 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Differentially-Private Sublinear-Time Clustering
Dec 27, 2021
Clustering is an essential primitive in unsupervised machine learning. We bring forth the problem of sublinear-time differentially-private clustering as a natural and well-motivated direction of research. We combine the $k$-means and $k$-median sublinear-time results of Mishra et al. (SODA, 2001) and of Czumaj and Sohler (Rand. Struct. and Algorithms, 2007) with recent results on private clustering of Balcan et al. (ICML 2017), Gupta et al. (SODA, 2010) and Ghazi et al. (NeurIPS, 2020) to obtain sublinear-time private $k$-means and $k$-median algorithms via subsampling. We also investigate the privacy benefits of subsampling for group privacy.
Sub-1ms Instinctual Interference Adaptive GaN LNA Front-End with Power and Linearity Tuning
Nov 27, 2022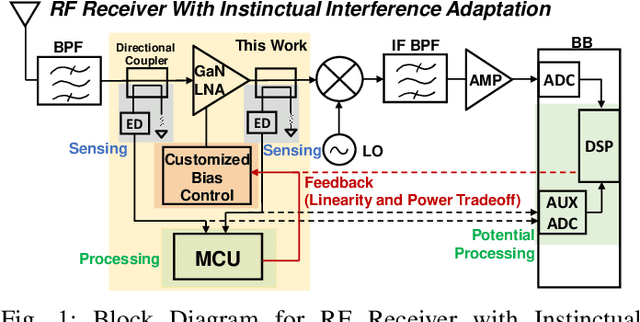
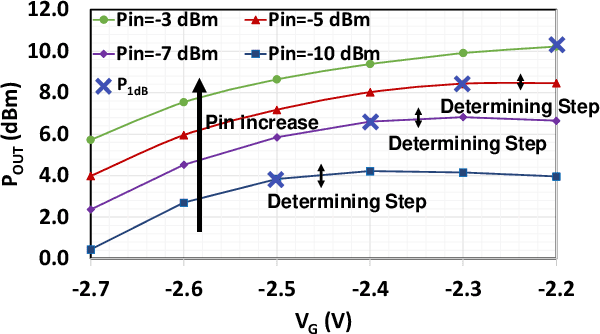
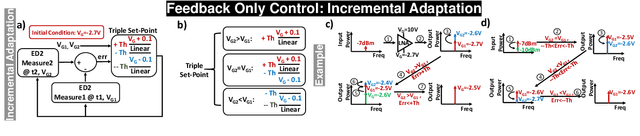
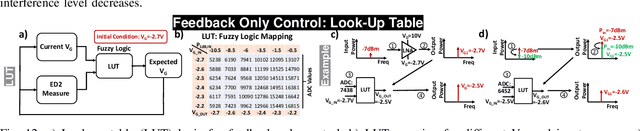
One of the major challenges in communication, radar, and electronic warfare receivers arises from nearby device interference. The paper presents a 2-6 GHz GaN LNA front-end with onboard sensing, processing, and feedback utilizing microcontroller-based controls to achieve adaptation to a variety of interference scenarios through power and linearity regulations. The utilization of GaN LNA provides high power handling capability (30 dBm) and high linearity (OIP3= 30 dBm) for radar and EW applications. The system permits an LNA power consumption to tune from 500 mW to 2 W (4X increase) in order to adjust the linearity from P\textsubscript{1dB,IN}=-10.5 dBm to 0.5 dBm (>10X increase). Across the tuning range, the noise figure increases by approximately 0.4 dB. Feedback control methods are presented with backgrounds from control theory. The rest of the controls consume $\leq$10$\%$ (100 mW) of nominal LNA power (1 W) to achieve an adaptation time <1 ms.
