 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
3inGAN: Learning a 3D Generative Model from Images of a Self-similar Scene
Nov 27, 2022
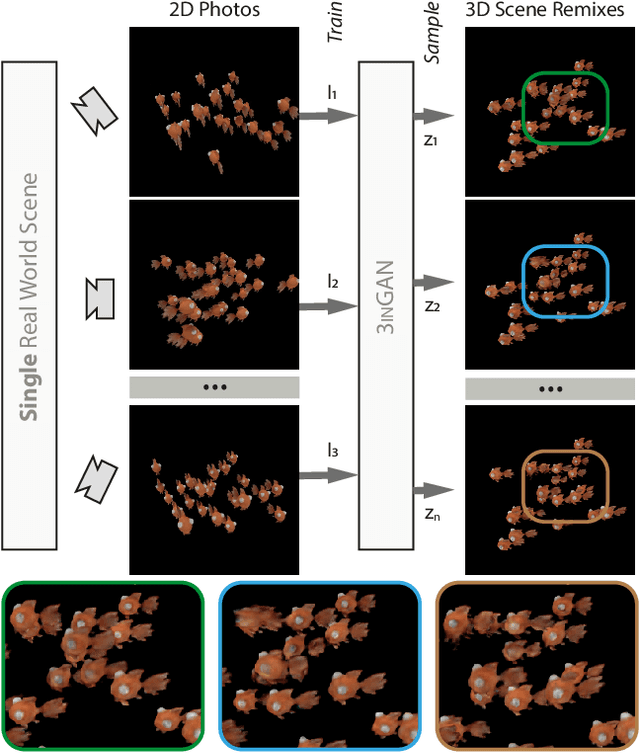
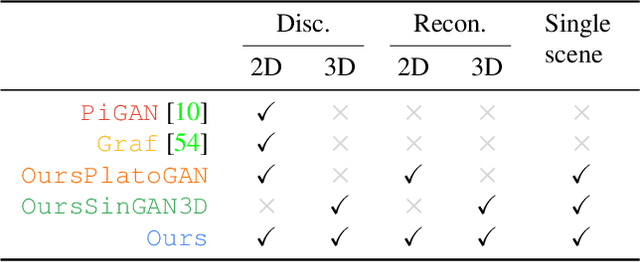
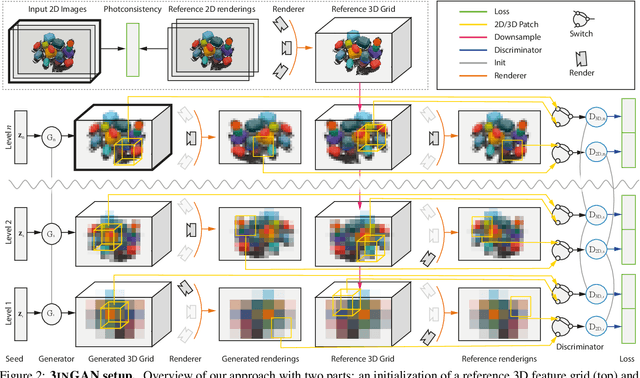

We introduce 3inGAN, an unconditional 3D generative model trained from 2D images of a single self-similar 3D scene. Such a model can be used to produce 3D "remixes" of a given scene, by mapping spatial latent codes into a 3D volumetric representation, which can subsequently be rendered from arbitrary views using physically based volume rendering. By construction, the generated scenes remain view-consistent across arbitrary camera configurations, without any flickering or spatio-temporal artifacts. During training, we employ a combination of 2D, obtained through differentiable volume tracing, and 3D Generative Adversarial Network (GAN) losses, across multiple scales, enforcing realism on both its 3D structure and the 2D renderings. We show results on semi-stochastic scenes of varying scale and complexity, obtained from real and synthetic sources. We demonstrate, for the first time, the feasibility of learning plausible view-consistent 3D scene variations from a single exemplar scene and provide qualitative and quantitative comparisons against recent related methods.
