 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Spatial Temporal Graph Convolution with Graph Structure Self-learning for Early MCI Detection
Nov 11, 2022

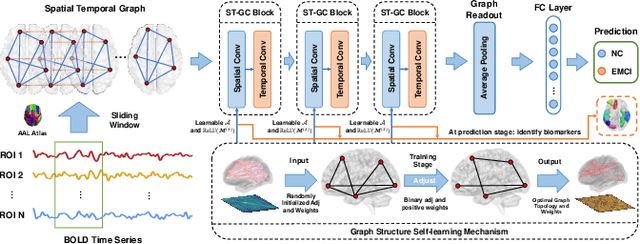
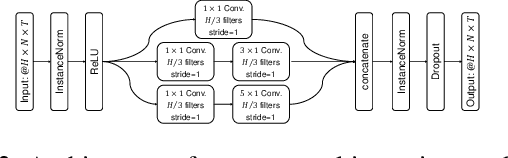
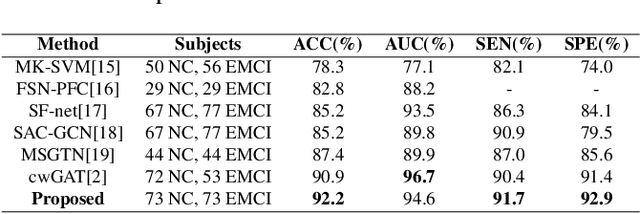
Graph neural networks (GNNs) have been successfully applied to early mild cognitive impairment (EMCI) detection, with the usage of elaborately designed features constructed from blood oxygen level-dependent (BOLD) time series. However, few works explored the feasibility of using BOLD signals directly as features. Meanwhile, existing GNN-based methods primarily rely on hand-crafted explicit brain topology as the adjacency matrix, which is not optimal and ignores the implicit topological organization of the brain. In this paper, we propose a spatial temporal graph convolutional network with a novel graph structure self-learning mechanism for EMCI detection. The proposed spatial temporal graph convolution block directly exploits BOLD time series as input features, which provides an interesting view for rsfMRI-based preclinical AD diagnosis. Moreover, our model can adaptively learn the optimal topological structure and refine edge weights with the graph structure self-learning mechanism. Results on the Alzheimer's Disease Neuroimaging Initiative (ADNI) database show that our method outperforms state-of-the-art approaches. Biomarkers consistent with previous studies can be extracted from the model, proving the reliable interpretability of our method.
Progressive Motion Context Refine Network for Efficient Video Frame Interpolation
Nov 11, 2022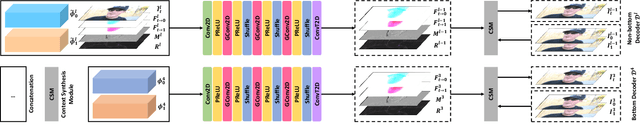
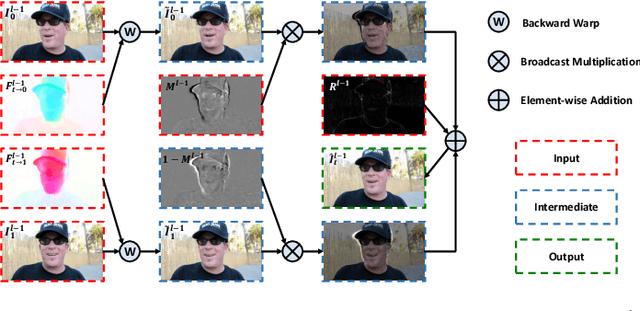

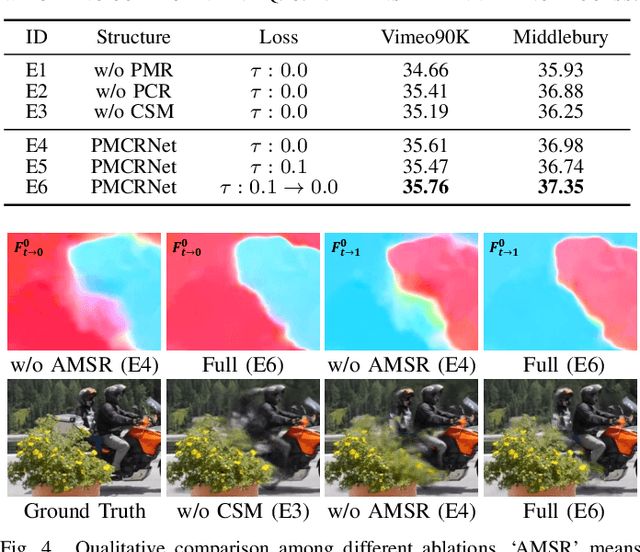
Recently, flow-based frame interpolation methods have achieved great success by first modeling optical flow between target and input frames, and then building synthesis network for target frame generation. However, above cascaded architecture can lead to large model size and inference delay, hindering them from mobile and real-time applications. To solve this problem, we propose a novel Progressive Motion Context Refine Network (PMCRNet) to predict motion fields and image context jointly for higher efficiency. Different from others that directly synthesize target frame from deep feature, we explore to simplify frame interpolation task by borrowing existing texture from adjacent input frames, which means that decoder in each pyramid level of our PMCRNet only needs to update easier intermediate optical flow, occlusion merge mask and image residual. Moreover, we introduce a new annealed multi-scale reconstruction loss to better guide the learning process of this efficient PMCRNet. Experiments on multiple benchmarks show that proposed approaches not only achieve favorable quantitative and qualitative results but also reduces current model size and running time significantly.
