 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Refining time-space traffic diagrams: A multiple linear regression model
Apr 09, 2022
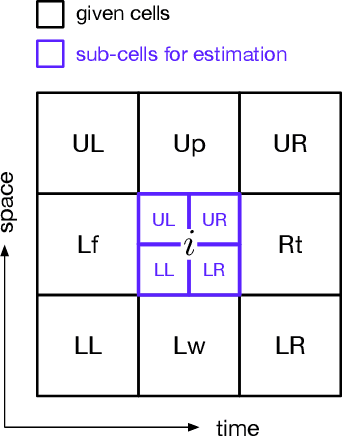
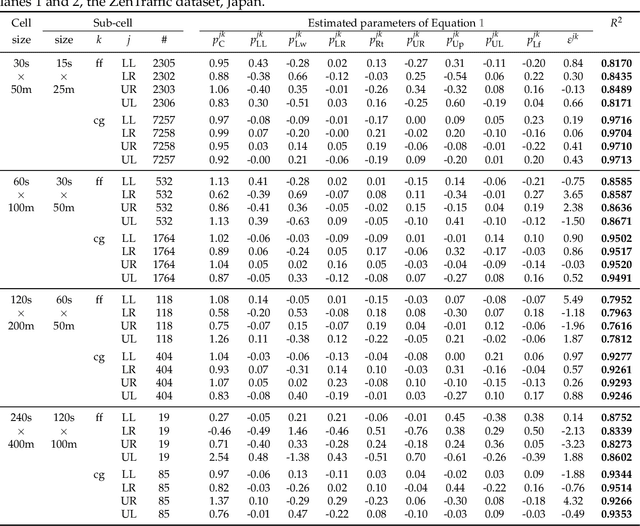
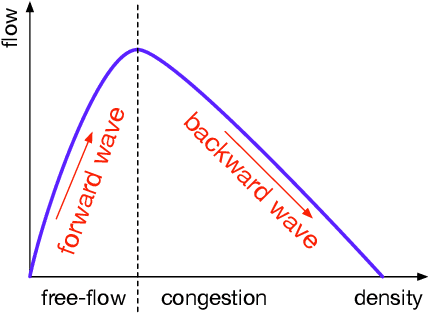
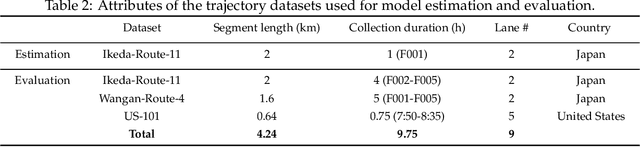
A time-space traffic (TS) diagram that presents traffic states in time-space cells with colors is one of the most important traffic analysis and visualization tools. Despite its importance for transportation research and engineering, most TS diagrams that have already existed or are being produced are too coarse to exhibit detailed traffic dynamics due to the limitation of the current information technology and traffic infrastructure investment. To increase the resolution of a TS diagram and make it present more traffic details, this paper introduces a TS diagram refinement problem and proposes a multiple linear regression-based model to solve the problem. Two tests, which attempt to increase the resolution of a TS diagram for 4 and 16 times, respectively, are carried out to evaluate the performance of the proposed model. The data collected from different time, different location and even different country is involved to thoroughly evaluate the accuracy and transferability of the proposed model. The strict tests with diverse data show that the proposed model, although it is simple in form, is able to refine a TS diagram with a promising accuracy and reliable transferability. The proposed refinement model will "save" those widely-existing TS diagrams from their blurry "faces" and make it possible to learn more traffic details from those TS diagrams.
Nonlinear controllability and function representation by neural stochastic differential equations
Dec 01, 2022There has been a great deal of recent interest in learning and approximation of functions that can be expressed as expectations of a given nonlinearity with respect to its random internal parameters. Examples of such representations include "infinitely wide" neural nets, where the underlying nonlinearity is given by the activation function of an individual neuron. In this paper, we bring this perspective to function representation by neural stochastic differential equations (SDEs). A neural SDE is an It\^o diffusion process whose drift and diffusion matrix are elements of some parametric families. We show that the ability of a neural SDE to realize nonlinear functions of its initial condition can be related to the problem of optimally steering a certain deterministic dynamical system between two given points in finite time. This auxiliary system is obtained by formally replacing the Brownian motion in the SDE by a deterministic control input. We derive upper and lower bounds on the minimum control effort needed to accomplish this steering; these bounds may be of independent interest in the context of motion planning and deterministic optimal control.
