 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SimCS: Simulation for Online Domain-Incremental Continual Segmentation
Nov 29, 2022
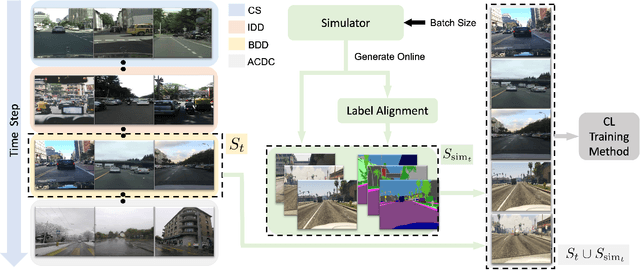
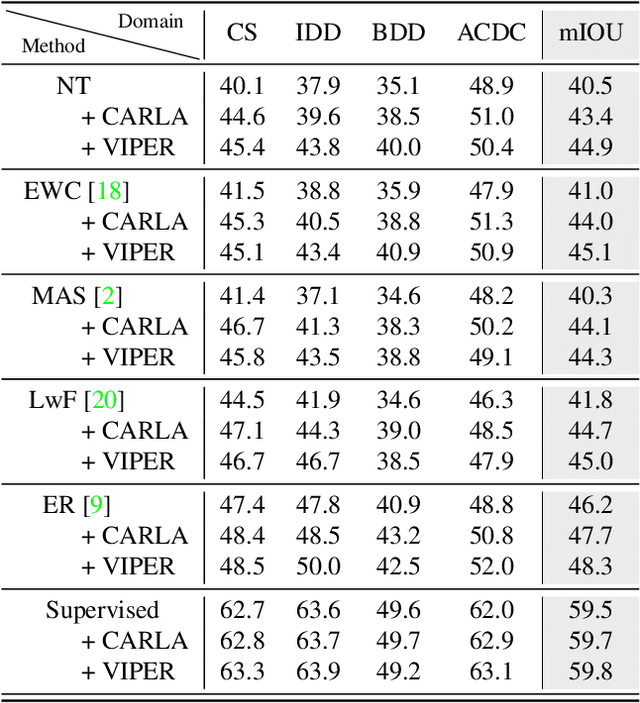
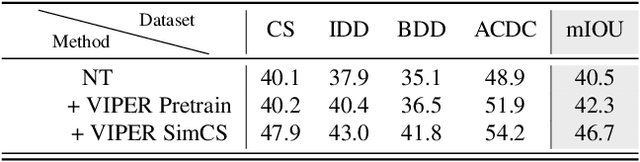

Continual Learning is a step towards lifelong intelligence where models continuously learn from recently collected data without forgetting previous knowledge. Existing continual learning approaches mostly focus on image classification in the class-incremental setup with clear task boundaries and unlimited computational budget. This work explores Online Domain-Incremental Continual Segmentation~(ODICS), a real-world problem that arises in many applications, \eg, autonomous driving. In ODICS, the model is continually presented with batches of densely labeled images from different domains; computation is limited and no information about the task boundaries is available. In autonomous driving, this may correspond to the realistic scenario of training a segmentation model over time on a sequence of cities. We analyze several existing continual learning methods and show that they do not perform well in this setting despite working well in class-incremental segmentation. We propose SimCS, a parameter-free method complementary to existing ones that leverages simulated data as a continual learning regularizer. Extensive experiments show consistent improvements over different types of continual learning methods that use regularizers and even replay.
