 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DimenFix: A novel meta-dimensionality reduction method for feature preservation
Nov 30, 2022
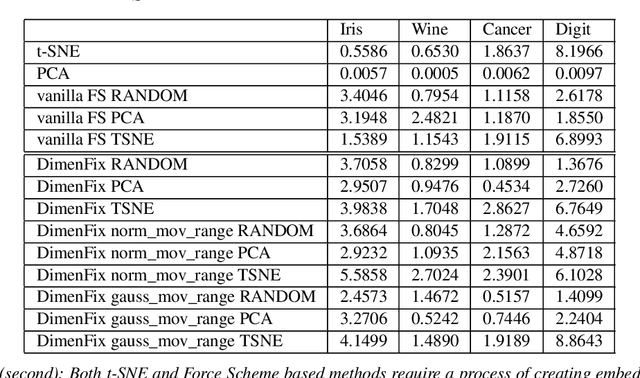
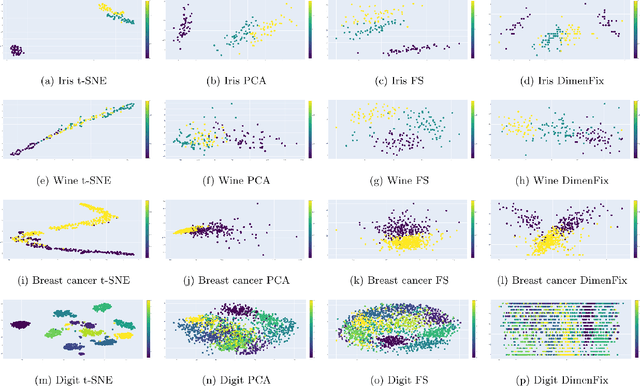
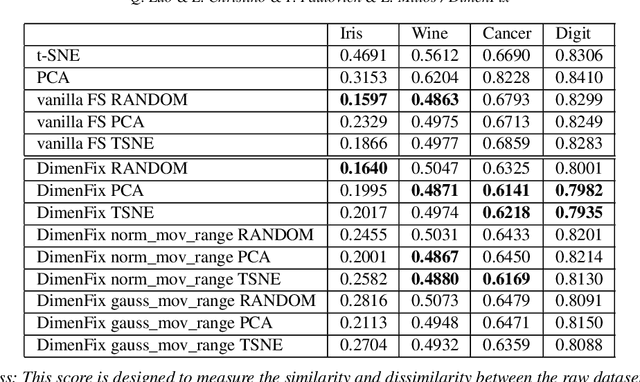
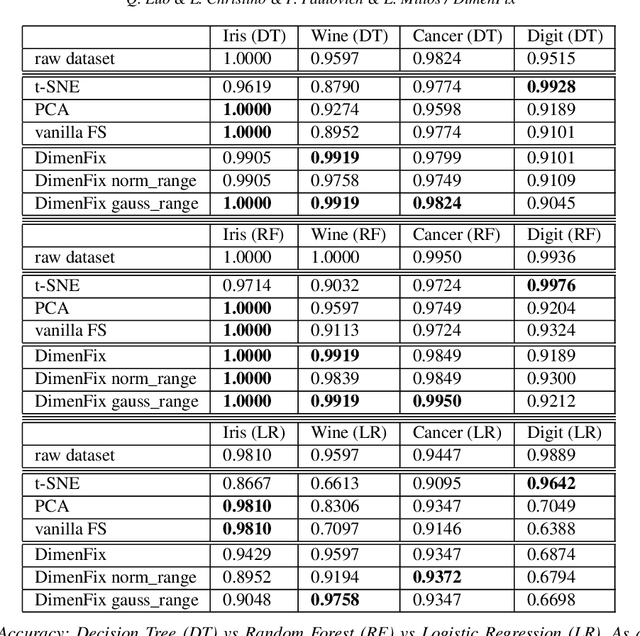
Dimensionality reduction has become an important research topic as demand for interpreting high-dimensional datasets has been increasing rapidly in recent years. There have been many dimensionality reduction methods with good performance in preserving the overall relationship among data points when mapping them to a lower-dimensional space. However, these existing methods fail to incorporate the difference in importance among features. To address this problem, we propose a novel meta-method, DimenFix, which can be operated upon any base dimensionality reduction method that involves a gradient-descent-like process. By allowing users to define the importance of different features, which is considered in dimensionality reduction, DimenFix creates new possibilities to visualize and understand a given dataset. Meanwhile, DimenFix does not increase the time cost or reduce the quality of dimensionality reduction with respect to the base dimensionality reduction used.
