 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Monitoring machine learning (ML)-based risk prediction algorithms in the presence of confounding medical interventions
Nov 17, 2022
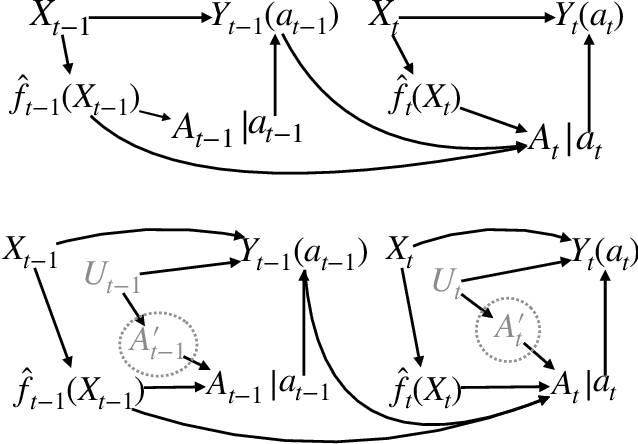
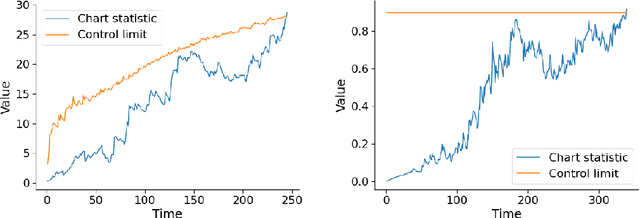
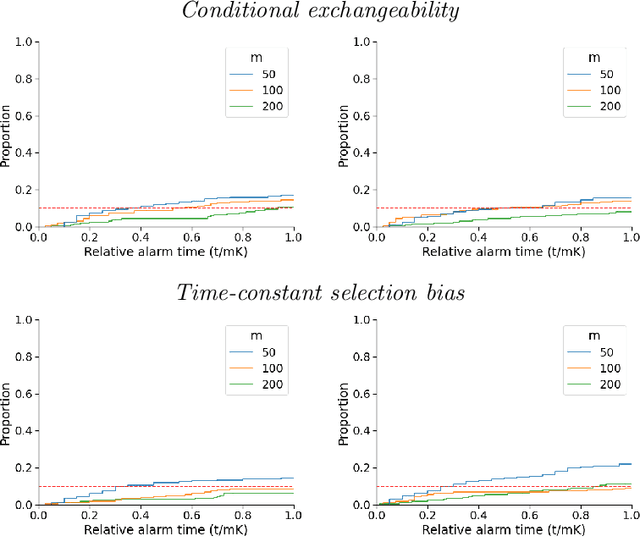
Monitoring the performance of machine learning (ML)-based risk prediction models in healthcare is complicated by the issue of confounding medical interventions (CMI): when an algorithm predicts a patient to be at high risk for an adverse event, clinicians are more likely to administer prophylactic treatment and alter the very target that the algorithm aims to predict. Ignoring CMI by monitoring only the untreated patients--whose outcomes remain unaltered--can inflate false alarm rates, because the evolution of both the model and clinician-ML interactions can induce complex dependencies in the data that violate standard assumptions. A more sophisticated approach is to explicitly account for CMI by modeling treatment propensities, but its time-varying nature makes accurate estimation difficult. Given the many sources of complexity in the data, it is important to determine situations in which a simple procedure that ignores CMI provides valid inference. Here we describe the special case of monitoring model calibration, under either the assumption of conditional exchangeability or time-constant selection bias. We introduce a new score-based cumulative sum (CUSUM) chart for monitoring in a frequentist framework and review an alternative approach using Bayesian inference. Through simulations, we investigate the benefits of combining model updating with monitoring and study when over-trust in a prediction model does (or does not) delay detection. Finally, we simulate monitoring an ML-based postoperative nausea and vomiting risk calculator during the COVID-19 pandemic.
A Log-Linear Time Sequential Optimal Calibration Algorithm for Quantized Isotonic L2 Regression
Jun 01, 2022We study the sequential calibration of estimations in a quantized isotonic L2 regression setting. We start by showing that the optimal calibrated quantized estimations can be acquired from the traditional isotonic L2 regression solution. We modify the traditional PAVA algorithm to create calibrators for both batch and sequential optimization of the quantized isotonic regression problem. Our algorithm can update the optimal quantized monotone mapping for the samples observed so far in linear space and logarithmic time per new unordered sample.
