 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BAD-NeRF: Bundle Adjusted Deblur Neural Radiance Fields
Nov 23, 2022

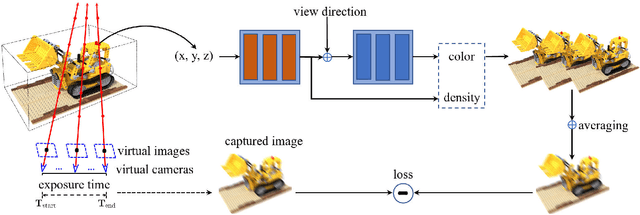
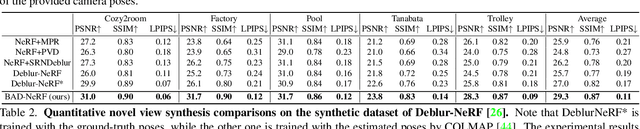
Neural Radiance Fields (NeRF) have received considerable attention recently, due to its impressive capability in photo-realistic 3D reconstruction and novel view synthesis, given a set of posed camera images. Earlier work usually assumes the input images are in good quality. However, image degradation (e.g. image motion blur in low-light conditions) can easily happen in real-world scenarios, which would further affect the rendering quality of NeRF. In this paper, we present a novel bundle adjusted deblur Neural Radiance Fields (BAD-NeRF), which can be robust to severe motion blurred images and inaccurate camera poses. Our approach models the physical image formation process of a motion blurred image, and jointly learns the parameters of NeRF and recovers the camera motion trajectories during exposure time. In experiments, we show that by directly modeling the real physical image formation process, BAD-NeRF achieves superior performance over prior works on both synthetic and real datasets.
Runtime Analysis for the NSGA-II: Proving, Quantifying, and Explaining the Inefficiency For Three or More Objectives
Nov 23, 2022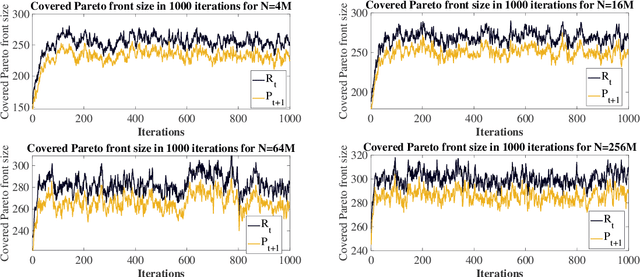
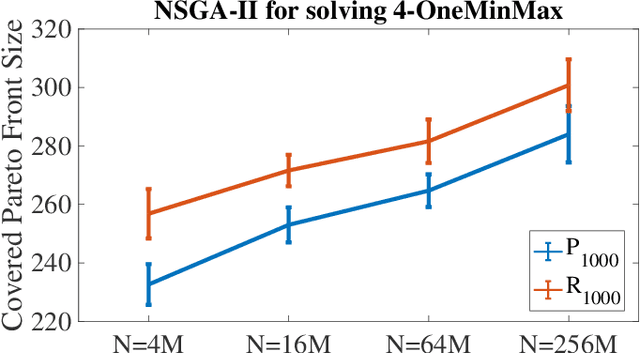
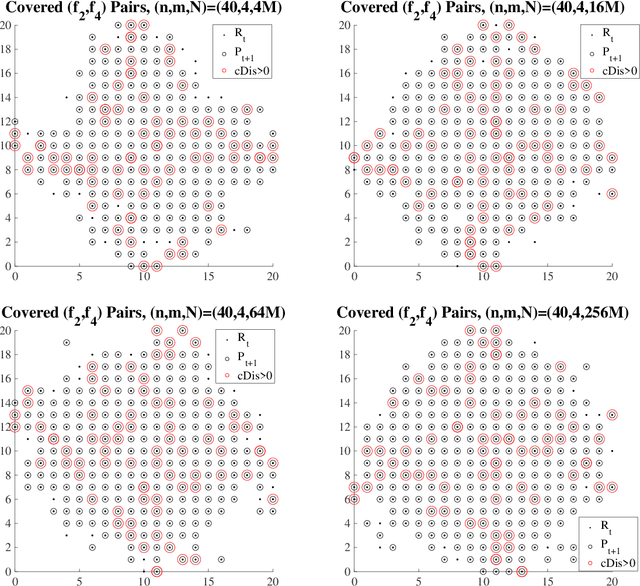
The NSGA-II is one of the most prominent algorithms to solve multi-objective optimization problems. Despite numerous successful applications and, very recently, also competitive mathematical performance guarantees, several studies have shown that the NSGA-II is less effective for larger numbers of objectives. In this work, we use mathematical runtime analyses to rigorously prove and quantify this phenomenon. We show that even on the simple OneMinMax benchmark, where every solution is Pareto optimal, the NSGA-II also with large population sizes cannot compute the full Pareto front (objective vectors of all Pareto optima) in sub-exponential time. Our proofs suggest that the reason for this unexpected behavior lies in the fact that in the computation of the crowding distance, the different objectives are regarded independently. This is not a problem for two objectives, where any sorting of a pair-wise incomparable set of solutions according to one objective is also such a sorting according to the other objective (in the inverse order).
