 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
3D Point Positional Encoding for Multi-Camera 3D Object Detection Transformers
Nov 27, 2022
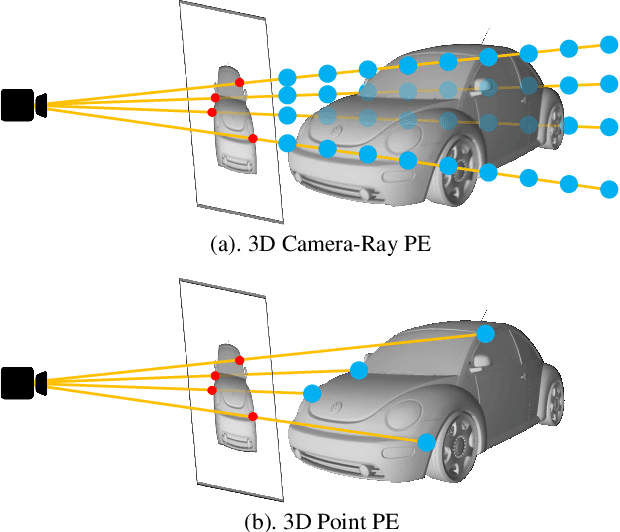
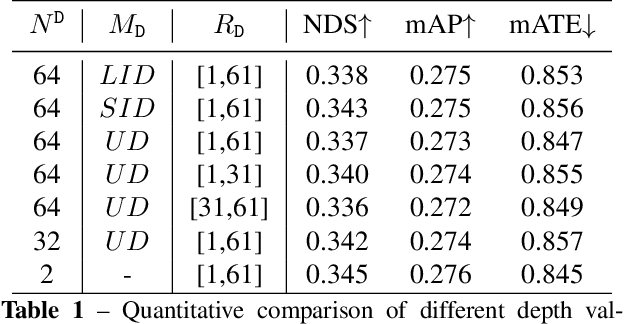
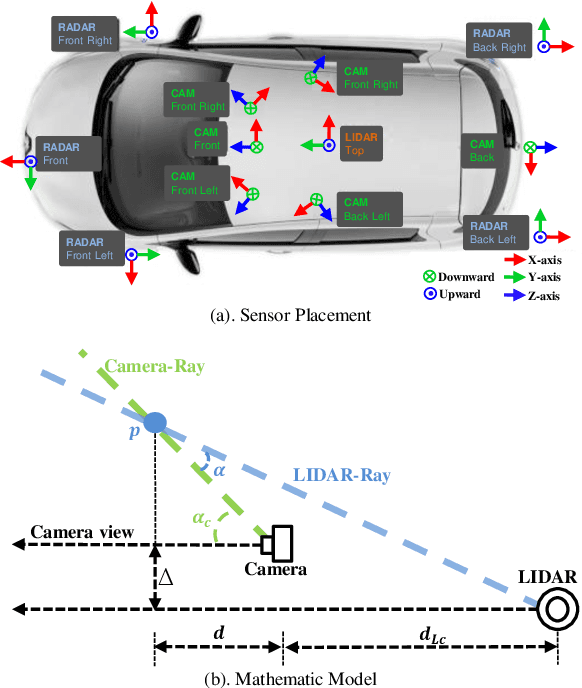
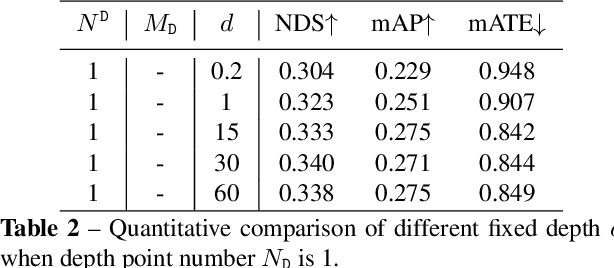
Multi-camera 3D object detection, a critical component for vision-only driving systems, has achieved impressive progress. Notably, transformer-based methods with 2D features augmented by 3D positional encodings (PE) have enjoyed great success. However, the mechanism and options of 3D PE have not been thoroughly explored. In this paper, we first explore, analyze and compare various 3D positional encodings. In particular, we devise 3D point PE and show its superior performance since more precise positioning may lead to superior 3D detection. In practice, we utilize monocular depth estimation to obtain the 3D point positions for multi-camera 3D object detection. The PE with estimated 3D point locations can bring significant improvements compared to the commonly used camera-ray PE. Among DETR-based strategies, our method achieves state-of-the-art 45.6 mAP and 55.1 NDS on the competitive nuScenes valuation set. It's the first time that the performance gap between the vision-only (DETR-based) and LiDAR-based methods is reduced within 5\% mAP and 6\% NDS.
