 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Taming Hyperparameter Tuning in Continuous Normalizing Flows Using the JKO Scheme
Nov 30, 2022
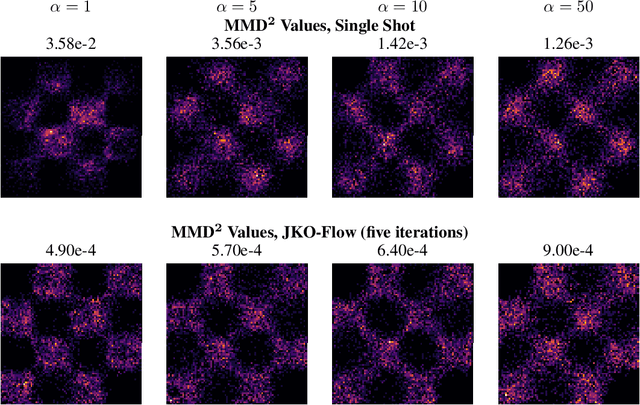
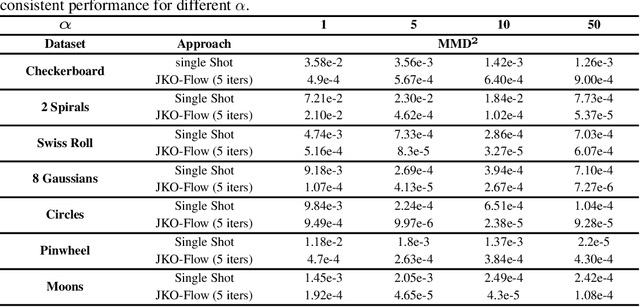

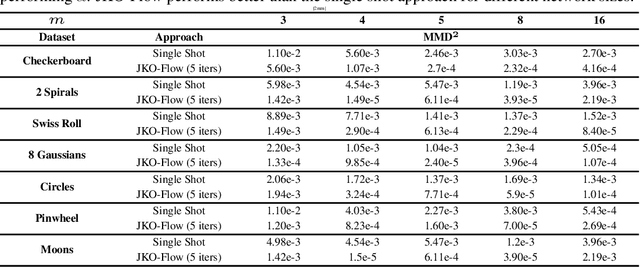
A normalizing flow (NF) is a mapping that transforms a chosen probability distribution to a normal distribution. Such flows are a common technique used for data generation and density estimation in machine learning and data science. The density estimate obtained with a NF requires a change of variables formula that involves the computation of the Jacobian determinant of the NF transformation. In order to tractably compute this determinant, continuous normalizing flows (CNF) estimate the mapping and its Jacobian determinant using a neural ODE. Optimal transport (OT) theory has been successfully used to assist in finding CNFs by formulating them as OT problems with a soft penalty for enforcing the standard normal distribution as a target measure. A drawback of OT-based CNFs is the addition of a hyperparameter, $\alpha$, that controls the strength of the soft penalty and requires significant tuning. We present JKO-Flow, an algorithm to solve OT-based CNF without the need of tuning $\alpha$. This is achieved by integrating the OT CNF framework into a Wasserstein gradient flow framework, also known as the JKO scheme. Instead of tuning $\alpha$, we repeatedly solve the optimization problem for a fixed $\alpha$ effectively performing a JKO update with a time-step $\alpha$. Hence we obtain a "divide and conquer" algorithm by repeatedly solving simpler problems instead of solving a potentially harder problem with large $\alpha$.
