 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multimodal Vision Transformers with Forced Attention for Behavior Analysis
Dec 07, 2022
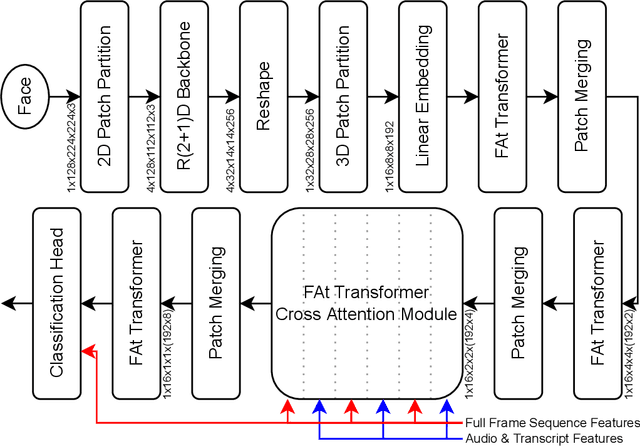
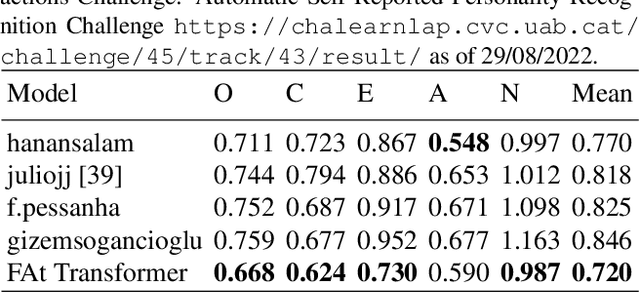
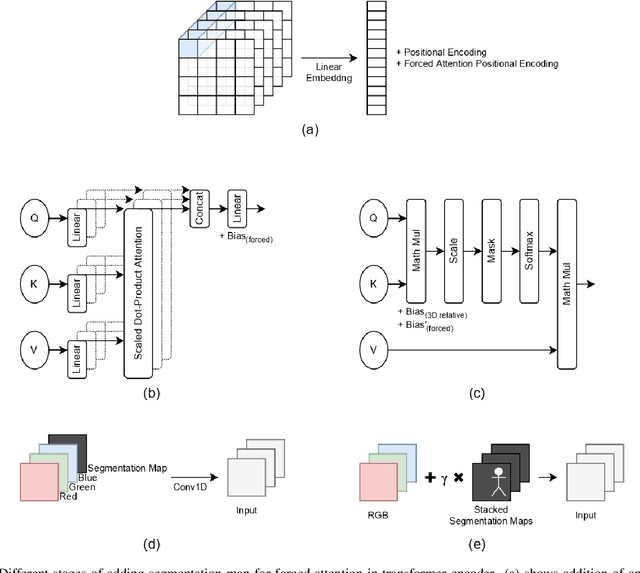

Human behavior understanding requires looking at minute details in the large context of a scene containing multiple input modalities. It is necessary as it allows the design of more human-like machines. While transformer approaches have shown great improvements, they face multiple challenges such as lack of data or background noise. To tackle these, we introduce the Forced Attention (FAt) Transformer which utilize forced attention with a modified backbone for input encoding and a use of additional inputs. In addition to improving the performance on different tasks and inputs, the modification requires less time and memory resources. We provide a model for a generalised feature extraction for tasks concerning social signals and behavior analysis. Our focus is on understanding behavior in videos where people are interacting with each other or talking into the camera which simulates the first person point of view in social interaction. FAt Transformers are applied to two downstream tasks: personality recognition and body language recognition. We achieve state-of-the-art results for Udiva v0.5, First Impressions v2 and MPII Group Interaction datasets. We further provide an extensive ablation study of the proposed architecture.