DigGAN: Discriminator gradIent Gap Regularization for GAN Training with Limited Data
Nov 27, 2022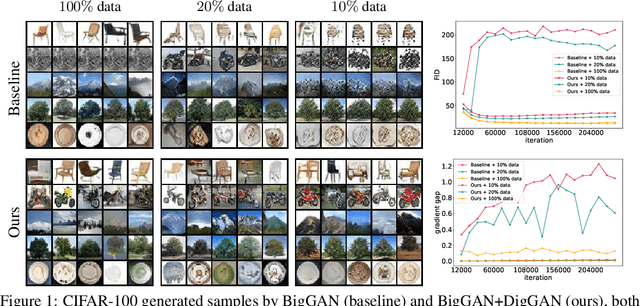

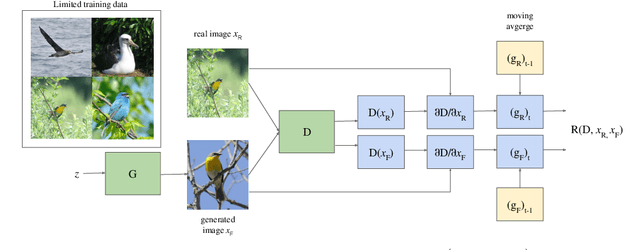
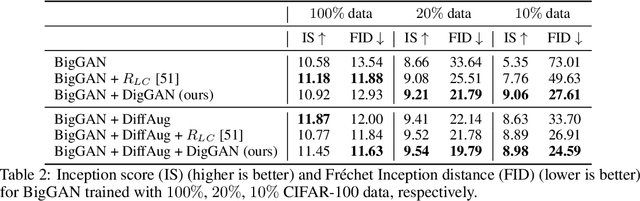
Generative adversarial nets (GANs) have been remarkably successful at learning to sample from distributions specified by a given dataset, particularly if the given dataset is reasonably large compared to its dimensionality. However, given limited data, classical GANs have struggled, and strategies like output-regularization, data-augmentation, use of pre-trained models and pruning have been shown to lead to improvements. Notably, the applicability of these strategies is 1) often constrained to particular settings, e.g., availability of a pretrained GAN; or 2) increases training time, e.g., when using pruning. In contrast, we propose a Discriminator gradIent Gap regularized GAN (DigGAN) formulation which can be added to any existing GAN. DigGAN augments existing GANs by encouraging to narrow the gap between the norm of the gradient of a discriminator's prediction w.r.t.\ real images and w.r.t.\ the generated samples. We observe this formulation to avoid bad attractors within the GAN loss landscape, and we find DigGAN to significantly improve the results of GAN training when limited data is available. Code is available at \url{https://github.com/AilsaF/DigGAN}.
