 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluating the Perceived Safety of Urban City via Maximum Entropy Deep Inverse Reinforcement Learning
Nov 19, 2022
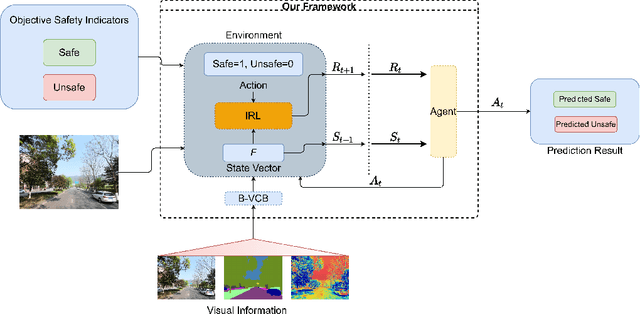


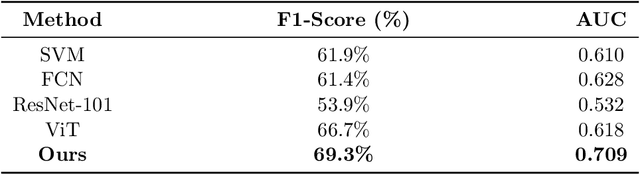
Inspired by expert evaluation policy for urban perception, we proposed a novel inverse reinforcement learning (IRL) based framework for predicting urban safety and recovering the corresponding reward function. We also presented a scalable state representation method to model the prediction problem as a Markov decision process (MDP) and use reinforcement learning (RL) to solve the problem. Additionally, we built a dataset called SmallCity based on the crowdsourcing method to conduct the research. As far as we know, this is the first time the IRL approach has been introduced to the urban safety perception and planning field to help experts quantitatively analyze perceptual features. Our results showed that IRL has promising prospects in this field. We will later open-source the crowdsourcing data collection site and the model proposed in this paper.
Can Gradient Descent Provably Learn Linear Dynamic Systems?
Nov 19, 2022
We study the learning ability of linear recurrent neural networks with gradient descent. We prove the first theoretical guarantee on linear RNNs with Gradient Descent to learn any stable linear dynamic system. We show that despite the non-convexity of the optimization loss if the width of the RNN is large enough (and the required width in hidden layers does not rely on the length of the input sequence), a linear RNN can provably learn any stable linear dynamic system with the sample and time complexity polynomial in $\frac{1}{1-\rho_C}$ where $\rho_C$ is roughly the spectral radius of the stable system. Our results provide the first theoretical guarantee to learn a linear RNN and demonstrate how can the recurrent structure help to learn a dynamic system.
Video-ReTime: Learning Temporally Varying Speediness for Time Remapping
May 11, 2022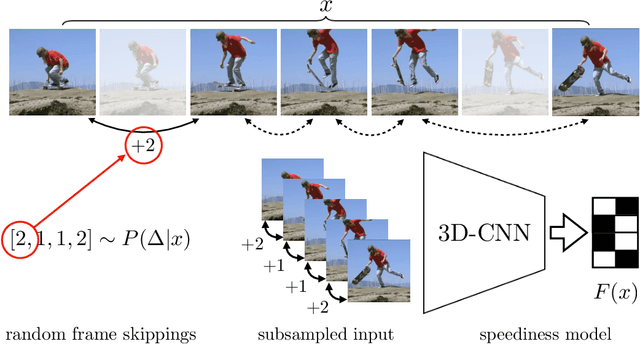
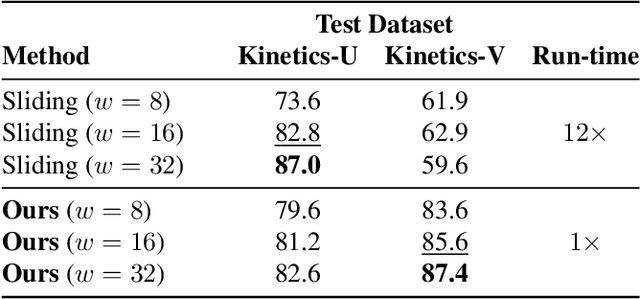
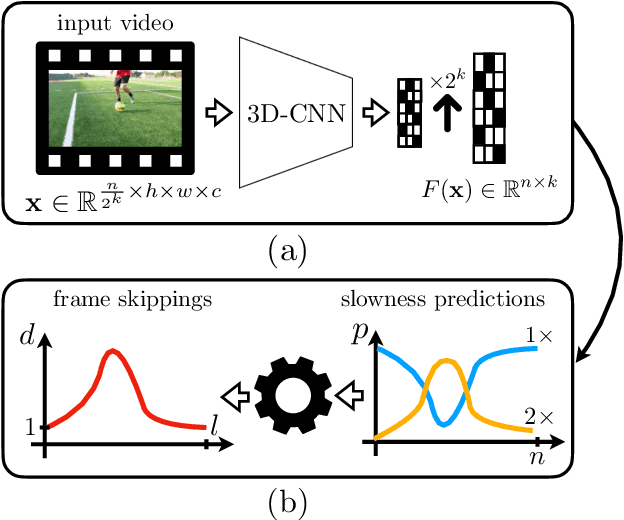
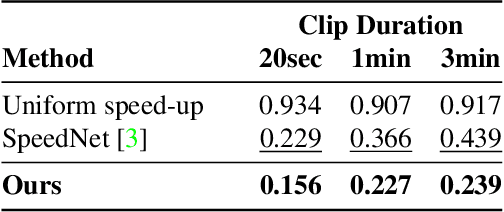