Assessing and Analyzing the Resilience of Graph Neural Networks Against Hardware Faults
Dec 07, 2022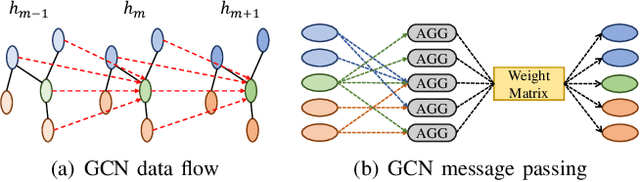
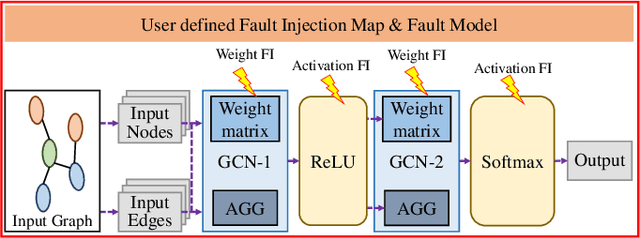
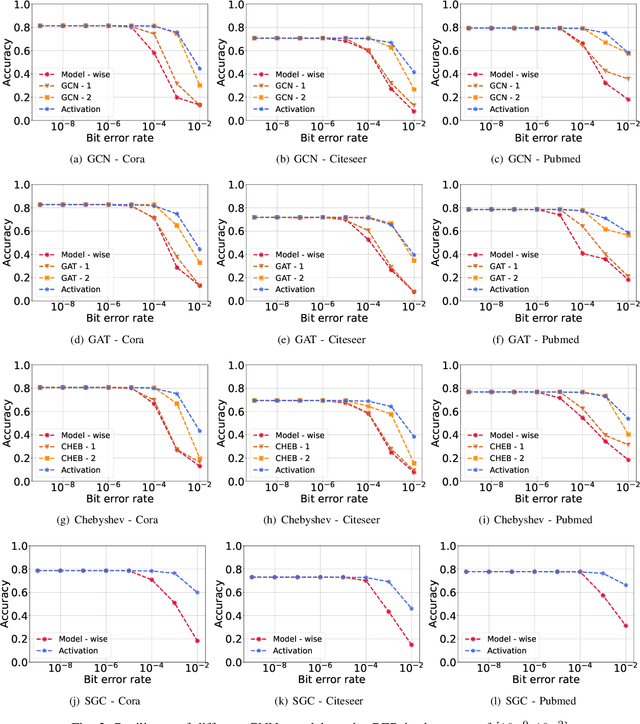
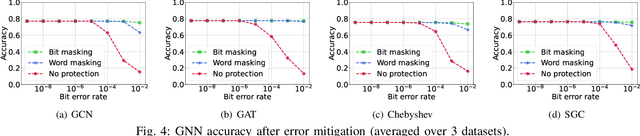
Graph neural networks (GNNs) have recently emerged as a promising learning paradigm in learning graph-structured data and have demonstrated wide success across various domains such as recommendation systems, social networks, and electronic design automation (EDA). Like other deep learning (DL) methods, GNNs are being deployed in sophisticated modern hardware systems, as well as dedicated accelerators. However, despite the popularity of GNNs and the recent efforts of bringing GNNs to hardware, the fault tolerance and resilience of GNNs has generally been overlooked. Inspired by the inherent algorithmic resilience of DL methods, this paper conducts, for the first time, a large-scale and empirical study of GNN resilience, aiming to understand the relationship between hardware faults and GNN accuracy. By developing a customized fault injection tool on top of PyTorch, we perform extensive fault injection experiments to various GNN models and application datasets. We observe that the error resilience of GNN models varies by orders of magnitude with respect to different models and application datasets. Further, we explore a low-cost error mitigation mechanism for GNN to enhance its resilience. This GNN resilience study aims to open up new directions and opportunities for future GNN accelerator design and architectural optimization.
On Principal Curve-Based Classifiers and Similarity-Based Selective Sampling in Time-Series
Apr 10, 2022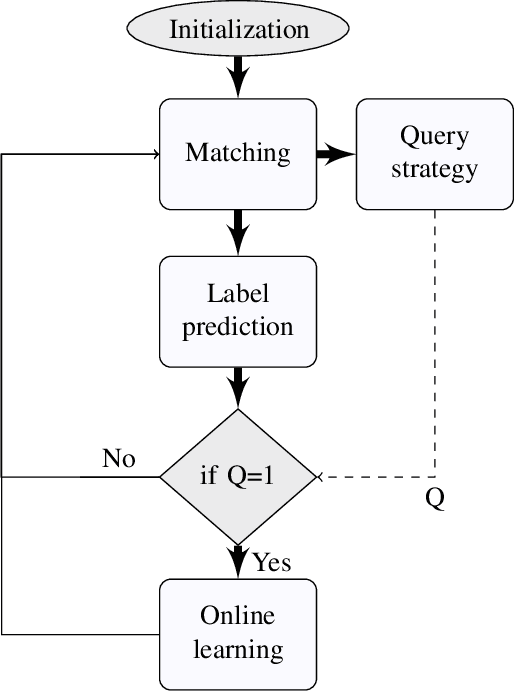
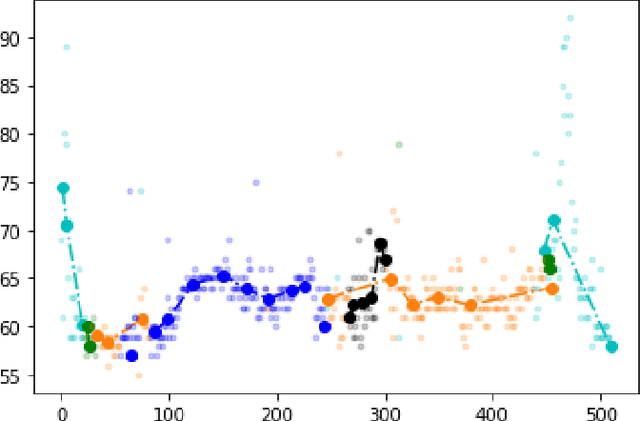
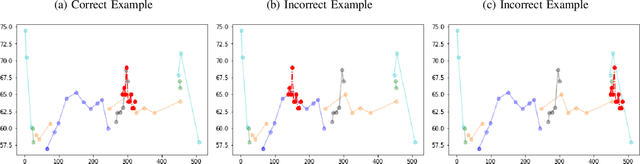
Considering the concept of time-dilation, there exist some major issues with recurrent neural Architectures. Any variation in time spans between input data points causes performance attenuation in recurrent neural network architectures. Principal curve-based classifiers have the ability of handling any kind of variation in time spans. In other words, principal curve-based classifiers