Sub-1ms Instinctual Interference Adaptive GaN LNA Front-End with Power and Linearity Tuning
Nov 27, 2022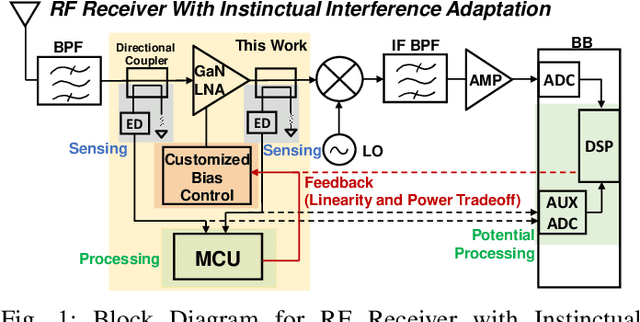
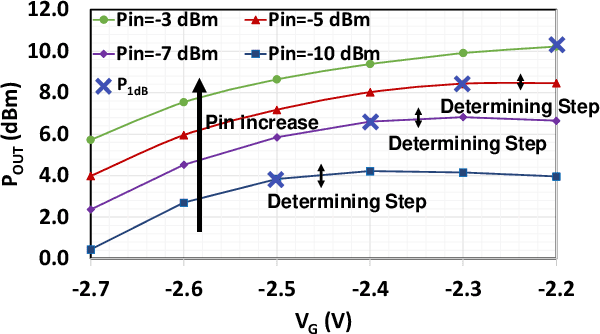
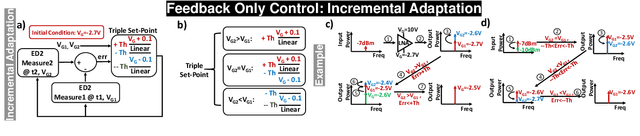
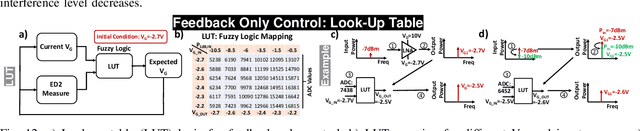
One of the major challenges in communication, radar, and electronic warfare receivers arises from nearby device interference. The paper presents a 2-6 GHz GaN LNA front-end with onboard sensing, processing, and feedback utilizing microcontroller-based controls to achieve adaptation to a variety of interference scenarios through power and linearity regulations. The utilization of GaN LNA provides high power handling capability (30 dBm) and high linearity (OIP3= 30 dBm) for radar and EW applications. The system permits an LNA power consumption to tune from 500 mW to 2 W (4X increase) in order to adjust the linearity from P\textsubscript{1dB,IN}=-10.5 dBm to 0.5 dBm (>10X increase). Across the tuning range, the noise figure increases by approximately 0.4 dB. Feedback control methods are presented with backgrounds from control theory. The rest of the controls consume $\leq$10$\%$ (100 mW) of nominal LNA power (1 W) to achieve an adaptation time <1 ms.
