 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A1 SLAM: Quadruped SLAM using the A1's Onboard Sensors
Nov 26, 2022
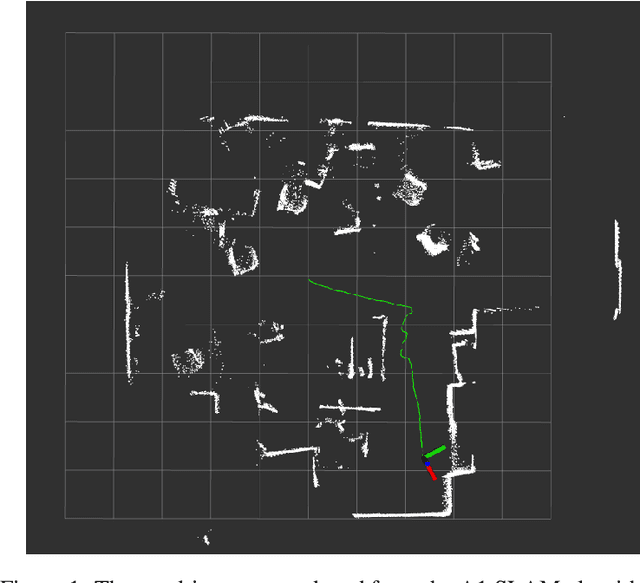
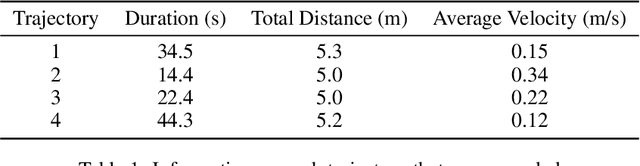
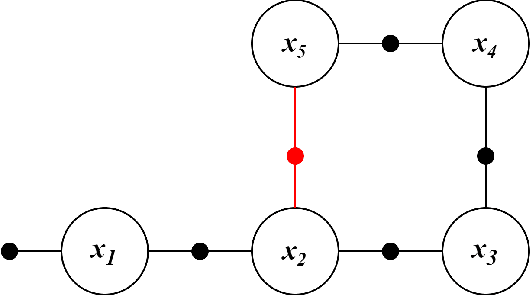

Quadrupeds are robots that have been of interest in the past few years due to their versatility in navigating across various terrain and utility in several applications. For quadrupeds to navigate without a predefined map a priori, they must rely on SLAM approaches to localize and build the map of the environment. Despite the surge of interest and research development in SLAM and quadrupeds, there still has yet to be an open-source package that capitalizes on the onboard sensors of an affordable quadruped. This motivates the A1 SLAM package, which is an open-source ROS package that provides the Unitree A1 quadruped with real-time, high performing SLAM capabilities using the default sensors shipped with the robot. A1 SLAM solves the PoseSLAM problem using the factor graph paradigm to optimize for the poses throughout the trajectory. A major design feature of the algorithm is using a sliding window of fully connected LiDAR odometry factors. A1 SLAM has been benchmarked against Google's Cartographer and has showed superior performance especially with trajectories experiencing aggressive motion.