Privacy Amplification by Subsampling in Time Domain
Jan 13, 2022
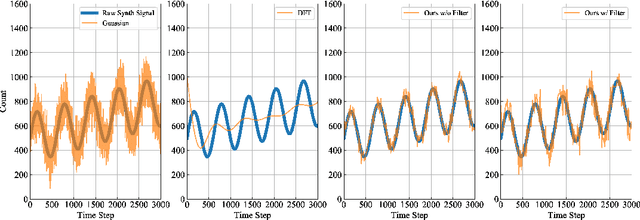

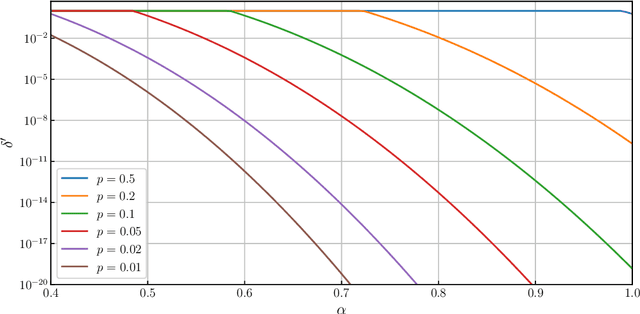
Aggregate time-series data like traffic flow and site occupancy repeatedly sample statistics from a population across time. Such data can be profoundly useful for understanding trends within a given population, but also pose a significant privacy risk, potentially revealing e.g., who spends time where. Producing a private version of a time-series satisfying the standard definition of Differential Privacy (DP) is challenging due to the large influence a single participant can have on the sequence: if an individual can contribute to each time step, the amount of additive noise needed to satisfy privacy increases linearly with the number of time steps sampled. As such, if a signal spans a long duration or is oversampled, an excessive amount of noise must be added, drowning out underlying trends. However, in many applications an individual realistically cannot participate at every time step. When this is the case, we observe that the influence of a single participant (sensitivity) can be reduced by subsampling and/or filtering in time, while still meeting privacy requirements. Using a novel analysis, we show this significant reduction in sensitivity and propose a corresponding class of privacy mechanisms. We demonstrate the utility benefits of these techniques empirically with real-world and synthetic time-series data.
Diverse Counterfactual Explanations for Anomaly Detection in Time Series
Mar 21, 2022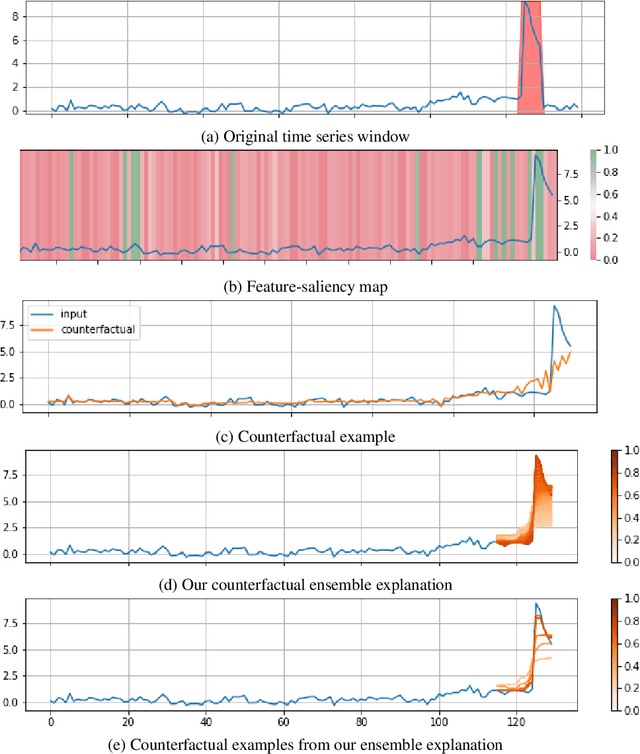
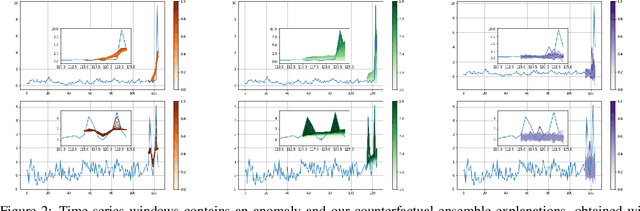
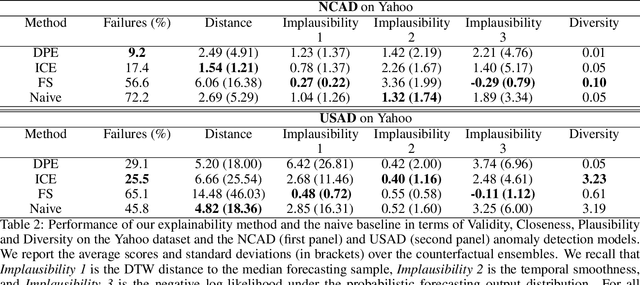
Data-driven methods that detect anomalies in times series data are ubiquitous in practice, but they are in general unable to provide helpful explanations for the predictions they make. In this work we propose a model-agnostic algorithm that generates counterfactual ensemble explanations for time series anomaly detection models. Our method generates a set of diverse counterfactual examples, i.e, multiple perturbed versions of the original time series that are not considered anomalous by the detection model. Since the magnitude of the perturbations is limited, these