 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning and Testing Latent-Tree Ising Models Efficiently
Nov 23, 2022
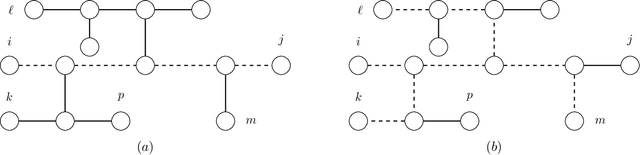
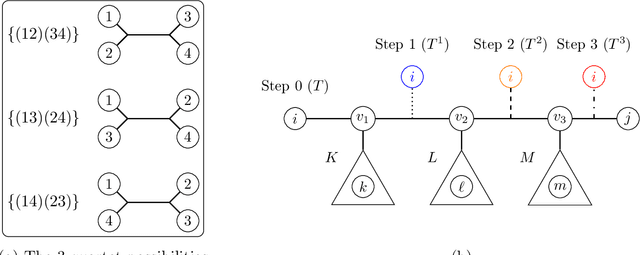
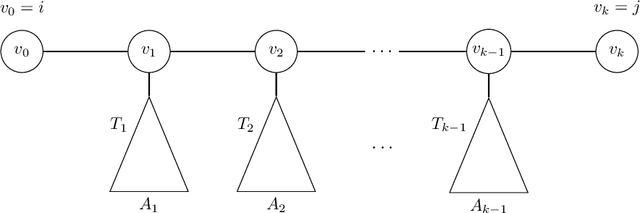
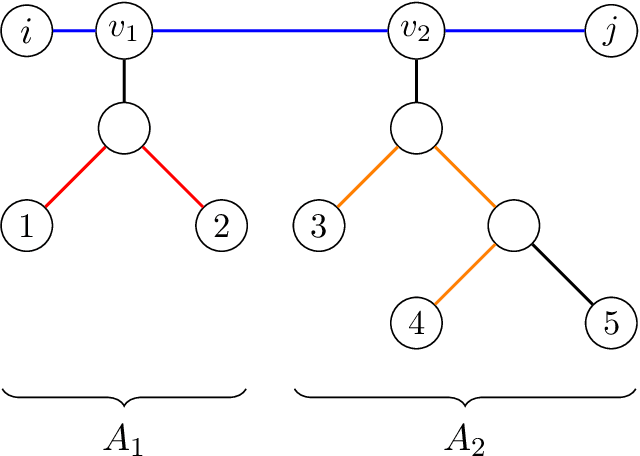
We provide time- and sample-efficient algorithms for learning and testing latent-tree Ising models, i.e. Ising models that may only be observed at their leaf nodes. On the learning side, we obtain efficient algorithms for learning a tree-structured Ising model whose leaf node distribution is close in Total Variation Distance, improving on the results of prior work. On the testing side, we provide an efficient algorithm with fewer samples for testing whether two latent-tree Ising models have leaf-node distributions that are close or far in Total Variation distance. We obtain our algorithms by showing novel localization results for the total variation distance between the leaf-node distributions of tree-structured Ising models, in terms of their marginals on pairs of leaves.
Faster Stochastic First-Order Method for Maximum-Likelihood Quantum State Tomography
Nov 23, 2022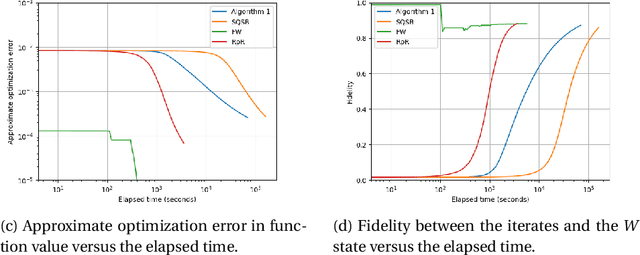
In maximum-likelihood quantum state tomography, both the sample size and dimension grow exponentially with the number of qubits. It is therefore desirable to develop a stochastic first-order method, just like stochastic gradient descent for modern machine learning, to compute the maximum-likelihood estimate. To this end, we propose an algorithm called stochastic mirror descent with the Burg entropy. Its expected optimization error vanishes at a $O ( \sqrt{ ( 1 / t ) d \log t } )$ rate, where $d$ and $t$ denote the dimension and number of iterations, respectively. Its per-iteration time complexity is $O ( d^3 )$, independent of the sample size. To the best of our knowledge, this is currently the computationally fastest stochastic first-order method for maximum-likelihood quantum state tomography.
