 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Efficient Incremental Text-to-Speech on GPUs
Nov 25, 2022
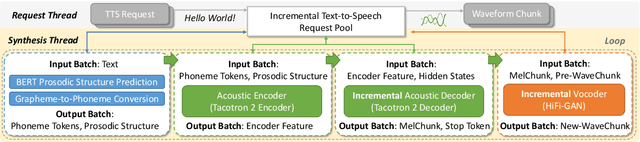
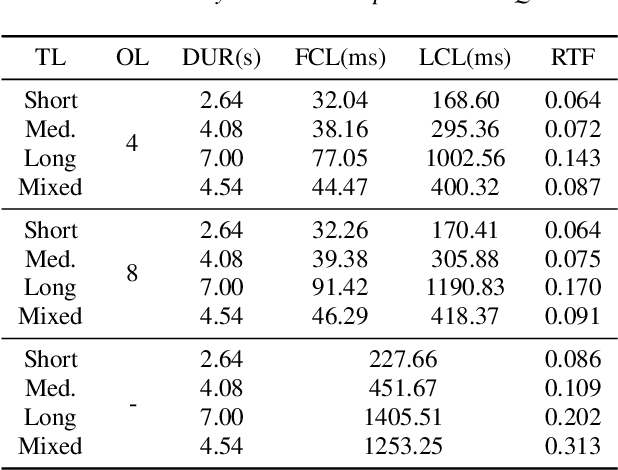
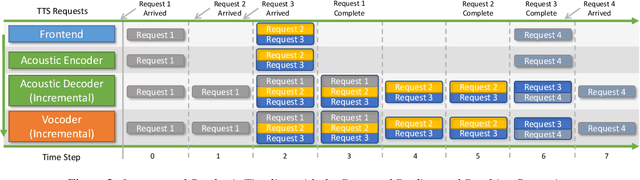
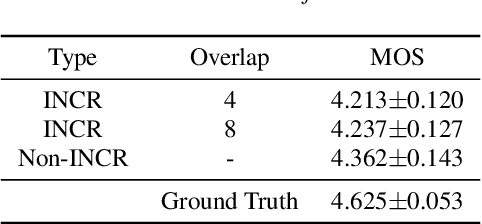
Incremental text-to-speech, also known as streaming TTS, has been increasingly applied to online speech applications that require ultra-low response latency to provide an optimal user experience. However, most of the existing speech synthesis pipelines deployed on GPU are still non-incremental, which uncovers limitations in high-concurrency scenarios, especially when the pipeline is built with end-to-end neural network models. To address this issue, we present a highly efficient approach to perform real-time incremental TTS on GPUs with Instant Request Pooling and Module-wise Dynamic Batching. Experimental results demonstrate that the proposed method is capable of producing high-quality speech with a first-chunk latency lower than 80ms under 100 QPS on a single NVIDIA A10 GPU and significantly outperforms the non-incremental twin in both concurrency and latency. Our work reveals the effectiveness of high-performance incremental TTS on GPUs.
LightDepth: A Resource Efficient Depth Estimation Approach for Dealing with Ground Truth Sparsity via Curriculum Learning
Nov 19, 2022



Advances in neural networks enable tackling complex computer vision tasks such as depth estimation of outdoor scenes at unprecedented accuracy. Promising research has been done on depth estimation. However, current efforts are computationally resource-intensive and do not consider the resource constraints of autonomous devices, such as robots and drones. In this work, we present a fast and battery-efficient approach for depth estimation. Our approach devises model-agnostic curriculum-based learning for depth estimation. Our experiments show that the accuracy of our model performs on par with the state-of-the-art models, while its response time outperforms other models by 71%. All codes are available online at https://github.com/fatemehkarimii/LightDepth.