Robust Augmentation for Multivariate Time Series Classification
Jan 27, 2022Neural networks are capable of learning powerful representations of data, but they are susceptible to overfitting due to the number of parameters. This is particularly challenging in the domain of time series classification, where datasets may contain fewer than 100 training examples. In this paper, we show that the simple methods of cutout, cutmix, mixup, and window warp improve the robustness and overall performance in a statistically significant way for convolutional, recurrent, and self-attention based architectures for time series classification. We evaluate these methods on 26 datasets from the University of East Anglia Multivariate Time Series Classification (UEA MTSC) archive and analyze how these methods perform on different types of time series data.. We show that the InceptionTime network with augmentation improves accuracy by 1% to 45% in 18 different datasets compared to without augmentation. We also show that augmentation improves accuracy for recurrent and self attention based architectures.
Generalized Classification of Satellite Image Time Series with Thermal Positional Encoding
Mar 17, 2022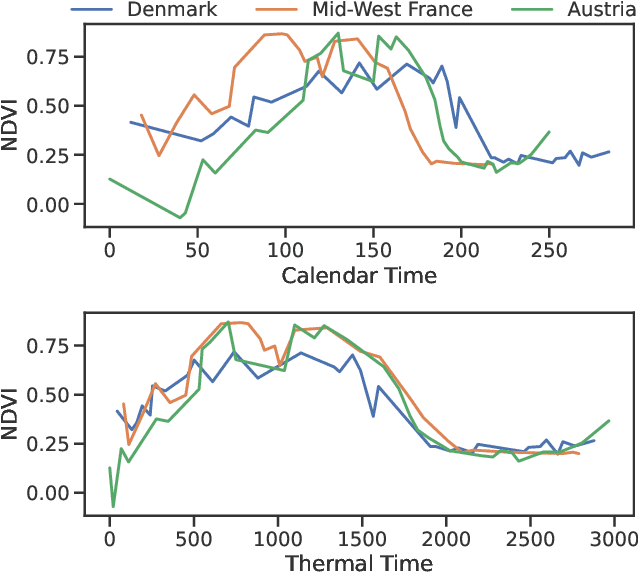
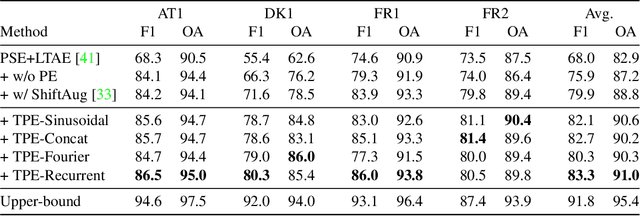
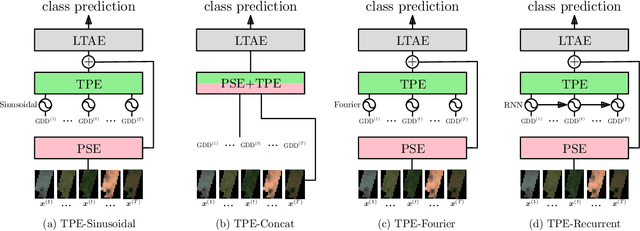
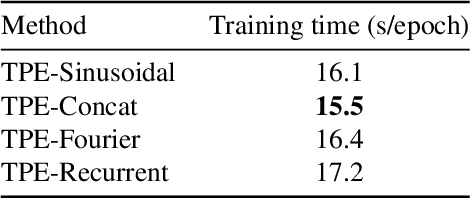
Large-scale crop type classification is a task at the core of remote sensing efforts with applications of both economic and ecological importance. Current state-of-the-art deep learning methods are based on self-attention and use satellite image time series (SITS) to discriminate crop types based on their unique growth patterns. However, existing methods generalize poorly to regions not seen during training mainly due to not being robust to temporal shifts of the growing season caused by variations in climate. To this end, we propose Thermal Positional Encoding (TPE) for attention-based crop classifiers. Unlike previous positional encoding based on calendar time (e.g. day-of-year), TPE is based on thermal time, which is obtained by accumulating daily average temperatures over the growing season. Since crop growth is directly related to thermal time, but not calendar time, TPE addresses the temporal shifts between different regions to improve generalization. We propose multiple TPE strategies, including learnable methods, to further improve results compared to the common fixed positional encodings. We demonstrate our approach on a crop classification task across four different European regions, where we obtain state-of-the-art generalization results.