SAITS: Self-Attention-based Imputation for Time Series
Feb 17, 2022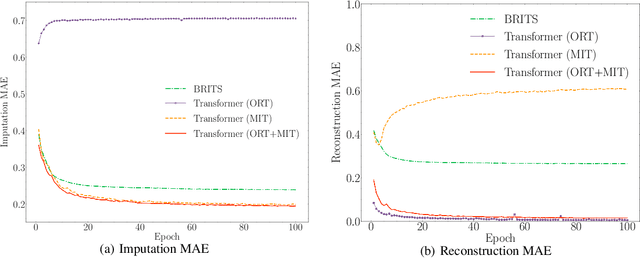
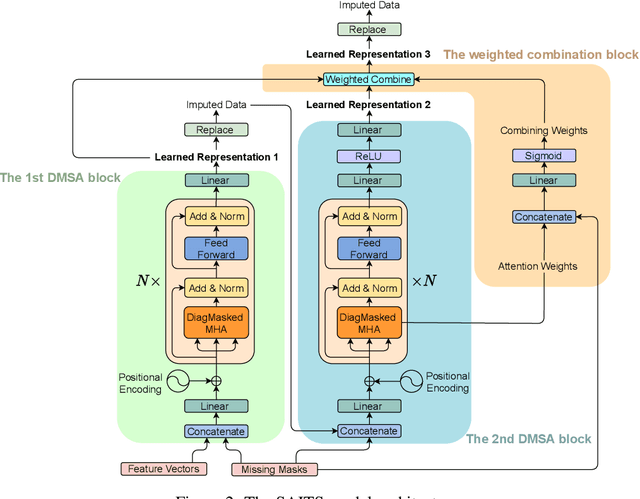
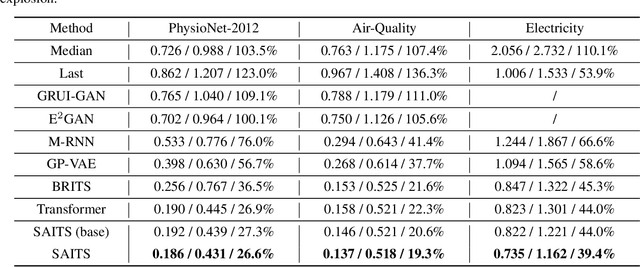
Missing data in time series is a pervasive problem that puts obstacles in the way of pattern recognition, especially in real-world applications. A popular solution is imputation, where the fundamental challenge is to determine what values should be filled in. This paper proposes SAITS, a novel method based on the self-attention mechanism for missing value imputation in multivariate time series. Trained by a joint-optimization approach, SAITS learns missing values from a weighted combination of two diagonally-masked self-attention (DMSA) blocks. DMSA explicitly captures both the temporal dependencies and feature correlations between time steps, which improves imputation accuracy and training speed. Meanwhile, the weighted-combination design enables SAITS to dynamically assign weights to the learned representations from two DMSA blocks according to the attention map and the missingness information. Extensive experiments demonstrate that SAITS outperforms the state-of-the-art methods on the time-series imputation task efficiently and reveal SAITS' potential to improve the learning performance of pattern recognition models on incomplete time-series data from the real world.
