 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Benchmarking multi-component signal processing methods in the time-frequency plane
Feb 13, 2024
Signal processing in the time-frequency plane has a long history and remains a field of methodological innovation. For instance, detection and denoising based on the zeros of the spectrogram have been proposed since 2015, contrasting with a long history of focusing on larger values of the spectrogram. Yet, unlike neighboring fields like optimization and machine learning, time-frequency signal processing lacks widely-adopted benchmarking tools. In this work, we contribute an open-source, Python-based toolbox termed MCSM-Benchs for benchmarking multi-component signal analysis methods, and we demonstrate our toolbox on three time-frequency benchmarks. First, we compare different methods for signal detection based on the zeros of the spectrogram, including unexplored variations of previously proposed detection tests. Second, we compare zero-based denoising methods to both classical and novel methods based on large values and ridges of the spectrogram. Finally, we compare the denoising performance of these methods against typical spectrogram thresholding strategies, in terms of post-processing artifacts commonly referred to as musical noise. At a low level, the obtained results provide new insight on the assessed approaches, and in particular research directions to further develop zero-based methods. At a higher level, our benchmarks exemplify the benefits of using a public, collaborative, common framework for benchmarking.
Improved LiDAR Odometry and Mapping using Deep Semantic Segmentation and Novel Outliers Detection
Mar 05, 2024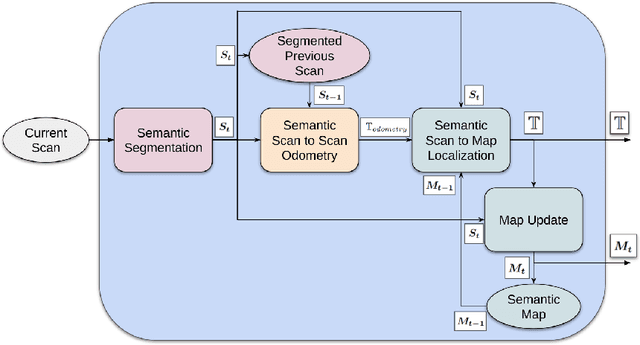

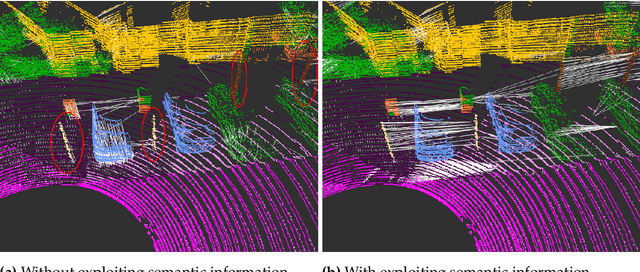

Perception is a key element for enabling intelligent autonomous navigation. Understanding the semantics of the surrounding environment and accurate vehicle pose estimation are essential capabilities for autonomous vehicles, including self-driving cars and mobile robots that perform complex tasks. Fast moving platforms like self-driving cars impose a hard challenge for localization and mapping algorithms. In this work, we propose a novel framework for real-time LiDAR odometry and mapping based on LOAM architecture for fast moving platforms. Our framework utilizes semantic information produced by a deep learning model to improve point-to-line and point-to-plane matching between LiDAR scans and build a semantic map of the environment, leading to more accurate motion estimation using LiDAR data. We observe that including semantic information in the matching process introduces a new type of outlier matches to the process, where matching occur between different objects of the same semantic class. To this end, we propose a novel algorithm that explicitly identifies and discards potential outliers in the matching process. In our experiments, we study the effect of improving the matching process on the robustness of LiDAR odometry against high speed motion. Our experimental evaluations on KITTI dataset demonstrate that utilizing semantic information and rejecting outliers significantly enhance the robustness of LiDAR odometry and mapping when there are large gaps between scan acquisition poses, which is typical for fast moving platforms.