On Principal Curve-Based Classifiers and Similarity-Based Selective Sampling in Time-Series
Apr 10, 2022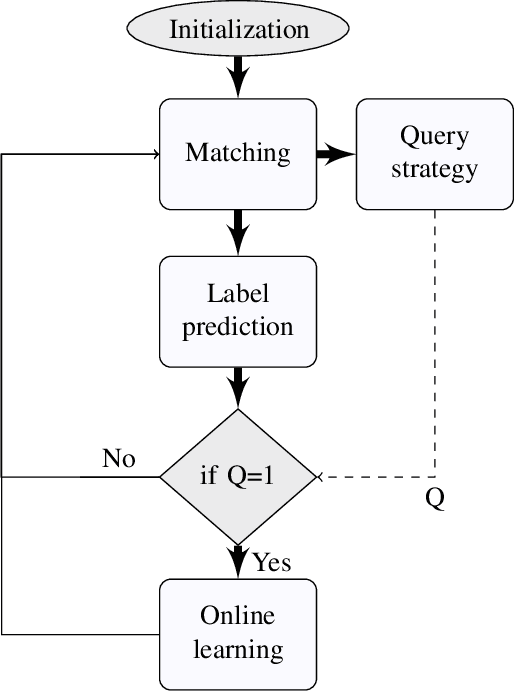
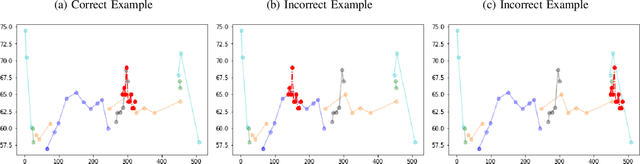
Considering the concept of time-dilation, there exist some major issues with recurrent neural Architectures. Any variation in time spans between input data points causes performance attenuation in recurrent neural network architectures. Principal curve-based classifiers have the ability of handling any kind of variation in time spans. In other words, principal curve-based classifiers preserve the relativity of time while neural network architecture violates this property of time. On the other hand, considering the labeling costs and problems in online monitoring devices, there should be an algorithm that finds the data points which knowing their labels will cause in better performance of the classifier. Current selective sampling algorithms have lack of reliability due to the randomness of the proposed algorithms. This paper proposes a classifier and also a deterministic selective sampling algorithm with the same computational steps, both by use of principal curve as their building block in model definition.
