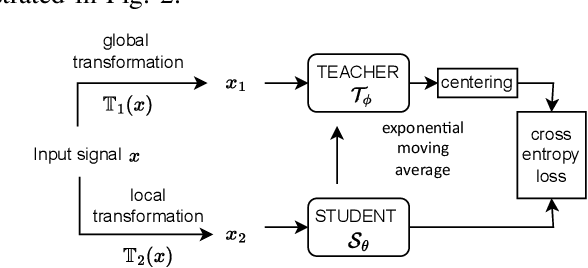
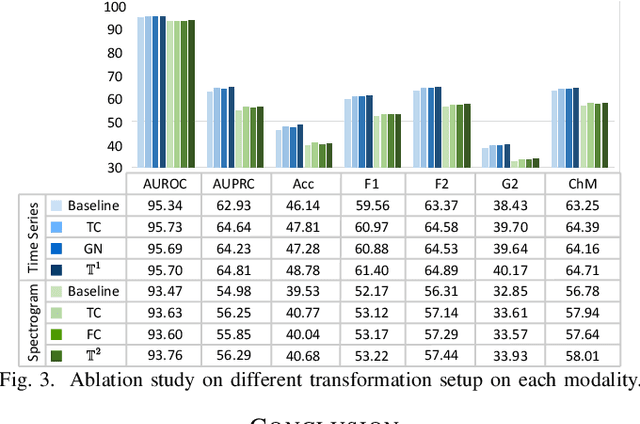
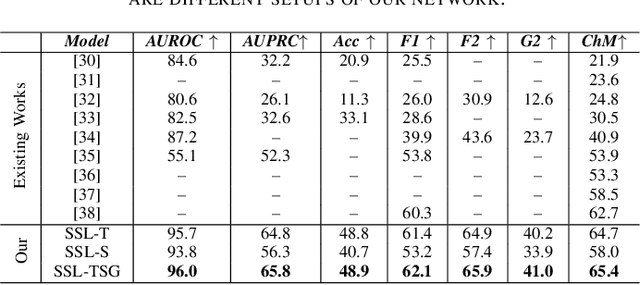
Electrocardiogram (ECG) signal is one of the most effective sources of information mainly employed for the diagnosis and prediction of cardiovascular diseases (CVDs) connected with the abnormalities in heart rhythm. Clearly, single modality ECG (i.e. time series) cannot convey its complete characteristics, thus, exploiting both time and time-frequency modalities in the form of time-series data and spectrogram is needed. Leveraging the cutting-edge self-supervised learning (SSL) technique on unlabeled data, we propose SSL-based multimodality ECG classification. Our proposed network follows SSL learning paradigm and consists of two modules corresponding to pre-stream task, and down-stream task, respectively. In the SSL-pre-stream task, we utilize self-knowledge distillation (KD) techniques with no labeled data, on various transformations and in both time and frequency domains. In the down-stream task, which is trained on labeled data, we propose a gate fusion mechanism to fuse information from multimodality.To evaluate the effectiveness of our approach, ten-fold cross validation on the 12-lead PhysioNet 2020 dataset has been conducted.