We propose a method for generating a temporally remapped video that matches the desired target duration while maximally preserving natural video dynamics. Our approach trains a neural network through self-supervision to recognize and accurately localize temporally varying changes in the video playback speed. To re-time videos, we 1. use the model to infer the slowness of individual video frames, and 2. optimize the temporal frame sub-sampling to be consistent with the model's slowness predictions. We demonstrate that this model can detect playback speed variations more accurately while also being orders of magnitude more efficient than prior approaches. Furthermore, we propose an optimization for video re-timing that enables precise control over the target duration and performs more robustly on longer videos than prior methods. We evaluate the model quantitatively on artificially speed-up videos, through transfer to action recognition, and qualitatively through user studies.
MiLMo:Minority Multilingual Pre-trained Language Model
Dec 04, 2022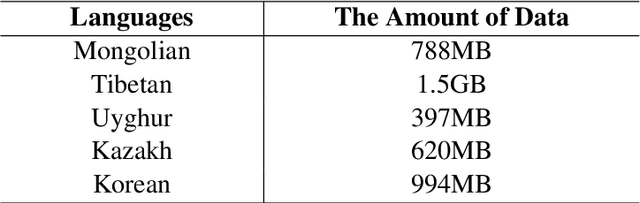
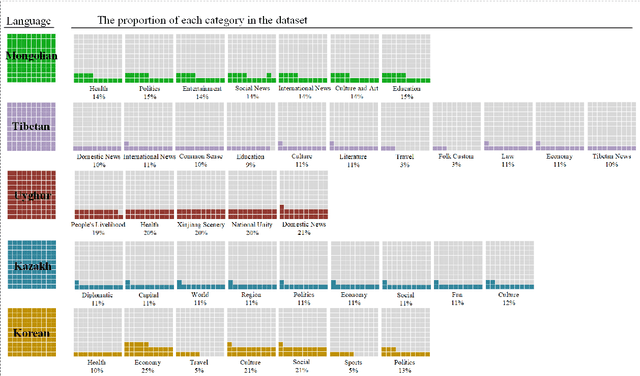

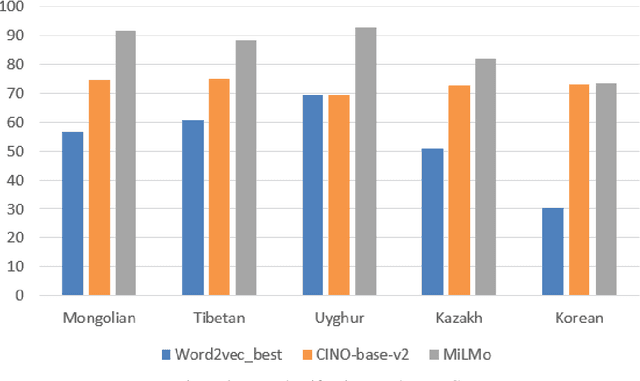
Pre-trained language models are trained on large-scale unsupervised data, and they can be fine-tuned on small-scale labeled datasets and achieve good results. Multilingual pre-trained language models can be trained on multiple languages and understand multiple languages at the same time. At present, the research on pre-trained models mainly focuses on rich-resource language, while there is relatively little research on low-resource languages such as minority languages, and the public multilingual pre-trained language model can not work well for minority languages. Therefore, this paper constructs a multilingual pre-trained language model named MiLMo that performs better on minority language tasks, including Mongolian, Tibetan, Uyghur, Kazakh and Korean. To solve the problem of scarcity of datasets on minority languages and verify the effectiveness of the MiLMo model, this paper constructs a minority multilingual text classification dataset named MiTC, and trains a word2vec model for each language. By comparing the word2vec model and the pre-trained model in the text classification task, this paper provides an optimal scheme for the downstream task research of minority