 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Design of Reconfigurable Intelligent Surface-Aided Cross-Media Communications
Nov 05, 2022
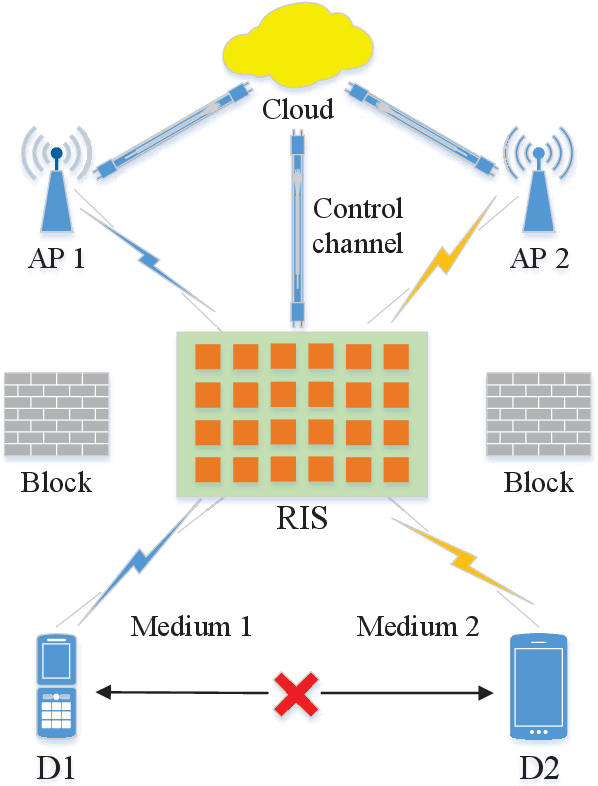
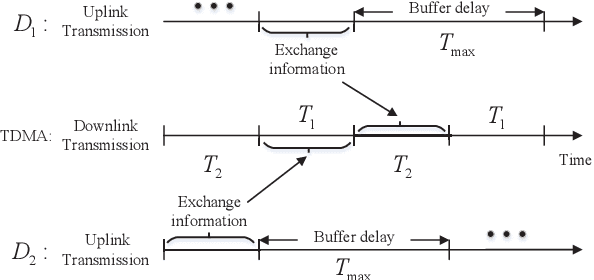
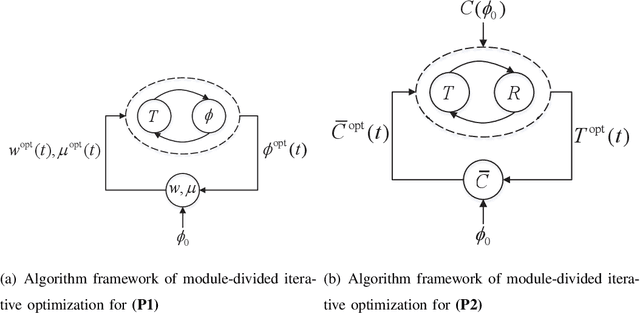
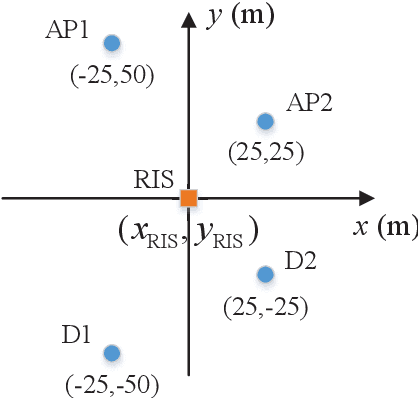
A novel reconfigurable intelligent surface (RIS)-aided hybrid reflection/transmitter design is proposed for achieving information exchange in cross-media communications. In pursuit of the balance between energy efficiency and low-cost implementations, the cloud-management transmission protocol is adopted in the integrated multi-media system. Specifically, the messages of devices using heterogeneous propagation media, are firstly transmitted to the medium-matched AP, with the aid of the RIS-based dual-hop transmission. After the operation of intermediate frequency conversion, the access point (AP) uploads the received signals to the cloud for further demodulating and decoding process. Based on time division multiple access (TDMA), the cloud is able to distinguish the downlink data transmitted to different devices and transforms them into the input of the RIS controller via the dedicated control channel. Thereby, the RIS can passively reflect the incident carrier back into the original receiver with the exchanged information during the preallocated slots, following the idea of an index modulation-based transmitter. Moreover, the iterative optimization algorithm is utilized for optimizing the RIS phase, transmit rate and time allocation jointly in the delay-constrained cross-media communication model. Our simulation results demonstrate that the proposed RIS-based scheme can improve the end-to-end throughput than that of the AP-based transmission, the equal time allocation, the random and the discrete phase adjustment benchmarks.
