 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PatchShading: High-Quality Human Reconstruction by Patch Warping and Shading Refinement
Nov 26, 2022

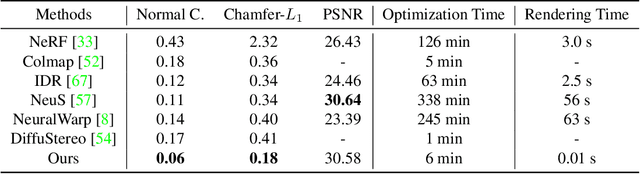
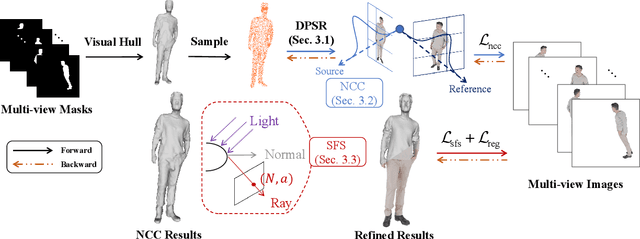
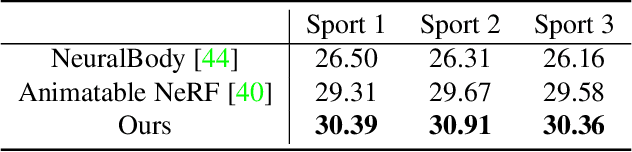
Human reconstruction from multi-view images plays an important role in many applications. Although neural rendering methods have achieved promising results on synthesising realistic images, it is still difficult to handle the ambiguity between the geometry and appearance using only rendering loss. Moreover, it is very computationally intensive to render a whole image as each pixel requires a forward network inference. To tackle these challenges, we propose a novel approach called \emph{PatchShading} to reconstruct high-quality mesh of human body from multi-view posed images. We first present a patch warping strategy to constrain multi-view photometric consistency explicitly. Second, we adopt sphere harmonics (SH) illumination and shape from shading image formation to further refine the geometric details. By taking advantage of the oriented point clouds shape representation and SH shading, our proposed method significantly reduce the optimization and rendering time compared to those implicit methods. The encouraging results on both synthetic and real-world datasets demonstrate the efficacy of our proposed approach.
Recognition and Prediction of Surgical Gestures and Trajectories Using Transformer Models in Robot-Assisted Surgery
Dec 03, 2022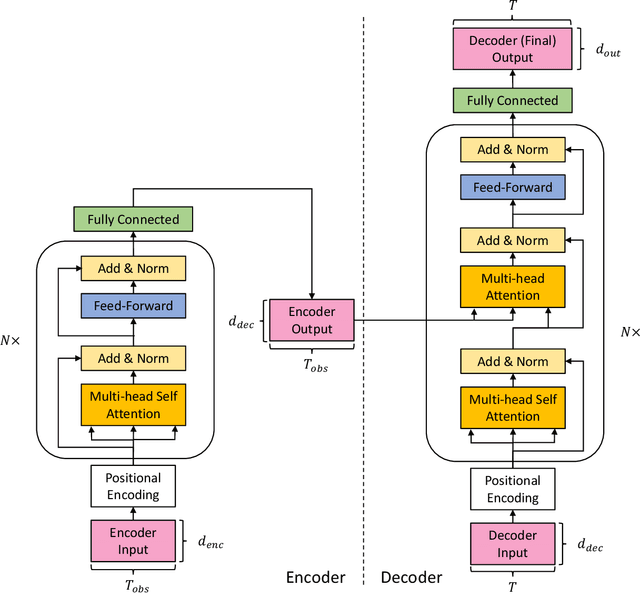
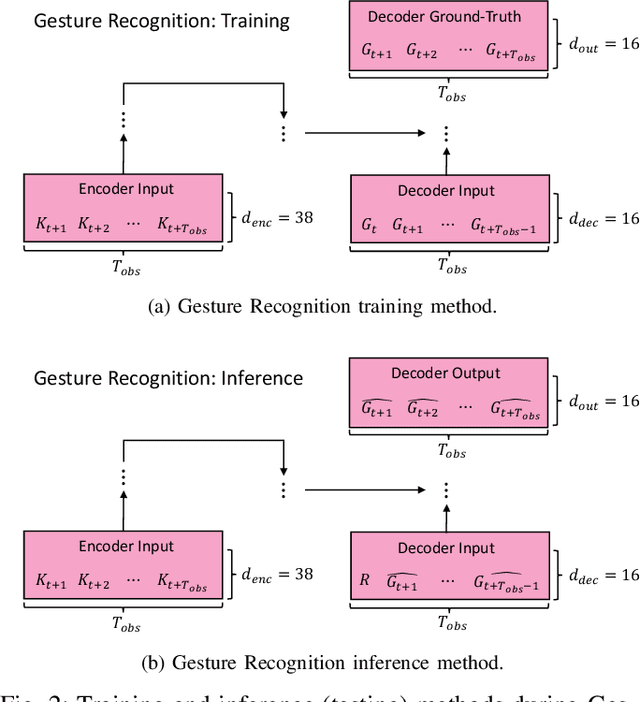
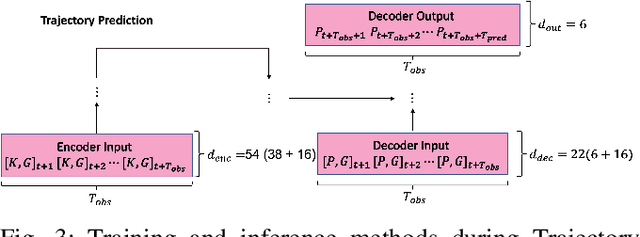
