 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Generalized Deep Learning-based Proximal Gradient Descent for MR Reconstruction
Nov 30, 2022

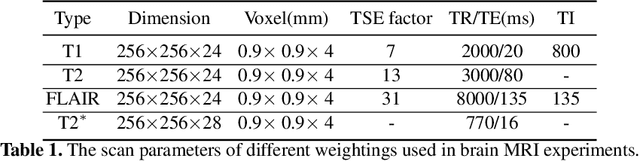
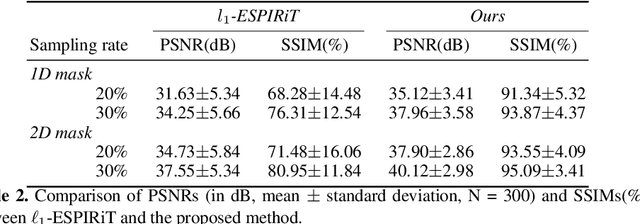
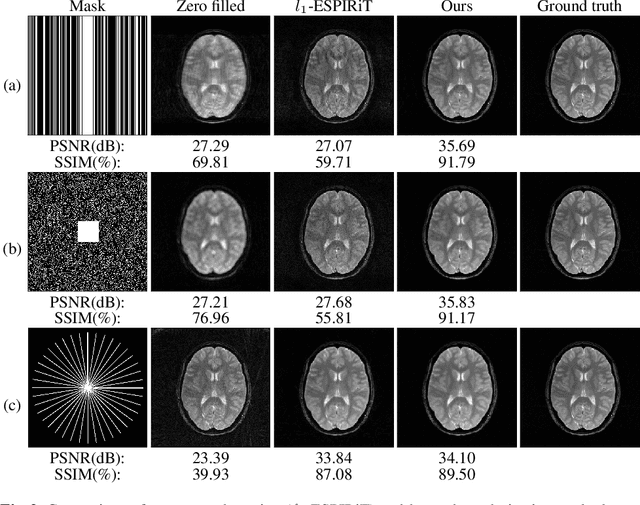
The data consistency for the physical forward model is crucial in inverse problems, especially in MR imaging reconstruction. The standard way is to unroll an iterative algorithm into a neural network with a forward model embedded. The forward model always changes in clinical practice, so the learning component's entanglement with the forward model makes the reconstruction hard to generalize. The proposed method is more generalizable for different MR acquisition settings by separating the forward model from the deep learning component. The deep learning-based proximal gradient descent was proposed to create a learned regularization term independent of the forward model. We applied the one-time trained regularization term to different MR acquisition settings to validate the proposed method and compared the reconstruction with the commonly used $\ell_1$ regularization. We showed ~3 dB improvement in the peak signal to noise ratio, compared with conventional $\ell_1$ regularized reconstruction. We demonstrated the flexibility of the proposed method in choosing different undersampling patterns. We also evaluated the effect of parameter tuning for the deep learning regularization.
Uncertainty-Aware Image Captioning
Nov 30, 2022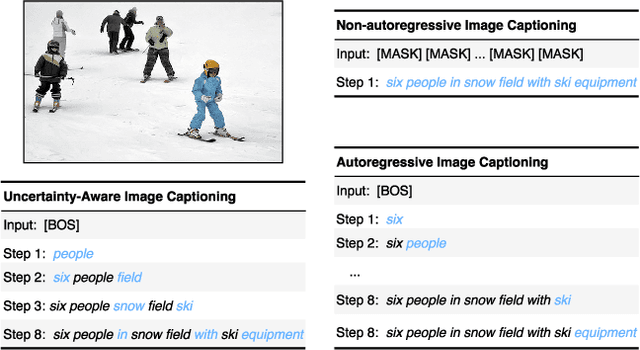
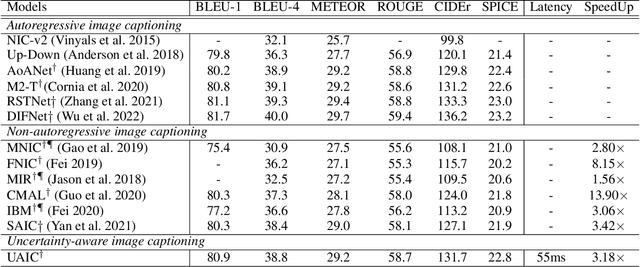
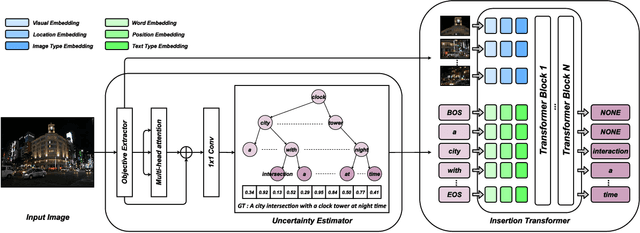
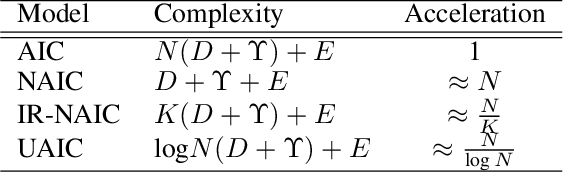
It is well believed that the higher uncertainty in a word of the caption, the more inter-correlated context information is required to determine it. However, current image captioning methods usually consider the generation of all words in a sentence sequentially and equally. In this paper, we propose an uncertainty-aware image captioning framework, which