 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Zero-Shot Motor Health Monitoring by Blind Domain Transition
Dec 12, 2022
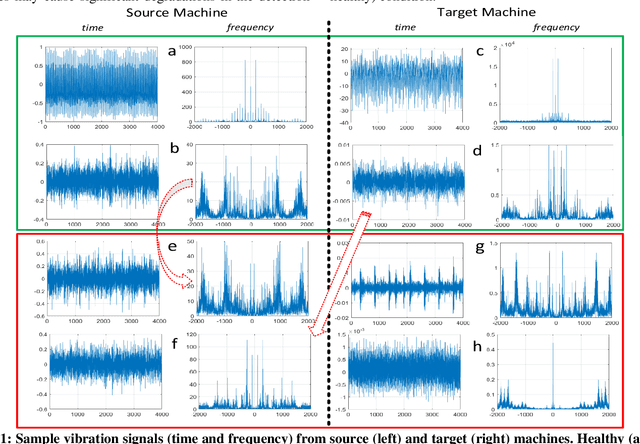
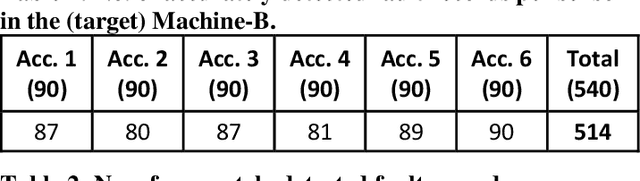
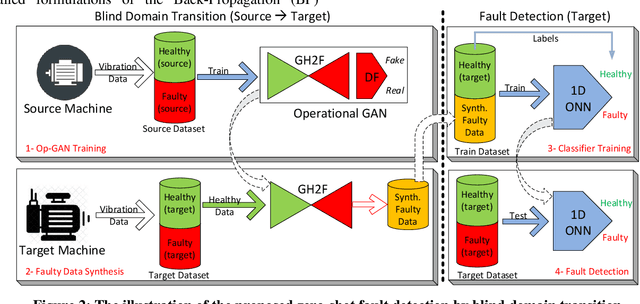

Continuous long-term monitoring of motor health is crucial for the early detection of abnormalities such as bearing faults (up to 51% of motor failures are attributed to bearing faults). Despite numerous methodologies proposed for bearing fault detection, most of them require normal (healthy) and abnormal (faulty) data for training. Even with the recent deep learning (DL) methodologies trained on the labeled data from the same machine, the classification accuracy significantly deteriorates when one or few conditions are altered. Furthermore, their performance suffers significantly or may entirely fail when they are tested on another machine with entirely different healthy and faulty signal patterns. To address this need, in this pilot study, we propose a zero-shot bearing fault detection method that can detect any fault on a new (target) machine regardless of the working conditions, sensor parameters, or fault characteristics. To accomplish this objective, a 1D Operational Generative Adversarial Network (Op-GAN) first characterizes the transition between normal and fault vibration signals of (a) source machine(s) under various conditions, sensor parameters, and fault types. Then for a target machine, the potential faulty signals can be generated, and over its actual healthy and synthesized faulty signals, a compact, and lightweight 1D Self-ONN fault detector can then be trained to detect the real faulty condition in real time whenever it occurs. To validate the proposed approach, a new benchmark dataset is created using two different motors working under different conditions and sensor locations. Experimental results demonstrate that this novel approach can accurately detect any bearing fault achieving an average recall rate of around 89% and 95% on two target machines regardless of its type, severity, and location.