Ada3Diff: Defending against 3D Adversarial Point Clouds via Adaptive Diffusion
Nov 29, 2022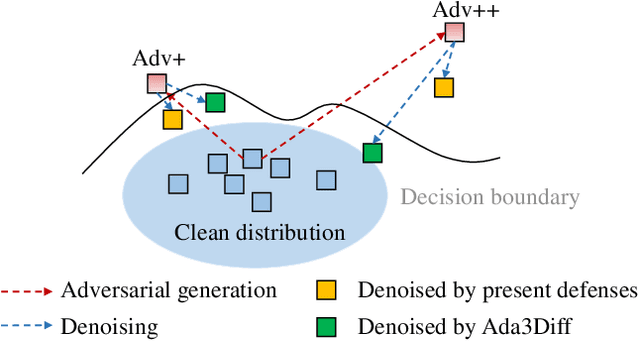
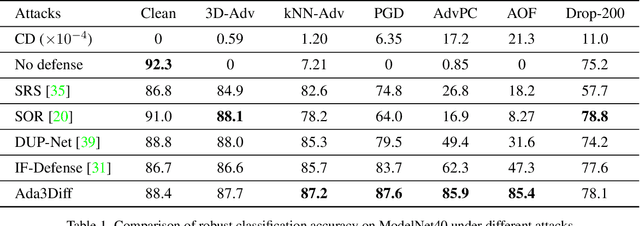
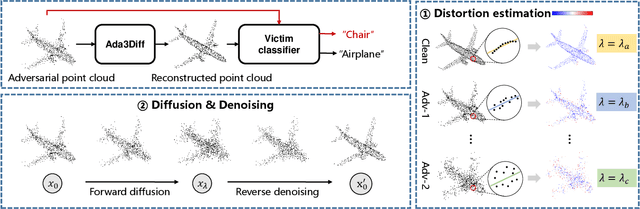
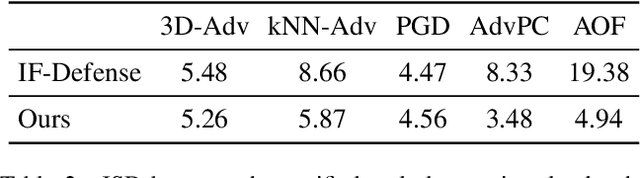
Deep 3D point cloud models are sensitive to adversarial attacks, which poses threats to safety-critical applications such as autonomous driving. Robust training and defend-by-denoise are typical strategies for defending adversarial perturbations, including adversarial training and statistical filtering, respectively. However, they either induce massive computational overhead or rely heavily upon specified noise priors, limiting generalized robustness against attacks of all kinds. This paper introduces a new defense mechanism based on denoising diffusion models that can adaptively remove diverse noises with a tailored intensity estimator. Specifically, we first estimate adversarial distortions by calculating the distance of the points to their neighborhood best-fit plane. Depending on the distortion degree, we choose specific diffusion time steps for the input point cloud and perform the forward diffusion to disrupt potential adversarial shifts. Then we conduct the reverse denoising process to restore the disrupted point cloud back to a clean distribution. This approach enables effective defense against adaptive attacks with varying noise budgets, achieving accentuated robustness of existing 3D deep recognition models.
Automated Play-Testing Through RL Based Human-Like Play-Styles Generation
Nov 29, 2022
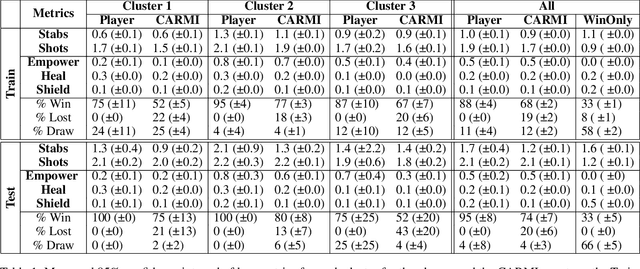
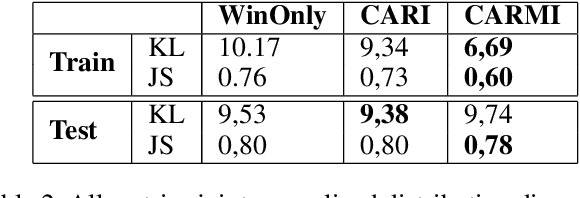
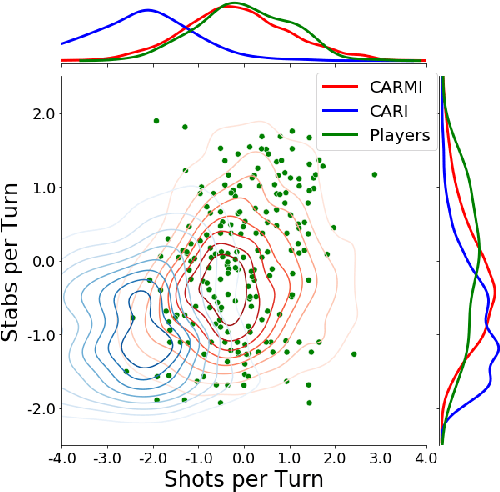
The increasing complexity of gameplay mechanisms in modern video games is leading to the emergence of a wider range of ways to play games. The variety of possible play-styles needs to be anticipated by designers, through automated tests. Reinforcement Learning is a promising answer to the need of automating video game testing. To that effect one needs to train an agent to play the game, while ensuring this agent will generate the same play-styles as the players in order to give meaningful feedback to the designers. We present CARMI: a Configurable Agent with Relative Metrics as Input. An agent able to emulate the players play-styles, even on previously unseen levels. Unlike current methods it does not rely on having full trajectories, but only summary data. Moreover it only requires little human data, thus compatible with the constraints of modern video game production. This novel agent could be used to investigate behaviors and balancing during the production of a video game with a realistic amount of training time.
* Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, 18(1)
Neural Vocoder Feature Estimation for Dry Singing Voice Separation
Nov 29, 2022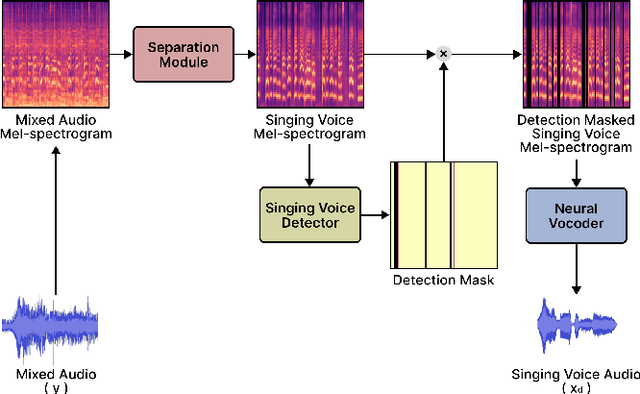
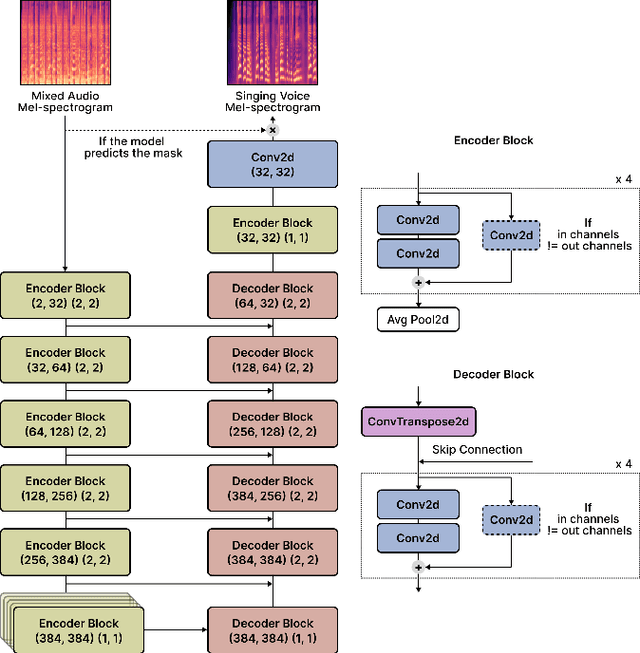
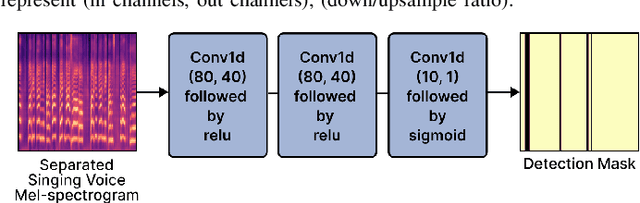
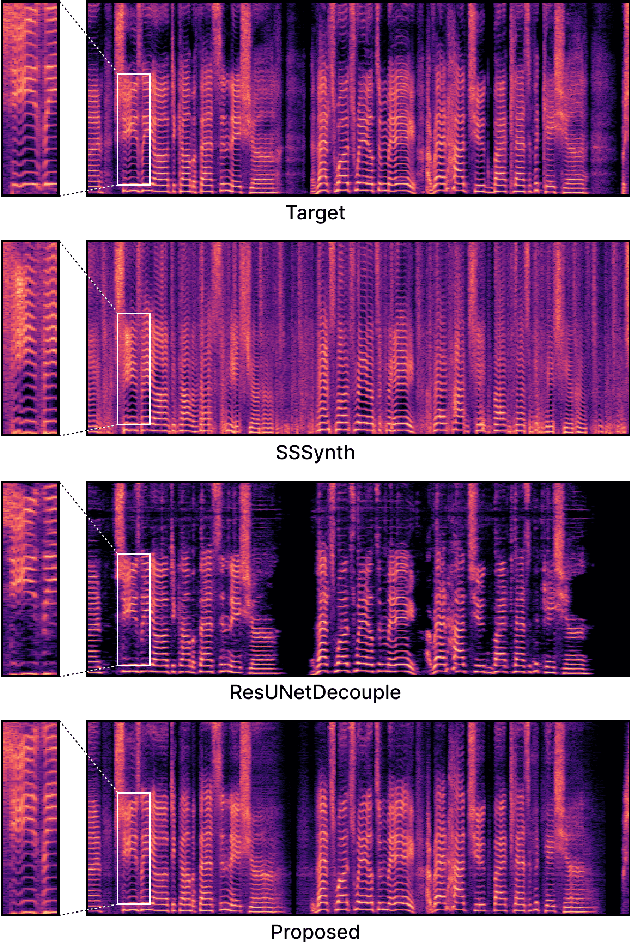
Singing voice separation (SVS) is a task that separates singing voice audio from its mixture with instrumental audio. Previous SVS studies have mainly employed the spectrogram masking method which requires a large dimensionality in predicting the binary masks. In addition, they focused on extracting a vocal stem that retains the wet sound with the reverberation effect. This result may hinder the reusability of the isolated singing voice. This paper addresses the issues by predicting mel-spectrogram of dry singing voices from the mixed audio as neural vocoder features and synthesizing the singing voice waveforms from the neural vocoder. We experimented with two separation methods. One is predicting binary masks in the mel-spectrogram domain and the other is directly predicting the mel-spectrogram. Furthermore, we add a singing voice detector to identify the singing voice segments over time more explicitly. We measured the model performance in terms of audio, dereverberation, separation, and overall quality. The results show that our proposed model outperforms state-of-the-art singing voice separation models in both objective and subjective evaluation except the audio quality.