languages. The final experimental results show that the performance of the pre-trained model is better than that of the word2vec model, and it has achieved the best results in minority multilingual text classification. The multilingual pre-trained language model MiLMo, multilingual word2vec model and multilingual text classification dataset MiTC are published on https://milmo.cmli-nlp.com.
Remote estimation of geologic composition using interferometric synthetic-aperture radar in California's Central Valley
Dec 04, 2022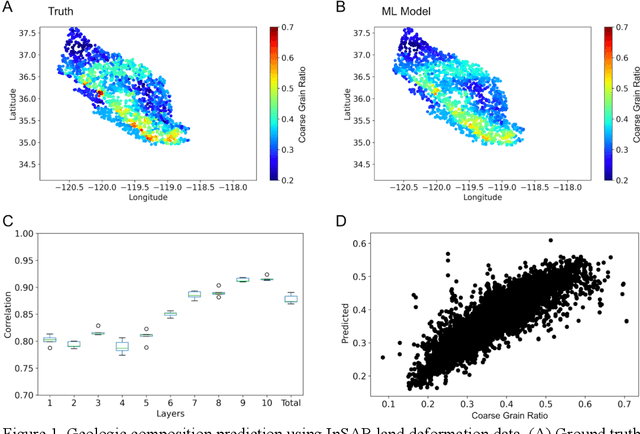
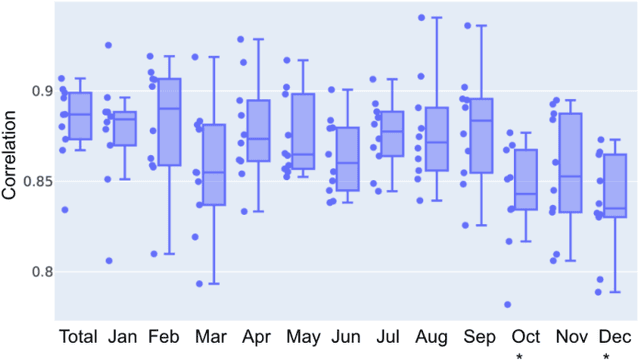
California's Central Valley is the national agricultural center, producing 1/4 of the nation's food. However, land in the Central Valley is sinking at a rapid rate (as much as 20 cm per year) due to continued groundwater pumping. Land subsidence has a significant impact on infrastructure resilience and groundwater sustainability. In this study, we aim to identify specific regions with different temporal dynamics of land displacement and find relationships with underlying geological composition. Then, we aim to remotely estimate geologic composition using interferometric synthetic aperture radar (InSAR)-based land deformation temporal changes using machine learning techniques. We identified regions with different temporal characteristics of land displacement in that some areas (e.g., Helm) with coarser grain geologic compositions exhibited potentially reversible land deformation (elastic land compaction). We found a significant correlation between InSAR-based land deformation and geologic composition using random forest and deep neural network regression models. We also achieved significant accuracy with 1/4 sparse sampling to reduce any spatial correlations among data, suggesting that the model has the potential to be generalized to other regions for indirect estimation of geologic composition. Our results indicate that geologic composition can be estimated using InSAR-based land deformation data. In-situ measurements of geologic composition can be expensive and time consuming and may be impractical in some areas. The generalizability of the model sheds light on high spatial resolution geologic composition estimation utilizing existing measurements.