Unifying Vision, Text, and Layout for Universal Document Processing
Dec 05, 2022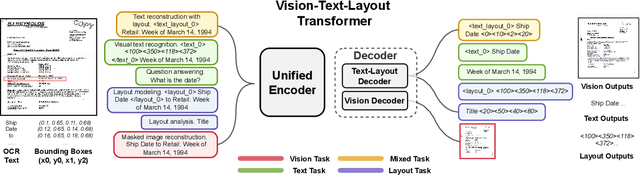

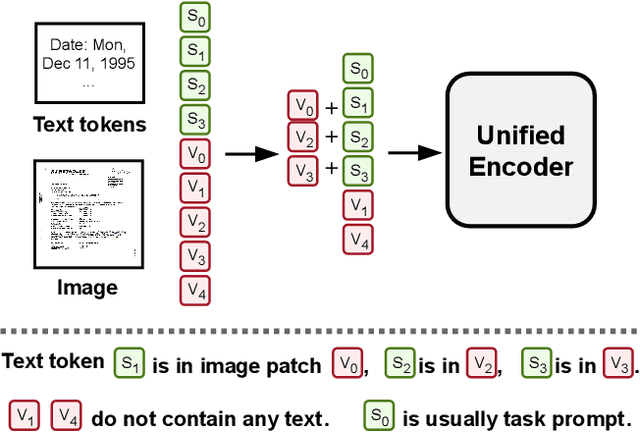
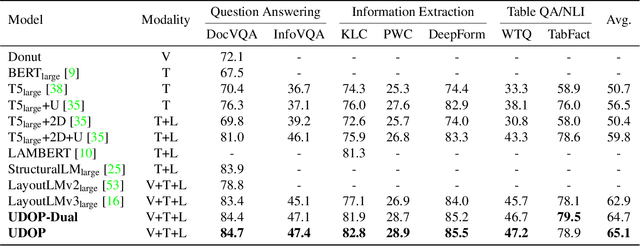
We propose Universal Document Processing (UDOP), a foundation Document AI model which unifies text, image, and layout modalities together with varied task formats, including document understanding and generation. UDOP leverages the spatial correlation between textual content and document image to model image, text, and layout modalities with one uniform representation. With a novel Vision-Text-Layout Transformer, UDOP unifies pretraining and multi-domain downstream tasks into a prompt-based sequence generation scheme. UDOP is pretrained on both large-scale unlabeled document corpora using innovative self-supervised objectives and diverse labeled data. UDOP also learns to generate document images from text and layout modalities via masked image reconstruction. To the best of our knowledge, this is the first time in the field of document AI that one model simultaneously achieves high-quality neural document editing and content customization. Our method sets the state-of-the-art on 9 Document AI tasks, e.g., document understanding and QA, across diverse data domains like finance reports, academic papers, and websites. UDOP ranks first on the leaderboard of the Document Understanding Benchmark (DUE).