PPS-QMIX: Periodically Parameter Sharing for Accelerating Convergence of Multi-Agent Reinforcement Learning
Mar 05, 2024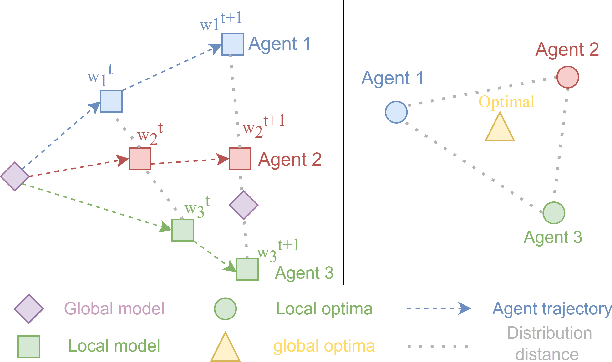

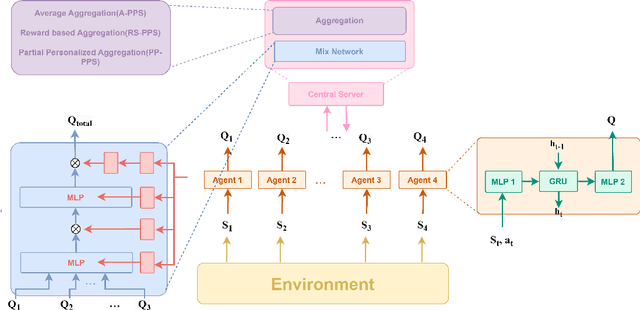
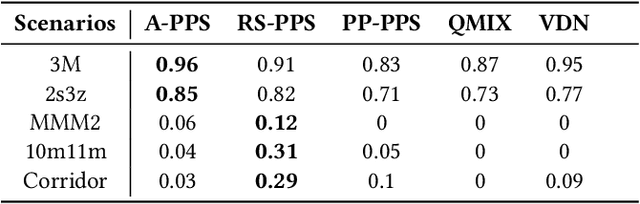
Training for multi-agent reinforcement learning(MARL) is a time-consuming process caused by distribution shift of each agent. One drawback is that strategy of each agent in MARL is independent but actually in cooperation. Thus, a vertical issue in multi-agent reinforcement learning is how to efficiently accelerate training process. To address this problem, current research has leveraged a centralized function(CF) across multiple agents to learn contribution of the team reward for each agent. However, CF based methods introduce joint error from other agents in estimation of value network. In so doing, inspired by federated learning, we propose three simple novel approaches called Average Periodically Parameter Sharing(A-PPS), Reward-Scalability Periodically Parameter Sharing(RS-PPS) and Partial Personalized Periodically Parameter Sharing(PP-PPS) mechanism to accelerate training of MARL. Agents share Q-value network periodically during the training process. Agents which has same identity adapt collected reward as scalability and update partial neural network during period to share different parameters. We apply our approaches in classical MARL method QMIX and evaluate our approaches on various tasks in StarCraft Multi-Agent Challenge(SMAC) environment. Performance of numerical experiments yield enormous enhancement, with an average improvement of 10\%-30\%, and enable to win tasks that QMIX cannot. Our code can be downloaded from https://github.com/ColaZhang22/PPS-QMIX
Feint in Multi-Player Games
Mar 04, 2024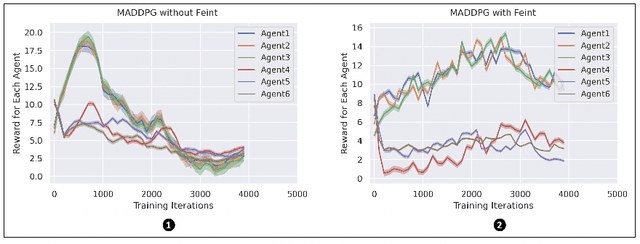
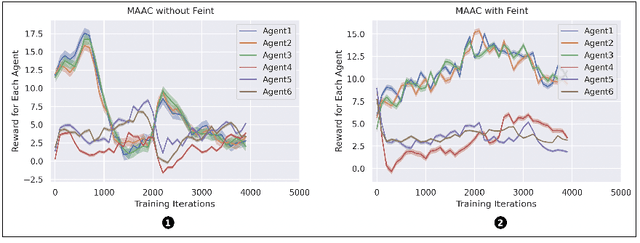
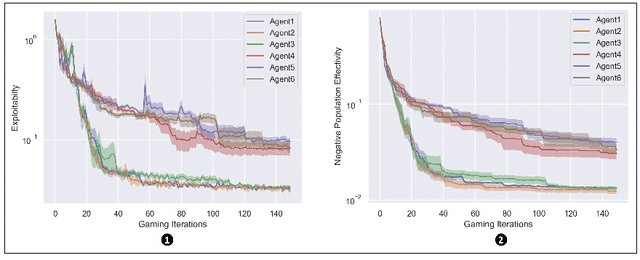
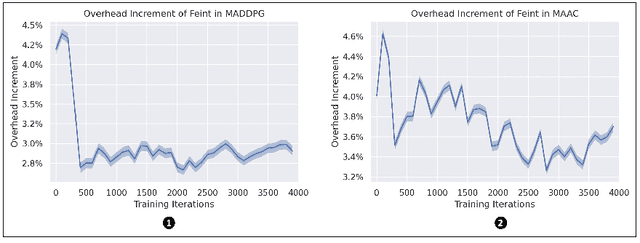