* 6 pages, 4 figures
Taming a Generative Model
Nov 29, 2022
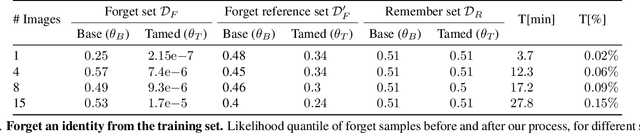
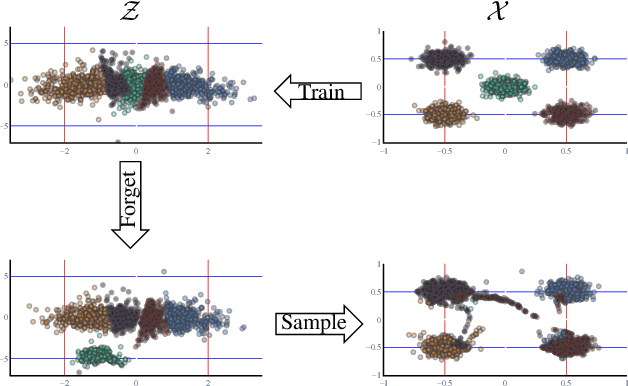
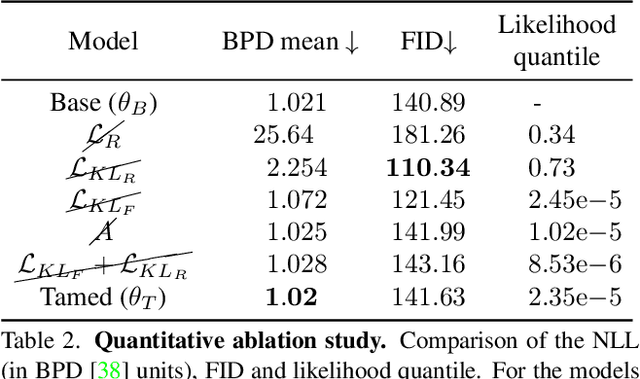
Generative models are becoming ever more powerful, being able to synthesize highly realistic images. We propose an algorithm for taming these models - changing the probability that the model will produce a specific image or image category. We consider generative models that are powered by normalizing flows, which allows us to reason about the exact generation probability likelihood for a given image. Our method is general purpose, and we exemplify it using models that generate human faces, a subdomain with many interesting privacy and bias considerations. Our method can be used in the context of privacy, e.g., removing a specific person from the output of a model, and also in the context of de-biasing by forcing a model to output specific image categories according to a given target distribution. Our method uses a fast fine-tuning process without retraining the model from scratch, achieving the goal in less than 1% of the time taken to initially train the generative model. We evaluate qualitatively and quantitatively, to examine the success of the taming process and output quality.