POLCOVID: a multicenter multiclass chest X-ray database (Poland, 2020-2021)
Dec 05, 2022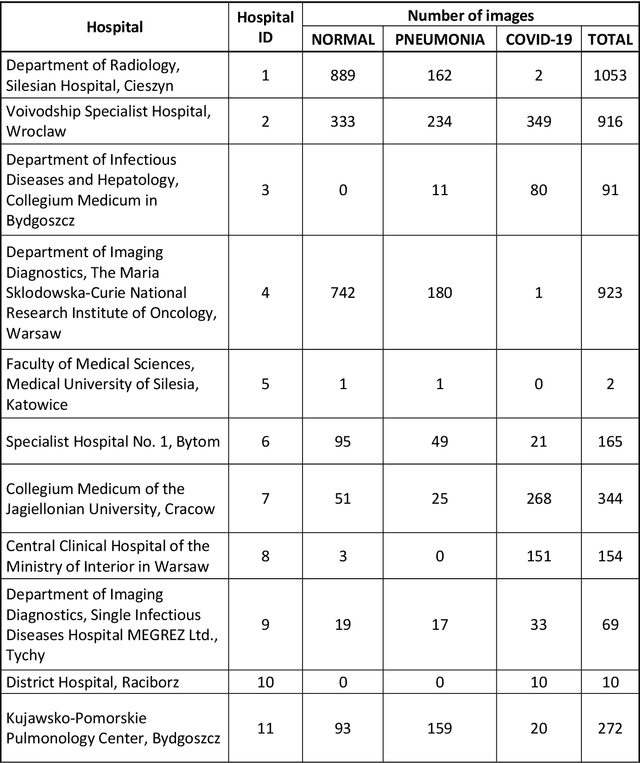
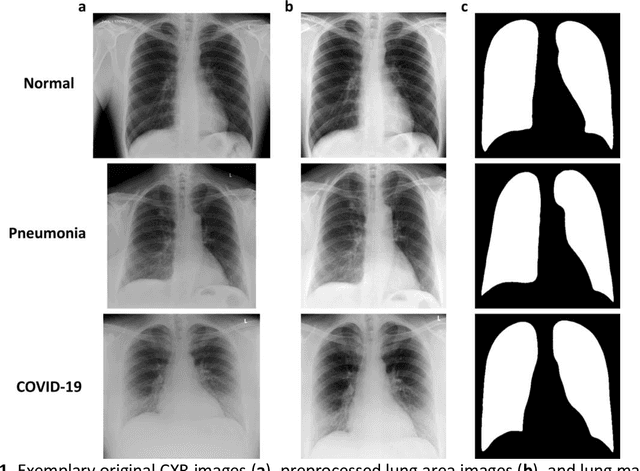
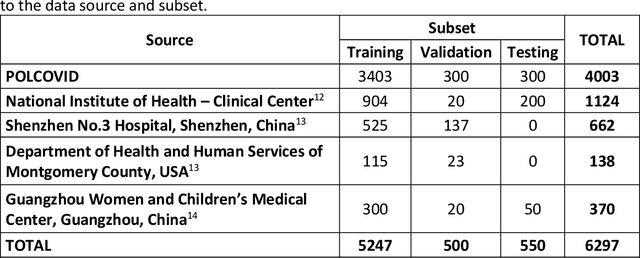
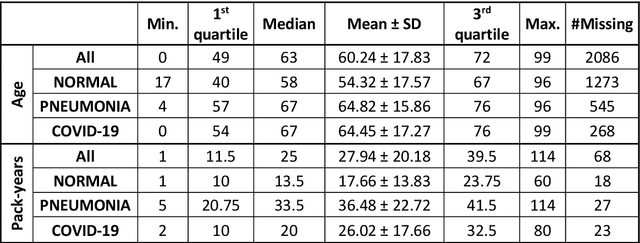
The outbreak of the SARS-CoV-2 pandemic has put healthcare systems worldwide to their limits, resulting in increased waiting time for diagnosis and required medical assistance. With chest radiographs (CXR) being one of the most common COVID-19 diagnosis methods, many artificial intelligence tools for image-based COVID-19 detection have been developed, often trained on a small number of images from COVID-19-positive patients. Thus, the need for high-quality and well-annotated CXR image databases increased. This paper introduces POLCOVID dataset, containing chest X-ray (CXR) images of patients with COVID-19 or other-type pneumonia, and healthy individuals gathered from 15 Polish hospitals. The original radiographs are accompanied by the preprocessed images limited to the lung area and the corresponding lung masks obtained with the segmentation model. Moreover, the manually created lung masks are provided for a part of POLCOVID dataset and the other four publicly available CXR image collections. POLCOVID dataset can help in pneumonia or COVID-19 diagnosis, while the set of matched images and lung masks may serve for the development of lung segmentation solutions.
Mixed Cloud Control Testbed: Validating Vehicle-Road-Cloud Integration via Mixed Digital Twin