parallelly and iteratively operates insertion of discontinuous candidate words between existing words from easy to difficult until converged. We hypothesize that high-uncertainty words in a sentence need more prior information to make a correct decision and should be produced at a later stage. The resulting non-autoregressive hierarchy makes the caption generation explainable and intuitive. Specifically, we utilize an image-conditioned bag-of-word model to measure the word uncertainty and apply a dynamic programming algorithm to construct the training pairs. During inference, we devise an uncertainty-adaptive parallel beam search technique that yields an empirically logarithmic time complexity. Extensive experiments on the MS COCO benchmark reveal that our approach outperforms the strong baseline and related methods on both captioning quality as well as decoding speed.
Extract Dynamic Information To Improve Time Series Modeling: a Case Study with Scientific Workflow
May 19, 2022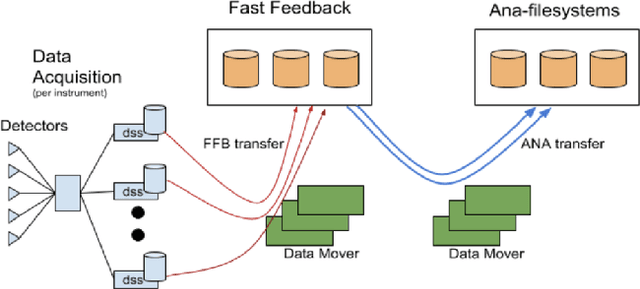
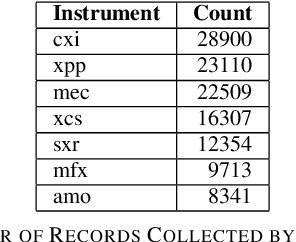
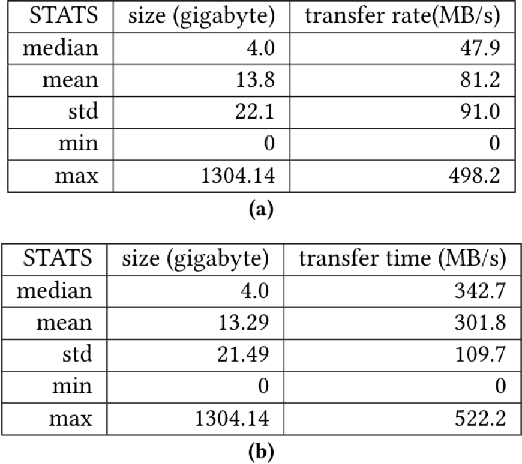

In modeling time series data, we often need to augment the existing data records to increase the modeling accuracy. In this work, we describe a number of techniques to extract dynamic information about the current state of a large scientific workflow, which could be generalized to other types of applications. The specific task to be modeled is the time needed for transferring a file from an experimental facility to a data center. The key idea of our approach is to find recent past data transfer events that match the current event in some ways. Tests showed that we could identify recent events matching some recorded properties and reduce the prediction error by about 12% compared to the similar models with only static features. We additionally explored an application specific technique to extract information about the data production process, and was able to reduce the average prediction error by 44%.