Automatic Discovery of Multi-perspective Process Model using Reinforcement Learning
Nov 30, 2022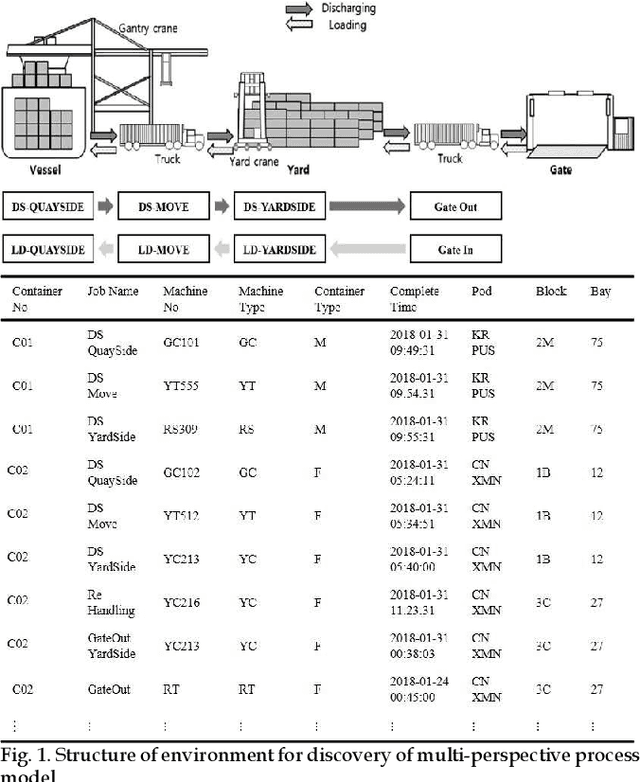
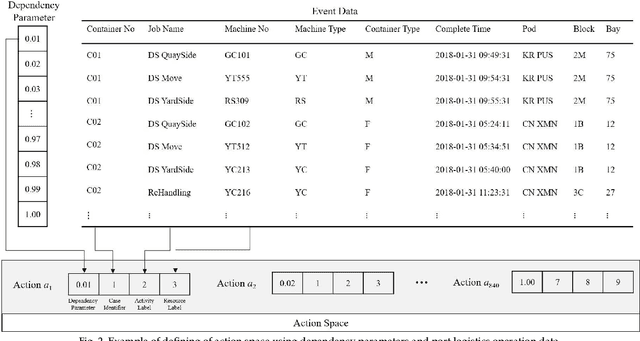
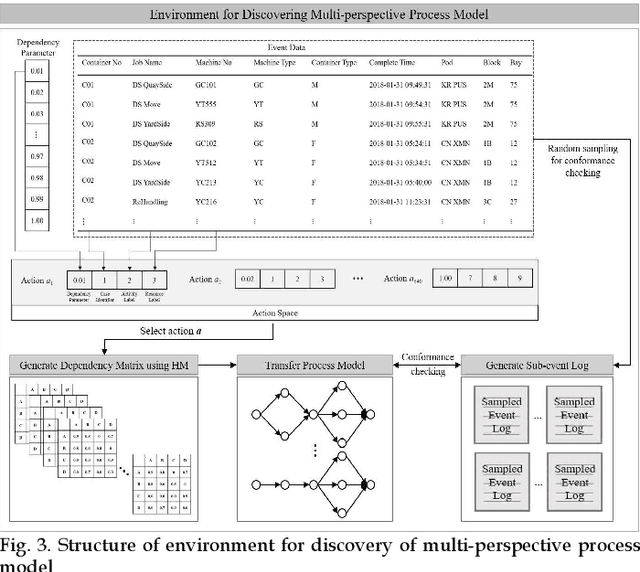
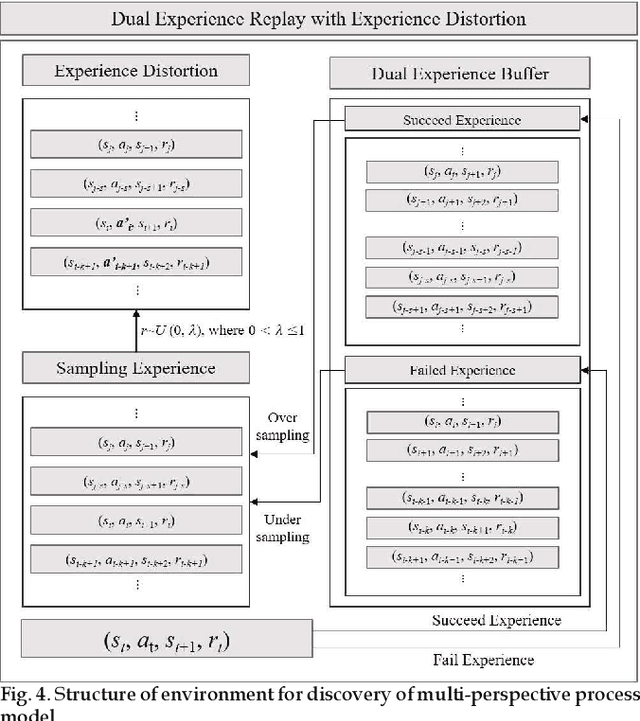
Process mining is a methodology for the derivation and analysis of process models based on the event log. When process mining is employed to analyze business processes, the process discovery step, the conformance checking step, and the enhancements step are repeated. If a user wants to analyze a process from multiple perspectives (such as activity perspectives, originator perspectives, and time perspectives), the above procedure, inconveniently, has to be repeated over and over again. Although past studies involving process mining have applied detailed stepwise methodologies, no attempt has been made to incorporate and optimize multi-perspective process mining procedures. This paper contributes to developing a solution approach to this problem. First, we propose an automatic discovery framework of a multi-perspective process model based on deep Q-Learning. Our Dual Experience Replay with Experience Distribution (DERED) approach can automatically perform process model discovery steps, conformance check steps, and enhancements steps. Second, we propose a new method that further optimizes the experience replay (ER) method, one of the key algorithms of deep Q-learning, to improve the learning performance of reinforcement learning agents. Finally, we validate our approach using six real-world event datasets collected in port logistics, steel manufacturing, finance, IT, and government administration. We show that our DERED approach can provide users with multi-perspective, high-quality process models that can be employed more conveniently for multi-perspective process mining.
