 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Embracing AWKWARD! Real-time Adjustment of Reactive Plans Using Social Norms
Apr 26, 2022
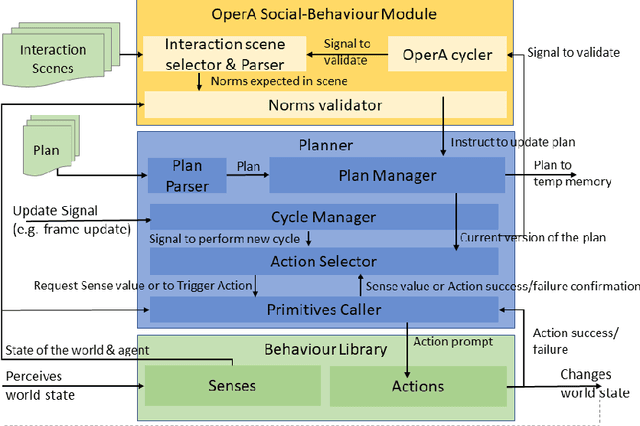


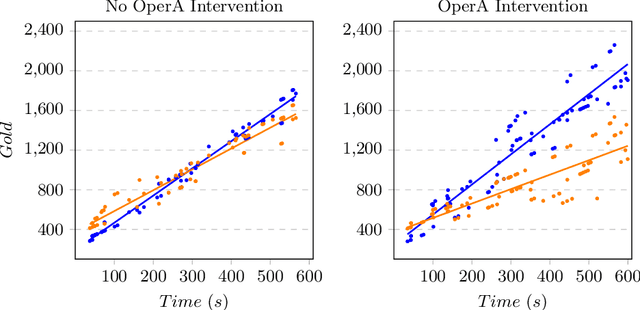
This paper presents the AWKWARD agent architecture for the development of agents in Multi-Agent Systems. AWKWARD agents can have their plans re-configured in real time to align with social role requirements under changing environmental and social circumstances. The proposed hybrid architecture makes use of Behaviour Oriented Design (BOD) to develop agents with reactive planning and of the well-established OperA framework to provide organisational, social, and interaction definitions in order to validate and adjust agents' behaviours. Together, OperA and BOD can achieve real-time adjustment of agent plans for evolving social roles, while providing the additional benefit of transparency into the interactions that drive this behavioural change in individual agents. We present this architecture to motivate the bridging between traditional symbolic- and behaviour-based AI communities, where such combined solutions can help MAS researchers in their pursuit of building stronger, more robust intelligent agent teams. We use DOTA2, a game where success is heavily dependent on social interactions, as a medium to demonstrate a sample implementation of our proposed hybrid architecture.
Time-triggered Federated Learning over Wireless Networks