Going Beyond XAI: A Systematic Survey for Explanation-Guided Learning
Dec 07, 2022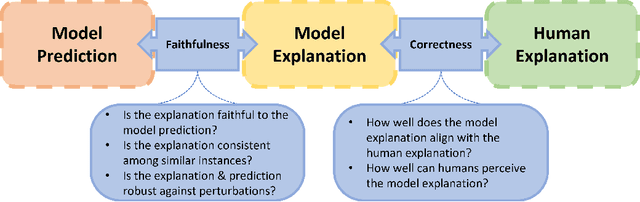

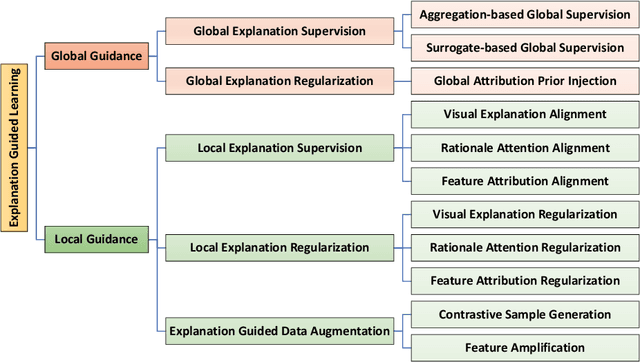
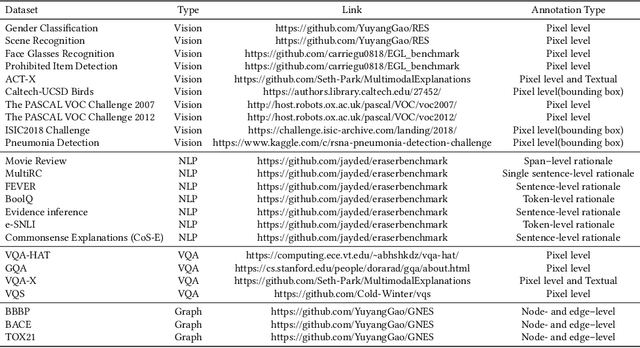
As the societal impact of Deep Neural Networks (DNNs) grows, the goals for advancing DNNs become more complex and diverse, ranging from improving a conventional model accuracy metric to infusing advanced human virtues such as fairness, accountability, transparency (FaccT), and unbiasedness. Recently, techniques in Explainable Artificial Intelligence (XAI) are attracting considerable attention, and have tremendously helped Machine Learning (ML) engineers in understanding AI models. However, at the same time, we started to witness the emerging need beyond XAI among AI communities; based on the insights learned from XAI, how can we better empower ML engineers in steering their DNNs so that the model's reasonableness and performance can be improved as intended? This article provides a timely and extensive literature overview of the field Explanation-Guided Learning (EGL), a domain of techniques that steer the DNNs' reasoning process by adding regularization, supervision, or intervention on model explanations. In doing so, we first provide a formal definition of EGL and its general learning paradigm. Secondly, an overview of the key factors for EGL evaluation, as well as summarization and categorization of existing evaluation procedures and metrics for EGL are provided. Finally, the current and potential future application areas and directions of EGL are discussed, and an extensive experimental study is presented aiming at providing comprehensive comparative studies among existing EGL models in various popular application domains, such as Computer Vision (CV) and Natural Language Processing (NLP) domains.