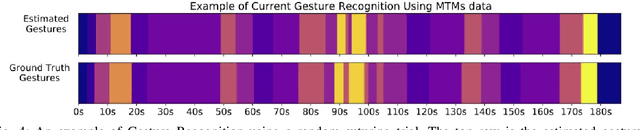
Surgical activity recognition and prediction can help provide important context in many Robot-Assisted Surgery (RAS) applications, for example, surgical progress monitoring and estimation, surgical skill evaluation, and shared control strategies during teleoperation. Transformer models were first developed for Natural Language Processing (NLP) to model word sequences and soon the method gained popularity for general sequence modeling tasks. In this paper, we propose the novel use of a Transformer model for three tasks: gesture recognition, gesture prediction, and trajectory prediction during RAS. We modify the original Transformer architecture to be able to generate the current gesture sequence, future gesture sequence, and future trajectory sequence estimations using only the current kinematic data of the surgical robot end-effectors. We evaluate our proposed models on the JHU-ISI Gesture and Skill Assessment Working Set (JIGSAWS) and use Leave-One-User-Out (LOUO) cross-validation to ensure the generalizability of our results. Our models achieve up to 89.3\% gesture recognition accuracy, 84.6\% gesture prediction accuracy (1 second ahead) and 2.71mm trajectory prediction error (1 second ahead). Our models are comparable to and able to outperform state-of-the-art methods while using only the kinematic data channel. This approach can enable near-real time surgical activity recognition and prediction.
Thales: Formulating and Estimating Architectural Vulnerability Factors for DNN Accelerators
Dec 05, 2022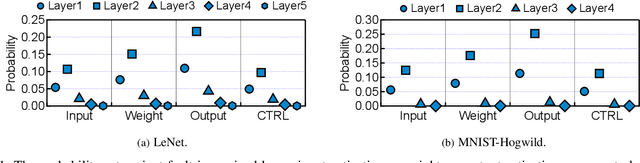
