 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AdsorbML: Accelerating Adsorption Energy Calculations with Machine Learning
Nov 29, 2022
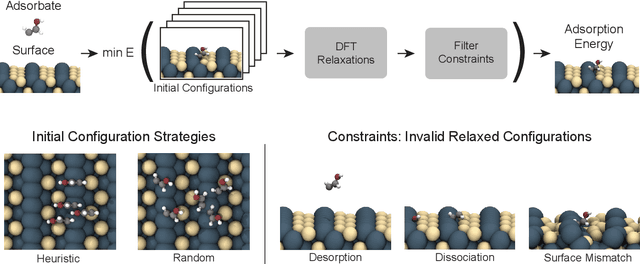
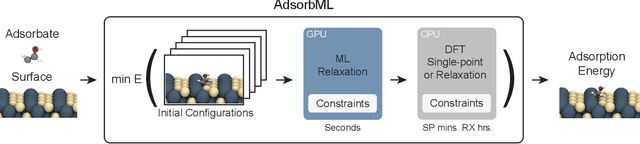
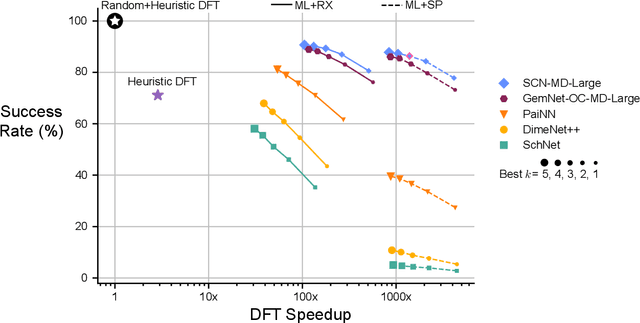
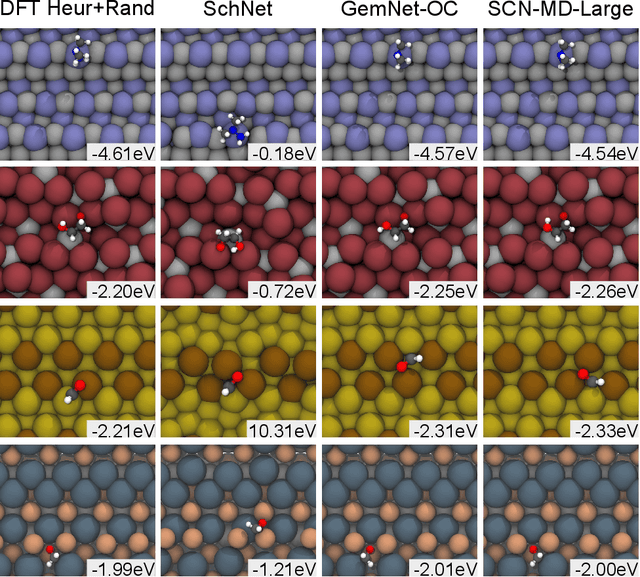
Computational catalysis is playing an increasingly significant role in the design of catalysts across a wide range of applications. A common task for many computational methods is the need to accurately compute the minimum binding energy - the adsorption energy - for an adsorbate and a catalyst surface of interest. Traditionally, the identification of low energy adsorbate-surface configurations relies on heuristic methods and researcher intuition. As the desire to perform high-throughput screening increases, it becomes challenging to use heuristics and intuition alone. In this paper, we demonstrate machine learning potentials can be leveraged to identify low energy adsorbate-surface configurations more accurately and efficiently. Our algorithm provides a spectrum of trade-offs between accuracy and efficiency, with one balanced option finding the lowest energy configuration, within a 0.1 eV threshold, 86.63% of the time, while achieving a 1387x speedup in computation. To standardize benchmarking, we introduce the Open Catalyst Dense dataset containing nearly 1,000 diverse surfaces and 87,045 unique configurations.