How to Train an Accurate and Efficient Object Detection Model on Any Dataset
Nov 30, 2022
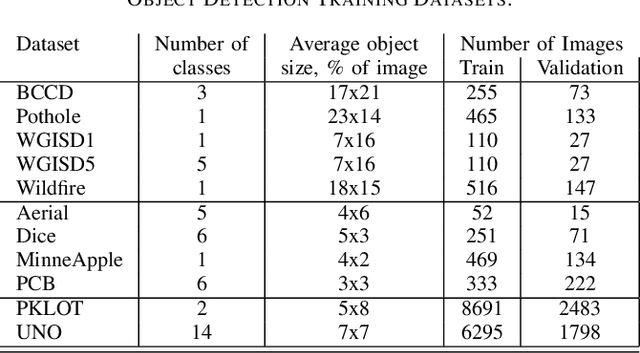
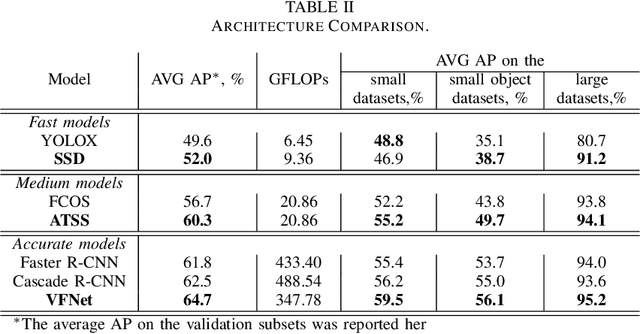
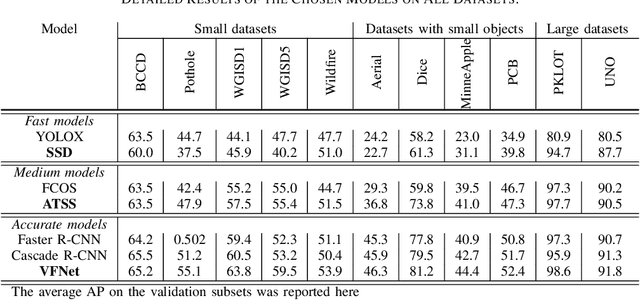
The rapidly evolving industry demands high accuracy of the models without the need for time-consuming and computationally expensive experiments required for fine-tuning. Moreover, a model and training pipeline, which was once carefully optimized for a specific dataset, rarely generalizes well to training on a different dataset. This makes it unrealistic to have carefully fine-tuned models for each use case. To solve this, we propose an alternative approach that also forms a backbone of Intel Geti platform: a dataset-agnostic template for object detection trainings, consisting of carefully chosen and pre-trained models together with a robust training pipeline for further training. Our solution works out-of-the-box and provides a strong baseline on a wide range of datasets. It can be used on its own or as a starting point for further fine-tuning for specific use cases when needed. We obtained dataset-agnostic templates by performing parallel training on a corpus of datasets and optimizing the choice of architectures and training tricks with respect to the average results on the whole corpora. We examined a number of architectures, taking into account the performance-accuracy trade-off. Consequently, we propose 3 finalists, VFNet, ATSS, and SSD, that can be deployed on CPU using the OpenVINO toolkit. The source code is available as a part of the OpenVINO Training Extensions (https://github.com/openvinotoolkit/training_extensions}
Parameter Inference of Time Series by Delay Embeddings and Learning Differentiable Operators
Mar 11, 2022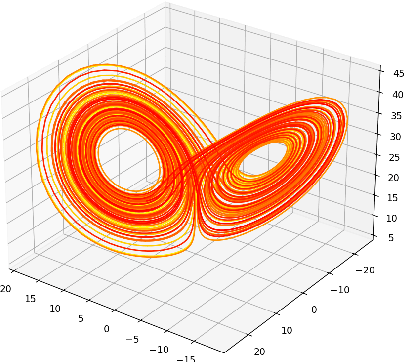
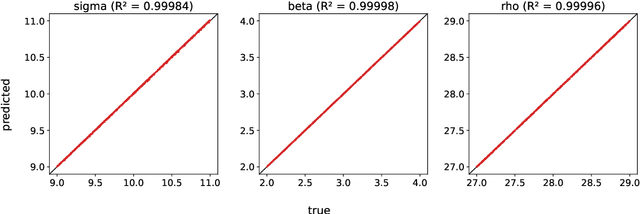
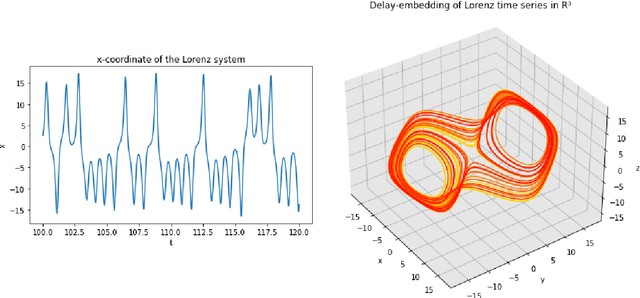
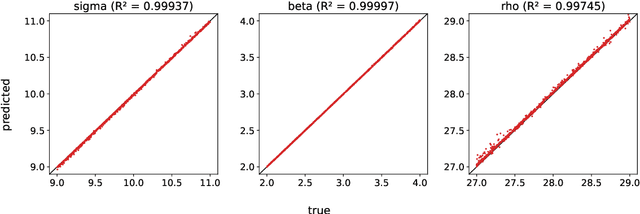