CIM: Constrained Intrinsic Motivation for Sparse-Reward Continuous Control
Nov 28, 2022
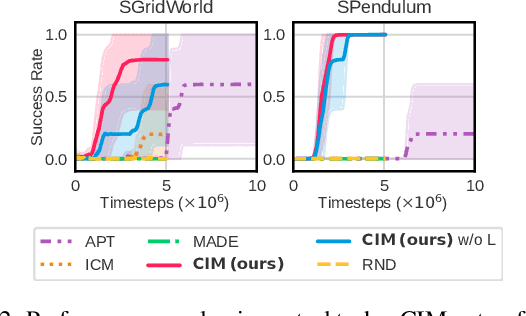

Intrinsic motivation is a promising exploration technique for solving reinforcement learning tasks with sparse or absent extrinsic rewards. There exist two technical challenges in implementing intrinsic motivation: 1) how to design a proper intrinsic objective to facilitate efficient exploration; and 2) how to combine the intrinsic objective with the extrinsic objective to help find better solutions. In the current literature, the intrinsic objectives are all designed in a task-agnostic manner and combined with the extrinsic objective via simple addition (or used by itself for reward-free pre-training). In this work, we show that these designs would fail in typical sparse-reward continuous control tasks. To address the problem, we propose Constrained Intrinsic Motivation (CIM) to leverage readily attainable task priors to construct a constrained intrinsic objective, and at the same time, exploit the Lagrangian method to adaptively balance the intrinsic and extrinsic objectives via a simultaneous-maximization framework. We empirically show, on multiple sparse-reward continuous control tasks, that our CIM approach achieves greatly improved performance and sample efficiency over state-of-the-art methods. Moreover, the key techniques of our CIM can also be plugged into existing methods to boost their performances.
A Bayesian Approach to Reconstructing Interdependent Infrastructure Networks from Cascading Failures
Nov 28, 2022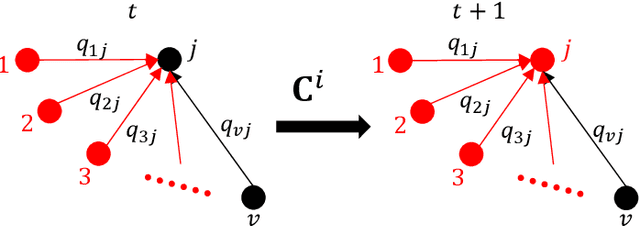
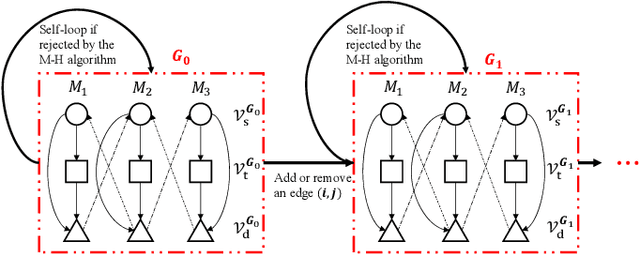
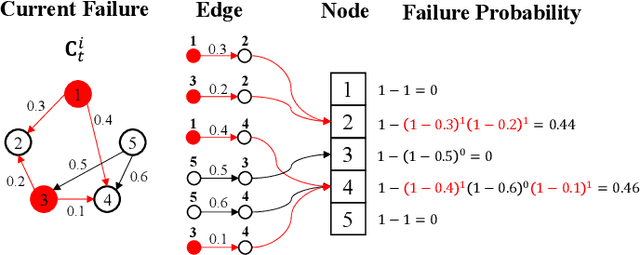