SparsePose: Sparse-View Camera Pose Regression and Refinement
Nov 29, 2022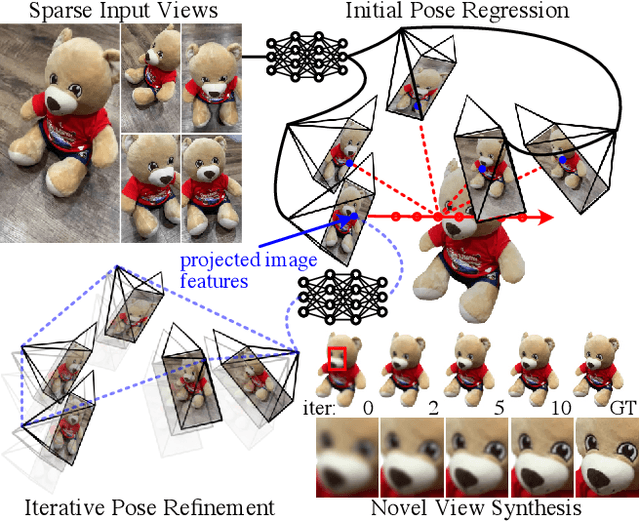
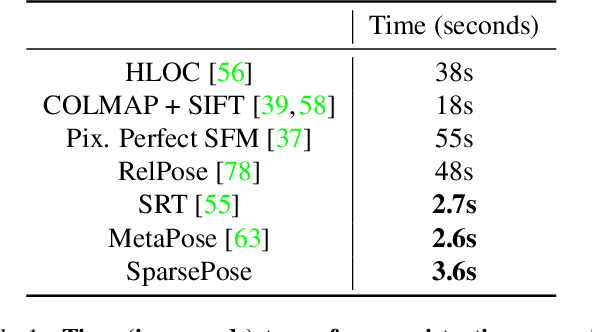
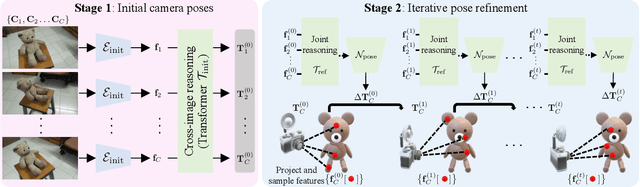
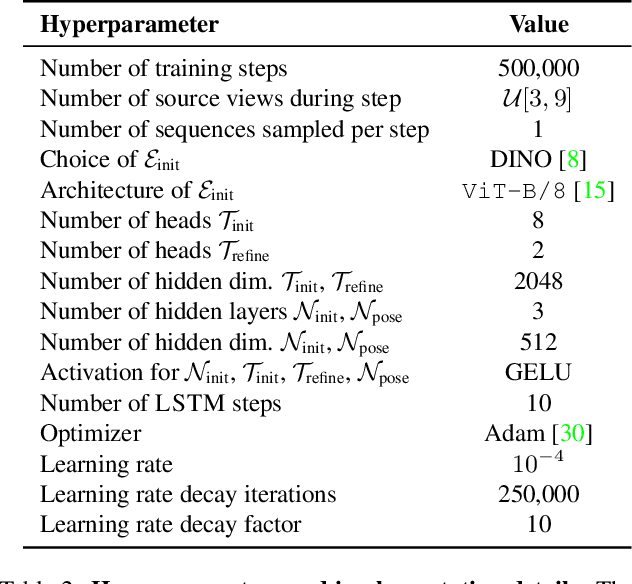
Camera pose estimation is a key step in standard 3D reconstruction pipelines that operate on a dense set of images of a single object or scene. However, methods for pose estimation often fail when only a few images are available because they rely on the ability to robustly identify and match visual features between image pairs. While these methods can work robustly with dense camera views, capturing a large set of images can be time-consuming or impractical. We propose SparsePose for recovering accurate camera poses given a sparse set of wide-baseline images (fewer than 10). The method learns to regress initial camera poses and then iteratively refine them after training on a large-scale dataset of objects (Co3D: Common Objects in 3D). SparsePose significantly outperforms conventional and learning-based baselines in recovering accurate camera rotations and translations. We also demonstrate our pipeline for high-fidelity 3D reconstruction using only 5-9 images of an object.
