 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Invariance-Aware Randomized Smoothing Certificates
Nov 25, 2022
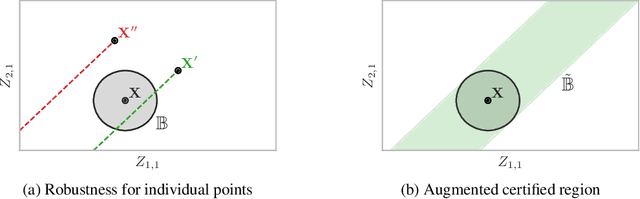
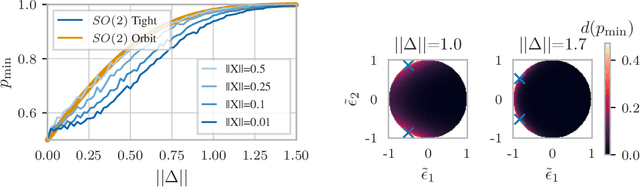
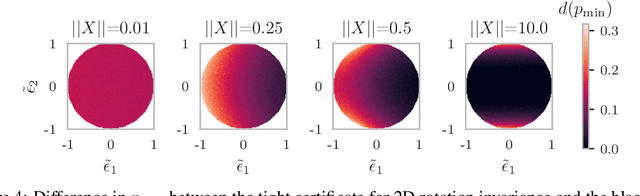
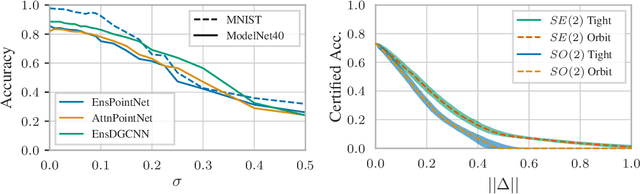
Building models that comply with the invariances inherent to different domains, such as invariance under translation or rotation, is a key aspect of applying machine learning to real world problems like molecular property prediction, medical imaging, protein folding or LiDAR classification. For the first time, we study how the invariances of a model can be leveraged to provably guarantee the robustness of its predictions. We propose a gray-box approach, enhancing the powerful black-box randomized smoothing technique with white-box knowledge about invariances. First, we develop gray-box certificates based on group orbits, which can be applied to arbitrary models with invariance under permutation and Euclidean isometries. Then, we derive provably tight gray-box certificates. We experimentally demonstrate that the provably tight certificates can offer much stronger guarantees, but that in practical scenarios the orbit-based method is a good approximation.
Uncertainty Principles for the Short-time Free Metaplectic Transform
Mar 24, 2022The free metaplectic transformation (FMT) has gained much popularity in recent times because of its various application in signal processing, paraxial optical systems, digital algorithms, optical encryption and so on. However, the FMT is inadequate for localized analysis of non-transient signals, as such, it is imperative to introduce a unique localized transform coined as the short time free metaplectic transform (STFMT). In this paper, we investigate the STFMT. Firstly, we propose the definition of the STFMT, and provide the time frequency analysis of the proposed transform in the FMT domain. Secondly, we investigate the basic properties of the proposed transform including the reconstruction formula, Moyals formula. The emergence of the STFMT definition and its properties broadens the development of time-frequency representation of higher-dimensional signals theory to a certain extent. Finally, we extend some different uncertainty principles (UP) from quantum mechanics including Liebs, Pitts UP, Heisenbergs uncertainty principle, Hausdorff-Young, Hardys UP, Beurlings UP, Logarithmic UP, and Nazarovs UP which have already been well studied in the FMT domain