SWIFT: Rapid Decentralized Federated Learning via Wait-Free Model Communication
Oct 25, 2022
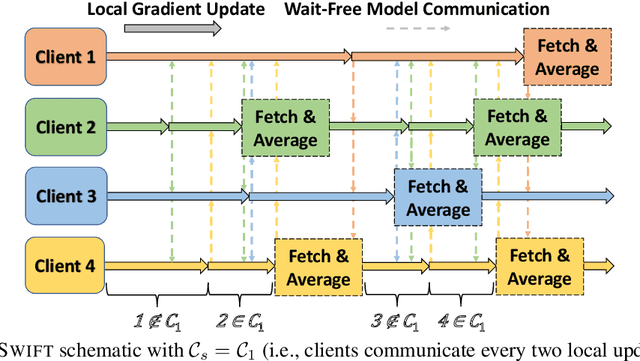
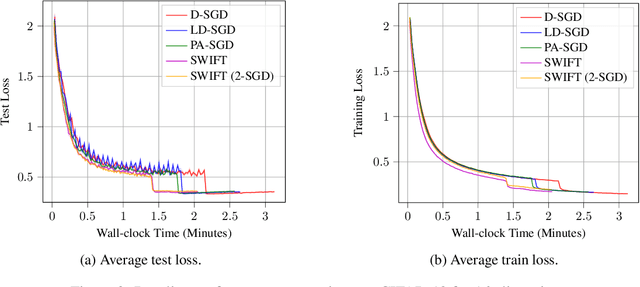
The decentralized Federated Learning (FL) setting avoids the role of a potentially unreliable or untrustworthy central host by utilizing groups of clients to collaboratively train a model via localized training and model/gradient sharing. Most existing decentralized FL algorithms require synchronization of client models where the speed of synchronization depends upon the slowest client. In this work, we propose SWIFT: a novel wait-free decentralized FL algorithm that allows clients to conduct training at their own speed. Theoretically, we prove that SWIFT matches the gold-standard iteration convergence rate $\mathcal{O}(1/\sqrt{T})$ of parallel stochastic gradient descent for convex and non-convex smooth optimization (total iterations $T$). Furthermore, we provide theoretical results for IID and non-IID settings without any bounded-delay assumption for slow clients which is required by other asynchronous decentralized FL algorithms. Although SWIFT achieves the same iteration convergence rate with respect to $T$ as other state-of-the-art (SOTA) parallel stochastic algorithms, it converges faster with respect to run-time due to its wait-free structure. Our experimental results demonstrate that SWIFT's run-time is reduced due to a large reduction in communication time per epoch, which falls by an order of magnitude compared to synchronous counterparts. Furthermore, SWIFT produces loss levels for image classification, over IID and non-IID data settings, upwards of 50% faster than existing SOTA algorithms.
