 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Evaluating and reducing the distance between synthetic and real speech distributions
Nov 29, 2022
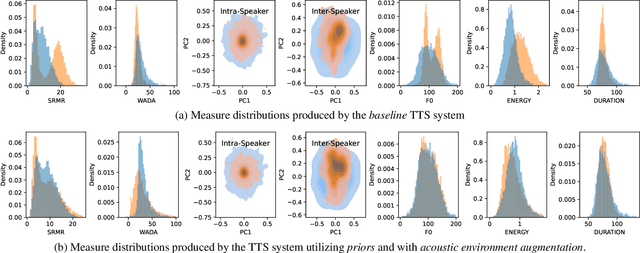
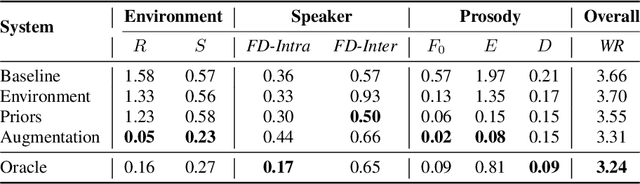
While modern Text-to-Speech (TTS) systems can produce speech rated highly in terms of subjective evaluation, the distance between real and synthetic speech distributions remains understudied, where we use the term \textit{distribution} to mean the sample space of all possible real speech recordings from a given set of speakers; or of the synthetic samples that could be generated for the same set of speakers. We evaluate the distance of real and synthetic speech distributions along the dimensions of the acoustic environment, speaker characteristics and prosody using a range of speech processing measures and the respective Wasserstein distances of their distributions. We reduce these distribution distances along said dimensions by providing utterance-level information derived from the measures to the model and show they can be generated at inference time. The improvements to the dimensions translate to overall distribution distance reduction approximated using Automatic Speech Recognition (ASR) by evaluating the fitness of the synthetic data as training data.
Design Space Exploration and Explanation via Conditional Variational Autoencoders in Meta-model-based Conceptual Design of Pedestrian Bridges
Nov 29, 2022
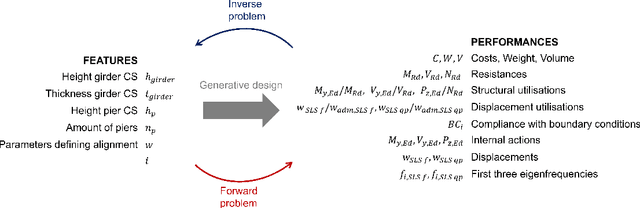
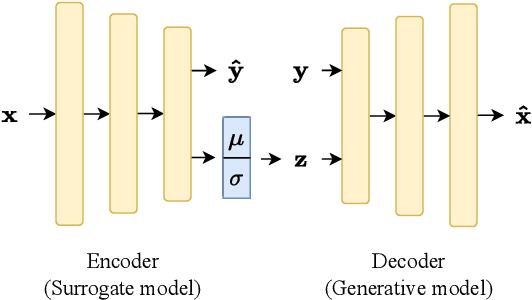
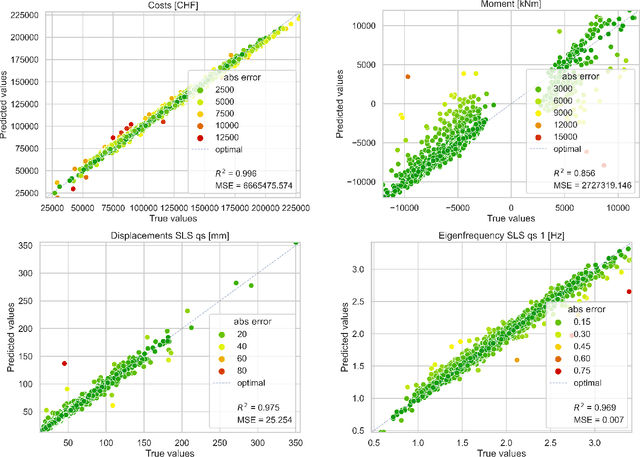
For conceptual design, engineers rely on conventional iterative (often manual) techniques. Emerging parametric models facilitate design space exploration based on quantifiable performance metrics, yet remain time-consuming and computationally expensive. Pure optimisation methods, however, ignore qualitative aspects (e.g. aesthetics or construction methods). This paper provides a performance-driven design exploration framework to augment the human designer through a Conditional Variational Autoencoder (CVAE), which serves as forward performance predictor for given design features as well as an inverse design feature predictor conditioned on a set of performance requests. The CVAE is trained on 18'000 synthetically generated instances of a pedestrian bridge in Switzerland. Sensitivity analysis is employed for explainability and informing designers about (i) relations of the model between features and/or performances and (ii) structural improvements under user-defined objectives. A case study proved our framework's potential to serve as a future co-pilot for conceptual design studies of pedestrian bridges and beyond.