Neural Transducer Training: Reduced Memory Consumption with Sample-wise Computation
Nov 29, 2022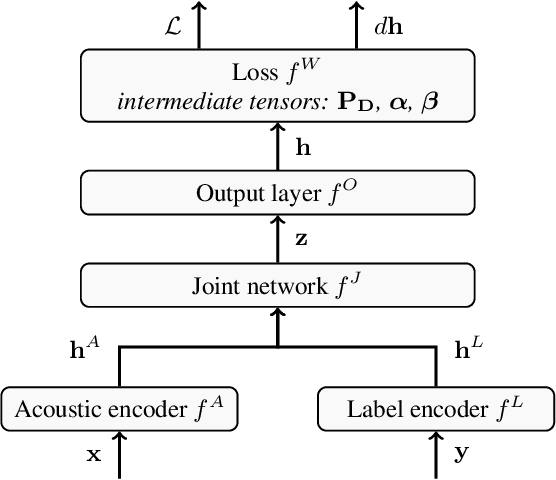

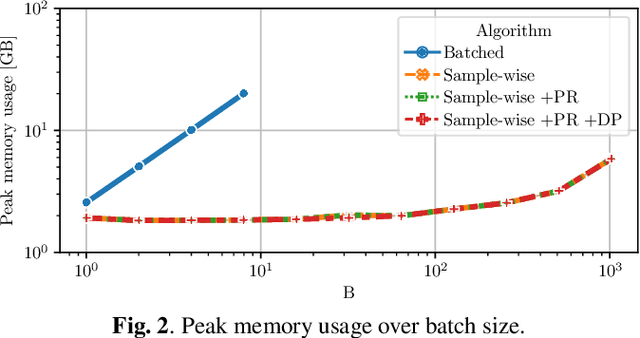
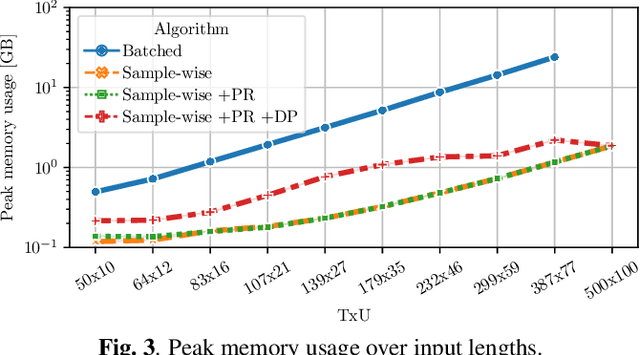
The neural transducer is an end-to-end model for automatic speech recognition (ASR). While the model is well-suited for streaming ASR, the training process remains challenging. During training, the memory requirements may quickly exceed the capacity of state-of-the-art GPUs, limiting batch size and sequence lengths. In this work, we analyze the time and space complexity of a typical transducer training setup. We propose a memory-efficient training method that computes the transducer loss and gradients sample by sample. We present optimizations to increase the efficiency and parallelism of the sample-wise method. In a set of thorough benchmarks, we show that our sample-wise method significantly reduces memory usage, and performs at competitive speed when compared to the default batched computation. As a highlight, we manage to compute the transducer loss and gradients for a batch size of 1024, and audio length of 40 seconds, using only 6 GB of memory.
Encoder-Decoder Model for Suffix Prediction in Predictive Monitoring
Nov 29, 2022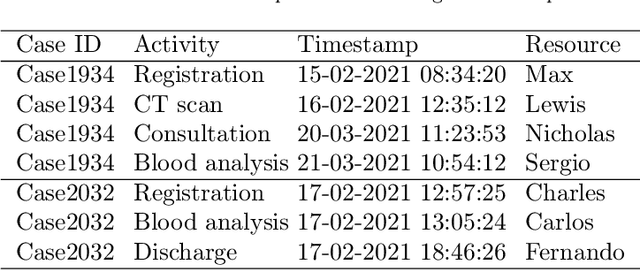
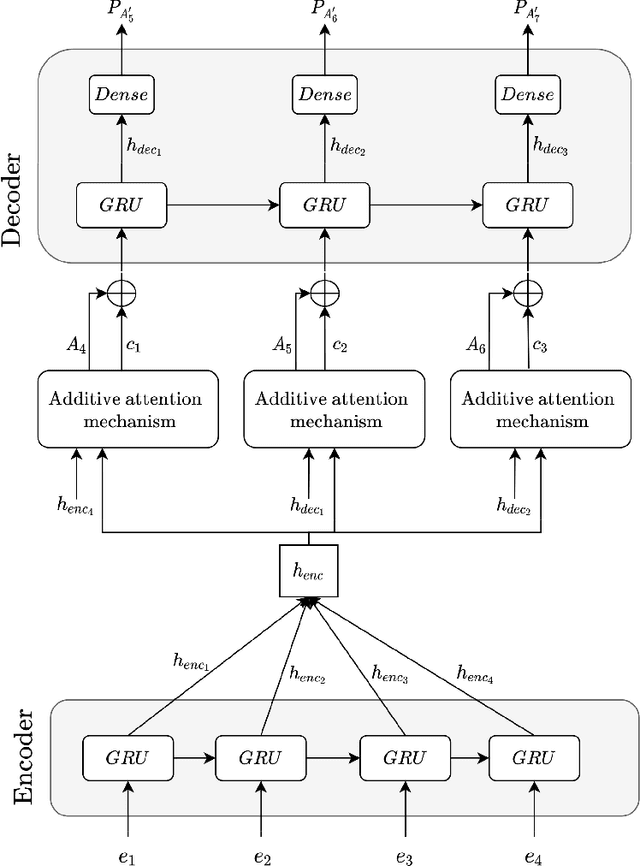

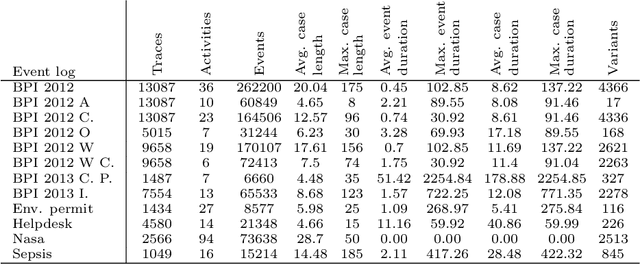
Predictive monitoring is a subfield of process mining that aims to predict how a running case will unfold in the future. One of its main challenges is forecasting the sequence of activities that will occur from a given point in time -- suffix prediction -- . Most approaches to the suffix prediction problem learn to predict the suffix by learning how to predict the next activity only, not learning from the whole suffix during the training phase. This paper proposes a novel architecture