 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Hybrid Statistical-Machine Learning Approach for Analysing Online Customer Behavior: An Empirical Study
Dec 01, 2022

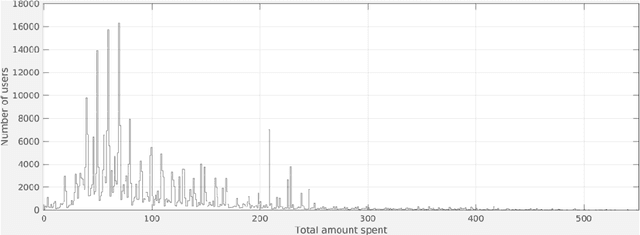
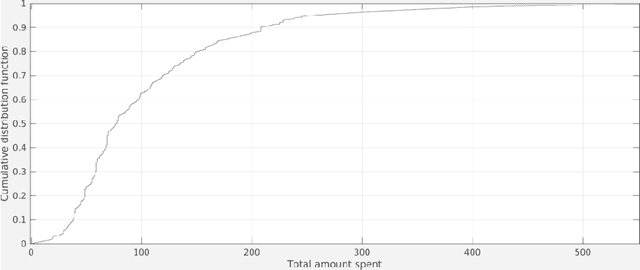
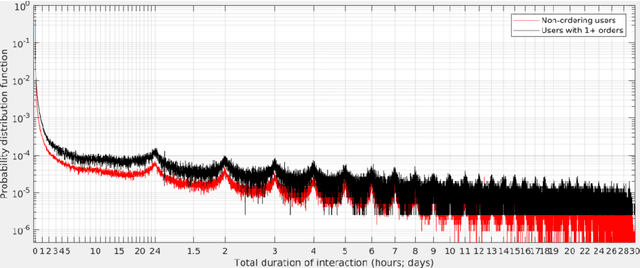
We apply classical statistical methods in conjunction with the state-of-the-art machine learning techniques to develop a hybrid interpretable model to analyse 454,897 online customers' behavior for a particular product category at the largest online retailer in China, that is JD. While most mere machine learning methods are plagued by the lack of interpretability in practice, our novel hybrid approach will address this practical issue by generating explainable output. This analysis involves identifying what features and characteristics have the most significant impact on customers' purchase behavior, thereby enabling us to predict future sales with a high level of accuracy, and identify the most impactful variables. Our results reveal that customers' product choice is insensitive to the promised delivery time, but this factor significantly impacts customers' order quantity. We also show that the effectiveness of various discounting methods depends on the specific product and the discount size. We identify product classes for which certain discounting approaches are more effective and provide recommendations on better use of different discounting tools. Customers' choice behavior across different product classes is mostly driven by price, and to a lesser extent, by customer demographics. The former finding asks for exercising care in deciding when and how much discount should be offered, whereas the latter identifies opportunities for personalized ads and targeted marketing. Further, to curb customers' batch ordering behavior and avoid the undesirable Bullwhip effect, JD should improve its logistics to ensure faster delivery of orders.
Kick-motion Training with DQN in AI Soccer Environment
Dec 01, 2022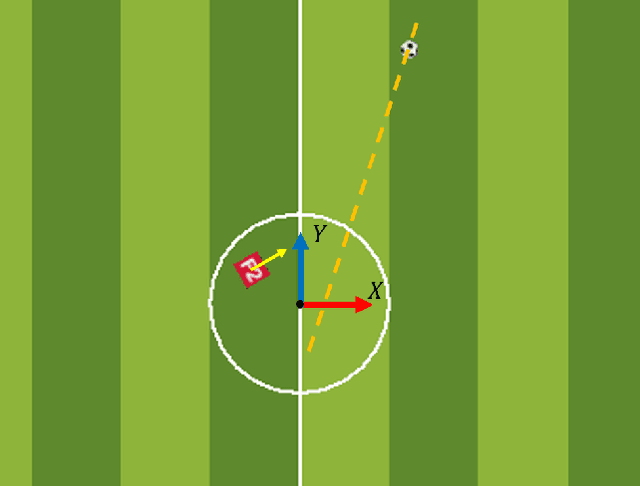
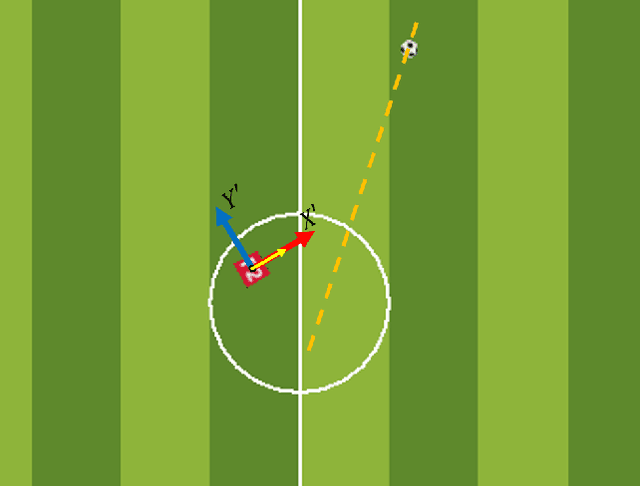
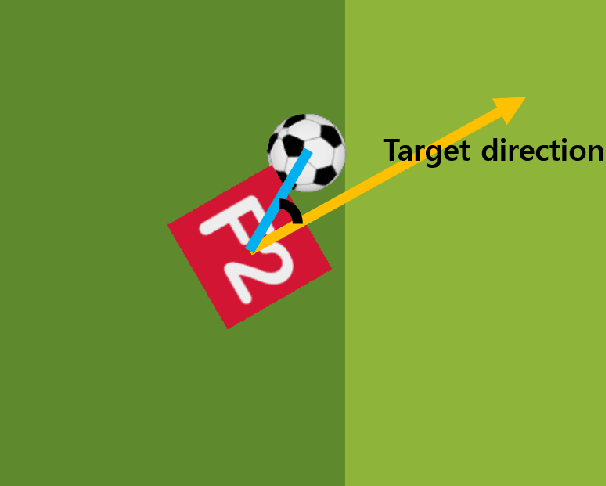
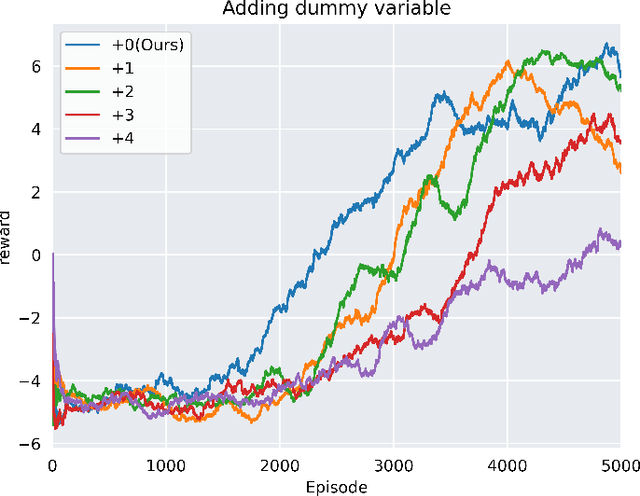
This paper presents a technique to train a robot to perform kick-motion in AI soccer by using reinforcement learning (RL). In RL, an agent interacts with an environment and learns to choose an action in a state at each step. When training RL algorithms, a problem called the curse of dimensionality (COD) can occur if the dimension of the state is high and the number of training data is low. The COD often causes degraded performance of RL models. In the situation of the robot kicking the ball, as the