 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DeepExtrema: A Deep Learning Approach for Forecasting Block Maxima in Time Series Data
May 05, 2022
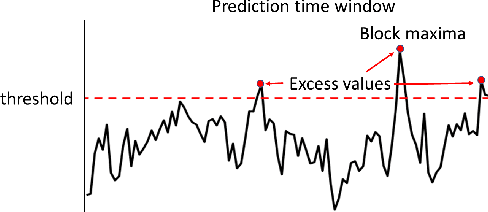

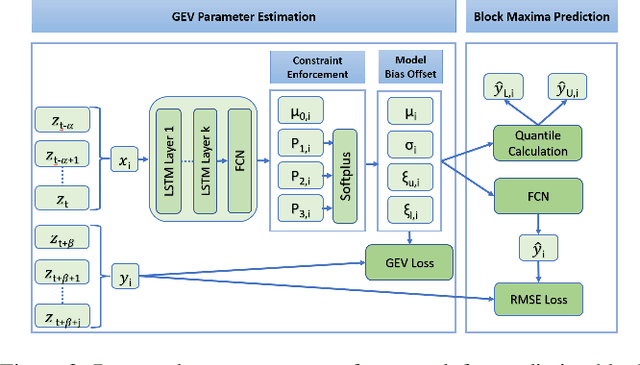
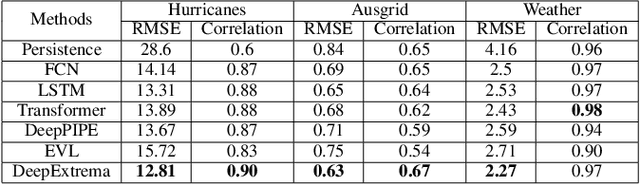
Accurate forecasting of extreme values in time series is critical due to the significant impact of extreme events on human and natural systems. This paper presents DeepExtrema, a novel framework that combines a deep neural network (DNN) with generalized extreme value (GEV) distribution to forecast the block maximum value of a time series. Implementing such a network is a challenge as the framework must preserve the inter-dependent constraints among the GEV model parameters even when the DNN is initialized. We describe our approach to address this challenge and present an architecture that enables both conditional mean and quantile prediction of the block maxima. The extensive experiments performed on both real-world and synthetic data demonstrated the superiority of DeepExtrema compared to other baseline methods.
Thermodynamics-informed neural networks for physically realistic mixed reality
Oct 24, 2022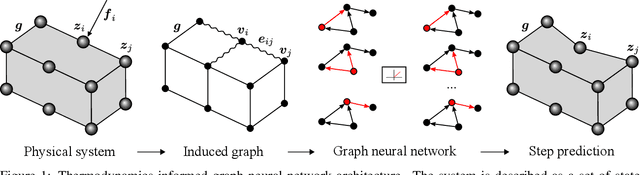
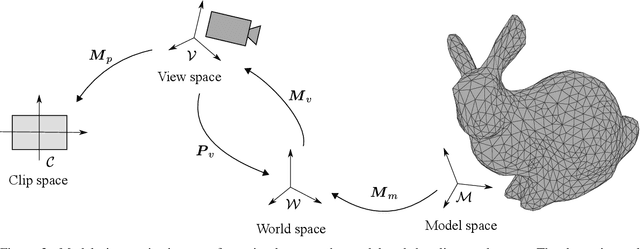
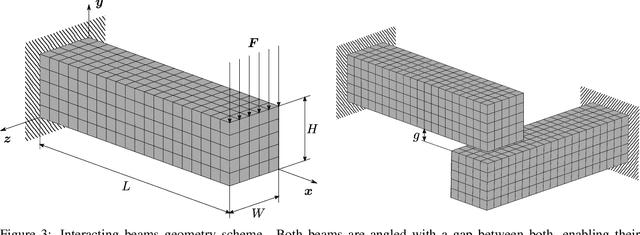

The imminent impact of immersive technologies in society urges for active research in real-time and interactive physics simulation for virtual worlds to be realistic. In this context, realistic means to be compliant to the laws of physics. In this paper we present a method for computing the dynamic response of (possibly non-linear and dissipative) deformable objects induced by real-time user interactions in mixed reality using deep learning. The graph-based architecture of the method ensures the thermodynamic consistency of the predictions, whereas the visualization pipeline allows a natural and realistic user experience. Two examples of virtual solids interacting with virtual or physical solids in mixed reality scenarios are provided to prove the performance of the method.