Psychophysiology-aided Perceptually Fluent Speech Analysis of Children Who Stutter
Nov 16, 2022
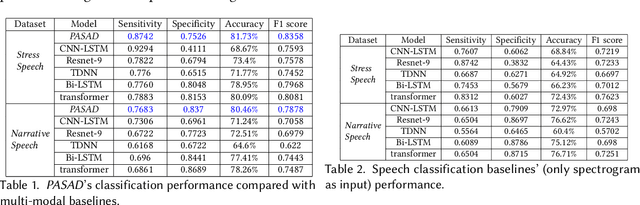
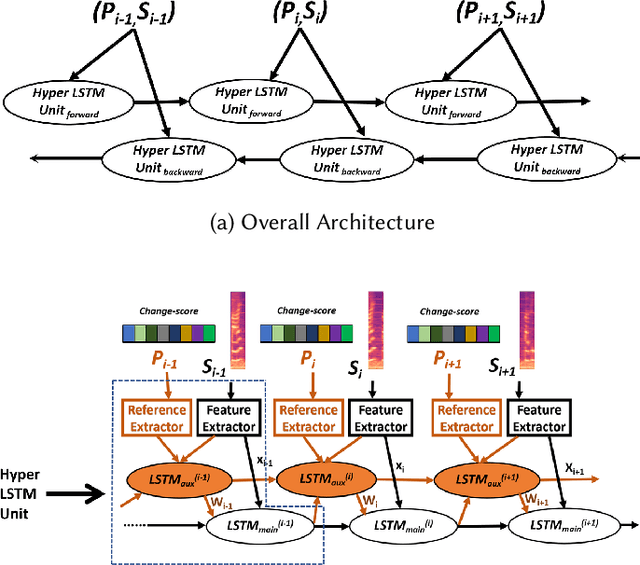
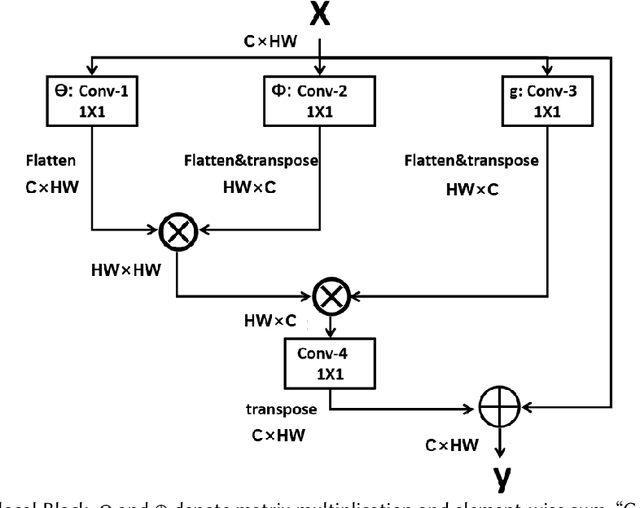
This first-of-its-kind paper presents a novel approach named PASAD that detects changes in perceptually fluent speech acoustics of young children. Particularly, analysis of perceptually fluent speech enables identifying the speech-motor-control factors that are considered as the underlying cause of stuttering disfluencies. Recent studies indicate that the speech production of young children, especially those who stutter, may get adversely affected by situational physiological arousal. A major contribution of this paper is leveraging the speaker's situational physiological responses in real-time to analyze the speech signal effectively. The presented PASAD approach adapts a Hyper-Network structure to extract temporal speech importance information leveraging physiological parameters. In addition, a novel non-local acoustic spectrogram feature extraction network identifies meaningful acoustic attributes. Finally, a sequential network utilizes the acoustic attributes and the extracted temporal speech importance for effective classification. We