Real-time Hyper-Dimensional Reconfiguration at the Edge using Hardware Accelerators
Jun 10, 2022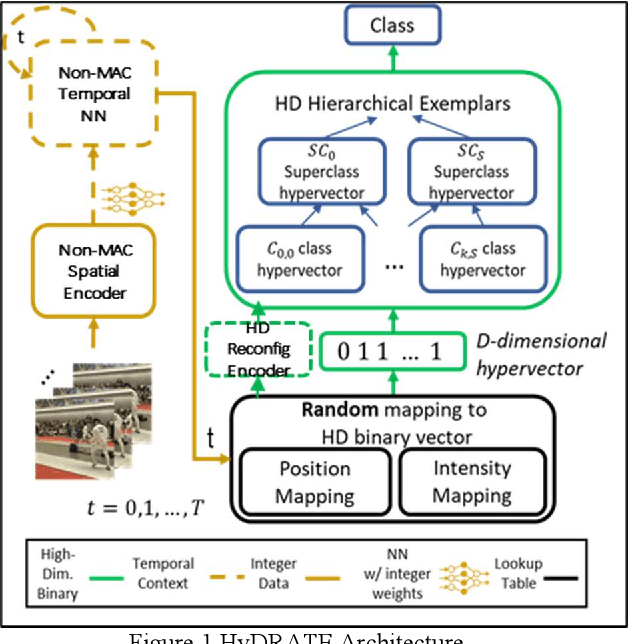
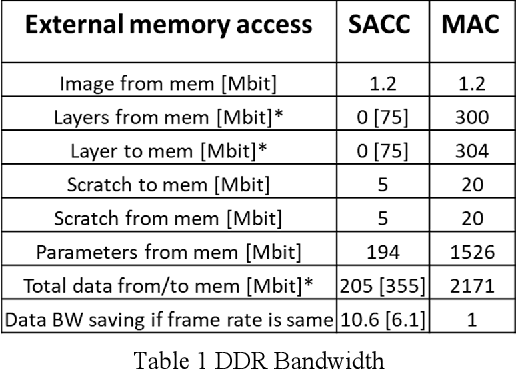
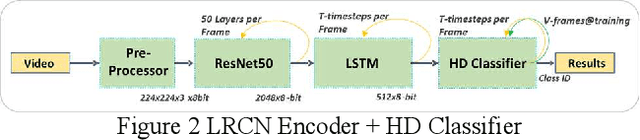
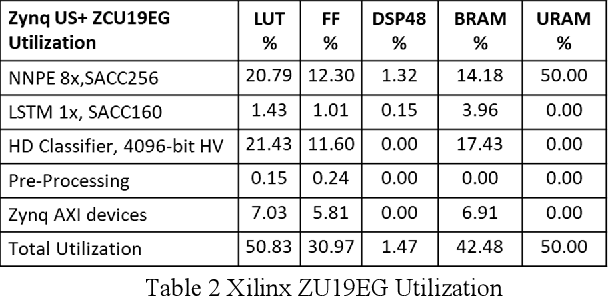
In this paper we present Hyper-Dimensional Reconfigurable Analytics at the Tactical Edge (HyDRATE) using low-SWaP embedded hardware that can perform real-time reconfiguration at the edge leveraging non-MAC (free of floating-point MultiplyACcumulate operations) deep neural nets (DNN) combined with hyperdimensional (HD) computing accelerators. We describe the algorithm, trained quantized model generation, and simulated performance of a feature extractor free of multiply-accumulates feeding a hyperdimensional logic-based classifier. Then we show how performance increases with the number of hyperdimensions. We describe the realized low-SWaP FPGA hardware and embedded software system compared to traditional DNNs and detail the implemented hardware accelerators. We discuss the measured system latency and power, noise robustness due to use of learnable quantization and HD computing, actual versus simulated system performance for a video activity classification task and demonstration of reconfiguration on this same dataset. We show that reconfigurability in the field is achieved by retraining only the feed-forward HD classifier without gradient descent backpropagation (gradient-free), using few-shot learning of new classes at the edge. Initial work performed used LRCN DNN and is currently extended to use Two-stream DNN with improved performance.