Cold Start Streaming Learning for Deep Networks
Nov 09, 2022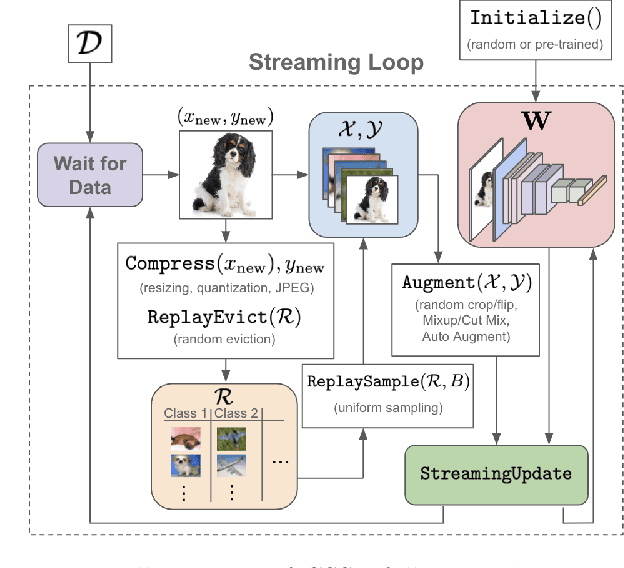
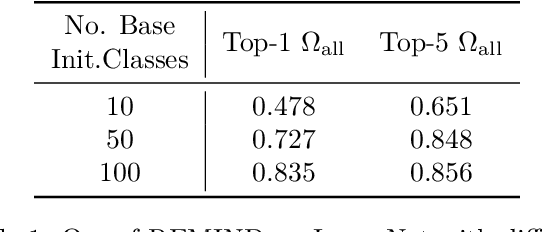
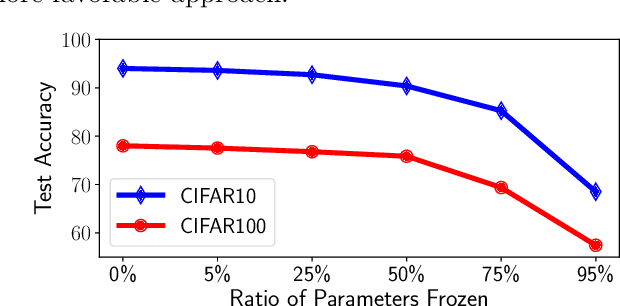

The ability to dynamically adapt neural networks to newly-available data without performance deterioration would revolutionize deep learning applications. Streaming learning (i.e., learning from one data example at a time) has the potential to enable such real-time adaptation, but current approaches i) freeze a majority of network parameters during streaming and ii) are dependent upon offline, base initialization procedures over large subsets of data, which damages performance and limits applicability. To mitigate these shortcomings, we propose Cold Start Streaming Learning (CSSL), a simple, end-to-end approach for streaming learning with deep networks that uses a combination of replay and data augmentation to avoid catastrophic forgetting. Because CSSL updates all model parameters during streaming, the algorithm is capable of beginning streaming from a random initialization, making base initialization optional. Going further, the algorithm's simplicity allows theoretical convergence guarantees to be derived using analysis of the Neural Tangent Random Feature (NTRF). In experiments, we find that CSSL outperforms existing baselines for streaming learning in experiments on CIFAR100, ImageNet, and Core50 datasets. Additionally, we propose a novel multi-task streaming learning setting and show that CSSL performs favorably in this domain. Put simply, CSSL performs well and demonstrates that the complicated, multi-step training pipelines adopted by most streaming methodologies can be replaced with a simple, end-to-end learning approach without sacrificing performance.