Apr 26, 2022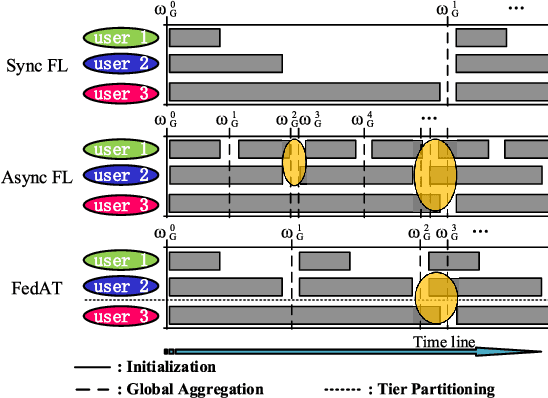
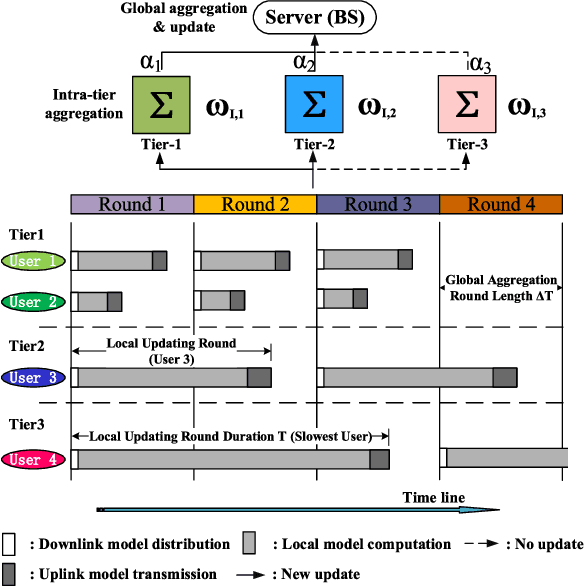
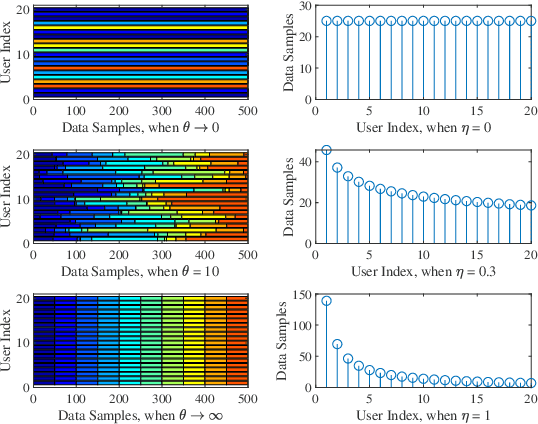
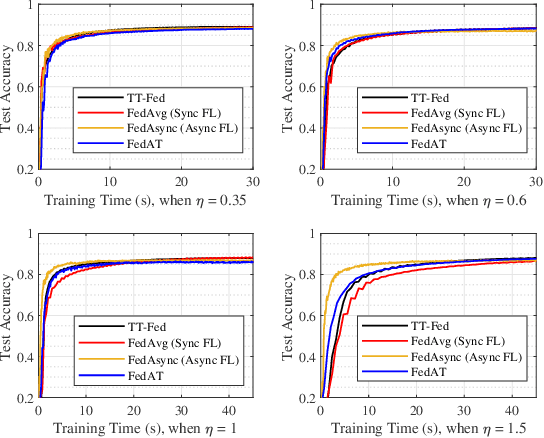
The newly emerging federated learning (FL) framework offers a new way to train machine learning models in a privacy-preserving manner. However, traditional FL algorithms are based on an event-triggered aggregation, which suffers from stragglers and communication overhead issues. To address these issues, in this paper, we present a time-triggered FL algorithm (TT-Fed) over wireless networks, which is a generalized form of classic synchronous and asynchronous FL. Taking the constrained resource and unreliable nature of wireless communication into account, we jointly study the user selection and bandwidth optimization problem to minimize the FL training loss. To solve this joint optimization problem, we provide a thorough convergence analysis for TT-Fed. Based on the obtained analytical convergence upper bound, the optimization problem is decomposed into tractable sub-problems with respect to each global aggregation round, and finally solved by our proposed online search algorithm. Simulation results show that compared to asynchronous FL (FedAsync) and FL with asynchronous user tiers (FedAT) benchmarks, our proposed TT-Fed algorithm improves the converged test accuracy by up to 12.5% and 5%, respectively, under highly imbalanced and non-IID data, while substantially reducing the communication overhead.