based on an encoder-decoder model with an attention mechanism that decouples the representation learning of the prefixes from the inference phase, predicting only the activities of the suffix. During the inference phase, this architecture is extended with a heuristic search algorithm that improves the selection of the activity for each index of the suffix. Our approach has been tested using 12 public event logs against 6 different state-of-the-art proposals, showing that it significantly outperforms these proposals.
Triadic Temporal Exponential Random Graph Models (TTERGM)
Nov 29, 2022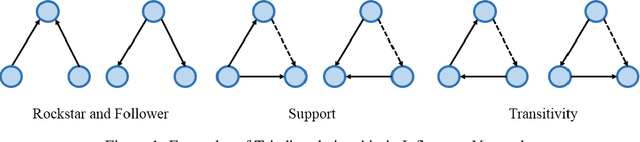
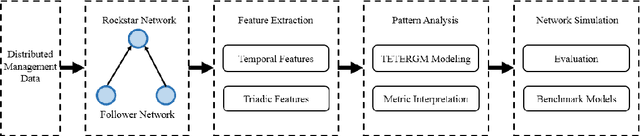
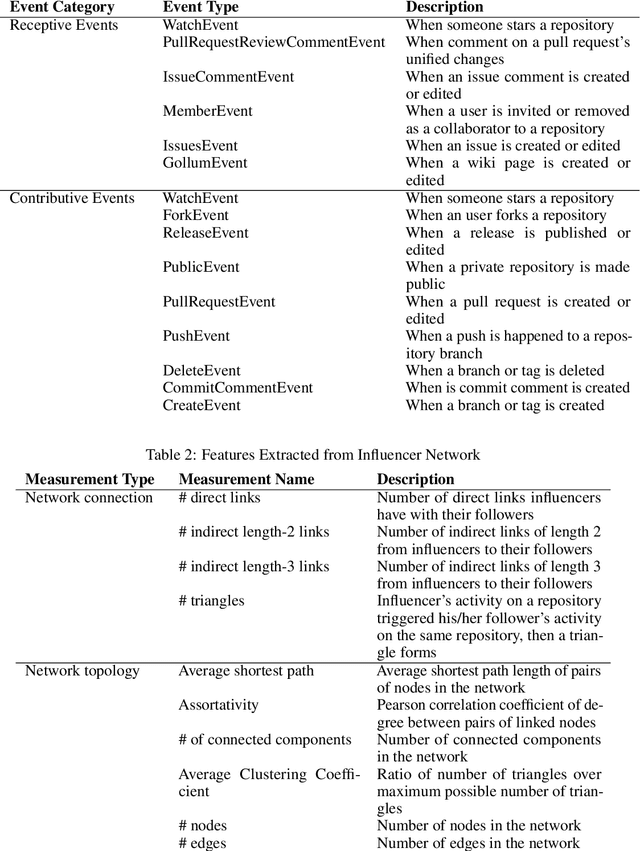

Temporal exponential random graph models (TERGM) are powerful statistical models that can be used to infer the temporal pattern of edge formation and elimination in complex networks (e.g., social networks). TERGMs can also be used in a generative capacity to predict longitudinal time series data in these evolving graphs. However, parameter estimation within this framework fails to capture many real-world properties of social networks, including: triadic relationships, small world characteristics, and social learning theories which could be used to constrain the probabilistic estimation of dyadic covariates. Here, we propose triadic temporal exponential random graph models (TTERGM) to fill this void, which includes these hierarchical network relationships within the graph model. We represent social network learning theory as an additional probability distribution that optimizes Markov chains in the graph vector space. The new parameters are then approximated via Monte Carlo maximum likelihood estimation. We show that our TTERGM model achieves improved fidelity and more accurate predictions compared to several benchmark methods on GitHub network data.