Reduced Order Probabilistic Emulation for Physics-Based Thermosphere Models
Nov 09, 2022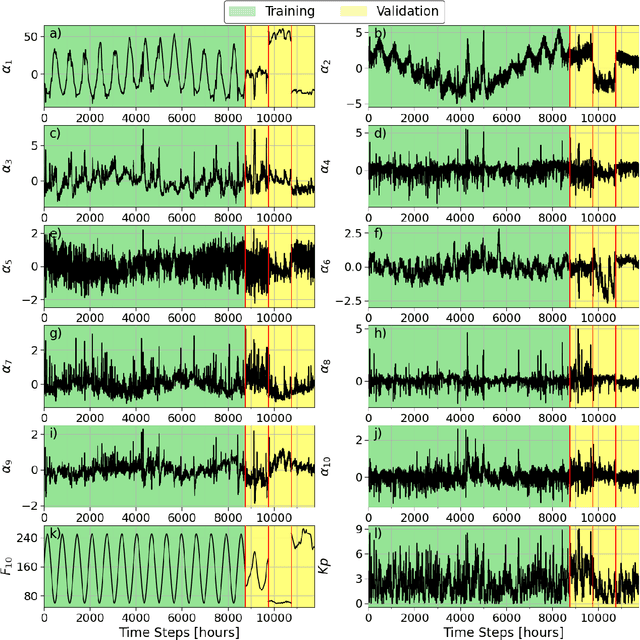
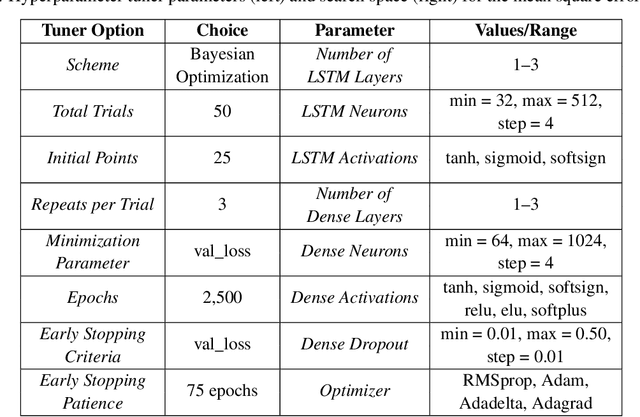
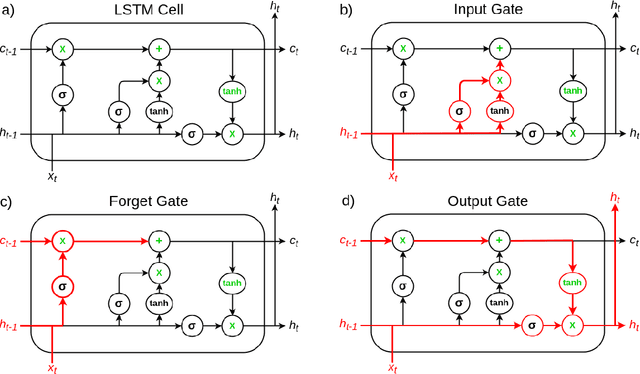
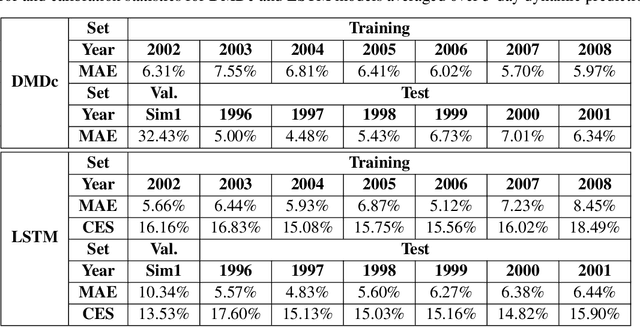
The geospace environment is volatile and highly driven. Space weather has effects on Earth's magnetosphere that cause a dynamic and enigmatic response in the thermosphere, particularly on the evolution of neutral mass density. Many models exist that use space weather drivers to produce a density response, but these models are typically computationally expensive or inaccurate for certain space weather conditions. In response, this work aims to employ a probabilistic machine learning (ML) method to create an efficient surrogate for the Thermosphere Ionosphere Electrodynamics General Circulation Model (TIE-GCM), a physics-based thermosphere model. Our method leverages principal component analysis to reduce the dimensionality of TIE-GCM and recurrent neural networks to model the dynamic behavior of the thermosphere much quicker than the numerical model. The newly developed reduced order probabilistic emulator (ROPE) uses Long-Short Term Memory neural networks to perform time-series forecasting in the reduced state and provide distributions for future density. We show that across the available data, TIE-GCM ROPE has similar error to previous linear approaches while improving storm-time modeling. We also conduct a satellite propagation study for the significant November 2003 storm which shows that TIE-GCM ROPE can capture the position resulting from TIE-GCM density with < 5 km bias. Simultaneously, linear approaches provide point estimates that can result in biases of 7 - 18 km.