This paper introduces the first formalization, implementation and quantitative evaluation of Feint in Multi-Player Games. Our work first formalizes Feint from the perspective of Multi-Player Games, in terms of the temporal, spatial, and their collective impacts. The formalization is built upon Non-transitive Active Markov Game Model, where Feint can have a considerable amount of impacts. Then, our work considers practical implementation details of Feint in Multi-Player Games, under the state-of-the-art progress of multi-agent modeling to date (namely Multi-Agent Reinforcement Learning). Finally, our work quantitatively examines the effectiveness of our design, and the results show that our design of Feint can (1) greatly improve the reward gains from the game; (2) significantly improve the diversity of Multi-Player Games; and (3) only incur negligible overheads in terms of time consumption. We conclude that our design of Feint is effective and practical, to make Multi-Player Games more interesting.
ARED: Argentina Real Estate Dataset
Mar 01, 2024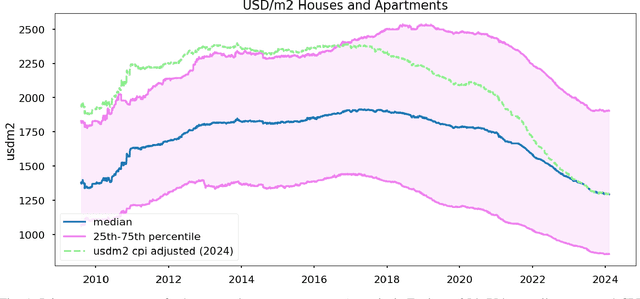
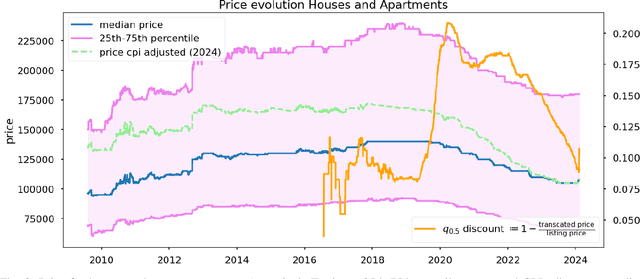
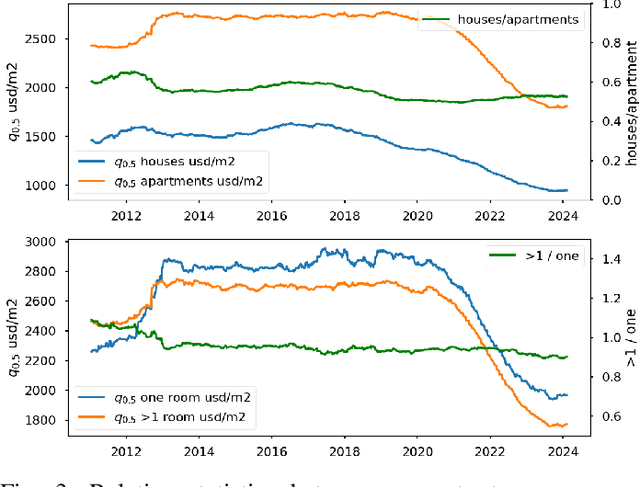
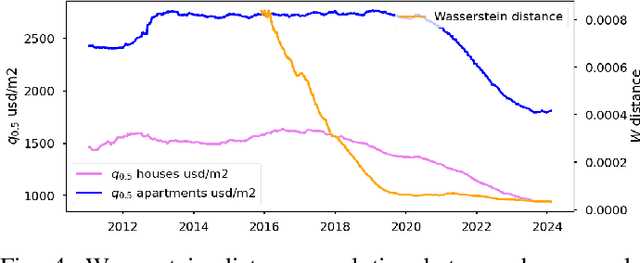
The Argentinian real estate market presents a unique case study characterized by its unstable and rapidly shifting macroeconomic circumstances over the past decades. Despite the existence of a few datasets for price prediction, there is a lack of mixed modality datasets specifically focused on Argentina. In this paper, the first edition of ARED is introduced. A comprehensive real estate price prediction dataset series, designed for the Argentinian market. This edition contains information solely for Jan-Feb 2024. It was found that despite the short time range captured by this zeroth edition (44 days), time dependent phenomena has been occurring mostly on a market level (market as a whole). Nevertheless future editions of this dataset, will most likely contain historical data. Each listing in ARED comprises descriptive features, and variable-length sets of images.