POLCOVID: a multicenter multiclass chest X-ray database (Poland, 2020-2021)
Nov 29, 2022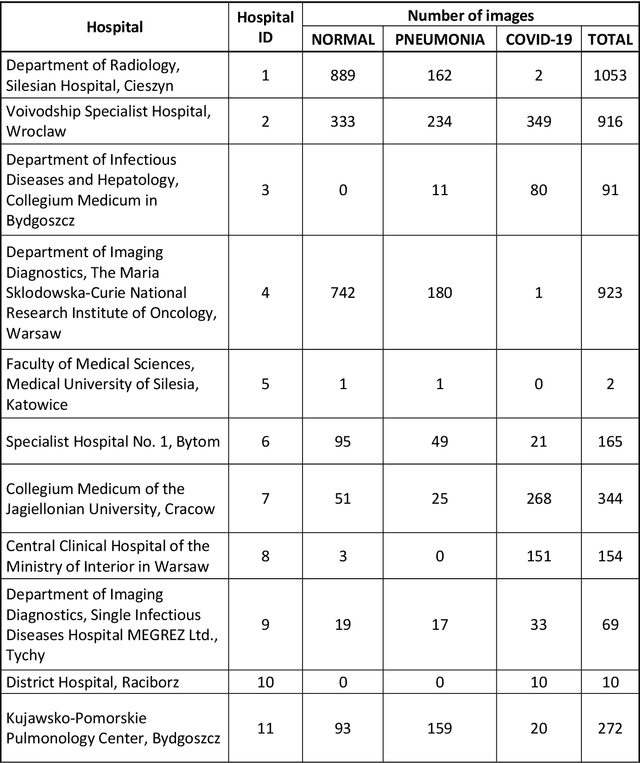
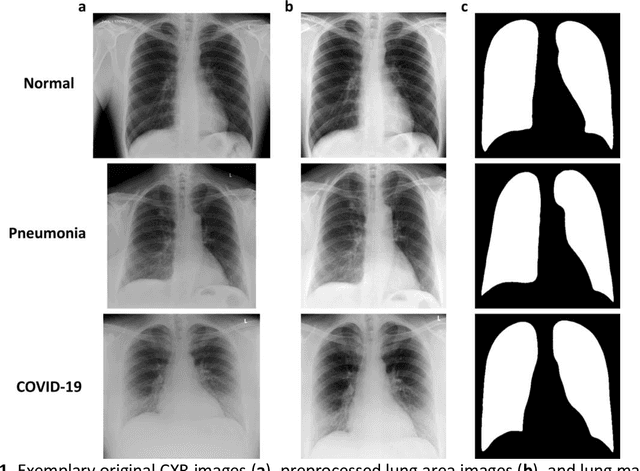
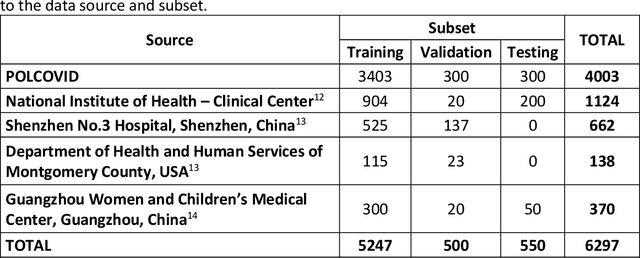
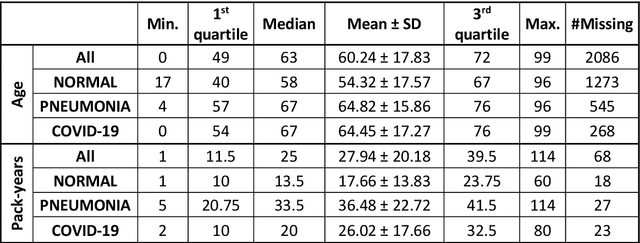
The outbreak of the SARS-CoV-2 pandemic has put healthcare systems worldwide to their limits, resulting in increased waiting time for diagnosis and required medical assistance. With chest radiographs (CXR) being one of the most common COVID-19 diagnosis methods, many artificial intelligence tools for image-based COVID-19 detection have been developed, often trained on a small number of images from COVID-19-positive patients. Thus, the need for high-quality and well-annotated CXR image databases increased. This paper introduces POLCOVID dataset, containing chest X-ray (CXR) images of patients with COVID-19 or other-type pneumonia, and healthy individuals gathered from 15 Polish hospitals. The original radiographs are accompanied by the preprocessed images limited to the lung area and the corresponding lung masks obtained with the segmentation model. Moreover, the manually created lung masks are provided for a part of POLCOVID dataset and the other four publicly available CXR image collections. POLCOVID dataset can help in pneumonia or COVID-19 diagnosis, while the set of matched images and lung masks may serve for the development of lung segmentation solutions.
