 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Indoor Coverage Enhancement for RIS-Assisted Communication Systems: Practical Measurements and Efficient Grouping
Nov 14, 2022
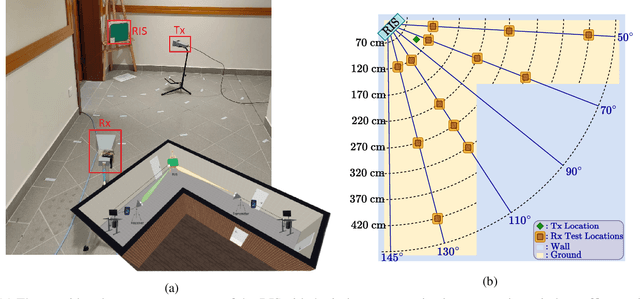
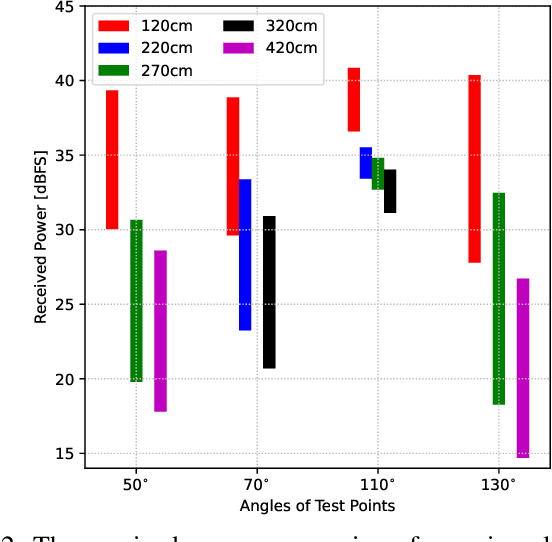
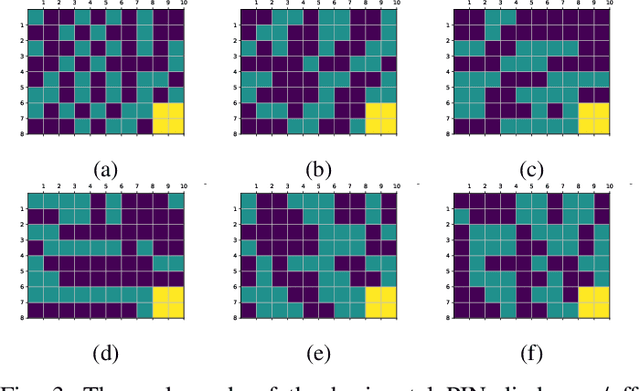
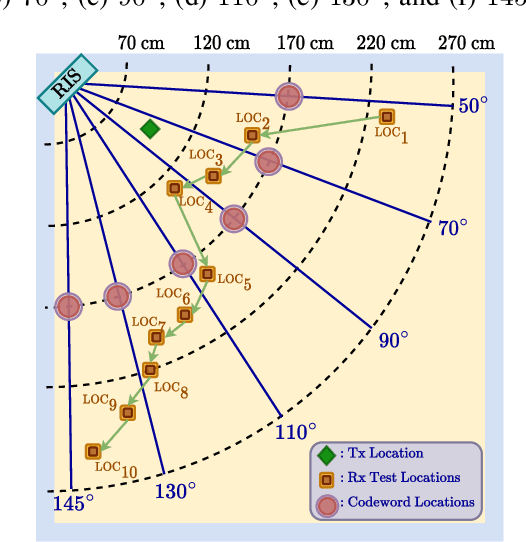
Reconfigurable intelligent surface (RIS)-empowered communications represent exciting prospects as one of the promising technologies capable of meeting the requirements of the sixth generation networks such as low-latency, reliability, and dense connectivity. However, validation of test cases and real-world experiments of RISs are imperative to their practical viability. To this end, this paper presents a physical demonstration of an RIS-assisted communication system in an indoor environment in order to enhance the coverage by increasing the received signal power. We first analyze the performance of the RIS-assisted system for a set of different locations of the receiver and observe around 10 dB improvement in the received signal power by careful RIS phase adjustments. Then, we employ an efficient codebook design for RIS configurations to adjust the RIS states on the move without feedback channels. We also investigate the impact of an efficient grouping of RIS elements, whose objective is to reduce the training time needed to find the optimal RIS configuration. In our extensive experimental measurements, we demonstrate that with the proposed grouping scheme, training time is reduced from one-half to one-eighth by sacrificing only a few dBs in received signal power.