ball approaches the robot, the robot chooses the action based on the information obtained from the soccer field. In order not to suffer COD, the training data, which are experiences in the case of RL, should be collected evenly from all areas of the soccer field over (theoretically infinite) time. In this paper, we attempt to use the relative coordinate system (RCS) as the state for training kick-motion of robot agent, instead of using the absolute coordinate system (ACS). Using the RCS eliminates the necessity for the agent to know all the (state) information of entire soccer field and reduces the dimension of the state that the agent needs to know to perform kick-motion, and consequently alleviates COD. The training based on the RCS is performed with the widely used Deep Q-network (DQN) and tested in the AI Soccer environment implemented with Webots simulation software.
Nonlinear and Machine Learning Analyses on High-Density EEG data of Math Experts and Novices
Dec 01, 2022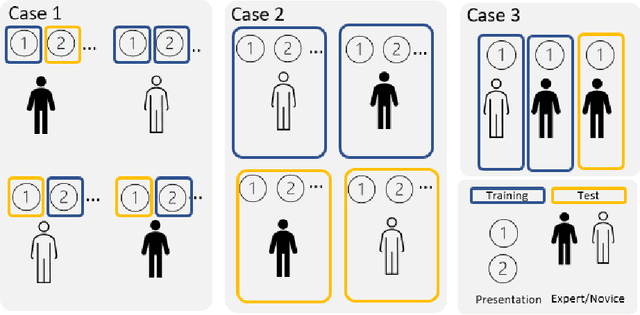

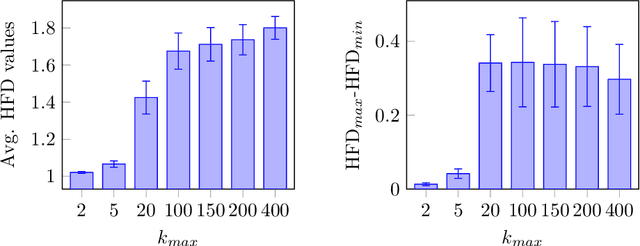
Current trend in neurosciences is to use naturalistic stimuli, such as cinema, class-room biology or video gaming, aiming to understand the brain functions during ecologically valid conditions. Naturalistic stimuli recruit complex and overlapping cognitive, emotional and sensory brain processes. Brain oscillations form underlying mechanisms for such processes, and further, these processes can be modified by expertise. Human cortical oscillations are often analyzed with linear methods despite brain as a biological system is highly nonlinear. This study applies a relatively robust nonlinear method, Higuchi fractal dimension (HFD), to classify cortical oscillations of math experts and novices when they solve long and complex math demonstrations in an EEG laboratory. Brain imaging data, which is collected over a long time span during naturalistic stimuli, enables the application of data-driven analyses. Therefore, we also explore the neural signature of math expertise with machine learning algorithms. There is a need for novel methodologies in analyzing naturalistic data because formulation of theories of the brain functions in the real world based on reductionist and simplified study designs is both challenging and questionable. Data-driven intelligent approaches may be helpful in developing and testing new theories on complex brain functions. Our results clarify the different neural signature, analyzed by HFD, of math experts and novices during complex math and suggest machine learning as a promising data-driven approach to understand the brain processes in expertise and mathematical cognition.