$\textit{FastSVD-ML-ROM}$: A Reduced-Order Modeling Framework based on Machine Learning for Real-Time Applications
Jul 24, 2022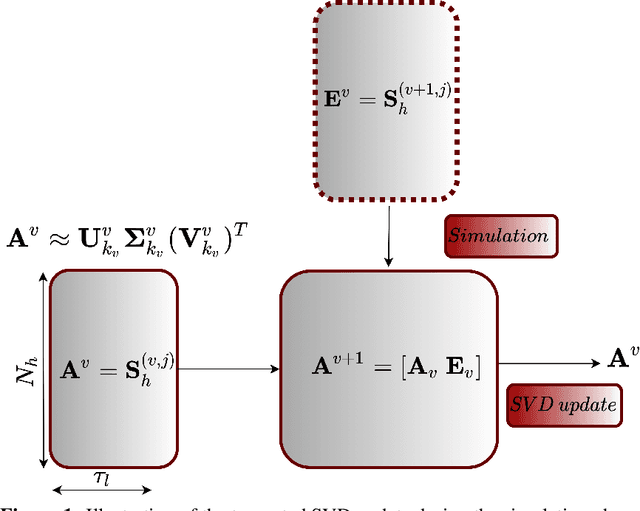
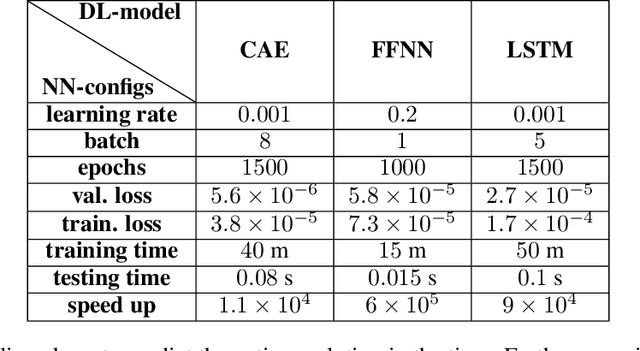
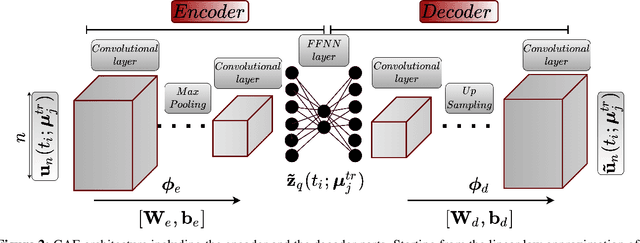
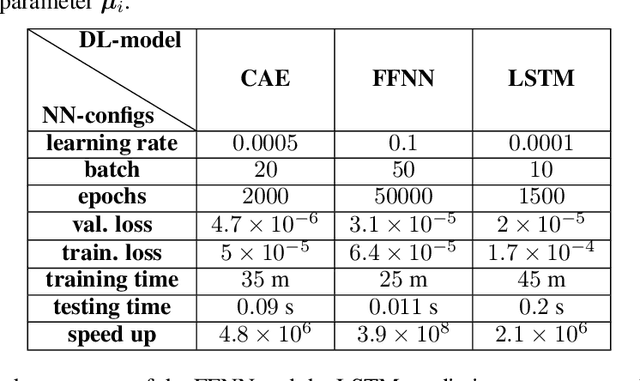
Digital twins have emerged as a key technology for optimizing the performance of engineering products and systems. High-fidelity numerical simulations constitute the backbone of engineering design, providing an accurate insight into the performance of complex systems. However, large-scale, dynamic, non-linear models require significant computational resources and are prohibitive for real-time digital twin applications. To this end, reduced order models (ROMs) are employed, to approximate the high-fidelity solutions while accurately capturing the dominant aspects of the physical behavior. The present work proposes a new machine learning (ML) platform for the development of ROMs, to handle large-scale numerical problems dealing with transient nonlinear partial differential equations. Our framework, mentioned as $\textit{FastSVD-ML-ROM}$, utilizes $\textit{(i)}$ a singular value decomposition (SVD) update methodology, to compute a linear subspace of the multi-fidelity solutions during the simulation process, $\textit{(ii)}$ convolutional autoencoders for nonlinear dimensionality reduction, $\textit{(iii)}$ feed-forward neural networks to map the input parameters to the latent spaces, and $\textit{(iv)}$ long short-term memory networks to predict and forecast the dynamics of parametric solutions. The efficiency of the $\textit{FastSVD-ML-ROM}$ framework is demonstrated for a 2D linear convection-diffusion equation, the problem of fluid around a cylinder, and the 3D blood flow inside an arterial segment. The accuracy of the reconstructed results demonstrates the robustness and assesses the efficiency of the proposed approach.