Certain and Approximately Certain Models for Statistical Learning
Mar 01, 2024Real-world data is often incomplete and contains missing values. To train accurate models over real-world datasets, users need to spend a substantial amount of time and resources imputing and finding proper values for missing data items. In this paper, we demonstrate that it is possible to learn accurate models directly from data with missing values for certain training data and target models. We propose a unified approach for checking the necessity of data imputation to learn accurate models across various widely-used machine learning paradigms. We build efficient algorithms with theoretical guarantees to check this necessity and return accurate models in cases where imputation is unnecessary. Our extensive experiments indicate that our proposed algorithms significantly reduce the amount of time and effort needed for data imputation without imposing considerable computational overhead.
Automatic Radar Signal Detection and FFT Estimation using Deep Learning
Feb 29, 2024This paper addresses a critical preliminary step in radar signal processing: detecting the presence of a radar signal and robustly estimating its bandwidth. Existing methods which are largely statistical feature-based approaches face challenges in electronic warfare (EW) settings where prior information about signals is lacking. While alternate deep learning based methods focus on more challenging environments, they primarily formulate this as a binary classification problem. In this research, we propose a novel methodology that not only detects the presence of a signal, but also localises it in the time domain and estimates its operating frequency band at that point in time. To achieve robust estimation, we introduce a compound loss function that leverages complementary information from both time-domain and frequency-domain representations. By integrating these approaches, we aim to improve the efficiency and accuracy of radar signal detection and parameter estimation, reducing both unnecessary resource consumption and human effort in downstream tasks.