Deep subspace encoders for continuous-time state-space identification
Apr 20, 2022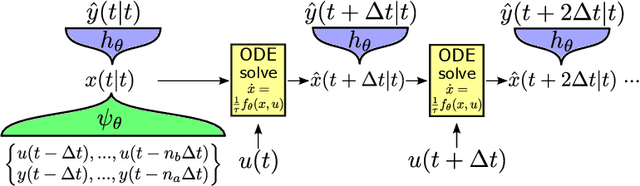
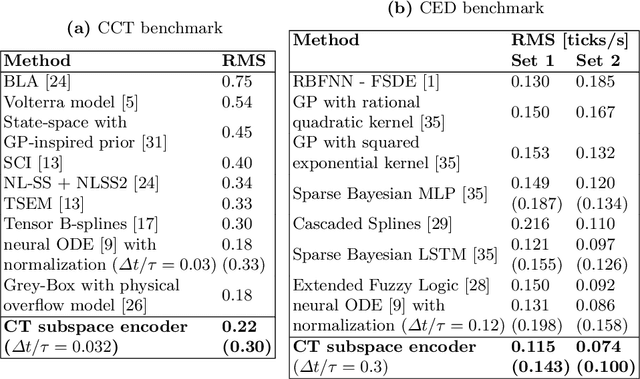
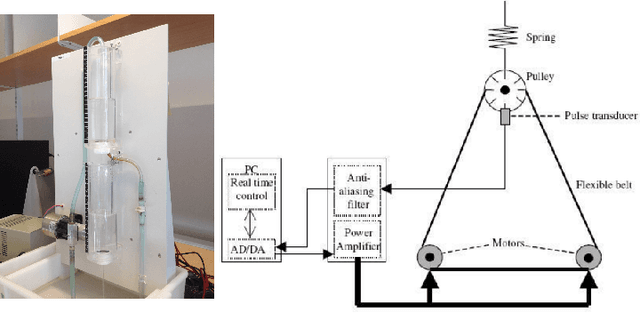
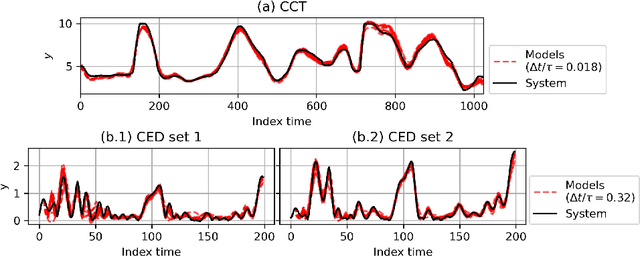
Continuous-time (CT) models have shown an improved sample efficiency during learning and enable ODE analysis methods for enhanced interpretability compared to discrete-time (DT) models. Even with numerous recent developments, the multifaceted CT state-space model identification problem remains to be solved in full, considering common experimental aspects such as the presence of external inputs, measurement noise, and latent states. This paper presents a novel estimation method that includes these aspects and that is able to obtain state-of-the-art results on multiple benchmarks where a small fully connected neural network describes the CT dynamics. The novel estimation method called the subspace encoder approach ascertains these results by altering the well-known simulation loss to include short subsections instead, by using an encoder function and a state-derivative normalization term to obtain a computationally feasible and stable optimization problem. This encoder function estimates the initial states of each considered subsection. We prove that the existence of the encoder function has the necessary condition of a Lipschitz continuous state-derivative utilizing established properties of ODEs.