Vertical Layering of Quantized Neural Networks for Heterogeneous Inference
Dec 10, 2022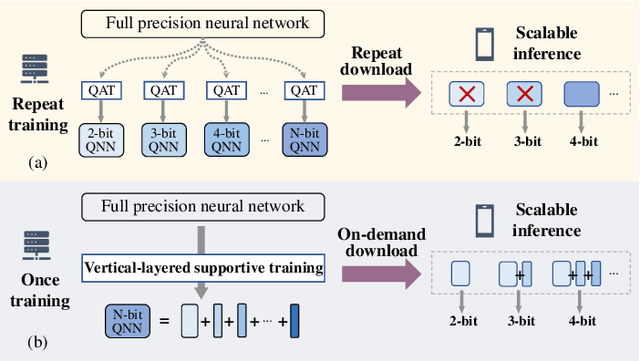
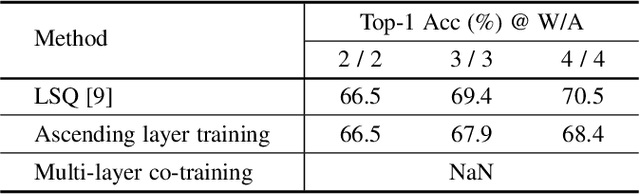
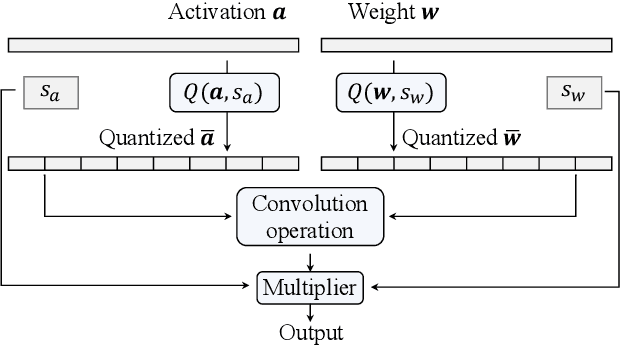
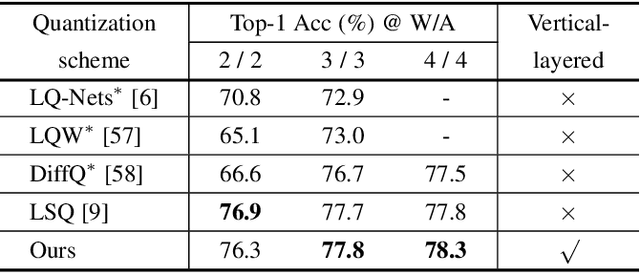
Although considerable progress has been obtained in neural network quantization for efficient inference, existing methods are not scalable to heterogeneous devices as one dedicated model needs to be trained, transmitted, and stored for one specific hardware setting, incurring considerable costs in model training and maintenance. In this paper, we study a new vertical-layered representation of neural network weights for encapsulating all quantized models into a single one. With this representation, we can theoretically achieve any precision network for on-demand service while only needing to train and maintain one model. To this end, we propose a simple once quantization-aware training (QAT) scheme for obtaining high-performance vertical-layered models. Our design incorporates a cascade downsampling mechanism which allows us to obtain multiple quantized networks from one full precision source model by progressively mapping the higher precision weights to their adjacent lower precision counterparts. Then, with networks of different bit-widths from one source model, multi-objective optimization is employed to train the shared source model weights such that they can be updated simultaneously, considering the performance of all networks. By doing this, the shared weights will be optimized to balance the performance of different quantized models, thus making the weights transferable among different bit widths. Experiments show that the proposed vertical-layered representation and developed once QAT scheme are effective in embodying multiple quantized networks into a single one and allow one-time training, and it delivers comparable performance as that of quantized models tailored to any specific bit-width. Code will be available.