RSTT: Real-time Spatial Temporal Transformer for Space-Time Video Super-Resolution
Mar 27, 2022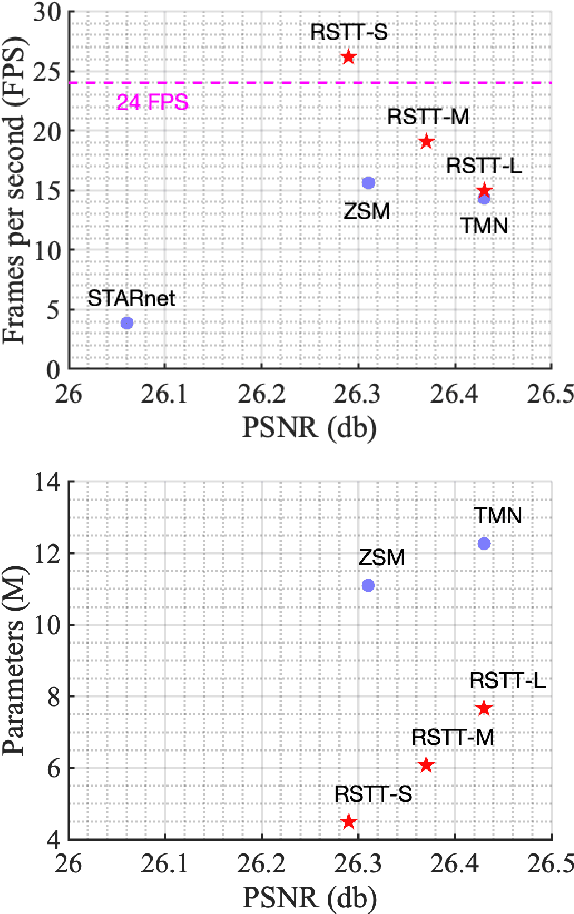
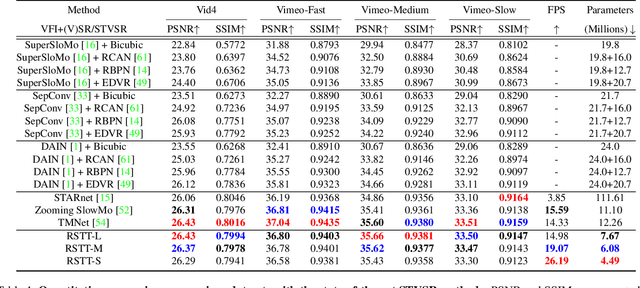
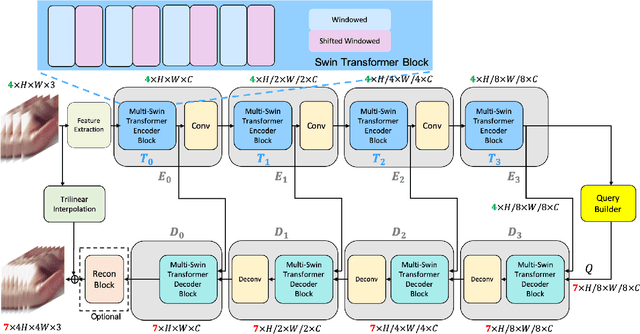

Space-time video super-resolution (STVSR) is the task of interpolating videos with both Low Frame Rate (LFR) and Low Resolution (LR) to produce High-Frame-Rate (HFR) and also High-Resolution (HR) counterparts. The existing methods based on Convolutional Neural Network~(CNN) succeed in achieving visually satisfied results while suffer from slow inference speed due to their heavy architectures. We propose to resolve this issue by using a spatial-temporal transformer that naturally incorporates the spatial and temporal super resolution modules into a single model. Unlike CNN-based methods, we do not explicitly use separated building blocks for temporal interpolations and spatial super-resolutions; instead, we only use a single end-to-end transformer architecture. Specifically, a reusable dictionary is built by encoders based on the input LFR and LR frames, which is then utilized in the decoder part to synthesize the HFR and HR frames. Compared with the state-of-the-art TMNet \cite{xu2021temporal}, our network is $60\%$ smaller (4.5M vs 12.3M parameters) and $80\%$ faster (26.2fps vs 14.3fps on $720\times576$ frames) without sacrificing much performance. The source code is available at https://github.com/llmpass/RSTT.