Single microphone speaker extraction using unified time-frequency Siamese-Unet
Mar 06, 2022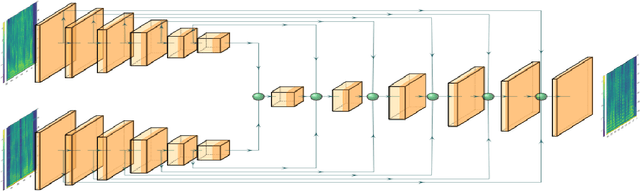
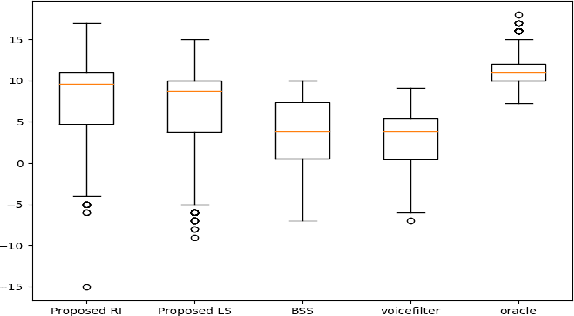
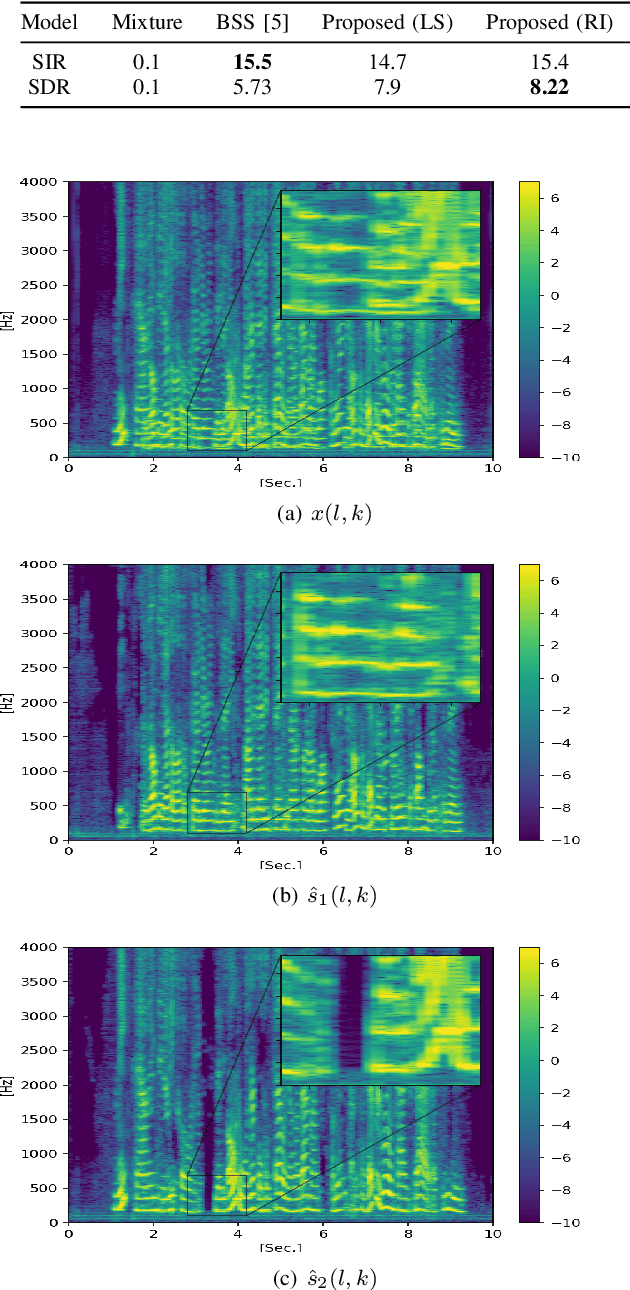

In this paper we present a unified time-frequency method for speaker extraction in clean and noisy conditions. Given a mixed signal, along with a reference signal, the common approaches for extracting the desired speaker are either applied in the time-domain or in the frequency-domain. In our approach, we propose a Siamese-Unet architecture that uses both representations. The Siamese encoders are applied in the frequency-domain to infer the embedding of the noisy and reference spectra, respectively. The concatenated representations are then fed into the decoder to estimate the real and imaginary components of the desired speaker, which are then inverse-transformed to the time-domain. The model is trained with the Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) loss to exploit the time-domain information. The time-domain loss is also regularized with frequency-domain loss to preserve the speech patterns. Experimental results demonstrate that the unified approach is not only very easy to train, but also provides superior results as compared with state-of-the-art (SOTA) Blind Source Separation (BSS) methods, as well as commonly used speaker extraction approach.