Snapshot Multispectral Imaging Using a Diffractive Optical Network
Dec 10, 2022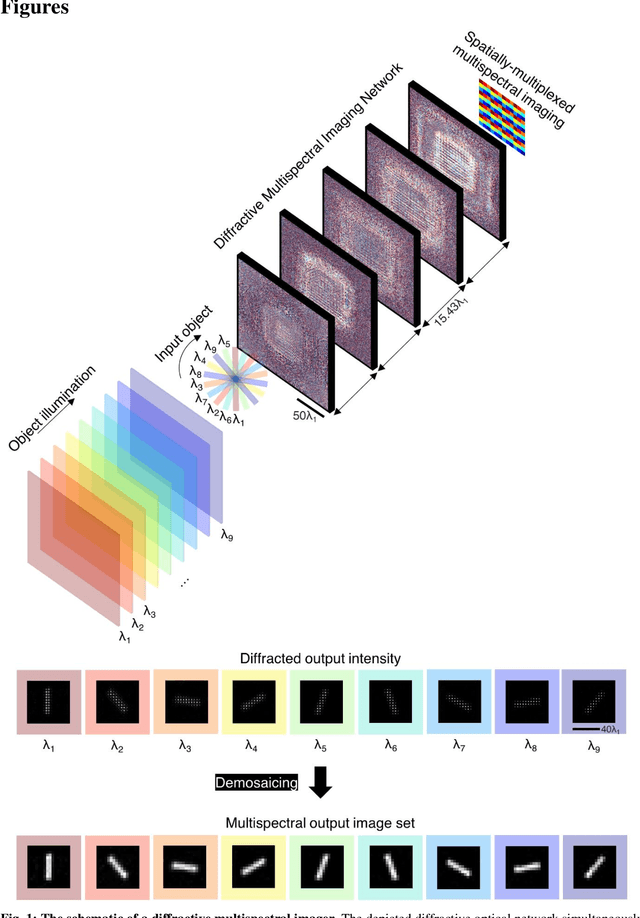
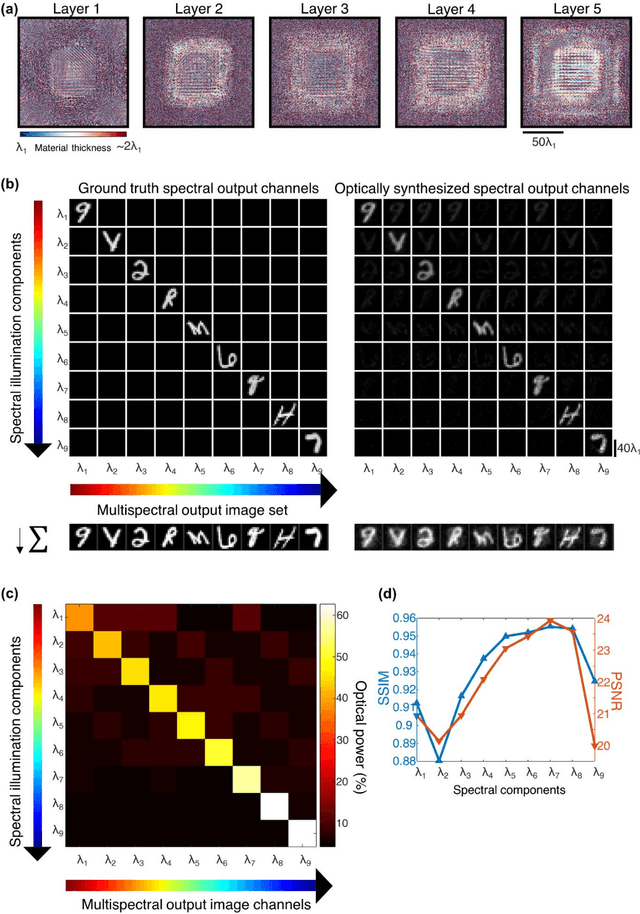
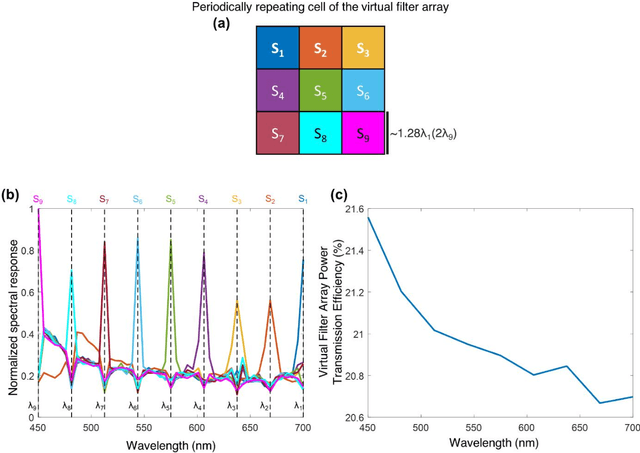
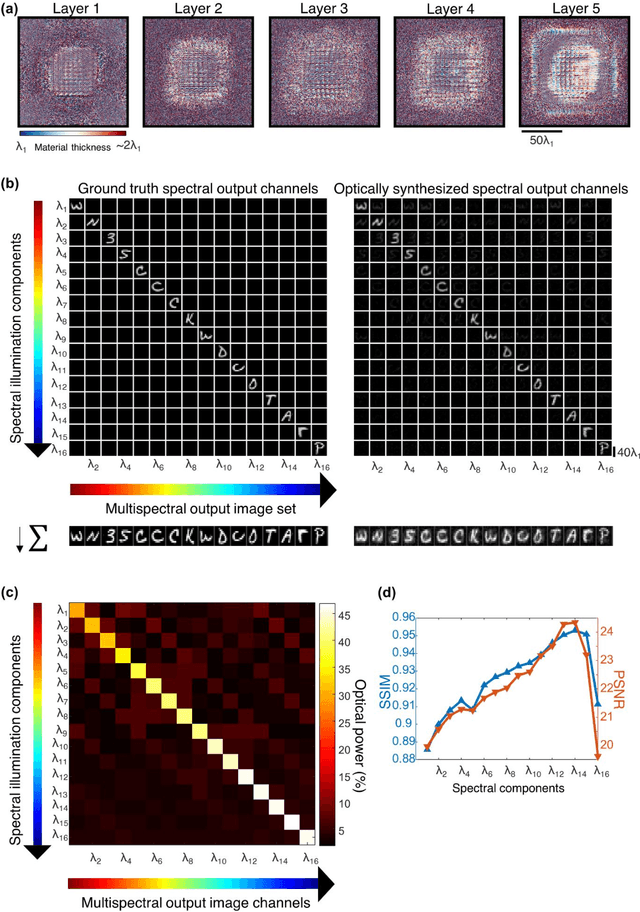
Multispectral imaging has been used for numerous applications in e.g., environmental monitoring, aerospace, defense, and biomedicine. Here, we present a diffractive optical network-based multispectral imaging system trained using deep learning to create a virtual spectral filter array at the output image field-of-view. This diffractive multispectral imager performs spatially-coherent imaging over a large spectrum, and at the same time, routes a pre-determined set of spectral channels onto an array of pixels at the output plane, converting a monochrome focal plane array or image sensor into a multispectral imaging device without any spectral filters or image recovery algorithms. Furthermore, the spectral responsivity of this diffractive multispectral imager is not sensitive to input polarization states. Through numerical simulations, we present different diffractive network designs that achieve snapshot multispectral imaging with 4, 9 and 16 unique spectral bands within the visible spectrum, based on passive spatially-structured diffractive surfaces, with a compact design that axially spans ~72 times the mean wavelength of the spectral band of interest. Moreover, we experimentally demonstrate a diffractive