collected speech and physiological sensing data from 73 preschool-age children who stutter (CWS) and who don't stutter (CWNS) in different conditions. PASAD's unique architecture enables visualizing speech attributes distinct to a CWS's fluent speech and mapping them to the speaker's respective speech-motor-control factors (i.e., speech articulators). Extracted knowledge can enhance understanding of children's fluent speech, speech-motor-control (SMC), and stuttering development. Our comprehensive evaluation shows that PASAD outperforms state-of-the-art multi-modal baseline approaches in different conditions, is expressive and adaptive to the speaker's speech and physiology, generalizable, robust, and is real-time executable on mobile and scalable devices.
Ischemic Stroke Lesion Prediction using imbalanced Temporal Deep Gaussian Process (iTDGP)
Nov 16, 2022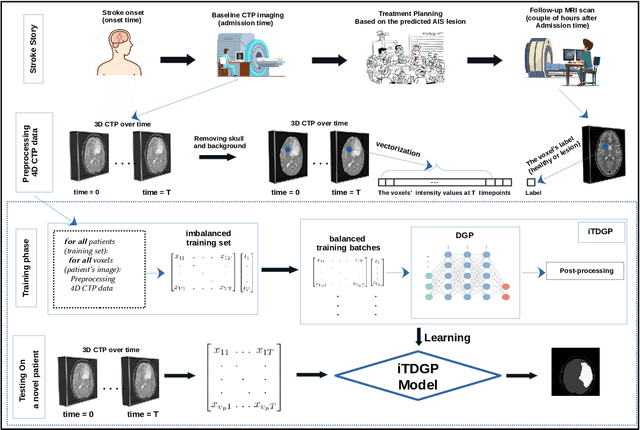
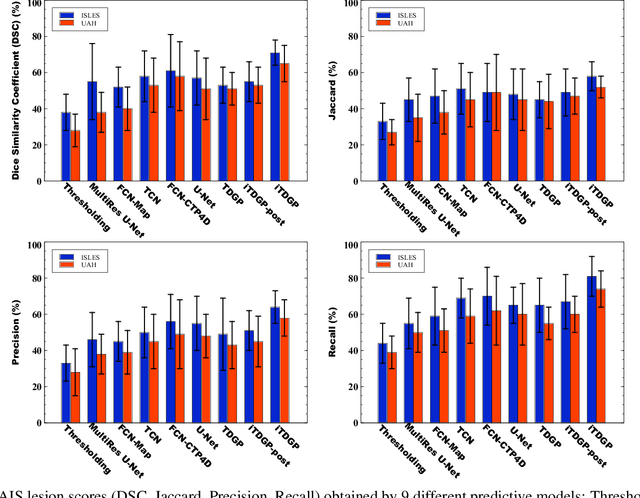
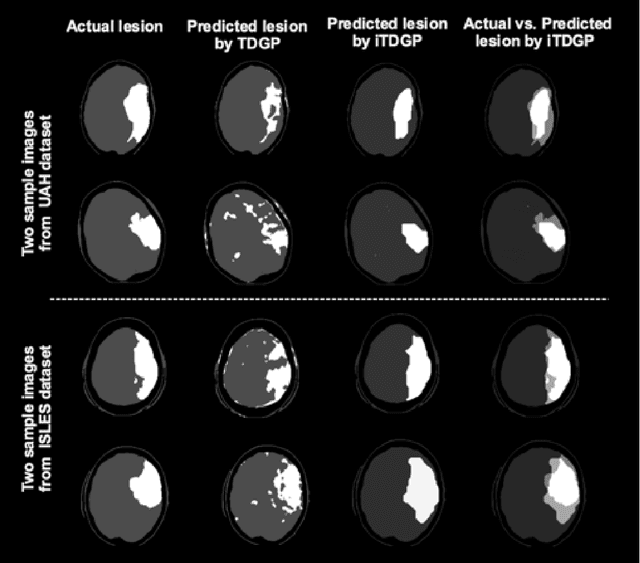
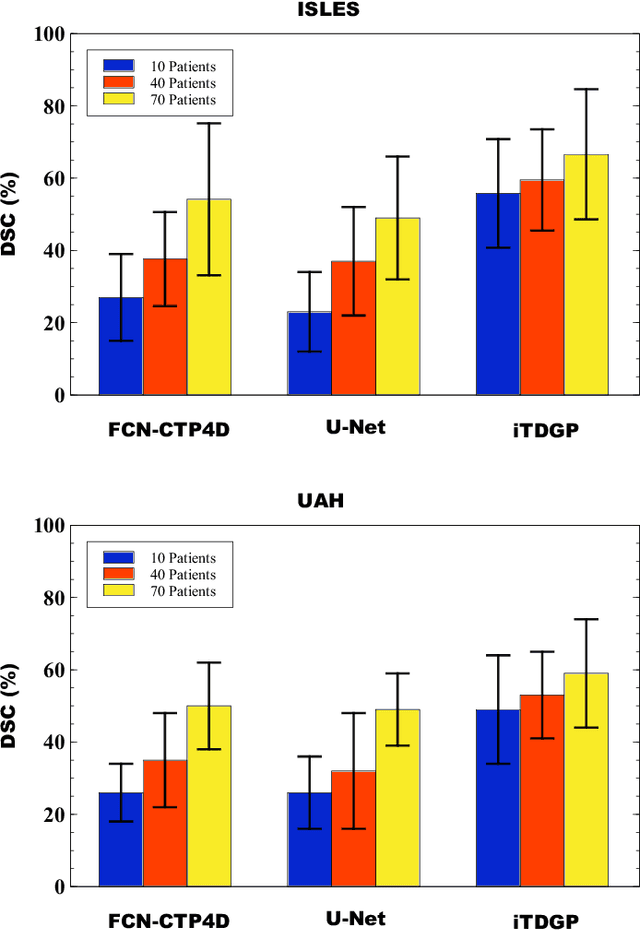
As one of the leading causes of mortality and disability worldwide, Acute Ischemic Stroke (AIS) occurs when the blood supply to the brain is suddenly interrupted because of a blocked artery. Within seconds of AIS onset, the brain cells surrounding the blocked artery die, which leads to the progression of the lesion. The automated and precise prediction of the existing lesion plays a vital role in the AIS treatment planning and prevention of further injuries. The current standard AIS assessment method, which thresholds the 3D measurement maps extracted from Computed Tomography Perfusion (CTP) images, is not accurate enough. Due to this fact, in this article, we propose the imbalanced Temporal Deep Gaussian Process (iTDGP), a probabilistic model that can improve AIS lesions prediction by using baseline CTP time series. Our proposed model can effectively extract temporal information from the CTP time series and map it to the class labels of the brain's voxels. In addition, by using batch training and voxel-level analysis iTDGP can learn from a few patients and it is robust against imbalanced classes. Moreover, our model incorporates a post-processor capable of improving prediction accuracy using spatial information. Our comprehensive experiments, on the ISLES 2018 and the University of Alberta Hospital (UAH) datasets, show that iTDGP performs better than state-of-the-art AIS lesion predictors, obtaining the (cross-validation) Dice score of 71.42% and 65.37% with a significant p<0.05, respectively.