Invariance-Aware Randomized Smoothing Certificates
Nov 25, 2022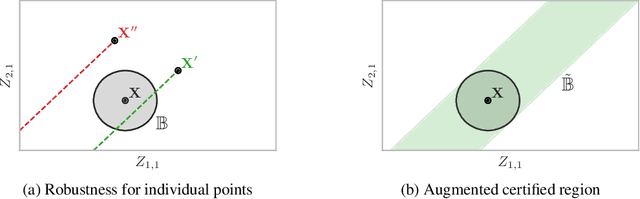
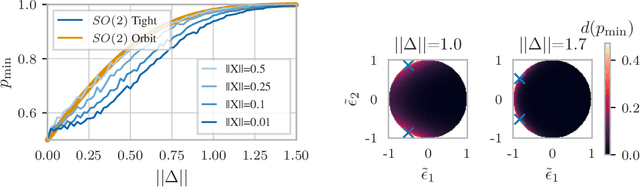
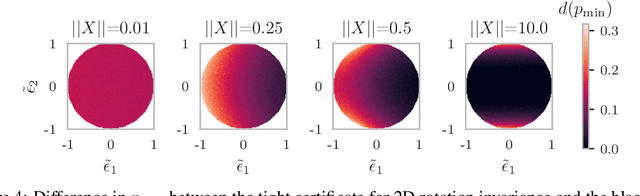
Building models that comply with the invariances inherent to different domains, such as invariance under translation or rotation, is a key aspect of applying machine learning to real world problems like molecular property prediction, medical imaging, protein folding or LiDAR classification. For the first time, we study how the invariances of a model can be leveraged to provably guarantee the robustness of its predictions. We propose a gray-box approach, enhancing the powerful black-box randomized smoothing technique with white-box knowledge about invariances. First, we develop gray-box certificates based on group orbits, which can be applied to arbitrary models with invariance under permutation and Euclidean isometries. Then, we derive provably tight gray-box certificates. We experimentally demonstrate that the provably tight certificates can offer much stronger guarantees, but that in practical scenarios the orbit-based method is a good approximation.
SIMD-size aware weight regularization for fast neural vocoding on CPU