A common issue in dealing with real-world dynamical systems is identifying system parameters responsible for its behavior. A frequent scenario is that one has time series data, along with corresponding parameter labels, but there exists new time series with unknown parameter labels, which one seeks to identify. We tackle this problem by first delay-embedding the time series into a higher dimension to obtain a proper ordinary differential equation (ODE), and then having a neural network learn to predict future time-steps of the trajectory given the present time-step. We then use the learned neural network to backpropagate prediction errors through the parameter inputs of the neural network in order to obtain a gradient in parameter space. Using this gradient, we can approximately identify parameters of time series. We demonstrate the viability of our approach on the chaotic Lorenz system, as well as real-world data with the Hall-effect Thruster (HET).
Pedestrian Spatio-Temporal Information Fusion For Video Anomaly Detection
Nov 28, 2022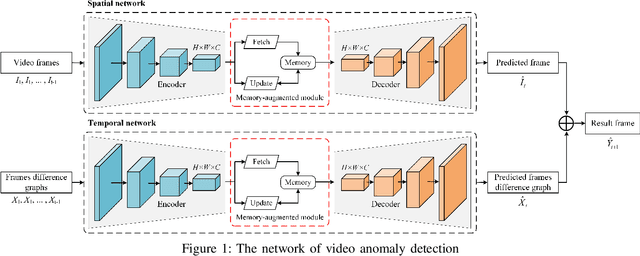
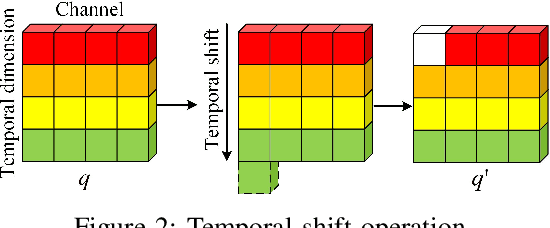
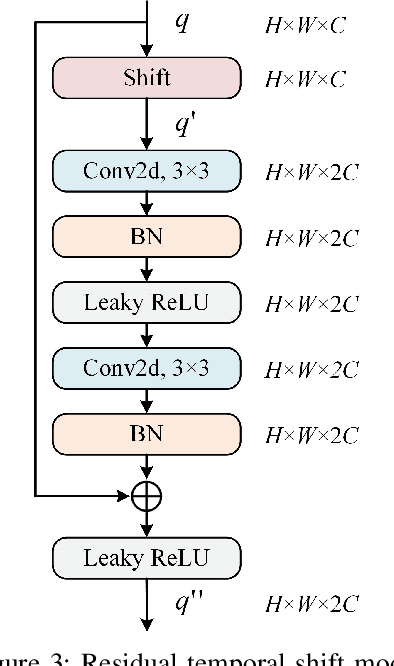
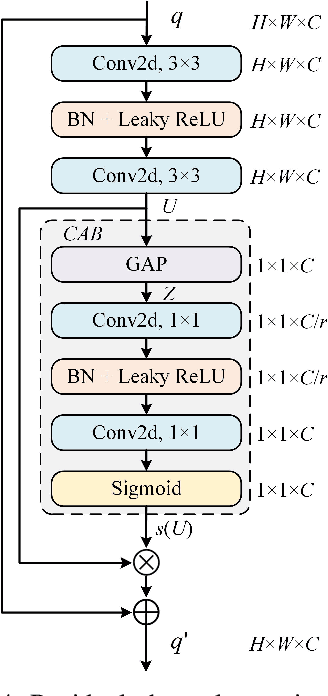
Aiming at the problem that the current video anomaly detection cannot fully use the temporal information and ignore the diversity of normal behavior, an anomaly detection method is proposed to integrate the spatiotemporal information of pedestrians. Based on the convolutional autoencoder, the input frame is compressed and restored through the encoder and decoder. Anomaly detection is realized according to the difference between the output frame and the true value. In order to strengthen the characteristic information connection between continuous video frames, the residual temporal shift module and the residual channel attention module are introduced to improve the modeling ability of the network on temporal information and channel information, respectively. Due to the excessive generalization of convolutional neural networks, in the memory enhancement modules, the hopping connections of each codec layer are added to limit autoencoders' ability to represent abnormal frames too vigorously and improve the anomaly detection accuracy of the network. In addition, the objective function is modified by a feature discretization loss, which effectively distinguishes different normal behavior patterns. The experimental results on the CUHK Avenue and ShanghaiTech datasets show that the proposed method is superior to the current mainstream video anomaly detection methods while meeting the real-time requirements.