Analyzing the behavior of complex interdependent networks requires complete information about the network topology and the interdependent links across networks. For many applications such as critical infrastructure systems, understanding network interdependencies is crucial to anticipate cascading failures and plan for disruptions. However, data on the topology of individual networks are often publicly unavailable due to privacy and security concerns. Additionally, interdependent links are often only revealed in the aftermath of a disruption as a result of cascading failures. We propose a scalable nonparametric Bayesian approach to reconstruct the topology of interdependent infrastructure networks from observations of cascading failures. Metropolis-Hastings algorithm coupled with the infrastructure-dependent proposal are employed to increase the efficiency of sampling possible graphs. Results of reconstructing a synthetic system of interdependent infrastructure networks demonstrate that the proposed approach outperforms existing methods in both accuracy and computational time. We further apply this approach to reconstruct the topology of one synthetic and two real-world systems of interdependent infrastructure networks, including gas-power-water networks in Shelby County, TN, USA, and an interdependent system of power-water networks in Italy, to demonstrate the general applicability of the approach.
Cell Biomechanical Modeling Based on Membrane Theory with Considering Speed Effect of Microinjection
Nov 28, 2022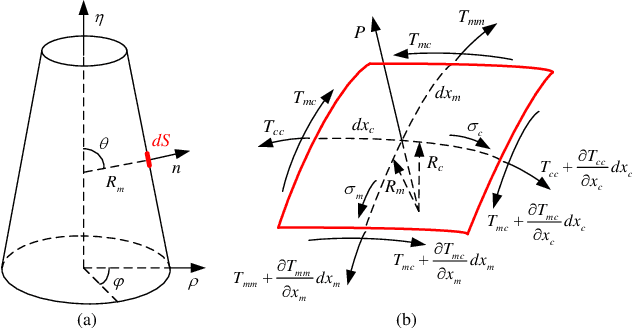
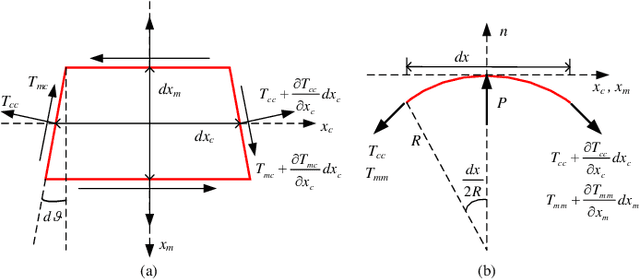
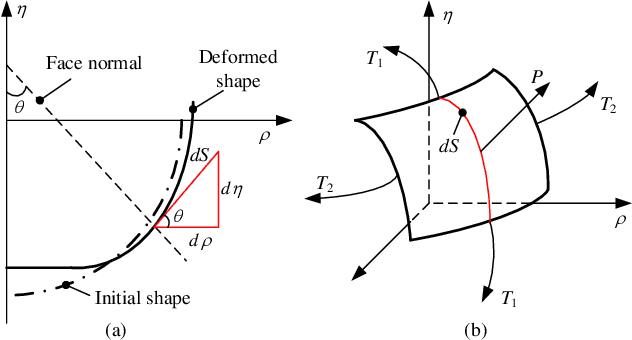
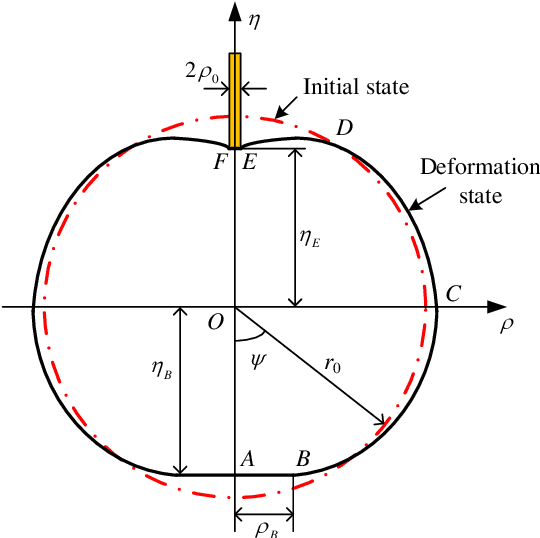