Knowledge Distillation for Multi-Target Domain Adaptation in Real-Time Person Re-Identification
May 12, 2022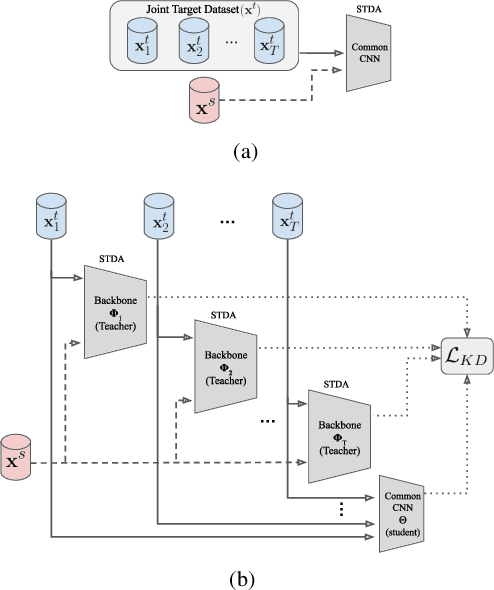
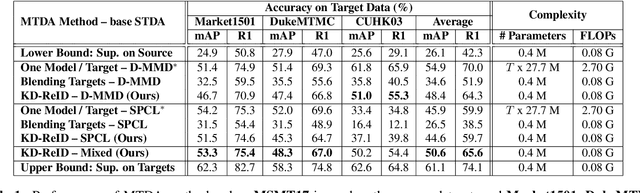
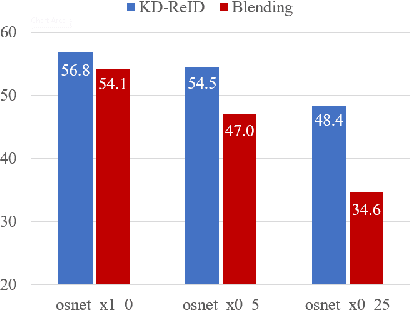
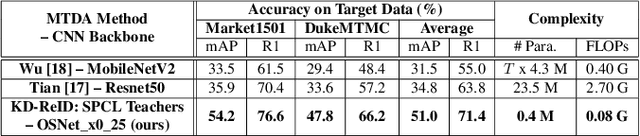
Despite the recent success of deep learning architectures, person re-identification (ReID) remains a challenging problem in real-word applications. Several unsupervised single-target domain adaptation (STDA) methods have recently been proposed to limit the decline in ReID accuracy caused by the domain shift that typically occurs between source and target video data. Given the multimodal nature of person ReID data (due to variations across camera viewpoints and capture conditions), training a common CNN backbone to address domain shifts across multiple target domains, can provide an efficient solution for real-time ReID applications. Although multi-target domain adaptation (MTDA) has not been widely addressed in the ReID literature, a straightforward approach consists in blending different target datasets, and performing STDA on the mixture to train a common CNN. However, this approach may lead to poor generalization, especially when blending a growing number of distinct target domains to train a smaller CNN. To alleviate this problem, we introduce a new MTDA method based on knowledge distillation (KD-ReID) that is suitable for real-time person ReID applications. Our method adapts a common lightweight student backbone CNN over the target domains by alternatively distilling from multiple specialized teacher CNNs, each one adapted on data from a specific target domain. Extensive experiments conducted on several challenging person ReID datasets indicate that our approach outperforms state-of-art methods for MTDA, including blending methods, particularly when training a compact CNN backbone like OSNet. Results suggest that our flexible MTDA approach can be employed to design cost-effective ReID systems for real-time video surveillance applications.