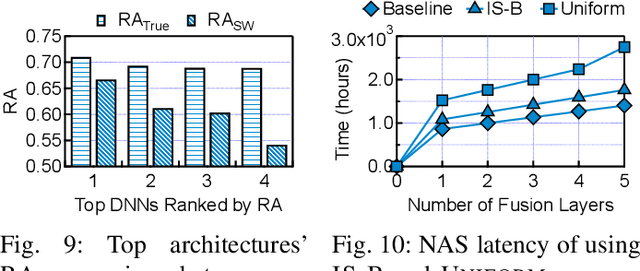
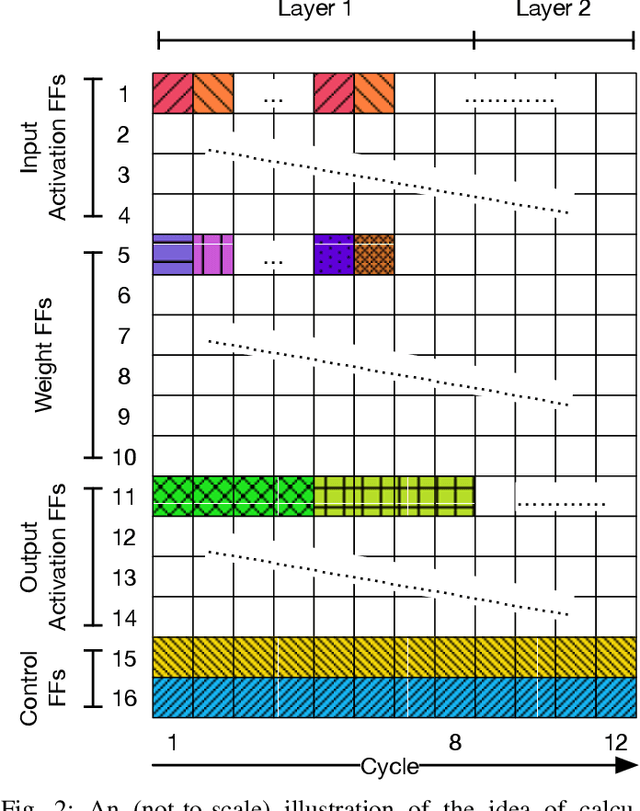
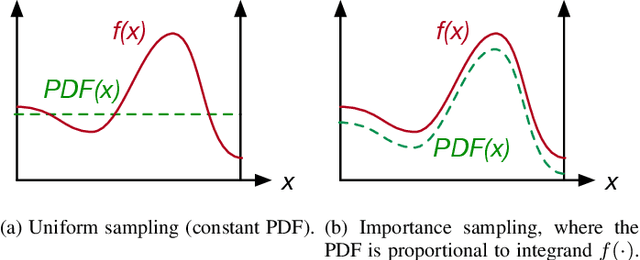
As Deep Neural Networks (DNNs) are increasingly deployed in safety critical and privacy sensitive applications such as autonomous driving and biometric authentication, it is critical to understand the fault-tolerance nature of DNNs. Prior work primarily focuses on metrics such as Failures In Time (FIT) rate and the Silent Data Corruption (SDC) rate, which quantify how often a device fails. Instead, this paper focuses on quantifying the DNN accuracy given that a transient error has occurred, which tells us how well a network behaves when a transient error occurs. We call this metric Resiliency Accuracy (RA). We show that existing RA formulation is fundamentally inaccurate, because it incorrectly assumes that software variables (model weights/activations) have equal faulty probability under hardware transient faults. We present an algorithm that captures the faulty probabilities of DNN variables under transient faults and, thus, provides correct RA estimations validated by hardware. To accelerate RA estimation, we reformulate RA calculation as a Monte Carlo integration problem, and solve it using importance sampling driven by DNN specific heuristics. Using our lightweight RA estimation method, we show that transient faults lead to far greater accuracy degradation than what todays DNN resiliency tools estimate. We show how our RA estimation tool can help design more resilient DNNs by integrating it with a Network Architecture Search framework.
Deep reinforcement learning of event-triggered communication and consensus-based control for distributed cooperative transport