Dynamic Structured Illumination Microscopy with a Neural Space-time Model
Jun 03, 2022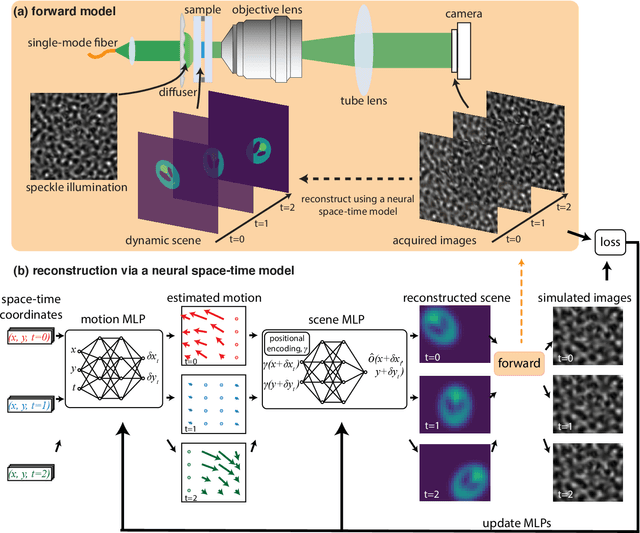
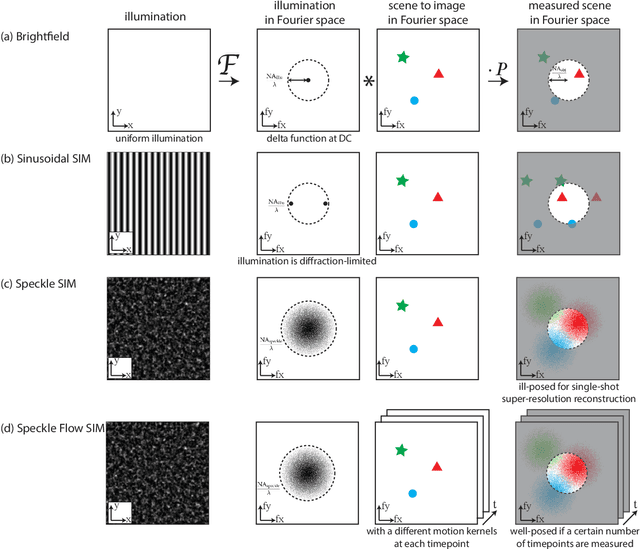
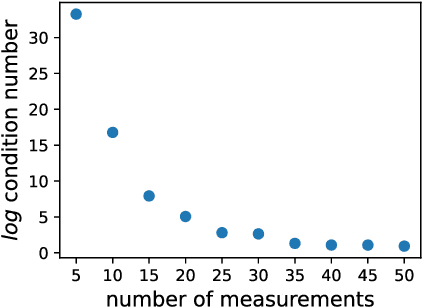
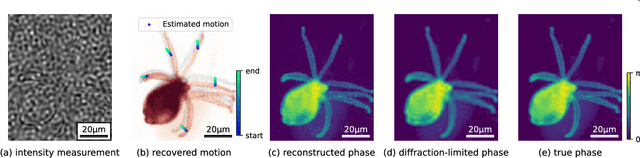
Structured illumination microscopy (SIM) reconstructs a super-resolved image from multiple raw images; hence, acquisition speed is limited, making it unsuitable for dynamic scenes. We propose a new method, Speckle Flow SIM, that models sample motion during the data capture in order to reconstruct dynamic scenes with super-resolution. Speckle Flow SIM uses fixed speckle illumination and relies on sample motion to capture a sequence of raw images. Then, the spatio-temporal relationship of the dynamic scene is modeled using a neural space-time model with coordinate-based multi-layer perceptrons (MLPs), and the motion dynamics and the super-resolved scene are jointly recovered. We validated Speckle Flow SIM in simulation and built a simple, inexpensive experimental setup with off-the-shelf components. We demonstrated that Speckle Flow SIM can reconstruct a dynamic scene with deformable motion and 1.88x the diffraction-limited resolution in experiment.