preserve the relativity of time while neural network architecture violates this property of time. On the other hand, considering the labeling costs and problems in online monitoring devices, there should be an algorithm that finds the data points which knowing their labels will cause in better performance of the classifier. Current selective sampling algorithms have lack of reliability due to the randomness of the proposed algorithms. This paper proposes a classifier and also a deterministic selective sampling algorithm with the same computational steps, both by use of principal curve as their building block in model definition.
Layered Control for Cooperative Locomotion of Two Quadrupedal Robots: Centralized and Distributed Approaches
Nov 13, 2022
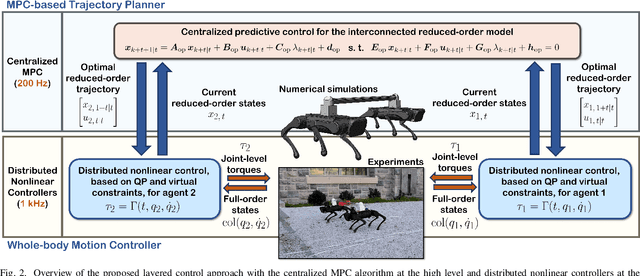
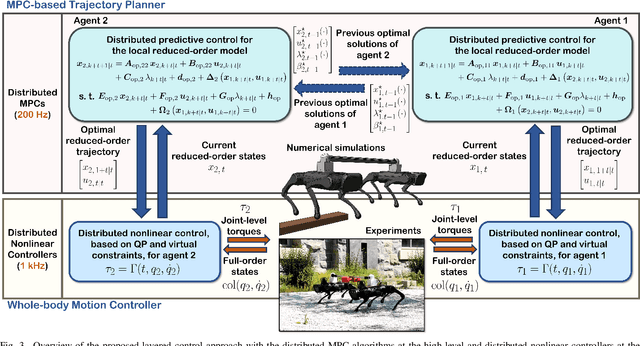
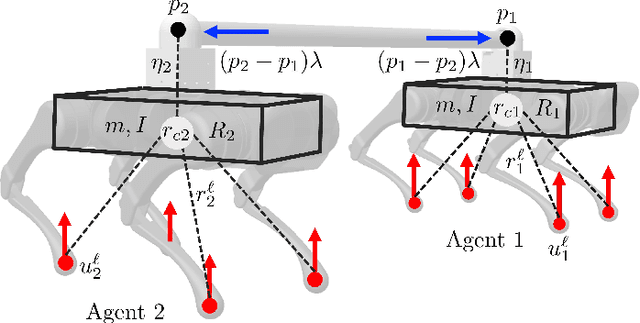
This paper presents a layered control approach for real-time trajectory planning and control of robust cooperative locomotion by two holonomically constrained quadrupedal robots. A novel interconnected network of reduced-order models, based on the single rigid body (SRB) dynamics, is developed for trajectory planning purposes. At the higher level of the control architecture, two different model predictive control (MPC) algorithms are proposed to address the optimal control problem of the interconnected SRB dynamics: centralized and distributed MPCs. The distributed MPC assumes two local quadratic programs that share their optimal solutions according to a one-step communication delay and an agreement protocol. At the lower level of the control scheme, distributed nonlinear controllers are developed to impose the full-order dynamics to track the prescribed reduced-order trajectories generated by MPCs. The effectiveness of the control approach is verified with extensive numerical simulations and experiments for the robust and cooperative locomotion of two holonomically constrained A1 robots with different payloads on variable terrains and in the presence of disturbances. It is shown that the distributed MPC has a performance similar to that of the centralized MPC, while the computation time is reduced significantly.