A Novel Speech Feature Fusion Algorithm for Text-Independent Speaker Recognition
Dec 01, 2022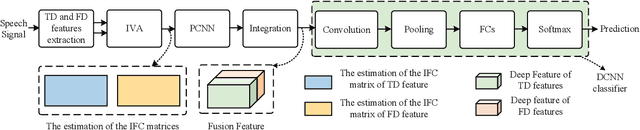
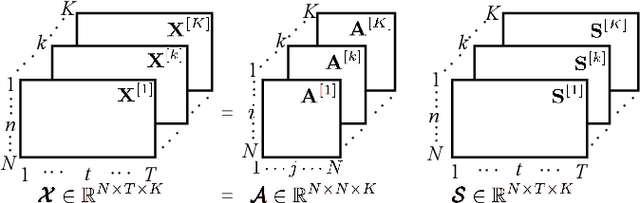
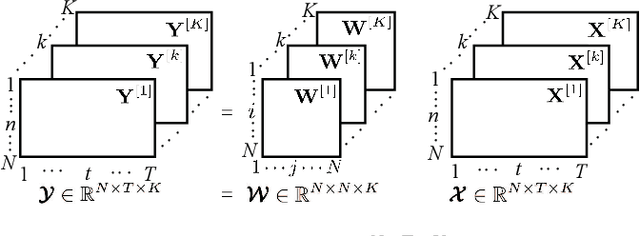
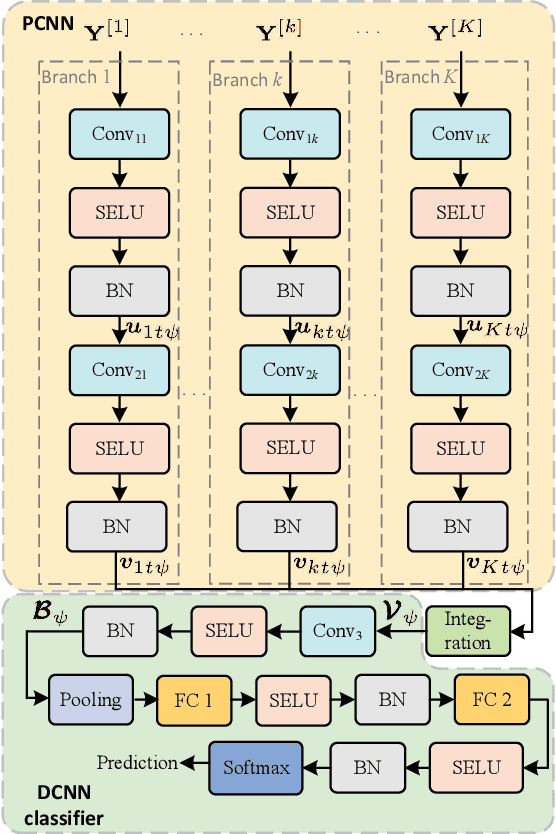
A novel speech feature fusion algorithm with independent vector analysis (IVA) and parallel convolutional neural network (PCNN) is proposed for text-independent speaker recognition. Firstly, some different feature types, such as the time domain (TD) features and the frequency domain (FD) features, can be extracted from a speaker's speech, and the TD and the FD features can be considered as the linear mixtures of independent feature components (IFCs) with an unknown mixing system. To estimate the IFCs, the TD and the FD features of the speaker's speech are concatenated to build the TD and the FD feature matrix, respectively. Then, a feature tensor of the speaker's speech is obtained by paralleling the TD and the FD feature matrix. To enhance the dependence on different feature types and remove the redundancies of the same feature type, the independent vector analysis (IVA) can be used to estimate the IFC matrices of TD and FD features with the feature tensor. The IFC matrices are utilized as the input of the PCNN to extract the deep features of the TD and FD features, respectively. The deep features can be integrated to obtain the fusion feature of the speaker's speech. Finally, the fusion feature of the speaker's speech is employed as the input of a deep convolutional neural network (DCNN) classifier for speaker recognition. The experimental results show the effectiveness and performances of the proposed speaker recognition system.