Nov 02, 2022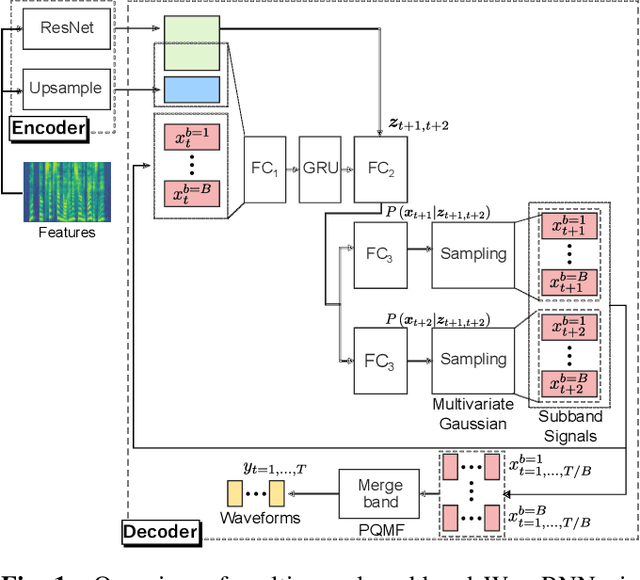
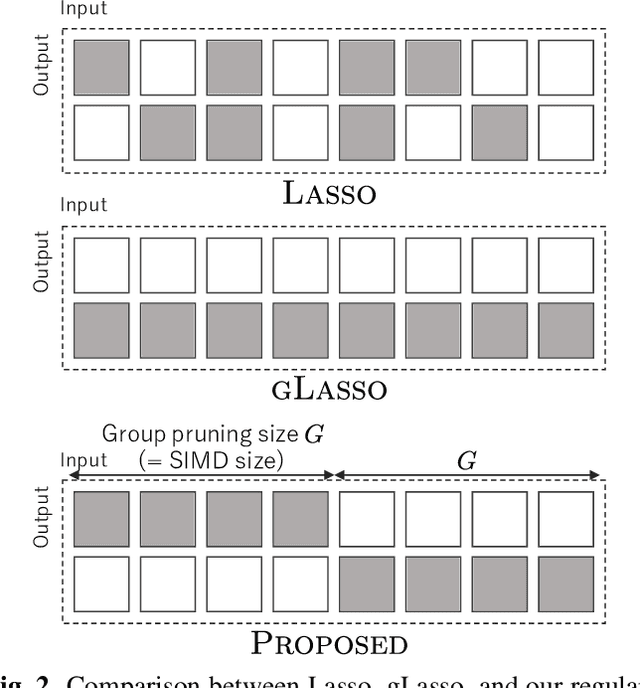
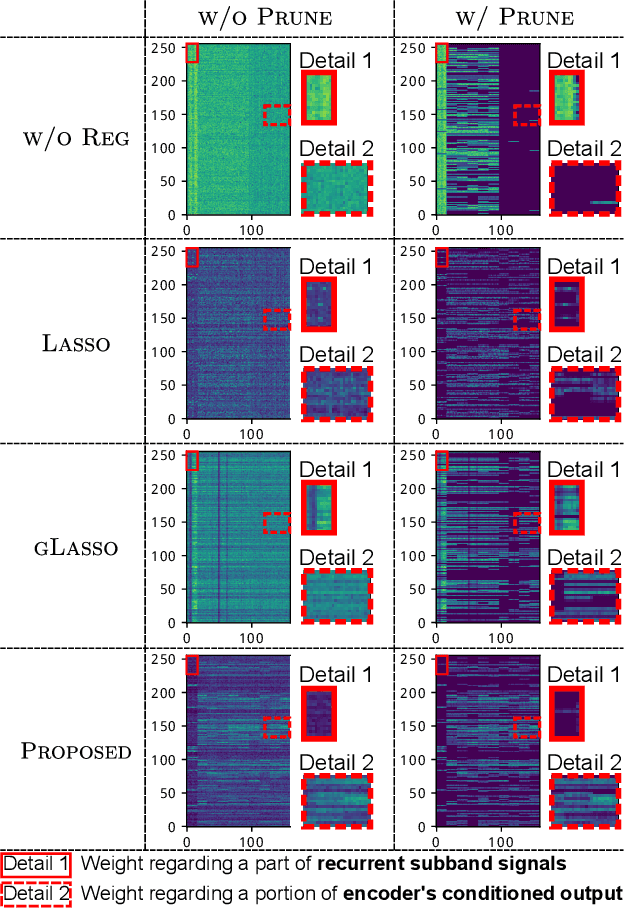
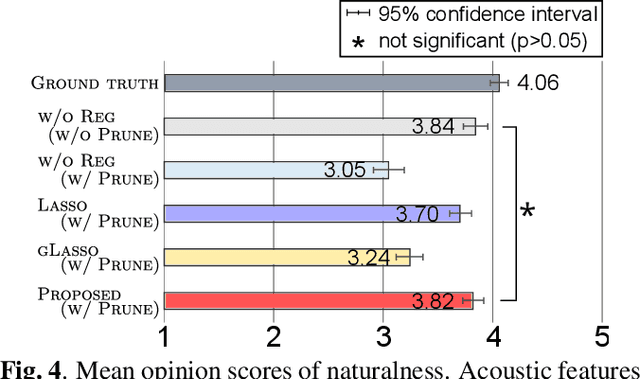
This paper proposes weight regularization for a faster neural vocoder. Pruning time-consuming DNN modules is a promising way to realize a real-time vocoder on a CPU (e.g. WaveRNN, LPCNet). Regularization that encourages sparsity is also effective in avoiding the quality degradation created by pruning. However, the orders of weight matrices must be contiguous in SIMD size for fast vocoding. To ensure this order, we propose explicit SIMD size aware regularization. Our proposed method reshapes a weight matrix into a tensor so that the weights are aligned by group size in advance, and then computes the group Lasso-like regularization loss. Experiments on 70% sparse subband WaveRNN show that pruning in conventional Lasso and column-wise group Lasso degrades the synthetic speech's naturalness. The vocoder with proposed regularization 1) achieves comparable naturalness to that without pruning and 2) performs meaningfully faster than other conventional vocoders using regularization.