UmeTrack: Unified multi-view end-to-end hand tracking for VR
Oct 31, 2022
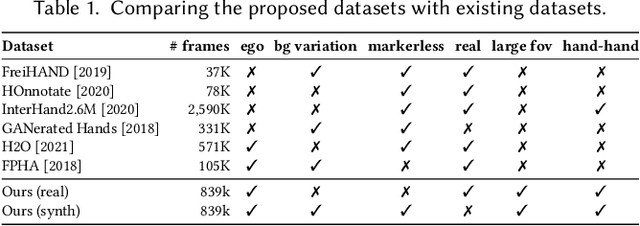
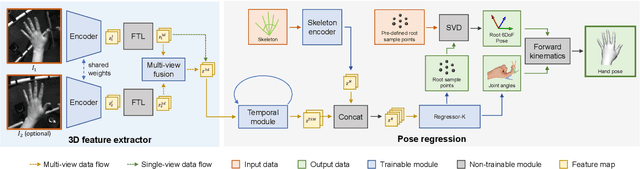
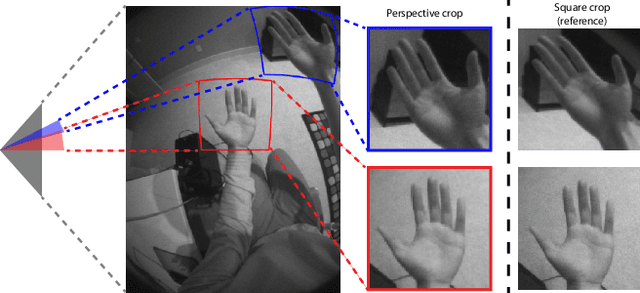
Real-time tracking of 3D hand pose in world space is a challenging problem and plays an important role in VR interaction. Existing work in this space are limited to either producing root-relative (versus world space) 3D pose or rely on multiple stages such as generating heatmaps and kinematic optimization to obtain 3D pose. Moreover, the typical VR scenario, which involves multi-view tracking from wide \ac{fov} cameras is seldom addressed by these methods. In this paper, we present a unified end-to-end differentiable framework for multi-view, multi-frame hand tracking that directly predicts 3D hand pose in world space. We demonstrate the benefits of end-to-end differentiabilty by extending our framework with downstream tasks such as jitter reduction and pinch prediction. To demonstrate the efficacy of our model, we further present a new large-scale egocentric hand pose dataset that consists of both real and synthetic data. Experiments show that our system trained on this dataset handles various challenging interactive motions, and has been successfully applied to real-time VR applications.
Collaboration with Cellular Networks for RFI Cancellation at Radio Telescope
Oct 31, 2022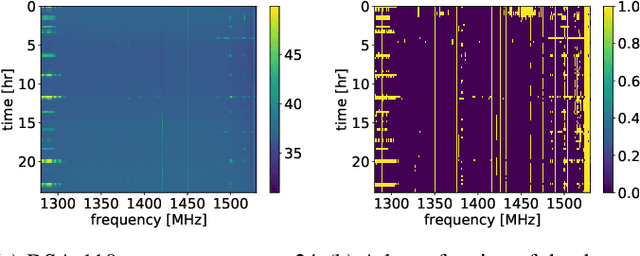
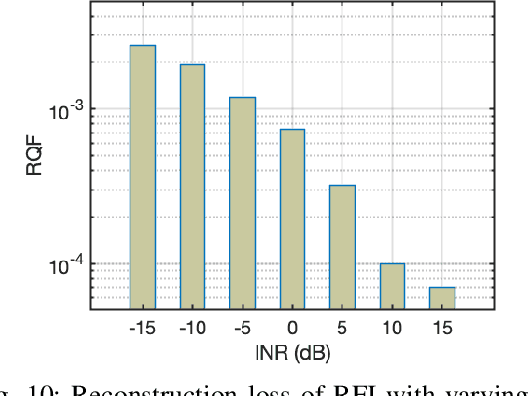
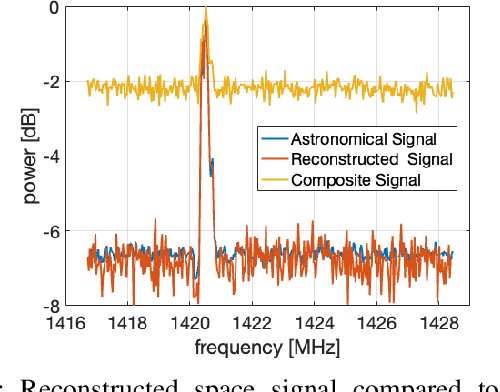
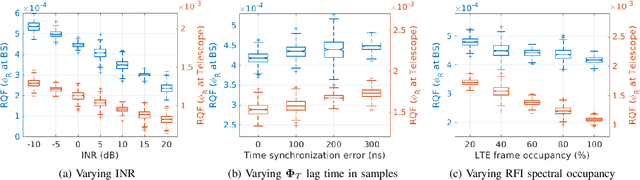
The growing need for electromagnetic spectrum to support the next generation (xG) communication networks increasingly generate unwanted radio frequency interference (RFI) in protected bands for radio astronomy. RFI is commonly mitigated at the Radio Telescope without any active collaboration with the interfering sources. In this work, we provide a method of signal characterization and its use in subsequent cancellation, that uses Eigenspaces derived from the telescope and the transmitter signals. This is different from conventional time-frequency domain analysis, which is limited to fixed characterizations (e.g., complex exponential in Fourier methods) that cannot adapt to the changing statistics (e.g., autocorrelation) of the RFI, typically observed in communication systems. We have presented effectiveness of this collaborative method using real-world astronomical signals and practical simulated LTE signals (downlink and uplink) as source of RFI along with propagation conditions based on preset benchmarks and standards. Through our analysis and simulation using these signals, we are able to remove 89.04% of the RFI from cellular networks, which reduces excision at the Telescope and capable of significantly improving throughput as corrupted time frequency bins data becomes usable.