Data-driven low-dimensional dynamic model of Kolmogorov flow
Oct 29, 2022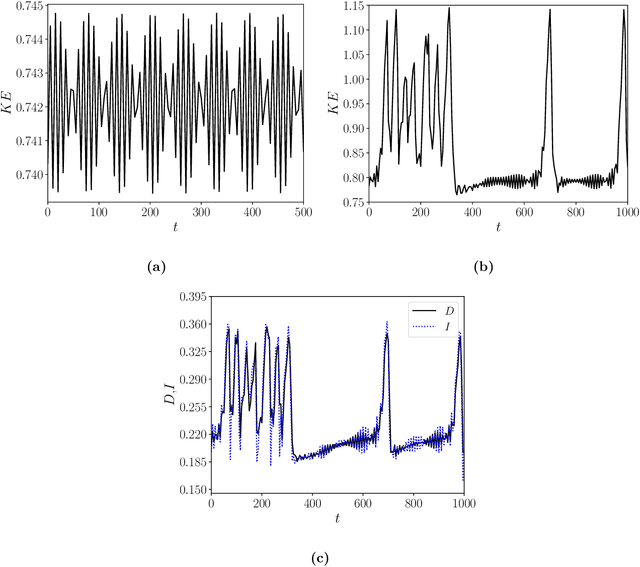
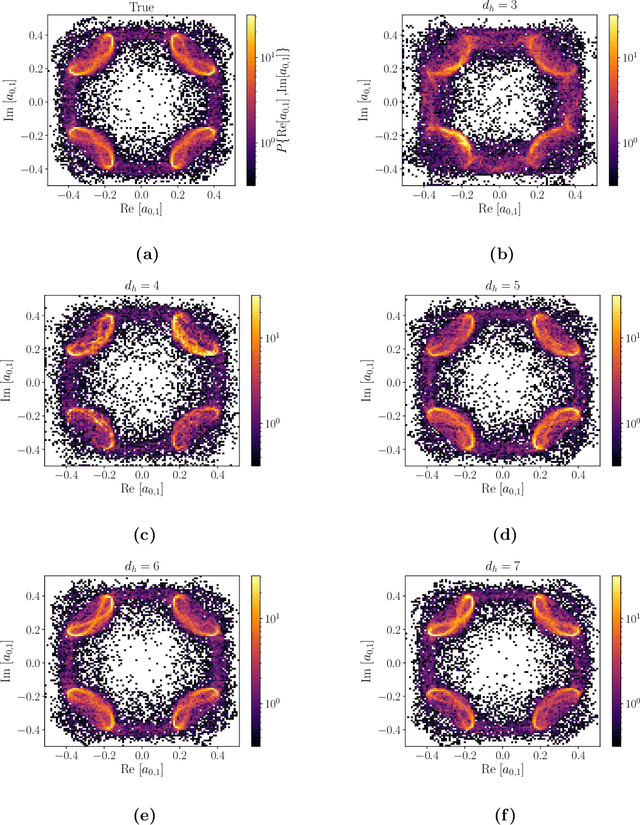
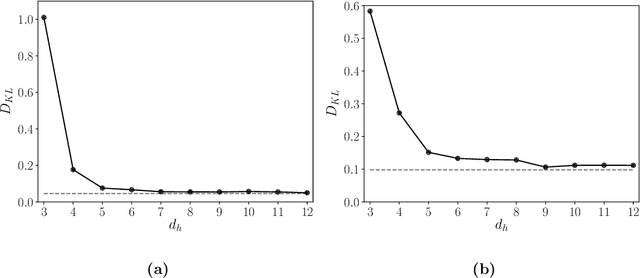
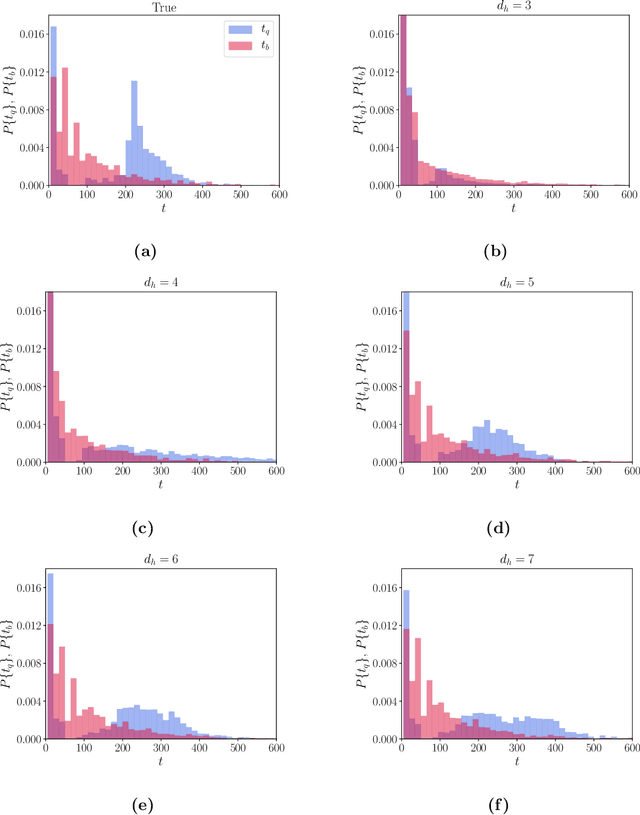
Reduced order models (ROMs) that capture flow dynamics are of interest for decreasing computational costs for simulation as well as for model-based control approaches. This work presents a data-driven framework for minimal-dimensional models that effectively capture the dynamics and properties of the flow. We apply this to Kolmogorov flow in a regime consisting of chaotic and intermittent behavior, which is common in many flows processes and is challenging to model. The trajectory of the flow travels near relative periodic orbits (RPOs), interspersed with sporadic bursting events corresponding to excursions between the regions containing the RPOs. The first step in development of the models is use of an undercomplete autoencoder to map from the full state data down to a latent space of dramatically lower dimension. Then models of the discrete-time evolution of the dynamics in the latent space are developed. By analyzing the model performance as a function of latent space dimension we can estimate the minimum number of dimensions required to capture the system dynamics. To further reduce the dimension of the dynamical model, we factor out a phase variable in the direction of translational invariance for the flow, leading to separate evolution equations for the pattern and phase dynamics. At a model dimension of five for the pattern dynamics, as opposed to the full state dimension of 1024 (i.e. a 32x32 grid), accurate predictions are found for individual trajectories out to about two