Dec 05, 2022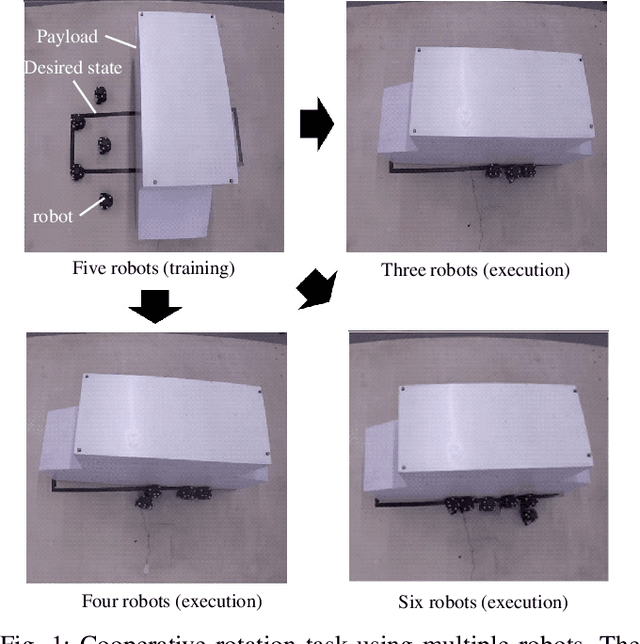
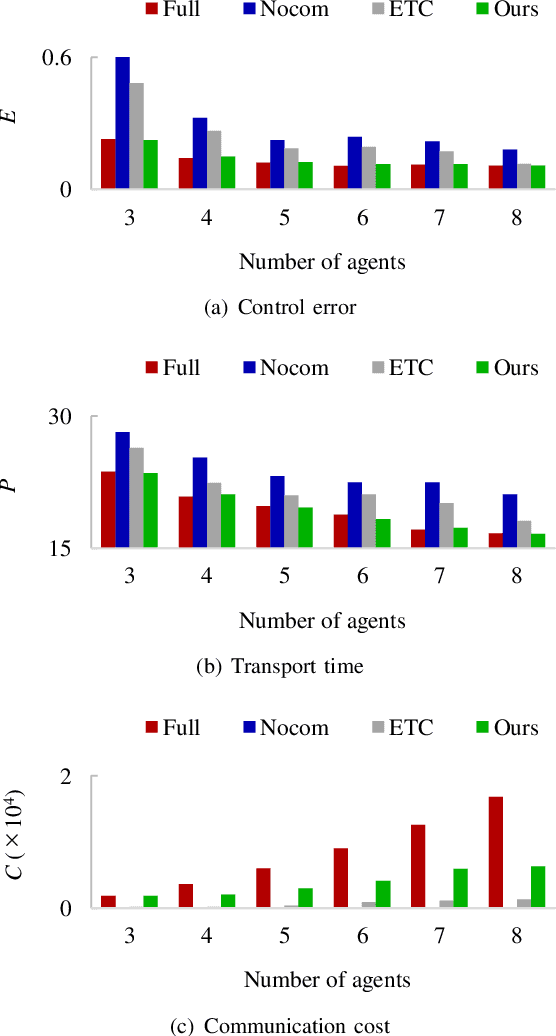
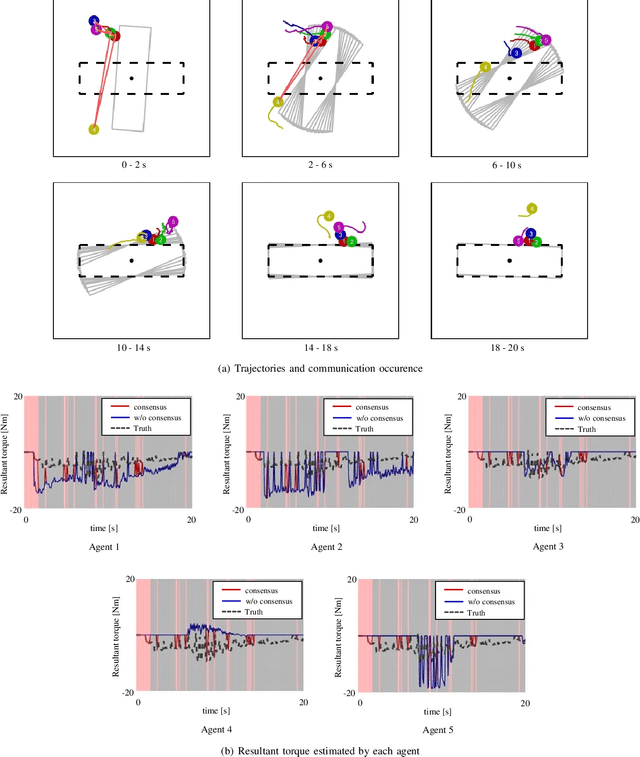

In this paper, we present a solution to a design problem of control strategies for multi-agent cooperative transport. Although existing learning-based methods assume that the number of agents is the same as that in the training environment, the number might differ in reality considering that the robots' batteries may completely discharge, or additional robots may be introduced to reduce the time required to complete a task. Therefore, it is crucial that the learned strategy be applicable to scenarios wherein the number of agents differs from that in the training environment. In this paper, we propose a novel multi-agent reinforcement learning framework of event-triggered communication and consensus-based control for distributed cooperative transport. The proposed policy model estimates the resultant force and torque in a consensus manner using the estimates of the resultant force and torque with the neighborhood agents. Moreover, it computes the control and communication inputs to determine when to communicate with the neighboring agents under local observations and estimates of the resultant force and torque. Therefore, the proposed framework can balance the control performance and communication savings in scenarios wherein the number of agents differs from that in the training environment. We confirm the effectiveness of our approach by using a maximum of eight and six robots in the simulations and experiments, respectively.