DynaVIG: Monocular Vision/INS/GNSS Integrated Navigation and Object Tracking for AGV in Dynamic Scenes
Nov 26, 2022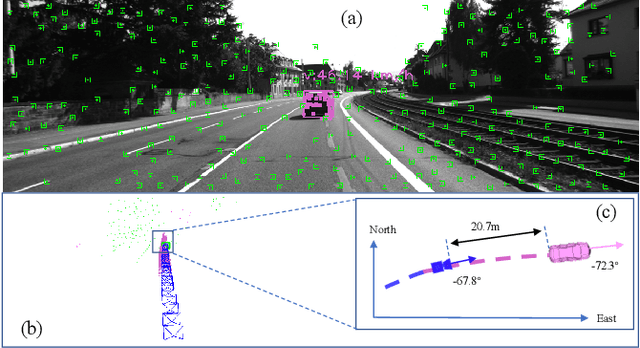
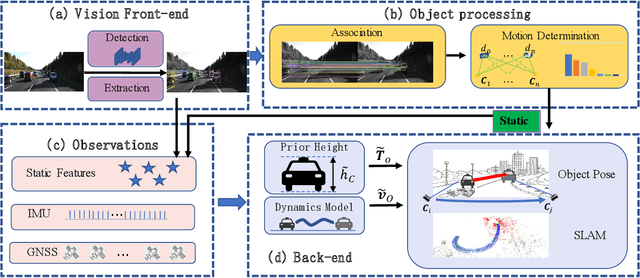
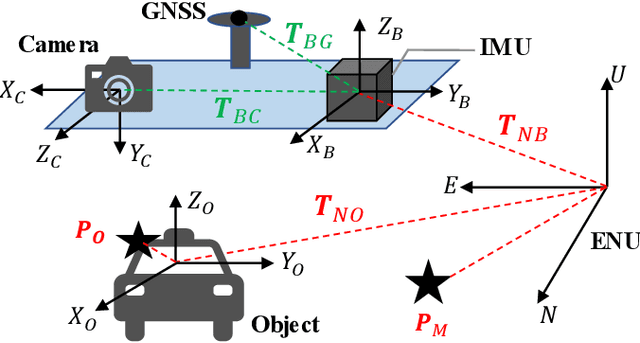
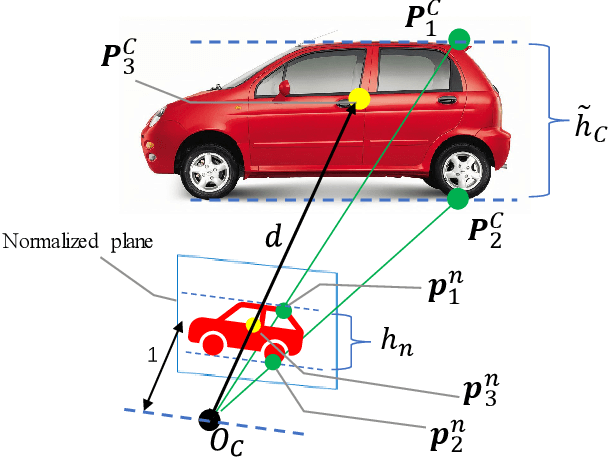
Visual-Inertial Odometry (VIO) usually suffers from drifting over long-time runs, the accuracy is easily affected by dynamic objects. We propose DynaVIG, a navigation and object tracking system based on the integration of Monocular Vision, Inertial Navigation System (INS), and Global Navigation Satellite System (GNSS). Our system aims to provide an accurate global estimation of the navigation states and object poses for the automated ground vehicle (AGV) in dynamic scenes. Due to the scale ambiguity of the object, a prior height model is proposed to initialize the object pose, and the scale is continuously estimated with the aid of GNSS and INS. To precisely track the object with complex moving, we establish an accurate dynamics model according to its motion state. Then the multi-sensor observations are optimized in a unified framework. Experiments on the KITTI dataset demonstrate that the multisensor fusion can effectively improve the accuracy of navigation and object tracking, compared to state-of-the-art methods. In addition, the proposed system achieves good estimation of the objects that change speed or direction.