Agnostic Learning for Packing Machine Stoppage Prediction in Smart Factories
Dec 12, 2022
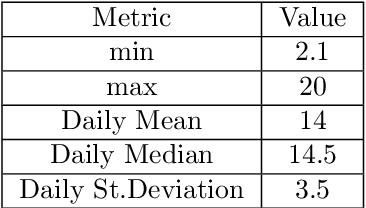
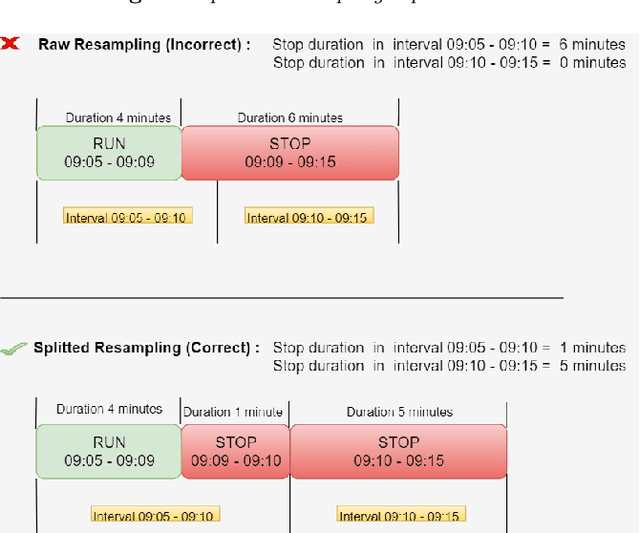
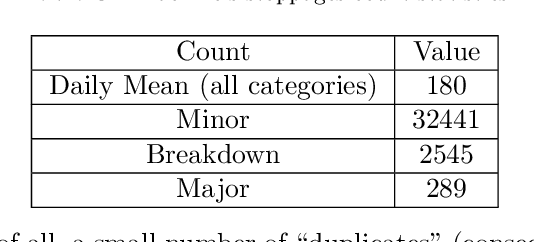
The cyber-physical convergence is opening up new business opportunities for industrial operators. The need for deep integration of the cyber and the physical worlds establishes a rich business agenda towards consolidating new system and network engineering approaches. This revolution would not be possible without the rich and heterogeneous sources of data, as well as the ability of their intelligent exploitation, mainly due to the fact that data will serve as a fundamental resource to promote Industry 4.0. One of the most fruitful research and practice areas emerging from this data-rich, cyber-physical, smart factory environment is the data-driven process monitoring field, which applies machine learning methodologies to enable predictive maintenance applications. In this paper, we examine popular time series forecasting techniques as well as supervised machine learning algorithms in the applied context of Industry 4.0, by transforming and preprocessing the historical industrial dataset of a packing machine's operational state recordings (real data coming from the production line of a manufacturing plant from the food and beverage domain). In our methodology, we use only a single signal concerning the machine's operational status to make our predictions, without considering other operational variables or fault and warning signals, hence its characterization as ``agnostic''. In this respect, the results demonstrate that the adopted methods achieve a quite promising performance on three targeted use cases.