ESFPNet: efficient deep learning architecture for real-time lesion segmentation in autofluorescence bronchoscopic video
Jul 15, 2022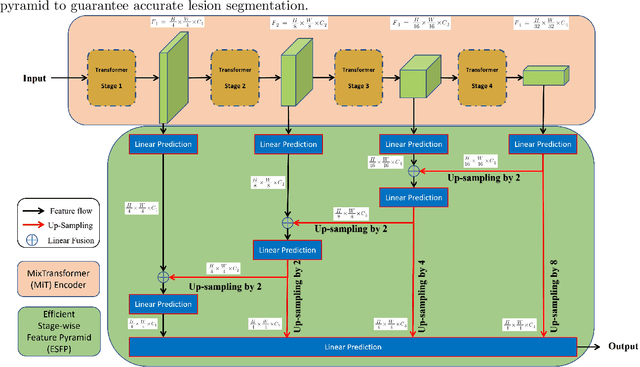

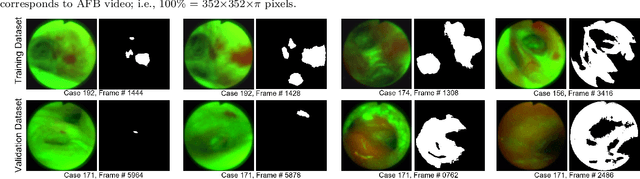

Lung cancer tends to be detected at an advanced stage, resulting in a high patient mortality rate. Thus, recent research has focused on early disease detection. Lung cancer generally first appears as lesions developing within the bronchial epithelium of the airway walls. Bronchoscopy is the procedure of choice for effective noninvasive bronchial lesion detection. In particular, autofluorescence bronchoscopy (AFB) discriminates the autofluorescence properties of normal and diseased tissue, whereby lesions appear reddish brown in AFB video frames, while normal tissue appears green. Because recent studies show AFB's ability for high lesion sensitivity, it has become a potentially pivotal method during the standard bronchoscopic airway exam for early-stage lung cancer detection. Unfortunately, manual inspection of AFB video is extremely tedious and error-prone, while limited effort has been expended toward potentially more robust automatic AFB lesion detection and segmentation. We propose a real-time deep learning architecture ESFPNet for robust detection and segmentation of bronchial lesions from an AFB video stream. The architecture features an encoder structure that exploits pretrained Mix Transformer (MiT) encoders and a stage-wise feature pyramid (ESFP) decoder structure. Results from AFB videos derived from lung cancer patient airway exams indicate that our approach gives mean Dice index and IOU values of 0.782 and 0.658, respectively, while having a processing throughput of 27 frames/sec. These values are superior to results achieved by other competing architectures that use Mix transformers or CNN-based encoders. Moreover, the superior performance on the ETIS-LaribPolypDB dataset demonstrates its potential applicability to other domains.