Paint by Example: Exemplar-based Image Editing with Diffusion Models
Nov 23, 2022


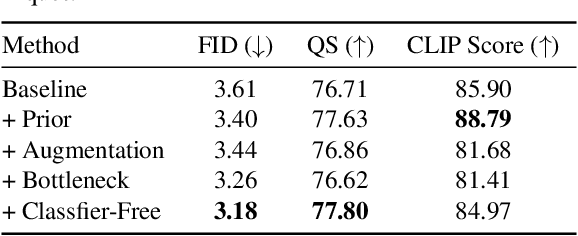
Language-guided image editing has achieved great success recently. In this paper, for the first time, we investigate exemplar-guided image editing for more precise control. We achieve this goal by leveraging self-supervised training to disentangle and re-organize the source image and the exemplar. However, the naive approach will cause obvious fusing artifacts. We carefully analyze it and propose an information bottleneck and strong augmentations to avoid the trivial solution of directly copying and pasting the exemplar image. Meanwhile, to ensure the controllability of the editing process, we design an arbitrary shape mask for the exemplar image and leverage the classifier-free guidance to increase the similarity to the exemplar image. The whole framework involves a single forward of the diffusion model without any iterative optimization. We demonstrate that our method achieves an impressive performance and enables controllable editing on in-the-wild images with high fidelity.
Unsupervised Unlearning of Concept Drift with Autoencoders
Nov 23, 2022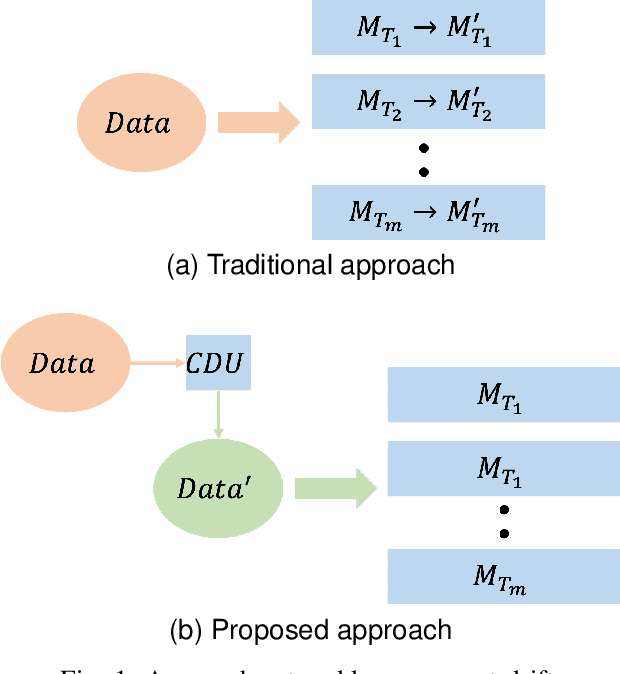

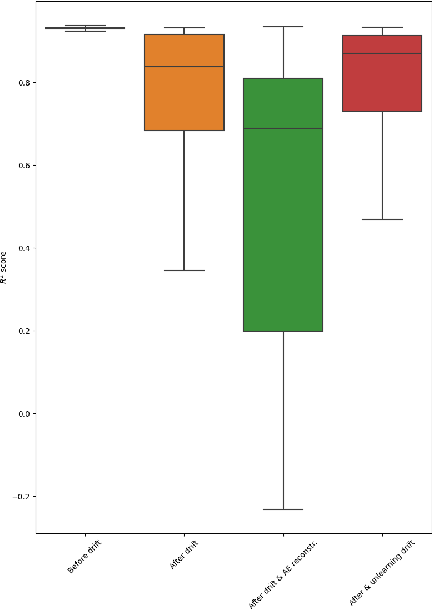
The phenomena of concept drift refers to a change of the data distribution affecting the data stream of future samples -- such non-stationary environments are often encountered in the real world. Consequently, learning models operating on the data stream might become obsolete, and need costly and difficult adjustments such as retraining or adaptation. Existing methods to address concept drift are, typically, categorised as active or passive. The former continually adapt a model using incremental learning, while the latter perform a complete model retraining when a drift detection mechanism triggers an alarm. We depart from the traditional avenues and propose for the first time an alternative approach which "unlearns" the effects of the concept drift. Specifically, we propose an autoencoder-based method for "unlearning" the concept drift in an unsupervised manner, without having to retrain or adapt any of the learning models operating on the data.