LightDepth: A Resource Efficient Depth Estimation Approach for Dealing with Ground Truth Sparsity via Curriculum Learning
Nov 19, 2022



Advances in neural networks enable tackling complex computer vision tasks such as depth estimation of outdoor scenes at unprecedented accuracy. Promising research has been done on depth estimation. However, current efforts are computationally resource-intensive and do not consider the resource constraints of autonomous devices, such as robots and drones. In this work, we present a fast and battery-efficient approach for depth estimation. Our approach devises model-agnostic curriculum-based learning for depth estimation. Our experiments show that the accuracy of our model performs on par with the state-of-the-art models, while its response time outperforms other models by 71%. All codes are available online at https://github.com/fatemehkarimii/LightDepth.
Grokking phase transitions in learning local rules with gradient descent
Oct 26, 2022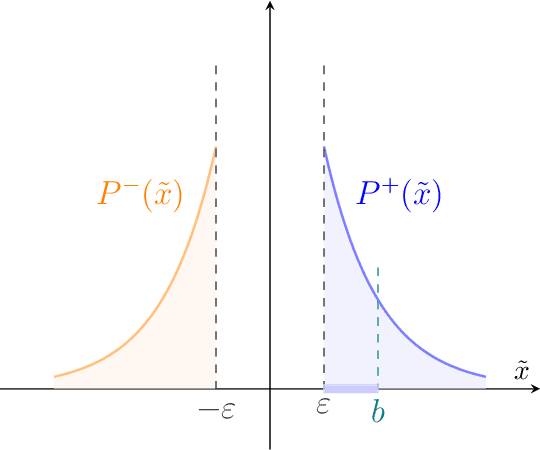
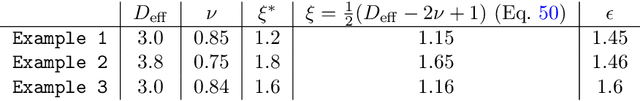
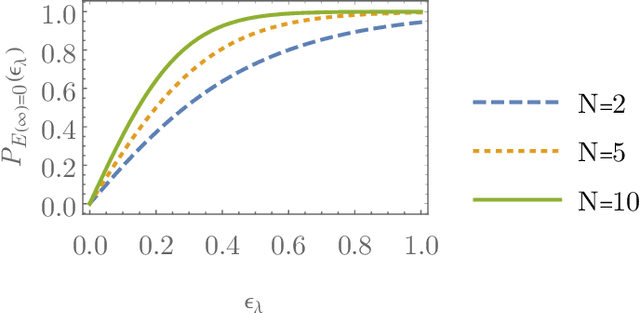
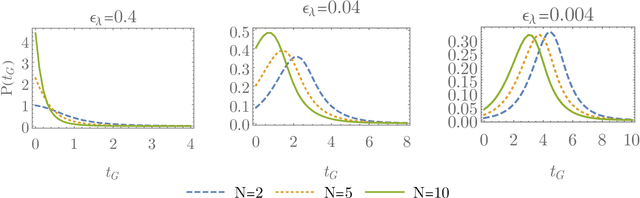
We discuss two solvable grokking (generalisation beyond overfitting) models in a rule learning scenario. We show that grokking is a phase transition and find exact analytic expressions for the critical exponents, grokking probability, and grokking time distribution. Further, we introduce a tensor-network map that connects the proposed grokking setup with the standard (perceptron) statistical learning theory and show that grokking is a consequence of the locality of the teacher model. As an example, we analyse the cellular automata learning task, numerically determine the critical exponent and the grokking time distributions and compare them with the prediction of the proposed grokking model. Finally, we numerically analyse the connection between structure formation and grokking.