Exploring Effects of Computational Parameter Changes to Image Recognition Systems
Nov 02, 2022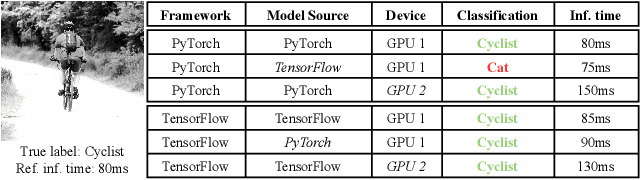
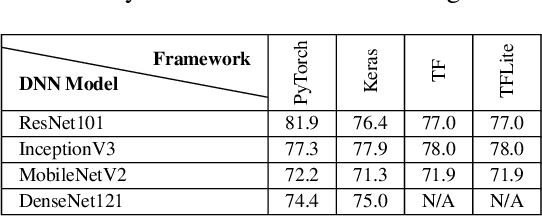
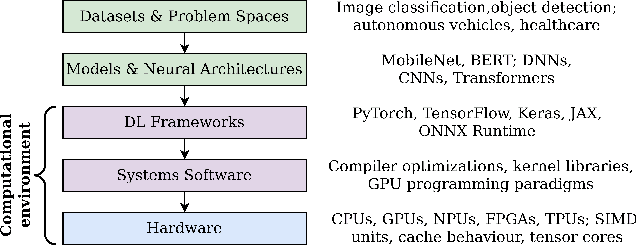
Image recognition tasks typically use deep learning and require enormous processing power, thus relying on hardware accelerators like GPUs and FPGAs for fast, timely processing. Failure in real-time image recognition tasks can occur due to incorrect mapping on hardware accelerators, which may lead to timing uncertainty and incorrect behavior. Owing to the increased use of image recognition tasks in safety-critical applications like autonomous driving and medical imaging, it is imperative to assess their robustness to changes in the computational environment as parameters like deep learning frameworks, compiler optimizations for code generation, and hardware devices are not regulated with varying impact on model performance and correctness. In this paper we conduct robustness analysis of four popular image recognition models (MobileNetV2, ResNet101V2, DenseNet121 and InceptionV3) with the ImageNet dataset, assessing the impact of the following parameters in the model's computational environment: (1) deep learning frameworks; (2) compiler optimizations; and (3) hardware devices. We report sensitivity of model performance in terms of output label and inference time for changes in each of these environment parameters. We find that output label predictions for all four models are sensitive to choice of deep learning framework (by up to 57%) and insensitive to other parameters. On the other hand, model inference time was affected by all environment parameters with changes in hardware device having the most effect. The extent of effect was not uniform across models.
Modeling Beats and Downbeats with a Time-Frequency Transformer