Data Leakage via Access Patterns of Sparse Features in Deep Learning-based Recommendation Systems
Dec 12, 2022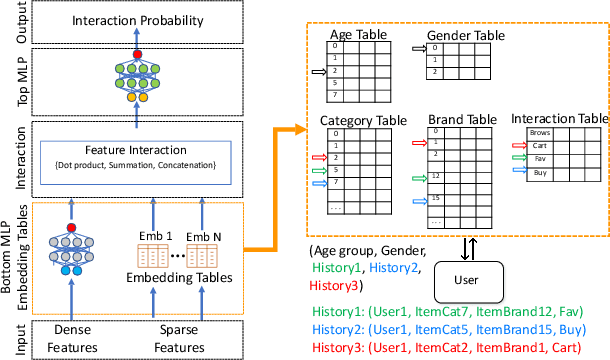
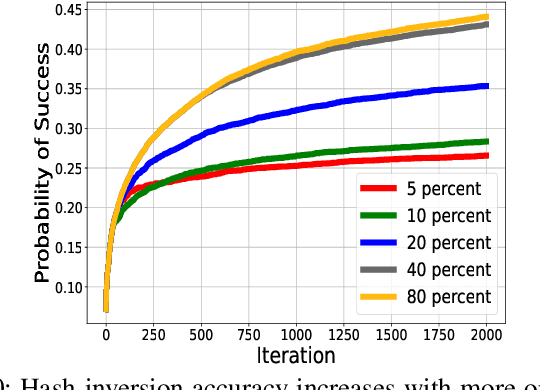
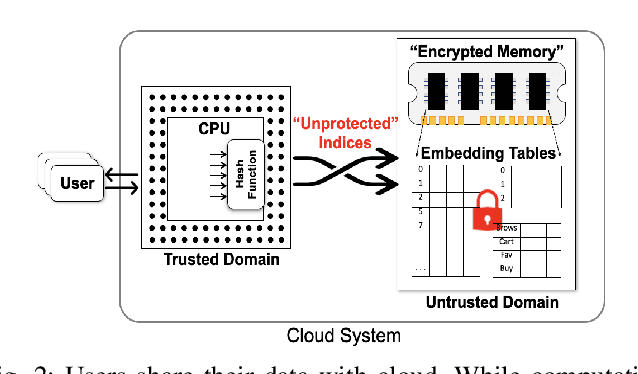
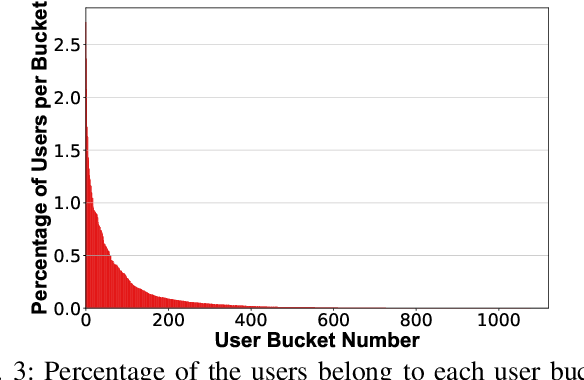
Online personalized recommendation services are generally hosted in the cloud where users query the cloud-based model to receive recommended input such as merchandise of interest or news feed. State-of-the-art recommendation models rely on sparse and dense features to represent users' profile information and the items they interact with. Although sparse features account for 99% of the total model size, there was not enough attention paid to the potential information leakage through sparse features. These sparse features are employed to track users' behavior, e.g., their click history, object interactions, etc., potentially carrying each user's private information. Sparse features are represented as learned embedding vectors that are stored in large tables, and personalized recommendation is performed by using a specific user's sparse feature to index through the tables. Even with recently-proposed methods that hides the computation happening in the cloud, an attacker in the cloud may be able to still track the access patterns to the embedding tables. This paper explores the private information that may be learned by tracking a recommendation model's sparse feature access patterns. We first characterize the types of attacks that can be carried out on sparse features in recommendation models in an untrusted cloud, followed by a demonstration of how each of these attacks leads to extracting users' private information or tracking users by their behavior over time.