Lodestar: An Integrated Embedded Real-Time Control Engine
Mar 01, 2022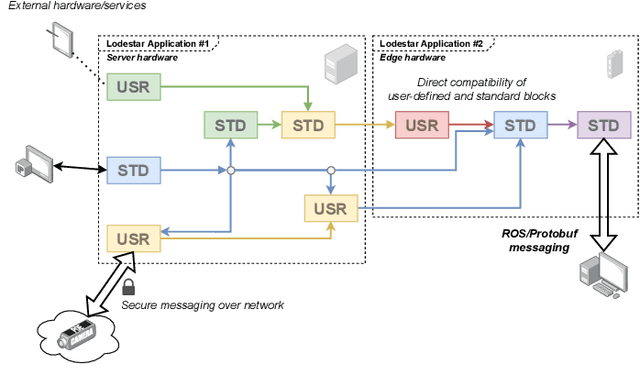
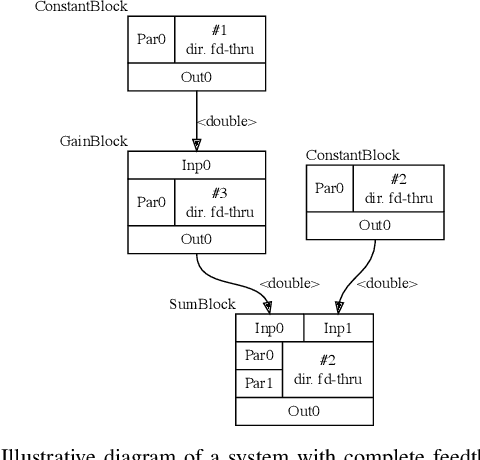
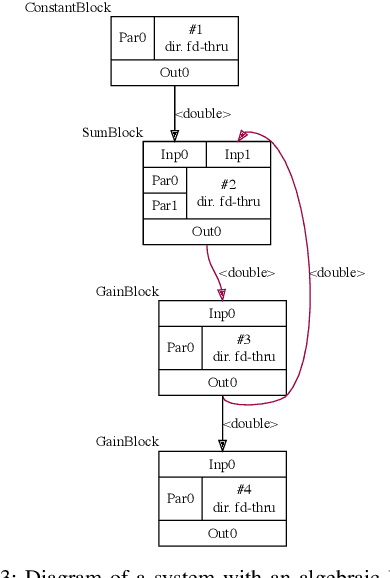

In this work we present Lodestar, an integrated engine for rapid real-time control system development. Using a functional block diagram paradigm, Lodestar allows for complex multi-disciplinary control software design, while automatically resolving execution order, circular data-dependencies, and networking. In particular, Lodestar presents a unified set of control, signal processing, and computer vision routines to users, which may be interfaced with external hardware and software packages using interoperable user-defined wrappers. Lodestar allows for user-defined block diagrams to be directly executed, or for them to be translated to overhead-free source code for integration in other programs. We demonstrate how our framework departs from approaches used in state-of-the-art simulation frameworks to enable real-time performance, and compare its capabilities to existing solutions in the realm of control software. To demonstrate the utility of Lodestar in real-time control systems design, we have applied Lodestar to implement two real-time torque-based controller for a robotic arm. In addition, we have developed a novel autofocus algorithm for use in thermography-based localization and parameter estimation in electrosurgery and other areas of robot-assisted surgery. We compare our algorithm design approach in Lodestar to a classical ground-up approach, showing that Lodestar considerably eases the design process. We also show how Lodestar can seamlessly interface with existing simulation and networking framework in a number of simulation examples.
CATNet: Cross-event Attention-based Time-aware Network for Medical Event Prediction
Apr 29, 2022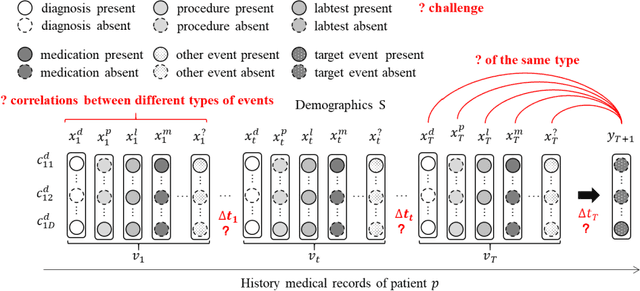

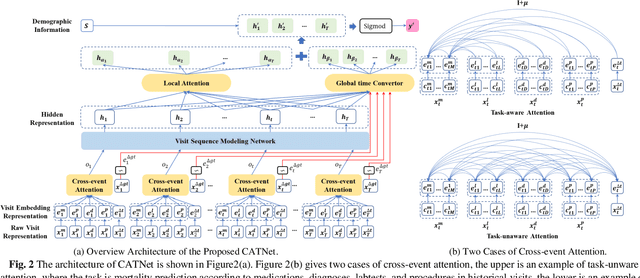
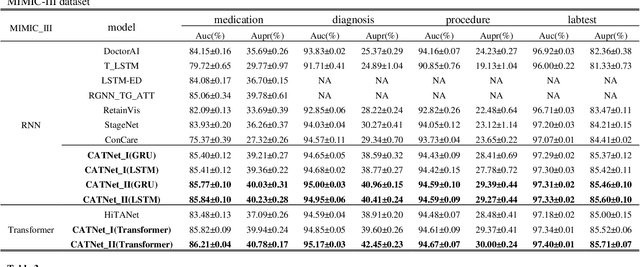
Medical event prediction (MEP) is a fundamental task in the medical domain, which needs to predict medical events, including medications, diagnosis codes, laboratory tests, procedures, outcomes, and so on, according to historical medical records. The task is challenging as medical data is a type of complex time series data with heterogeneous and temporal irregular characteristics. Many machine learning methods that consider the two characteristics have been proposed for medical event prediction. However, most of them consider the two characteristics separately and ignore the correlations among different types of medical events, especially relations between historical medical events and target medical events. In this paper, we propose a novel neural network based on attention mechanism, called cross-event attention-based time-aware network (CATNet), for medical event prediction. It is a time-aware, event-aware and task-adaptive method with the following advantages: 1) modeling heterogeneous information and temporal information in a unified way and considering temporal irregular characteristics locally and globally respectively, 2) taking full advantage of correlations among different types of events via cross-event attention. Experiments on two public datasets (MIMIC-III and eICU) show CATNet can be adaptive with different MEP tasks and outperforms other state-of-the-art methods on various MEP tasks. The source code of CATNet will be released after this manuscript is accepted.