A Review of Open Source Software Tools for Time Series Analysis
Mar 10, 2022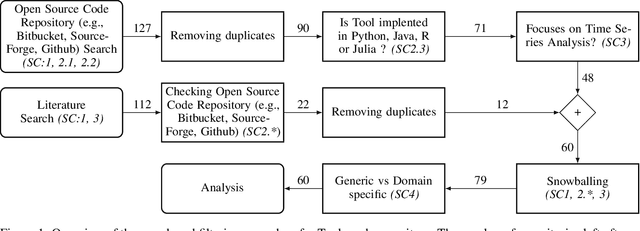
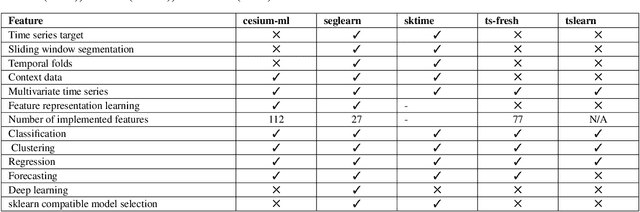
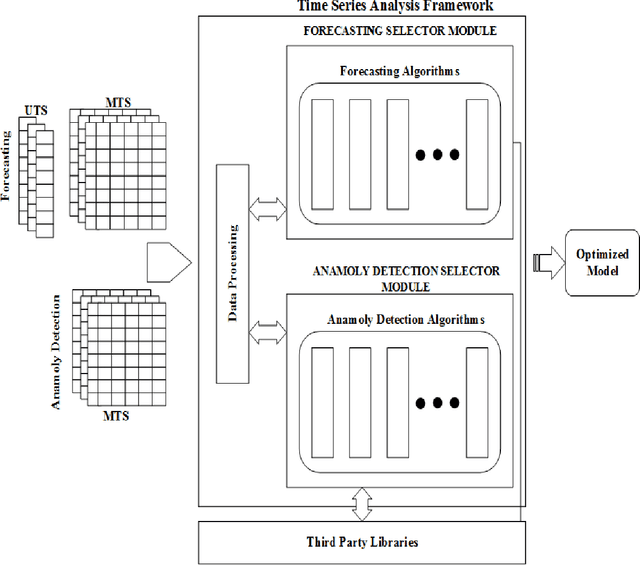

Time series data is used in a wide range of real world applications. In a variety of domains , detailed analysis of time series data (via Forecasting and Anomaly Detection) leads to a better understanding of how events associated with a specific time instance behave. Time Series Analysis (TSA) is commonly performed with plots and traditional models. Machine Learning (ML) approaches , on the other hand , have seen an increase in the state of the art for Forecasting and Anomaly Detection because they provide comparable results when time and data constraints are met. A number of time series toolboxes are available that offer rich interfaces to specific model classes (ARIMA/filters , neural networks) or framework interfaces to isolated time series modelling tasks (forecasting , feature extraction , annotation , classification). Nonetheless , open source machine learning capabilities for time series remain limited , and existing libraries are frequently incompatible with one another. The goal of this paper is to provide a concise and user friendly overview of the most important open source tools for time series analysis. This article examines two related toolboxes (1) forecasting and (2) anomaly detection. This paper describes a typical Time Series Analysis (TSA) framework with an architecture and lists the main features of TSA framework. The tools are categorized based on the criteria of analysis tasks completed , data preparation methods employed , and evaluation methods for results generated. This paper presents quantitative analysis and discusses the current state of actively developed open source Time Series Analysis frameworks. Overall , this article considered 60 time series analysis tools , and 32 of which provided forecasting modules , and 21 packages included anomaly detection.
Zero-Shot Dynamic Quantization for Transformer Inference
Nov 17, 2022
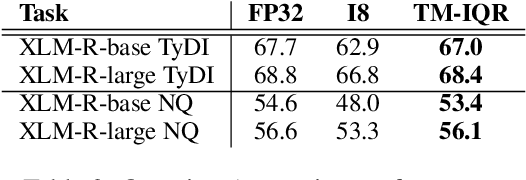
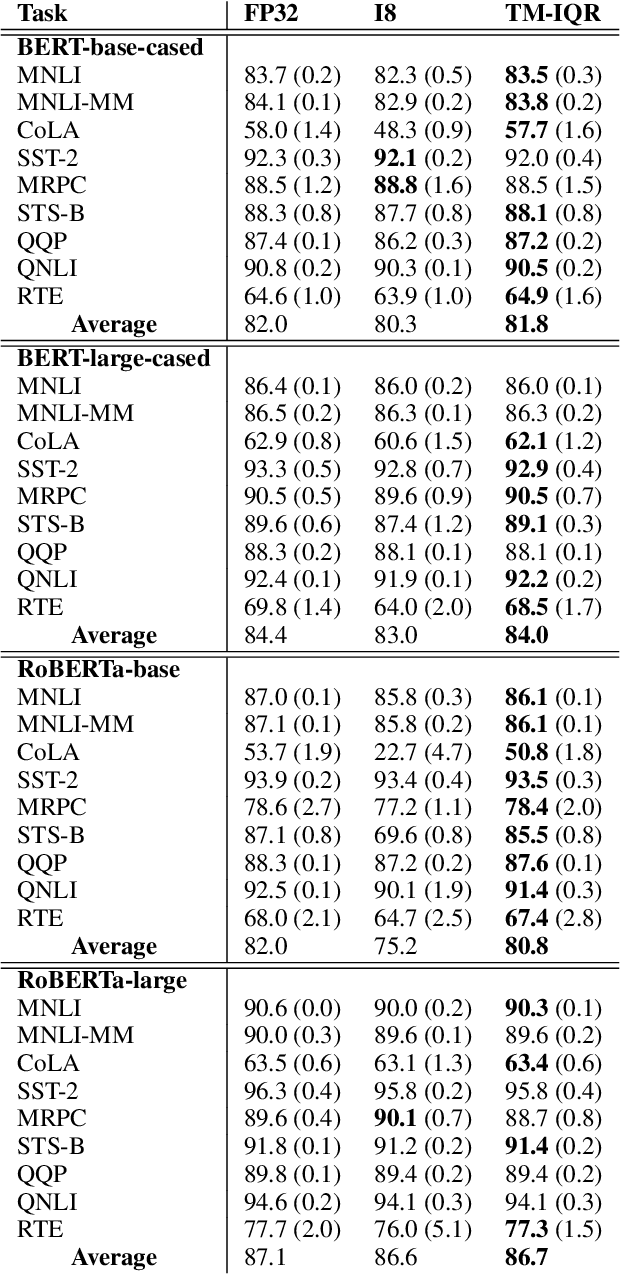
We introduce a novel run-time method for significantly reducing the accuracy loss associated with quantizing BERT-like models to 8-bit integers. Existing methods for quantizing models either modify the training procedure,or they require an additional calibration step to adjust parameters that also requires a selected held-out dataset. Our method permits taking advantage of quantization without the need for these adjustments. We present results on several NLP tasks demonstrating the usefulness of this technique.