Time-aware Graph Neural Networks for Entity Alignment between Temporal Knowledge Graphs
Mar 04, 2022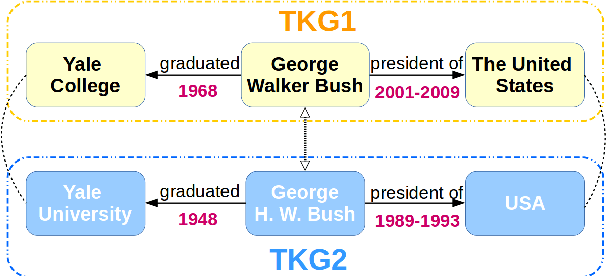

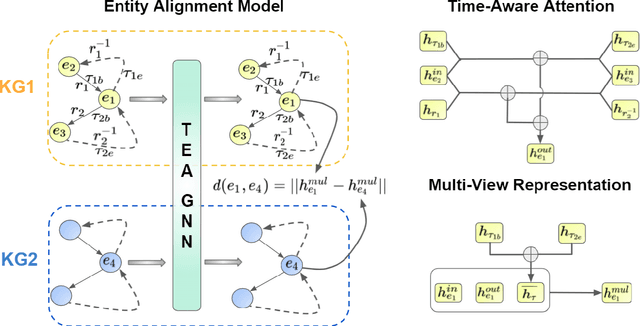
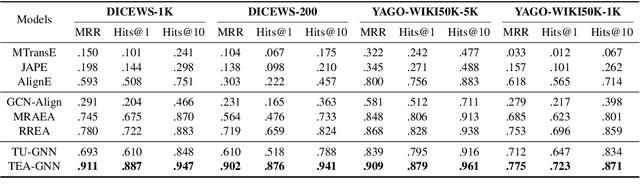
Entity alignment aims to identify equivalent entity pairs between different knowledge graphs (KGs). Recently, the availability of temporal KGs (TKGs) that contain time information created the need for reasoning over time in such TKGs. Existing embedding-based entity alignment approaches disregard time information that commonly exists in many large-scale KGs, leaving much room for improvement. In this paper, we focus on the task of aligning entity pairs between TKGs and propose a novel Time-aware Entity Alignment approach based on Graph Neural Networks (TEA-GNN). We embed entities, relations and timestamps of different KGs into a vector space and use GNNs to learn entity representations. To incorporate both relation and time information into the GNN structure of our model, we use a time-aware attention mechanism which assigns different weights to different nodes with orthogonal transformation matrices computed from embeddings of the relevant relations and timestamps in a neighborhood. Experimental results on multiple real-world TKG datasets show that our method significantly outperforms the state-of-the-art methods due to the inclusion of time information.
Improving Time Sensitivity for Question Answering over Temporal Knowledge Graphs
Mar 01, 2022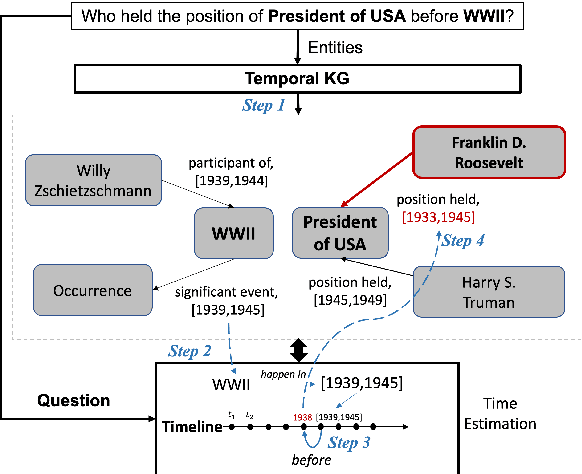
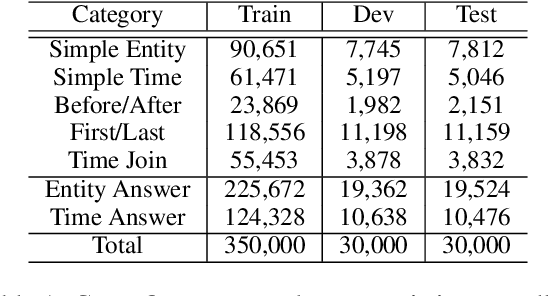
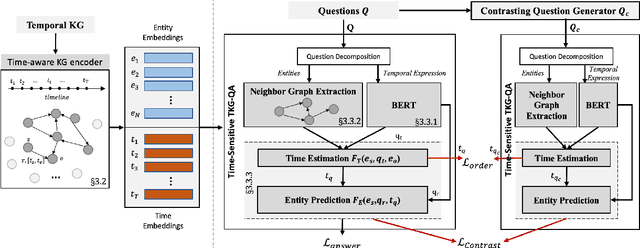
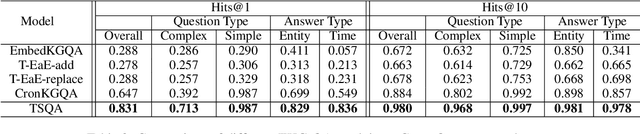
Question answering over temporal knowledge graphs (KGs) efficiently uses facts contained in a temporal KG, which records entity relations and when they occur in time, to answer natural language questions (e.g., "Who was the president of the US before Obama?"). These questions often involve three time-related challenges that previous work fail to adequately address: 1) questions often do not specify exact timestamps of interest (e.g., "Obama" instead of 2000); 2) subtle lexical differences in time relations (e.g., "before" vs "after"); 3) off-the-shelf temporal KG embeddings that previous work builds on ignore the temporal order of timestamps, which is crucial for answering temporal-order related questions. In this paper, we propose a time-sensitive question answering (TSQA) framework to tackle these problems. TSQA features a timestamp estimation module to infer the unwritten timestamp from the question. We also employ a time-sensitive KG encoder to inject ordering information into the temporal KG embeddings that TSQA is based on. With the help of techniques to reduce the search space for potential answers, TSQA significantly outperforms the previous state of the art on a new benchmark for question answering over temporal KGs, especially achieving a 32% (absolute) error reduction on complex questions that require multiple steps of reasoning over facts in the temporal KG.