Voice-preserving Zero-shot Multiple Accent Conversion
Nov 23, 2022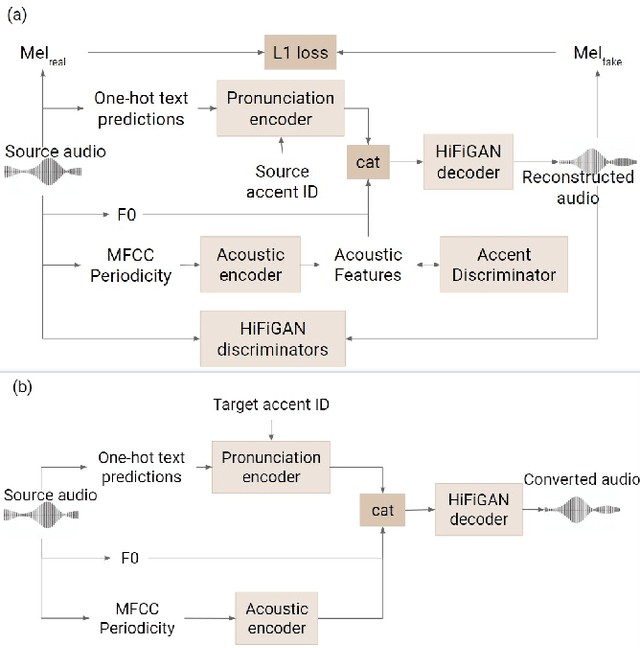
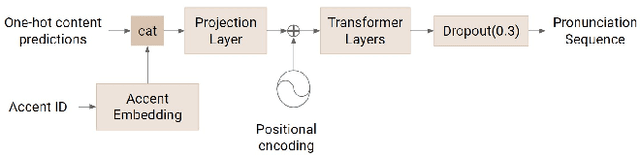
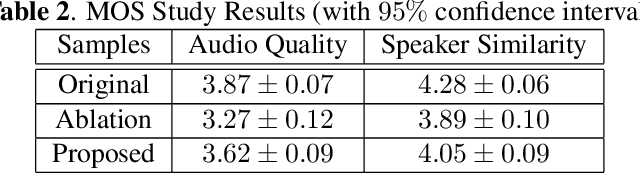
Most people who have tried to learn a foreign language would have experienced difficulties understanding or speaking with a native speaker's accent. For native speakers, understanding or speaking a new accent is likewise a difficult task. An accent conversion system that changes a speaker's accent but preserves that speaker's voice identity, such as timbre and pitch, has the potential for a range of applications, such as communication, language learning, and entertainment. Existing accent conversion models tend to change the speaker identity and accent at the same time. Here, we use adversarial learning to disentangle accent dependent features while retaining other acoustic characteristics. What sets our work apart from existing accent conversion models is the capability to convert an unseen speaker's utterance to multiple accents while preserving its original voice identity. Subjective evaluations show that our model generates audio that sound closer to the target accent and like the original speaker.