Efficient Test-Time Model Adaptation without Forgetting
Apr 06, 2022
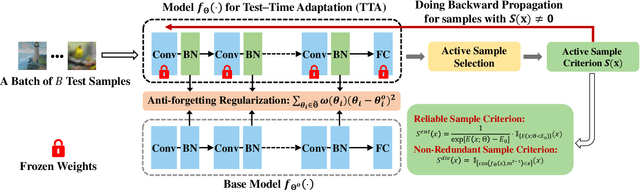
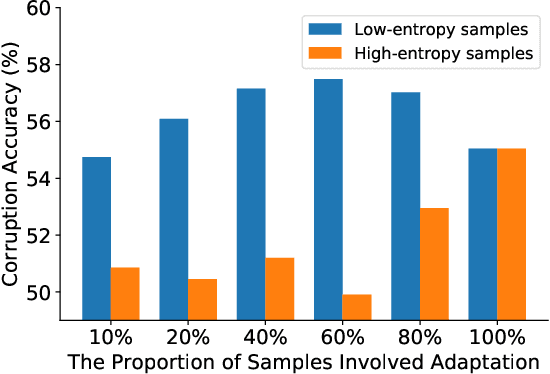
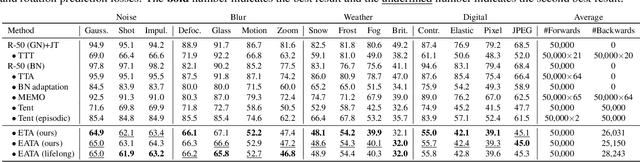
Test-time adaptation (TTA) seeks to tackle potential distribution shifts between training and testing data by adapting a given model w.r.t. any testing sample. This task is particularly important for deep models when the test environment changes frequently. Although some recent attempts have been made to handle this task, we still face two practical challenges: 1) existing methods have to perform backward computation for each test sample, resulting in unbearable prediction cost to many applications; 2) while existing TTA solutions can significantly improve the test performance on out-of-distribution data, they often suffer from severe performance degradation on in-distribution data after TTA (known as catastrophic forgetting). In this paper, we point out that not all the test samples contribute equally to model adaptation, and high-entropy ones may lead to noisy gradients that could disrupt the model. Motivated by this, we propose an active sample selection criterion to identify reliable and non-redundant samples, on which the model is updated to minimize the entropy loss for test-time adaptation. Furthermore, to alleviate the forgetting issue, we introduce a Fisher regularizer to constrain important model parameters from drastic changes, where the Fisher importance is estimated from test samples with generated pseudo labels. Extensive experiments on CIFAR-10-C, ImageNet-C, and ImageNet-R verify the effectiveness of our proposed method.
Decentralized Federated Reinforcement Learning for User-Centric Dynamic TFDD Control
Nov 04, 2022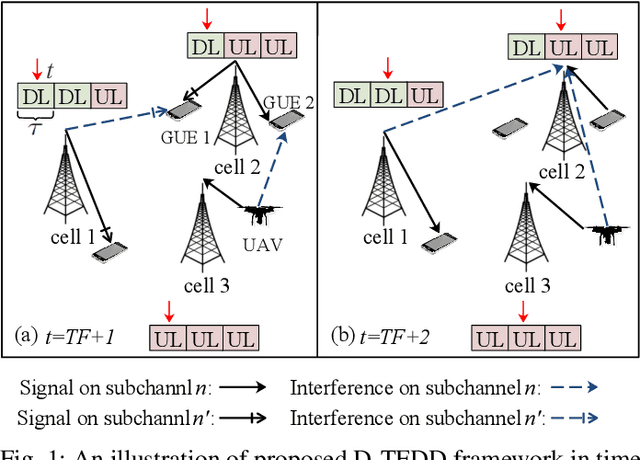
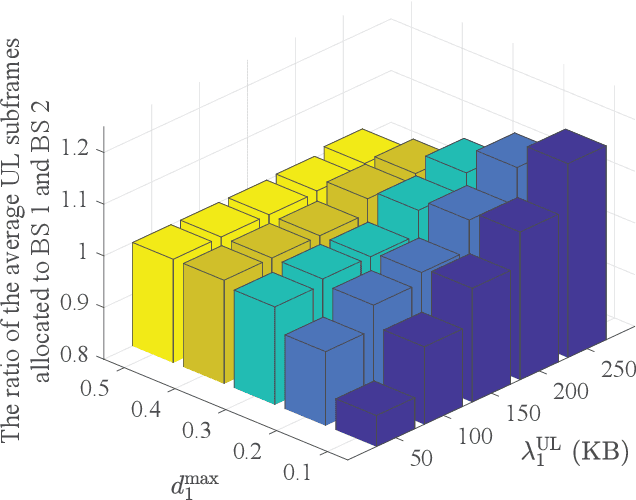
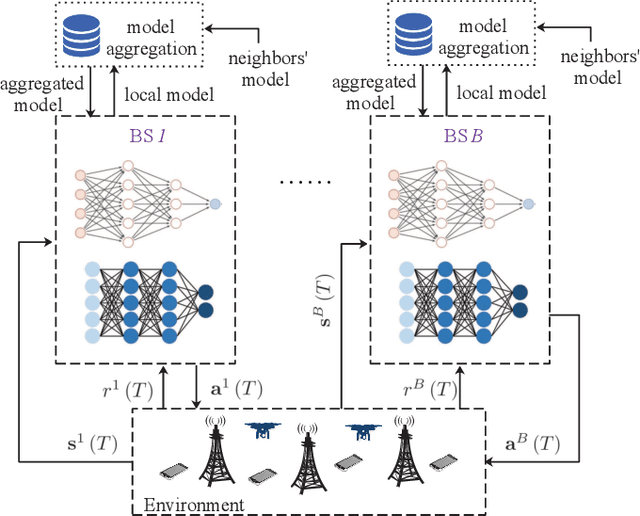
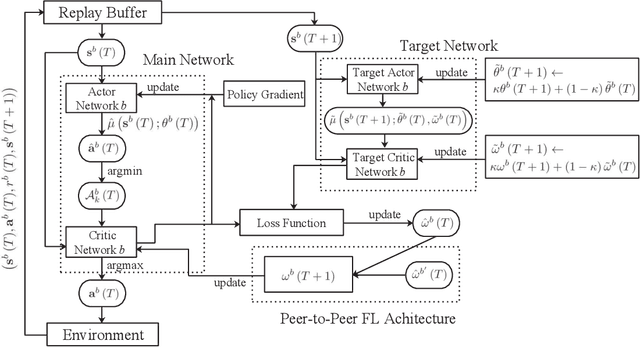
The explosive growth of dynamic and heterogeneous data traffic brings great challenges for 5G and beyond mobile networks. To enhance the network capacity and reliability, we propose a learning-based dynamic time-frequency division duplexing (D-TFDD) scheme that adaptively allocates the uplink and downlink time-frequency resources of base stations (BSs) to meet the