Language Model Pre-training on True Negatives
Dec 01, 2022
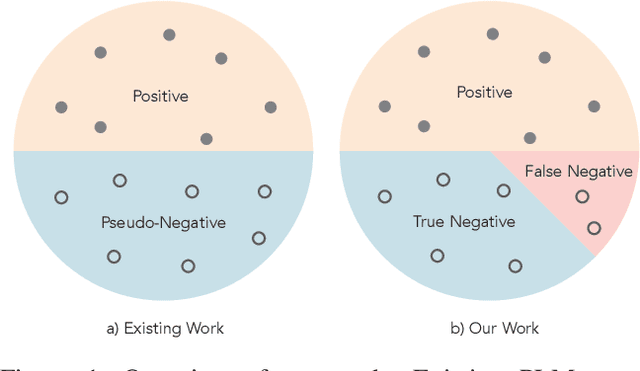
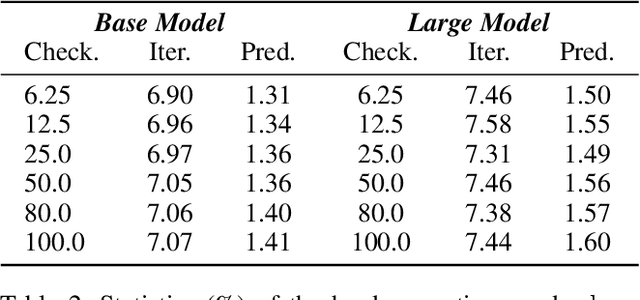
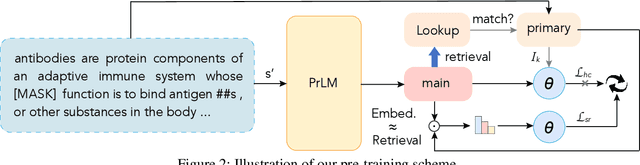
Discriminative pre-trained language models (PLMs) learn to predict original texts from intentionally corrupted ones. Taking the former text as positive and the latter as negative samples, the PLM can be trained effectively for contextualized representation. However, the training of such a type of PLMs highly relies on the quality of the automatically constructed samples. Existing PLMs simply treat all corrupted texts as equal negative without any examination, which actually lets the resulting model inevitably suffer from the false negative issue where training is carried out on pseudo-negative data and leads to less efficiency and less robustness in the resulting PLMs. In this work, on the basis of defining the false negative issue in discriminative PLMs that has been ignored for a long time, we design enhanced pre-training methods to counteract false negative predictions and encourage pre-training language models on true negatives by correcting the harmful gradient updates subject to false negative predictions. Experimental results on GLUE and SQuAD benchmarks show that our counter-false-negative pre-training methods indeed bring about better performance together with stronger robustness.
Enabling Fast Unit Commitment Constraint Screening via Learning Cost Model
Dec 01, 2022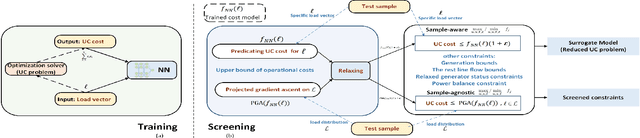
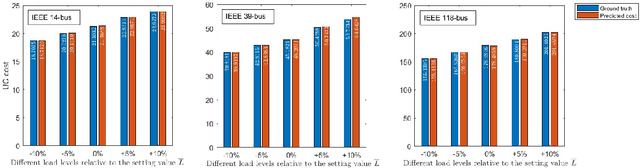
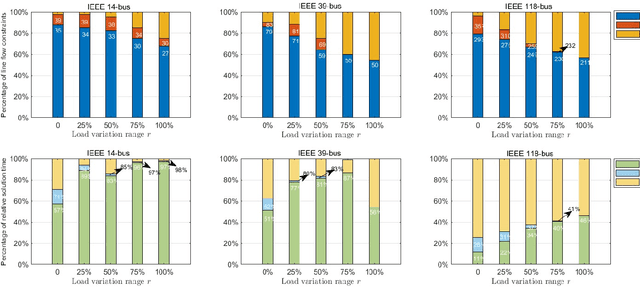
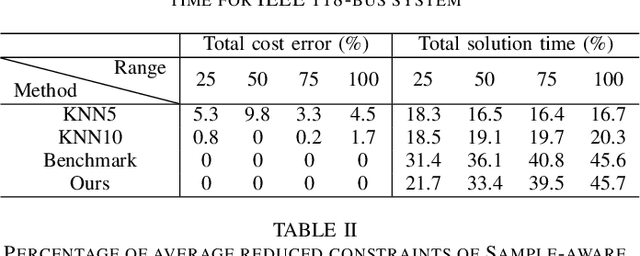