Spatio-Temporal Crop Aggregation for Video Representation Learning
Nov 30, 2022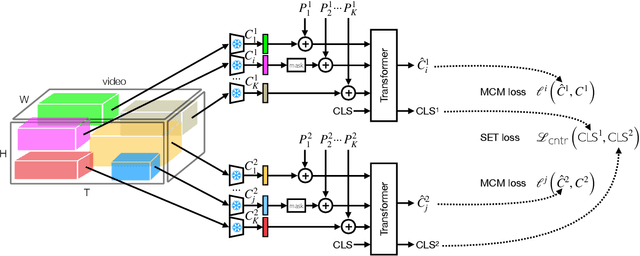
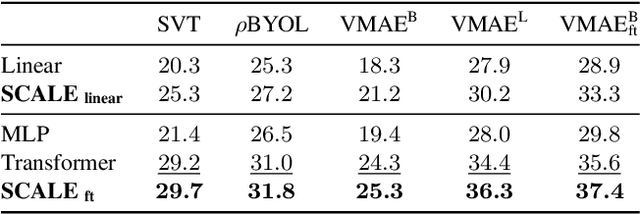
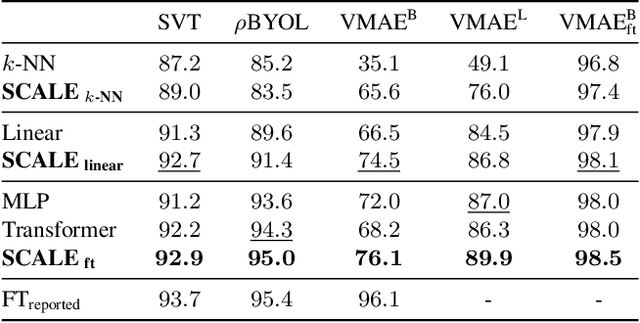
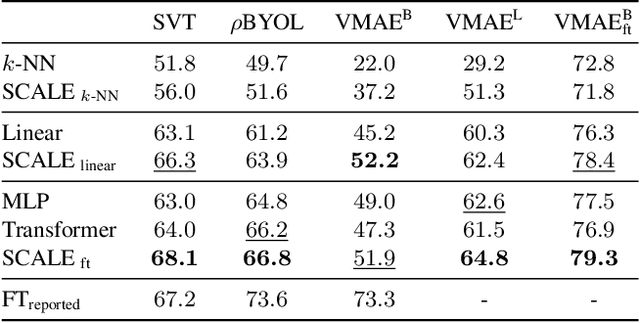
We propose Spatio-temporal Crop Aggregation for video representation LEarning (SCALE), a novel method that enjoys high scalability at both training and inference time. Our model builds long-range video features by learning from sets of video clip-level features extracted with a pre-trained backbone. To train the model, we propose a self-supervised objective consisting of masked clip feature prediction. We apply sparsity to both the input, by extracting a random set of video clips, and to the loss function, by only reconstructing the sparse inputs. Moreover, we use dimensionality reduction by working in the latent space of a pre-trained backbone applied to single video clips. The video representation is then obtained by taking the ensemble of the concatenation of embeddings of separate video clips with a video clip set summarization token. These techniques make our method not only extremely efficient to train, but also highly effective in transfer learning. We demonstrate that our video representation yields state-of-the-art performance with linear, non-linear, and $k$-NN probing on common action classification datasets.