* 14 pages, 14 figures
FiLM: Frequency improved Legendre Memory Model for Long-term Time Series Forecasting
May 18, 2022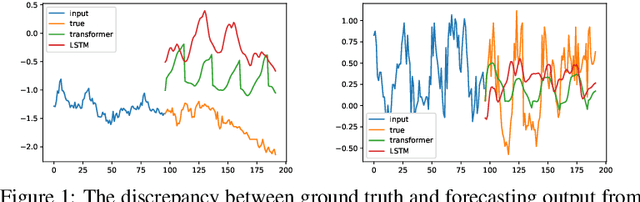
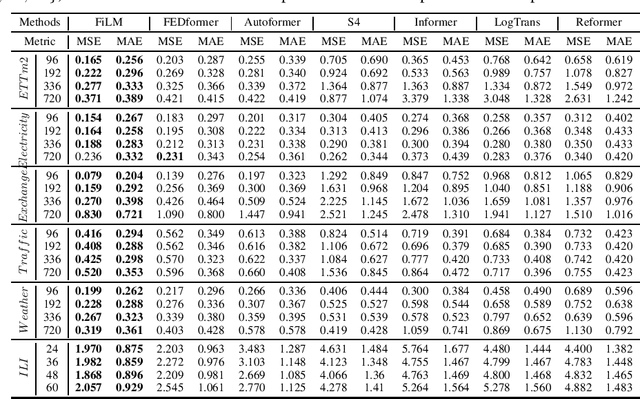
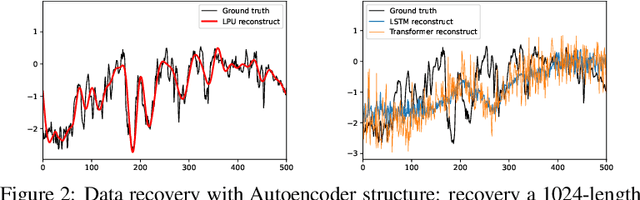
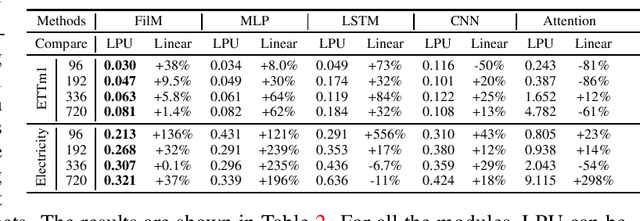
Recent studies have shown the promising performance of deep learning models (e.g., RNN and Transformer) for long-term time series forecasting. These studies mostly focus on designing deep models to effectively combine historical information for long-term forecasting. However, the question of how to effectively represent historical information for long-term forecasting has not received enough attention, limiting our capacity to exploit powerful deep learning models. The main challenge in time series representation is how to handle the dilemma between accurately preserving historical information and reducing the impact of noisy signals in the past. To this end, we design a \textbf{F}requency \textbf{i}mproved \textbf{L}egendre \textbf{M}emory model, or {\bf FiLM} for short: it introduces Legendre Polynomial projections to preserve historical information accurately and Fourier projections plus low-rank approximation to remove noisy signals. Our empirical studies show that the proposed FiLM improves the accuracy of state-of-the-art models by a significant margin (\textbf{19.2\%}, \textbf{22.6\%}) in multivariate and univariate long-term forecasting, respectively. In addition, dimensionality reduction introduced by low-rank approximation leads to a dramatic improvement in computational efficiency. We also demonstrate that the representation module developed in this work can be used as a general plug-in to improve the performance of most deep learning modules for long-term forecasting. Code will be released soon
Time Reversal for 6G Spatiotemporal Focusing: Recent Experiments, Opportunities, and Challenges
Jun 16, 2022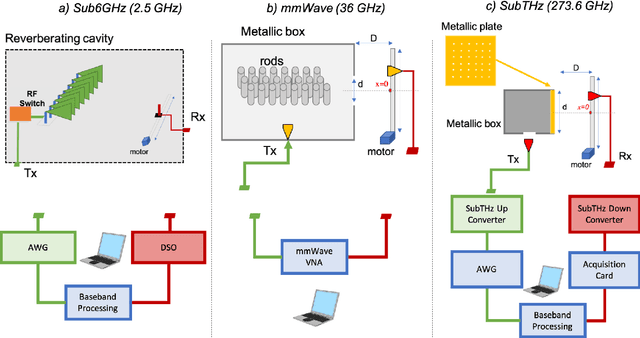
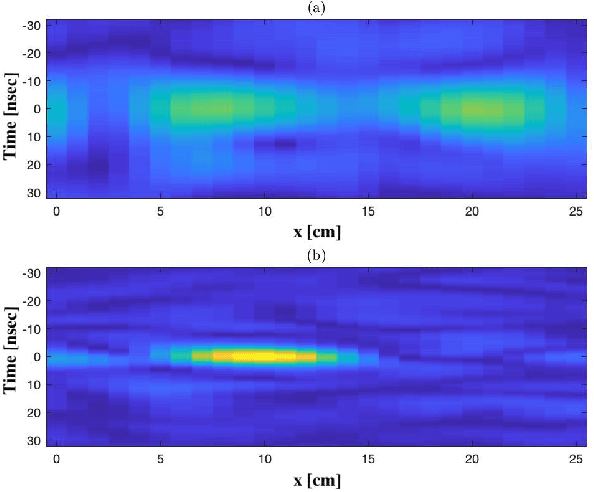
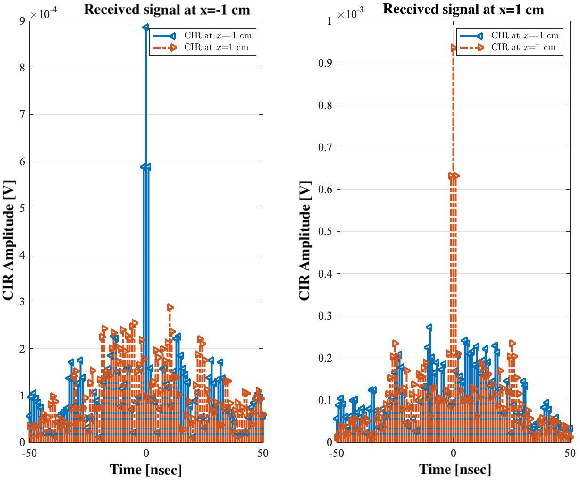
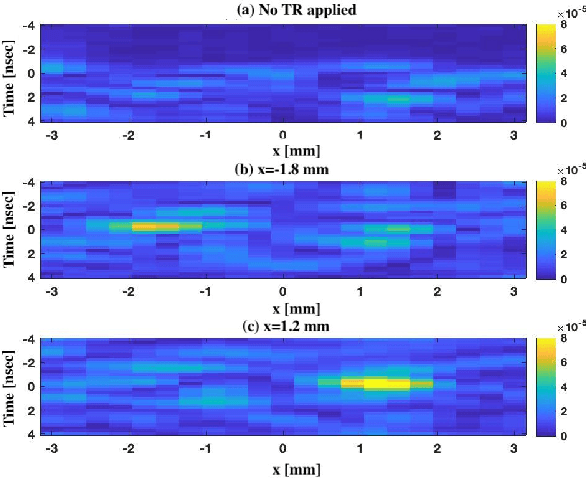