OMU: A Probabilistic 3D Occupancy Mapping Accelerator for Real-time OctoMap at the Edge
May 06, 2022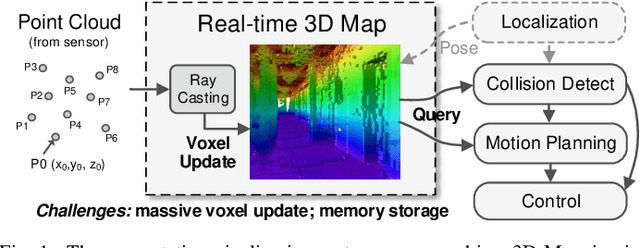
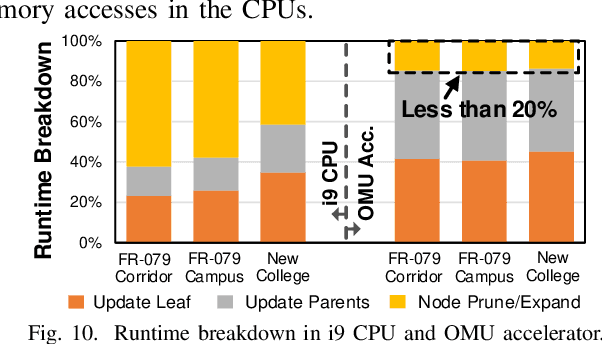
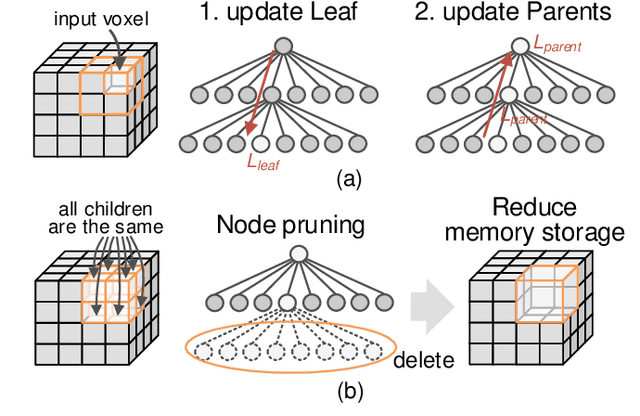
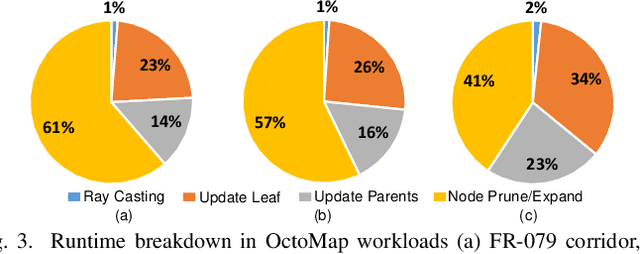
Autonomous machines (e.g., vehicles, mobile robots, drones) require sophisticated 3D mapping to perceive the dynamic environment. However, maintaining a real-time 3D map is expensive both in terms of compute and memory requirements, especially for resource-constrained edge machines. Probabilistic OctoMap is a reliable and memory-efficient 3D dense map model to represent the full environment, with dynamic voxel node pruning and expansion capacity. This paper presents the first efficient accelerator solution, i.e. OMU, to enable real-time probabilistic 3D mapping at the edge. To improve the performance, the input map voxels are updated via parallel PE units for data parallelism. Within each PE, the voxels are stored using a specially developed data structure in parallel memory banks. In addition, a pruning address manager is designed within each PE unit to reuse the pruned memory addresses. The proposed 3D mapping accelerator is implemented and evaluated using a commercial 12 nm technology. Compared to the ARM Cortex-A57 CPU in the Nvidia Jetson TX2 platform, the proposed accelerator achieves up to 62$\times$ performance and 708$\times$ energy efficiency improvement. Furthermore, the accelerator provides 63 FPS throughput, more than 2$\times$ higher than a real-time requirement, enabling real-time perception for 3D mapping.