Dec 05, 2022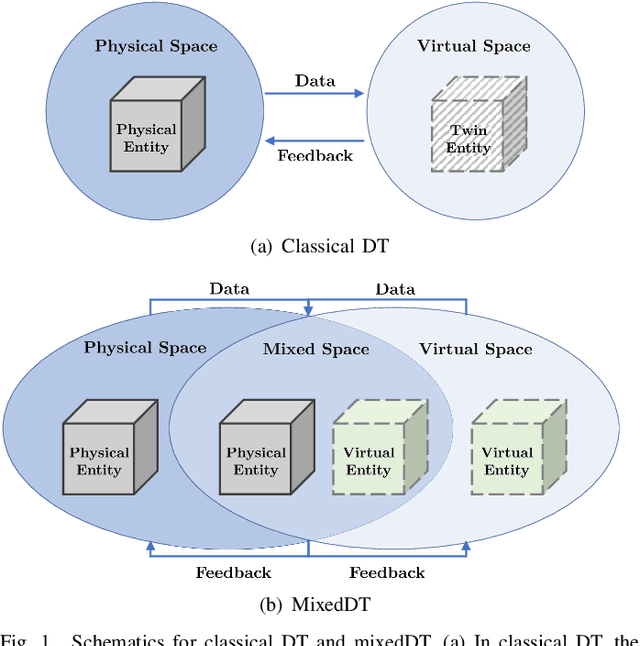

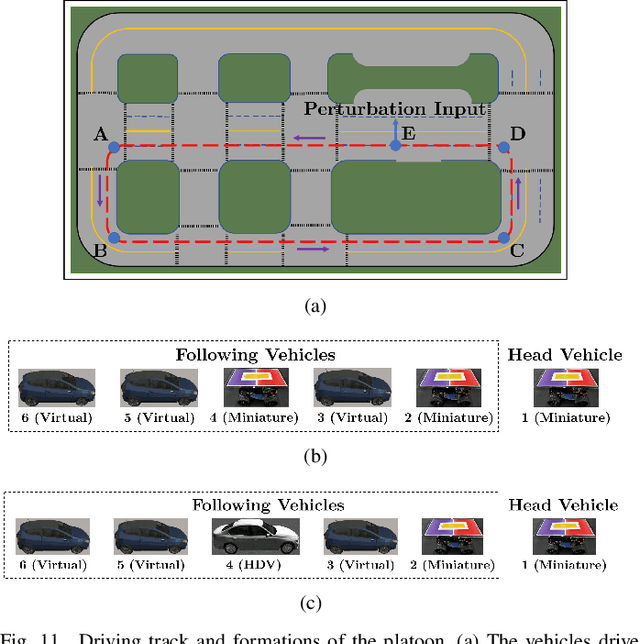
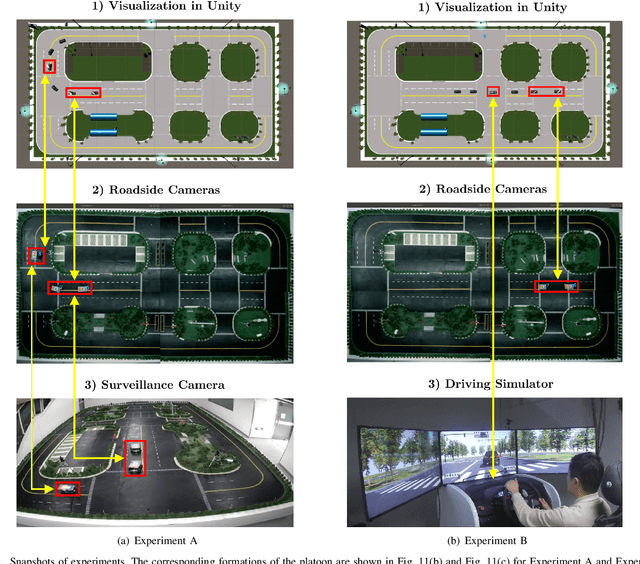
Reliable and efficient validation technologies are critical for the recent development of multi-vehicle cooperation and vehicle-road-cloud integration. In this paper, we introduce our miniature experimental platform, Mixed Cloud Control Testbed (MCCT), developed based on a new notion of Mixed Digital Twin (mixedDT). Combining Mixed Reality with Digital Twin, mixedDT integrates the virtual and physical spaces into a mixed one, where physical entities coexist and interact with virtual entities via their digital counterparts. Under the framework of mixedDT, MCCT contains three major experimental platforms in the physical, virtual and mixed spaces respectively, and provides a unified access for various human-machine interfaces and external devices such as driving simulators. A cloud unit, where the mixed experimental platform is deployed, is responsible for fusing multi-platform information and assigning control instructions, contributing to synchronous operation and real-time cross-platform interaction. Particularly, MCCT allows for multi-vehicle coordination composed of different multi-source vehicles (\eg, physical vehicles, virtual vehicles and human-driven vehicles). Validations on vehicle platooning demonstrate the flexibility and scalability of MCCT.