Lyapunov times, as well as for long-time statistics. The nearly heteroclinic connections between the different RPOs, including the quiescent and bursting time scales, are well captured. We also capture key features of the phase dynamics. Finally, we use the low-dimensional representation to predict future bursting events, finding good success.
MEESO: A Multi-objective End-to-End Self-Optimized Approach for Automatically Building Deep Learning Models
Nov 20, 2022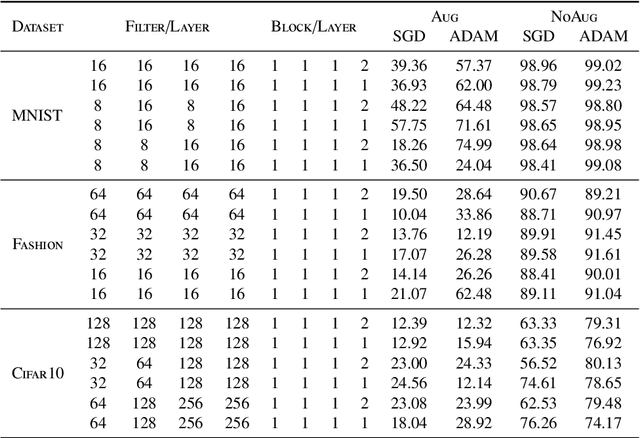
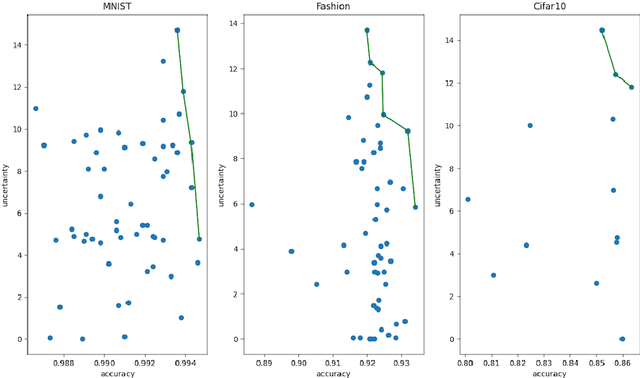
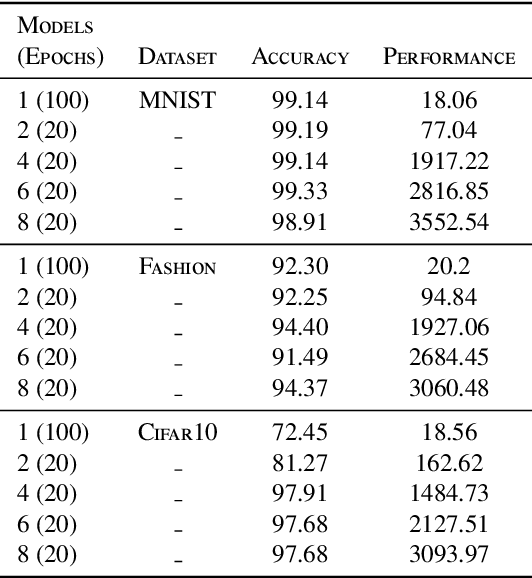
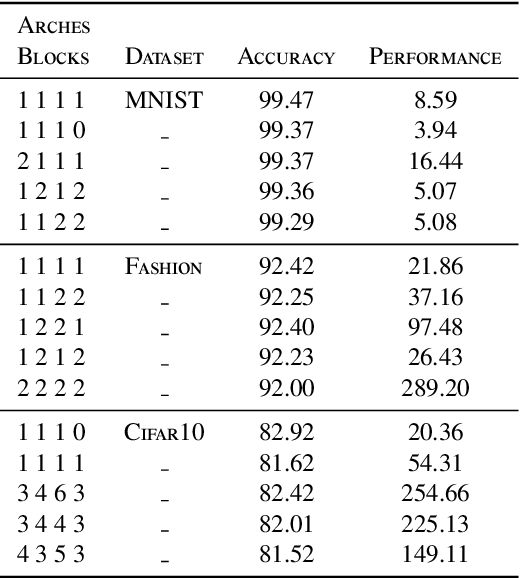
Deep learning has been widely used in various applications from different fields such as computer vision, natural language processing, etc. However, the training models are often manually developed via many costly experiments. This manual work usually requires substantial computing resources, time, and experience. To simplify the use of deep learning and alleviate human effort, automated deep learning has emerged as a potential tool that releases the burden for both users and researchers. Generally, an automatic approach should support the diversity of model selection and the evaluation should allow users to decide upon their demands. To that end, we propose a multi-objective end-to-end self-optimized approach for constructing deep learning models automatically. Experimental results on well-known datasets such as MNIST, Fashion, and Cifar10 show that our algorithm can discover various competitive models compared with the state-of-the-art approach. In addition, our approach also introduces multi-objective trade-off solutions for both accuracy and uncertainty metrics for users to make better decisions.