* International Conference on Intelligent Media, Big Data and Knowledge Mining
Superpoint Transformer for 3D Scene Instance Segmentation
Nov 28, 2022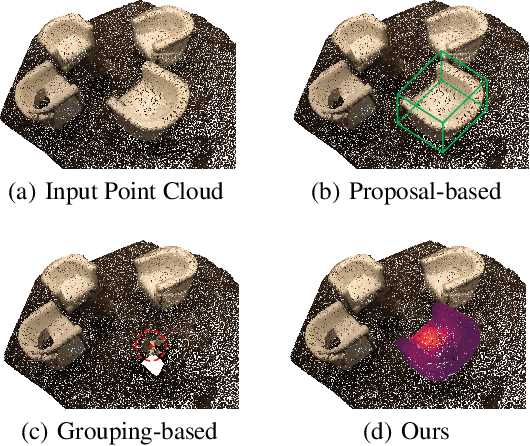
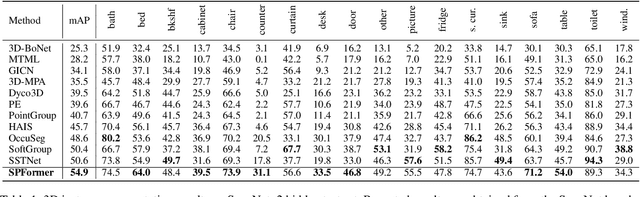
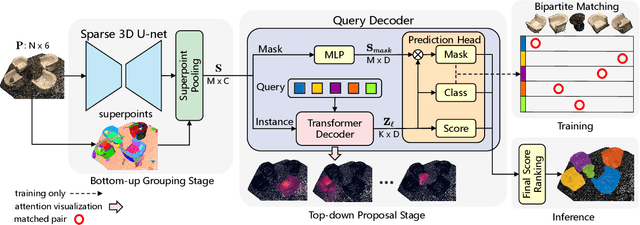
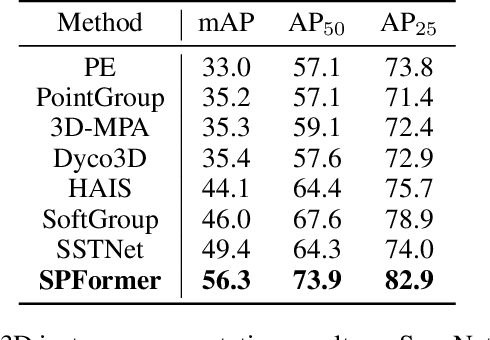
Most existing methods realize 3D instance segmentation by extending those models used for 3D object detection or 3D semantic segmentation. However, these non-straightforward methods suffer from two drawbacks: 1) Imprecise bounding boxes or unsatisfactory semantic predictions limit the performance of the overall 3D instance segmentation framework. 2) Existing method requires a time-consuming intermediate step of aggregation. To address these issues, this paper proposes a novel end-to-end 3D instance segmentation method based on Superpoint Transformer, named as SPFormer. It groups potential features from point clouds into superpoints, and directly predicts instances through query vectors without relying on the results of object detection or semantic segmentation. The key step in this framework is a novel query decoder with transformers that can capture the instance information through the superpoint cross-attention mechanism and generate the superpoint masks of the instances. Through bipartite matching based on superpoint masks, SPFormer can implement the network training without the intermediate aggregation step, which accelerates the network. Extensive experiments on ScanNetv2 and S3DIS benchmarks verify that our method is concise yet efficient. Notably, SPFormer exceeds compared state-of-the-art methods by 4.3% on ScanNetv2 hidden test set in terms of mAP and keeps fast inference speed (247ms per frame) simultaneously. Code is available at https://github.com/sunjiahao1999/SPFormer.