Multi-Task Edge Prediction in Temporally-Dynamic Video Graphs
Dec 06, 2022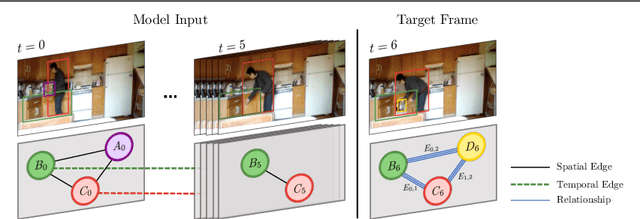
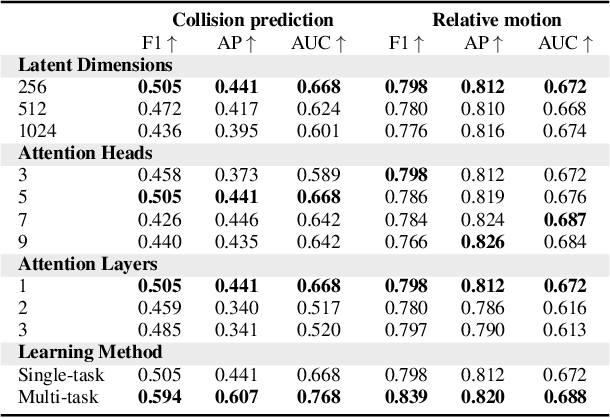
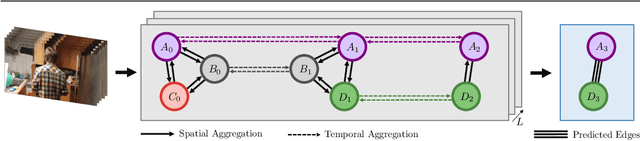
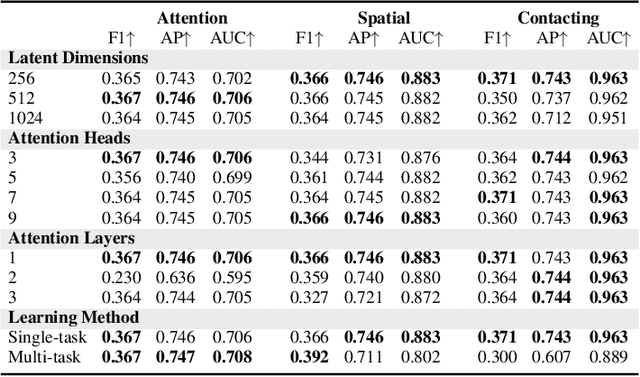
Graph neural networks have shown to learn effective node representations, enabling node-, link-, and graph-level inference. Conventional graph networks assume static relations between nodes, while relations between entities in a video often evolve over time, with nodes entering and exiting dynamically. In such temporally-dynamic graphs, a core problem is inferring the future state of spatio-temporal edges, which can constitute multiple types of relations. To address this problem, we propose MTD-GNN, a graph network for predicting temporally-dynamic edges for multiple types of relations. We propose a factorized spatio-temporal graph attention layer to learn dynamic node representations and present a multi-task edge prediction loss that models multiple relations simultaneously. The proposed architecture operates on top of scene graphs that we obtain from videos through object detection and spatio-temporal linking. Experimental evaluations on ActionGenome and CLEVRER show that modeling multiple relations in our temporally-dynamic graph network can be mutually beneficial, outperforming existing static and spatio-temporal graph neural networks, as well as state-of-the-art predicate classification methods.