Tangent Bundle Filters and Neural Networks: from Manifolds to Cellular Sheaves and Back
Nov 18, 2022
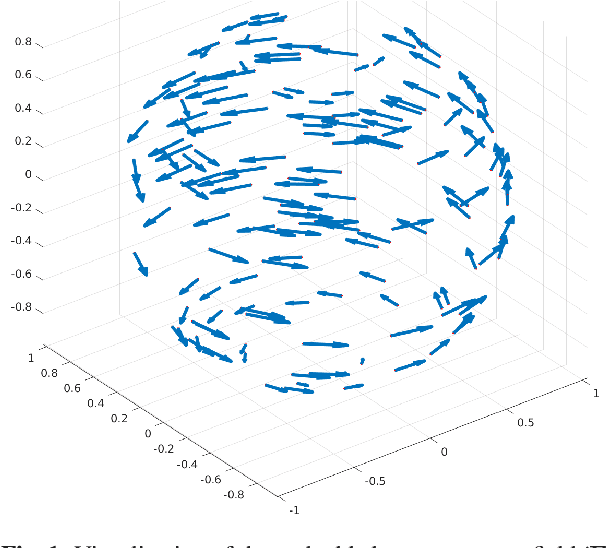
In this work we introduce a convolution operation over the tangent bundle of Riemannian manifolds exploiting the Connection Laplacian operator. We use the convolution to define tangent bundle filters and tangent bundle neural networks (TNNs), novel continuous architectures operating on tangent bundle signals, i.e. vector fields over manifolds. We discretize TNNs both in space and time domains, showing that their discrete counterpart is a principled variant of the recently introduced Sheaf Neural Networks. We formally prove that this discrete architecture converges to the underlying continuous TNN. We numerically evaluate the effectiveness of the proposed architecture on a denoising task of a tangent vector field over the unit 2-sphere.
Metadata Might Make Language Models Better
Nov 18, 2022


This paper discusses the benefits of including metadata when training language models on historical collections. Using 19th-century newspapers as a case study, we extend the time-masking approach proposed by Rosin et al., 2022 and compare different strategies for inserting temporal, political and geographical information into a Masked Language Model. After fine-tuning several DistilBERT on enhanced input data, we provide a systematic evaluation of these models on a set of evaluation tasks: pseudo-perplexity, metadata mask-filling and supervised classification. We find that showing relevant metadata to a language model has a beneficial impact and may even produce more robust and fairer models.
Embed and Emulate: Learning to estimate parameters of dynamical systems with uncertainty quantification
Nov 03, 2022
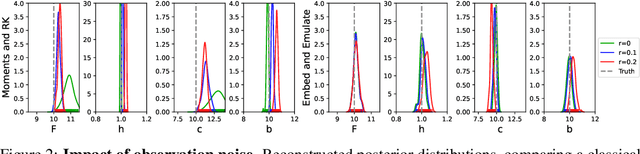
This paper explores learning emulators for parameter estimation with uncertainty estimation of high-dimensional dynamical systems. We assume access to a computationally complex simulator that inputs a candidate parameter and outputs a corresponding multichannel time series. Our task is to accurately estimate a range of likely values of the underlying parameters. Standard iterative approaches necessitate running the simulator many times, which is computationally prohibitive. This paper describes a novel framework for learning feature embeddings of observed dynamics jointly with an emulator that can replace high-cost simulators for parameter estimation. Leveraging a contrastive learning approach, our method exploits intrinsic data properties within and across parameter and trajectory domains. On a coupled 396-dimensional multiscale Lorenz 96 system, our method significantly outperforms a typical parameter estimation method based on predefined metrics and a classical numerical simulator, and with only 1.19% of the baseline's computation time. Ablation studies highlight the potential of explicitly designing learned emulators for parameter estimation by leveraging contrastive learning.