Optimizing Stimulus Energy for Cochlear Implants with a Machine Learning Model of the Auditory Nerve
Nov 14, 2022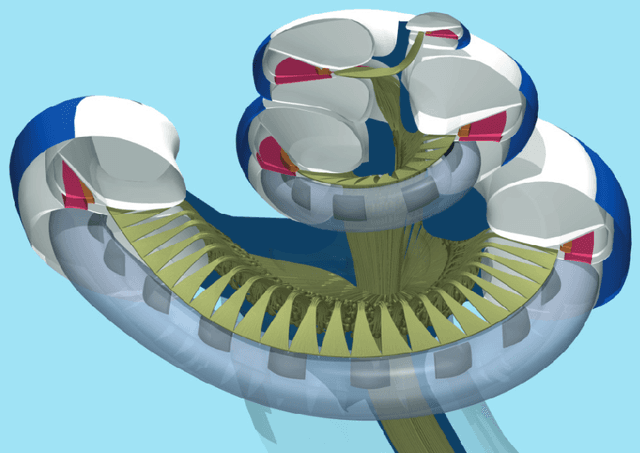
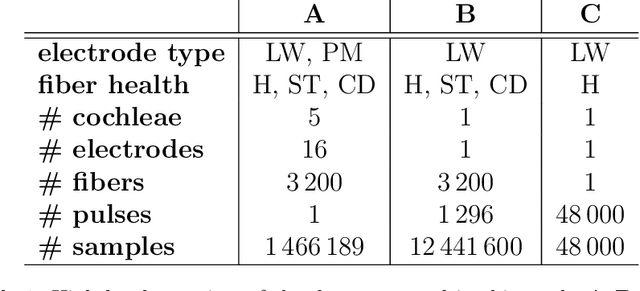
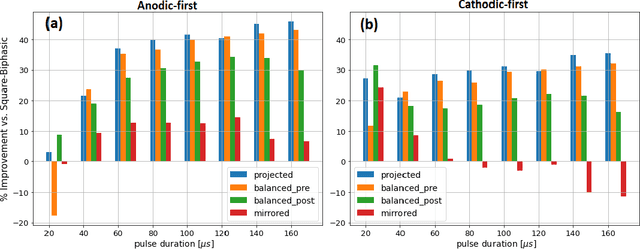
Performing simulations with a realistic biophysical auditory nerve fiber model can be very time consuming, due to the complex nature of the calculations involved. Here, a surrogate (approximate) model of such an auditory nerve fiber model was developed using machine learning methods, to perform simulations more efficiently. Several machine learning models were compared, of which a Convolutional Neural Network showed the best performance. In fact, the Convolutional Neural Network was able to emulate the behavior of the auditory nerve fiber model with extremely high similarity ($R^2 > 0.99$), tested under a wide range of experimental conditions, whilst reducing the simulation time by five orders of magnitude. In addition, we introduce a method for randomly generating charge-balanced waveforms using hyperplane projection. In the second part of this paper, the Convolutional Neural Network surrogate model was used by an Evolutionary Algorithm to optimize the shape of the stimulus waveform in terms energy efficiency. The resulting waveforms resemble a positive Gaussian-like peak, preceded by an elongated negative phase. When comparing the energy of the waveforms generated by the Evolutionary Algorithm with the commonly used square wave, energy decreases of 8% - 45% were observed for different pulse durations. These results were validated with the original auditory nerve fiber model, which demonstrates that our proposed surrogate model can be used as its accurate and efficient replacement.