Asynchronous Training Schemes in Distributed Learning with Time Delay
Aug 28, 2022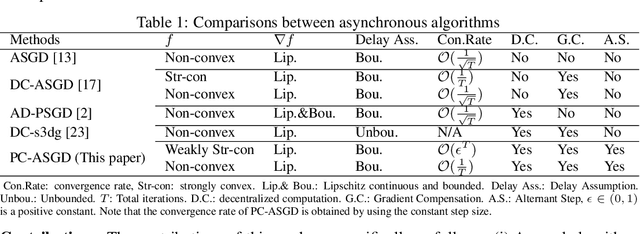
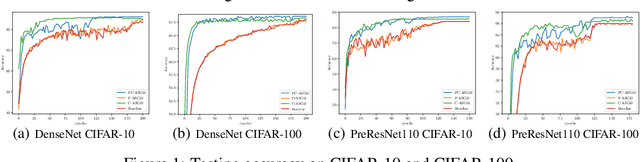

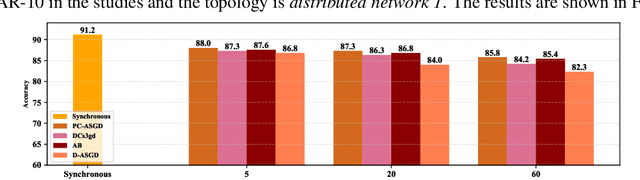
In the context of distributed deep learning, the issue of stale weights or gradients could result in poor algorithmic performance. This issue is usually tackled by delay tolerant algorithms with some mild assumptions on the objective functions and step sizes. In this paper, we propose a different approach to develop a new algorithm, called $\textbf{P}$redicting $\textbf{C}$lipping $\textbf{A}$synchronous $\textbf{S}$tochastic $\textbf{G}$radient $\textbf{D}$escent (aka, PC-ASGD). Specifically, PC-ASGD has two steps - the $\textit{predicting step}$ leverages the gradient prediction using Taylor expansion to reduce the staleness of the outdated weights while the $\textit{clipping step}$ selectively drops the outdated weights to alleviate their negative effects. A tradeoff parameter is introduced to balance the effects between these two steps. Theoretically, we present the convergence rate considering the effects of delay of the proposed algorithm with constant step size when the smooth objective functions are weakly strongly-convex and nonconvex. One practical variant of PC-ASGD is also proposed by adopting a condition to help with the determination of the tradeoff parameter. For empirical validation, we demonstrate the performance of the algorithm with two deep neural network architectures on two benchmark datasets.
Self-supervised and Weakly Supervised Contrastive Learning for Frame-wise Action Representations
Dec 11, 2022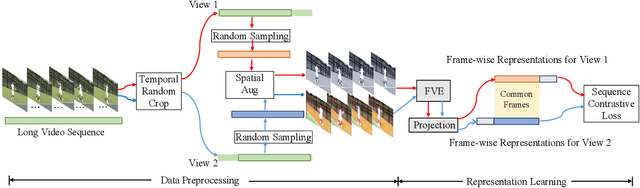
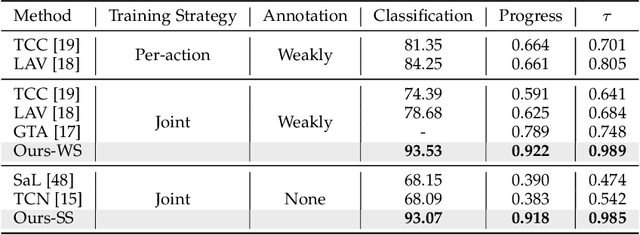
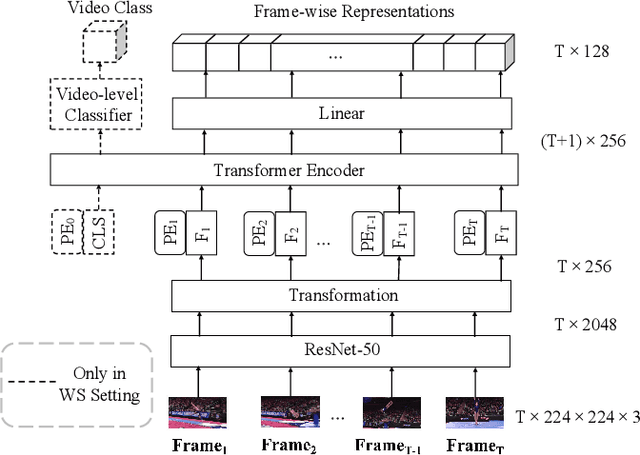
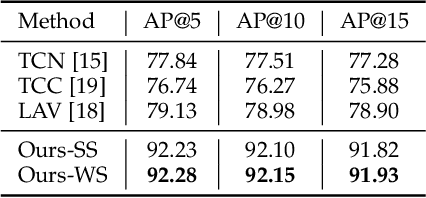
Previous work on action representation learning focused on global representations for short video clips. In contrast, many practical applications, such as video alignment, strongly demand learning the intensive representation of long videos. In this paper, we introduce a new framework of contrastive action representation learning (CARL) to learn frame-wise action representation in a self-supervised or weakly-supervised manner, especially for long videos. Specifically, we introduce a simple but effective video encoder that considers both spatial and temporal context by combining convolution and transformer. Inspired by the recent massive progress in self-supervised learning, we propose a new sequence contrast loss (SCL) applied to two related views obtained by expanding a series of spatio-temporal data in two versions. One is the self-supervised version that optimizes embedding space by minimizing KL-divergence between sequence similarity of two augmented views and prior Gaussian distribution of timestamp distance. The other is the weakly-supervised version that builds more sample pairs among videos using video-level labels by dynamic time wrapping (DTW). Experiments on FineGym, PennAction, and Pouring datasets show that our method outperforms previous state-of-the-art by a large margin for downstream fine-grained action classification and even faster inference. Surprisingly, although without training on paired videos like in previous works, our self-supervised version also shows outstanding performance in video alignment and fine-grained frame retrieval tasks.