* 10 pages, 2 figures
Predicting Eye Gaze Location on Websites
Nov 26, 2022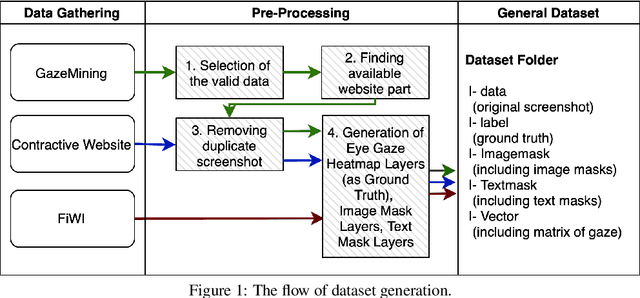
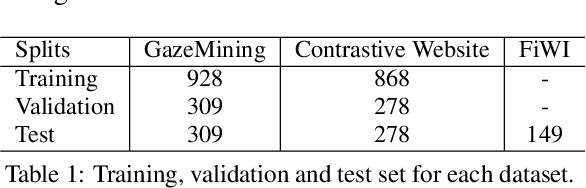
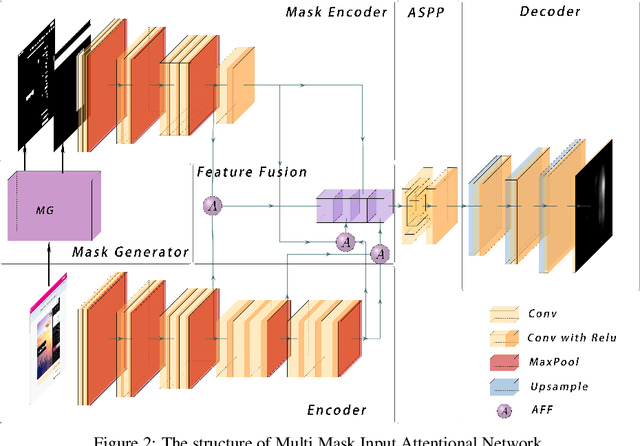
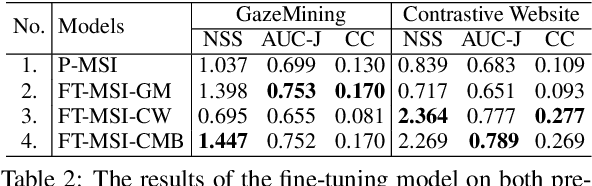
World-wide-web, with the website and webpage as the main interface, facilitates the dissemination of important information. Hence it is crucial to optimize them for better user interaction, which is primarily done by analyzing users' behavior, especially users' eye-gaze locations. However, gathering these data is still considered to be labor and time intensive. In this work, we enable the development of automatic eye-gaze estimations given a website screenshots as the input. This is done by the curation of a unified dataset that consists of website screenshots, eye-gaze heatmap and website's layout information in the form of image and text masks. Our pre-processed dataset allows us to propose an effective deep learning-based model that leverages both image and text spatial location, which is combined through attention mechanism for effective eye-gaze prediction. In our experiment, we show the benefit of careful fine-tuning using our unified dataset to improve the accuracy of eye-gaze predictions. We further observe the capability of our model to focus on the targeted areas (images and text) to achieve high accuracy. Finally, the comparison with other alternatives shows the state-of-the-art result of our model establishing the benchmark for the eye-gaze prediction task.