As an effective method to deliver external materials into biological cells, microinjection has been widely applied in the biomedical field. However, the cognition of cell mechanical property is still inadequate, which greatly limits the efficiency and success rate of injection. Thus, a new rate-dependent mechanical model based on membrane theory is proposed for the first time. In this model, an analytical equilibrium equation between the injection force and cell deformation is established by considering the speed effect of microinjection. Different from the traditional membrane-theory-based model, the elastic coefficient of the constitutive material in the proposed model is modified as a function of the injection velocity and acceleration, effectively simulating the influence of speeds on the mechanical responses and providing a more generalized and practical model. Using this model, other mechanical responses at different speeds can be also accurately predicted, including the distribution of membrane tension and stress and the deformed shape. To verify the validity of the model, numerical simulations and experiments are carried out. The results show that the proposed model can match the real mechanical responses well at different injection speeds.
Efficient Mirror Detection via Multi-level Heterogeneous Learning
Nov 28, 2022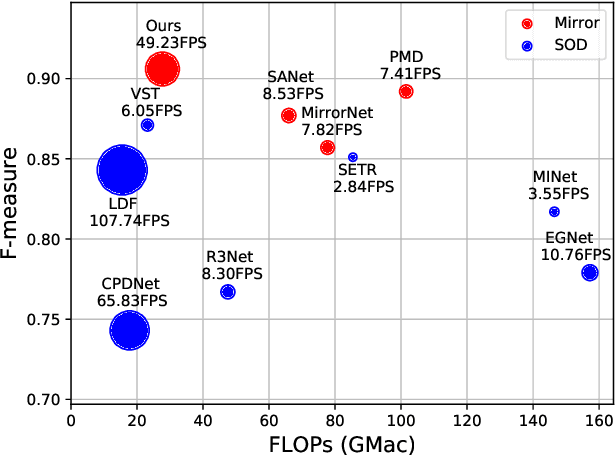
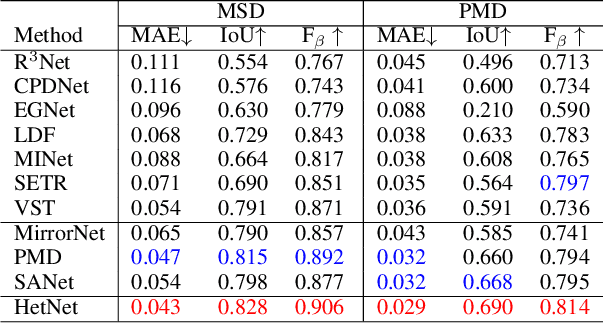
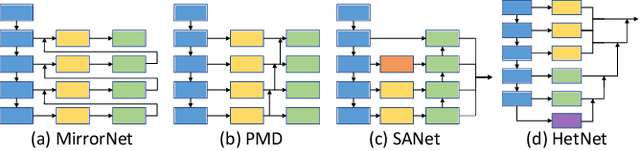
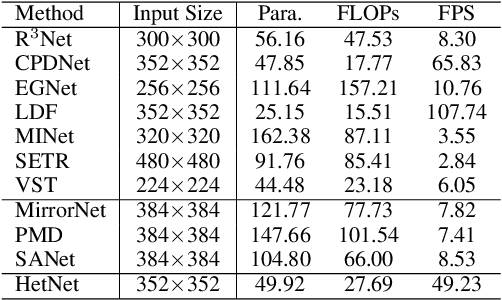
We present HetNet (Multi-level \textbf{Het}erogeneous \textbf{Net}work), a highly efficient mirror detection network. Current mirror detection methods focus more on performance than efficiency, limiting the real-time applications (such as drones). Their lack of efficiency is aroused by the common design of adopting homogeneous modules at different levels, which ignores the difference between different levels of features. In contrast, HetNet detects potential mirror regions initially through low-level understandings (\textit{e.g.