Task-Driven Hybrid Model Reduction for Dexterous Manipulation
Nov 30, 2022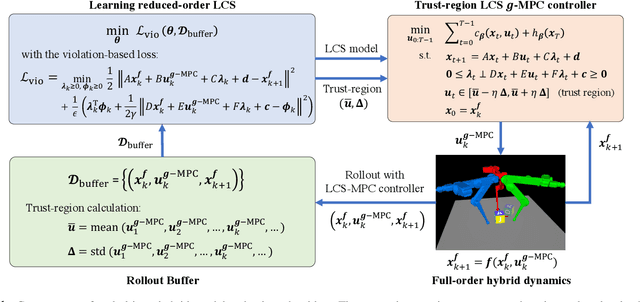
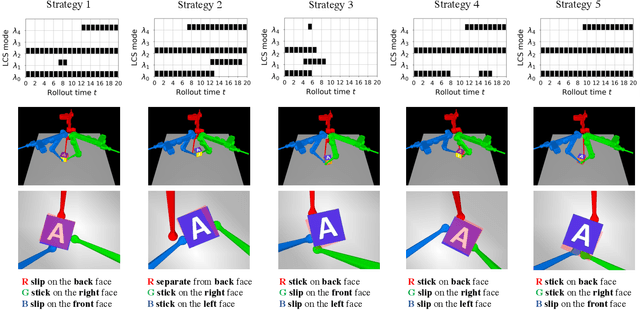
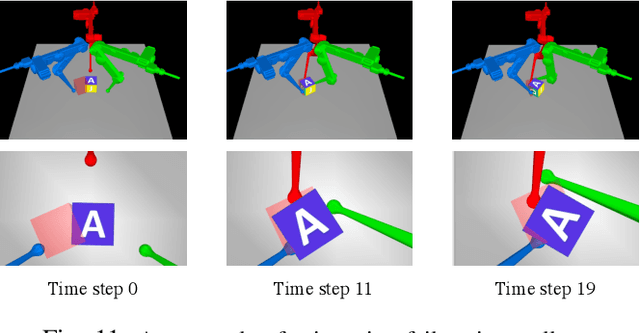
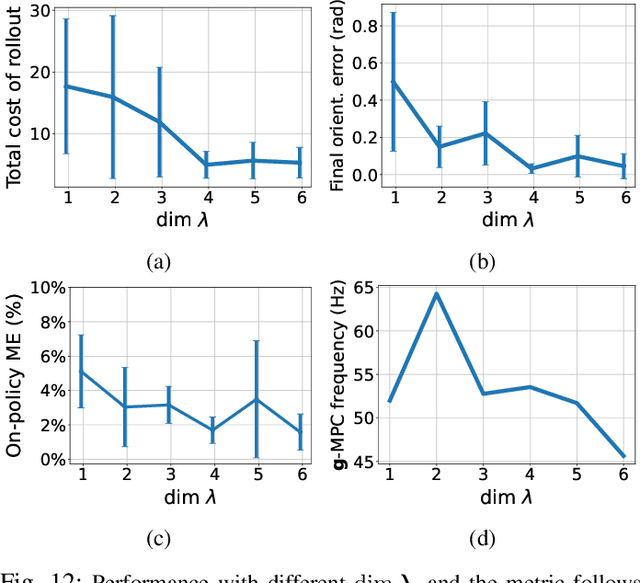
In contact-rich tasks, like dexterous manipulation, the hybrid nature of making and breaking contact creates challenges for model representation and control. For example, choosing and sequencing contact locations for in-hand manipulation, where there are thousands of potential hybrid modes, is not generally tractable. In this paper, we are inspired by the observation that far fewer modes are actually necessary to accomplish many tasks. Building on our prior work learning hybrid models, represented as linear complementarity systems, we find a reduced-order hybrid model requiring only a limited number of task-relevant modes. This simplified representation, in combination with model predictive control, enables real-time control yet is sufficient for achieving high performance. We demonstrate the proposed method first on synthetic hybrid systems, reducing the mode count by multiple orders of magnitude while achieving task performance loss of less than 5%. We also apply the proposed method to a three-fingered robotic hand manipulating a previously unknown object. With no prior knowledge, we achieve state-of-the-art closed-loop performance in less than five minutes of online learning.