asymmetric and heterogeneous traffic demands while alleviating the inter-cell interference. We formulate the problem as a decentralized partially observable Markov decision process (Dec-POMDP) that maximizes the long-term expected sum rate under the users' packet dropping ratio constraints. In order to jointly optimize the global resources in a decentralized manner, we propose a federated reinforcement learning (RL) algorithm named federated Wolpertinger deep deterministic policy gradient (FWDDPG) algorithm. The BSs decide their local time-frequency configurations through RL algorithms and achieve global training via exchanging local RL models with their neighbors under a decentralized federated learning framework. Specifically, to deal with the large-scale discrete action space of each BS, we adopt a DDPG-based algorithm to generate actions in a continuous space, and then utilize Wolpertinger policy to reduce the mapping errors from continuous action space back to discrete action space. Simulation results demonstrate the superiority of our proposed algorithm to benchmark algorithms with respect to system sum rate.
SBSS: Stacking-Based Semantic Segmentation Framework for Very High Resolution Remote Sensing Image
Dec 15, 2022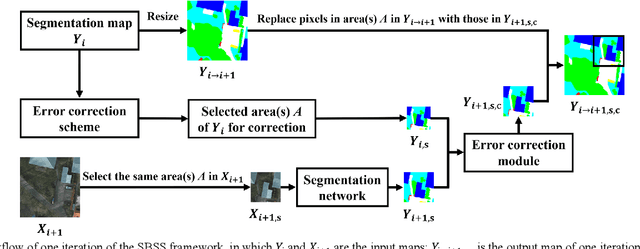
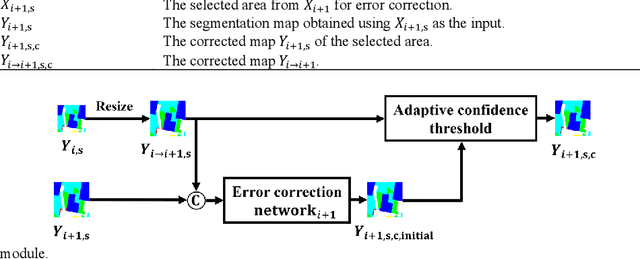
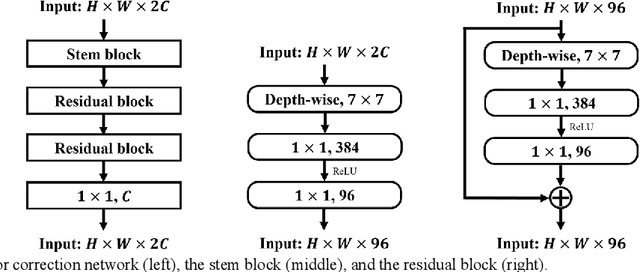
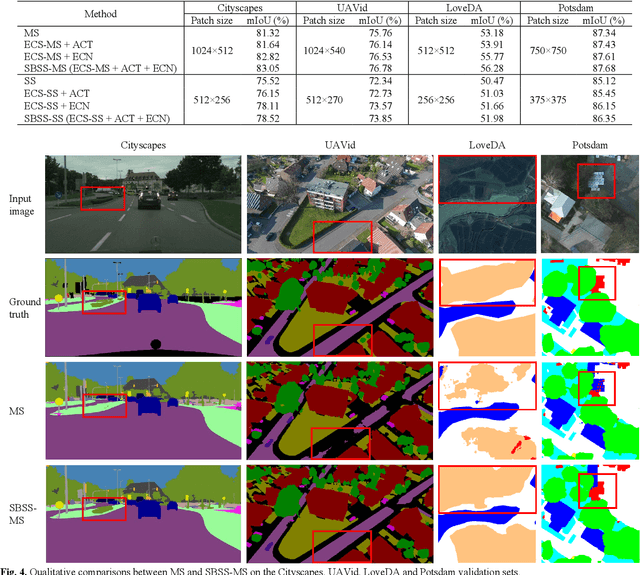
Semantic segmentation of Very High Resolution (VHR) remote sensing images is a fundamental task for many applications. However, large variations in the scales of objects in those VHR images pose a challenge for performing accurate semantic segmentation. Existing semantic segmentation networks are able to analyse an input image at up to four resizing scales, but this may be insufficient given the diversity of object scales. Therefore, Multi Scale (MS) test-time data augmentation is often used in practice to obtain more accurate segmentation results, which makes equal use of the segmentation results obtained at the different resizing scales. However, it was found in this study that different classes of objects had their preferred resizing scale for more accurate semantic segmentation. Based on this behaviour, a Stacking-Based Semantic Segmentation (SBSS) framework