Retrieval as Attention: End-to-end Learning of Retrieval and Reading within a Single Transformer
Dec 05, 2022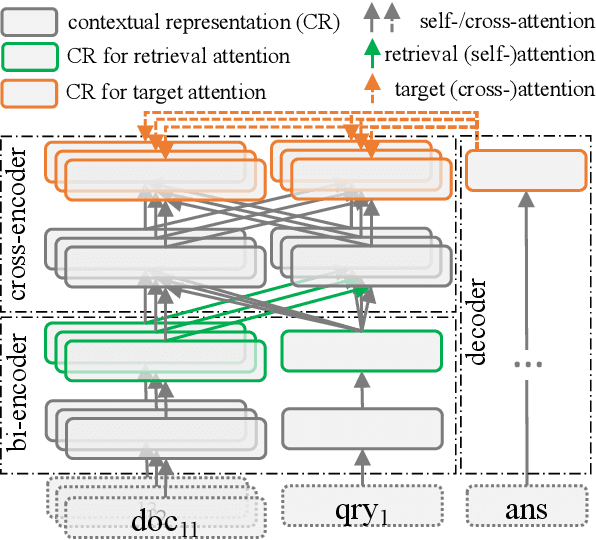
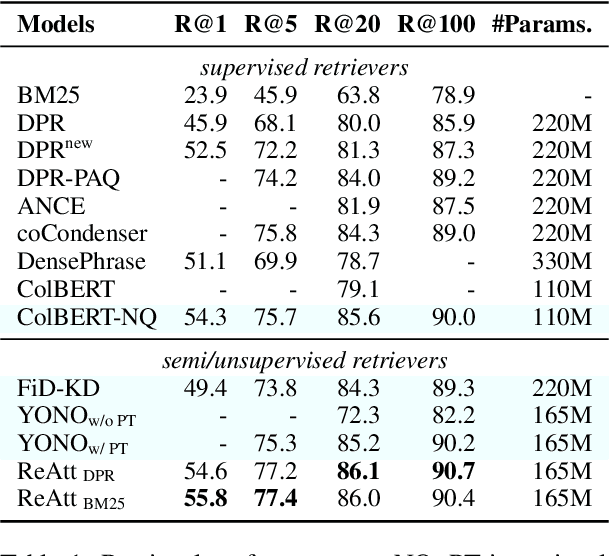
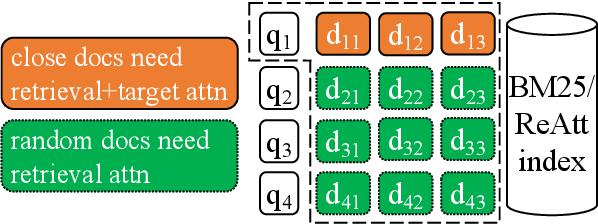
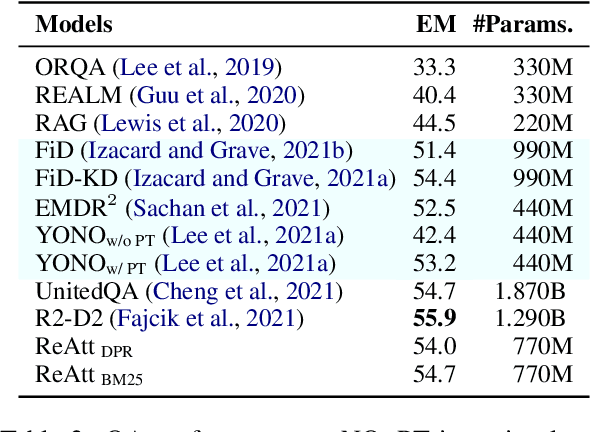
Systems for knowledge-intensive tasks such as open-domain question answering (QA) usually consist of two stages: efficient retrieval of relevant documents from a large corpus and detailed reading of the selected documents to generate answers. Retrievers and readers are usually modeled separately, which necessitates a cumbersome implementation and is hard to train and adapt in an end-to-end fashion. In this paper, we revisit this design and eschew the separate architecture and training in favor of a single Transformer that performs Retrieval as Attention (ReAtt), and end-to-end training solely based on supervision from the end QA task. We demonstrate for the first time that a single model trained end-to-end can achieve both competitive retrieval and QA performance, matching or slightly outperforming state-of-the-art separately trained retrievers and readers. Moreover, end-to-end adaptation significantly boosts its performance on out-of-domain datasets in both supervised and unsupervised settings, making our model a simple and adaptable solution for knowledge-intensive tasks. Code and models are available at https://github.com/jzbjyb/ReAtt.