Instant Volumetric Head Avatars
Nov 22, 2022
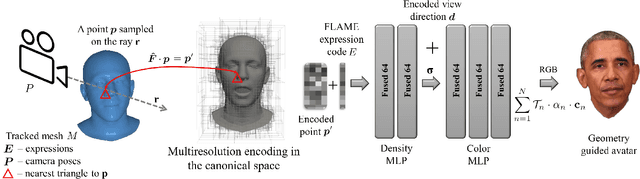
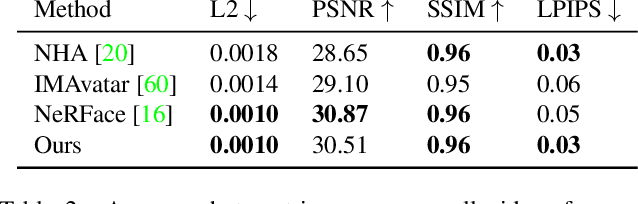

We present Instant Volumetric Head Avatars (INSTA), a novel approach for reconstructing photo-realistic digital avatars instantaneously. INSTA models a dynamic neural radiance field based on neural graphics primitives embedded around a parametric face model. Our pipeline is trained on a single monocular RGB portrait video that observes the subject under different expressions and views. While state-of-the-art methods take up to several days to train an avatar, our method can reconstruct a digital avatar in less than 10 minutes on modern GPU hardware, which is orders of magnitude faster than previous solutions. In addition, it allows for the interactive rendering of novel poses and expressions. By leveraging the geometry prior of the underlying parametric face model, we demonstrate that INSTA extrapolates to unseen poses. In quantitative and qualitative studies on various subjects, INSTA outperforms state-of-the-art methods regarding rendering quality and training time.
AERO: Audio Super Resolution in the Spectral Domain
Nov 22, 2022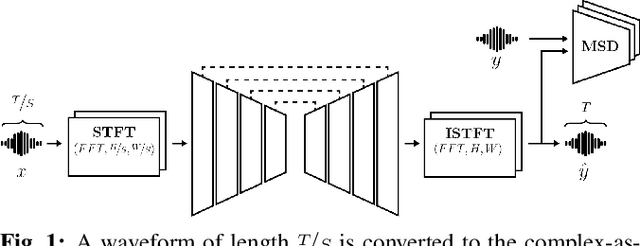
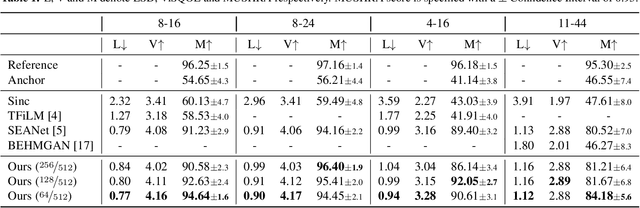
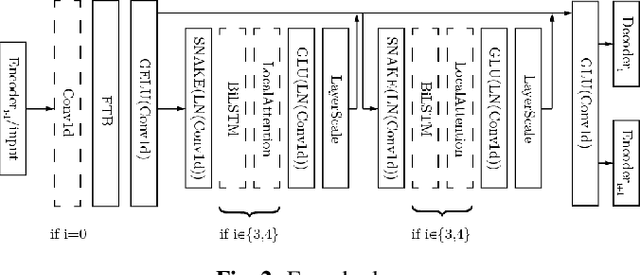
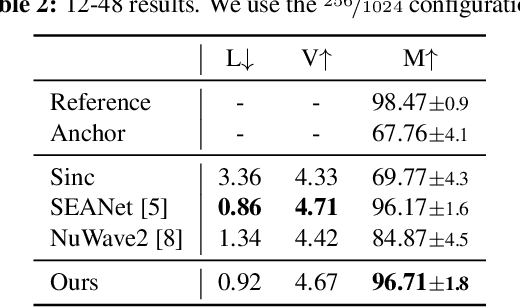
We present AERO, a audio super-resolution model that processes speech and music signals in the spectral domain. AERO is based on an encoder-decoder architecture with U-Net like skip connections. We optimize the model using both time and frequency domain loss functions. Specifically, we consider a set of reconstruction losses together with perceptual ones in the form of adversarial and feature discriminator loss functions. To better handle phase information the proposed method operates over the complex-valued spectrogram using two separate channels. Unlike prior work which mainly considers low and high frequency concatenation for audio super-resolution, the proposed method directly predicts the full frequency range. We demonstrate high performance across a wide range of sample rates considering both speech and music. AERO outperforms the evaluated baselines considering Log-Spectral Distance, ViSQOL, and the subjective MUSHRA test. Audio samples and code are available at https://pages.cs.huji.ac.il/adiyoss-lab/aero