Scale-Semantic Joint Decoupling Network for Image-text Retrieval in Remote Sensing
Dec 12, 2022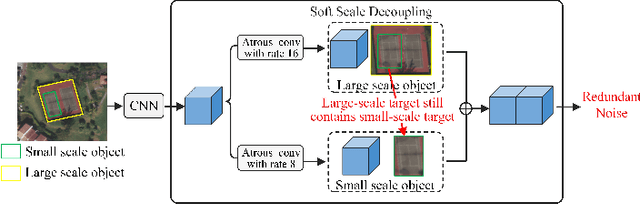
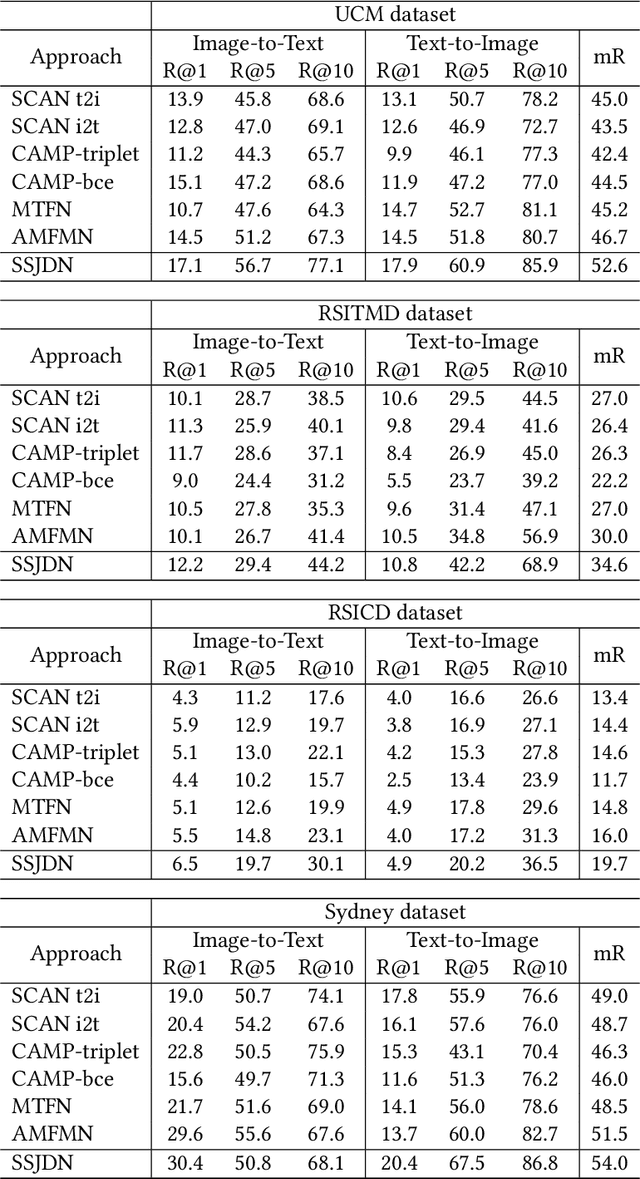
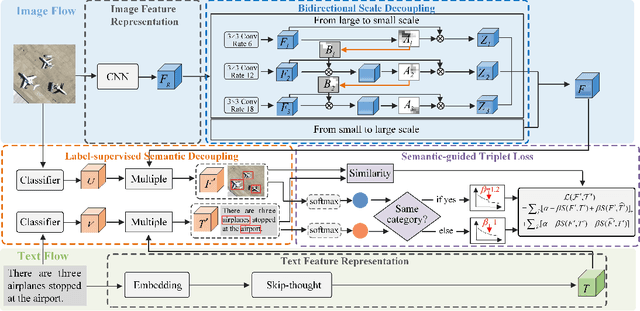

Image-text retrieval in remote sensing aims to provide flexible information for data analysis and application. In recent years, state-of-the-art methods are dedicated to ``scale decoupling'' and ``semantic decoupling'' strategies to further enhance the capability of representation. However, these previous approaches focus on either the disentangling scale or semantics but ignore merging these two ideas in a union model, which extremely limits the performance of cross-modal retrieval models. To address these issues, we propose a novel Scale-Semantic Joint Decoupling Network (SSJDN) for remote sensing image-text retrieval. Specifically, we design the Bidirectional Scale Decoupling (BSD) module, which exploits Salience Feature Extraction (SFE) and Salience-Guided Suppression (SGS) units to adaptively extract potential features and suppress cumbersome features at other scales in a bidirectional pattern to yield different scale clues. Besides, we design the Label-supervised Semantic Decoupling (LSD) module by leveraging the category semantic labels as prior knowledge to supervise images and texts probing significant semantic-related information. Finally, we design a Semantic-guided Triple Loss (STL), which adaptively generates a constant to adjust the loss function to improve the probability of matching the same semantic image and text and shorten the convergence time of the retrieval model. Our proposed SSJDN outperforms state-of-the-art approaches in numerical experiments conducted on four benchmark remote sensing datasets.