Snapshot Multispectral Imaging Using a Diffractive Optical Network
Dec 10, 2022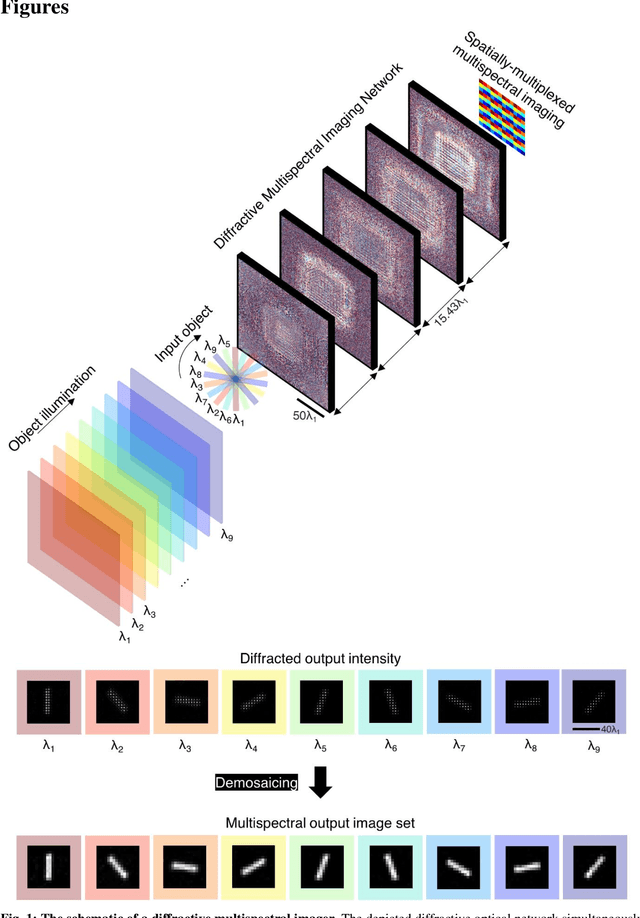
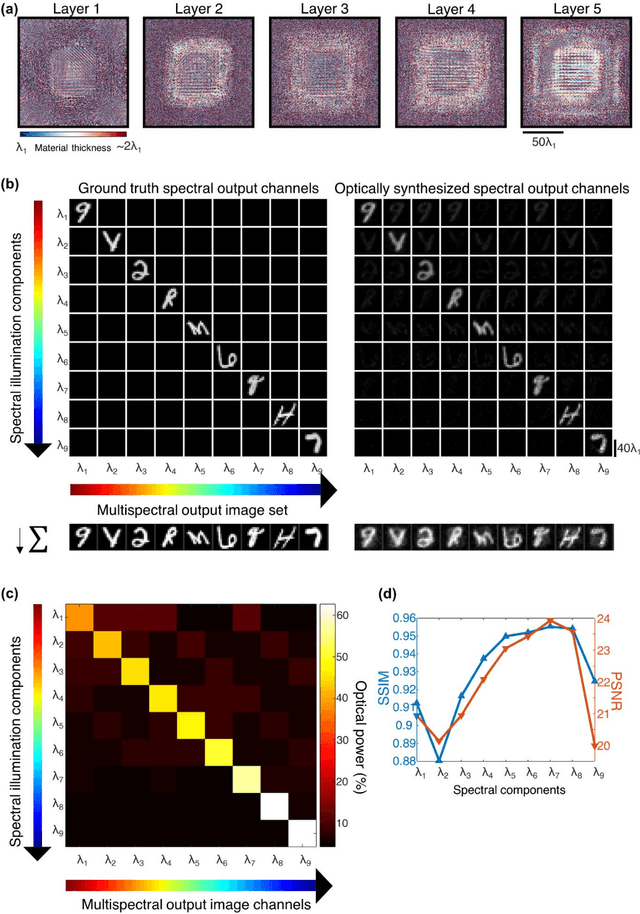
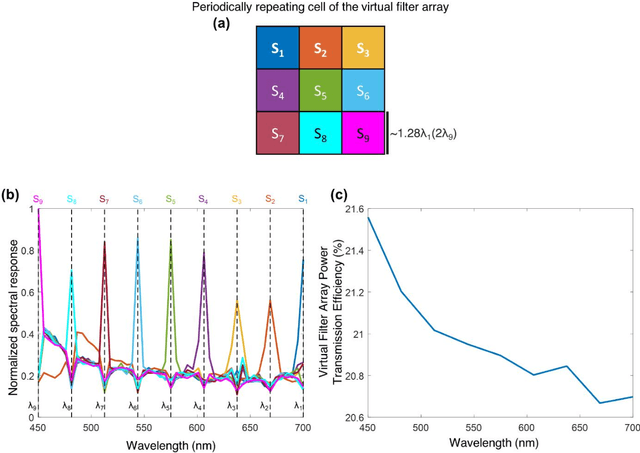
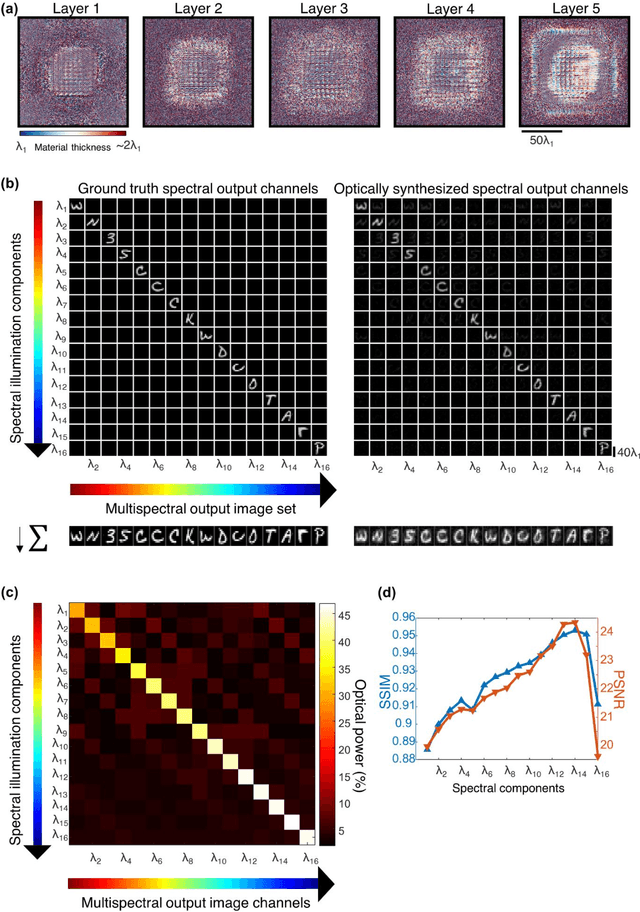
Multispectral imaging has been used for numerous applications in e.g., environmental monitoring, aerospace, defense, and biomedicine. Here, we present a diffractive optical network-based multispectral imaging system trained using deep learning to create a virtual spectral filter array at the output image field-of-view. This diffractive multispectral imager performs spatially-coherent imaging over a large spectrum, and at the same time, routes a pre-determined set of spectral channels onto an array of pixels at the output plane, converting a monochrome focal plane array or image sensor into a multispectral imaging device without any spectral filters or image recovery algorithms. Furthermore, the spectral responsivity of this diffractive multispectral imager is not sensitive to input polarization states. Through numerical simulations, we present different diffractive network designs that achieve snapshot multispectral imaging with 4, 9 and 16 unique spectral bands within the visible spectrum, based on passive spatially-structured diffractive surfaces, with a compact design that axially spans ~72 times the mean wavelength of the spectral band of interest. Moreover, we experimentally demonstrate a diffractive multispectral imager based on a 3D-printed diffractive network that creates at its output image plane a spatially-repeating virtual spectral filter array with 2x2=4 unique bands at terahertz spectrum. Due to their compact form factor and computation-free, power-efficient and