Satlas: A Large-Scale, Multi-Task Dataset for Remote Sensing Image Understanding
Nov 28, 2022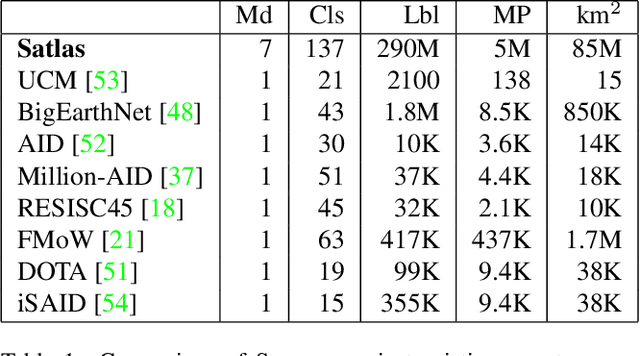

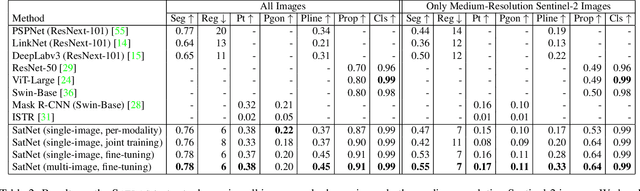
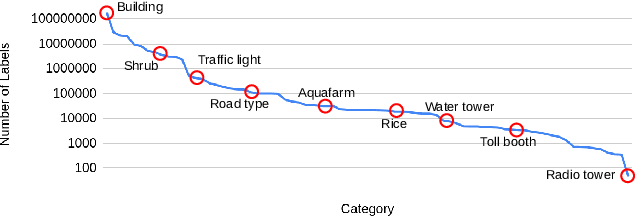
Remote sensing images are useful for a wide variety of environmental and earth monitoring tasks, including tracking deforestation, illegal fishing, urban expansion, and natural disasters. The earth is extremely diverse -- the amount of potential tasks in remote sensing images is massive, and the sizes of features range from several kilometers to just tens of centimeters. However, creating generalizable computer vision methods is a challenge in part due to the lack of a large-scale dataset that captures these diverse features for many tasks. In this paper, we present Satlas, a remote sensing dataset and benchmark that is large in both breadth, featuring all of the aforementioned applications and more, as well as scale, comprising 290M labels under 137 categories and seven label modalities. We evaluate eight baselines and a proposed method on Satlas, and find that there is substantial room for improvement in addressing research challenges specific to remote sensing, including processing image time series that consist of images from very different types of sensors, and taking advantage of long-range spatial context. We also find that pre-training on Satlas substantially improves performance on downstream tasks with few labeled examples, increasing average accuracy by 16% over ImageNet and 5% over the next best baseline.