Fast and parallel decoding for transducer
Oct 31, 2022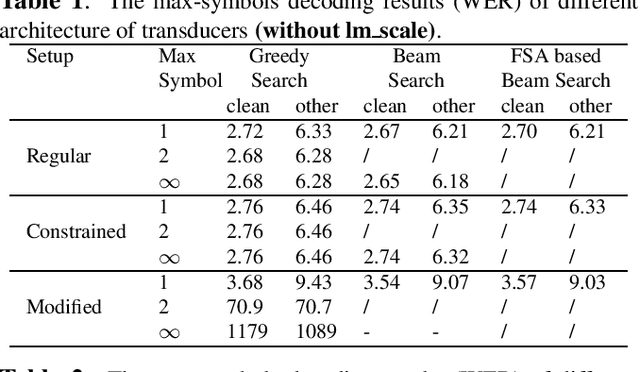
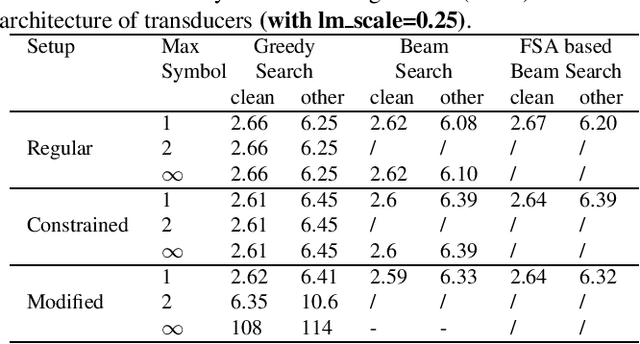
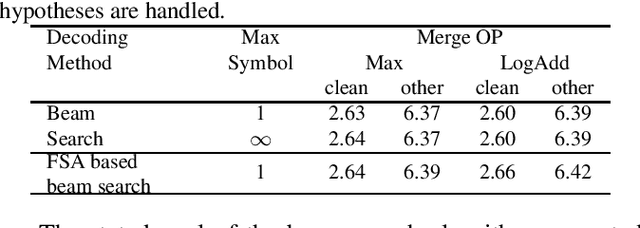
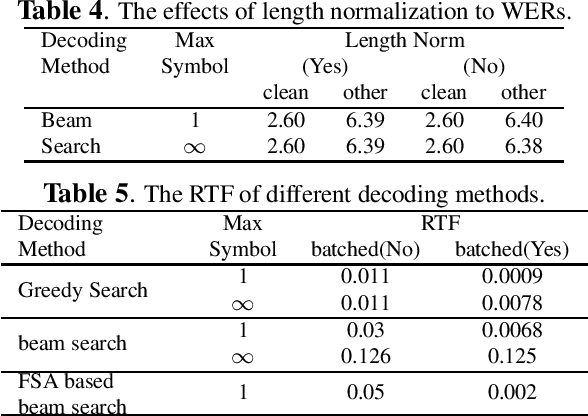
The transducer architecture is becoming increasingly popular in the field of speech recognition, because it is naturally streaming as well as high in accuracy. One of the drawbacks of transducer is that it is difficult to decode in a fast and parallel way due to an unconstrained number of symbols that can be emitted per time step. In this work, we introduce a constrained version of transducer loss to learn strictly monotonic alignments between the sequences; we also improve the standard greedy search and beam search algorithms by limiting the number of symbols that can be emitted per time step in transducer decoding, making it more efficient to decode in parallel with batches. Furthermore, we propose an finite state automaton-based (FSA) parallel beam search algorithm that can run with graphs on GPU efficiently. The experiment results show that we achieve slight word error rate (WER) improvement as well as significant speedup in decoding. Our work is open-sourced and publicly available\footnote{https://github.com/k2-fsa/icefall}.