multispectral imager based on a 3D-printed diffractive network that creates at its output image plane a spatially-repeating virtual spectral filter array with 2x2=4 unique bands at terahertz spectrum. Due to their compact form factor and computation-free, power-efficient and polarization-insensitive forward operation, diffractive multispectral imagers can be transformative for various imaging and sensing applications and be used at different parts of the electromagnetic spectrum where high-density and wide-area multispectral pixel arrays are not widely available.
Physics-informed neural networks for operator equations with stochastic data
Nov 15, 2022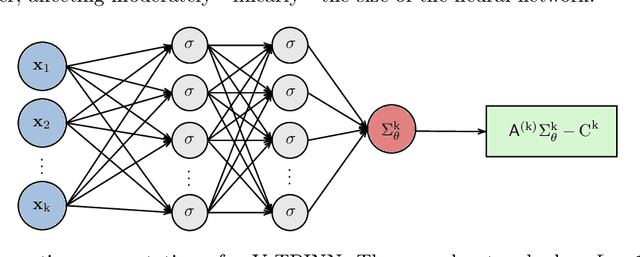
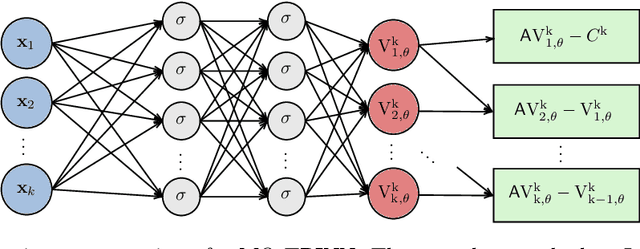
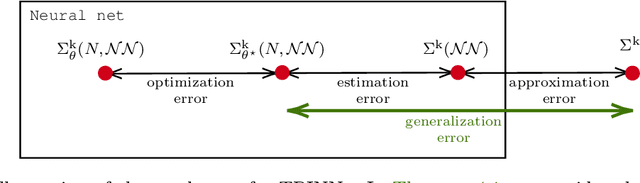
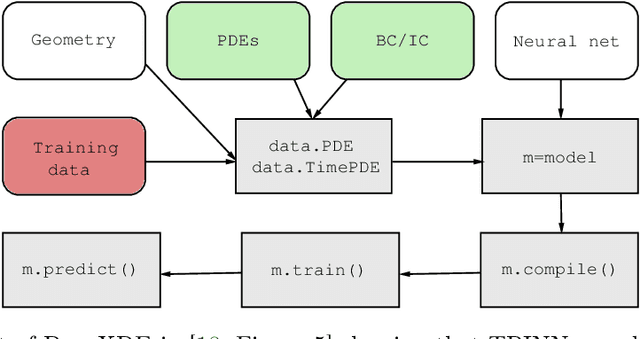
We consider the computation of statistical moments to operator equations with stochastic data. We remark that application of PINNs -- referred to as TPINNs -- allows to solve the induced tensor operator equations under minimal changes of existing PINNs code. This scheme can overcome the curse of dimensionality and covers non-linear and time-dependent operators. We propose two types of architectures, referred to as vanilla and multi-output TPINNs, and investigate their benefits and limitations. Exhaustive numerical experiments are performed; demonstrating applicability and performance; raising a variety of new promising research avenues.