Learning to Imitate Object Interactions from Internet Videos
Nov 23, 2022



We study the problem of imitating object interactions from Internet videos. This requires understanding the hand-object interactions in 4D, spatially in 3D and over time, which is challenging due to mutual hand-object occlusions. In this paper we make two main contributions: (1) a novel reconstruction technique RHOV (Reconstructing Hands and Objects from Videos), which reconstructs 4D trajectories of both the hand and the object using 2D image cues and temporal smoothness constraints; (2) a system for imitating object interactions in a physics simulator with reinforcement learning. We apply our reconstruction technique to 100 challenging Internet videos. We further show that we can successfully imitate a range of different object interactions in a physics simulator. Our object-centric approach is not limited to human-like end-effectors and can learn to imitate object interactions using different embodiments, like a robotic arm with a parallel jaw gripper.
Rate-Distortion Optimized Post-Training Quantization for Learned Image Compression
Nov 05, 2022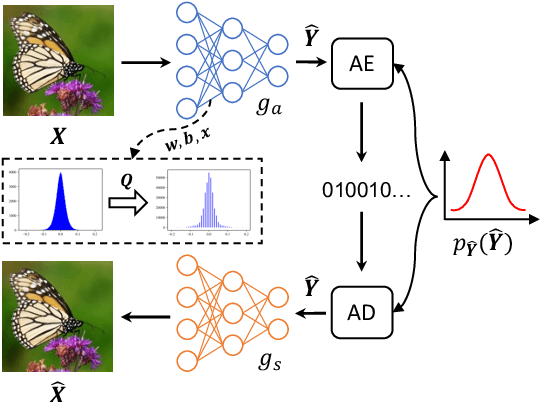
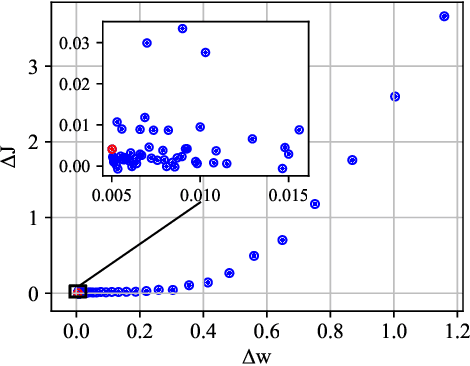
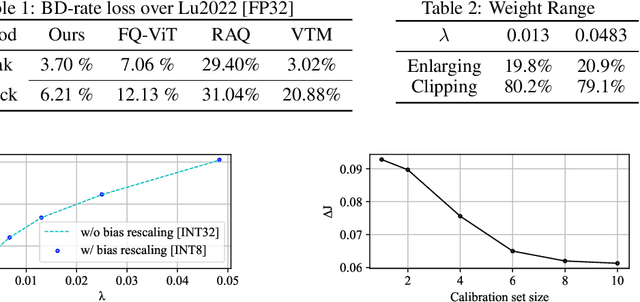
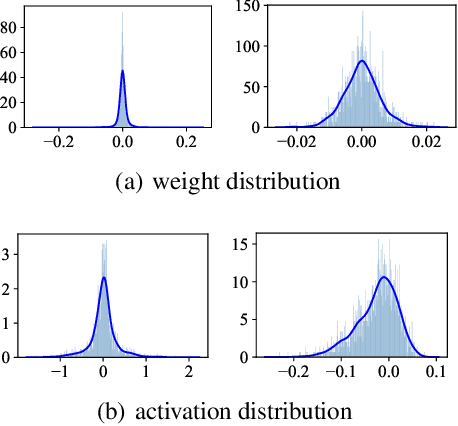
Quantizing floating-point neural network to its fixed-point representation is crucial for Learned Image Compression (LIC) because it ensures the decoding consistency for interoperability and reduces space-time complexity for implementation. Existing solutions often have to retrain the network for model quantization which is time consuming and impractical. This work suggests the use of Post-Training Quantization (PTQ) to directly process pretrained, off-the-shelf LIC models. We theoretically prove that minimizing the mean squared error (MSE) in PTQ is sub-optimal for compression task and thus develop a novel Rate-Distortion (R-D) Optimized PTQ (RDO-PTQ) to best retain the compression performance. Such RDO-PTQ just needs to compress few images (e.g., 10) to optimize the transformation of weight, bias, and activation of underlying LIC model from its native 32-bit floating-point (FP32) format to 8-bit fixed-point (INT8) precision for fixed-point inference onwards. Experiments reveal outstanding efficiency of the proposed method on different LICs, showing the closest coding performance to their floating-point counterparts. And, our method is a lightweight and plug-and-play approach without any need of model retraining which is attractive to practitioners.