Compressing Explicit Voxel Grid Representations: fast NeRFs become also small
Oct 23, 2022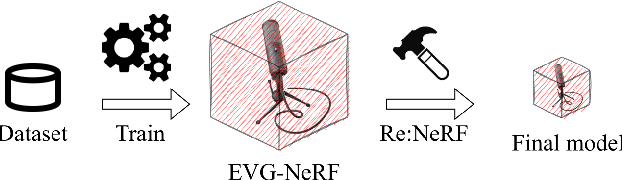

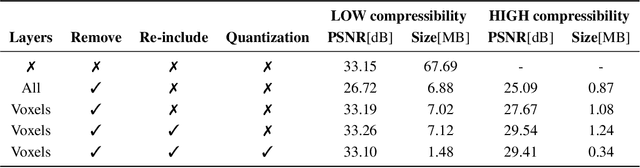
NeRFs have revolutionized the world of per-scene radiance field reconstruction because of their intrinsic compactness. One of the main limitations of NeRFs is their slow rendering speed, both at training and inference time. Recent research focuses on the optimization of an explicit voxel grid (EVG) that represents the scene, which can be paired with neural networks to learn radiance fields. This approach significantly enhances the speed both at train and inference time, but at the cost of large memory occupation. In this work we propose Re:NeRF, an approach that specifically targets EVG-NeRFs compressibility, aiming to reduce memory storage of NeRF models while maintaining comparable performance. We benchmark our approach with three different EVG-NeRF architectures on four popular benchmarks, showing Re:NeRF's broad usability and effectiveness.
Single-domain Generalization in Medical Image Segmentation via Test-time Adaptation from Shape Dictionary
Jun 29, 2022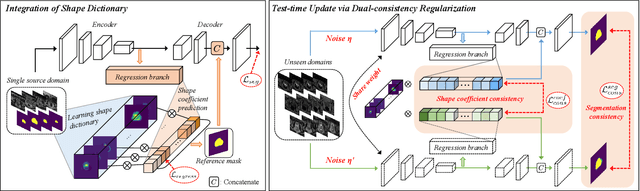
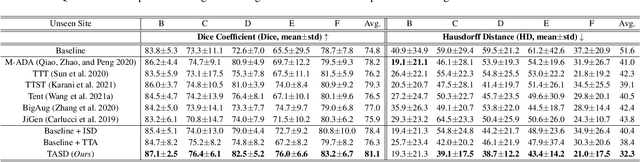

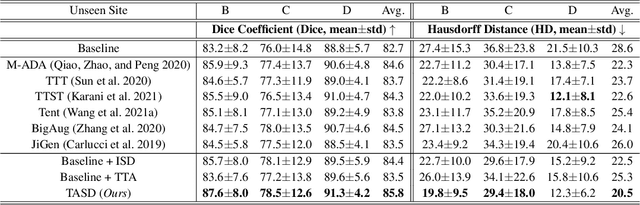
Domain generalization typically requires data from multiple source domains for model learning. However, such strong assumption may not always hold in practice, especially in medical field where the data sharing is highly concerned and sometimes prohibitive due to privacy issue. This paper studies the important yet challenging single domain generalization problem, in which a model is learned under the worst-case scenario with only one source domain to directly generalize to different unseen target domains. We present a novel approach to address this problem in medical image segmentation, which extracts and integrates the semantic shape prior information of segmentation that are invariant across domains and can be well-captured even from single domain data to facilitate segmentation under distribution shifts. Besides, a test-time adaptation strategy with dual-consistency regularization is further devised to promote dynamic incorporation of these shape priors under each unseen domain to improve model generalizability. Extensive experiments on two medical image segmentation tasks demonstrate the consistent improvements of our method across various unseen domains, as well as its superiority over state-of-the-art approaches in addressing domain generalization under the worst-case scenario.