Lodestar: An Integrated Embedded Real-Time Control Engine
Mar 01, 2022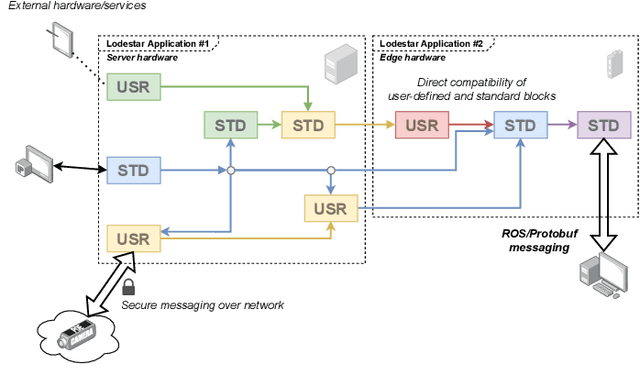
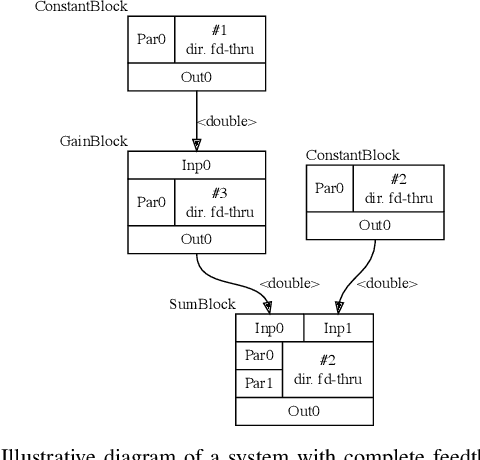
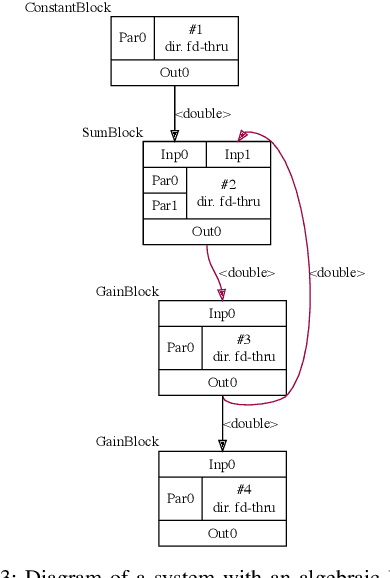

In this work we present Lodestar, an integrated engine for rapid real-time control system development. Using a functional block diagram paradigm, Lodestar allows for complex multi-disciplinary control software design, while automatically resolving execution order, circular data-dependencies, and networking. In particular, Lodestar presents a unified set of control, signal processing, and computer vision routines to users, which may be interfaced with external hardware and software packages using interoperable user-defined wrappers. Lodestar allows for user-defined block diagrams to be directly executed, or for them to be translated to overhead-free source code for integration in other programs. We demonstrate how our framework departs from approaches used in state-of-the-art simulation frameworks to enable real-time performance, and compare its capabilities to existing solutions in the realm of control software. To demonstrate the utility of Lodestar in real-time control systems design, we have applied Lodestar to implement two real-time torque-based controller for a robotic arm. In addition, we have developed a novel autofocus algorithm for use in thermography-based localization and parameter estimation in electrosurgery and other areas of robot-assisted surgery. We compare our algorithm design approach in Lodestar to a classical ground-up approach, showing that Lodestar considerably eases the design process. We also show how Lodestar can seamlessly interface with existing simulation and networking framework in a number of simulation examples.
Differentially-Private Sublinear-Time Clustering
Dec 27, 2021Clustering is an essential primitive in unsupervised machine learning. We bring forth the problem of sublinear-time differentially-private clustering as a natural and well-motivated direction of research. We combine the $k$-means and $k$-median sublinear-time results of Mishra et al. (SODA, 2001) and of Czumaj and Sohler (Rand. Struct. and Algorithms, 2007) with recent results on private clustering of Balcan et al. (ICML 2017), Gupta et al. (SODA, 2010) and Ghazi et al. (NeurIPS, 2020) to obtain sublinear-time private $k$-means and $k$-median algorithms via subsampling. We also investigate the privacy benefits of subsampling for group privacy.