Integrating Intelligent Reflecting Surface into Base Station: Architecture, Channel Model, and Passive Reflection Design
Dec 06, 2022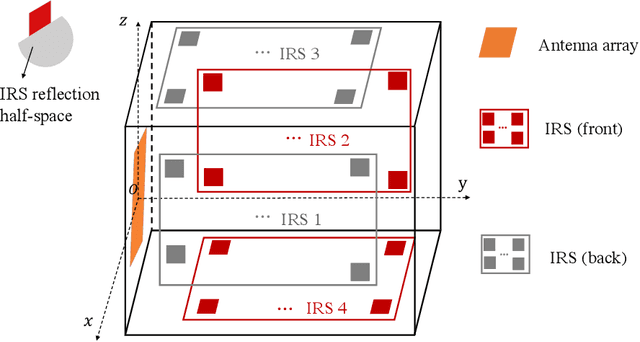
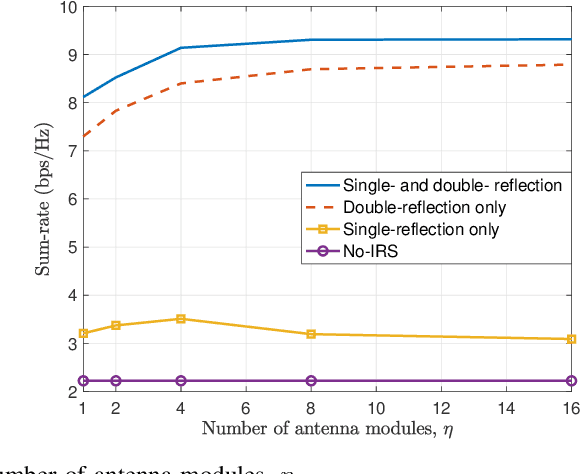
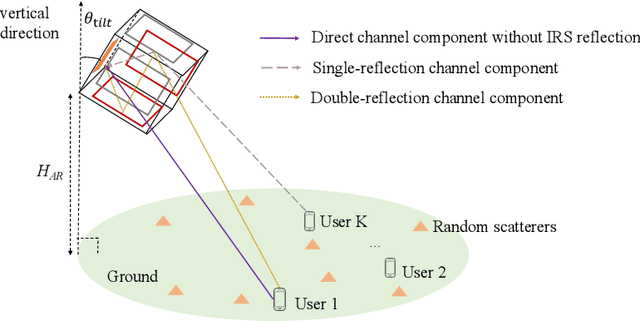
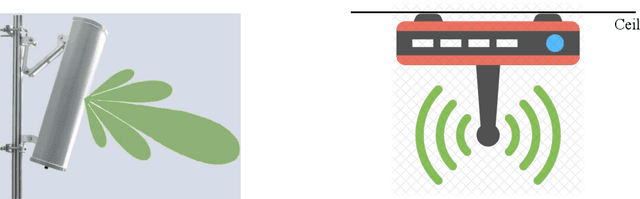
Existing works on IRS have mainly considered IRS being deployed in the environment to dynamically control the wireless channels between the BS and its served users. In contrast, we propose in this paper a new integrated IRS BS architecture by deploying IRSs inside the BS antenna radome. Since the distance between the integrated IRSs and BS antenna array is practically small, the path loss among them is significantly reduced and the real time control of the IRS reflection by the BS becomes easier to implement. However, the resultant near field channel model also becomes drastically different. Thus, we propose an element wise channel model for IRS to characterize the channel vector between each single antenna user and the antenna array of the BS, which includes the direct (without any IRS reflection) as well as the single and double IRS-reflection channel components. Then, we formulate a problem to optimize the reflection coefficients of all IRS reflecting elements for maximizing the uplink sum rate of the users. By considering two typical cases with/without perfect CSI at the BS, the formulated problem is solved efficiently by adopting the successive refinement method and iterative random phase algorithm (IRPA), respectively. Numerical results validate the substantial capacity gain of the integrated IRS BS architecture over the conventional multi antenna BS without integrated IRS. Moreover, the proposed algorithms significantly outperform other benchmark schemes in terms of sum rate, and the IRPA without CSI can approach the performance upper bound with perfect CSI as the training overhead increases.