TACTiS: Transformer-Attentional Copulas for Time Series
Feb 07, 2022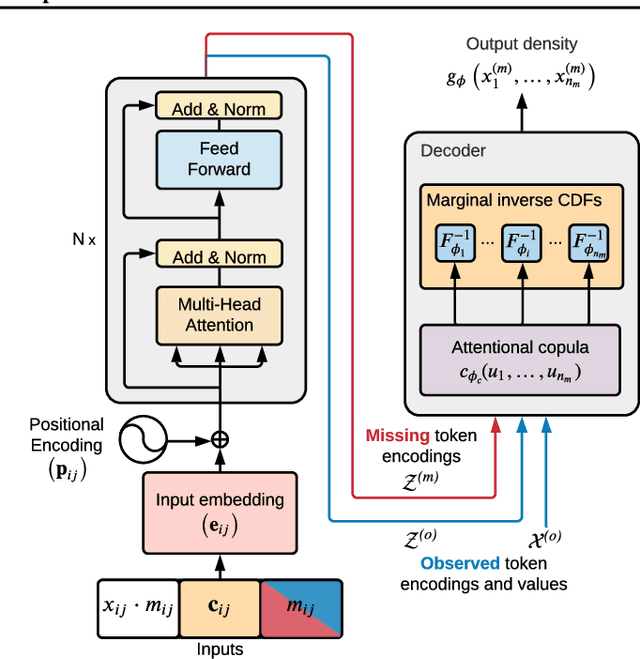
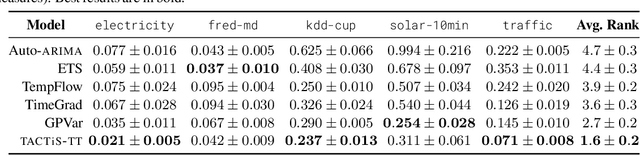
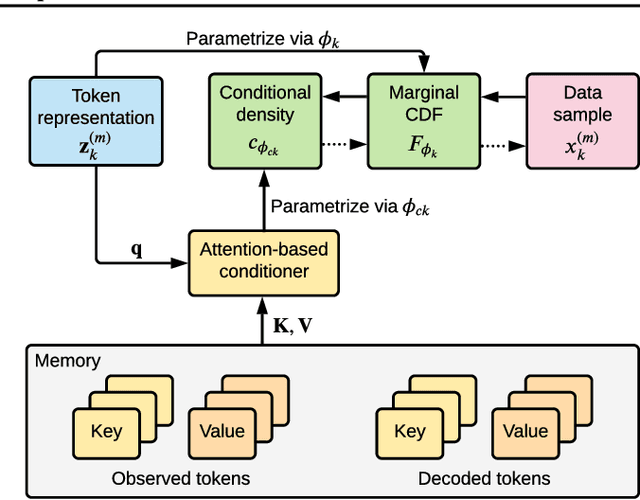
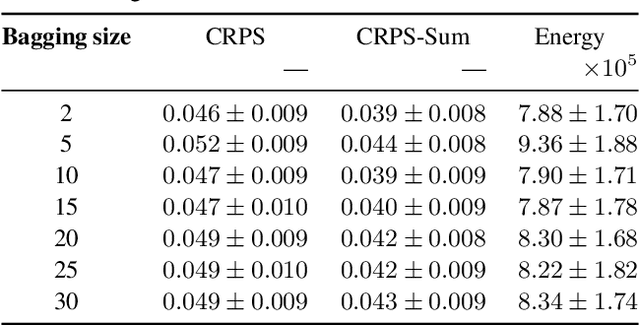
The estimation of time-varying quantities is a fundamental component of decision making in fields such as healthcare and finance. However, the practical utility of such estimates is limited by how accurately they quantify predictive uncertainty. In this work, we address the problem of estimating the joint predictive distribution of high-dimensional multivariate time series. We propose a versatile method, based on the transformer architecture, that estimates joint distributions using an attention-based decoder that provably learns to mimic the properties of non-parametric copulas. The resulting model has several desirable properties: it can scale to hundreds of time series, supports both forecasting and interpolation, can handle unaligned and non-uniformly sampled data, and can seamlessly adapt to missing data during training. We demonstrate these properties empirically and show that our model produces state-of-the-art predictions on several real-world datasets.