is proposed to improve the segmentation results by learning this behaviour, which contains a learnable Error Correction Module (ECM) for segmentation result fusion and an Error Correction Scheme (ECS) for computational complexity control. Two ECS, i.e., ECS-MS and ECS-SS, are proposed and investigated in this study. The Floating-point operations (Flops) required for ECS-MS and ECS-SS are similar to the commonly used MS test and the Single-Scale (SS) test, respectively. Extensive experiments on four datasets (i.e., Cityscapes, UAVid, LoveDA and Potsdam) show that SBSS is an effective and flexible framework. It achieved higher accuracy than MS when using ECS-MS, and similar accuracy as SS with a quarter of the memory footprint when using ECS-SS.
An analysis of degenerating speech due to progressive dysarthria on ASR performance
Oct 31, 2022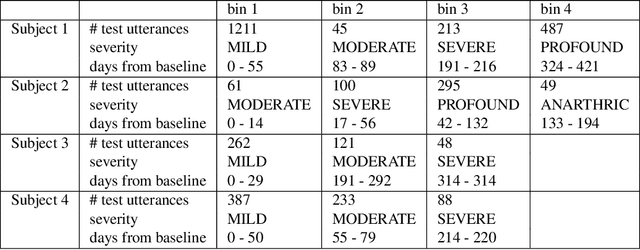
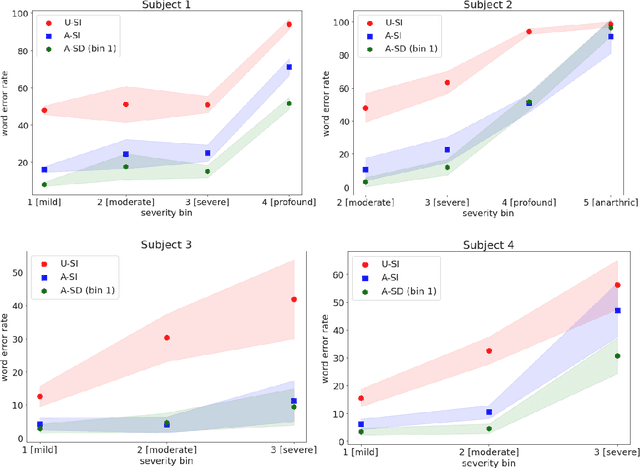

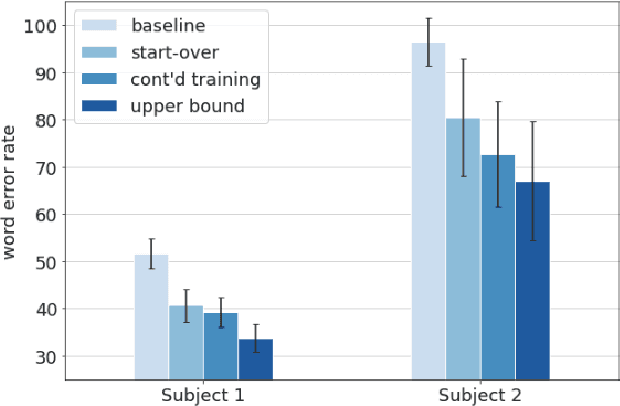
Although personalized automatic speech recognition (ASR) models have recently been designed to recognize even severely impaired speech, model performance may degrade over time for persons with degenerating speech. The aims of this study were to (1) analyze the change of performance of ASR over time in individuals with degrading speech, and (2) explore mitigation strategies to optimize recognition throughout disease progression. Speech was recorded by four individuals with degrading speech due to amyotrophic lateral sclerosis (ALS). Word error rates (WER) across recording sessions were computed for three ASR models: Unadapted Speaker Independent (U-SI), Adapted Speaker Independent (A-SI), and Adapted Speaker Dependent (A-SD or personalized). The performance of all three models degraded significantly over time as speech became more impaired, but the performance of the A-SD model improved markedly when it was updated with recordings from the severe stages of speech progression. Recording additional utterances early in the disease before speech degraded significantly did not improve the performance of A-SD models. Overall, our findings emphasize the importance of continuous recording (and model retraining) when providing personalized models for individuals with progressive speech impairments.