counterfactuals represent an ensemble of inputs similar to the original time series that the model would deem normal. Our algorithm is applicable to any differentiable anomaly detection model. We investigate the value of our method on univariate and multivariate real-world datasets and two deep-learning-based anomaly detection models, under several explainability criteria previously proposed in other data domains such as Validity, Plausibility, Closeness and Diversity. We show that our algorithm can produce ensembles of counterfactual examples that satisfy these criteria and thanks to a novel type of visualisation, can convey a richer interpretation of a model's internal mechanism than existing methods. Moreover, we design a sparse variant of our method to improve the interpretability of counterfactual explanations for high-dimensional time series anomalies. In this setting, our explanation is localised on only a few dimensions and can therefore be communicated more efficiently to the model's user.
Exact Statistical Inference for Time Series Similarity using Dynamic Time Warping by Selective Inference
Feb 14, 2022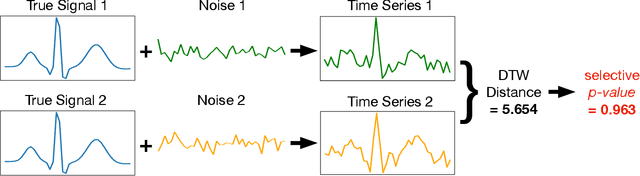
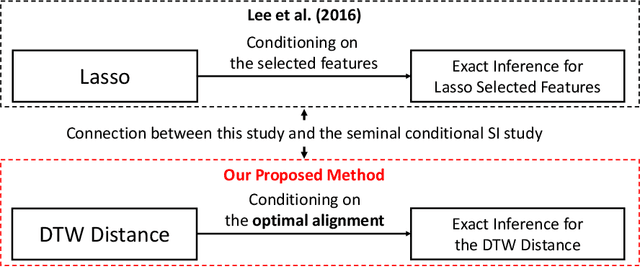
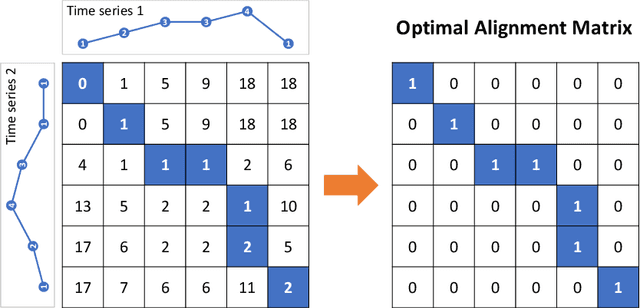
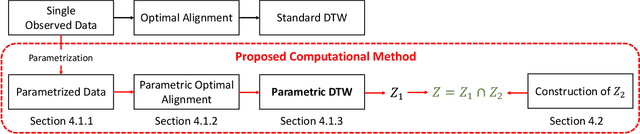
In this paper, we study statistical inference on the similarity/distance between two time-series under uncertain environment by considering a statistical hypothesis test on the distance obtained from Dynamic Time Warping (DTW) algorithm. The sampling distribution of the DTW distance is too complicated to derive because it is obtained based on the solution of a complicated algorithm. To circumvent this difficulty, we propose to employ a conditional sampling distribution for the inference, which enables us to derive an exact (non-asymptotic) inference method on the DTW distance. Besides, we also develop a novel computational method to compute the conditional sampling distribution. To our knowledge, this is the first method that can provide valid $p$-value to quantify the statistical significance of the DTW distance, which is helpful for high-stake decision making. We evaluate the performance of the proposed inference method on both synthetic and real-world datasets.