SafeLight: A Reinforcement Learning Method toward Collision-free Traffic Signal Control
Nov 20, 2022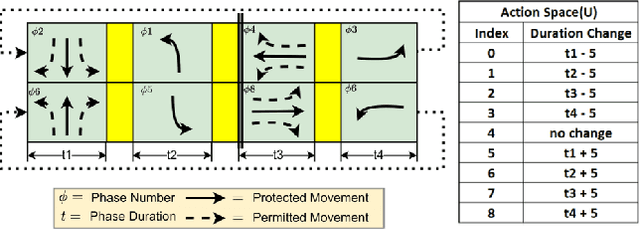
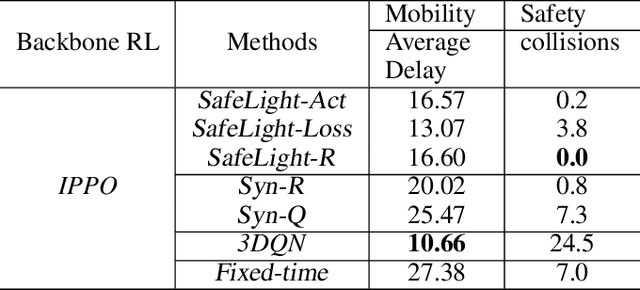
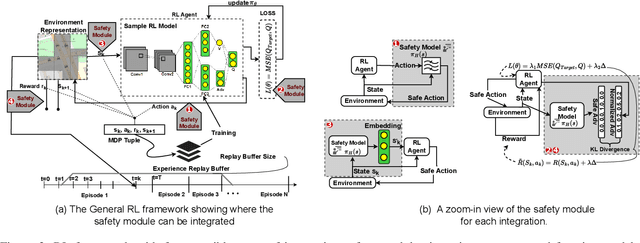
Traffic signal control is safety-critical for our daily life. Roughly one-quarter of road accidents in the U.S. happen at intersections due to problematic signal timing, urging the development of safety-oriented intersection control. However, existing studies on adaptive traffic signal control using reinforcement learning technologies have focused mainly on minimizing traffic delay but neglecting the potential exposure to unsafe conditions. We, for the first time, incorporate road safety standards as enforcement to ensure the safety of existing reinforcement learning methods, aiming toward operating intersections with zero collisions. We have proposed a safety-enhanced residual reinforcement learning method (SafeLight) and employed multiple optimization techniques, such as multi-objective loss function and reward shaping for better knowledge integration. Extensive experiments are conducted using both synthetic and real-world benchmark datasets. Results show that our method can significantly reduce collisions while increasing traffic mobility.
Heterogenous Ensemble of Models for Molecular Property Prediction
Nov 20, 2022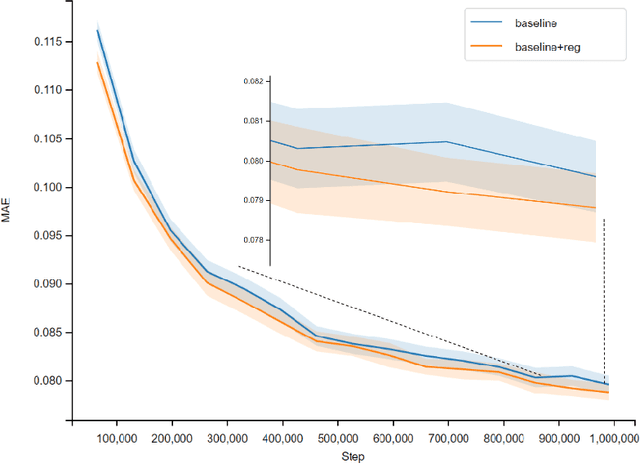
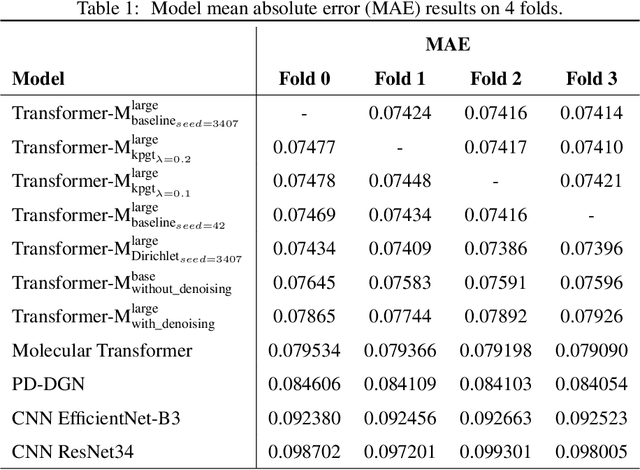
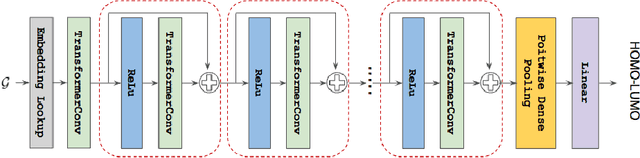
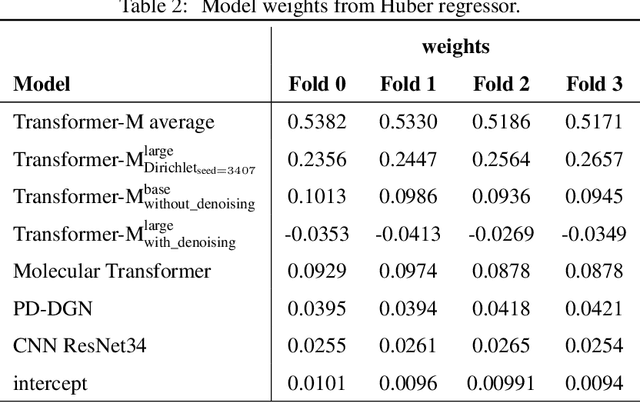
Previous works have demonstrated the importance of considering different modalities on molecules, each of which provide a varied granularity of information for downstream property prediction tasks. Our method combines variants of the recent TransformerM architecture with Transformer, GNN, and