Target Detection Framework for Lobster Eye X-Ray Telescopes with Machine Learning Algorithms
Dec 11, 2022

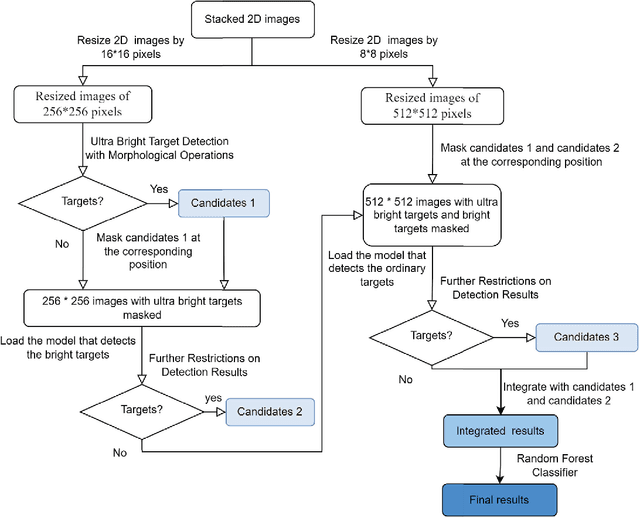

Lobster eye telescopes are ideal monitors to detect X-ray transients, because they could observe celestial objects over a wide field of view in X-ray band. However, images obtained by lobster eye telescopes are modified by their unique point spread functions, making it hard to design a high efficiency target detection algorithm. In this paper, we integrate several machine learning algorithms to build a target detection framework for data obtained by lobster eye telescopes. Our framework would firstly generate two 2D images with different pixel scales according to positions of photons on the detector. Then an algorithm based on morphological operations and two neural networks would be used to detect candidates of celestial objects with different flux from these 2D images. At last, a random forest algorithm will be used to pick up final detection results from candidates obtained by previous steps. Tested with simulated data of the Wide-field X-ray Telescope onboard the Einstein Probe, our detection framework could achieve over 94% purity and over 90% completeness for targets with flux more than 3 mCrab (9.6 * 10-11 erg/cm2/s) and more than 94% purity and moderate completeness for targets with lower flux at acceptable time cost. The framework proposed in this paper could be used as references for data processing methods developed for other lobster eye X-ray telescopes.