Monte-Carlo Tree-Search for Leveraging Performance of Blackbox Job-Shop Scheduling Heuristics
Dec 14, 2022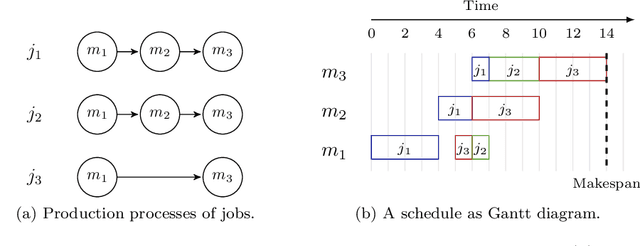
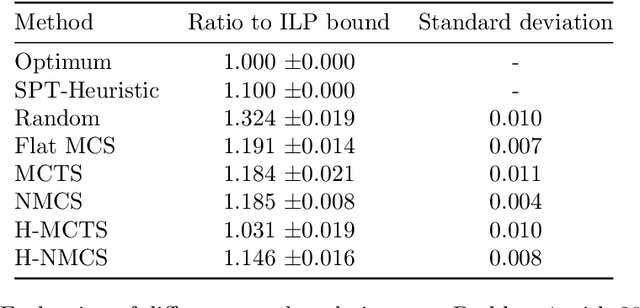
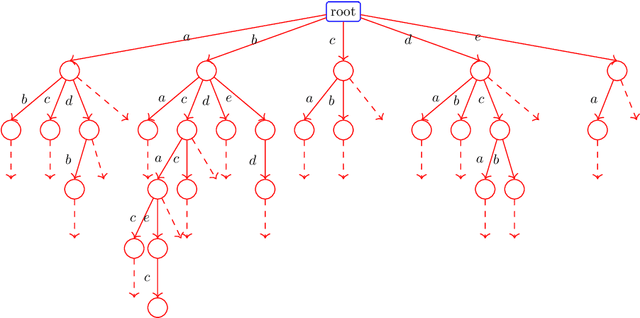
In manufacturing, the production is often done on out-of-the-shelf manufacturing lines, whose underlying scheduling heuristics are not known due to the intellectual property. We consider such a setting with a black-box job-shop system and an unknown scheduling heuristic that, for a given permutation of jobs, schedules the jobs for the black-box job-shop with the goal of minimizing the makespan. Here, the jobs need to enter the job-shop in the given order of the permutation, but may take different paths within the job shop, which depends on the black-box heuristic. The performance of the black-box heuristic depends on the order of the jobs, and the natural problem for the manufacturer is to find an optimum ordering of the jobs. Facing a real-world scenario as described above, we engineer the Monte-Carlo tree-search for finding a close-to-optimum ordering of jobs. To cope with a large solutions-space in planning scenarios, a hierarchical Monte-Carlo tree search (H-MCTS) is proposed based on abstraction of jobs. On synthetic and real-life problems, H-MCTS with integrated abstraction significantly outperforms pure heuristic-based techniques as well as other Monte-Carlo search variants. We furthermore show that, by modifying the evaluation metric in H-MCTS, it is possible to achieve other optimization objectives than what the scheduling heuristics are designed for -- e.g., minimizing the total completion time instead of the makespan. Our experimental observations have been also validated in real-life cases, and our H-MCTS approach has been implemented in a production plant's controller.