3inGAN: Learning a 3D Generative Model from Images of a Self-similar Scene
Nov 27, 2022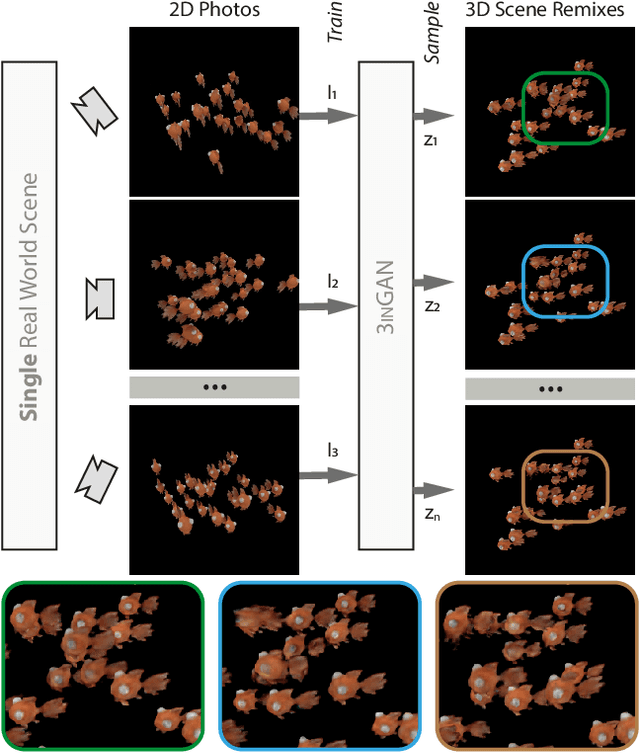
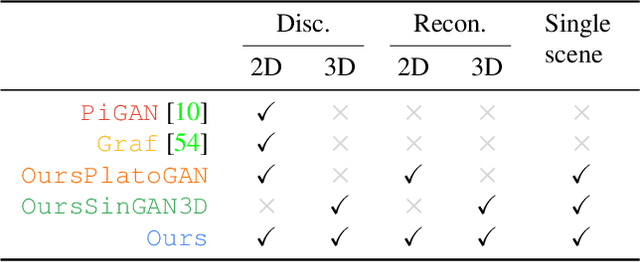
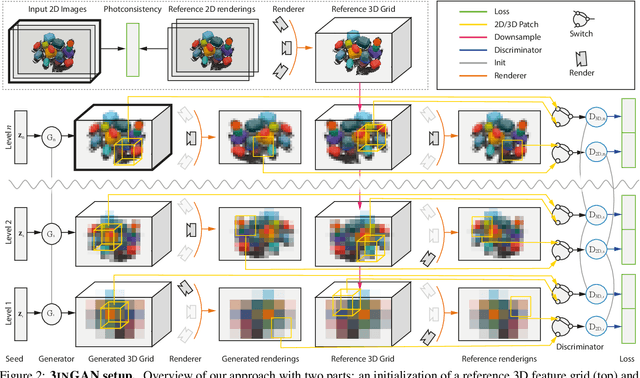

We introduce 3inGAN, an unconditional 3D generative model trained from 2D images of a single self-similar 3D scene. Such a model can be used to produce 3D "remixes" of a given scene, by mapping spatial latent codes into a 3D volumetric representation, which can subsequently be rendered from arbitrary views using physically based volume rendering. By construction, the generated scenes remain view-consistent across arbitrary camera configurations, without any flickering or spatio-temporal artifacts. During training, we employ a combination of 2D, obtained through differentiable volume tracing, and 3D Generative Adversarial Network (GAN) losses, across multiple scales, enforcing realism on both its 3D structure and the 2D renderings. We show results on semi-stochastic scenes of varying scale and complexity, obtained from real and synthetic sources. We demonstrate, for the first time, the feasibility of learning plausible view-consistent 3D scene variations from a single exemplar scene and provide qualitative and quantitative comparisons against recent related methods.