LiePoseNet: Heterogeneous Loss Function Based on Lie Group for Significant Speed-up of PoseNet Training Process
Nov 15, 2022

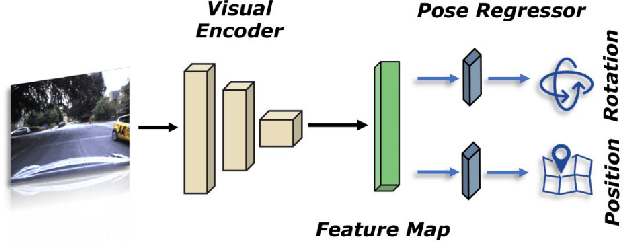
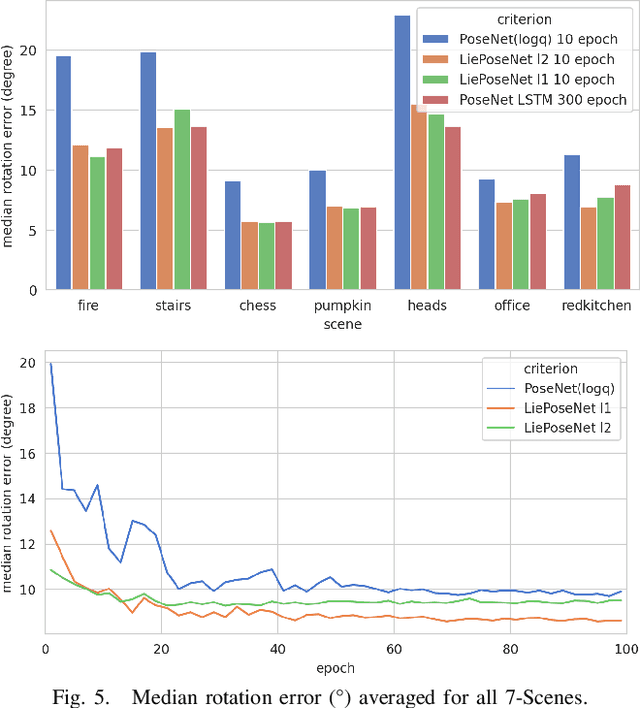
Visual localization is an essential modern technology for robotics and computer vision. Popular approaches for solving this task are image-based methods. Nowadays, these methods have low accuracy and a long training time. The reasons are the lack of rigid-body and projective geometry awareness, landmark symmetry, and homogeneous error assumption. We propose a heterogeneous loss function based on concentrated Gaussian distribution with the Lie group to overcome these difficulties. Following our experiment, the proposed method allows us to speed up the training process significantly (from 300 to 10 epochs) with acceptable error values.