Time-Series Anomaly Detection with Implicit Neural Representation
Jan 28, 2022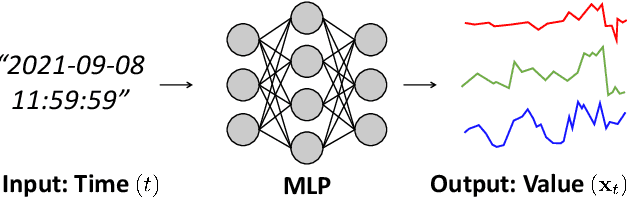
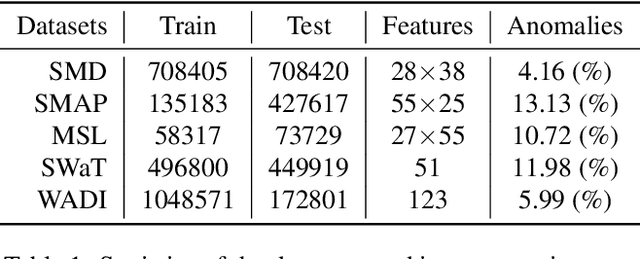
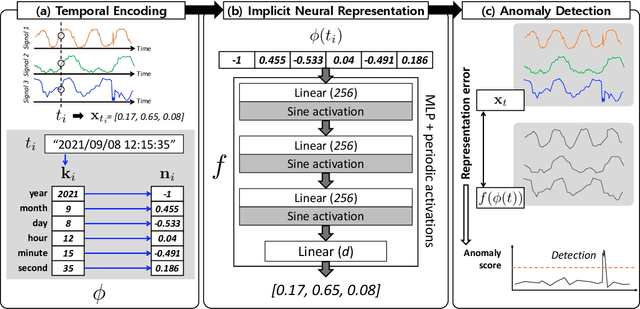
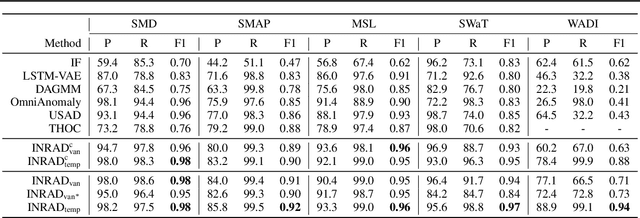
Detecting anomalies in multivariate time-series data is essential in many real-world applications. Recently, various deep learning-based approaches have shown considerable improvements in time-series anomaly detection. However, existing methods still have several limitations, such as long training time due to their complex model designs or costly tuning procedures to find optimal hyperparameters (e.g., sliding window length) for a given dataset. In our paper, we propose a novel method called Implicit Neural Representation-based Anomaly Detection (INRAD). Specifically, we train a simple multi-layer perceptron that takes time as input and outputs corresponding values at that time. Then we utilize the representation error as an anomaly score for detecting anomalies. Experiments on five real-world datasets demonstrate that our proposed method outperforms other state-of-the-art methods in performance, training speed, and robustness.