From Points to Functions: Infinite-dimensional Representations in Diffusion Models
Oct 25, 2022
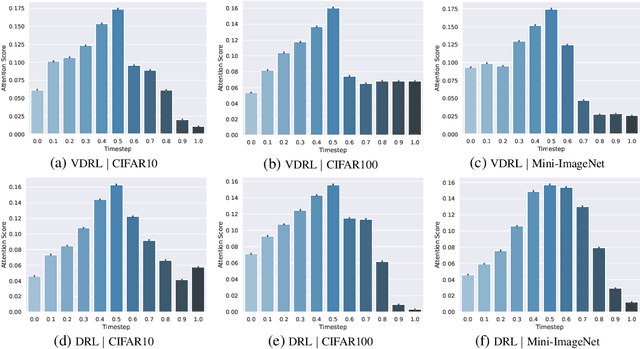
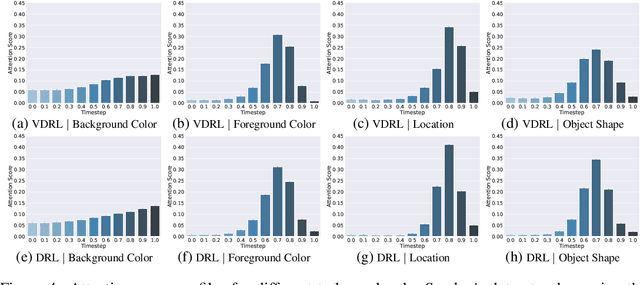
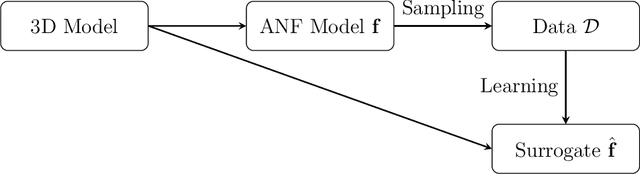
Diffusion-based generative models learn to iteratively transfer unstructured noise to a complex target distribution as opposed to Generative Adversarial Networks (GANs) or the decoder of Variational Autoencoders (VAEs) which produce samples from the target distribution in a single step. Thus, in diffusion models every sample is naturally connected to a random trajectory which is a solution to a learned stochastic differential equation (SDE). Generative models are only concerned with the final state of this trajectory that delivers samples from the desired distribution. Abstreiter et. al showed that these stochastic trajectories can be seen as continuous filters that wash out information along the way. Consequently, it is reasonable to ask if there is an intermediate time step at which the preserved information is optimal for a given downstream task. In this work, we show that a combination of information content from different time steps gives a strictly better representation for the downstream task. We introduce an attention and recurrence based modules that ``learn to mix'' information content of various time-steps such that the resultant representation leads to superior performance in downstream tasks.
Exploring Effects of Computational Parameter Changes to Image Recognition Systems
Nov 02, 2022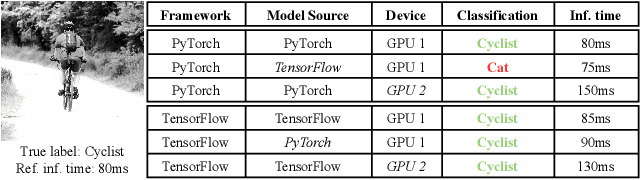
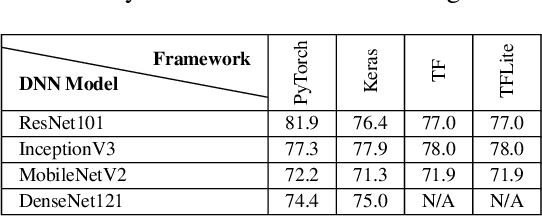
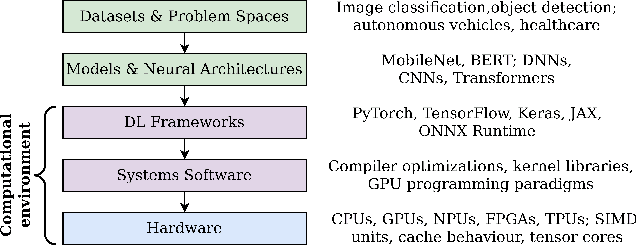
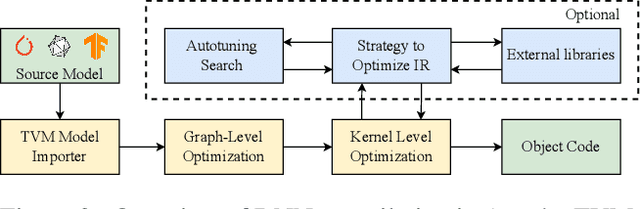
Image recognition tasks typically use deep learning and require enormous processing power, thus relying on hardware accelerators like GPUs and FPGAs for fast, timely processing. Failure in real-time image recognition tasks can occur due to incorrect mapping on hardware accelerators, which may lead to timing uncertainty and incorrect behavior. Owing to the increased use of image recognition tasks in safety-critical applications like autonomous driving and medical imaging, it is imperative to assess their robustness to changes in the computational environment as parameters like deep learning frameworks, compiler optimizations