ResNet backbone architectures. Models are trained on the 2D data, 3D data, and image modalities of molecular graphs. We ensemble these models with a HuberRegressor. The models are trained on 4 different train/validation splits of the original train + valid datasets. This yields a winning solution to the 2\textsuperscript{nd} edition of the OGB Large-Scale Challenge (2022) on the PCQM4Mv2 molecular property prediction dataset. Our proposed method achieves a test-challenge MAE of $0.0723$ and a validation MAE of $0.07145$. Total inference time for our solution is less than 2 hours. We open-source our code at https://github.com/jfpuget/NVIDIA-PCQM4Mv2.
Joint Embedding Predictive Architectures Focus on Slow Features
Nov 20, 2022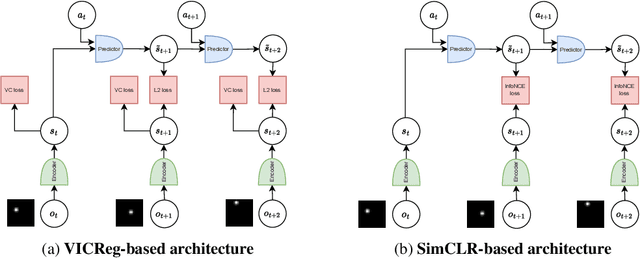
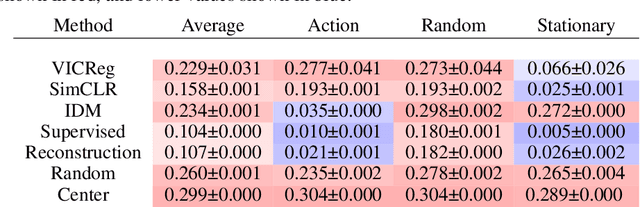

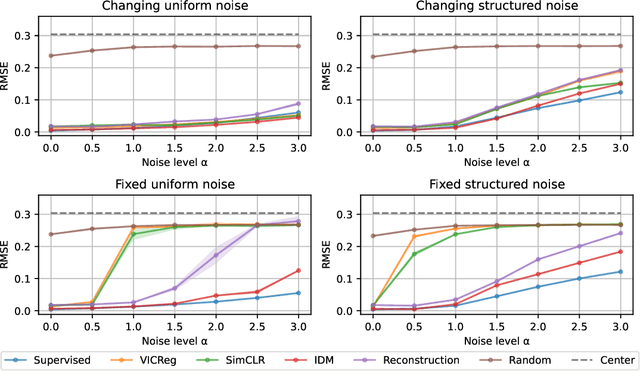
Many common methods for learning a world model for pixel-based environments use generative architectures trained with pixel-level reconstruction objectives. Recently proposed Joint Embedding Predictive Architectures (JEPA) offer a reconstruction-free alternative. In this work, we analyze performance of JEPA trained with VICReg and SimCLR objectives in the fully offline setting without access to rewards, and compare the results to the performance of the generative architecture. We test the methods in a simple environment with a moving dot with various background distractors, and probe learned representations for the dot's location. We find that JEPA methods perform on par or better than reconstruction when distractor noise changes every time step, but fail when the noise is fixed. Furthermore, we provide a theoretical explanation for the poor performance of JEPA-based methods with fixed noise, highlighting an important limitation.