Time Series Generation with Masked Autoencoder
Jan 14, 2022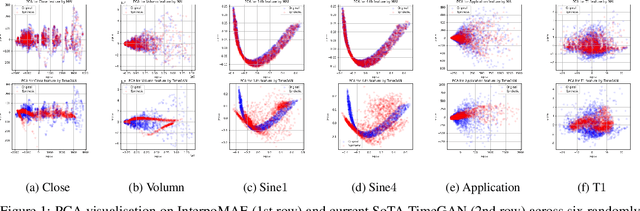
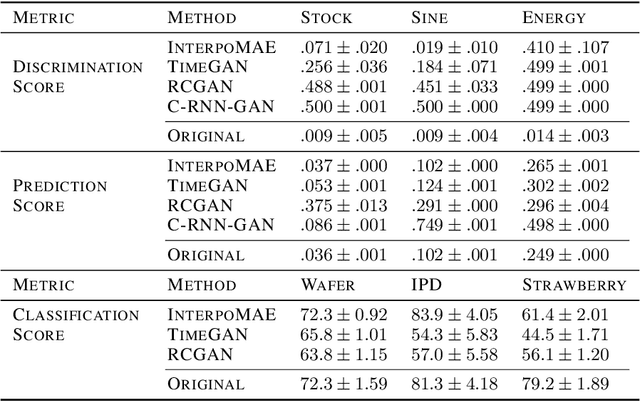
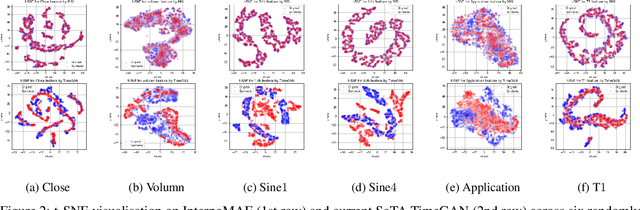
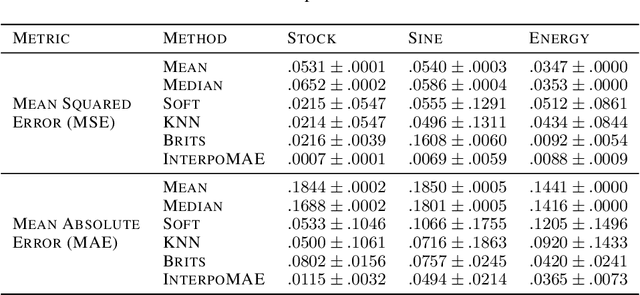
This paper shows that masked autoencoders with interpolators (InterpoMAE) are scalable self-supervised generators for time series. InterpoMAE masks random patches from the input time series and restore the missing patches in the latent space by an interpolator. The core design is that InterpoMAE uses an interpolator rather than mask tokens to restore the latent representations for missing patches in the latent space. This design enables more efficient and effective capture of temporal dynamics with bidirectional information. InterpoMAE allows for explicit control on the diversity of synthetic data by changing the size and number of masked patches. Our approach consistently and significantly outperforms state-of-the-art (SoTA) benchmarks of unsupervised learning in time series generation on several real datasets. Synthetic data produced show promising scaling behavior in various downstream tasks such as data augmentation, imputation and denoise.
Federated Learning for 5G Base Station Traffic Forecasting
Nov 28, 2022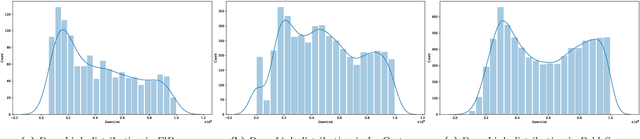
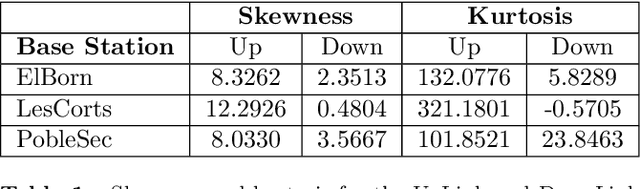
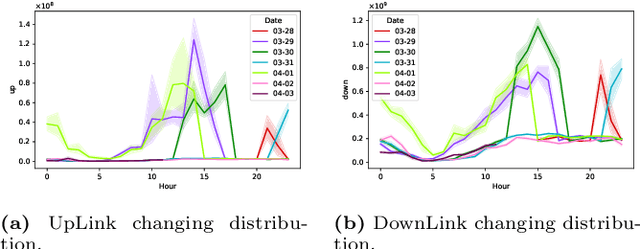
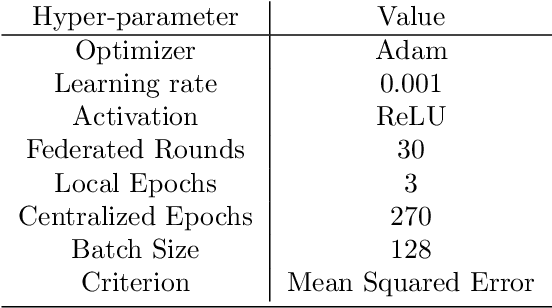
Mobile traffic prediction is of great importance on the path of enabling 5G mobile networks to perform smart and efficient infrastructure planning and management. However, available data are limited to base station logging information. Hence, training methods for generating high-quality predictions that can generalize to new observations on different parties are in demand. Traditional approaches require collecting measurements from different base stations and sending them to a central entity, followed by performing machine learning operations using the received data. The dissemination of local observations raises privacy, confidentiality, and performance concerns, hindering the applicability of machine learning techniques. Various distributed learning methods have been proposed to address this issue, but their application to traffic prediction has yet to be explored. In this work, we study the effectiveness of federated learning applied to raw base station aggregated LTE data for time-series forecasting. We evaluate one-step predictions using 5 different neural network architectures trained with a federated setting on non-iid data. The presented algorithms have been submitted to the Global Federated Traffic Prediction for 5G and Beyond Challenge. Our results show that the learning architectures adapted to the federated setting achieve equivalent prediction error to the centralized setting, pre-processing techniques on base stations lead to higher forecasting accuracy, while state-of-the-art aggregators do not outperform simple approaches.