ECM-OPCC: Efficient Context Model for Octree-based Point Cloud Compression
Nov 20, 2022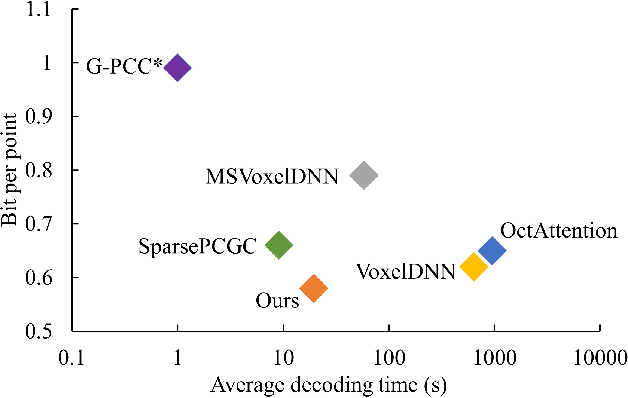
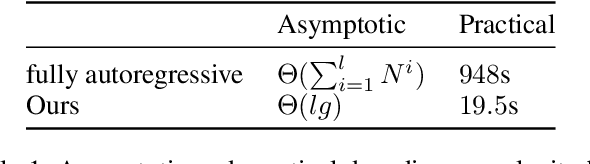
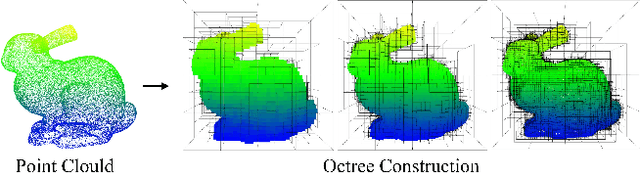
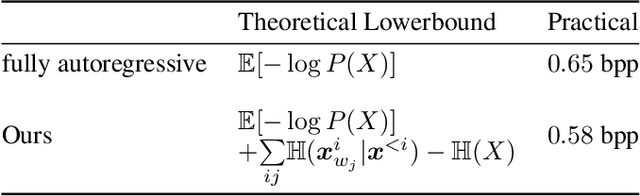
Recently, deep learning methods have shown promising results in point cloud compression. For octree-based point cloud compression, previous works show that the information of ancestor nodes and sibling nodes are equally important for predicting current node. However, those works either adopt insufficient context or bring intolerable decoding complexity (e.g. >600s). To address this problem, we propose a sufficient yet efficient context model and design an efficient deep learning codec for point clouds. Specifically, we first propose a window-constrained multi-group coding strategy to exploit the autoregressive context while maintaining decoding efficiency. Then, we propose a dual transformer architecture to utilize the dependency of current node on its ancestors and siblings. We also propose a random-masking pre-train method to enhance our model. Experimental results show that our approach achieves state-of-the-art performance for both lossy and lossless point cloud compression. Moreover, our multi-group coding strategy saves 98% decoding time compared with previous octree-based compression method.