Nonlinear Discrete-time Systems' Identification without Persistence of Excitation: A Finite-time Concurrent Learning
Dec 14, 2021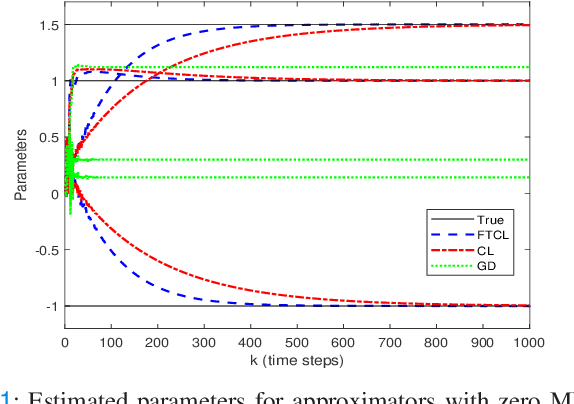
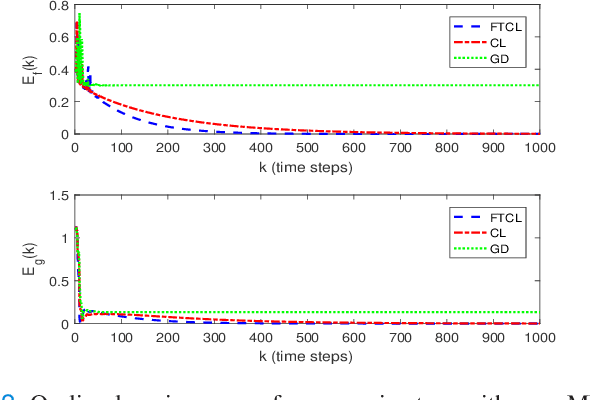
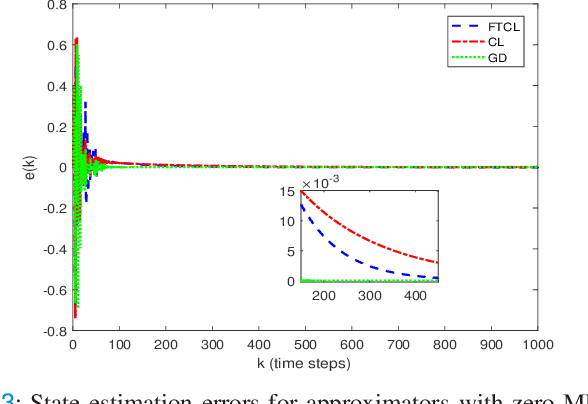
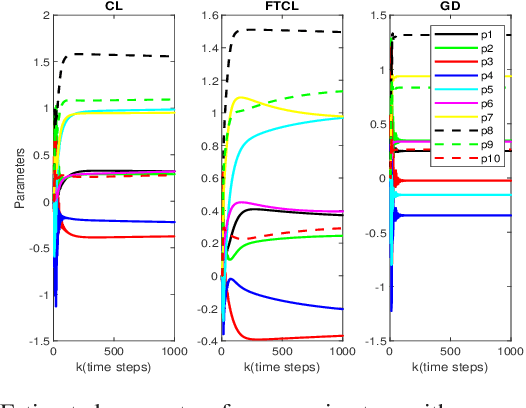
This paper deals with the problem of finite-time learning for unknown discrete-time nonlinear systems' dynamics, without the requirement of the persistence of excitation. A finite-time concurrent learning approach is presented to approximate the uncertainties of the discrete-time nonlinear systems in an on-line fashion by employing current data along with recorded experienced data satisfying an easy-to-check rank condition on the richness of the recorded data which is less restrictive in comparison with persistence of excitation condition. Rigorous proofs guarantee the finite-time convergence of the estimated parameters to their optimal values based on a discrete-time Lyapunov analysis. Compared with the existing work in the literature, simulation results illustrate that the proposed method can timely and precisely approximate the uncertainties.