How Can Optical Communications Shape the Future of Deep Space Communications? A Survey
Dec 07, 2022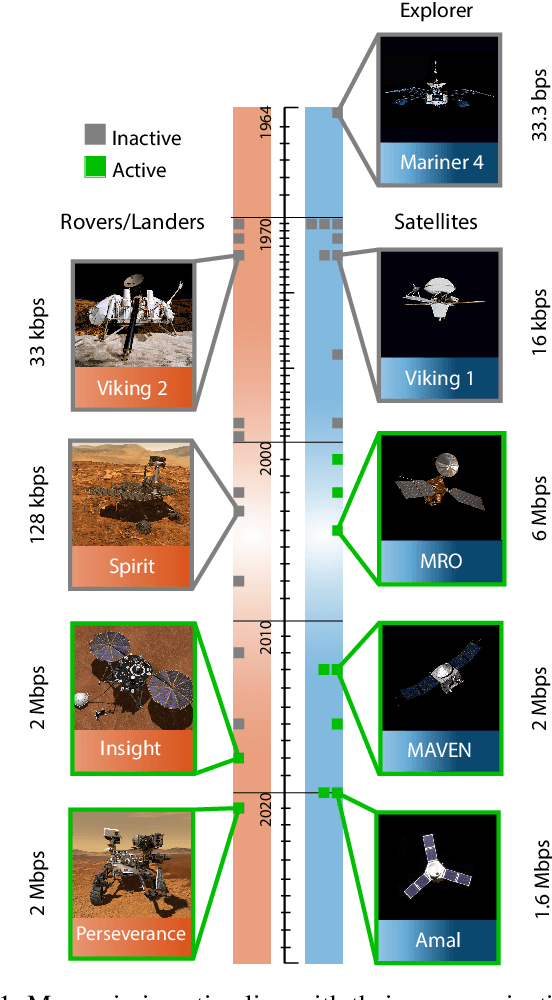
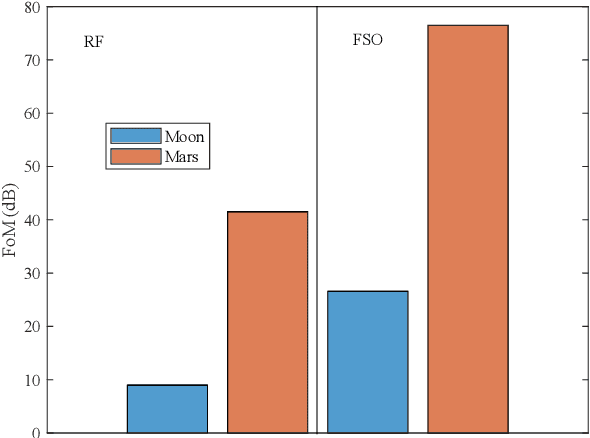
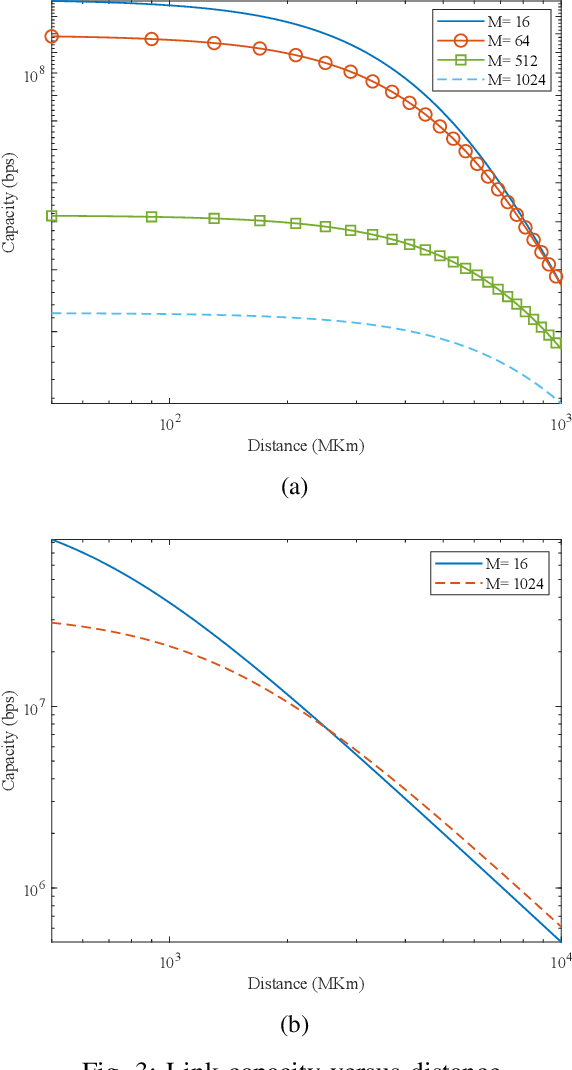
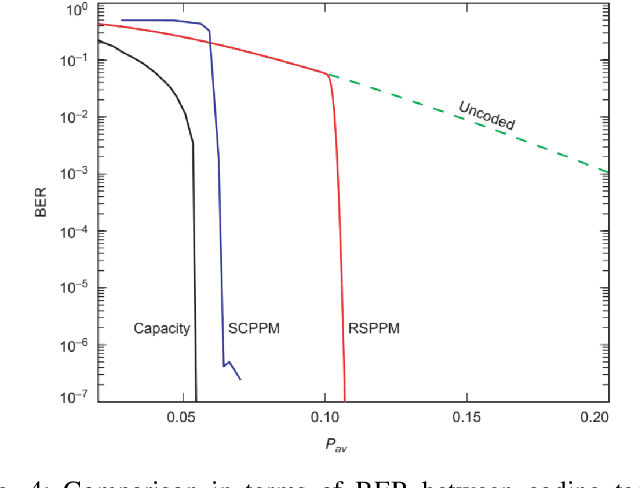
With a large number of deep space (DS) missions anticipated by the end of this decade, reliable and high-capacity DS communications systems are needed more than ever. Nevertheless, existing DS communications technologies are far from meeting such a goal. Improving current DS communications systems does not only require system engineering leadership but also, very crucially, an investigation of potential emerging technologies that overcome the unique challenges of ultra-long DS communications links. To the best of our knowledge, there has not been any comprehensive surveys of DS communications technologies over the last decade.Fee-space optical (FSO) technology is an emerging DS technology, proven to acquire lower communications systems size, weight and power (SWaP) and achieve a very high capacity compared to its counterpart radio frequency (RF) technology, the current used DS technology. In this survey, we discuss the pros and cons of deep space optical communications (DSOC). Furthermore, we review the modulation, coding, and detection, receiver, and protocols schemes and technologies for DSOC. We provide, for the very first time, thoughtful discussions about implementing orbital angular momentum (OAM) and quantum communications (QC)for DS. We elaborate on how these technologies among other field advances, including interplanetary network, and RF/FSO systems improve reliability, capacity, and security and address related implementation challenges and potential solutions. This paper provides a holistic survey in DSOC technologies gathering 200+ fragmented literature and including novel perspectives aiming to setting the stage for more developments in the field.