Evaluating the Perceived Safety of Urban City via Maximum Entropy Deep Inverse Reinforcement Learning
Nov 19, 2022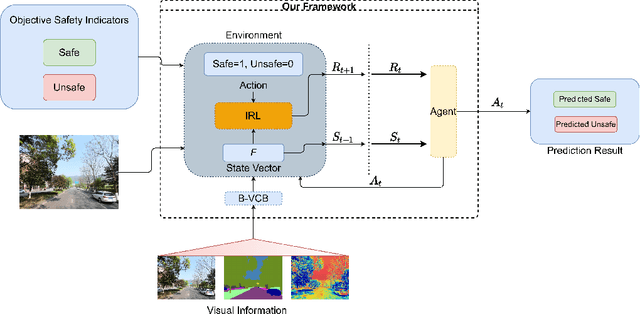


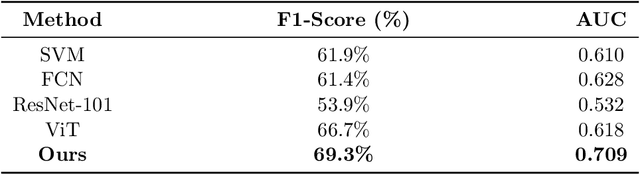
Inspired by expert evaluation policy for urban perception, we proposed a novel inverse reinforcement learning (IRL) based framework for predicting urban safety and recovering the corresponding reward function. We also presented a scalable state representation method to model the prediction problem as a Markov decision process (MDP) and use reinforcement learning (RL) to solve the problem. Additionally, we built a dataset called SmallCity based on the crowdsourcing method to conduct the research. As far as we know, this is the first time the IRL approach has been introduced to the urban safety perception and planning field to help experts quantitatively analyze perceptual features. Our results showed that IRL has promising prospects in this field. We will later open-source the crowdsourcing data collection site and the model proposed in this paper.
Can Gradient Descent Provably Learn Linear Dynamic Systems?
Nov 19, 2022
We study the learning ability of linear recurrent neural networks with gradient descent. We prove the first theoretical guarantee on linear RNNs with Gradient Descent to learn any stable linear dynamic system. We show that despite the non-convexity of the optimization loss if the width of the RNN is large enough (and the required width in hidden layers does not rely on the length of the input sequence), a linear RNN can provably learn any stable linear dynamic system with the sample and time complexity polynomial in $\frac{1}{1-\rho_C}$ where $\rho_C$ is roughly the spectral radius of the stable system. Our results provide the first theoretical guarantee to learn a linear RNN and demonstrate how can the recurrent structure help to learn a dynamic system.
Boosted Ensemble Learning based on Randomized NNs for Time Series Forecasting
Mar 02, 2022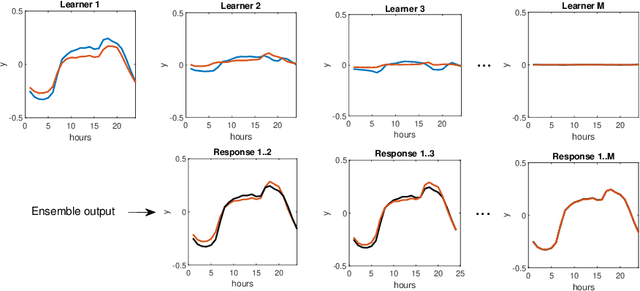
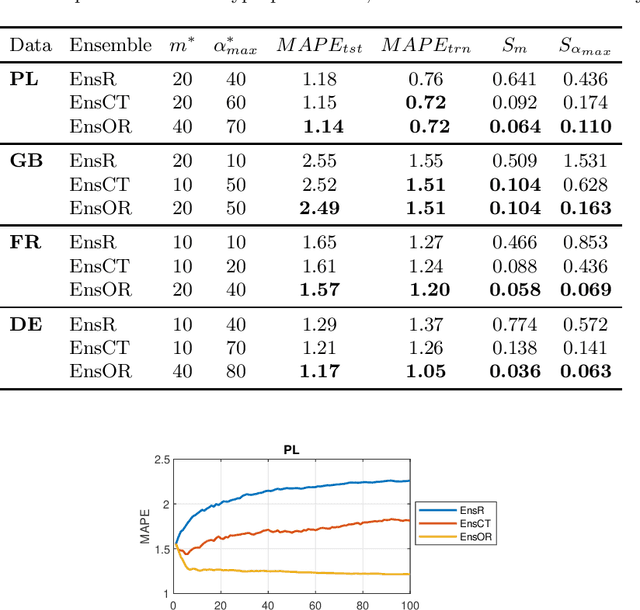
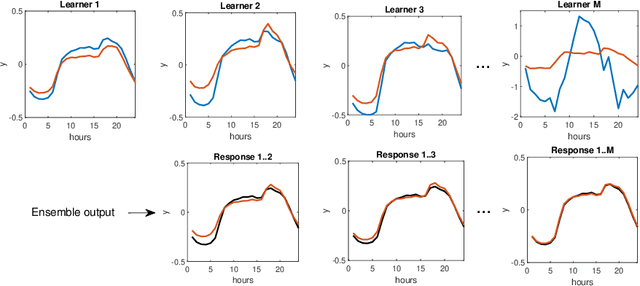