May 29, 2022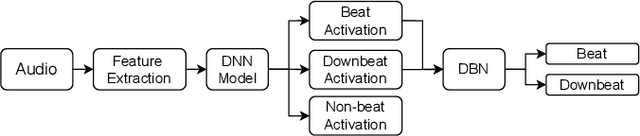
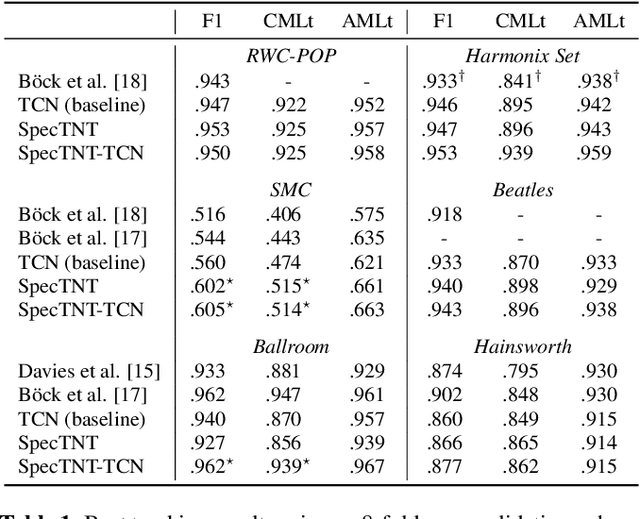
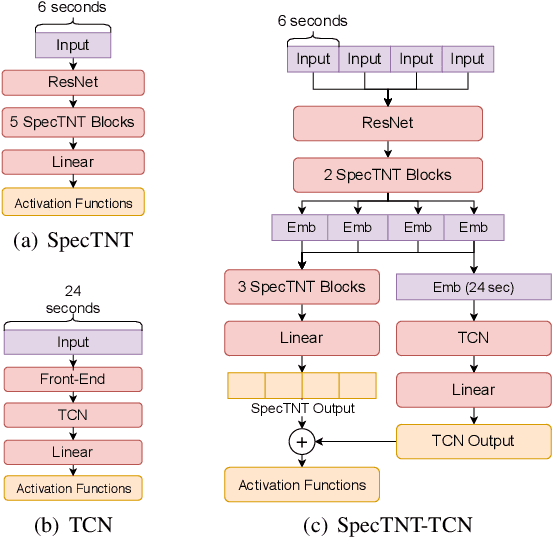
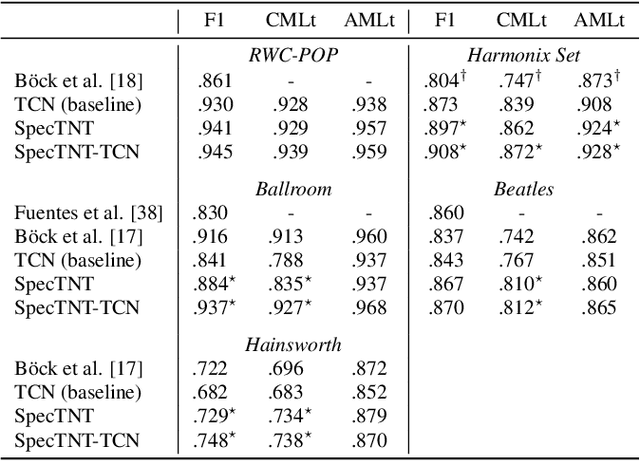
Transformer is a successful deep neural network (DNN) architecture that has shown its versatility not only in natural language processing but also in music information retrieval (MIR). In this paper, we present a novel Transformer-based approach to tackle beat and downbeat tracking. This approach employs SpecTNT (Spectral-Temporal Transformer in Transformer), a variant of Transformer that models both spectral and temporal dimensions of a time-frequency input of music audio. A SpecTNT model uses a stack of blocks, where each consists of two levels of Transformer encoders. The lower-level (or spectral) encoder handles the spectral features and enables the model to pay attention to harmonic components of each frame. Since downbeats indicate bar boundaries and are often accompanied by harmonic changes, this step may help downbeat modeling. The upper-level (or temporal) encoder aggregates useful local spectral information to pay attention to beat/downbeat positions. We also propose an architecture that combines SpecTNT with a state-of-the-art model, Temporal Convolutional Networks (TCN), to further improve the performance. Extensive experiments demonstrate that our approach can significantly outperform TCN in downbeat tracking while maintaining comparable result in beat tracking.
Approximation of nearly-periodic symplectic maps via structure-preserving neural networks
Oct 11, 2022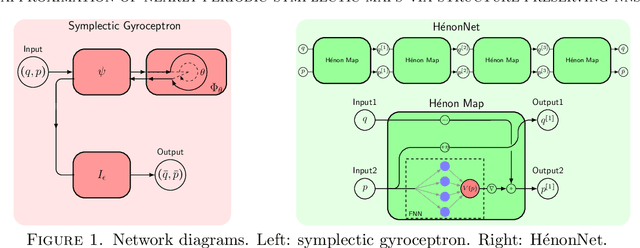
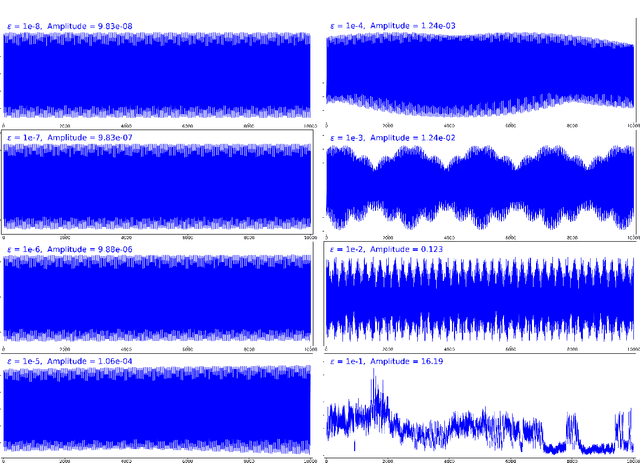
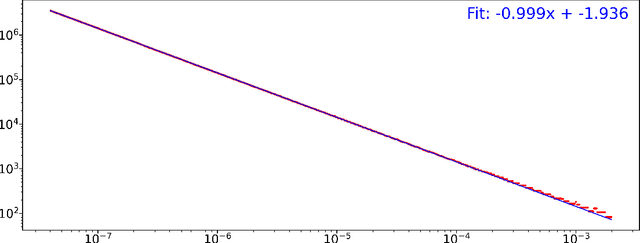
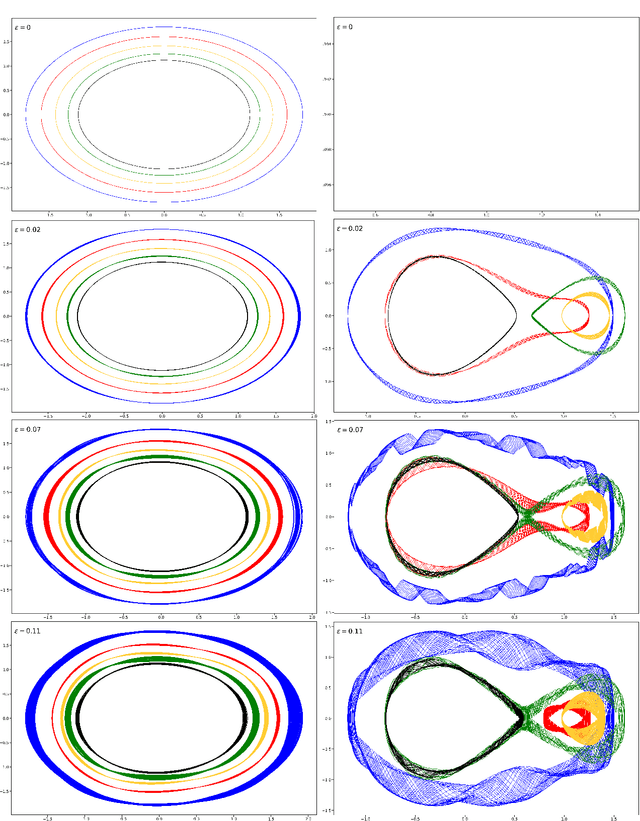