Multiple Perturbation Attack: Attack Pixelwise Under Different $\ell_p$-norms For Better Adversarial Performance
Dec 07, 2022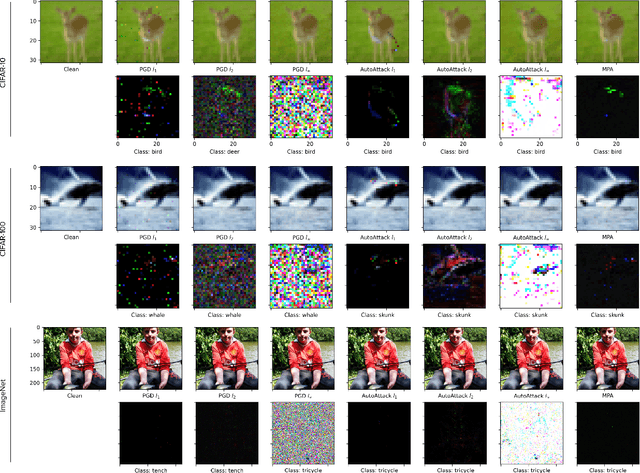


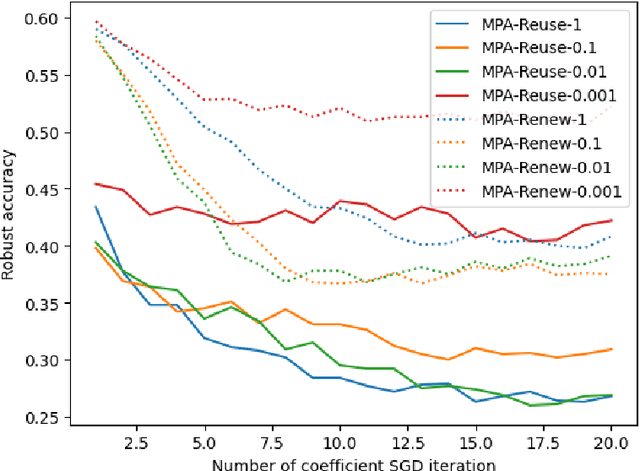
Adversarial machine learning has been both a major concern and a hot topic recently, especially with the ubiquitous use of deep neural networks in the current landscape. Adversarial attacks and defenses are usually likened to a cat-and-mouse game in which defenders and attackers evolve over the time. On one hand, the goal is to develop strong and robust deep networks that are resistant to malicious actors. On the other hand, in order to achieve that, we need to devise even stronger adversarial attacks to challenge these defense models. Most of existing attacks employs a single $\ell_p$ distance (commonly, $p\in\{1,2,\infty\}$) to define the concept of closeness and performs steepest gradient ascent w.r.t. this $p$-norm to update all pixels in an adversarial example in the same way. These $\ell_p$ attacks each has its own pros and cons; and there is no single attack that can successfully break through defense models that are robust against multiple $\ell_p$ norms simultaneously. Motivated by these observations, we come up with a natural approach: combining various $\ell_p$ gradient projections on a pixel level to achieve a joint adversarial perturbation. Specifically, we learn how to perturb each pixel to maximize the attack performance, while maintaining the overall visual imperceptibility of adversarial examples. Finally, through various experiments with standardized benchmarks, we show that our method outperforms most current strong attacks across state-of-the-art defense mechanisms, while retaining its ability to remain clean visually.