Deep Cooperation in ISAC System: Resource, Node and Infrastructure Perspectives
Mar 05, 2024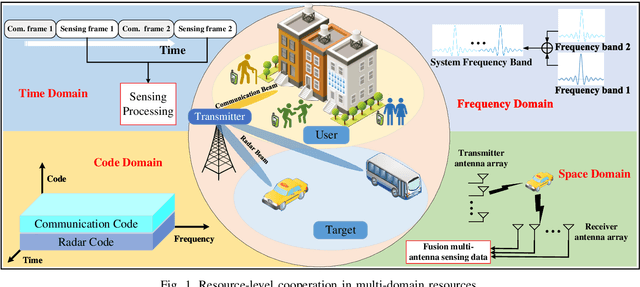
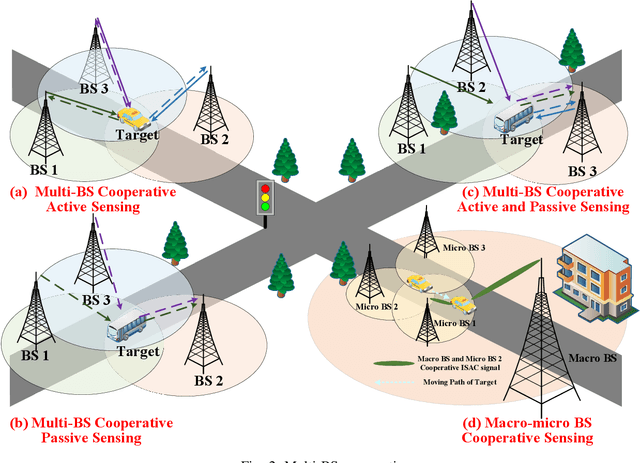
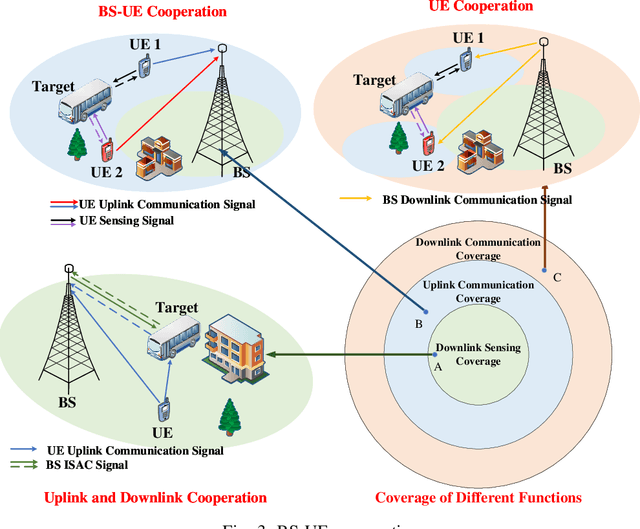
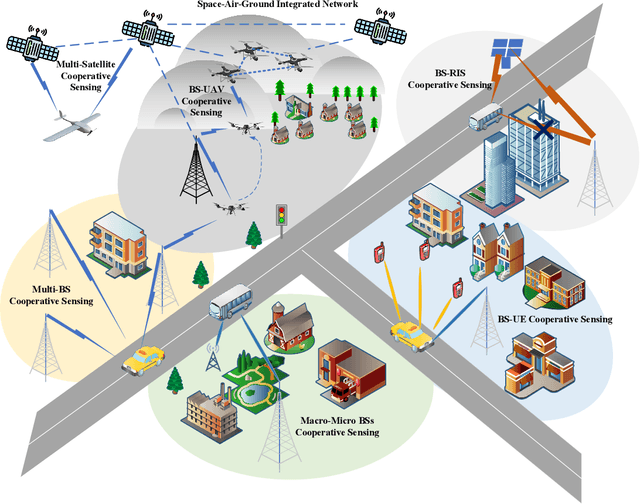
With the mobile communication system evolving into 6th-generation (6G), the Internet of Everything (IoE) is becoming reality, which connects human, big data and intelligent machines to support the intelligent decision making, reconfiguring the traditional industries and human life. The applications of IoE require not only pure communication capability, but also high-accuracy and large-scale sensing capability. With the emerging integrated sensing and communication (ISAC) technique, exploiting the mobile communication system with multi-domain resources, multiple network elements, and large-scale infrastructures to realize cooperative sensing is a crucial approach to satisfy the requirements of high-accuracy and large-scale sensing in IoE. In this article, the deep cooperation in ISAC system including three perspectives is investigated. In the microscopic perspective, namely, within a single node, the cooperation at the resource-level is performed to improve sensing accuracy by fusing the sensing information carried in the time-frequency-space-code multi-domain resources. In the mesoscopic perspective, the sensing accuracy could be improved through the cooperation of multiple nodes including Base Station (BS), User Equipment (UE), and Reconfigurable Intelligence Surface (RIS), etc. In the macroscopic perspective, the massive number of infrastructures from the same operator or different operators could perform cooperative sensing to extend the sensing coverage and improve the sensing continuity. This article may provide a deep and comprehensive view on the cooperative sensing in ISAC system to enhance the performance of sensing, supporting the applications of IoE.