Deep Discriminative Direct Decoders for High-dimensional Time-series Analysis
May 22, 2022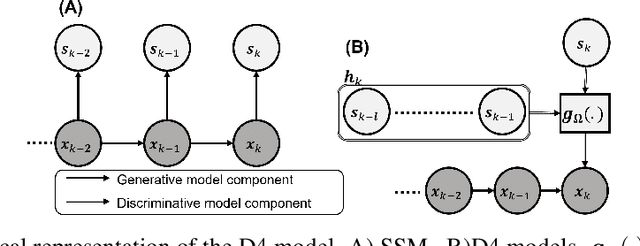
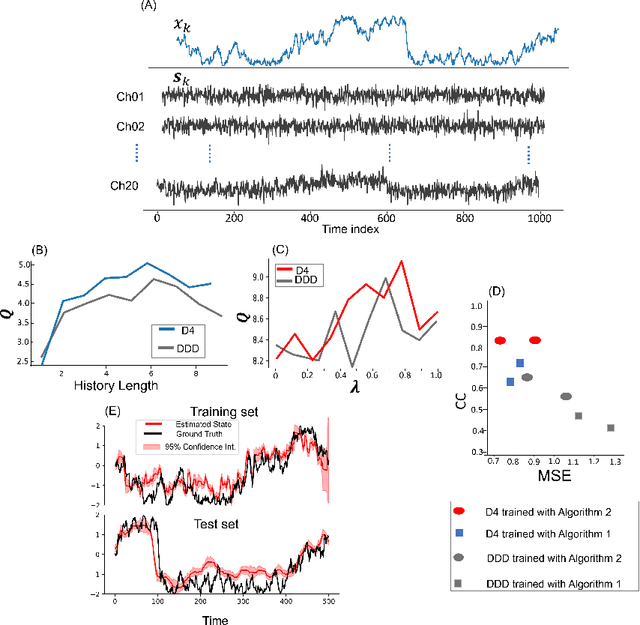
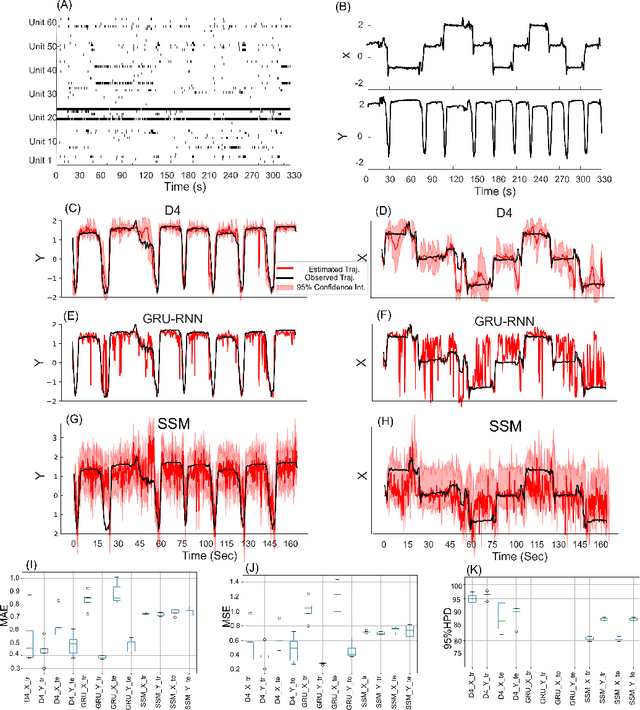
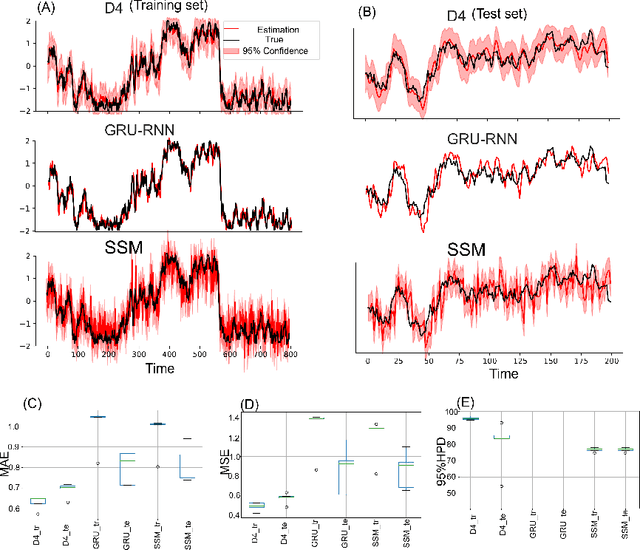
Dynamical latent variable modeling has been significantly invested over the last couple of decades with established solutions encompassing generative processes like the state-space model (SSM) and discriminative processes like a recurrent or a deep neural network (DNN). These solutions are powerful tools with promising results; however, surprisingly they were never put together in a unified model to analyze complex multivariate time-series data. A very recent modeling approach, called the direct discriminative decoder (DDD) model, proposes a principal solution to combine SMM and DNN models, with promising results in decoding underlying latent processes, e.g. rat movement trajectory, through high-dimensional neural recordings. The DDD consists of a) a state transition process, as per the classical dynamical models, and b) a discriminative process, like DNN, in which the conditional distribution of states is defined as a function of the current observations and their recent history. Despite promising results of the DDD model, no training solutions, in the context of DNN, have been utilized for this model. Here, we propose how DNN parameters along with an optimal history term can be simultaneously estimated as a part of the DDD model. We use the D4 abbreviation for a DDD with a DNN as its discriminative process. We showed the D4 decoding performance in both simulation and (relatively) high-dimensional neural data. In both datasets, D4 performance surpasses the state-of-art decoding solutions, including those of SSM and DNNs. The key success of DDD and potentially D4 is efficient utilization of the recent history of observation along with the state-process that carries long-term information, which is not addressed in either SSM or DNN solutions. We argue that D4 can be a powerful tool for the analysis of high-dimensional time-series data.