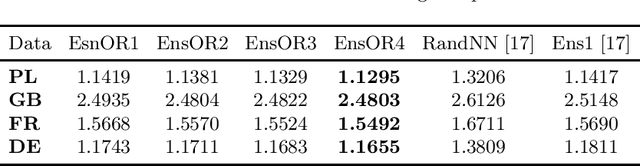
Time series forecasting is a challenging problem particularly when a time series expresses multiple seasonality, nonlinear trend and varying variance. In this work, to forecast complex time series, we propose ensemble learning which is based on randomized neural networks, and boosted in three ways. These comprise ensemble learning based on residuals, corrected targets and opposed response. The latter two methods are employed to ensure similar forecasting tasks are solved by all ensemble members, which justifies the use of exactly the same base models at all stages of ensembling. Unification of the tasks for all members simplifies ensemble learning and leads to increased forecasting accuracy. This was confirmed in an experimental study involving forecasting time series with triple seasonality, in which we compare our three variants of ensemble boosting. The strong points of the proposed ensembles based on RandNNs are extremely rapid training and pattern-based time series representation, which extracts relevant information from time series.
Heterogeneous Graph Sparsification for Efficient Representation Learning
Nov 14, 2022
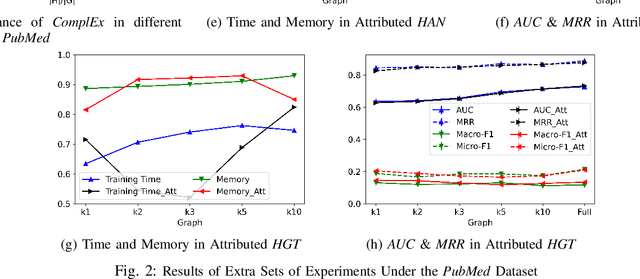
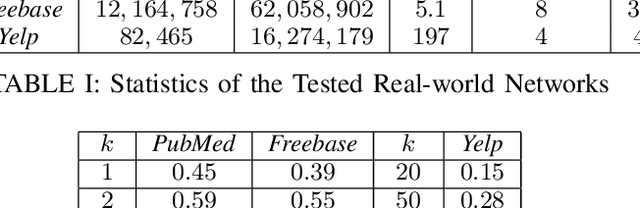
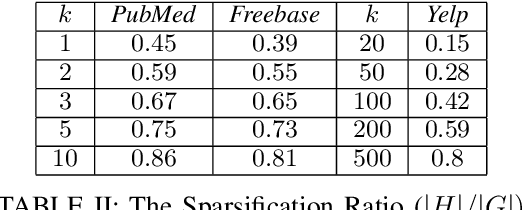
Graph sparsification is a powerful tool to approximate an arbitrary graph and has been used in machine learning over homogeneous graphs. In heterogeneous graphs such as knowledge graphs, however, sparsification has not been systematically exploited to improve efficiency of learning tasks. In this work, we initiate the study on heterogeneous graph sparsification and develop sampling-based algorithms for constructing sparsifiers that are provably sparse and preserve important information in the original graphs. We have performed extensive experiments to confirm that the proposed method can improve time and space complexities of representation learning while achieving comparable, or even better performance in subsequent graph learning tasks based on the learned embedding.