polarization-insensitive forward operation, diffractive multispectral imagers can be transformative for various imaging and sensing applications and be used at different parts of the electromagnetic spectrum where high-density and wide-area multispectral pixel arrays are not widely available.
Vertical Layering of Quantized Neural Networks for Heterogeneous Inference
Dec 10, 2022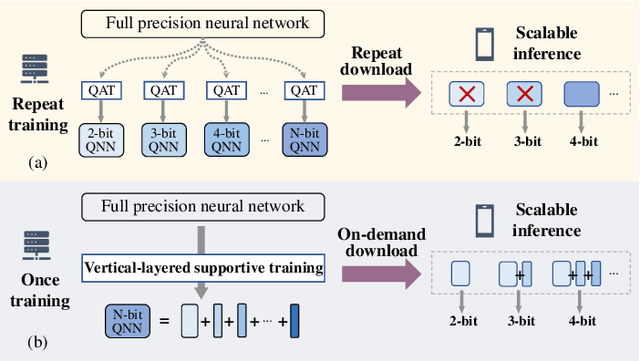
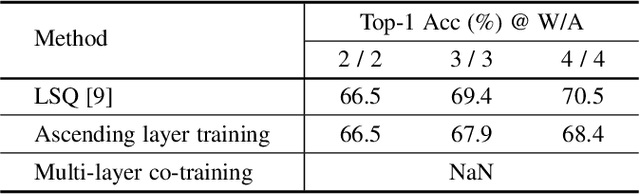
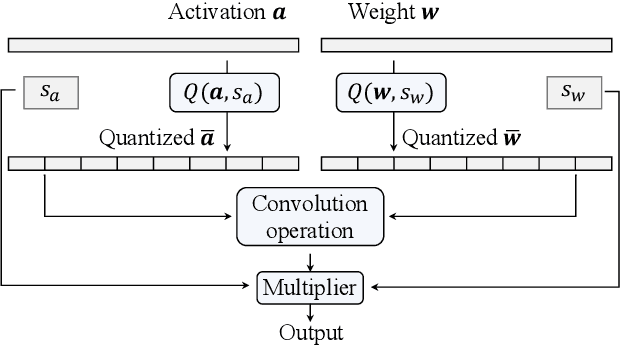
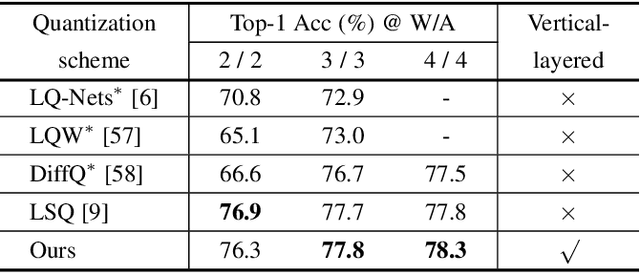
Although considerable progress has been obtained in neural network quantization for efficient inference, existing methods are not scalable to heterogeneous devices as one dedicated model needs to be trained, transmitted, and stored for one specific hardware setting, incurring considerable costs in model training and maintenance. In this paper, we study a new vertical-layered representation of neural network weights for encapsulating all quantized models into a single one. With this representation, we can theoretically achieve any precision network for on-demand service while only needing to train and maintain one model. To this end, we propose a simple once quantization-aware training (QAT) scheme for obtaining high-performance vertical-layered models. Our design incorporates a cascade downsampling mechanism which allows us to obtain multiple quantized networks from one full precision source model by progressively mapping the higher precision weights to their adjacent lower precision counterparts. Then, with networks of different bit-widths from one source model, multi-objective optimization is employed to train the shared source model weights such that they can be updated simultaneously, considering the performance of all networks. By doing this, the shared weights will be optimized to balance the performance