Deep learning methods for automatic classification of medical images and disease detection based on chest X-Ray images
Nov 14, 2022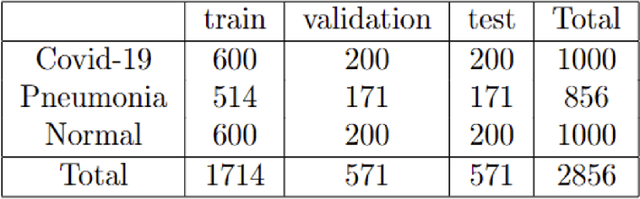
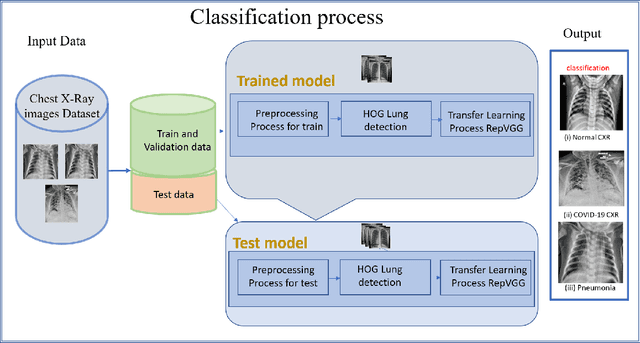
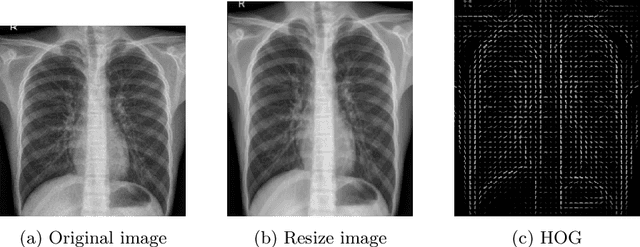
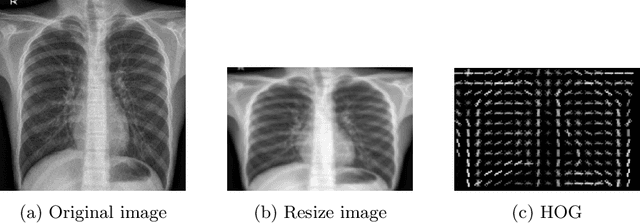
Detecting and classifying diseases using X-Ray images is one of the more challenging core tasks in the medical and research world. Innovations and revolutions of Computer Vision with Deep learning methods offer great promise for fast and accurate diagnosis of screening and detection from chest X-Ray images (CXR). This work presents rapid detection of diseases in the lung using the efficient Deep learning pre-trained RepVGG algorithm for deep feature extraction and classification. We performed automatic classification of X-Ray images into three categories as Covid-19, Pneumonia, and Normal X-Ray cases. For evaluation, first, we used a histogram-oriented gradient (HOG) to detect the shape of the region of interest (ROI). We used the ROI object to improve the detection accuracy for lung extraction, followed by data pre-processing and augmentation. Then a pre-trained RepVGG model is used for deep feature extraction and classification, similar to VGG and ResNet convolutional neural network for the training-time and inference-time architecture transformed from the multi to the flat mode by a structural re-parameterization technique. Next, using the Computer Vision technique, we created a feature map and superimposed it on the original images. We used this technique for the automatic highlighted detection of affected areas of people's lungs. Based on the X-Ray images, we developed an algorithm that classifies X-Ray images with height accuracy and power faster thanks to the architecture transformation of the model. We compare deep learning frameworks' accuracy and detection of disease. The study shows the high power of deep learning methods for X-Ray images based on COVID-19 detection utilizing chest X-Ray. The proposed framework shows better diagnostic accuracy by comparing popular deep learning models, i.e., VGG, ResNet50, inceptionV3, DenseNet, and InceptionResnetV2.