Implementation of Trained Factorization Machine Recommendation System on Quantum Annealer
Oct 24, 2022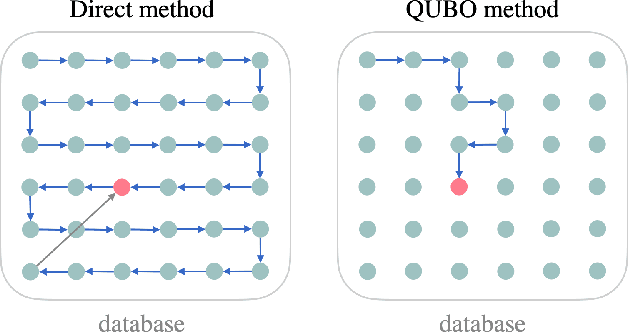
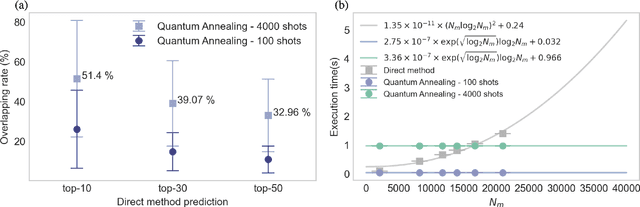
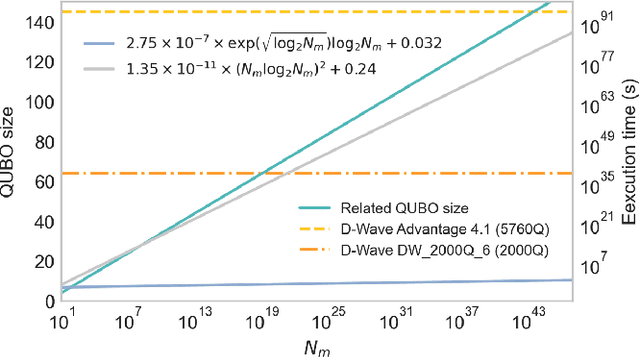
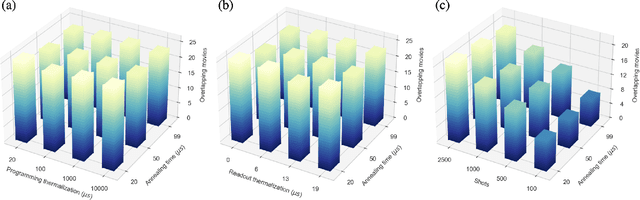
Factorization Machine (FM) is the most commonly used model to build a recommendation system since it can incorporate side information to improve performance. However, producing item suggestions for a given user with a trained FM is time-consuming. It requires a run-time of $O((N_m \log N_m)^2)$, where $N_m$ is the number of items in the dataset. To address this problem, we propose a quadratic unconstrained binary optimization (QUBO) scheme to combine with FM and apply quantum annealing (QA) computation. Compared to classical methods, this hybrid algorithm provides a faster than quadratic speedup in finding good user suggestions. We then demonstrate the aforementioned computational advantage on current NISQ hardware by experimenting with a real example on a D-Wave annealer.