MDA: Availability-Aware Federated Learning Client Selection
Nov 25, 2022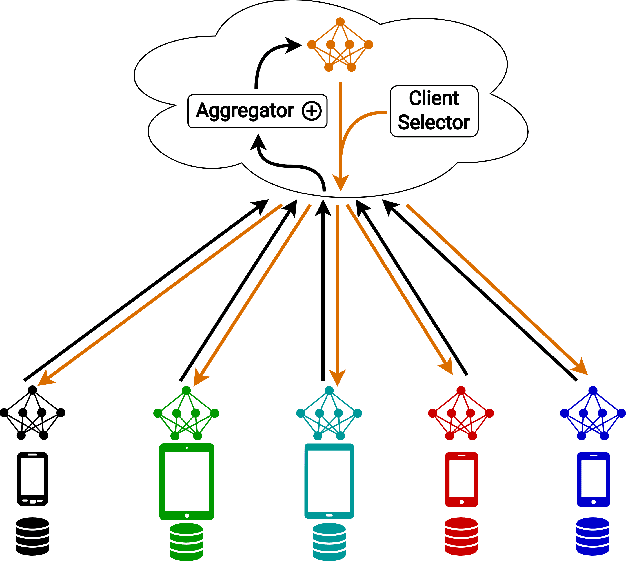
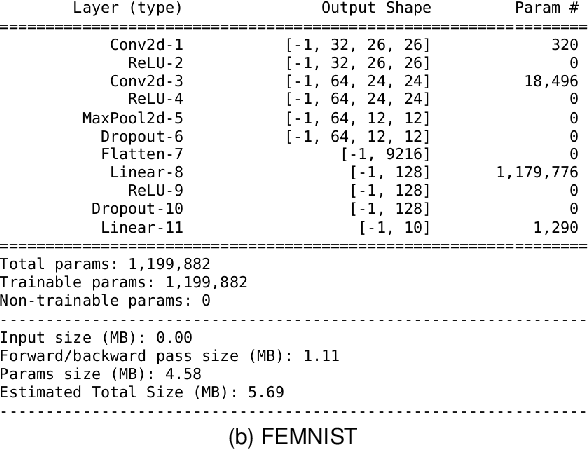
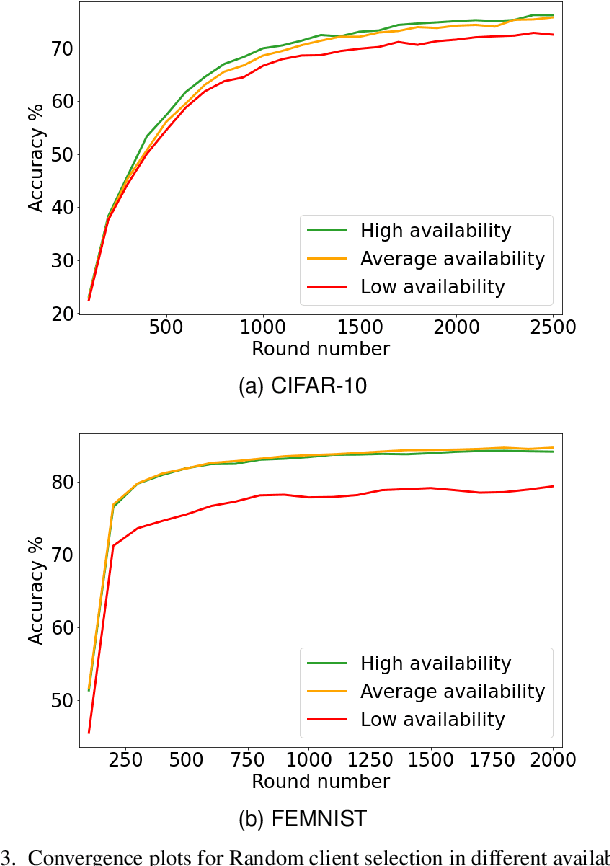
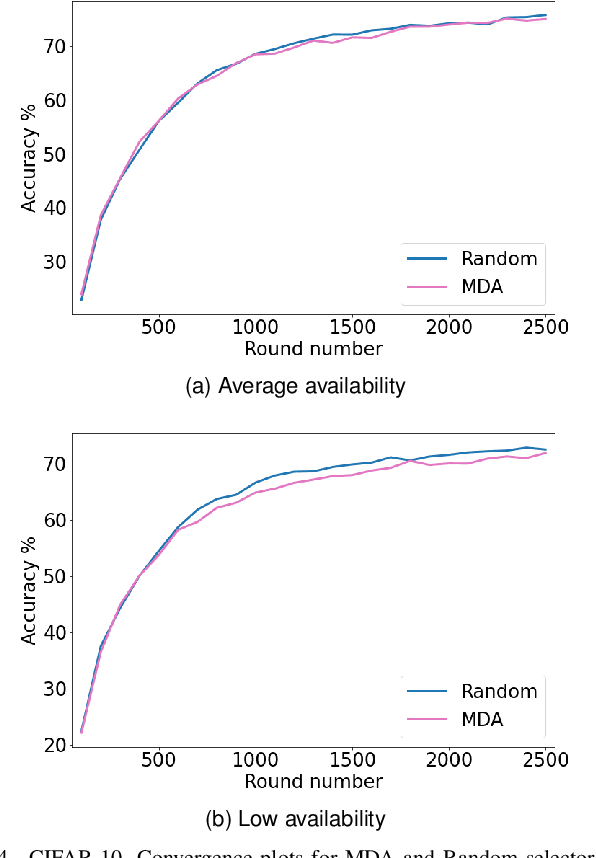
Recently, a new distributed learning scheme called Federated Learning (FL) has been introduced. FL is designed so that server never collects user-owned data meaning it is great at preserving privacy. FL's process starts with the server sending a model to clients, then the clients train that model using their data and send the updated model back to the server. Afterward, the server aggregates all the updates and modifies the global model. This process is repeated until the model converges. This study focuses on an FL setting called cross-device FL, which trains based on a large number of clients. Since many devices may be unavailable in cross-device FL, and communication between the server and all clients is extremely costly, only a fraction of clients gets selected for training at each round. In vanilla FL, clients are selected randomly, which results in an acceptable accuracy but is not ideal from the overall training time perspective, since some clients are slow and can cause some training rounds to be slow. If only fast clients get selected the learning would speed up, but it will be biased toward only the fast clients' data, and the accuracy degrades. Consequently, new client selection techniques have been proposed to improve the training time by considering individual clients' resources and speed. This paper introduces the first availability-aware selection strategy called MDA. The results show that our approach makes learning faster than vanilla FL by up to 6.5%. Moreover, we show that resource heterogeneity-aware techniques