Time Reversal for 6G Spatiotemporal Focusing: Recent Experiments, Opportunities, and Challenges
Jun 16, 2022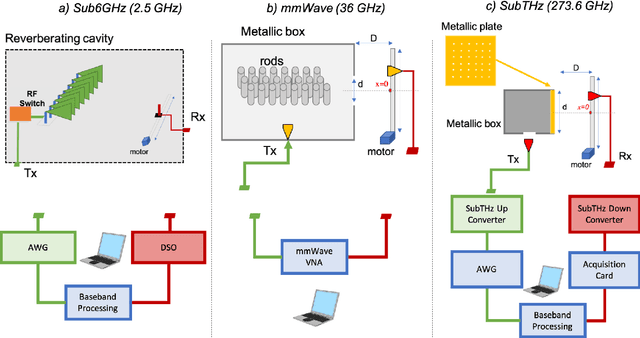
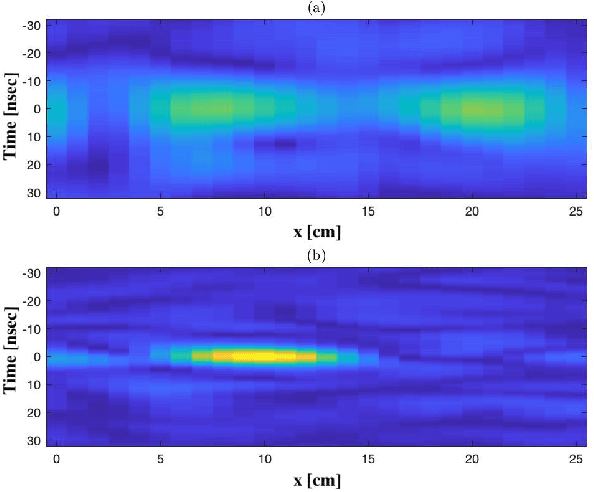
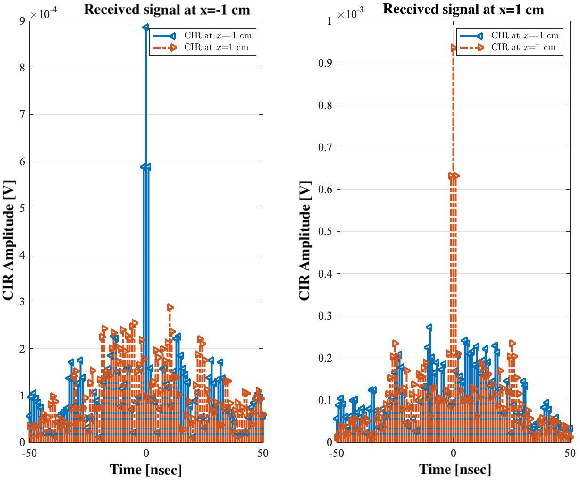
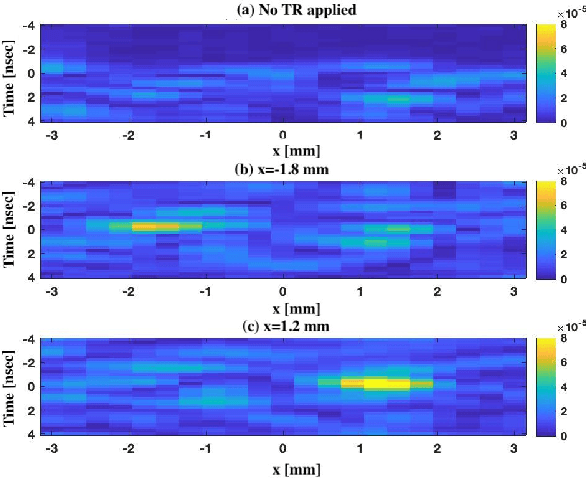
Late visions and trends for the future sixth Generation (6G) of wireless communications advocate, among other technologies, towards the deployment of network nodes with extreme numbers of antennas and up to terahertz frequencies, as means to enable various immersive applications. However, these technologies impose several challenges in the design of radio-frequency front-ends and beamforming architectures, as well as of ultra-wideband waveforms and computationally efficient transceiver signal processing. In this article, we revisit the Time Reversal (TR) technique, which was initially experimented in acoustics, in the context of large-bandwidth 6G wireless communications, capitalizing on its high resolution spatiotemporal focusing realized with low complexity transceivers. We first overview representative state-of-the-art in TR-based wireless communications, identifying the key competencies and requirements of TR for efficient operation. Recent and novel experimental setups and results for the spatiotemporal focusing capability of TR at the carrier frequencies $2.5$, $36$, and $273$ GHz are then presented, demonstrating in quantitative ways the technique's effectiveness in these very different frequency