Unit commitment (UC) are essential tools to transmission system operators for finding the most economical and feasible generation schedules and dispatch signals. Constraint screening has been receiving attention as it holds the promise for reducing a number of inactive or redundant constraints in the UC problem, so that the solution process of large scale UC problem can be accelerated by considering the reduced optimization problem. Standard constraint screening approach relies on optimizing over load and generations to find binding line flow constraints, yet the screening is conservative with a large percentage of constraints still reserved for the UC problem. In this paper, we propose a novel machine learning (ML) model to predict the most economical costs given load inputs. Such ML model bridges the cost perspectives of UC decisions to the optimization-based constraint screening model, and can screen out higher proportion of operational constraints. We verify the proposed method's performance on both sample-aware and sample-agnostic setting, and illustrate the proposed scheme can further reduce the computation time on a variety of setup for UC problems.
IRRGN: An Implicit Relational Reasoning Graph Network for Multi-turn Response Selection
Dec 01, 2022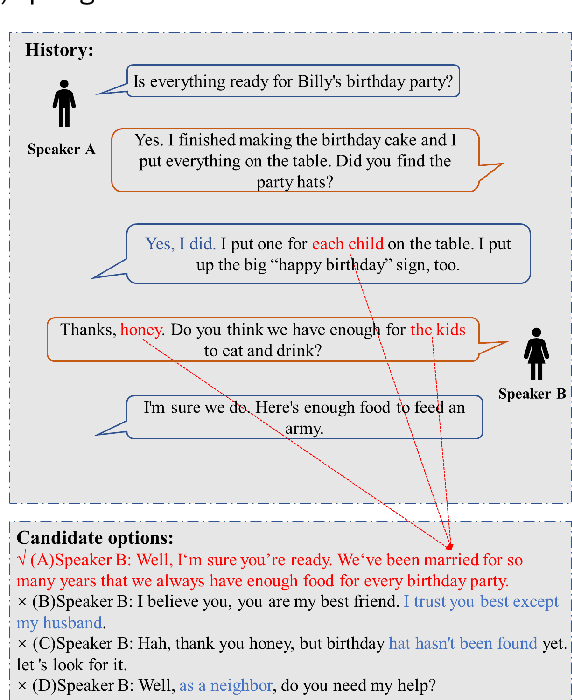
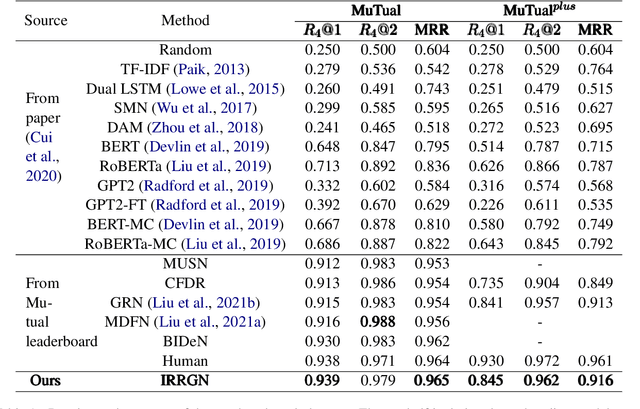
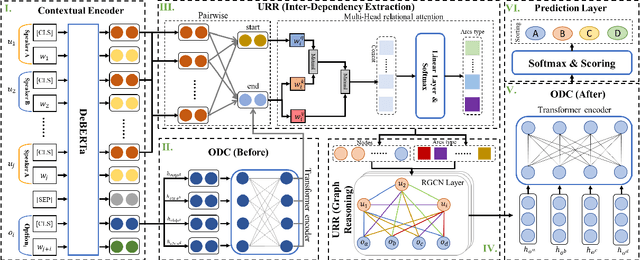
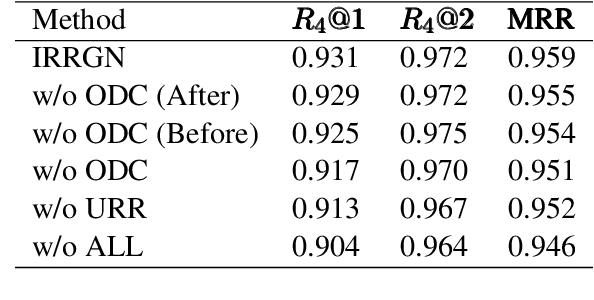
The task of response selection in multi-turn dialogue is to find the best option from all candidates. In order to improve the reasoning ability of the model, previous studies pay more attention to using explicit algorithms to model the dependencies between utterances, which are deterministic, limited and inflexible. In addition, few studies consider differences between the options before and after