Privacy Amplification by Subsampling in Time Domain
Jan 13, 2022
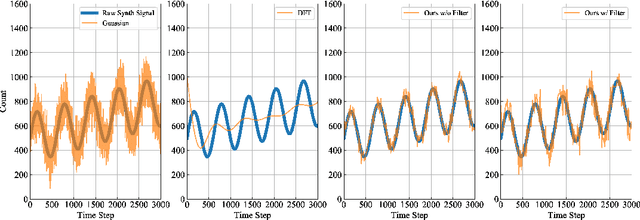

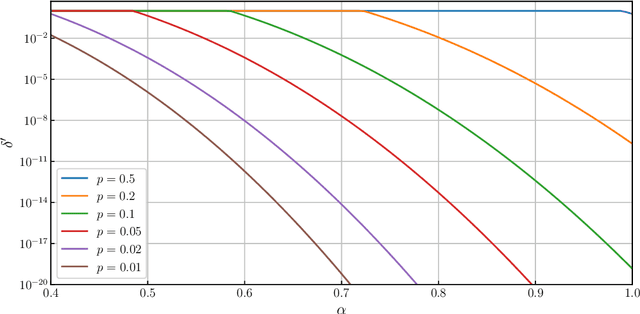
Aggregate time-series data like traffic flow and site occupancy repeatedly sample statistics from a population across time. Such data can be profoundly useful for understanding trends within a given population, but also pose a significant privacy risk, potentially revealing e.g., who spends time where. Producing a private version of a time-series satisfying the standard definition of Differential Privacy (DP) is challenging due to the large influence a single participant can have on the sequence: if an individual can contribute to each time step, the amount of additive noise needed to satisfy privacy increases linearly with the number of time steps sampled. As such, if a signal spans a long duration or is oversampled, an excessive amount of noise must be added, drowning out underlying trends. However, in many applications an individual realistically cannot participate at every time step. When this is the case, we observe that the influence of a single participant (sensitivity) can be reduced by subsampling and/or filtering in time, while still meeting privacy requirements. Using a novel analysis, we show this significant reduction in sensitivity and propose a corresponding class of privacy mechanisms. We demonstrate the utility benefits of these techniques empirically with real-world and synthetic time-series data.
Self Supervised Clustering of Traffic Scenes using Graph Representations
Nov 24, 2022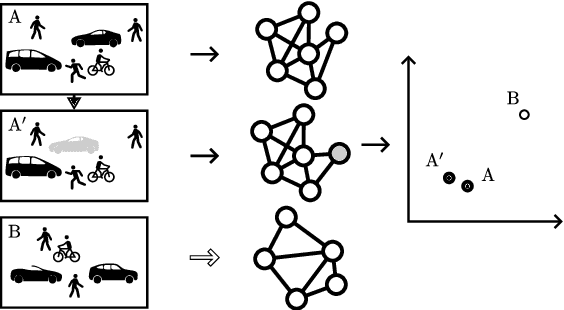
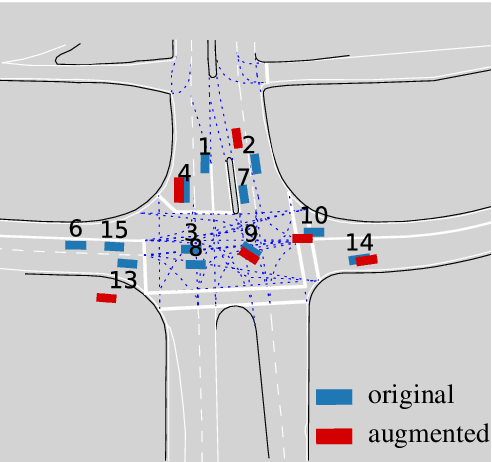
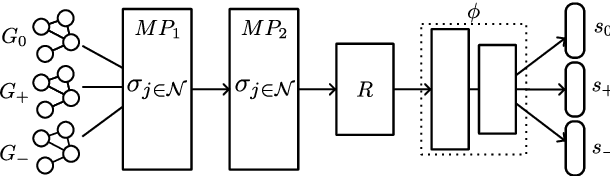
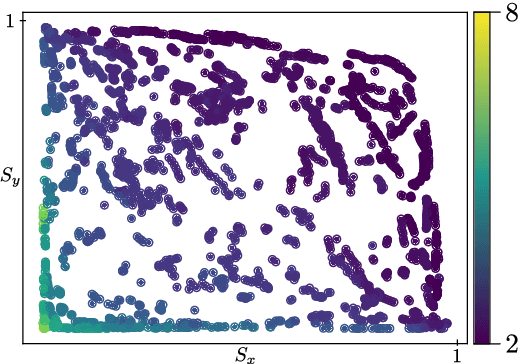
Examining graphs for similarity is a well-known challenge, but one that is mandatory for grouping graphs together. We present a data-driven method to cluster traffic scenes that is self-supervised, i.e. without manual labelling. We leverage the semantic scene graph model to create a generic graph embedding of the traffic scene, which is then mapped to a low-dimensional embedding space using a Siamese network, in which clustering is performed. In the training process of our novel approach, we augment existing traffic scenes in the Cartesian space to generate positive similarity samples. This allows us to overcome the challenge of reconstructing a graph and at the same time obtain a representation to describe the similarity of traffic scenes. We could show, that the resulting clusters possess common semantic characteristics. The approach was evaluated on the INTERACTION dataset.