}, intensity contrasts) and then combines with high-level understandings (contextual discontinuity for instance) to finalize the predictions. To perform accurate yet efficient mirror detection, HetNet follows an effective architecture that obtains specific information at different stages to detect mirrors. We further propose a multi-orientation intensity-based contrasted module (MIC) and a reflection semantic logical module (RSL), equipped on HetNet, to predict potential mirror regions by low-level understandings and analyze semantic logic in scenarios by high-level understandings, respectively. Compared to the state-of-the-art method, HetNet runs 664$\%$ faster and draws an average performance gain of 8.9$\%$ on MAE, 3.1$\%$ on IoU, and 2.0$\%$ on F-measure on two mirror detection benchmarks.
Time Domain Adversarial Voice Conversion for ADD 2022
Apr 20, 2022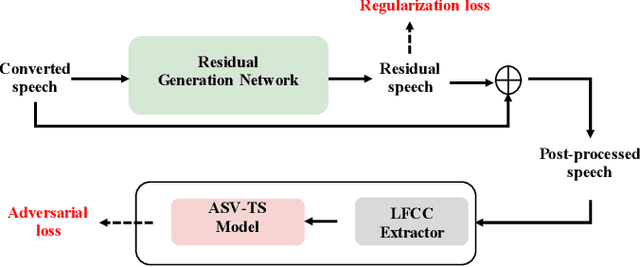

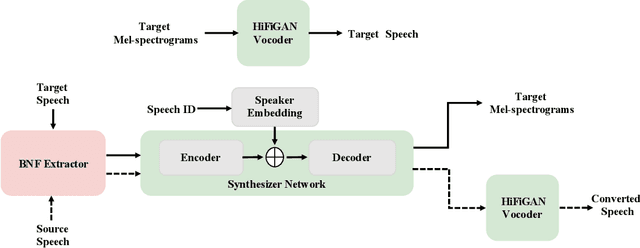
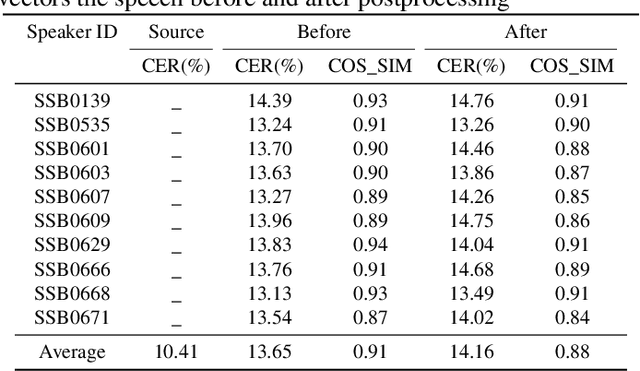
In this paper, we describe our speech generation system for the first Audio Deep Synthesis Detection Challenge (ADD 2022). Firstly, we build an any-to-many voice conversion (VC) system to convert source speech with arbitrary language content into the target speaker%u2019s fake speech. Then the converted speech generated from VC is post-processed in the time domain to improve the deception ability. The experimental results show that our system has adversarial ability against anti-spoofing detectors with a little compromise in audio quality and speaker similarity. This system ranks top in Track 3.1 in the ADD 2022, showing that our method could also gain good generalization ability against different detectors.