A Curriculum-Training-Based Strategy for Distributing Collocation Points during Physics-Informed Neural Network Training
Nov 22, 2022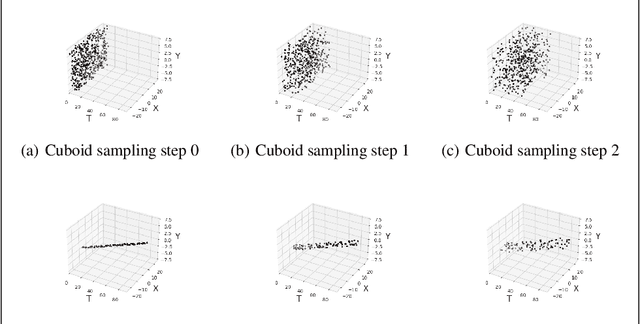
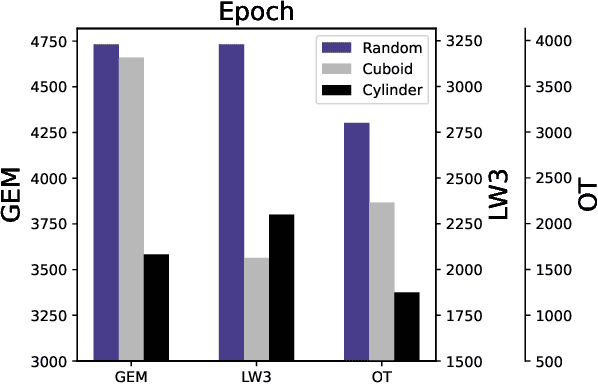
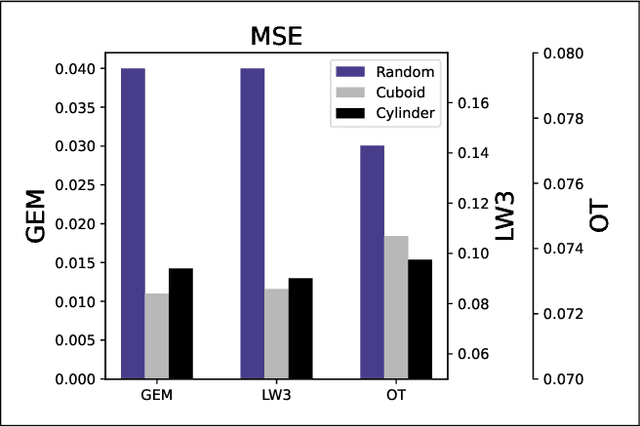
Physics-informed Neural Networks (PINNs) often have, in their loss functions, terms based on physical equations and derivatives. In order to evaluate these terms, the output solution is sampled using a distribution of collocation points. However, density-based strategies, in which the number of collocation points over the domain increases throughout the training period, do not scale well to multiple spatial dimensions. To remedy this issue, we present here a curriculum-training-based method for lightweight collocation point distributions during network training. We apply this method to a PINN which recovers a full two-dimensional magnetohydrodynamic (MHD) solution from a partial sample taken from a baseline MHD simulation. We find that the curriculum collocation point strategy leads to a significant decrease in training time and simultaneously enhances the quality of the reconstructed solution.