Transfer Learning using Spectral Convolutional Autoencoders on Semi-Regular Surface Meshes
Dec 12, 2022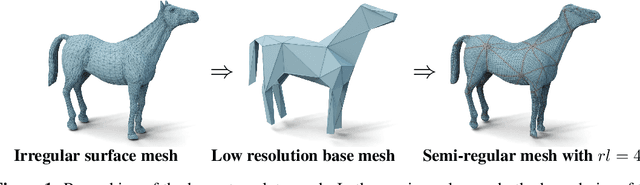
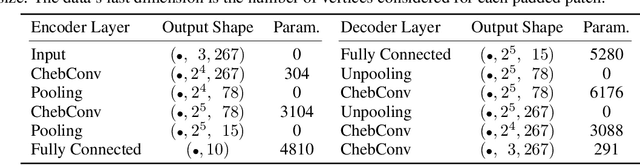
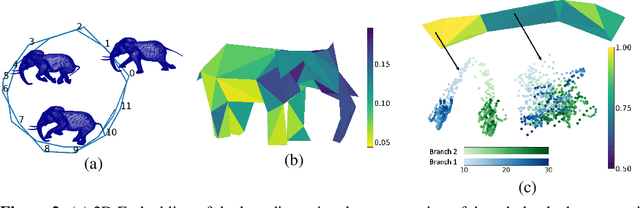
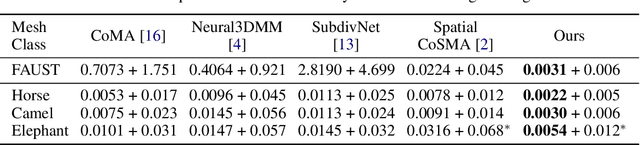
The underlying dynamics and patterns of 3D surface meshes deforming over time can be discovered by unsupervised learning, especially autoencoders, which calculate low-dimensional embeddings of the surfaces. To study the deformation patterns of unseen shapes by transfer learning, we want to train an autoencoder that can analyze new surface meshes without training a new network. Here, most state-of-the-art autoencoders cannot handle meshes of different connectivity and therefore have limited to no generalization capacities to new meshes. Also, reconstruction errors strongly increase in comparison to the errors for the training shapes. To address this, we propose a novel spectral CoSMA (Convolutional Semi-Regular Mesh Autoencoder) network. This patch-based approach is combined with a surface-aware training. It reconstructs surfaces not presented during training and generalizes the deformation behavior of the surfaces' patches. The novel approach reconstructs unseen meshes from different datasets in superior quality compared to state-of-the-art autoencoders that have been trained on these shapes. Our transfer learning errors on unseen shapes are 40% lower than those from models learned directly on the data. Furthermore, baseline autoencoders detect deformation patterns of unseen mesh sequences only for the whole shape. In contrast, due to the employed regional patches and stable reconstruction quality, we can localize where on the surfaces these deformation patterns manifest.
QESK: Quantum-based Entropic Subtree Kernels for Graph Classification
Dec 10, 2022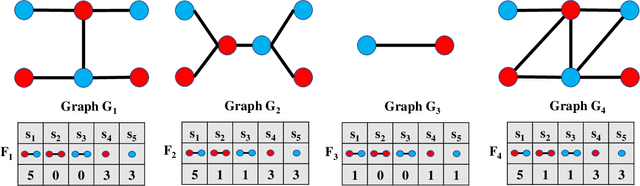
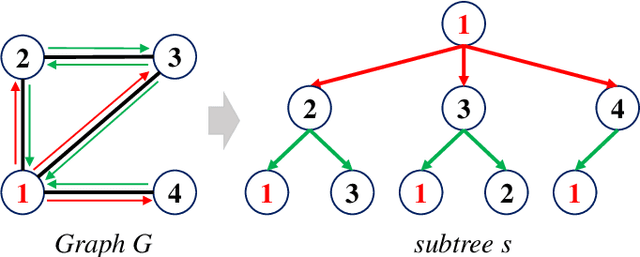
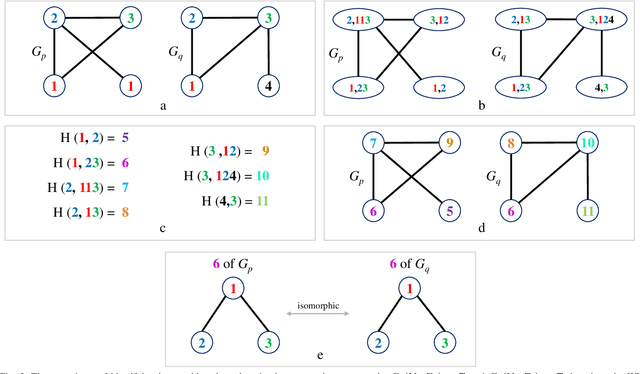
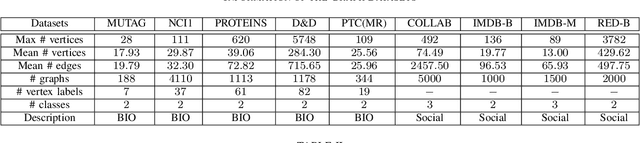
In this paper, we propose a novel graph kernel, namely the Quantum-based Entropic Subtree Kernel (QESK), for Graph Classification. To this end, we commence by computing the Average Mixing Matrix (AMM) of the Continuous-time Quantum Walk (CTQW) evolved on each graph structure. Moreover, we show how this AMM matrix can be employed to compute a series of entropic subtree representations associated with the classical Weisfeiler-Lehman (WL) algorithm. For a pair of graphs, the QESK kernel is defined by computing the exponentiation of the negative Euclidean distance between their entropic subtree representations, theoretically resulting in a positive definite graph kernel. We show that the proposed QESK kernel not only encapsulates complicated intrinsic quantum-based structural characteristics of graph structures through the CTQW, but also theoretically addresses the shortcoming of ignoring the effects of unshared substructures arising in state-of-the-art R-convolution graph kernels. Moreover, unlike the classical R-convolution kernels, the proposed QESK can discriminate the distinctions of isomorphic subtrees in terms of the global graph structures, theoretically explaining the effectiveness. Experiments indicate that the proposed QESK kernel can significantly outperform state-of-the-art graph kernels and graph deep learning methods for graph classification problems.