UAVs for Industries and Supply Chain Management
Dec 06, 2022
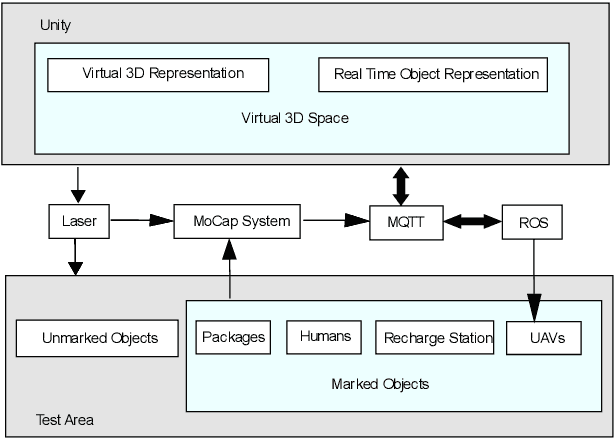
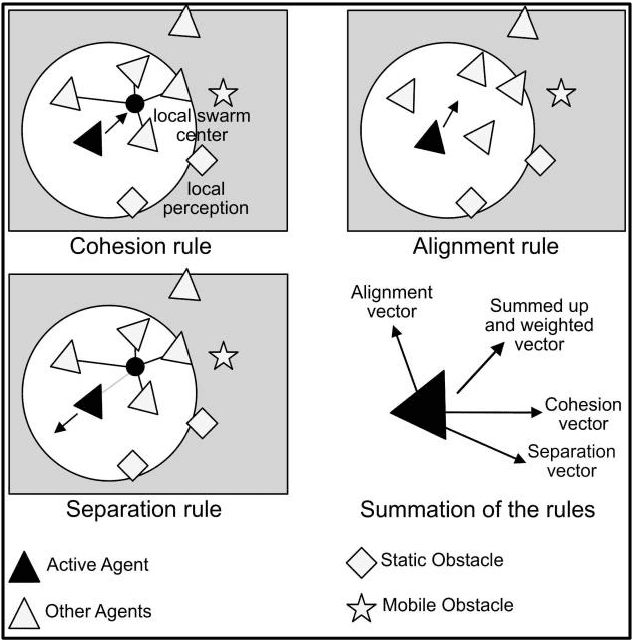

This work aims at showing that it is feasible and safe to use a swarm of Unmanned Aerial Vehicles (UAVs) indoors alongside humans. UAVs are increasingly being integrated under the Industry 4.0 framework. UAV swarms are primarily deployed outdoors in civil and military applications, but the opportunities for using them in manufacturing and supply chain management are immense. There is extensive research on UAV technology, e.g., localization, control, and computer vision, but less research on the practical application of UAVs in industry. UAV technology could improve data collection and monitoring, enhance decision-making in an Internet of Things framework and automate time-consuming and redundant tasks in the industry. However, there is a gap between the technological developments of UAVs and their integration into the supply chain. Therefore, this work focuses on automating the task of transporting packages utilizing a swarm of small UAVs operating alongside humans. MoCap system, ROS, and unity are used for localization, inter-process communication and visualization. Multiple experiments are performed with the UAVs in wander and swarm mode in a warehouse like environment.