Attend Who is Weak: Pruning-assisted Medical Image Localization under Sophisticated and Implicit Imbalances
Dec 06, 2022

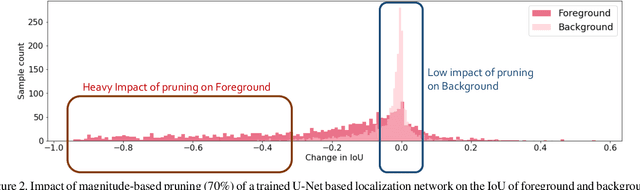
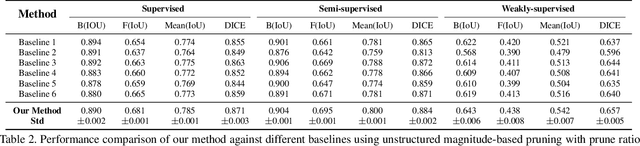
Deep neural networks (DNNs) have rapidly become a \textit{de facto} choice for medical image understanding tasks. However, DNNs are notoriously fragile to the class imbalance in image classification. We further point out that such imbalance fragility can be amplified when it comes to more sophisticated tasks such as pathology localization, as imbalances in such problems can have highly complex and often implicit forms of presence. For example, different pathology can have different sizes or colors (w.r.t.the background), different underlying demographic distributions, and in general different difficulty levels to recognize, even in a meticulously curated balanced distribution of training data. In this paper, we propose to use pruning to automatically and adaptively identify \textit{hard-to-learn} (HTL) training samples, and improve pathology localization by attending them explicitly, during training in \textit{supervised, semi-supervised, and weakly-supervised} settings. Our main inspiration is drawn from the recent finding that deep classification models have difficult-to-memorize samples and those may be effectively exposed through network pruning \cite{hooker2019compressed} - and we extend such observation beyond classification for the first time. We also present an interesting demographic analysis which illustrates HTLs ability to capture complex demographic imbalances. Our extensive experiments on the Skin Lesion Localization task in multiple training settings by paying additional attention to HTLs show significant improvement of localization performance by $\sim$2-3\%.
Self-supervised and Weakly Supervised Contrastive Learning for Frame-wise Action Representations
Dec 06, 2022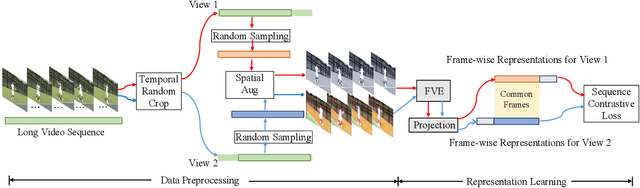
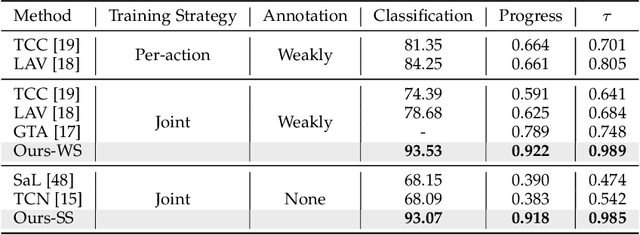
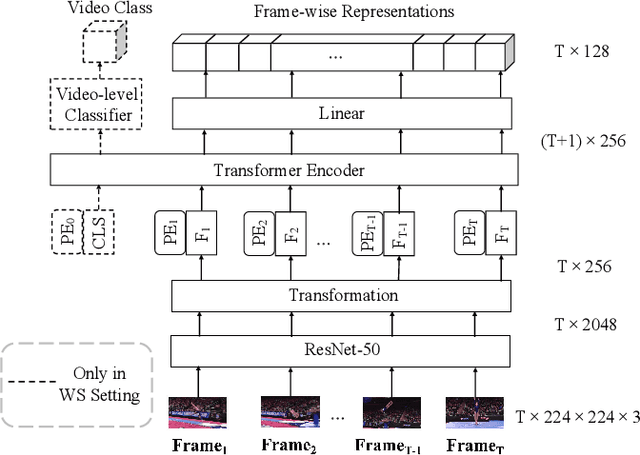
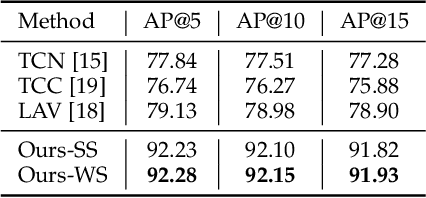
Previous work on action representation learning focused on global representations for short video clips. In contrast, many practical applications, such as video alignment, strongly demand learning the intensive representation of long videos. In this paper, we introduce a new framework of contrastive action representation learning (CARL) to learn frame-wise action representation in a self-supervised or weakly-supervised manner, especially for long videos. Specifically, we introduce a simple but effective video encoder that considers both spatial and temporal context by combining convolution and transformer. Inspired by the recent massive progress in self-supervised learning, we propose a new sequence contrast loss (SCL) applied to two related views obtained by expanding a series of spatio-temporal data in two versions. One is the self-supervised version that optimizes embedding space by minimizing KL-divergence between sequence similarity of two augmented views and prior Gaussian distribution of timestamp distance. The other is the weakly-supervised version that builds more sample pairs among videos using video-level labels by dynamic time wrapping (DTW). Experiments on FineGym, PennAction, and Pouring datasets show that our method outperforms previous state-of-the-art by a large margin for downstream fine-grained action classification and even faster inference. Surprisingly, although without training on paired videos like in previous works, our self-supervised version also shows outstanding performance in video alignment and fine-grained frame retrieval tasks.