A continuous-time dynamical system with parameter $\varepsilon$ is nearly-periodic if all its trajectories are periodic with nowhere-vanishing angular frequency as $\varepsilon$ approaches 0. Nearly-periodic maps are discrete-time analogues of nearly-periodic systems, defined as parameter-dependent diffeomorphisms that limit to rotations along a circle action, and they admit formal $U(1)$ symmetries to all orders when the limiting rotation is non-resonant. For Hamiltonian nearly-periodic maps on exact presymplectic manifolds, the formal $U(1)$ symmetry gives rise to a discrete-time adiabatic invariant. In this paper, we construct a novel structure-preserving neural network to approximate nearly-periodic symplectic maps. This neural network architecture, which we call symplectic gyroceptron, ensures that the resulting surrogate map is nearly-periodic and symplectic, and that it gives rise to a discrete-time adiabatic invariant and a long-time stability. This new structure-preserving neural network provides a promising architecture for surrogate modeling of non-dissipative dynamical systems that automatically steps over short timescales without introducing spurious instabilities.
From Points to Functions: Infinite-dimensional Representations in Diffusion Models
Oct 25, 2022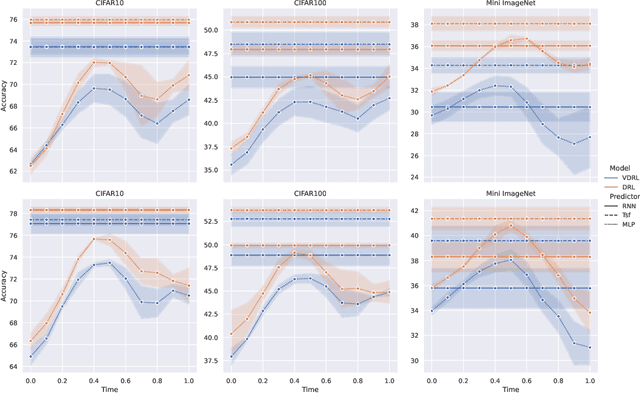
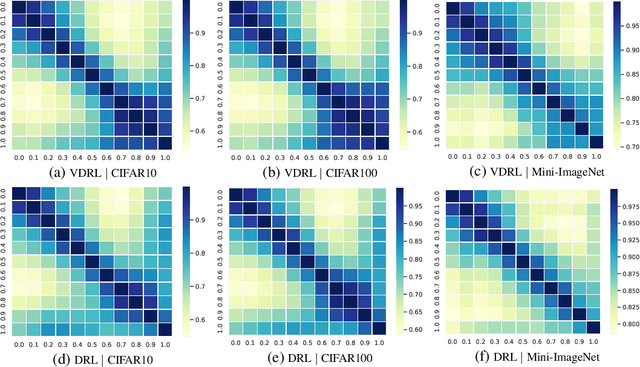
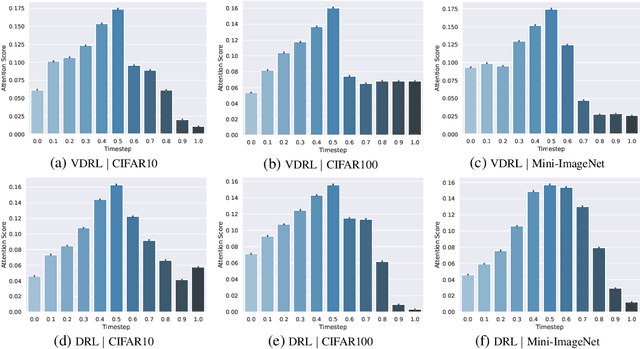
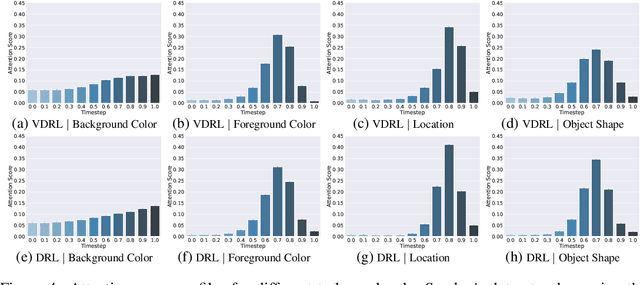
Diffusion-based generative models learn to iteratively transfer unstructured noise to a complex target distribution as opposed to Generative Adversarial Networks (GANs) or the decoder of Variational Autoencoders (VAEs) which produce samples from the target distribution in a single step. Thus, in diffusion models every sample is naturally connected to a random trajectory which is a solution to a learned stochastic differential equation (SDE). Generative models are only concerned with the final state of this trajectory that delivers