bands, as well as the roles of the available bandwidth and the number of transmit antennas. We also showcase the TR potential for realizing low complexity multi-user communications. The opportunities arising from TR-based wireless communications as well as the challenges for finding their place in 6G networks, also in conjunction with other complementary candidate technologies, are highlighted.
MetaMax: Improved Open-Set Deep Neural Networks via Weibull Calibration
Nov 20, 2022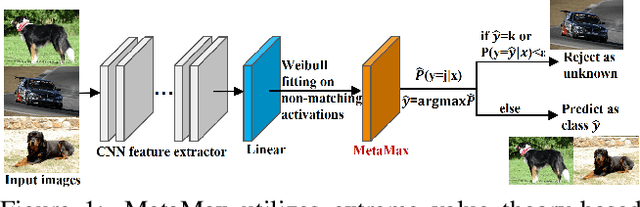
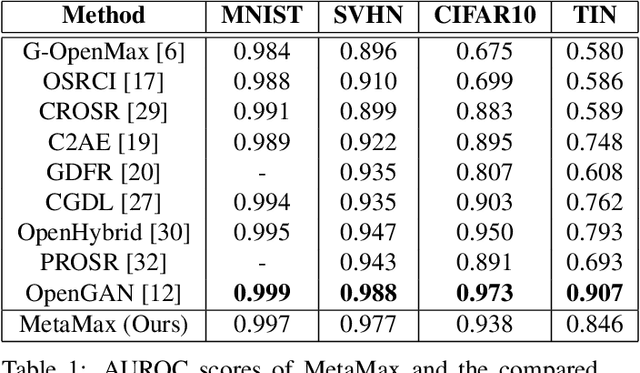
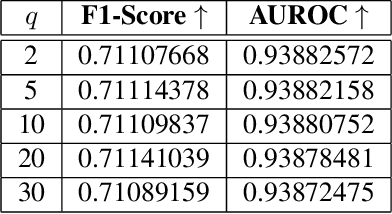
Open-set recognition refers to the problem in which classes that were not seen during training appear at inference time. This requires the ability to identify instances of novel classes while maintaining discriminative capability for closed-set classification. OpenMax was the first deep neural network-based approach to address open-set recognition by calibrating the predictive scores of a standard closed-set classification network. In this paper we present MetaMax, a more effective post-processing technique that improves upon contemporary methods by directly modeling class activation vectors. MetaMax removes the need for computing class mean activation vectors (MAVs) and distances between a query image and a class MAV as required in OpenMax. Experimental results show that MetaMax outperforms OpenMax and is comparable in performance to other state-of-the-art approaches.