Structure-Enhanced Deep Reinforcement Learning for Optimal Transmission Scheduling
Nov 20, 2022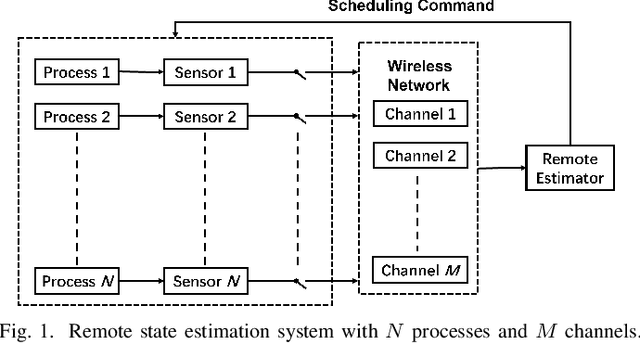
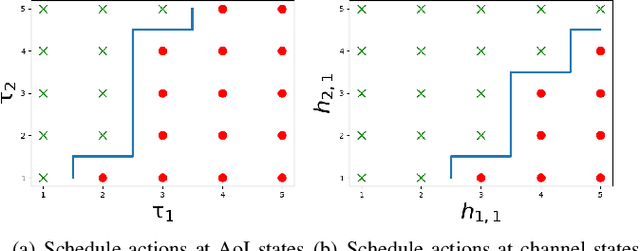
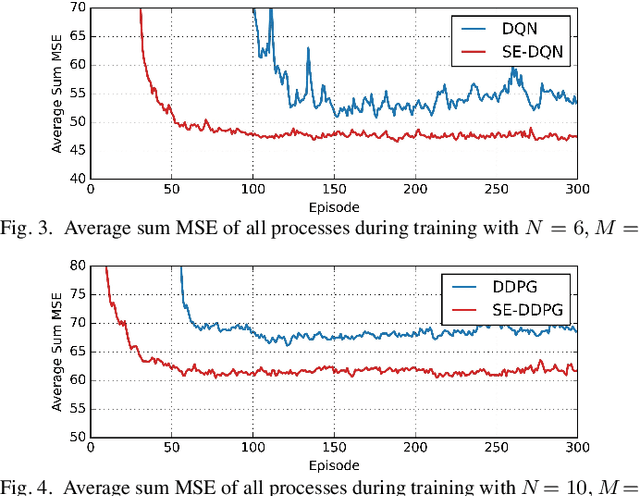
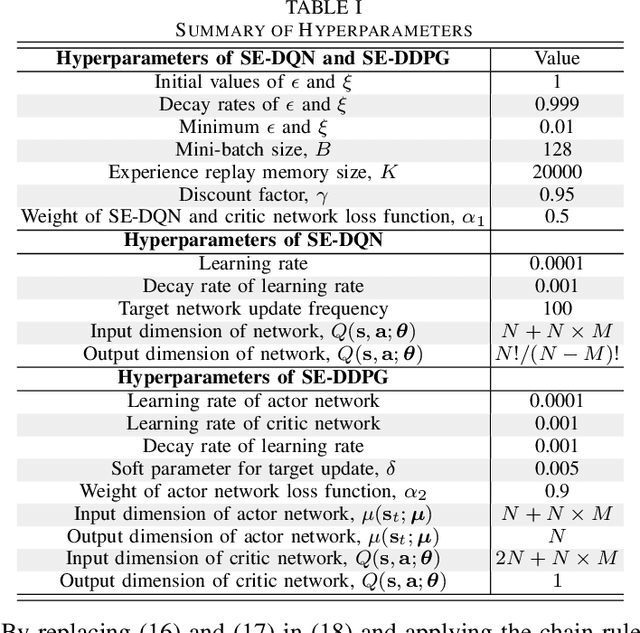
Remote state estimation of large-scale distributed dynamic processes plays an important role in Industry 4.0 applications. In this paper, by leveraging the theoretical results of structural properties of optimal scheduling policies, we develop a structure-enhanced deep reinforcement learning (DRL) framework for optimal scheduling of a multi-sensor remote estimation system to achieve the minimum overall estimation mean-square error (MSE). In particular, we propose a structure-enhanced action selection method, which tends to select actions that obey the policy structure. This explores the action space more effectively and enhances the learning efficiency of DRL agents. Furthermore, we introduce a structure-enhanced loss function to add penalty to actions that do not follow the policy structure. The new loss function guides the DRL to converge to the optimal policy structure quickly. Our numerical results show that the proposed structure-enhanced DRL algorithms can save the training time by 50% and reduce the remote estimation MSE by 10% to 25%, when compared to benchmark DRL algorithms.
Deep Learning-Based Prediction of Molecular Tumor Biomarkers from H&E: A Practical Review
Nov 27, 2022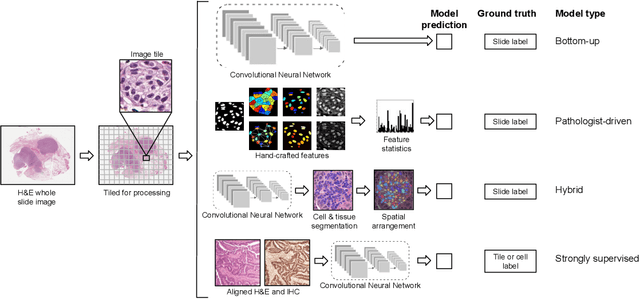
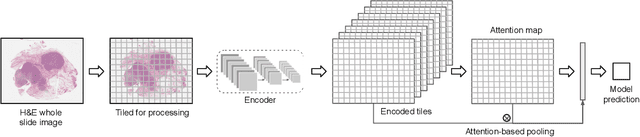
Molecular and genomic properties are critical in selecting cancer treatments to target individual tumors, particularly for immunotherapy. However, the methods to assess such properties are expensive, time-consuming, and often not routinely performed. Applying machine learning to H&E images can provide a more cost-effective screening method. Dozens of studies over the last few years have demonstrated that a variety of molecular biomarkers can be predicted from H&E alone using the advancements of deep learning: molecular alterations, genomic subtypes, protein biomarkers, and even the presence of viruses. This article reviews the diverse applications across cancer types and the methodology to train and validate these models on whole slide images. From bottom-up to pathologist-driven to hybrid approaches, the leading trends include a variety of weakly supervised deep learning-based approaches, as well as mechanisms for training strongly supervised models in select situations. While results of these algorithms look promising, some challenges still persist, including small training sets, rigorous validation, and model explainability. Biomarker prediction models may yield a screening method to determine when to run molecular tests or an alternative when molecular tests are not possible. They also create new opportunities in quantifying intratumoral heterogeneity and predicting patient outcomes.