ARLIF-IDS -- Attention augmented Real-Time Isolation Forest Intrusion Detection System
Apr 20, 2022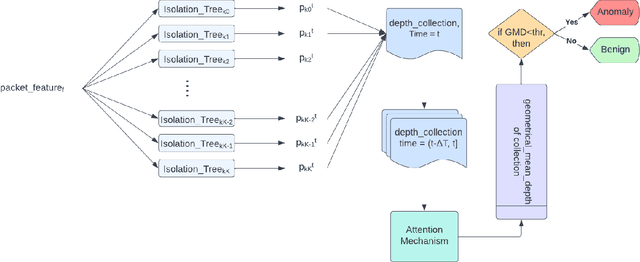
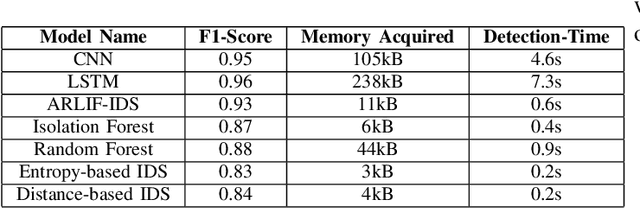
Distributed Denial of Service (DDoS) attack is a malicious attempt to disrupt the normal traffic of a targeted server, service or network by overwhelming the target or its surrounding infrastructure with a flood of Internet traffic. Emerging technologies such as the Internet of Things and Software Defined Networking leverage lightweight strategies for the early detection of DDoS attacks. Previous literature demonstrates the utility of lower number of significant features for intrusion detection. Thus, it is essential to have a fast and effective security identification model based on low number of features. In this work, a novel Attention-based Isolation Forest Intrusion Detection System is proposed. The model considerably reduces training time and memory consumption of the generated model. For performance assessment, the model is assessed over two benchmark datasets, the NSL-KDD dataset & the KDDCUP'99 dataset. Experimental results demonstrate that the proposed attention augmented model achieves a significant reduction in execution time, by 91.78%, and an average detection F1-Score of 0.93 on the NSL-KDD and KDDCUP'99 dataset. The results of performance evaluation show that the proposed methodology has low complexity and requires less processing time and computational resources, outperforming other current IDS based on machine learning algorithms.
DAMNETS: A Deep Autoregressive Model for Generating Markovian Network Time Series
Mar 28, 2022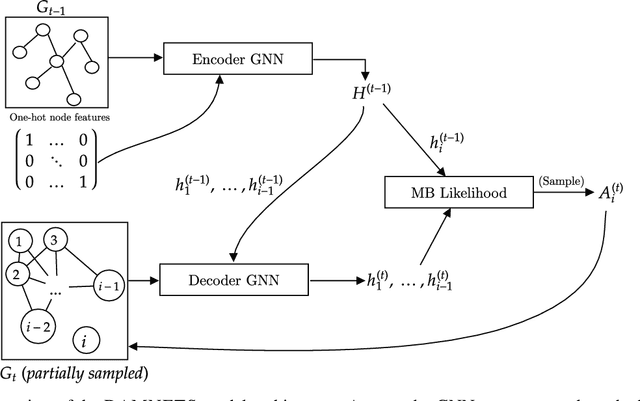
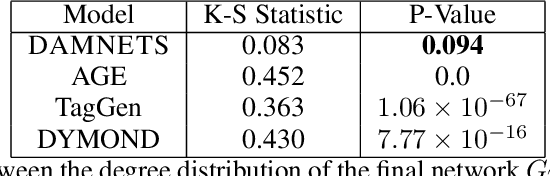
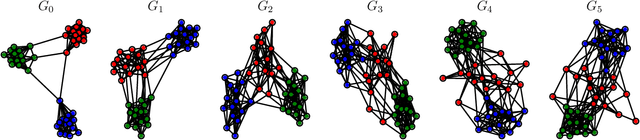

In this work, we introduce DAMNETS, a deep generative model for Markovian network time series. Time series of networks are found in many fields such as trade or payment networks in economics, contact networks in epidemiology or social media posts over time. Generative models of such data are useful for Monte-Carlo estimation and data set expansion, which is of interest for both data privacy and model fitting. Using recent ideas from the Graph Neural Network (GNN) literature, we introduce a novel GNN encoder-decoder structure in which an encoder GNN learns a latent representation of the input graph, and a decoder GNN uses this representation to simulate the network dynamics. We show using synthetic data sets that DAMNETS can replicate features of network topology across time observed in the real world, such as changing community structure and preferential attachment. DAMNETS outperforms competing methods on all of our measures of sample quality over several real and synthetic data sets.