of different quantized models, thus making the weights transferable among different bit widths. Experiments show that the proposed vertical-layered representation and developed once QAT scheme are effective in embodying multiple quantized networks into a single one and allow one-time training, and it delivers comparable performance as that of quantized models tailored to any specific bit-width. Code will be available.
Embed and Emulate: Learning to estimate parameters of dynamical systems with uncertainty quantification
Nov 03, 2022
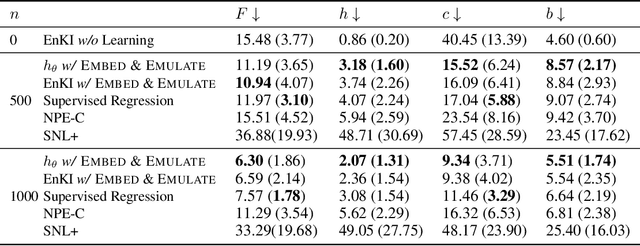
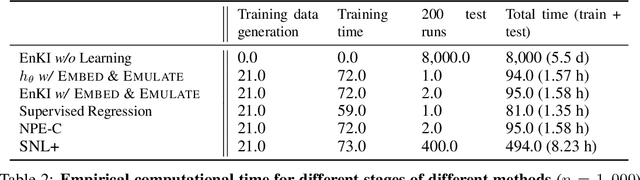
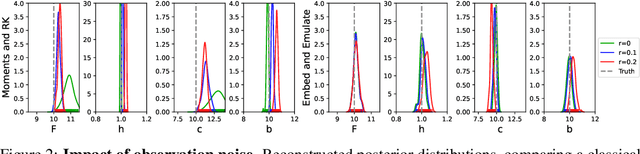
This paper explores learning emulators for parameter estimation with uncertainty estimation of high-dimensional dynamical systems. We assume access to a computationally complex simulator that inputs a candidate parameter and outputs a corresponding multichannel time series. Our task is to accurately estimate a range of likely values of the underlying parameters. Standard iterative approaches necessitate running the simulator many times, which is computationally prohibitive. This paper describes a novel framework for learning feature embeddings of observed dynamics jointly with an emulator that can replace high-cost simulators for parameter estimation. Leveraging a contrastive learning approach, our method exploits intrinsic data properties within and across parameter and trajectory domains. On a coupled 396-dimensional multiscale Lorenz 96 system, our method significantly outperforms a typical parameter estimation method based on predefined metrics and a classical numerical simulator, and with only 1.19% of the baseline's computation time. Ablation studies highlight the potential of explicitly designing learned emulators for parameter estimation by leveraging contrastive learning.