Late visions and trends for the future sixth Generation (6G) of wireless communications advocate, among other technologies, towards the deployment of network nodes with extreme numbers of antennas and up to terahertz frequencies, as means to enable various immersive applications. However, these technologies impose several challenges in the design of radio-frequency front-ends and beamforming architectures, as well as of ultra-wideband waveforms and computationally efficient transceiver signal processing. In this article, we revisit the Time Reversal (TR) technique, which was initially experimented in acoustics, in the context of large-bandwidth 6G wireless communications, capitalizing on its high resolution spatiotemporal focusing realized with low complexity transceivers. We first overview representative state-of-the-art in TR-based wireless communications, identifying the key competencies and requirements of TR for efficient operation. Recent and novel experimental setups and results for the spatiotemporal focusing capability of TR at the carrier frequencies $2.5$, $36$, and $273$ GHz are then presented, demonstrating in quantitative ways the technique's effectiveness in these very different frequency bands, as well as the roles of the available bandwidth and the number of transmit antennas. We also showcase the TR potential for realizing low complexity multi-user communications. The opportunities arising from TR-based wireless communications as well as the challenges for finding their place in 6G networks, also in conjunction with other complementary candidate technologies, are highlighted.
Robust Augmentation for Multivariate Time Series Classification
Jan 27, 2022Neural networks are capable of learning powerful representations of data, but they are susceptible to overfitting due to the number of parameters. This is particularly challenging in the domain of time series classification, where datasets may contain fewer than 100 training examples. In this paper, we show that the simple methods of cutout, cutmix, mixup, and window warp improve the robustness and overall performance in a statistically significant way for convolutional, recurrent, and self-attention based architectures for time series classification. We evaluate these methods on 26 datasets from the University of East Anglia Multivariate Time Series Classification (UEA MTSC) archive and analyze how these methods perform on different types of time series data.. We show that the InceptionTime network with augmentation improves accuracy by 1% to 45% in 18 different datasets compared to without augmentation. We also show that augmentation improves accuracy for recurrent and self attention based architectures.