Transforming RIS-Assisted Passive Beamforming from Tedious to Simple: A Relaxation Algorithm for Rician Channel
Nov 12, 2022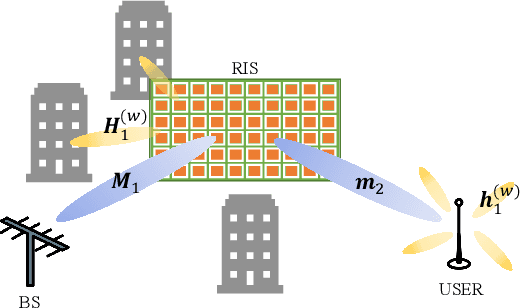
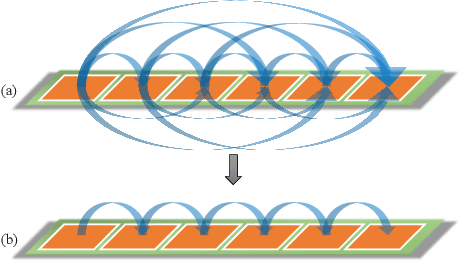
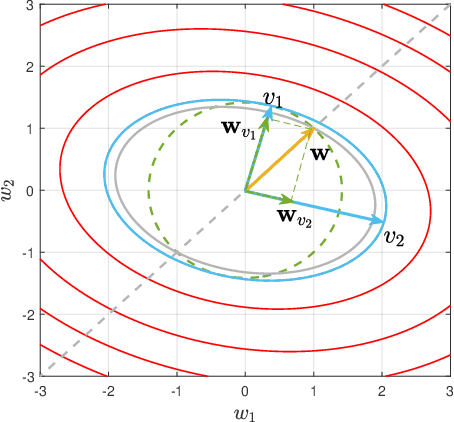
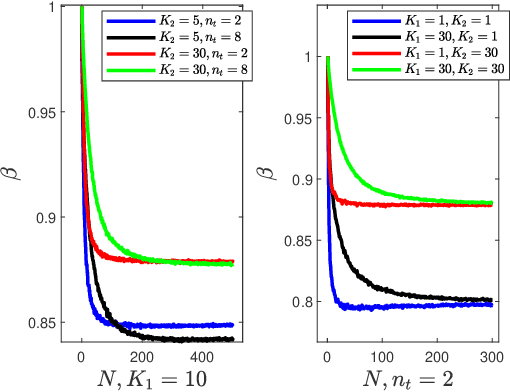
This paper investigates the problem of maximizing the signal-to-noise ratio (SNR) in reconfigurable intelligent surface (RIS)-assisted MISO communication systems. The problem will be reformulated as a complex quadratic form problem with unit circle constraints. We proved that the SNR maximizing problem has a closed-form global optimal solution when it is a rank-one problem, whereas the former researchers regarded it as an optimization problem. Moreover, We propose a relaxation algorithm (RA) that relaxes the constraints to that of Rayleigh's quotient problem and then projects the solution back, where the SNR obtained by RA achieves much the same SNR as the upper bound but with significantly low time consumption. Then we asymptotically analyze its performance when the transmitter antennas n_t and the number of units of RIS N grow large together, with N/n_t -> c. Finally, our numerical simulations show that RA achieves over 98% of the performance of the upper bound and takes below 1% time consumption of manifold optimization (MO) and 0.1% of semidefinite relaxation (SDR).
MOSPAT: AutoML based Model Selection and Parameter Tuning for Time Series Anomaly Detection
May 24, 2022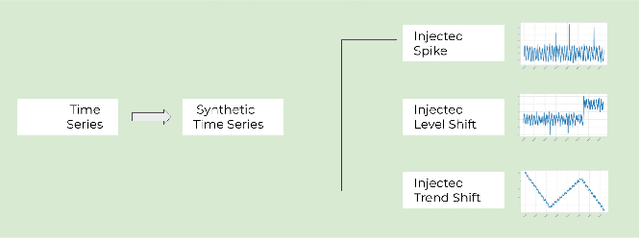
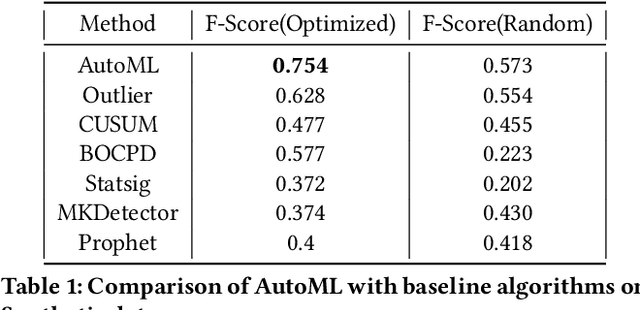
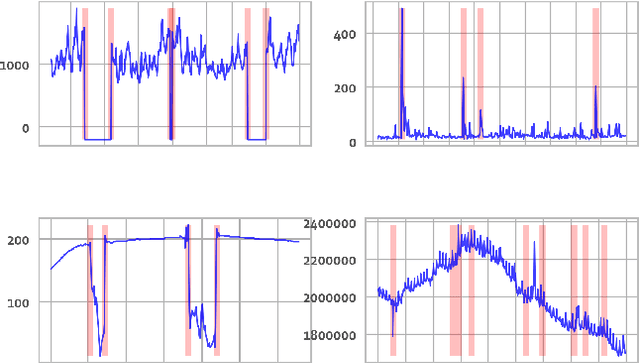
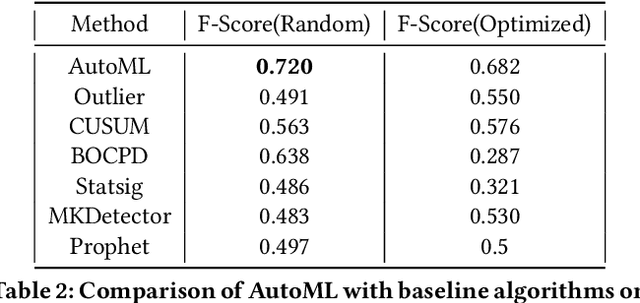
Organizations leverage anomaly and changepoint detection algorithms to detect changes in user behavior or service availability and performance. Many off-the-shelf detection algorithms, though effective, cannot readily be used in large organizations where thousands of users monitor millions of use cases and metrics with varied time series characteristics and anomaly patterns. The selection of algorithm and parameters needs to be precise for each use case: manual tuning does not scale, and automated tuning requires ground truth, which is rarely available. In this paper, we explore MOSPAT, an end-to-end automated machine learning based approach for model and parameter selection, combined