ARLIF-IDS -- Attention augmented Real-Time Isolation Forest Intrusion Detection System
Apr 20, 2022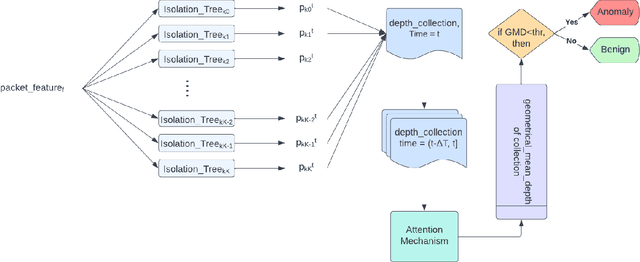
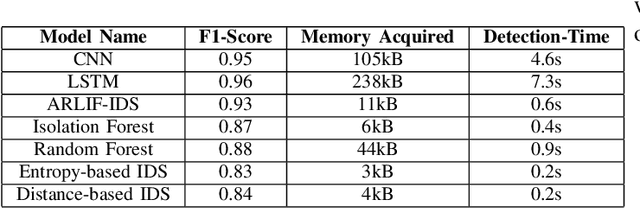
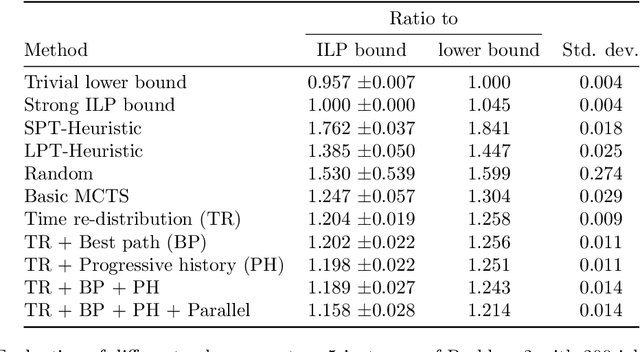
Distributed Denial of Service (DDoS) attack is a malicious attempt to disrupt the normal traffic of a targeted server, service or network by overwhelming the target or its surrounding infrastructure with a flood of Internet traffic. Emerging technologies such as the Internet of Things and Software Defined Networking leverage lightweight strategies for the early detection of DDoS attacks. Previous literature demonstrates the utility of lower number of significant features for intrusion detection. Thus, it is essential to have a fast and effective security identification model based on low number of features. In this work, a novel Attention-based Isolation Forest Intrusion Detection System is proposed. The model considerably reduces training time and memory consumption of the generated model. For performance assessment, the model is assessed over two benchmark datasets, the NSL-KDD dataset & the KDDCUP'99 dataset. Experimental results demonstrate that the proposed attention augmented model achieves a significant reduction in execution time, by 91.78%, and an average detection F1-Score of 0.93 on the NSL-KDD and KDDCUP'99 dataset. The results of performance evaluation show that the proposed methodology has low complexity and requires less processing time and computational resources, outperforming other current IDS based on machine learning algorithms.
Hankel low-rank approximation and completion in time series analysis and forecasting: a brief review
Jun 10, 2022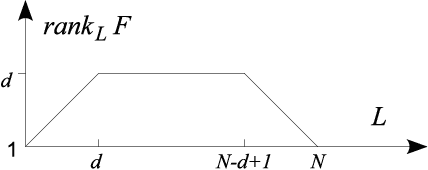
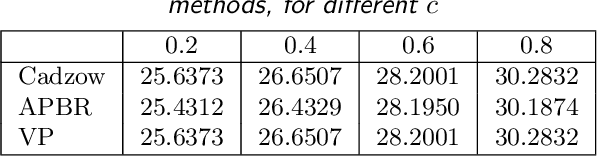
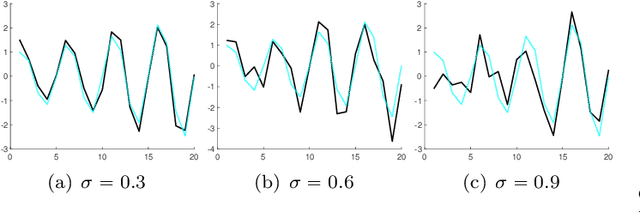
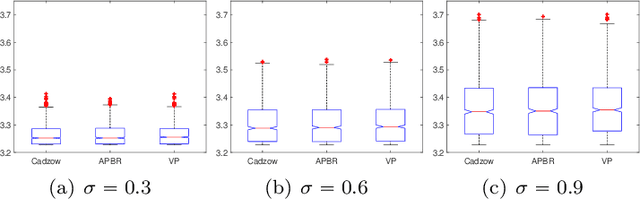
In this paper we offer a review and bibliography of work on Hankel low-rank approximation and completion, with particular emphasis on how this methodology can be used for time series analysis and forecasting. We begin by describing possible formulations of the problem and offer commentary on related topics and challenges in obtaining globally optimal solutions. Key theorems are provided, and the paper closes with some expository examples.