Optimizing Mobile-Friendly Viewport Prediction for Live 360-Degree Video Streaming
Mar 05, 2024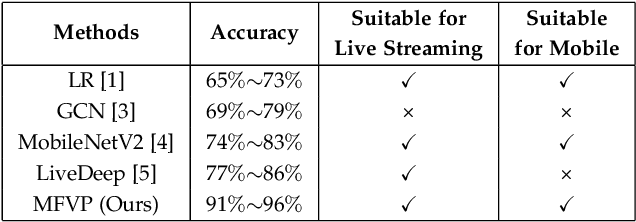
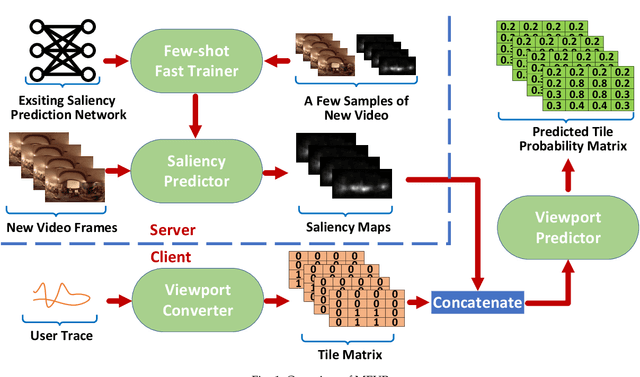
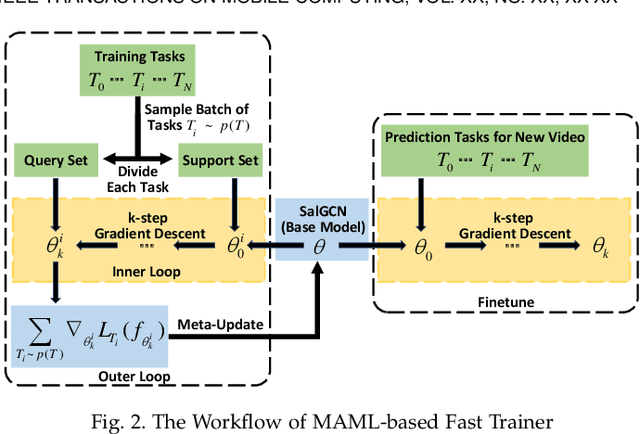
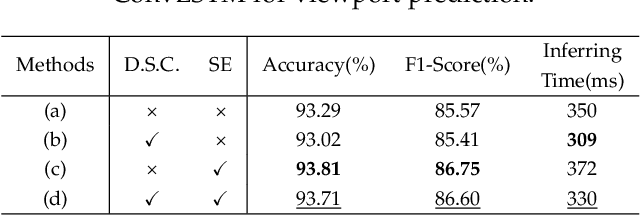
Viewport prediction is the crucial task for adaptive 360-degree video streaming, as the bitrate control algorithms usually require the knowledge of the user's viewing portions of the frames. Various methods are studied and adopted for viewport prediction from less accurate statistic tools to highly calibrated deep neural networks. Conventionally, it is difficult to implement sophisticated deep learning methods on mobile devices, which have limited computation capability. In this work, we propose an advanced learning-based viewport prediction approach and carefully design it to introduce minimal transmission and computation overhead for mobile terminals. We also propose a model-agnostic meta-learning (MAML) based saliency prediction network trainer, which provides a few-sample fast training solution to obtain the prediction model by utilizing the information from the past models. We further discuss how to integrate this mobile-friendly viewport prediction (MFVP) approach into a typical 360-degree video live streaming system by formulating and solving the bitrate adaptation problem. Extensive experiment results show that our prediction approach can work in real-time for live video streaming and can achieve higher accuracies compared to other existing prediction methods on mobile end, which, together with our bitrate adaptation algorithm, significantly improves the streaming QoE from various aspects. We observe the accuracy of MFVP is 8.1$\%$ to 28.7$\%$ higher than other algorithms and achieves 3.73$\%$ to 14.96$\%$ higher average quality level and 49.6$\%$ to 74.97$\%$ less quality level change than other algorithms.
Precise Extraction of Deep Learning Models via Side-Channel Attacks on Edge/Endpoint Devices
Mar 05, 2024With growing popularity, deep learning (DL) models are becoming larger-scale, and only the companies with vast training datasets and immense computing power can manage their business serving such large models. Most of those DL models are proprietary to the companies who thus strive to keep their private models safe from the model extraction attack (MEA), whose aim is to steal the model by training surrogate models. Nowadays, companies are inclined to offload the models from central servers to edge/endpoint devices. As revealed in the latest studies, adversaries exploit this opportunity as new attack vectors to launch side-channel attack (SCA) on the device running victim model and obtain various pieces of the model information, such as the model architecture (MA) and image dimension (ID). Our work provides a comprehensive understanding of such a relationship for the first time and would benefit future MEA studies in both offensive and defensive sides in that they may learn which pieces of information exposed by SCA are more important than the others. Our analysis additionally reveals that by grasping the victim model information from SCA, MEA can get highly effective and successful even without any prior knowledge of the model. Finally, to evince the practicality of our analysis results, we empirically apply SCA, and subsequently, carry out MEA under realistic threat assumptions. The results show up to 5.8 times better performance than when the adversary has no model information about the victim model.