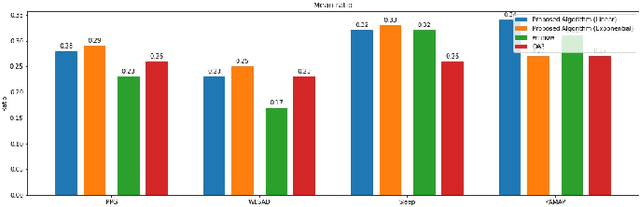
ProductGraphSleepNet: Sleep Staging using Product Spatio-Temporal Graph Learning with Attentive Temporal Aggregation
Dec 09, 2022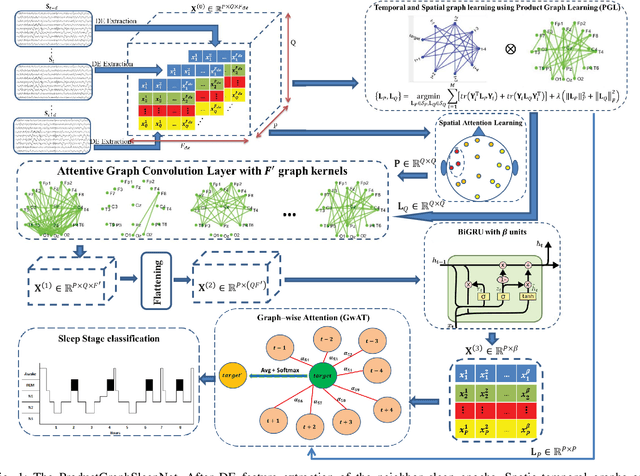
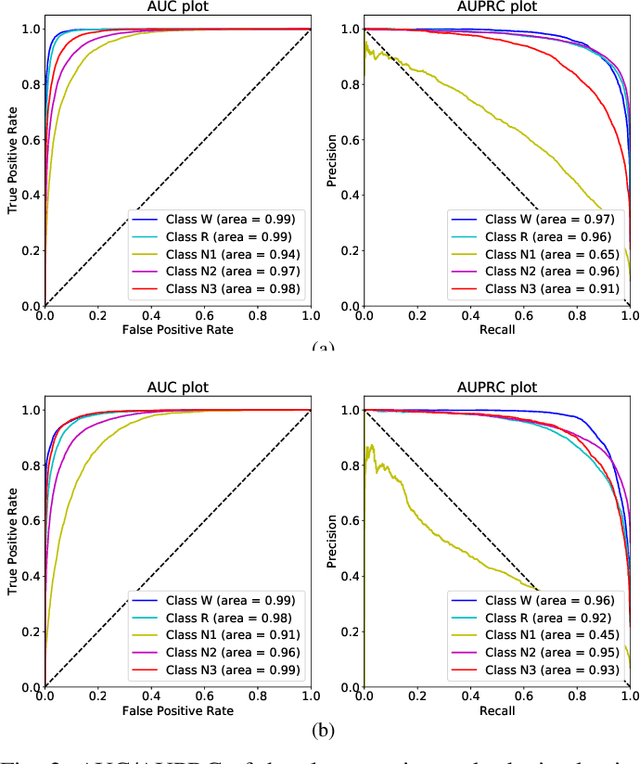
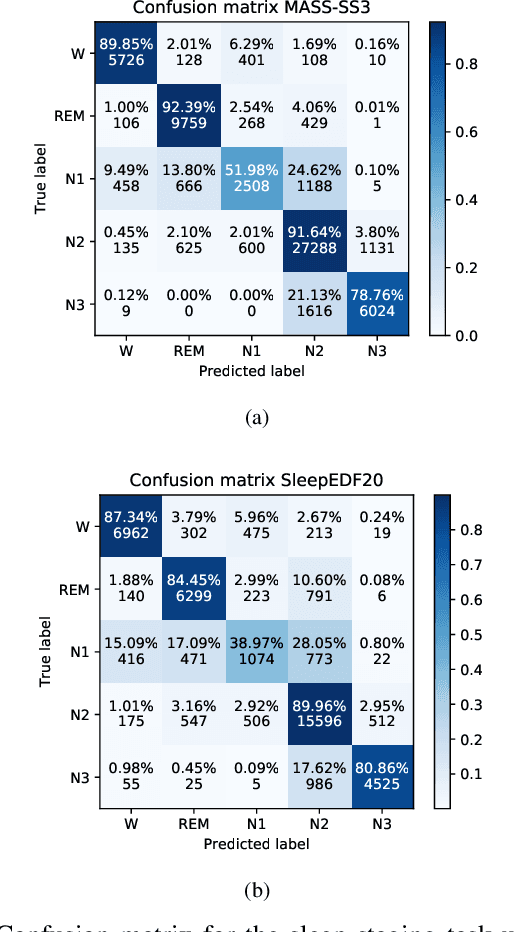
The classification of sleep stages plays a crucial role in understanding and diagnosing sleep pathophysiology. Sleep stage scoring relies heavily on visual inspection by an expert that is time consuming and subjective procedure. Recently, deep learning neural network approaches have been leveraged to develop a generalized automated sleep staging and account for shifts in distributions that may be caused by inherent inter/intra-subject variability, heterogeneity across datasets, and different recording environments. However, these networks ignore the connections among brain regions, and disregard the sequential connections between temporally adjacent sleep epochs. To address these issues, this work proposes an adaptive product graph learning-based graph convolutional network, named ProductGraphSleepNet, for learning joint spatio-temporal graphs along with a bidirectional gated recurrent unit and a modified graph attention network to capture the attentive dynamics of sleep stage transitions. Evaluation on two public databases: the Montreal Archive of Sleep Studies (MASS) SS3; and the SleepEDF, which contain full night polysomnography recordings of 62 and 20 healthy subjects, respectively, demonstrates performance comparable to the state-of-the-art (Accuracy: 0.867;0.838, F1-score: 0.818;0.774 and Kappa: 0.802;0.775, on each database respectively). More importantly, the proposed network makes it possible for clinicians to comprehend and interpret the learned connectivity graphs for sleep stages.