WOODS: Benchmarks for Out-of-Distribution Generalization in Time Series Tasks
Mar 18, 2022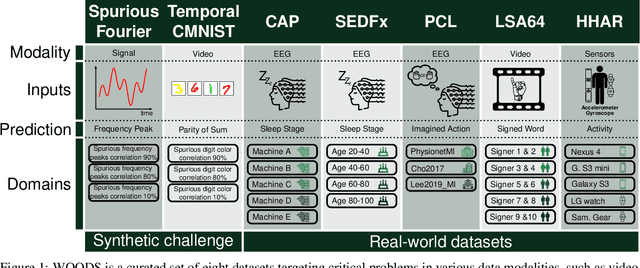
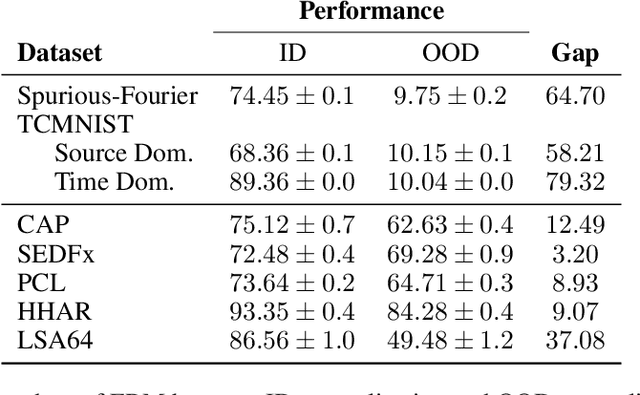
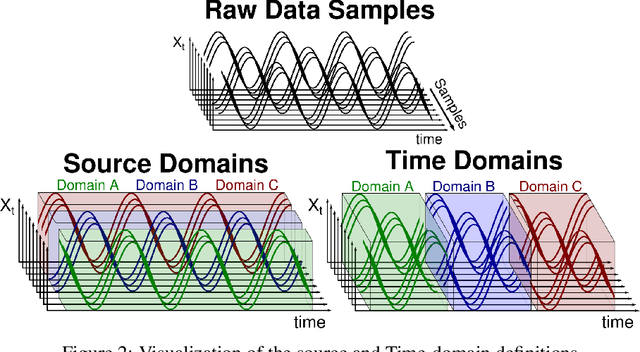

Machine learning models often fail to generalize well under distributional shifts. Understanding and overcoming these failures have led to a research field of Out-of-Distribution (OOD) generalization. Despite being extensively studied for static computer vision tasks, OOD generalization has been underexplored for time series tasks. To shine light on this gap, we present WOODS: eight challenging open-source time series benchmarks covering a diverse range of data modalities, such as videos, brain recordings, and sensor signals. We revise the existing OOD generalization algorithms for time series tasks and evaluate them using our systematic framework. Our experiments show a large room for improvement for empirical risk minimization and OOD generalization algorithms on our datasets, thus underscoring the new challenges posed by time series tasks. Code and documentation are available at https://woods-benchmarks.github.io .
Time Series Data Mining Algorithms Towards Scalable and Real-Time Behavior Monitoring
Dec 26, 2021


In recent years, there have been unprecedented technological advances in sensor technology, and sensors have become more affordable than ever. Thus, sensor-driven data collection is increasingly becoming an attractive and practical option for researchers around the globe. Such data is typically extracted in the form of time series data, which can be investigated with data mining techniques to summarize behaviors of a range of subjects including humans and animals. While enabling cheap and mass collection of data, continuous sensor data recording results in datasets which are big in size and volume, which are challenging to process and analyze with traditional techniques in a timely manner. Such collected sensor data is typically extracted in the form of time series data. There are two main approaches in the literature, namely, shape-based classification and feature-based classification. Shape-based classification determines the best class according to a distance measure. Feature-based classification, on the other hand, measures properties of the time series and finds the best class according to the set of features defined for the time series. In this dissertation, we demonstrate that neither of the two techniques will dominate for some problems, but that some combination of both might be the best. In other words, on a single problem, it might be possible that one of the techniques is better for one subset of the behaviors, and the other technique is better for another subset of behaviors. We introduce a hybrid algorithm to classify behaviors, using both shape and feature measures, in weakly labeled time series data collected from sensors to quantify specific behaviors performed by the subject. We demonstrate that our algorithm can robustly classify real, noisy, and complex datasets, based on a combination of shape and features, and tested our proposed algorithm on real-world datasets.