A Stream Learning Approach for Real-Time Identification of False Data Injection Attacks in Cyber-Physical Power Systems
Oct 13, 2022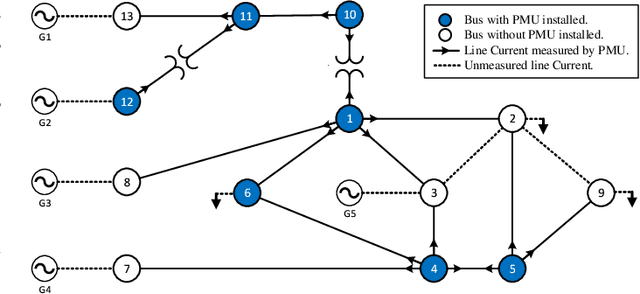
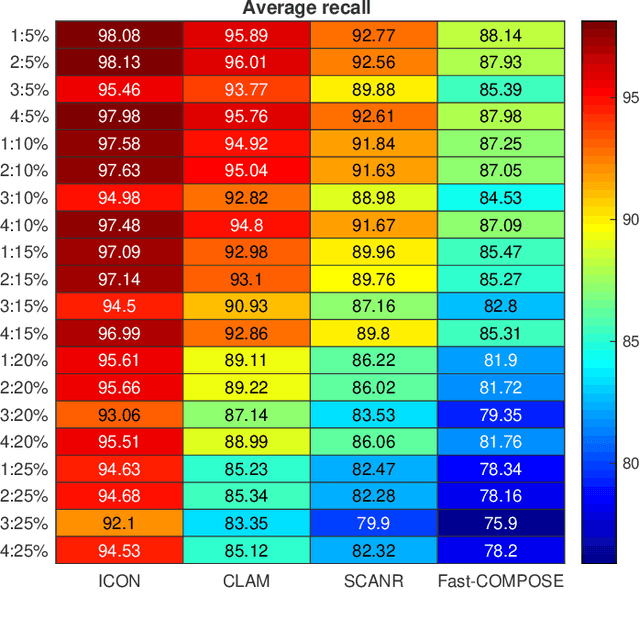
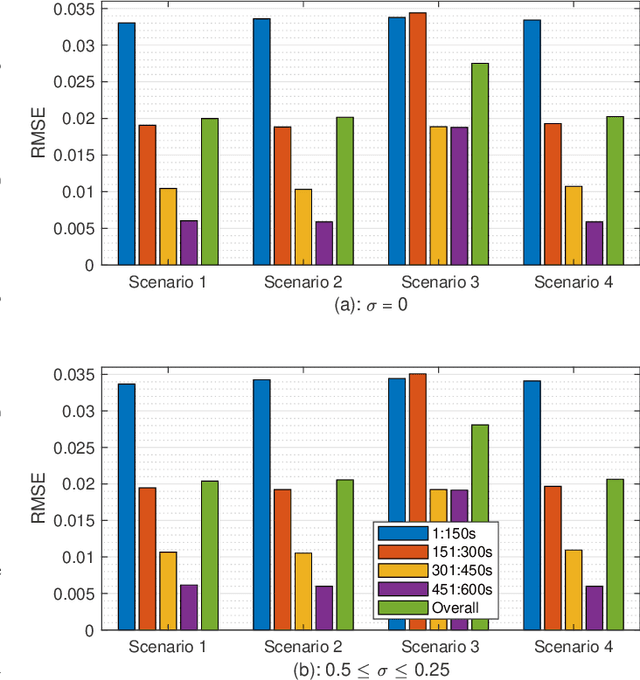
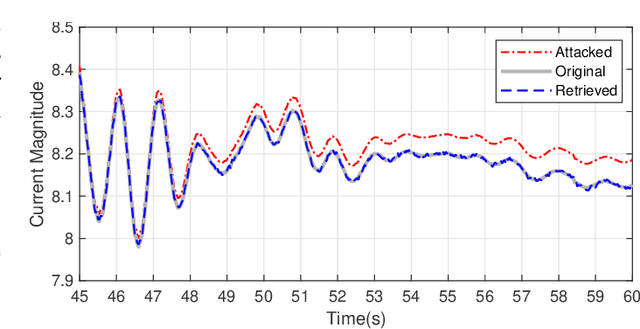
This paper presents a novel data-driven framework to aid in system state estimation when the power system is under unobservable false data injection attacks. The proposed framework dynamically detects and classifies false data injection attacks. Then, it retrieves the control signal using the acquired information. This process is accomplished in three main modules, with novel designs, for detection, classification, and control signal retrieval. The detection module monitors historical changes in phasor measurements and captures any deviation pattern caused by an attack on a complex plane. This approach can help to reveal characteristics of the attacks including the direction, magnitude, and ratio of the injected false data. Using this information, the signal retrieval module can easily recover the original control signal and remove the injected false data. Further information regarding the attack type can be obtained through the classifier module. The proposed ensemble learner is compatible with harsh learning conditions including the lack of labeled data, concept drift, concept evolution, recurring classes, and independence from external updates. The proposed novel classifier can dynamically learn from data and classify attacks under all these harsh learning conditions. The introduced framework is evaluated w.r.t. real-world data captured from the Central New York Power System. The obtained results indicate the efficacy and stability of the proposed framework.