for code generation, and hardware devices are not regulated with varying impact on model performance and correctness. In this paper we conduct robustness analysis of four popular image recognition models (MobileNetV2, ResNet101V2, DenseNet121 and InceptionV3) with the ImageNet dataset, assessing the impact of the following parameters in the model's computational environment: (1) deep learning frameworks; (2) compiler optimizations; and (3) hardware devices. We report sensitivity of model performance in terms of output label and inference time for changes in each of these environment parameters. We find that output label predictions for all four models are sensitive to choice of deep learning framework (by up to 57%) and insensitive to other parameters. On the other hand, model inference time was affected by all environment parameters with changes in hardware device having the most effect. The extent of effect was not uniform across models.
Demo: LE3D: A Privacy-preserving Lightweight Data Drift Detection Framework
Nov 18, 2022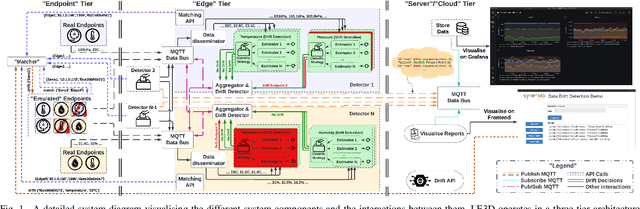
This paper presents LE3D; a novel data drift detection framework for preserving data integrity and confidentiality. LE3D is a generalisable platform for evaluating novel drift detection mechanisms within the Internet of Things (IoT) sensor deployments. Our framework operates in a distributed manner, preserving data privacy while still being adaptable to new sensors with minimal online reconfiguration. Our framework currently supports multiple drift estimators for time-series IoT data and can easily be extended to accommodate new data types and drift detection mechanisms. This demo will illustrate the functionality of LE3D under a real-world-like scenario.
Towards Similarity-Aware Time-Series Classification
Jan 06, 2022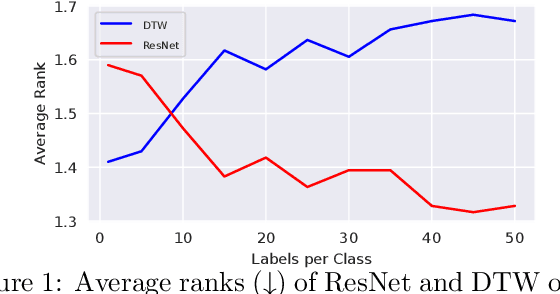

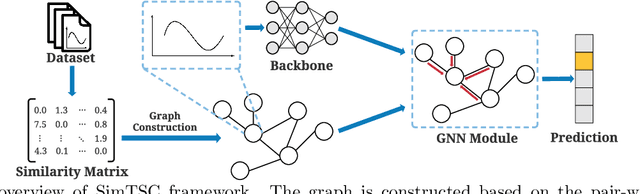
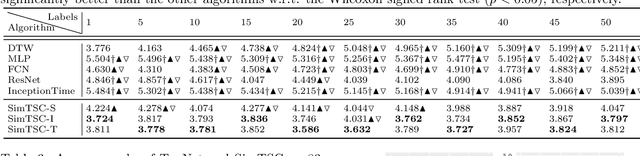
We study time-series classification (TSC), a fundamental task of time-series data mining. Prior work has approached TSC from two major directions: (1) similarity-based methods that classify time-series based on the nearest neighbors, and (2) deep learning models that directly learn the representations for classification in a data-driven manner. Motivated by the different working mechanisms within