Loss Adapted Plasticity in Deep Neural Networks to Learn from Data with Unreliable Sources
Dec 06, 2022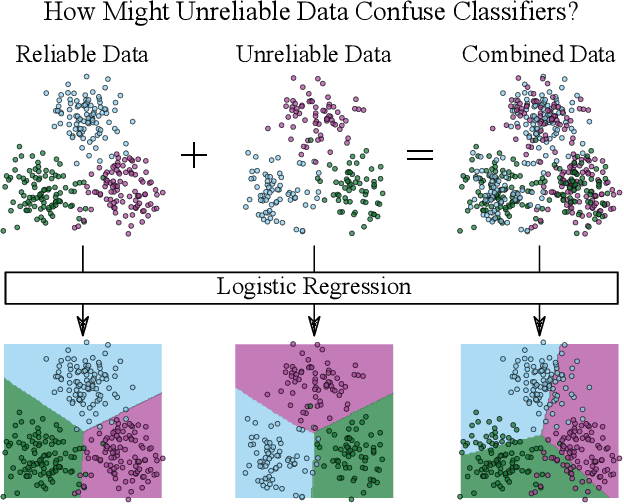
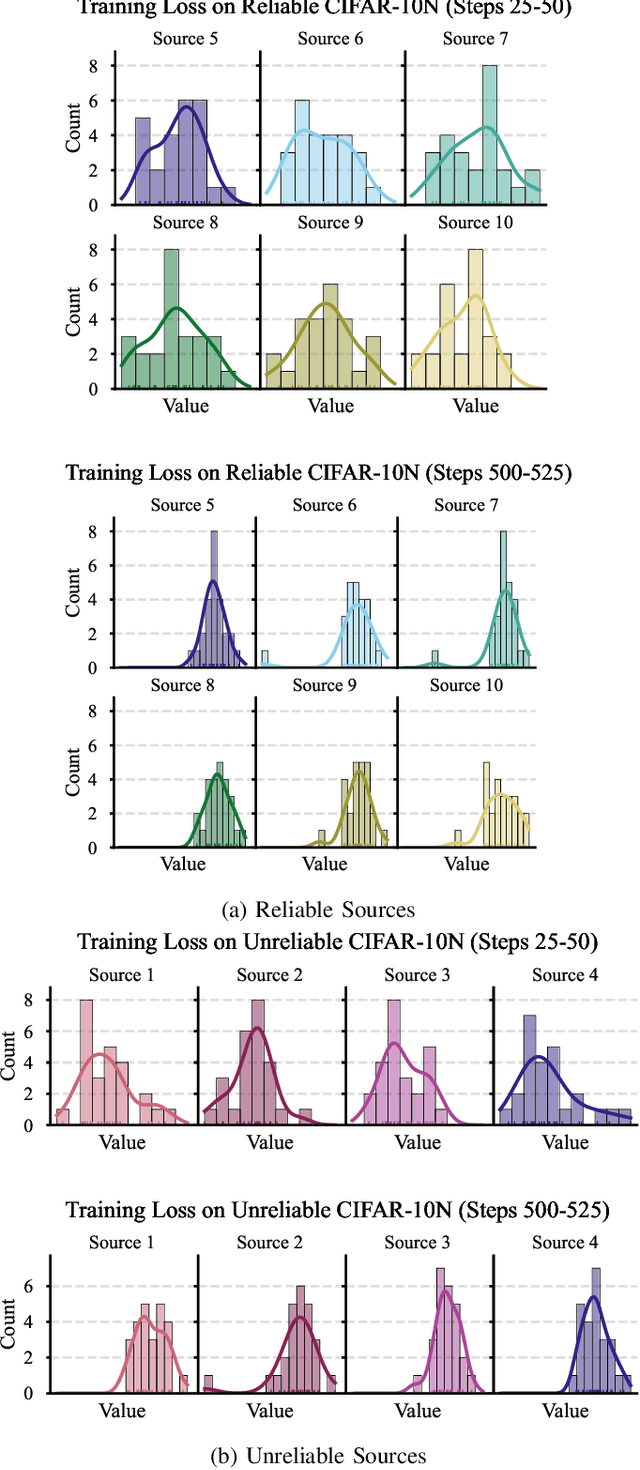
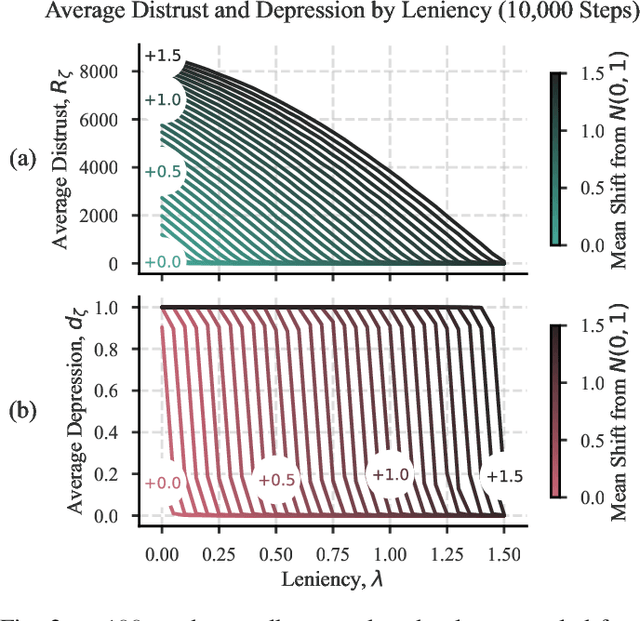
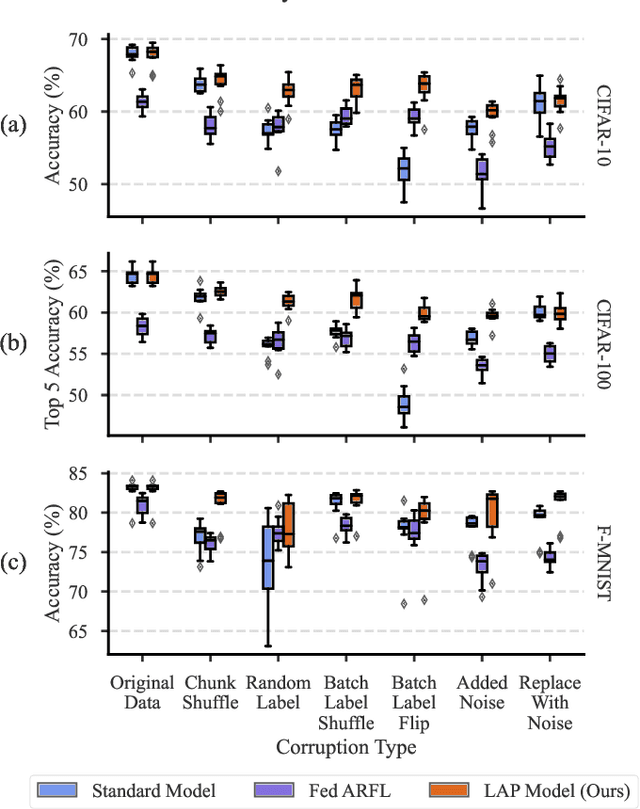
When data is streaming from multiple sources, conventional training methods update model weights often assuming the same level of reliability for each source; that is: a model does not consider data quality of each source during training. In many applications, sources can have varied levels of noise or corruption that has negative effects on the learning of a robust deep learning model. A key issue is that the quality of data or labels for individual sources is often not available during training and could vary over time. Our solution to this problem is to consider the mistakes made while training on data originating from sources and utilise this to create a perceived data quality for each source. This paper demonstrates a straight-forward and novel technique that can be applied to any gradient descent optimiser: Update model weights as a function of the perceived reliability of data sources within a wider data set. The algorithm controls the plasticity of a given model to weight updates based on the history of losses from individual data sources. We show that applying this technique can significantly improve model performance when trained on a mixture of reliable and unreliable data sources, and maintain performance when models are trained on data sources that are all considered reliable. All code to reproduce this work's experiments and implement the algorithm in the reader's own models is made available.