Unite and Conquer: Cross Dataset Multimodal Synthesis using Diffusion Models
Dec 01, 2022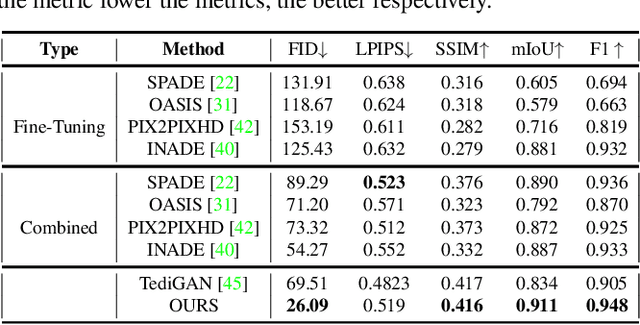
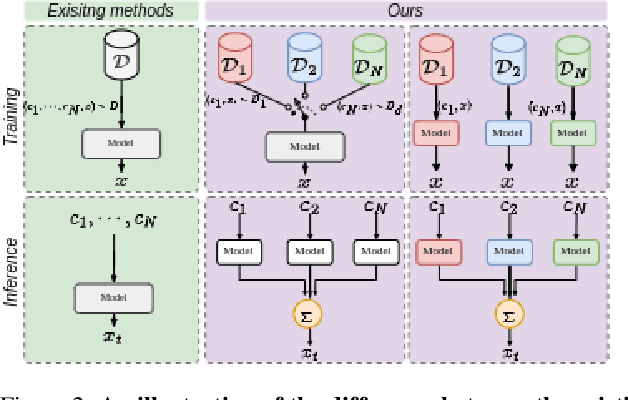
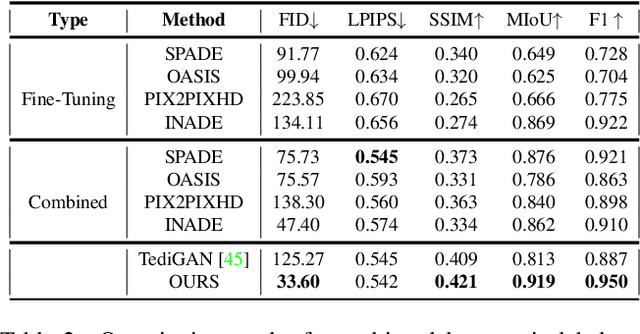
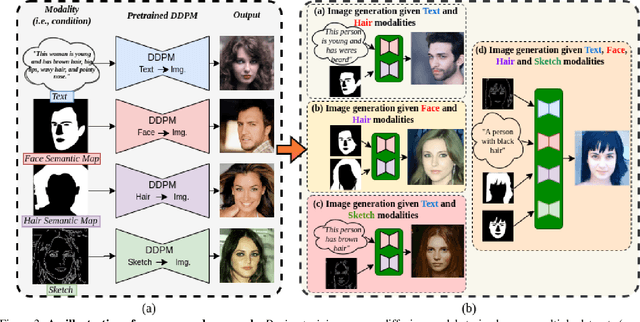
Generating photos satisfying multiple constraints find broad utility in the content creation industry. A key hurdle to accomplishing this task is the need for paired data consisting of all modalities (i.e., constraints) and their corresponding output. Moreover, existing methods need retraining using paired data across all modalities to introduce a new condition. This paper proposes a solution to this problem based on denoising diffusion probabilistic models (DDPMs). Our motivation for choosing diffusion models over other generative models comes from the flexible internal structure of diffusion models. Since each sampling step in the DDPM follows a Gaussian distribution, we show that there exists a closed-form solution for generating an image given various constraints. Our method can unite multiple diffusion models trained on multiple sub-tasks and conquer the combined task through our proposed sampling strategy. We also introduce a novel reliability parameter that allows using different off-the-shelf diffusion models trained across various datasets during sampling time alone to guide it to the desired outcome satisfying multiple constraints. We perform experiments on various standard multimodal tasks to demonstrate the effectiveness of our approach. More details can be found in https://nithin-gk.github.io/projectpages/Multidiff/index.html
An introduction to optimization under uncertainty -- A short survey
Dec 01, 2022Optimization equips engineers and scientists in a variety of fields with the ability to transcribe their problems into a generic formulation and receive optimal solutions with relative ease. Industries ranging from aerospace to robotics continue to benefit from advancements in optimization theory and the associated algorithmic developments. Nowadays, optimization is used in real time on autonomous systems acting in safety critical situations, such as self-driving vehicles. It has become increasingly more important to produce robust solutions by incorporating uncertainty into optimization programs. This paper provides a short survey about the state of the art in optimization under uncertainty. The paper begins with a brief overview of the main classes of optimization without uncertainty. The rest of the paper focuses on the different methods for handling both aleatoric and epistemic uncertainty. Many of the applications discussed in this paper are within the domain of control. The goal of this survey paper is to briefly touch upon the state of the art in a variety of different methods and refer the reader to other literature for more in-depth treatments of the topics discussed here.