Expanding Knowledge Graphs with Humans in the Loop
Dec 10, 2022

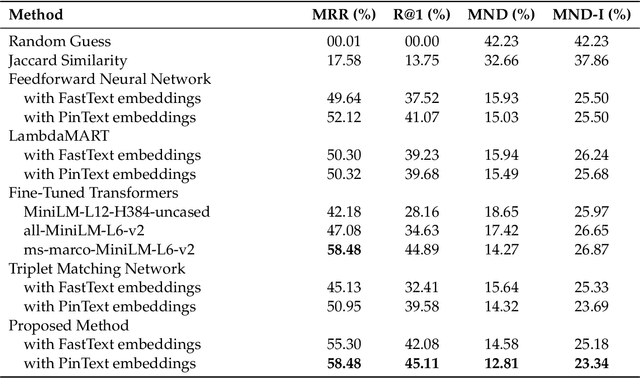
Curated knowledge graphs encode domain expertise and improve the performance of recommendation, segmentation, ad targeting, and other machine learning systems in several domains. As new concepts emerge in a domain, knowledge graphs must be expanded to preserve machine learning performance. Manually expanding knowledge graphs, however, is infeasible at scale. In this work, we propose a method for knowledge graph expansion with humans-in-the-loop. Concretely, given a knowledge graph, our method predicts the "parents" of new concepts to be added to this graph for further verification by human experts. We show that our method is both accurate and provably "human-friendly". Specifically, we prove that our method predicts parents that are "near" concepts' true parents in the knowledge graph, even when the predictions are incorrect. We then show, with a controlled experiment, that satisfying this property increases both the speed and the accuracy of the human-algorithm collaboration. We further evaluate our method on a knowledge graph from Pinterest and show that it outperforms competing methods on both accuracy and human-friendliness. Upon deployment in production at Pinterest, our method reduced the time needed for knowledge graph expansion by ~400% (compared to manual expansion), and contributed to a subsequent increase in ad revenue of 20%.
State-Regularized Recurrent Neural Networks to Extract Automata and Explain Predictions
Dec 10, 2022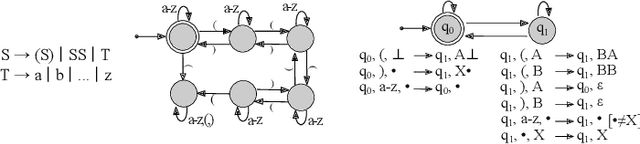
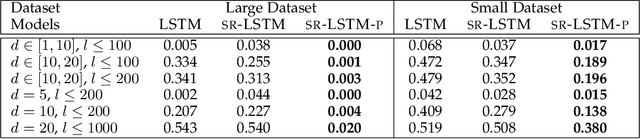

Recurrent neural networks are a widely used class of neural architectures. They have, however, two shortcomings. First, they are often treated as black-box models and as such it is difficult to understand what exactly they learn as well as how they arrive at a particular prediction. Second, they tend to work poorly on sequences requiring long-term memorization, despite having this capacity in principle. We aim to address both shortcomings with a class of recurrent networks that use a stochastic state transition mechanism between cell applications. This mechanism, which we term state-regularization, makes RNNs transition between a finite set of learnable states. We evaluate state-regularized RNNs on (1) regular languages for the purpose of automata extraction; (2) non-regular languages such as balanced parentheses and palindromes where external memory is required; and (3) real-word sequence learning tasks for sentiment analysis, visual object recognition and text categorisation. We show that state-regularization (a) simplifies the extraction of finite state automata that display an RNN's state transition dynamic; (b) forces RNNs to operate more like automata with external memory and less like finite state machines, which potentiality leads to a more structural memory; (c) leads to better interpretability and explainability of RNNs by leveraging the probabilistic finite state transition mechanism over time steps.