these two research lines, we aim to connect them in such a way as to jointly model time-series similarities and learn the representations. This is a challenging task because it is unclear how we should efficiently leverage similarity information. To tackle the challenge, we propose Similarity-Aware Time-Series Classification (SimTSC), a conceptually simple and general framework that models similarity information with graph neural networks (GNNs). Specifically, we formulate TSC as a node classification problem in graphs, where the nodes correspond to time-series, and the links correspond to pair-wise similarities. We further design a graph construction strategy and a batch training algorithm with negative sampling to improve training efficiency. We instantiate SimTSC with ResNet as the backbone and Dynamic Time Warping (DTW) as the similarity measure. Extensive experiments on the full UCR datasets and several multivariate datasets demonstrate the effectiveness of incorporating similarity information into deep learning models in both supervised and semi-supervised settings. Our code is available at https://github.com/daochenzha/SimTSC
Diffusion-based Generative Speech Source Separation
Nov 02, 2022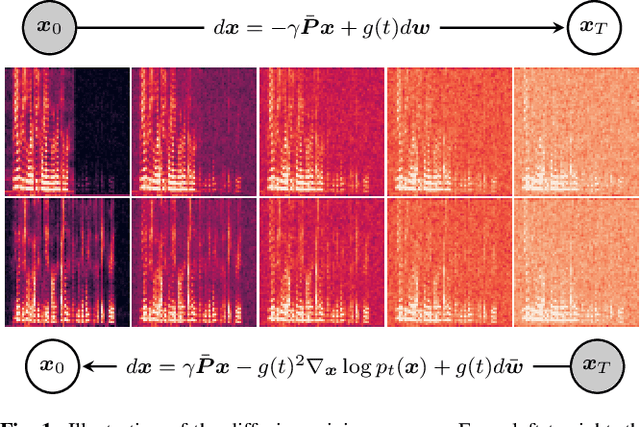
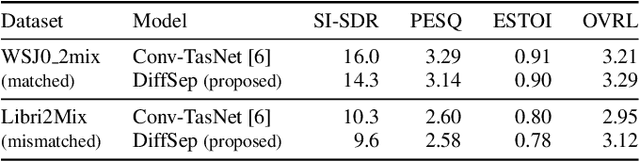
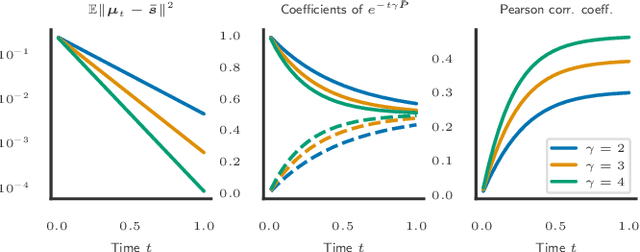
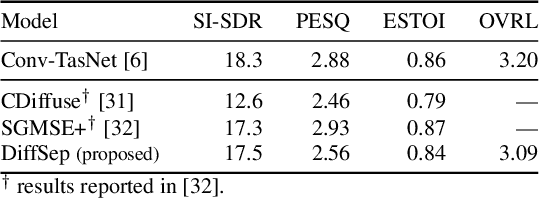
We propose DiffSep, a new single channel source separation method based on score-matching of a stochastic differential equation (SDE). We craft a tailored continuous time diffusion-mixing process starting from the separated sources and converging to a Gaussian distribution centered on their mixture. This formulation lets us apply the machinery of score-based generative modelling. First, we train a neural network to approximate the score function of the marginal probabilities or the diffusion-mixing process. Then, we use it to solve the reverse time SDE that progressively separates the sources starting from their mixture. We propose a modified training strategy to handle model mismatch and source permutation ambiguity. Experiments on the WSJ0 2mix dataset demonstrate the potential of the method. Furthermore, the method is also suitable for speech enhancement and shows performance competitive with prior work on the VoiceBank-DEMAND dataset.