samples from the desired distribution. Abstreiter et. al showed that these stochastic trajectories can be seen as continuous filters that wash out information along the way. Consequently, it is reasonable to ask if there is an intermediate time step at which the preserved information is optimal for a given downstream task. In this work, we show that a combination of information content from different time steps gives a strictly better representation for the downstream task. We introduce an attention and recurrence based modules that ``learn to mix'' information content of various time-steps such that the resultant representation leads to superior performance in downstream tasks.
Diffusion-based Generative Speech Source Separation
Nov 02, 2022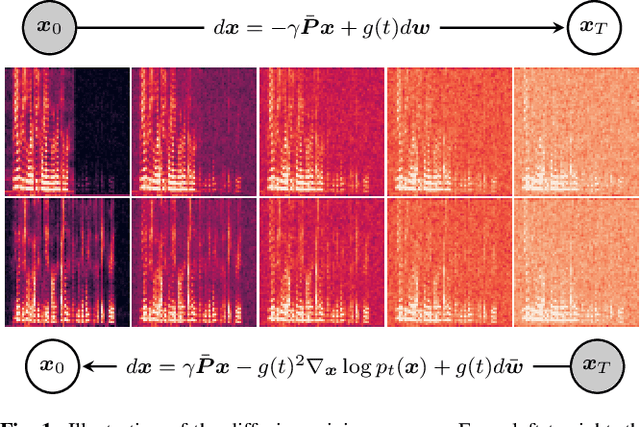
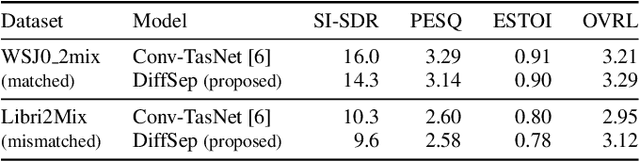
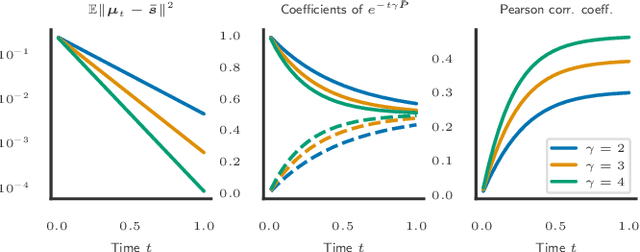
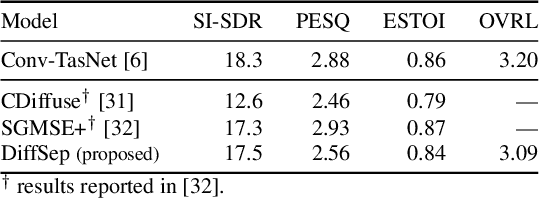
We propose DiffSep, a new single channel source separation method based on score-matching of a stochastic differential equation (SDE). We craft a tailored continuous time diffusion-mixing process starting from the separated sources and converging to a Gaussian distribution centered on their mixture. This formulation lets us apply the machinery of score-based generative modelling. First, we train a neural network to approximate the score function of the marginal probabilities or the diffusion-mixing process. Then, we use it to solve the reverse time SDE that progressively separates the sources starting from their mixture. We propose a modified training strategy to handle model mismatch and source permutation ambiguity. Experiments on the WSJ0 2mix dataset demonstrate the potential of the method. Furthermore, the method is also suitable for speech enhancement and shows performance competitive with prior work on the VoiceBank-DEMAND dataset.