VI-PINNs: Variance-involved Physics-informed Neural Networks for Fast and Accurate Prediction of Partial Differential Equations
Nov 30, 2022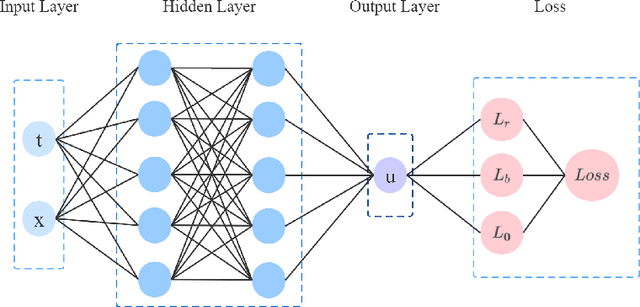

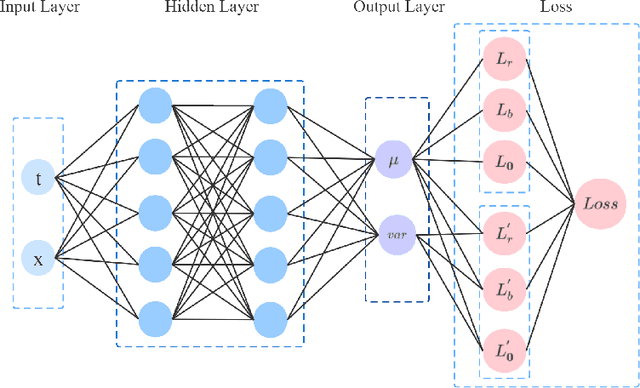
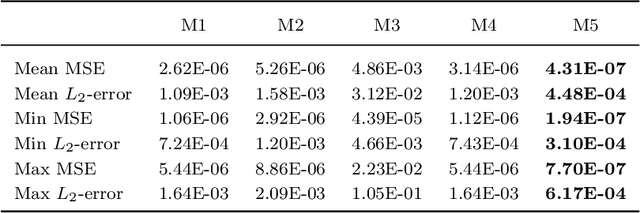
Although physics-informed neural networks(PINNs) have progressed a lot in many real applications recently, there remains problems to be further studied, such as achieving more accurate results, taking less training time, and quantifying the uncertainty of the predicted results. Recent advances in PINNs have indeed significantly improved the performance of PINNs in many aspects, but few have considered the effect of variance in the training process. In this work, we take into consideration the effect of variance and propose our VI-PINNs to give better predictions. We output two values in the final layer of the network to represent the predicted mean and variance respectively, and the latter is used to represent the uncertainty of the output. A modified negative log-likelihood loss and an auxiliary task are introduced for fast and accurate training. We perform several experiments on a wide range of different problems to highlight the advantages of our approach. The results convey that our method not only gives more accurate predictions but also converges faster.
Generalized Deep Learning-based Proximal Gradient Descent for MR Reconstruction
Nov 30, 2022
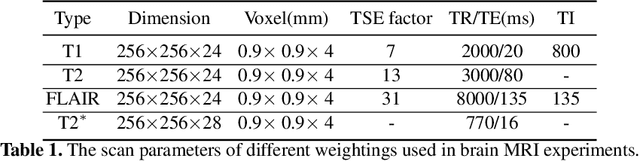
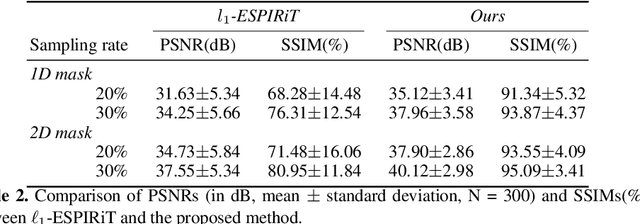
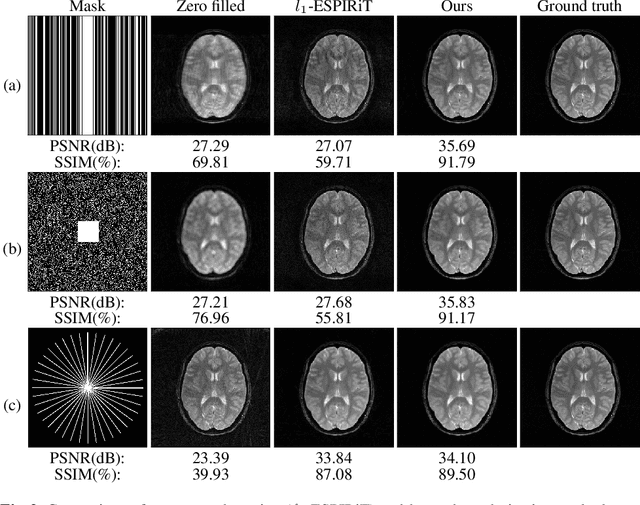
The data consistency for the physical forward model is crucial in inverse problems, especially in MR imaging reconstruction. The standard way is to unroll an iterative algorithm into a neural network with a forward model embedded. The forward model always changes in clinical practice, so the learning component's entanglement with the forward model makes the reconstruction hard to generalize. The proposed method is more generalizable for different MR acquisition settings by separating the forward model from the deep learning component. The deep learning-based proximal gradient descent was proposed to create a learned regularization term independent of the forward model. We applied the one-time trained regularization term to different MR acquisition settings to validate the proposed method and compared the reconstruction with the commonly used $\ell_1$ regularization. We showed ~3 dB improvement in the peak signal to noise ratio, compared with conventional $\ell_1$ regularized reconstruction. We demonstrated the flexibility of the proposed method in choosing different undersampling patterns. We also evaluated the effect of parameter tuning for the deep learning regularization.