Improvements to Embedding-Matching Acoustic-to-Word ASR Using Multiple-Hypothesis Pronunciation-Based Embeddings
Oct 30, 2022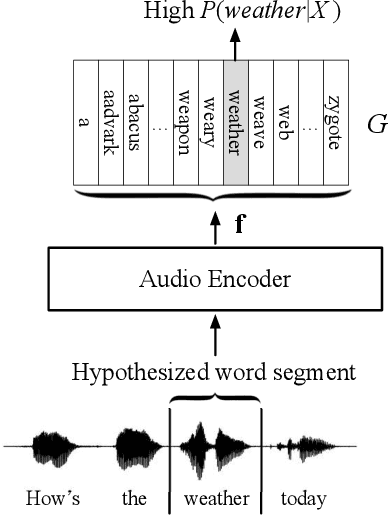
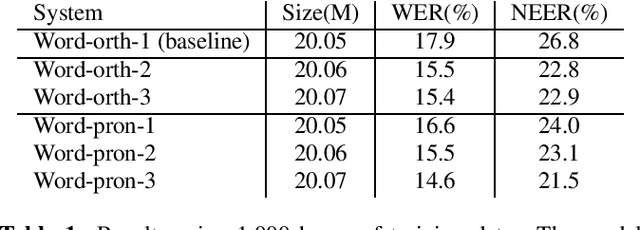
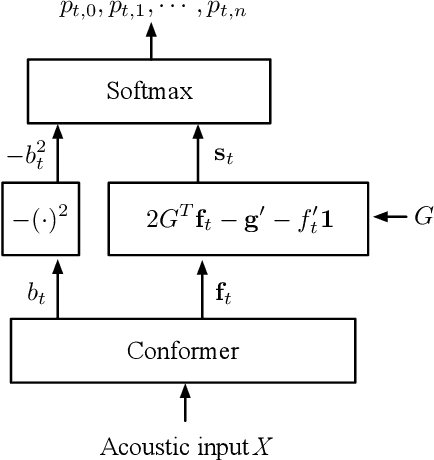
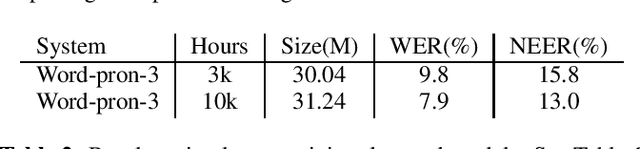
In embedding-matching acoustic-to-word (A2W) ASR, every word in the vocabulary is represented by a fixed-dimension embedding vector that can be added or removed independently of the rest of the system. The approach is potentially an elegant solution for the dynamic out-of-vocabulary (OOV) words problem, where speaker- and context-dependent named entities like contact names must be incorporated into the ASR on-the-fly for every speech utterance at testing time. Challenges still remain, however, in improving the overall accuracy of embedding-matching A2W. In this paper, we contribute two methods that improve the accuracy of embedding-matching A2W. First, we propose internally producing multiple embeddings, instead of a single embedding, at each instance in time, which allows the A2W model to propose a richer set of hypotheses over multiple time segments in the audio. Second, we propose using word pronunciation embeddings rather than word orthography embeddings to reduce ambiguities introduced by words that have more than one sound. We show that the above ideas give significant accuracy improvement, with the same training data and nearly identical model size, in scenarios where dynamic OOV words play a crucial role. On a dataset of various queries to a speech-based digital assistant that include many user-dependent contact names, we observe up to 18% decrease in word error rate using the proposed improvements.