A Low Latency Adaptive Coding Spiking Framework for Deep Reinforcement Learning
Nov 21, 2022

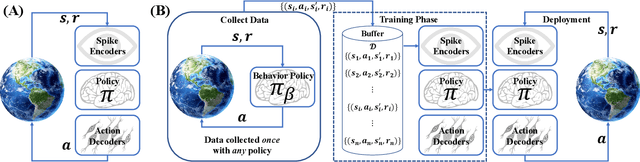
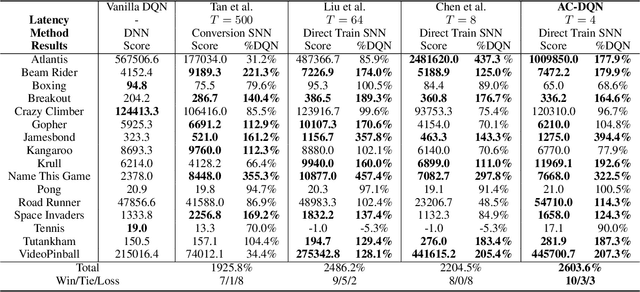
With the help of Deep Neural Networks, Deep Reinforcement Learning (DRL) has achieved great success on many complex tasks during the past few years. Spiking Neural Networks (SNNs) have been used for the implementation of Deep Neural Networks with superb energy efficiency on dedicated neuromorphic hardware, and recent years have witnessed increasing attention on combining SNNs with Reinforcement Learning, whereas most approaches still work with huge energy consumption and high latency. This work proposes the Adaptive Coding Spiking Framework (ACSF) for SNN-based DRL and achieves low latency and great energy efficiency at the same time. Inspired by classical conditioning in biology, we simulate receptors, central interneurons, and effectors with spike encoders, SNNs, and spike decoders, respectively. We use our proposed ACSF to estimate the value function in reinforcement learning and conduct extensive experiments to verify the effectiveness of our proposed framework.
High-Order Optimization of Gradient Boosted Decision Trees
Nov 21, 2022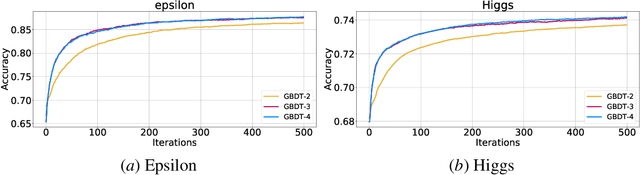

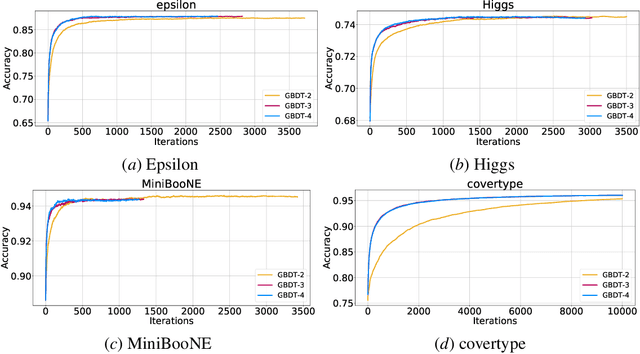
Gradient Boosted Decision Trees (GBDTs) are dominant machine learning algorithms for modeling discrete or tabular data. Unlike neural networks with millions of trainable parameters, GBDTs optimize loss function in an additive manner and have a single trainable parameter per leaf, which makes it easy to apply high-order optimization of the loss function. In this paper, we introduce high-order optimization for GBDTs based on numerical optimization theory which allows us to construct trees based on high-order derivatives of a given loss function. In the experiments, we show that high-order optimization has faster per-iteration convergence that leads to reduced running time. Our solution can be easily parallelized and run on GPUs with little overhead on the code. Finally, we discuss future potential improvements such as automatic differentiation of arbitrary loss function and combination of GBDTs with neural networks.