reasoning. In this paper, we propose an Implicit Relational Reasoning Graph Network to address these issues, which consists of the Utterance Relational Reasoner (URR) and the Option Dual Comparator (ODC). URR aims to implicitly extract dependencies between utterances, as well as utterances and options, and make reasoning with relational graph convolutional networks. ODC focuses on perceiving the difference between the options through dual comparison, which can eliminate the interference of the noise options. Experimental results on two multi-turn dialogue reasoning benchmark datasets MuTual and MuTual+ show that our method significantly improves the baseline of four pretrained language models and achieves state-of-the-art performance. The model surpasses human performance for the first time on the MuTual dataset.
PartAL: Efficient Partial Active Learning in Multi-Task Visual Settings
Nov 21, 2022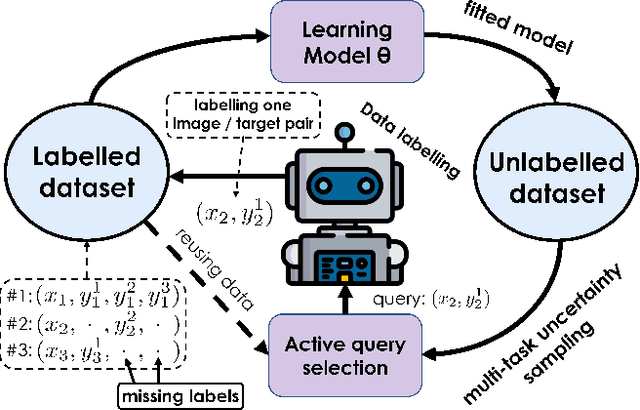
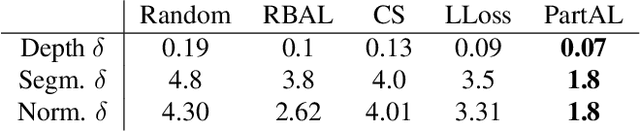

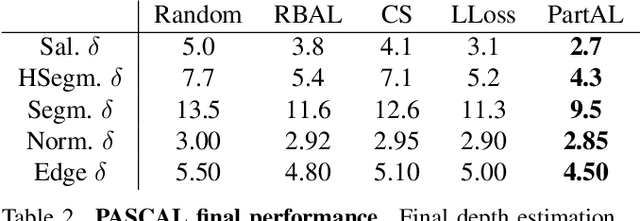
Multi-task learning is central to many real-world applications. Unfortunately, obtaining labelled data for all tasks is time-consuming, challenging, and expensive. Active Learning (AL) can be used to reduce this burden. Existing techniques typically involve picking images to be annotated and providing annotations for all tasks. In this paper, we show that it is more effective to select not only the images to be annotated but also a subset of tasks for which to provide annotations at each AL iteration. Furthermore, the annotations that are provided can be used to guess pseudo-labels for the tasks that remain unannotated. We demonstrate the effectiveness of our approach on several popular multi-task datasets.