Reinforcement Learning for UAV control with Policy and Reward Shaping
Dec 06, 2022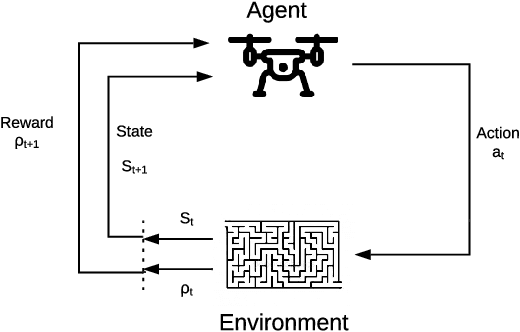
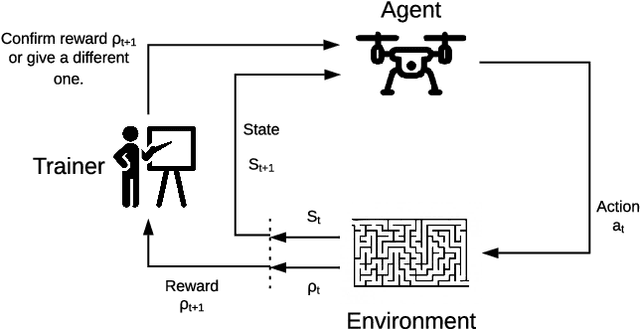
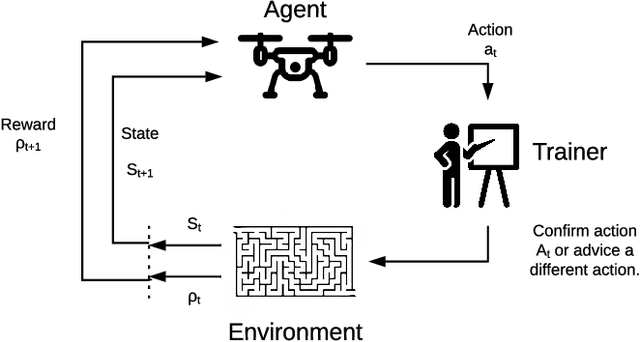
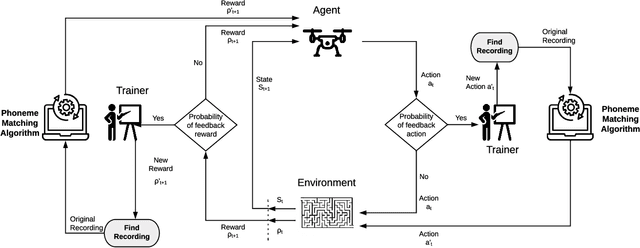
In recent years, unmanned aerial vehicle (UAV) related technology has expanded knowledge in the area, bringing to light new problems and challenges that require solutions. Furthermore, because the technology allows processes usually carried out by people to be automated, it is in great demand in industrial sectors. The automation of these vehicles has been addressed in the literature, applying different machine learning strategies. Reinforcement learning (RL) is an automation framework that is frequently used to train autonomous agents. RL is a machine learning paradigm wherein an agent interacts with an environment to solve a given task. However, learning autonomously can be time consuming, computationally expensive, and may not be practical in highly-complex scenarios. Interactive reinforcement learning allows an external trainer to provide advice to an agent while it is learning a task. In this study, we set out to teach an RL agent to control a drone using reward-shaping and policy-shaping techniques simultaneously. Two simulated scenarios were proposed for the training; one without obstacles and one with obstacles. We also studied the influence of each technique. The results show that an agent trained simultaneously with both techniques obtains a lower reward than an agent trained using only a policy-based approach. Nevertheless, the agent achieves lower execution times and less dispersion during training.