LaCAM: Search-Based Algorithm for Quick Multi-Agent Pathfinding
Nov 24, 2022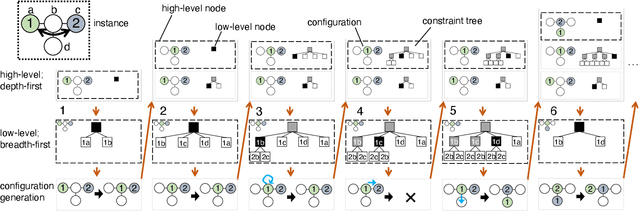
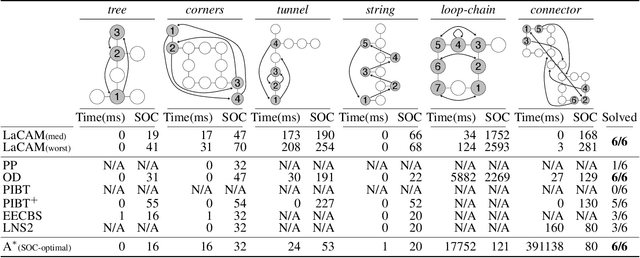
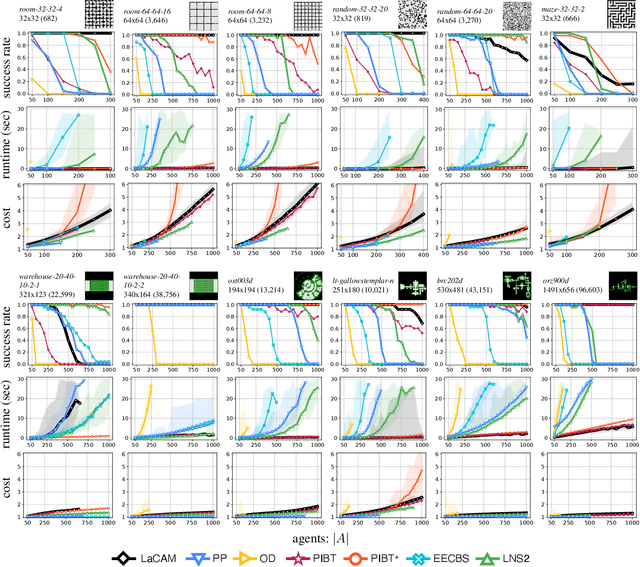
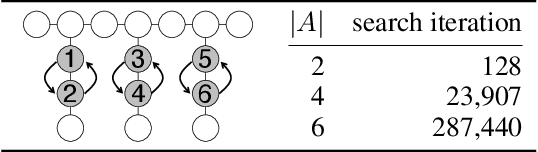
We propose a novel complete algorithm for multi-agent pathfinding (MAPF) called lazy constraints addition search for MAPF (LaCAM). MAPF is a problem of finding collision-free paths for multiple agents on graphs and is the foundation of multi-robot coordination. LaCAM uses a two-level search to find solutions quickly, even with hundreds of agents or more. At the low-level, it searches constraints about agents' locations. At the high-level, it searches a sequence of all agents' locations, following the constraints specified by the low-level. Our exhaustive experiments reveal that LaCAM is comparable to or outperforms state-of-the-art sub-optimal MAPF algorithms in a variety of scenarios, regarding success rate, planning time, and solution quality of sum-of-costs.