Frugal Reinforcement-based Active Learning
Dec 09, 2022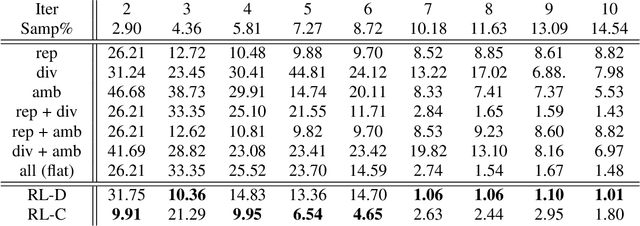
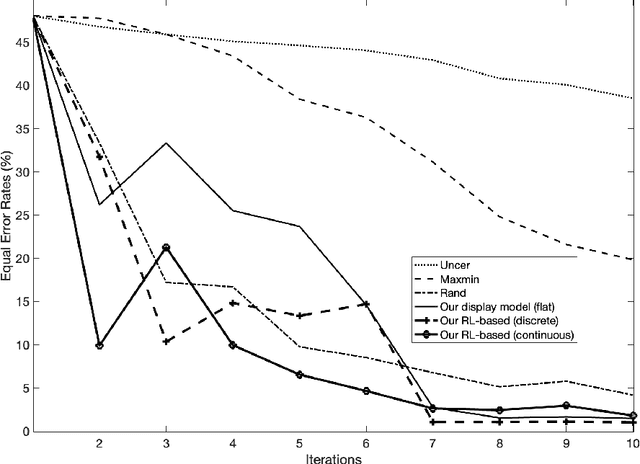
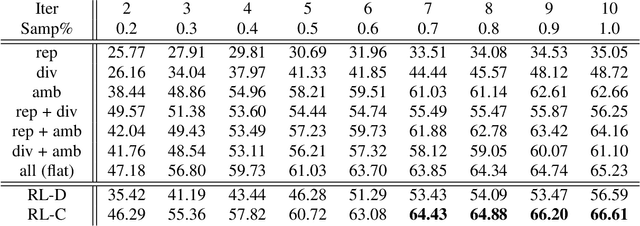
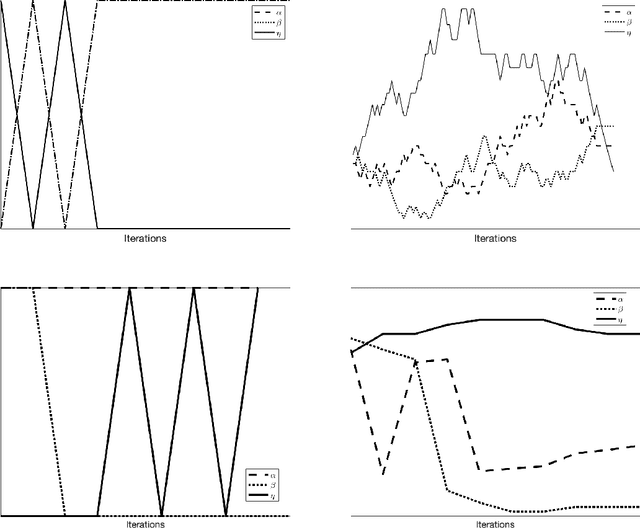
Most of the existing learning models, particularly deep neural networks, are reliant on large datasets whose hand-labeling is expensive and time demanding. A current trend is to make the learning of these models frugal and less dependent on large collections of labeled data. Among the existing solutions, deep active learning is currently witnessing a major interest and its purpose is to train deep networks using as few labeled samples as possible. However, the success of active learning is highly dependent on how critical are these samples when training models. In this paper, we devise a novel active learning approach for label-efficient training. The proposed method is iterative and aims at minimizing a constrained objective function that mixes diversity, representativity and uncertainty criteria. The proposed approach is probabilistic and unifies all these criteria in a single objective function whose solution models the probability of relevance of samples (i.e., how critical) when learning a decision function. We also introduce a novel weighting mechanism based on reinforcement learning, which adaptively balances these criteria at each training iteration, using a particular stateless Q-learning model. Extensive experiments conducted on staple image classification data, including Object-DOTA, show the effectiveness of our proposed model w.r.t. several baselines including random, uncertainty and flat as well as other work.