Best of Both Worlds in Online Control: Competitive Ratio and Policy Regret
Nov 21, 2022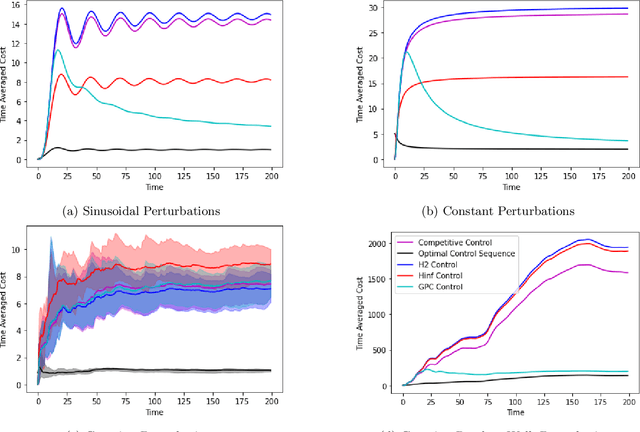
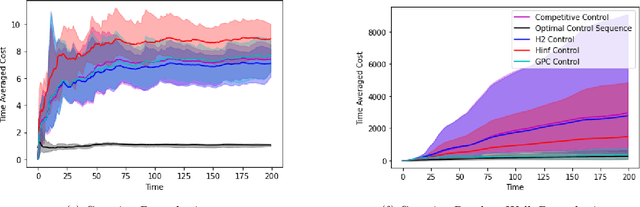
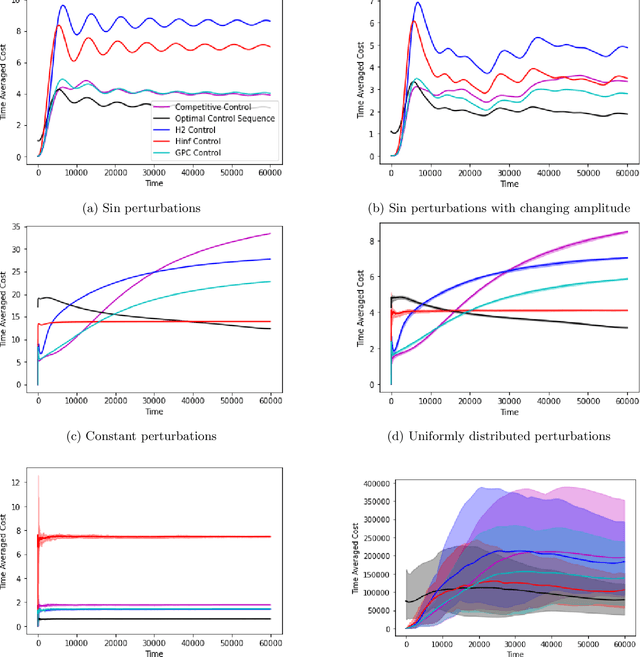
We consider the fundamental problem of online control of a linear dynamical system from two different viewpoints: regret minimization and competitive analysis. We prove that the optimal competitive policy is well-approximated by a convex parameterized policy class, known as a disturbance-action control (DAC) policies. Using this structural result, we show that several recently proposed online control algorithms achieve the best of both worlds: sublinear regret vs. the best DAC policy selected in hindsight, and optimal competitive ratio, up to an additive correction which grows sublinearly in the time horizon. We further conclude that sublinear regret vs. the optimal competitive policy is attainable when the linear dynamical system is unknown, and even when a stabilizing controller for the dynamics is not available a priori.