Nonuniqueness and Convergence to Equivalent Solutions in Observer-based Inverse Reinforcement Learning
Oct 28, 2022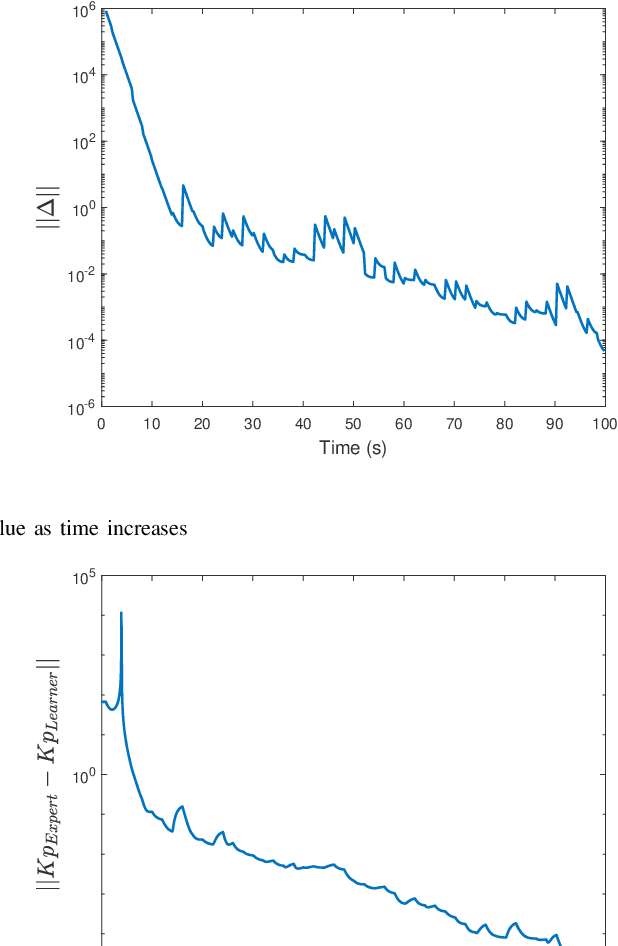
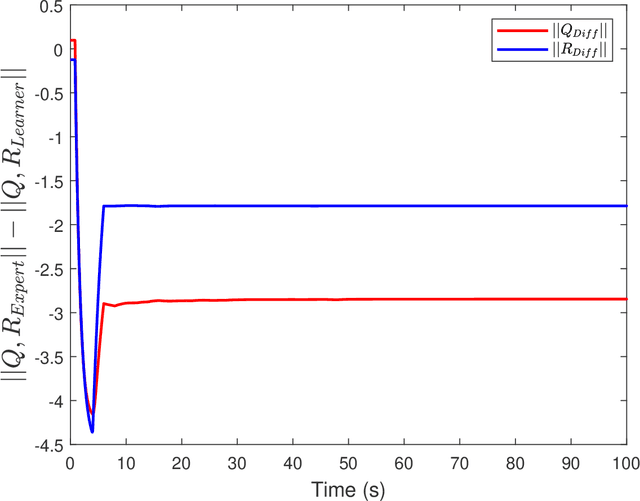
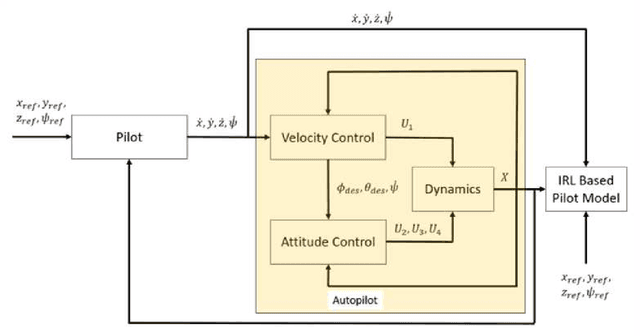
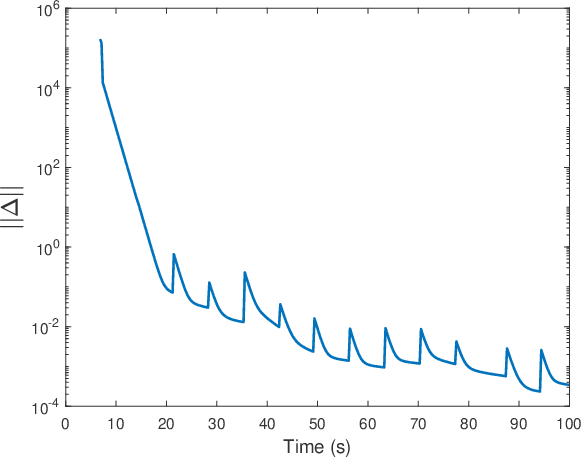
A key challenge in solving the deterministic inverse reinforcement learning problem online and in real time is the existence of non-unique solutions. Nonuniqueness necessitates the study of the notion of equivalent solutions and convergence to such solutions. While \emph{offline} algorithms that result in convergence to equivalent solutions have been developed in the literature, online, real-time techniques that address nonuniqueness are not available. In this paper, a regularized history stack observer is developed to generate solutions that are approximately equivalent. Novel data-richness conditions are developed to facilitate the analysis and simulation results are provided to demonstrate the effectiveness of the developed technique.