DGI: Easy and Efficient Inference for GNNs
Nov 28, 2022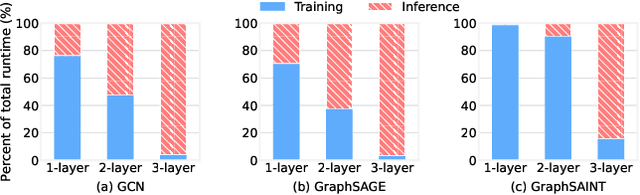
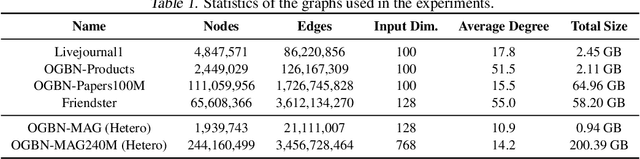
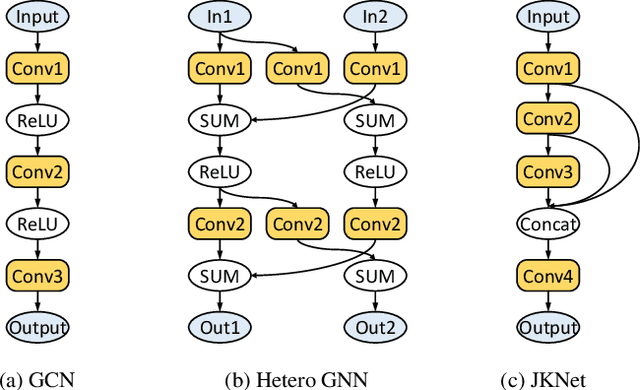
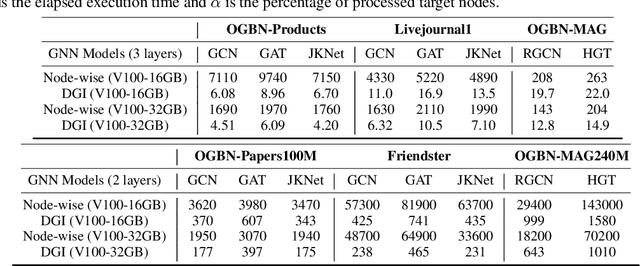
While many systems have been developed to train Graph Neural Networks (GNNs), efficient model inference and evaluation remain to be addressed. For instance, using the widely adopted node-wise approach, model evaluation can account for up to 94% of the time in the end-to-end training process due to neighbor explosion, which means that a node accesses its multi-hop neighbors. On the other hand, layer-wise inference avoids the neighbor explosion problem by conducting inference layer by layer such that the nodes only need their one-hop neighbors in each layer. However, implementing layer-wise inference requires substantial engineering efforts because users need to manually decompose a GNN model into layers for computation and split workload into batches to fit into device memory. In this paper, we develop Deep Graph Inference (DGI) -- a system for easy and efficient GNN model inference, which automatically translates the training code of a GNN model for layer-wise execution. DGI is general for various GNN models and different kinds of inference requests, and supports out-of-core execution on large graphs that cannot fit in CPU memory. Experimental results show that DGI consistently outperforms layer-wise inference across different datasets and hardware settings, and the speedup can be over 1,000x.
FsaNet: Frequency Self-attention for Semantic Segmentation
Nov 28, 2022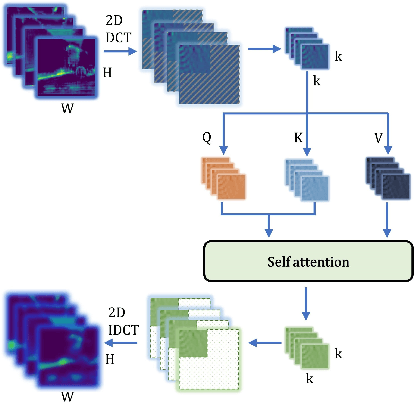
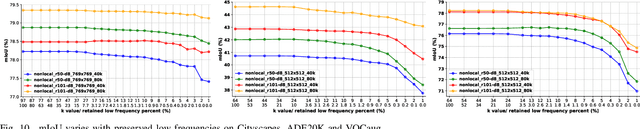
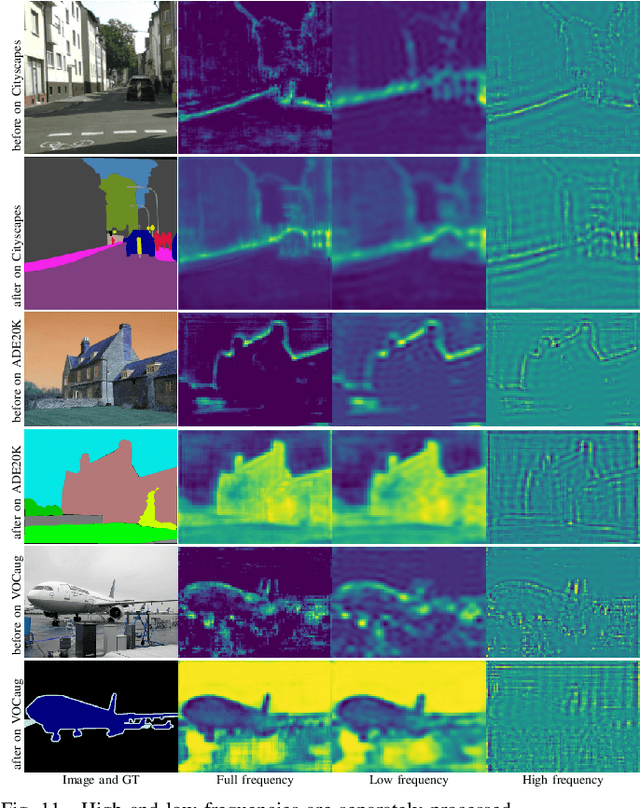

Considering the spectral properties of images, we propose a new self-attention mechanism with highly reduced computational complexity, up to a linear rate. To better preserve edges while promoting similarity within objects, we propose individualized processes over different frequency bands. In particular, we study a case where the process is merely over low-frequency components. By ablation study, we show that low frequency self-attention can achieve very close or better performance relative to full frequency even without retraining the network. Accordingly, we