Using Decoupled Features for Photo-realistic Style Transfer
Dec 05, 2022

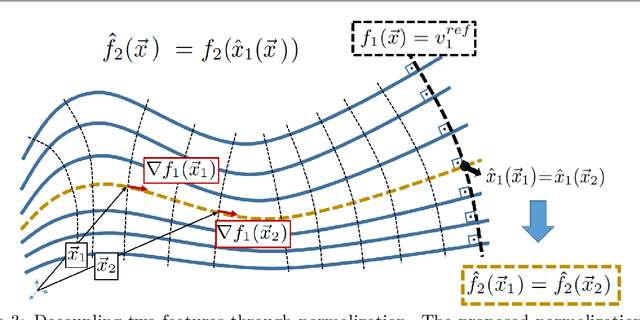
In this work we propose a photorealistic style transfer method for image and video that is based on vision science principles and on a recent mathematical formulation for the deterministic decoupling of sample statistics. The novel aspects of our approach include matching decoupled moments of higher order than in common style transfer approaches, and matching a descriptor of the power spectrum so as to characterize and transfer diffusion effects between source and target, which is something that has not been considered before in the literature. The results are of high visual quality, without spatio-temporal artifacts, and validation tests in the form of observer preference experiments show that our method compares very well with the state-of-the-art. The computational complexity of the algorithm is low, and we propose a numerical implementation that is amenable for real-time video application. Finally, another contribution of our work is to point out that current deep learning approaches for photorealistic style transfer don't really achieve photorealistic quality outside of limited examples, because the results too often show unacceptable visual artifacts.
OMU: A Probabilistic 3D Occupancy Mapping Accelerator for Real-time OctoMap at the Edge
May 06, 2022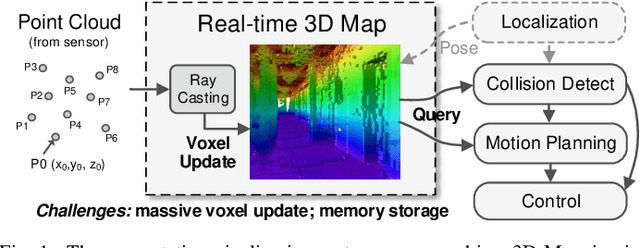
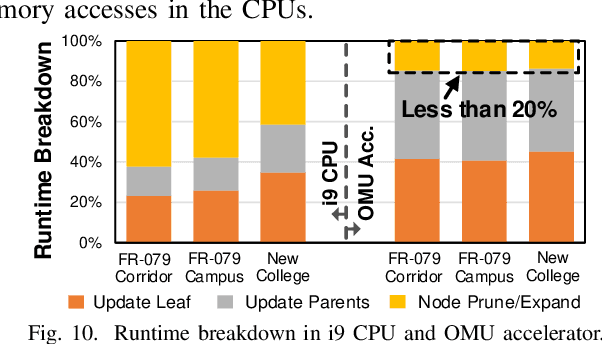
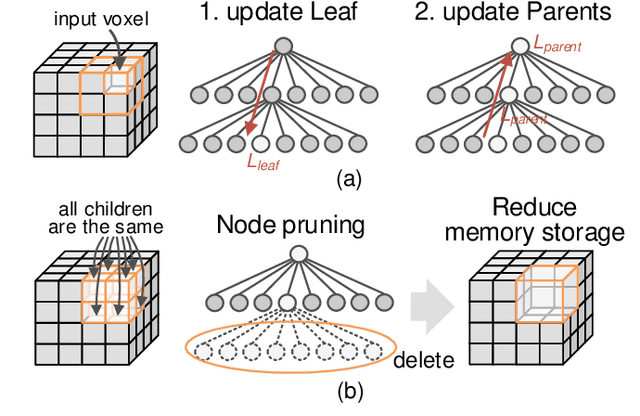
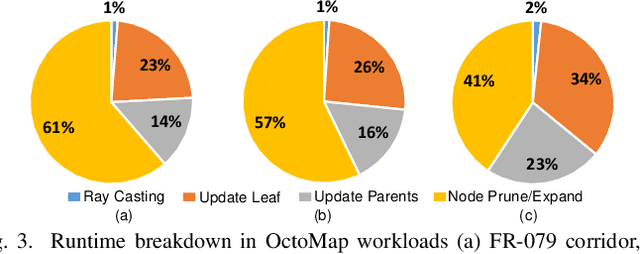
Autonomous machines (e.g., vehicles, mobile robots, drones) require sophisticated 3D mapping to perceive the dynamic environment. However, maintaining a real-time 3D map is expensive both in terms of compute and memory requirements, especially for resource-constrained edge machines. Probabilistic OctoMap is a reliable and memory-efficient 3D dense map model to represent the full environment, with dynamic voxel node pruning and expansion capacity. This paper presents the first efficient accelerator solution, i.e. OMU, to enable real-time probabilistic 3D mapping at the edge. To improve the performance, the input map voxels are updated via parallel PE units for data parallelism. Within each PE, the voxels are stored using a specially developed data structure in parallel memory banks. In addition, a pruning address manager is designed within each PE unit to reuse the pruned memory addresses. The proposed 3D mapping accelerator is implemented and evaluated using a commercial 12 nm technology. Compared to the ARM Cortex-A57 CPU in the Nvidia Jetson TX2 platform, the proposed accelerator achieves up to 62$\times$ performance and 708$\times$ energy efficiency improvement. Furthermore, the accelerator provides 63 FPS throughput, more than 2$\times$ higher than a real-time requirement, enabling real-time perception for 3D mapping.