with a generative model to produce labeled data. Our scalable end-to-end system allows individual users in large organizations to tailor time-series monitoring to their specific use case and data characteristics, without expert knowledge of anomaly detection algorithms or laborious manual labeling. Our extensive experiments on real and synthetic data demonstrate that this method consistently outperforms using any single algorithm.
Large Scale Time-Series Representation Learning via Simultaneous Low and High Frequency Feature Bootstrapping
Apr 24, 2022


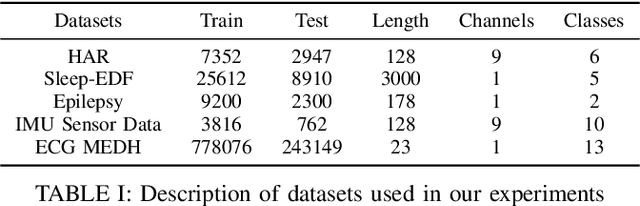
Learning representation from unlabeled time series data is a challenging problem. Most existing self-supervised and unsupervised approaches in the time-series domain do not capture low and high-frequency features at the same time. Further, some of these methods employ large scale models like transformers or rely on computationally expensive techniques such as contrastive learning. To tackle these problems, we propose a non-contrastive self-supervised learning approach efficiently captures low and high-frequency time-varying features in a cost-effective manner. Our method takes raw time series data as input and creates two different augmented views for two branches of the model, by randomly sampling the augmentations from same family. Following the terminology of BYOL, the two branches are called online and target network which allows bootstrapping of the latent representation. In contrast to BYOL, where a backbone encoder is followed by multilayer perceptron (MLP) heads, the proposed model contains additional temporal convolutional network (TCN) heads. As the augmented views are passed through large kernel convolution blocks of the encoder, the subsequent combination of MLP and TCN enables an effective representation of low as well as high-frequency time-varying features due to the varying receptive fields. The two modules (MLP and TCN) act in a complementary manner. We train an online network where each module learns to predict the outcome of the respective module of target network branch. To demonstrate the robustness of our model we performed extensive experiments and ablation studies on five real-world time-series datasets. Our method achieved state-of-art performance on all five real-world datasets.