Radon-based Image Reconstruction for MPI using a continuously rotating FFL
Nov 21, 2022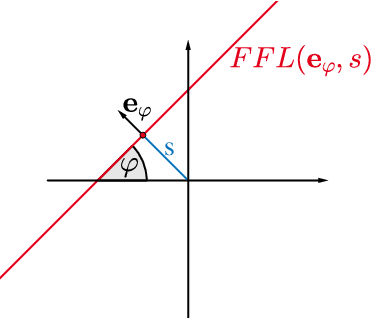
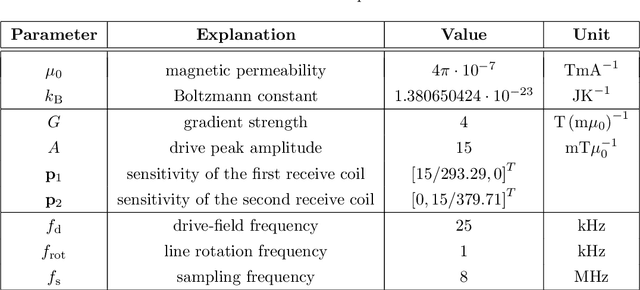
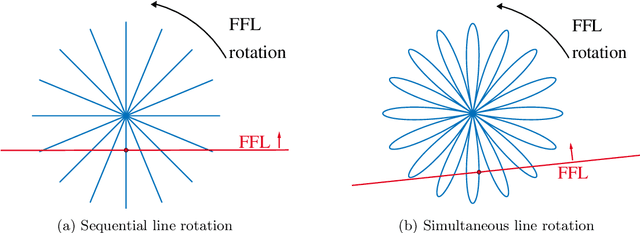

Magnetic particle imaging is a relatively new tracer-based medical imaging technique exploiting the non-linear magnetization response of magnetic nanoparticles to changing magnetic fields. If the data are generated by using a field-free line, the sampling geometry resembles the one in computerized tomography. Indeed, for an ideal field-free line rotating only in between measurements it was shown that the signal equation can be written as a convolution with the Radon transform of the particle concentration. In this work, we regard a continuously rotating field-free line and extend the forward operator accordingly. We obtain a similar result for the relation to the Radon data but with two additive terms resulting from the additional time-dependencies in the forward model. We jointly reconstruct particle concentration and corresponding Radon data by means of total variation regularization yielding promising results for synthetic data.
Dynamic selection of p-norm in linear adaptive filtering via online kernel-based reinforcement learning
Oct 20, 2022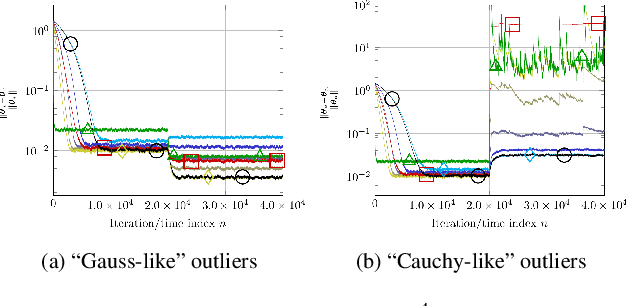
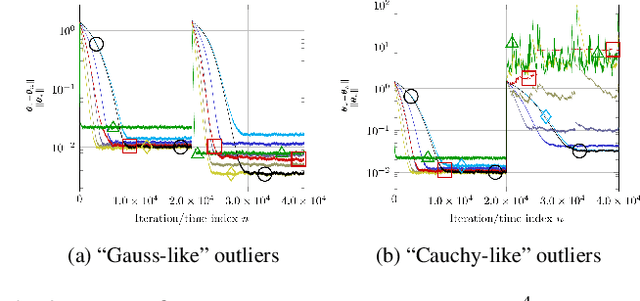
This study addresses the problem of selecting dynamically, at each time instance, the ``optimal'' p-norm to combat outliers in linear adaptive filtering without any knowledge on the potentially time-varying probability distribution function of the outliers. To this end, an online and data-driven framework is designed via kernel-based reinforcement learning (KBRL). Novel Bellman mappings on reproducing kernel Hilbert spaces (RKHSs) are introduced that need no knowledge on transition probabilities of Markov decision processes, and are nonexpansive with respect to the underlying Hilbertian norm. An approximate policy-iteration framework is finally offered via the introduction of a finite-dimensional affine superset of the fixed-point set of the proposed Bellman mappings. The well-known ``curse of dimensionality'' in RKHSs is addressed by building a basis of vectors via an approximate linear dependency criterion. Numerical tests on synthetic data demonstrate that the proposed framework selects always the ``optimal'' p-norm for the outlier scenario at hand, outperforming at the same time several non-RL and KBRL schemes.