Healthy Twitter discussions? Time will tell
Mar 21, 2022

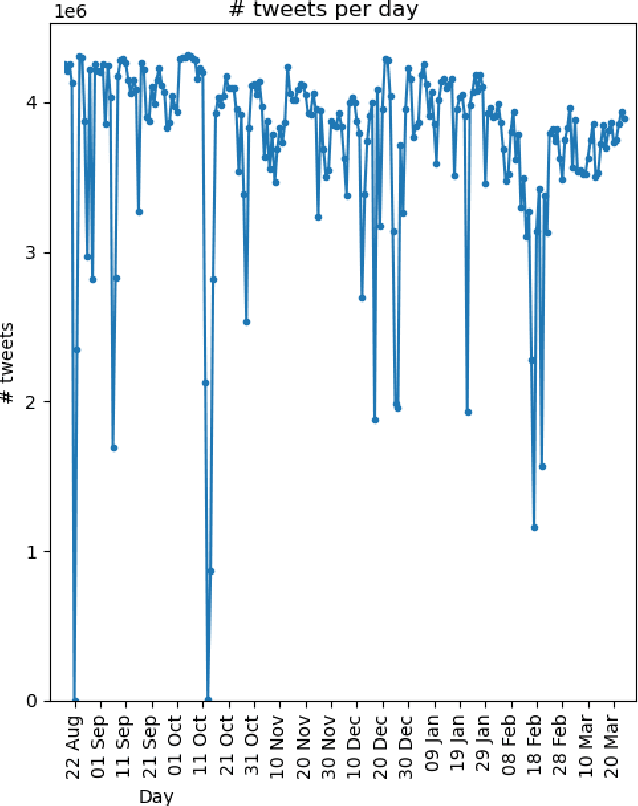
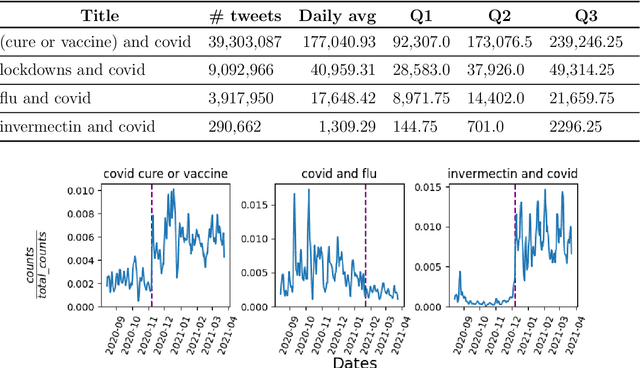
Studying misinformation and how to deal with unhealthy behaviours within online discussions has recently become an important field of research within social studies. With the rapid development of social media, and the increasing amount of available information and sources, rigorous manual analysis of such discourses has become unfeasible. Many approaches tackle the issue by studying the semantic and syntactic properties of discussions following a supervised approach, for example using natural language processing on a dataset labeled for abusive, fake or bot-generated content. Solutions based on the existence of a ground truth are limited to those domains which may have ground truth. However, within the context of misinformation, it may be difficult or even impossible to assign labels to instances. In this context, we consider the use of temporal dynamic patterns as an indicator of discussion health. Working in a domain for which ground truth was unavailable at the time (early COVID-19 pandemic discussions) we explore the characterization of discussions based on the the volume and time of contributions. First we explore the types of discussions in an unsupervised manner, and then characterize these types using the concept of ephemerality, which we formalize. In the end, we discuss the potential use of our ephemerality definition for labeling online discourses based on how desirable, healthy and constructive they are.