* 9 pages, 9 figures, Preprint accepted at the 41st International Conference of the Chilean Computer Science Society, SCCC 2022, Santiago, Chile, 2022
Synthesize Boundaries: A Boundary-aware Self-consistent Framework for Weakly Supervised Salient Object Detection
Dec 04, 2022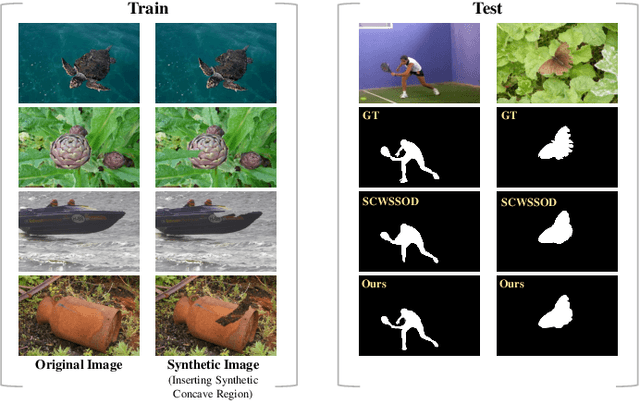
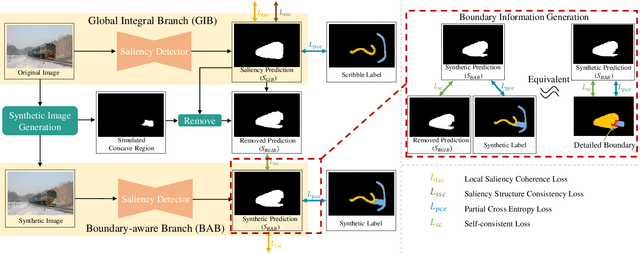
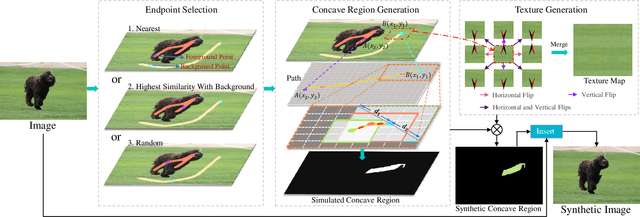
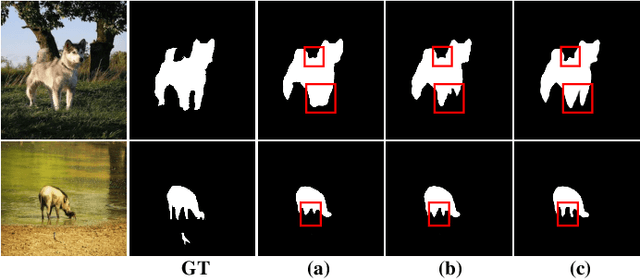
Fully supervised salient object detection (SOD) has made considerable progress based on expensive and time-consuming data with pixel-wise annotations. Recently, to relieve the labeling burden while maintaining performance, some scribble-based SOD methods have been proposed. However, learning precise boundary details from scribble annotations that lack edge information is still difficult. In this paper, we propose to learn precise boundaries from our designed synthetic images and labels without introducing any extra auxiliary data. The synthetic image creates boundary information by inserting synthetic concave regions that simulate the real concave regions of salient objects. Furthermore, we propose a novel self-consistent framework that consists of a global integral branch (GIB) and a boundary-aware branch (BAB) to train a saliency detector. GIB aims to identify integral salient objects, whose input is the original image. BAB aims to help predict accurate boundaries, whose input is the synthetic image. These two branches are connected through a self-consistent loss to guide the saliency detector to predict precise boundaries while identifying salient objects. Experimental results on five benchmarks demonstrate that our method outperforms the state-of-the-art weakly supervised SOD methods and further narrows the gap with the fully supervised methods.