Coordinated Transmit Beamforming for Multi-antenna Network Integrated Sensing and Communication
Nov 02, 2022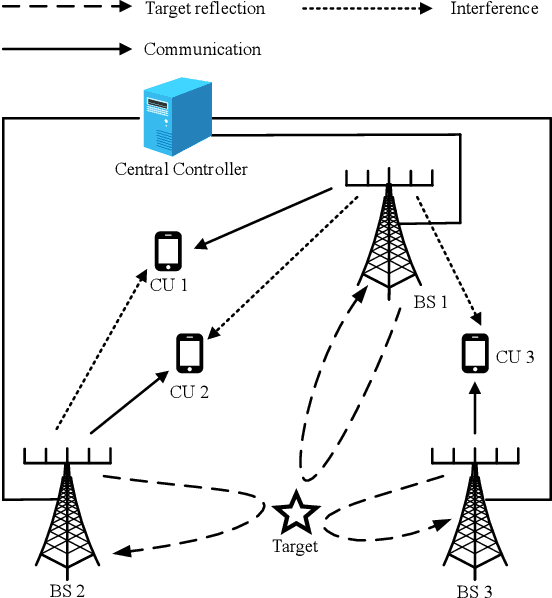
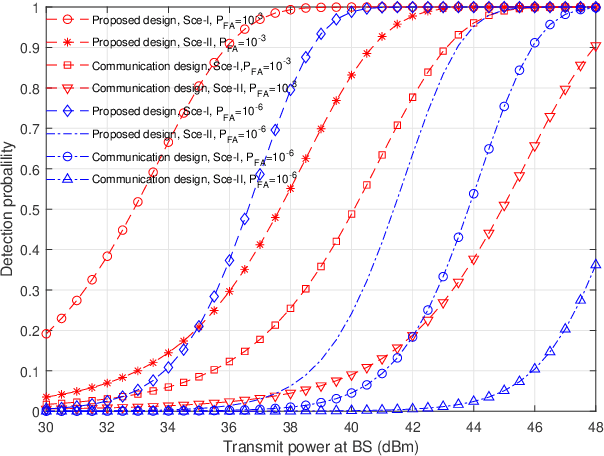
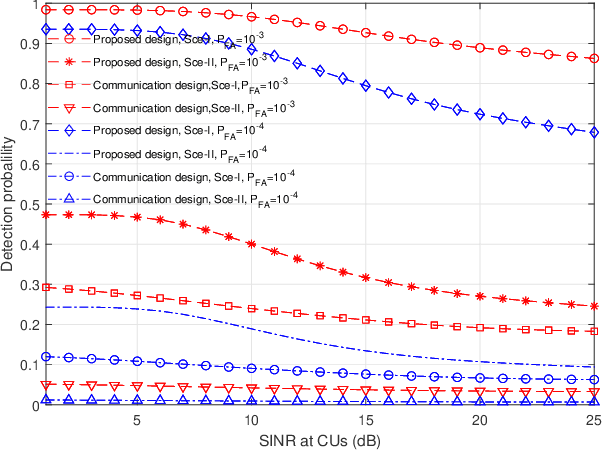
This paper studies a multi-antenna network integrated sensing and communication (ISAC) system, in which a set of multi-antenna base stations (BSs) employ the coordinated transmit beamforming to serve their respectively associated single-antenna communication users (CUs), and at the same time reuse the reflected information signals to perform joint target detection. In particular, we consider two target detection scenarios depending on the time synchronization among BSs. In Scenario \uppercase\expandafter{\romannumeral1}, these BSs are synchronized and can exploit the target-reflected signals over both the direct links (from each BS to target to itself) and the cross links (from each BS to target to other BSs) for joint detection. In Scenario \uppercase\expandafter{\romannumeral2}, these BSs are not synchronized and can only utilize target-reflected signals over the direct links for joint detection. For each scenario, we derive the detection probability under a specific false alarm probability at any given target location. Based on the derivation, we optimize the coordinated transmit beamforming at the BSs to maximize the minimum detection probability over a particular target area, while ensuring the minimum signal-to-interference-plus-noise ratio (SINR) constraints at the CUs, subject to the maximum transmit power constraints at the BSs. We use the semi-definite relaxation (SDR) technique to obtain highly-quality solutions to the formulated problems. Numerical results show that for each scenario, the proposed design achieves higher detection probability than the benchmark scheme based on communication design. It is also shown that the time synchronization among BSs is beneficial in enhancing the detection performance as more reflected signal paths are exploited.
SideRT: A Real-time Pure Transformer Architecture for Single Image Depth Estimation
Apr 29, 2022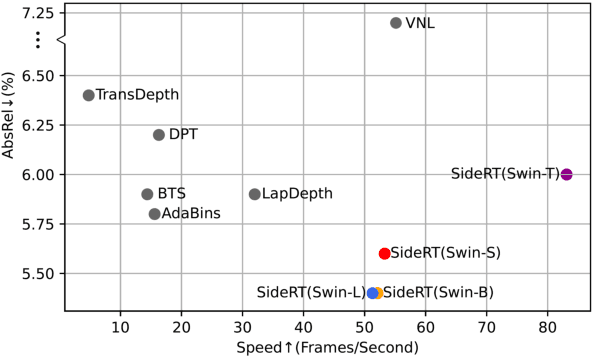
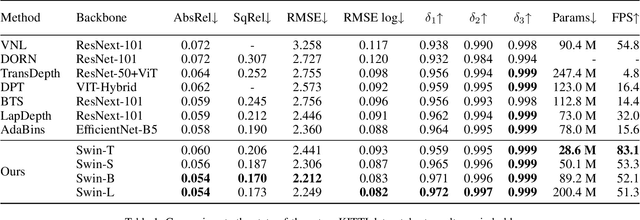
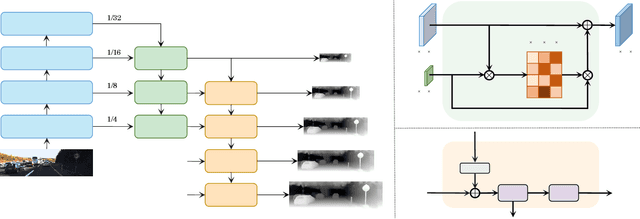
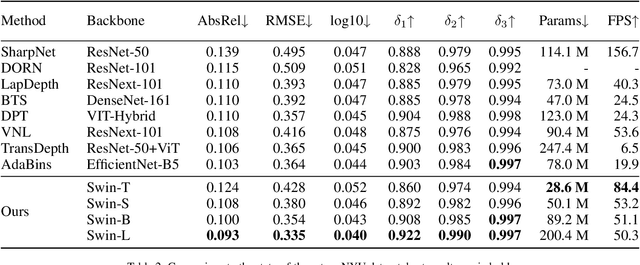