Understanding the Performance of Learning Precoding Policy with GNN and CNNs
Nov 27, 2022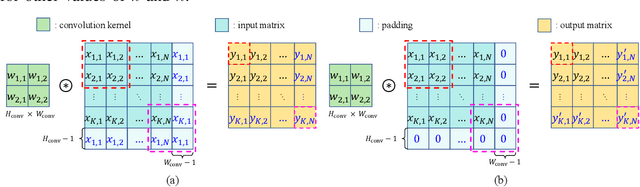
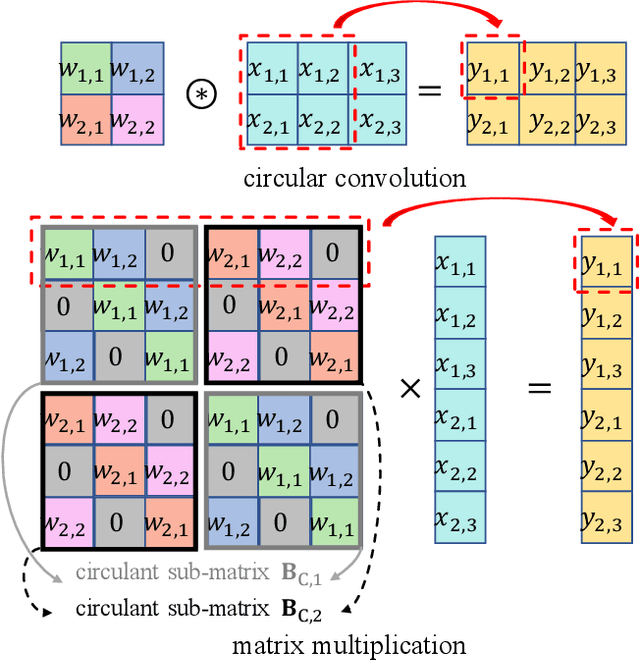
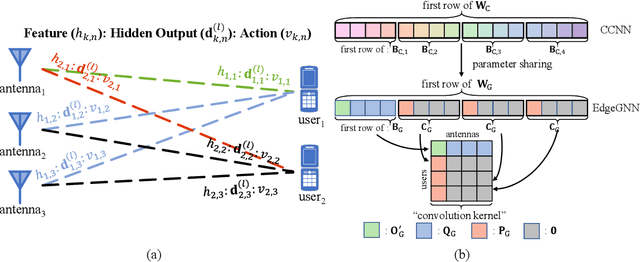
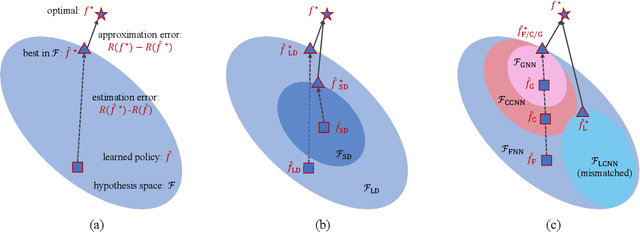
Learning-based precoding has been shown able to be implemented in real-time, jointly optimized with channel acquisition, and robust to imperfect channels. Yet previous works rarely explain the design choices and learning performance, and existing methods either suffer from high training complexity or depend on problem-specific models. In this paper, we address these issues by analyzing the properties of precoding policy and inductive biases of neural networks, noticing that the learning performance can be decomposed into approximation and estimation errors where the former is related to the smoothness of the policy and both depend on the inductive biases of neural networks. To this end, we introduce a graph neural network (GNN) to learn precoding policy and analyze its connection with the commonly used convolutional neural networks (CNNs). By taking a sum rate maximization precoding policy as an example, we explain why the learned precoding policy performs well in the low signal-to-noise ratio regime, in spatially uncorrelated channels, and when the number of users is much fewer than the number of antennas, as well as why GNN is with higher learning efficiency than CNNs. Extensive simulations validate our analyses and evaluate the generalization ability of the GNN.