Refining time-space traffic diagrams: A multiple linear regression model
Apr 09, 2022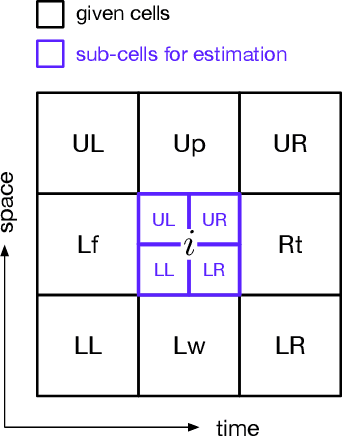
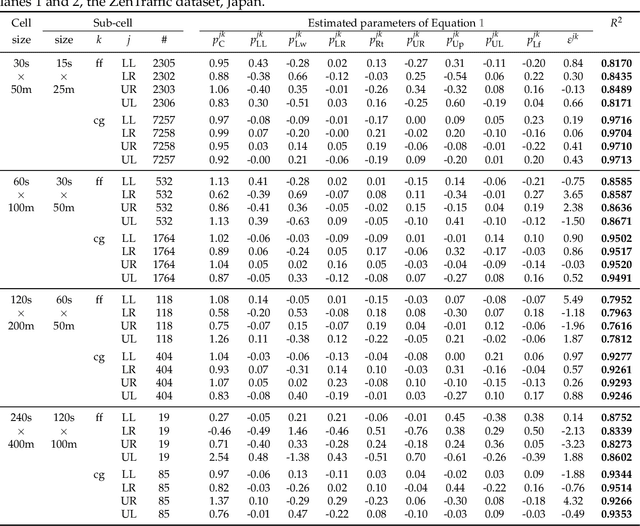
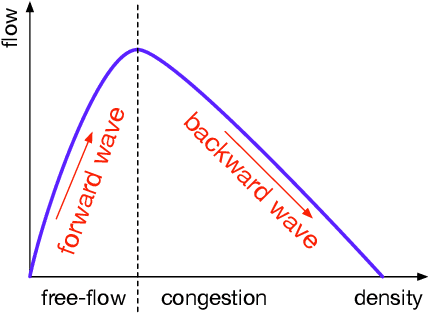
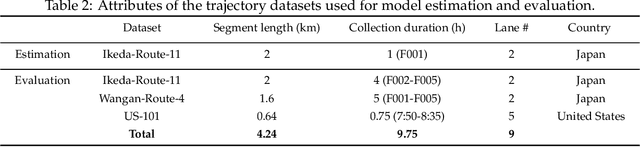
A time-space traffic (TS) diagram that presents traffic states in time-space cells with colors is one of the most important traffic analysis and visualization tools. Despite its importance for transportation research and engineering, most TS diagrams that have already existed or are being produced are too coarse to exhibit detailed traffic dynamics due to the limitation of the current information technology and traffic infrastructure investment. To increase the resolution of a TS diagram and make it present more traffic details, this paper introduces a TS diagram refinement problem and proposes a multiple linear regression-based model to solve the problem. Two tests, which attempt to increase the resolution of a TS diagram for 4 and 16 times, respectively, are carried out to evaluate the performance of the proposed model. The data collected from different time, different location and even different country is involved to thoroughly evaluate the accuracy and transferability of the proposed model. The strict tests with diverse data show that the proposed model, although it is simple in form, is able to refine a TS diagram with a promising accuracy and reliable transferability. The proposed refinement model will "save" those widely-existing TS diagrams from their blurry "faces" and make it possible to learn more traffic details from those TS diagrams.