Estimation of a Causal Directed Acyclic Graph Process using Non-Gaussianity
Nov 24, 2022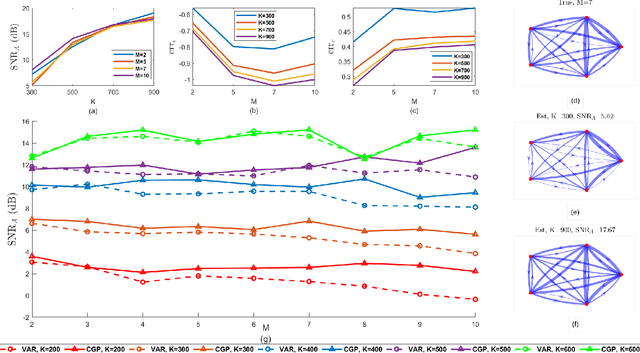
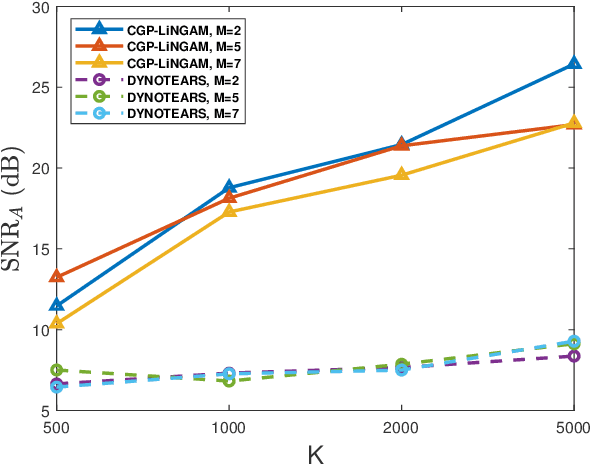
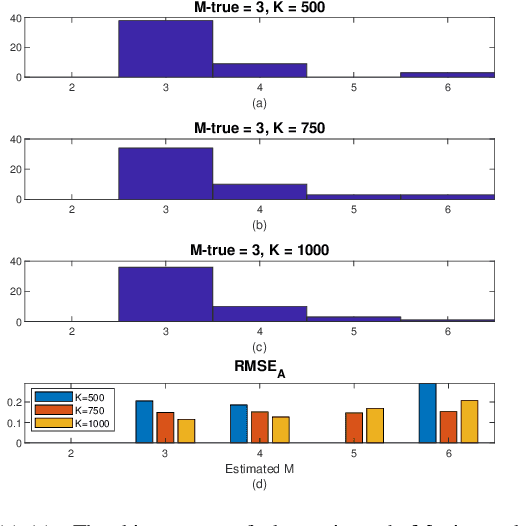
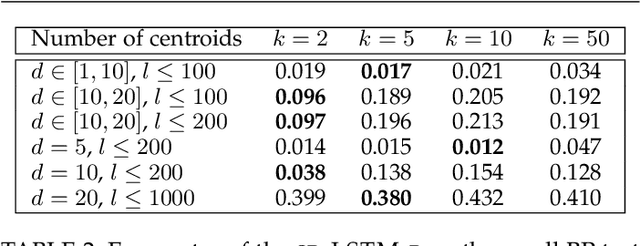
Numerous approaches have been proposed to discover causal dependencies in machine learning and data mining; among them, the state-of-the-art VAR-LiNGAM (short for Vector Auto-Regressive Linear Non-Gaussian Acyclic Model) is a desirable approach to reveal both the instantaneous and time-lagged relationships. However, all the obtained VAR matrices need to be analyzed to infer the final causal graph, leading to a rise in the number of parameters. To address this issue, we propose the CGP-LiNGAM (short for Causal Graph Process-LiNGAM), which has significantly fewer model parameters and deals with only one causal graph for interpreting the causal relations by exploiting Graph Signal Processing (GSP).