design and embed novel plug-and-play modules to the head of a CNN network that we refer to as FsaNet. The frequency self-attention 1) takes low frequency coefficients as input, 2) can be mathematically equivalent to spatial domain self-attention with linear structures, 3) simplifies token mapping ($1\times1$ convolution) stage and token mixing stage simultaneously. We show that the frequency self-attention requires $87.29\% \sim 90.04\%$ less memory, $96.13\% \sim 98.07\%$ less FLOPs, and $97.56\% \sim 98.18\%$ in run time than the regular self-attention. Compared to other ResNet101-based self-attention networks, FsaNet achieves a new state-of-the-art result ($83.0\%$ mIoU) on Cityscape test dataset and competitive results on ADE20k and VOCaug.
On the Effective Usage of Priors in RSS-based Localization
Nov 28, 2022
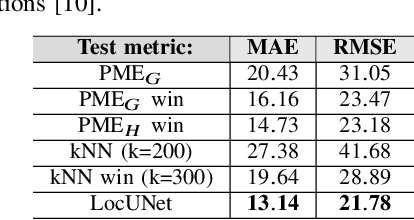
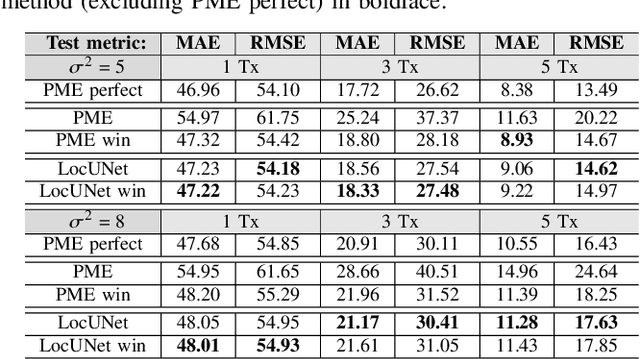
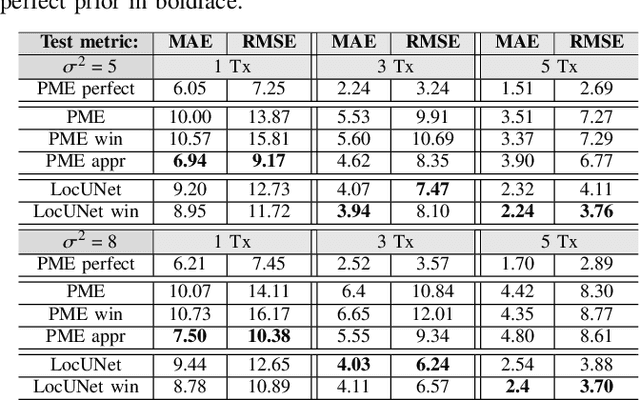
In this paper, we study the localization problem in dense urban settings. In such environments, Global Navigation Satellite Systems fail to provide good accuracy due to low likelihood of line-of-sight (LOS) links between the receiver (Rx) to be located and the satellites, due to the presence of obstacles like the buildings. Thus, one has to resort to other technologies, which can reliably operate under non-line-of-sight (NLOS) conditions. Recently, we proposed a Received Signal Strength (RSS) fingerprint and convolutional neural network-based algorithm, LocUNet, and demonstrated its state-of-the-art localization performance with respect to the widely adopted k-nearest neighbors (kNN) algorithm, and to state-of-the-art time of arrival (ToA) ranging-based methods. In the current work, we first recognize LocUNet's ability to learn the underlying prior distribution of the Rx position or Rx and transmitter (Tx) association preferences from the training data, and attribute its high performance to these. Conversely, we demonstrate that classical methods based on probabilistic approach, can greatly benefit from an appropriate incorporation of such prior information. Our studies also numerically prove LocUNet's close to optimal performance in many settings, by comparing it with the theoretically optimal formulations.