MicroAST: Towards Super-Fast Ultra-Resolution Arbitrary Style Transfer
Nov 28, 2022
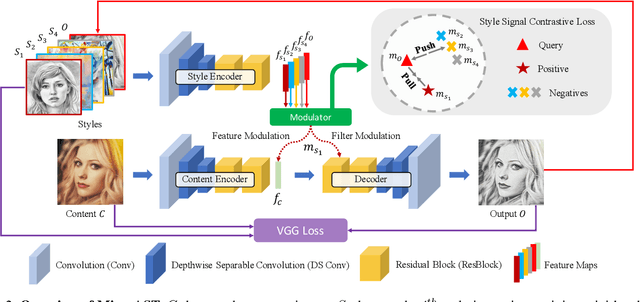
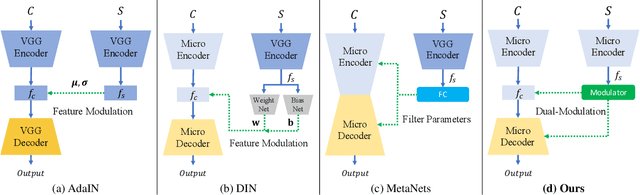
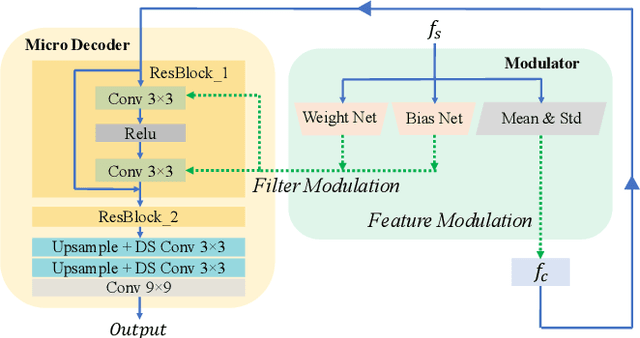
Arbitrary style transfer (AST) transfers arbitrary artistic styles onto content images. Despite the recent rapid progress, existing AST methods are either incapable or too slow to run at ultra-resolutions (e.g., 4K) with limited resources, which heavily hinders their further applications. In this paper, we tackle this dilemma by learning a straightforward and lightweight model, dubbed MicroAST. The key insight is to completely abandon the use of cumbersome pre-trained Deep Convolutional Neural Networks (e.g., VGG) at inference. Instead, we design two micro encoders (content and style encoders) and one micro decoder for style transfer. The content encoder aims at extracting the main structure of the content image. The style encoder, coupled with a modulator, encodes the style image into learnable dual-modulation signals that modulate both intermediate features and convolutional filters of the decoder, thus injecting more sophisticated and flexible style signals to guide the stylizations. In addition, to boost the ability of the style encoder to extract more distinct and representative style signals, we also introduce a new style signal contrastive loss in our model. Compared to the state of the art, our MicroAST not only produces visually superior results but also is 5-73 times smaller and 6-18 times faster, for the first time enabling super-fast (about 0.5 seconds) AST at 4K ultra-resolutions. Code is available at https://github.com/EndyWon/MicroAST.