Uncertainty-Aware Image Captioning
Nov 30, 2022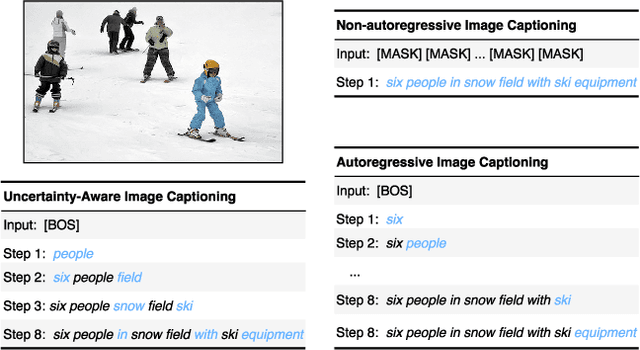
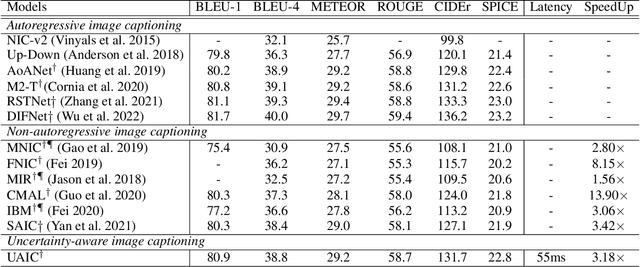
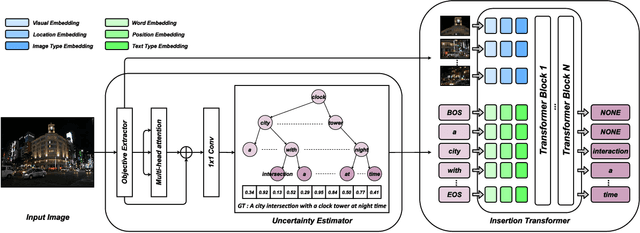
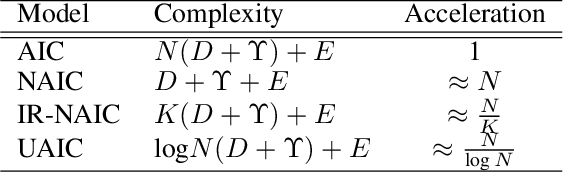
It is well believed that the higher uncertainty in a word of the caption, the more inter-correlated context information is required to determine it. However, current image captioning methods usually consider the generation of all words in a sentence sequentially and equally. In this paper, we propose an uncertainty-aware image captioning framework, which parallelly and iteratively operates insertion of discontinuous candidate words between existing words from easy to difficult until converged. We hypothesize that high-uncertainty words in a sentence need more prior information to make a correct decision and should be produced at a later stage. The resulting non-autoregressive hierarchy makes the caption generation explainable and intuitive. Specifically, we utilize an image-conditioned bag-of-word model to measure the word uncertainty and apply a dynamic programming algorithm to construct the training pairs. During inference, we devise an uncertainty-adaptive parallel beam search technique that yields an empirically logarithmic time complexity. Extensive experiments on the MS COCO benchmark reveal that our approach outperforms the strong baseline and related methods on both captioning quality as well as decoding speed.