Differentiable Physics-based Greenhouse Simulation
Nov 21, 2022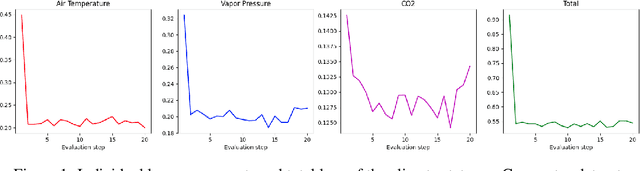
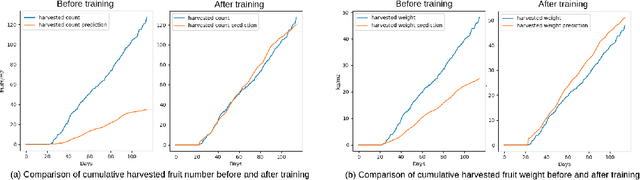
We present a differentiable greenhouse simulation model based on physical processes whose parameters can be obtained by training from real data. The physics-based simulation model is fully interpretable and is able to do state prediction for both climate and crop dynamics in the greenhouse over very a long time horizon. The model works by constructing a system of linear differential equations and solving them to obtain the next state. We propose a procedure to solve the differential equations, handle the problem of missing unobservable states in the data, and train the model efficiently. Our experiment shows the procedure is effective. The model improves significantly after training and can simulate a greenhouse that grows cucumbers accurately.
EDGE: Editable Dance Generation From Music
Nov 27, 2022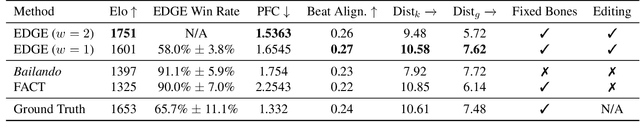
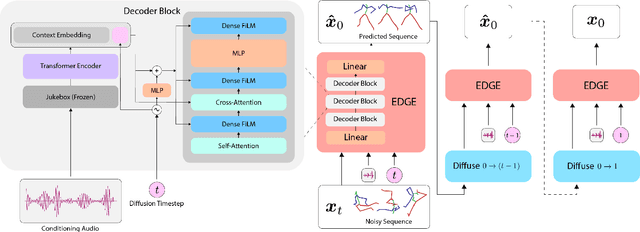
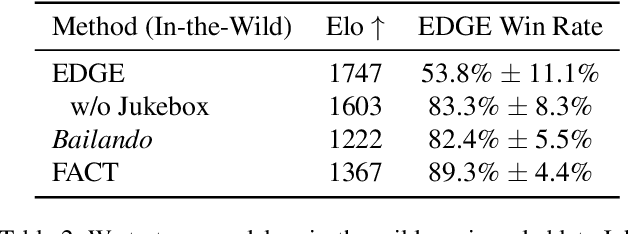
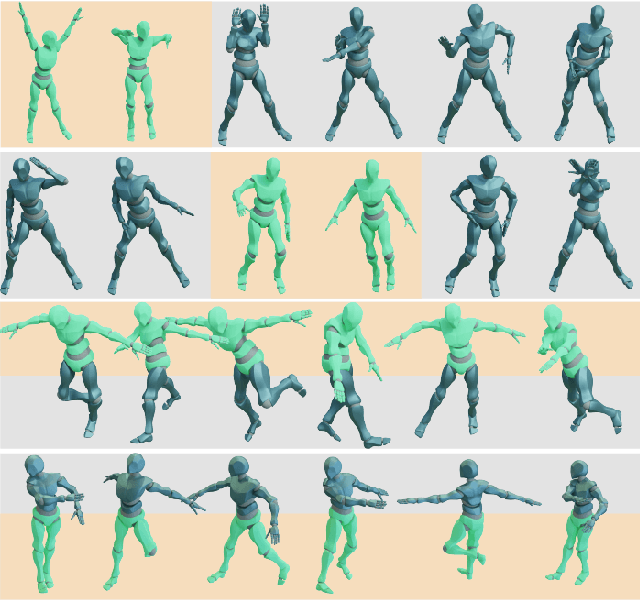
Dance is an important human art form, but creating new dances can be difficult and time-consuming. In this work, we introduce Editable Dance GEneration (EDGE), a state-of-the-art method for editable dance generation that is capable of creating realistic, physically-plausible dances while remaining faithful to the input music. EDGE uses a transformer-based diffusion model paired with Jukebox, a strong music feature extractor, and confers powerful editing capabilities well-suited to dance, including joint-wise conditioning, and in-betweening. We introduce a new metric for physical plausibility, and evaluate dance quality generated by our method extensively through (1) multiple quantitative metrics on physical plausibility, beat alignment, and diversity benchmarks, and more importantly, (2) a large-scale user study, demonstrating a significant improvement over previous state-of-the-art methods. Qualitative samples from our model can be found at our website.