are effective but can become even better when combined with our approach, making it faster than the state-of-the-art selectors by up to 16%. Lastly, our approach selects more unique clients for training compared to client selectors that only select fast clients, which reduces our technique's bias.
Spatial Temporal Graph Convolution with Graph Structure Self-learning for Early MCI Detection
Nov 11, 2022
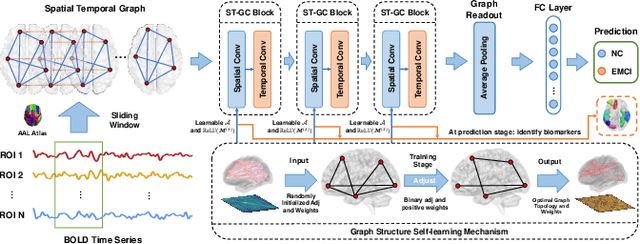
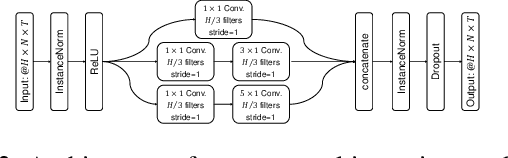
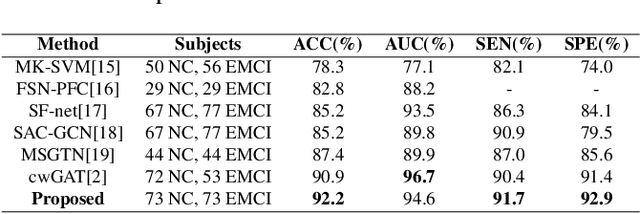
Graph neural networks (GNNs) have been successfully applied to early mild cognitive impairment (EMCI) detection, with the usage of elaborately designed features constructed from blood oxygen level-dependent (BOLD) time series. However, few works explored the feasibility of using BOLD signals directly as features. Meanwhile, existing GNN-based methods primarily rely on hand-crafted explicit brain topology as the adjacency matrix, which is not optimal and ignores the implicit topological organization of the brain. In this paper, we propose a spatial temporal graph convolutional network with a novel graph structure self-learning mechanism for EMCI detection. The proposed spatial temporal graph convolution block directly exploits BOLD time series as input features, which provides an interesting view for rsfMRI-based preclinical AD diagnosis. Moreover, our model can adaptively learn the optimal topological structure and refine edge weights with the graph structure self-learning mechanism. Results on the Alzheimer's Disease Neuroimaging Initiative (ADNI) database show that our method outperforms state-of-the-art approaches. Biomarkers consistent with previous studies can be extracted from the model, proving the reliable interpretability of our method.