THMA: Tencent HD Map AI System for Creating HD Map Annotations
Dec 14, 2022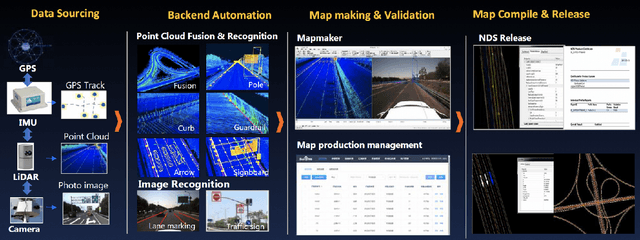
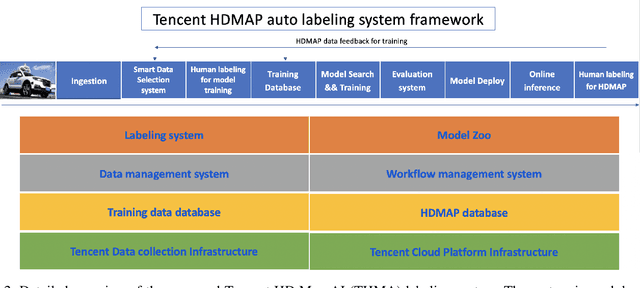

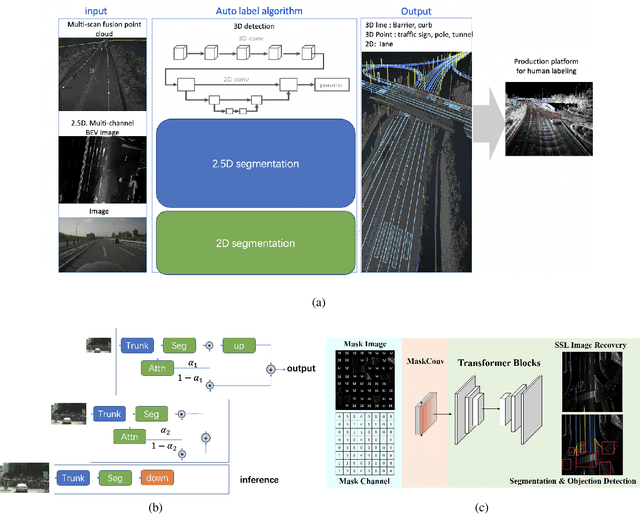
Nowadays, autonomous vehicle technology is becoming more and more mature. Critical to progress and safety, high-definition (HD) maps, a type of centimeter-level map collected using a laser sensor, provide accurate descriptions of the surrounding environment. The key challenge of HD map production is efficient, high-quality collection and annotation of large-volume datasets. Due to the demand for high quality, HD map production requires significant manual human effort to create annotations, a very time-consuming and costly process for the map industry. In order to reduce manual annotation burdens, many artificial intelligence (AI) algorithms have been developed to pre-label the HD maps. However, there still exists a large gap between AI algorithms and the traditional manual HD map production pipelines in accuracy and robustness. Furthermore, it is also very resource-costly to build large-scale annotated datasets and advanced machine learning algorithms for AI-based HD map automatic labeling systems. In this paper, we introduce the Tencent HD Map AI (THMA) system, an innovative end-to-end, AI-based, active learning HD map labeling system capable of producing and labeling HD maps with a scale of hundreds of thousands of kilometers. In THMA, we train AI models directly from massive HD map datasets via supervised, self-supervised, and weakly supervised learning to achieve high accuracy and efficiency required by downstream users. THMA has been deployed by the Tencent Map team to provide services to downstream companies and users, serving over 1,000 labeling workers and producing more than 30,000 kilometers of HD map data per day at most. More than 90 percent of the HD map data in Tencent Map is labeled automatically by THMA, accelerating the traditional HD map labeling process by more than ten times.