THMA: Tencent HD Map AI System for Creating HD Map Annotations
Dec 14, 2022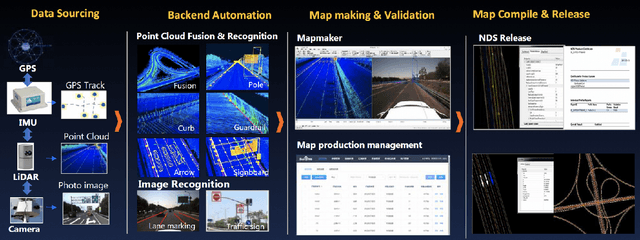
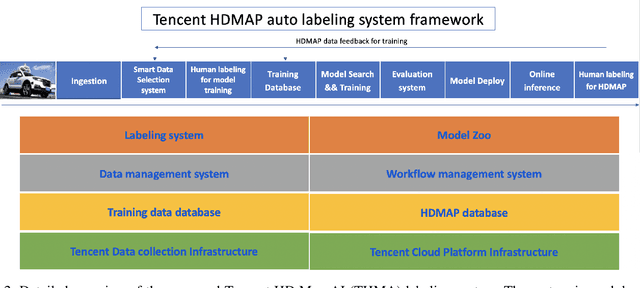

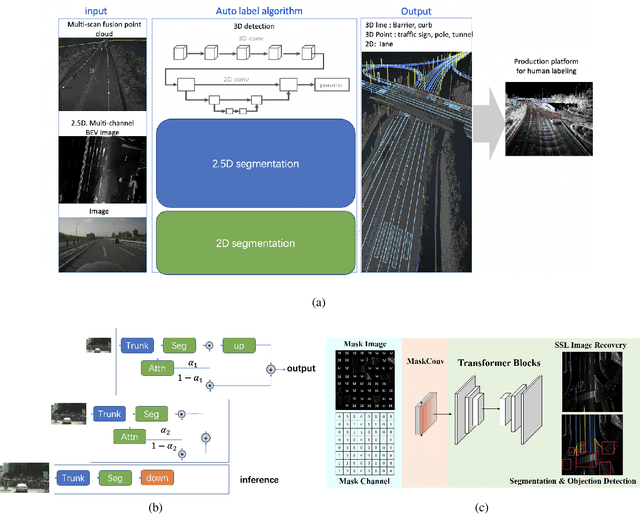
Nowadays, autonomous vehicle technology is becoming more and more mature. Critical to progress and safety, high-definition (HD) maps, a type of centimeter-level map collected using a laser sensor, provide accurate descriptions of the surrounding environment. The key challenge of HD map production is efficient, high-quality collection and annotation of large-volume datasets. Due to the demand for high quality, HD map production requires significant manual human effort to create annotations, a very time-consuming and costly process for the map industry. In order to reduce manual annotation burdens, many artificial intelligence (AI) algorithms have been developed to pre-label the HD maps. However, there still exists a large gap between AI algorithms and the traditional manual HD map production pipelines in accuracy and robustness. Furthermore, it is also very resource-costly to build large-scale annotated datasets and advanced machine learning algorithms for AI-based HD map automatic labeling systems. In this paper, we introduce the Tencent HD Map AI (THMA) system, an innovative end-to-end, AI-based, active learning HD map labeling system capable of producing and labeling HD maps with a scale of hundreds of thousands of kilometers. In THMA, we train AI models directly from massive HD map datasets via supervised, self-supervised, and weakly supervised learning to achieve high accuracy and efficiency required by downstream users. THMA has been deployed by the Tencent Map team to provide services to downstream companies and users, serving over 1,000 labeling workers and producing more than 30,000 kilometers of HD map data per day at most. More than 90 percent of the HD map data in Tencent Map is labeled automatically by THMA, accelerating the traditional HD map labeling process by more than ten times.