CT-DQN: Control-Tutored Deep Reinforcement Learning
Dec 02, 2022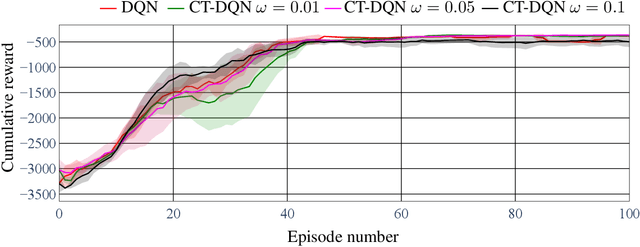
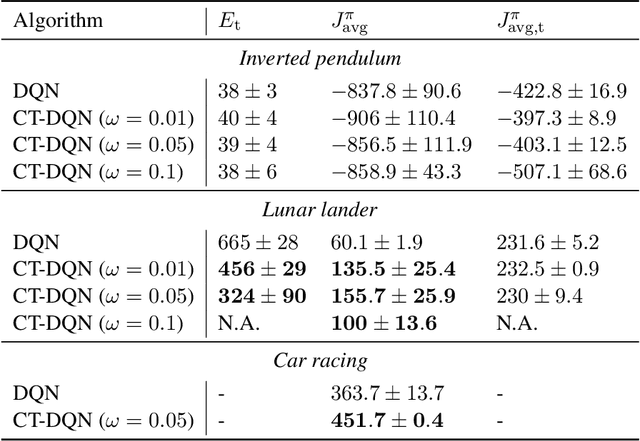
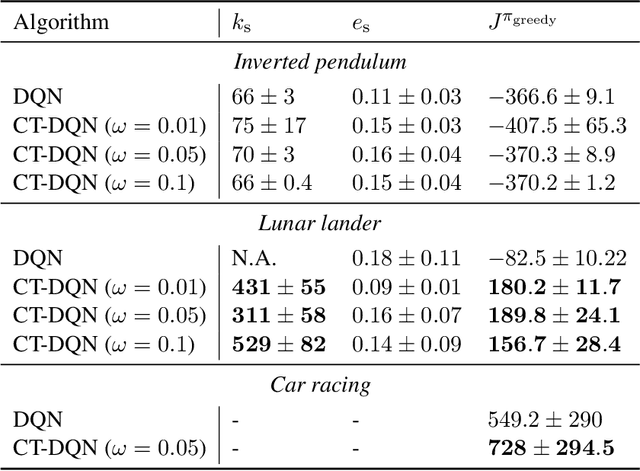
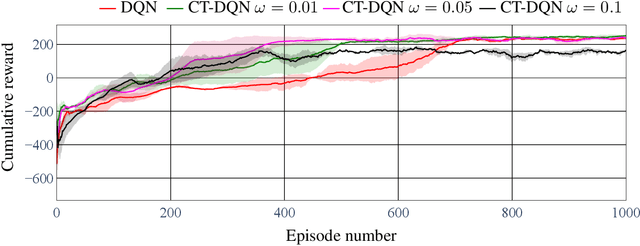
One of the major challenges in Deep Reinforcement Learning for control is the need for extensive training to learn the policy. Motivated by this, we present the design of the Control-Tutored Deep Q-Networks (CT-DQN) algorithm, a Deep Reinforcement Learning algorithm that leverages a control tutor, i.e., an exogenous control law, to reduce learning time. The tutor can be designed using an approximate model of the system, without any assumption about the knowledge of the system's dynamics. There is no expectation that it will be able to achieve the control objective if used stand-alone. During learning, the tutor occasionally suggests an action, thus partially guiding exploration. We validate our approach on three scenarios from OpenAI Gym: the inverted pendulum, lunar lander, and car racing. We demonstrate that CT-DQN is able to achieve better or equivalent data efficiency with respect to the classic function approximation solutions.