Fast and Lightweight Scene Regressor for Camera Relocalization
Dec 04, 2022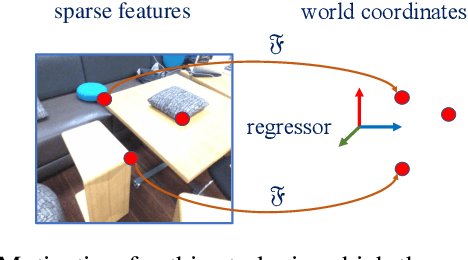
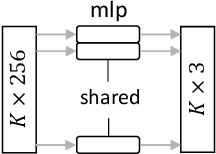
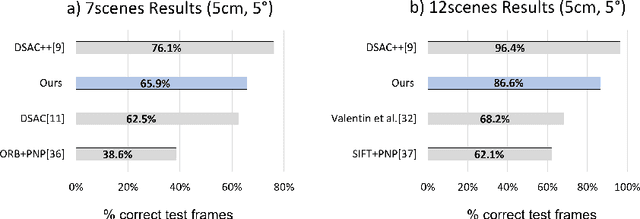
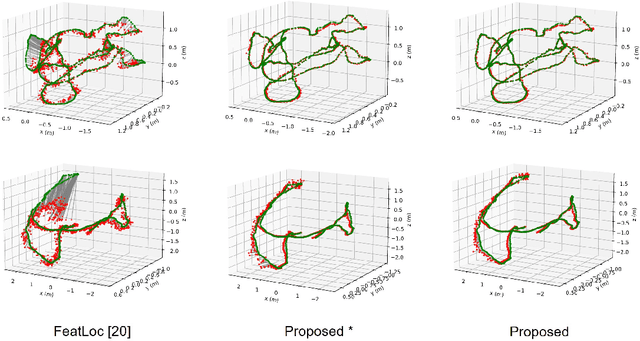
Camera relocalization involving a prior 3D reconstruction plays a crucial role in many mixed reality and robotics applications. Estimating the camera pose directly with respect to pre-built 3D models can be prohibitively expensive for several applications with limited storage and/or communication bandwidth. Although recent scene and absolute pose regression methods have become popular for efficient camera localization, most of them are computation-resource intensive and difficult to obtain a real-time inference with high accuracy constraints. This study proposes a simple scene regression method that requires only a multi-layer perceptron network for mapping scene coordinates to achieve accurate camera pose estimations. The proposed approach uses sparse descriptors to regress the scene coordinates, instead of a dense RGB image. The use of sparse features provides several advantages. First, the proposed regressor network is substantially smaller than those reported in previous studies. This makes our system highly efficient and scalable. Second, the pre-built 3D models provide the most reliable and robust 2D-3D matches. Therefore, learning from them can lead to an awareness of equivalent features and substantially improve the generalization performance. A detailed analysis of our approach and extensive evaluations using existing datasets are provided to support the proposed method. The implementation detail is available at https://github.com/aislab/feat2map
MixSeq: Connecting Macroscopic Time Series Forecasting with Microscopic Time Series Data
Oct 27, 2021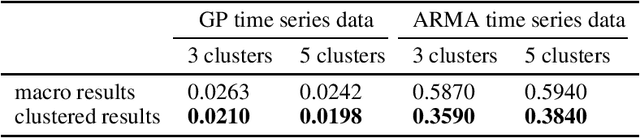

Time series forecasting is widely used in business intelligence, e.g., forecast stock market price, sales, and help the analysis of data trend. Most time series of interest are macroscopic time series that are aggregated from microscopic data. However, instead of directly modeling the macroscopic time series, rare literature studied the forecasting of macroscopic time series by leveraging data on the microscopic level. In this paper, we assume that the microscopic time series follow some unknown mixture probabilistic distributions. We theoretically show that as we identify the ground truth latent mixture components, the estimation of time series from each component could be improved because of lower variance, thus benefitting the estimation of macroscopic time series as well. Inspired by the power of Seq2seq and its variants on the modeling of time series data, we propose Mixture of Seq2seq (MixSeq), an end2end mixture model to cluster microscopic time series, where all the components come from a family of Seq2seq models parameterized by different parameters. Extensive experiments on both synthetic and real-world data show the superiority of our approach.