Plastic Contaminant Detection in Aerial Imagery of Cotton Fields with Deep Learning
Dec 14, 2022

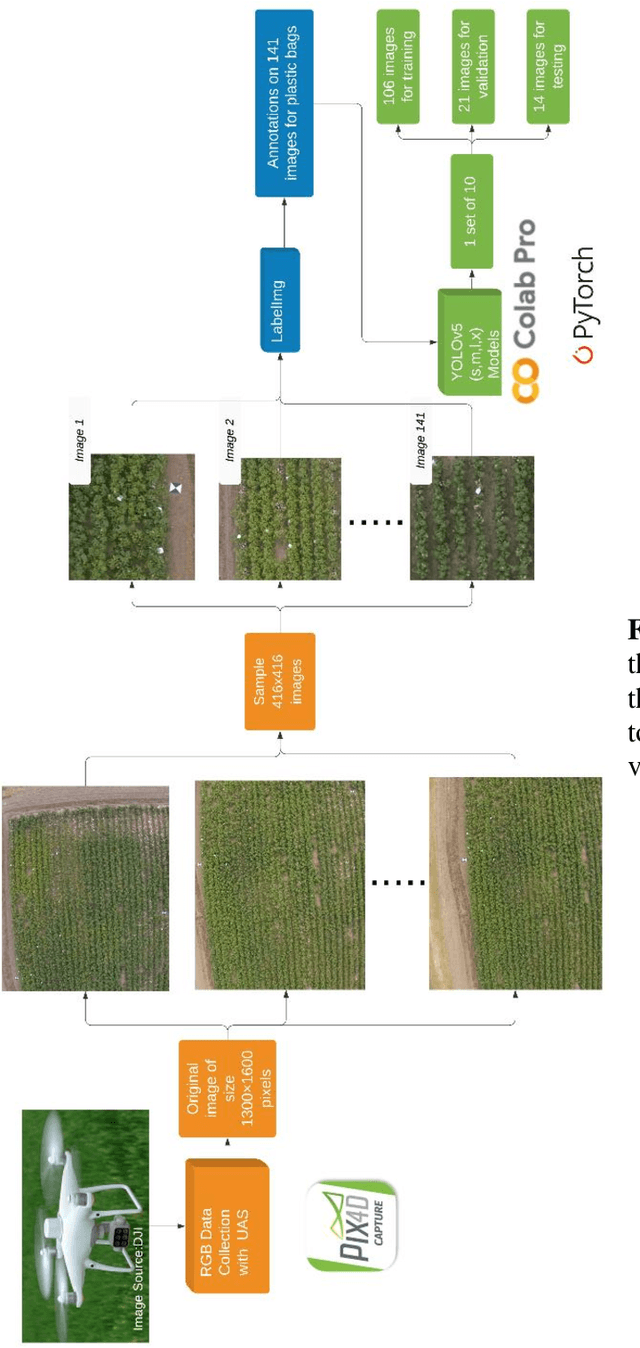
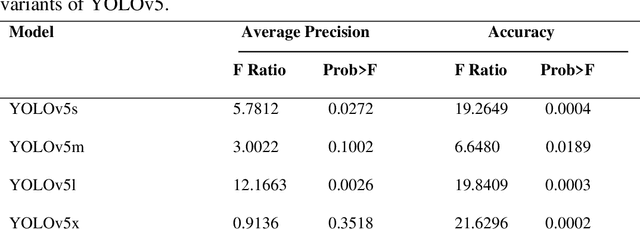
Plastic shopping bags that get carried away from the side of roads and tangled on cotton plants can end up at cotton gins if not removed before the harvest. Such bags may not only cause problem in the ginning process but might also get embodied in cotton fibers reducing its quality and marketable value. Therefore, it is required to detect, locate, and remove the bags before cotton is harvested. Manually detecting and locating these bags in cotton fields is labor intensive, time-consuming and a costly process. To solve these challenges, we present application of four variants of YOLOv5 (YOLOv5s, YOLOv5m, YOLOv5l and YOLOv5x) for detecting plastic shopping bags using Unmanned Aircraft Systems (UAS)-acquired RGB (Red, Green, and Blue) images. We also show fixed effect model tests of color of plastic bags as well as YOLOv5-variant on average precision (AP), mean average precision (mAP@50) and accuracy. In addition, we also demonstrate the effect of height of plastic bags on the detection accuracy. It was found that color of bags had significant effect (p < 0.001) on accuracy across all the four variants while it did not show any significant effect on the AP with YOLOv5m (p = 0.10) and YOLOv5x (p = 0.35) at 95% confidence level. Similarly, YOLOv5-variant did not show any significant effect on the AP (p = 0.11) and accuracy (p = 0.73) of white bags, but it had significant effects on the AP (p = 0.03) and accuracy (p = 0.02) of brown bags including on the mAP@50 (p = 0.01) and inference speed (p < 0.0001). Additionally, height of plastic bags had significant effect (p < 0.0001) on overall detection accuracy. The findings reported in this paper can be useful in speeding up removal of plastic bags from cotton fields before harvest and thereby reducing the amount of contaminants that end up at cotton gins.