Since context modeling is critical for estimating depth from a single image, researchers put tremendous effort into obtaining global context. Many global manipulations are designed for traditional CNN-based architectures to overcome the locality of convolutions. Attention mechanisms or transformers originally designed for capturing long-range dependencies might be a better choice, but usually complicates architectures and could lead to a decrease in inference speed. In this work, we propose a pure transformer architecture called SideRT that can attain excellent predictions in real-time. In order to capture better global context, Cross-Scale Attention (CSA) and Multi-Scale Refinement (MSR) modules are designed to work collaboratively to fuse features of different scales efficiently. CSA modules focus on fusing features of high semantic similarities, while MSR modules aim to fuse features at corresponding positions. These two modules contain a few learnable parameters without convolutions, based on which a lightweight yet effective model is built. This architecture achieves state-of-the-art performances in real-time (51.3 FPS) and becomes much faster with a reasonable performance drop on a smaller backbone Swin-T (83.1 FPS). Furthermore, its performance surpasses the previous state-of-the-art by a large margin, improving AbsRel metric 6.9% on KITTI and 9.7% on NYU. To the best of our knowledge, this is the first work to show that transformer-based networks can attain state-of-the-art performance in real-time in the single image depth estimation field. Code will be made available soon.
Time Domain Adversarial Voice Conversion for ADD 2022
Apr 20, 2022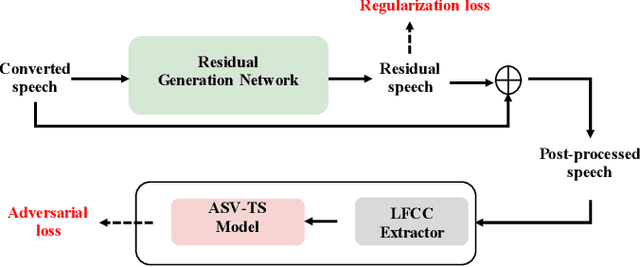

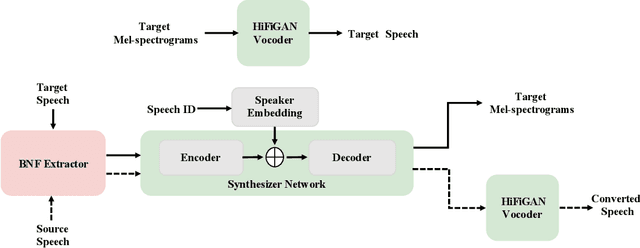
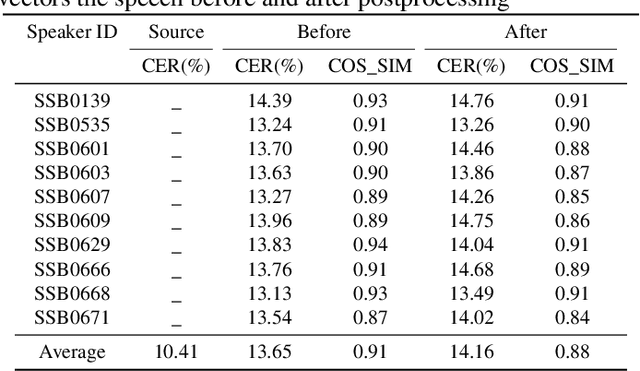
In this paper, we describe our speech generation system for the first Audio Deep Synthesis Detection Challenge (ADD 2022). Firstly, we build an any-to-many voice conversion (VC) system to convert source speech with arbitrary language content into the target speaker%u2019s fake speech. Then the converted speech generated from VC is post-processed in the time domain to improve the deception ability. The experimental results show that our system has adversarial ability against anti-spoofing detectors with a little compromise in audio quality and speaker similarity. This system ranks top in Track 3.1 in the ADD 2022, showing that our method could also gain good generalization ability against different detectors.