A Model-based GNN for Learning Precoding
Dec 01, 2022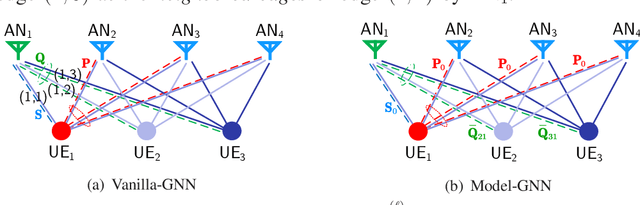

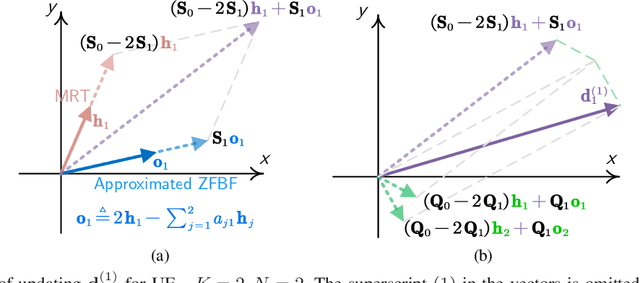
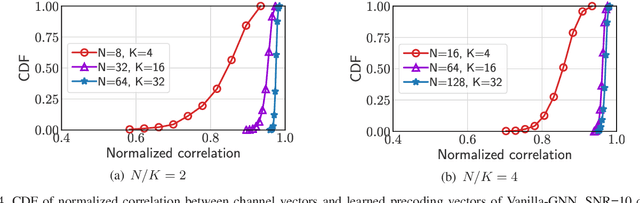
Learning precoding policies with neural networks enables low complexity online implementation, robustness to channel impairments, and joint optimization with channel acquisition. However, existing neural networks suffer from high training complexity and poor generalization ability when they are used to learn to optimize precoding for mitigating multi-user interference. This impedes their use in practical systems where the number of users is time-varying. In this paper, we propose a graph neural network (GNN) to learn precoding policies by harnessing both the mathematical model and the property of the policies. We first show that a vanilla GNN cannot well-learn pseudo-inverse of channel matrix when the numbers of antennas and users are large, and is not generalizable to unseen numbers of users. Then, we design a GNN by resorting to the Taylor's expansion of matrix pseudo-inverse, which allows for capturing the importance of the neighbored edges to be aggregated that is crucial for learning precoding policies efficiently. Simulation results show that the proposed GNN can well learn spectral efficient and energy efficient precoding policies in single- and multi-cell multi-user multi-antenna systems with low training complexity, and can be well generalized to the numbers of users.
Multilingual Communication System with Deaf Individuals Utilizing Natural and Visual Languages
Dec 01, 2022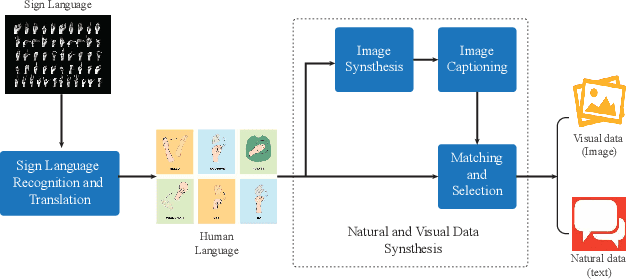

According to the World Federation of the Deaf, more than two hundred sign languages exist. Therefore, it is challenging to understand deaf individuals, even proficient sign language users, resulting in a barrier between the deaf community and the rest of society. To bridge this language barrier, we propose a novel multilingual communication system, namely MUGCAT, to improve the communication efficiency of sign language users. By converting recognized specific hand gestures into expressive pictures, which is universal usage and language independence, our MUGCAT system significantly helps deaf people convey their thoughts. To overcome the limitation of sign language usage, which is mostly impossible to translate into complete sentences for ordinary people, we propose to reconstruct meaningful sentences from the incomplete translation of sign language. We also measure the semantic similarity of generated sentences with fragmented recognized hand gestures to keep the original meaning. Experimental results show that the proposed system can work in a real-time manner and synthesize exquisite stunning illustrations and meaningful sentences from a few hand gestures of sign language. This proves that our MUGCAT has promising potential in assisting deaf communication.