Distributed Black-box Attack against Image Classification Cloud Services
Nov 02, 2022

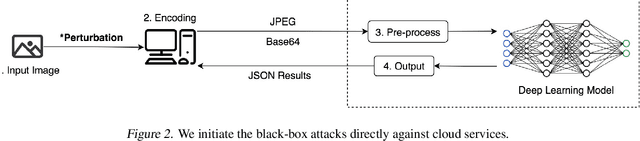

Black-box adversarial attacks can fool image classifiers into misclassifying images without requiring access to model structure and weights. Recently proposed black-box attacks can achieve a success rate of more than 95% after less than 1,000 queries. The question then arises of whether black-box attacks have become a real threat against IoT devices that rely on cloud APIs to achieve image classification. To shed some light on this, note that prior research has primarily focused on increasing the success rate and reducing the number of required queries. However, another crucial factor for black-box attacks against cloud APIs is the time required to perform the attack. This paper applies black-box attacks directly to cloud APIs rather than to local models, thereby avoiding multiple mistakes made in prior research. Further, we exploit load balancing to enable distributed black-box attacks that can reduce the attack time by a factor of about five for both local search and gradient estimation methods.
Efficient Incremental Text-to-Speech on GPUs
Nov 25, 2022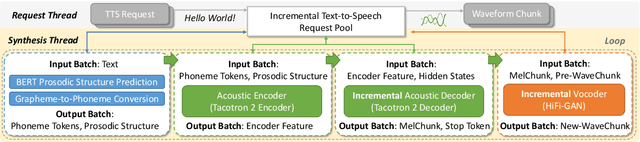
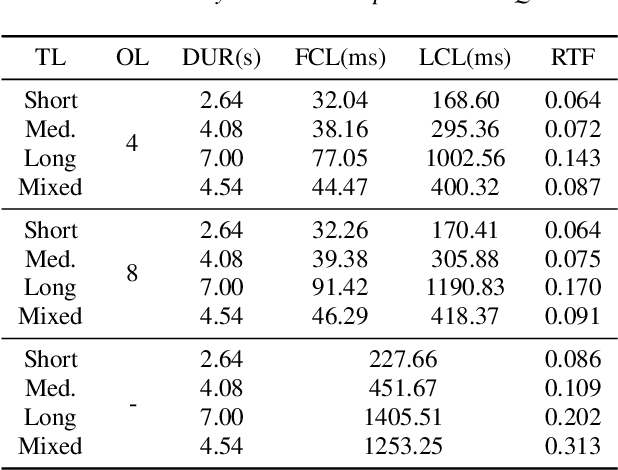
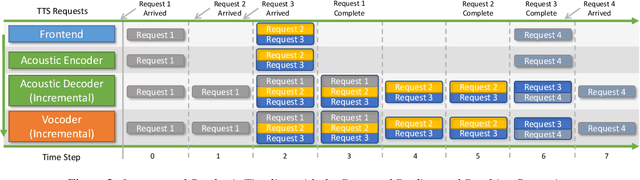
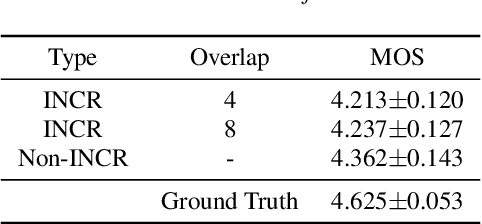
Incremental text-to-speech, also known as streaming TTS, has been increasingly applied to online speech applications that require ultra-low response latency to provide an optimal user experience. However, most of the existing speech synthesis pipelines deployed on GPU are still non-incremental, which uncovers limitations in high-concurrency scenarios, especially when the pipeline is built with end-to-end neural network models. To address this issue, we present a highly efficient approach to perform real-time incremental TTS on GPUs with Instant Request Pooling and Module-wise Dynamic Batching. Experimental results demonstrate that the proposed method is capable of producing high-quality speech with a first-chunk latency lower than 80ms under 100 QPS on a single NVIDIA A10 GPU and significantly outperforms the non-incremental twin in both concurrency and latency. Our work reveals the effectiveness of high-performance incremental TTS on GPUs.