Self-Supervised Geometry-Aware Encoder for Style-Based 3D GAN Inversion
Dec 14, 2022
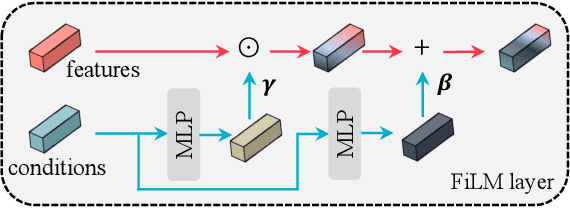

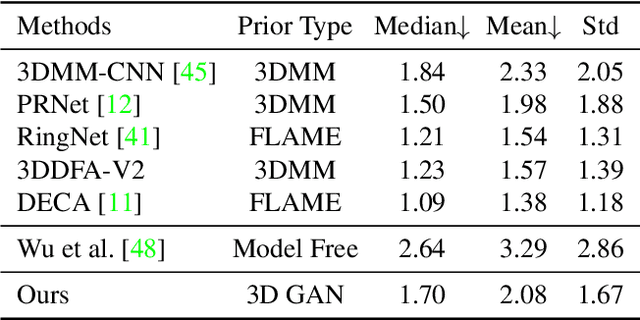
StyleGAN has achieved great progress in 2D face reconstruction and semantic editing via image inversion and latent editing. While studies over extending 2D StyleGAN to 3D faces have emerged, a corresponding generic 3D GAN inversion framework is still missing, limiting the applications of 3D face reconstruction and semantic editing. In this paper, we study the challenging problem of 3D GAN inversion where a latent code is predicted given a single face image to faithfully recover its 3D shapes and detailed textures. The problem is ill-posed: innumerable compositions of shape and texture could be rendered to the current image. Furthermore, with the limited capacity of a global latent code, 2D inversion methods cannot preserve faithful shape and texture at the same time when applied to 3D models. To solve this problem, we devise an effective self-training scheme to constrain the learning of inversion. The learning is done efficiently without any real-world 2D-3D training pairs but proxy samples generated from a 3D GAN. In addition, apart from a global latent code that captures the coarse shape and texture information, we augment the generation network with a local branch, where pixel-aligned features are added to faithfully reconstruct face details. We further consider a new pipeline to perform 3D view-consistent editing. Extensive experiments show that our method outperforms state-of-the-art inversion methods in both shape and texture reconstruction quality. Code and data will be released.
SDFusion: Multimodal 3D Shape Completion, Reconstruction, and Generation
Dec 08, 2022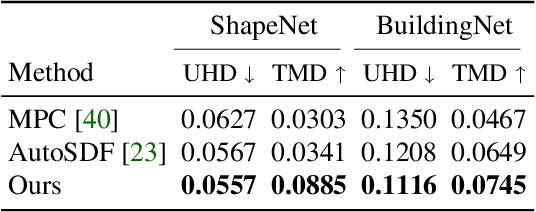
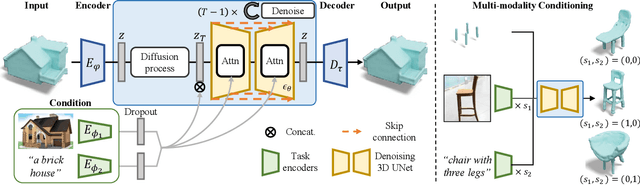
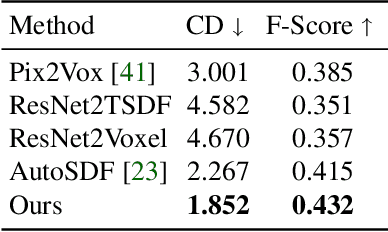
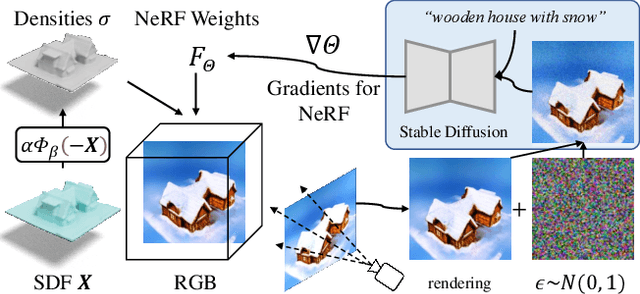
In this work, we present a novel framework built to simplify 3D asset generation for amateur users. To enable interactive generation, our method supports a variety of input modalities that can be easily provided by a human, including images, text, partially observed shapes and combinations of these, further allowing to adjust the strength of each input. At the core of our approach is an encoder-decoder, compressing 3D shapes into a compact latent representation, upon which a diffusion model is learned. To enable a variety of multi-modal inputs, we employ task-specific encoders with dropout followed by a cross-attention mechanism. Due to its flexibility, our model naturally supports a variety of tasks, outperforming prior works on shape completion, image-based 3D reconstruction, and text-to-3D. Most interestingly, our model can combine all these tasks into one swiss-army-knife tool, enabling the user to perform shape generation using incomplete shapes, images, and textual descriptions at the same time, providing the relative weights for each input and facilitating interactivity. Despite our approach being shape-only, we further show an efficient method to texture the generated shape using large-scale text-to-image models.