Optimizing Stock Option Forecasting with the Assembly of Machine Learning Models and Improved Trading Strategies
Nov 29, 2022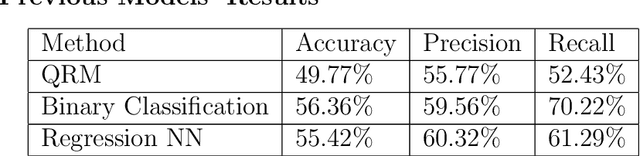

This paper introduced key aspects of applying Machine Learning (ML) models, improved trading strategies, and the Quasi-Reversibility Method (QRM) to optimize stock option forecasting and trading results. It presented the findings of the follow-up project of the research "Application of Convolutional Neural Networks with Quasi-Reversibility Method Results for Option Forecasting". First, the project included an application of Recurrent Neural Networks (RNN) and Long Short-Term Memory (LSTM) networks to provide a novel way of predicting stock option trends. Additionally, it examined the dependence of the ML models by evaluating the experimental method of combining multiple ML models to improve prediction results and decision-making. Lastly, two improved trading strategies and simulated investing results were presented. The Binomial Asset Pricing Model with discrete time stochastic process analysis and portfolio hedging was applied and suggested an optimized investment expectation. These results can be utilized in real-life trading strategies to optimize stock option investment results based on historical data.
Evaluating and reducing the distance between synthetic and real speech distributions
Nov 29, 2022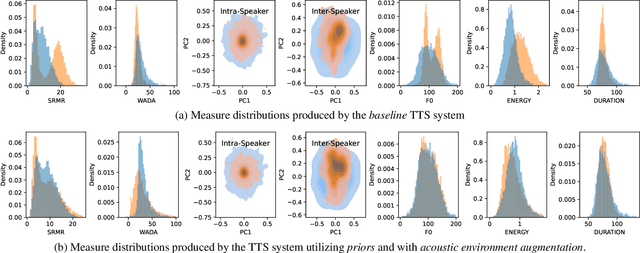
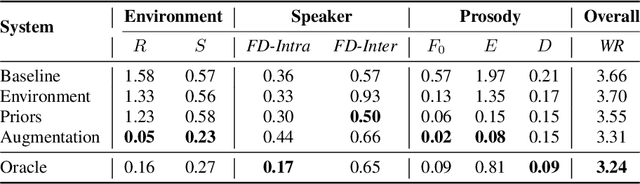
While modern Text-to-Speech (TTS) systems can produce speech rated highly in terms of subjective evaluation, the distance between real and synthetic speech distributions remains understudied, where we use the term \textit{distribution} to mean the sample space of all possible real speech recordings from a given set of speakers; or of the synthetic samples that could be generated for the same set of speakers. We evaluate the distance of real and synthetic speech distributions along the dimensions of the acoustic environment, speaker characteristics and prosody using a range of speech processing measures and the respective Wasserstein distances of their distributions. We reduce these distribution distances along said dimensions by providing utterance-level information derived from the measures to the model and show they can be generated at inference time. The improvements to the dimensions translate to overall distribution distance reduction approximated using Automatic Speech Recognition (ASR) by evaluating the fitness of the synthetic data as training data.
Design Space Exploration and Explanation via Conditional Variational Autoencoders in Meta-model-based Conceptual Design of Pedestrian Bridges
Nov 29, 2022
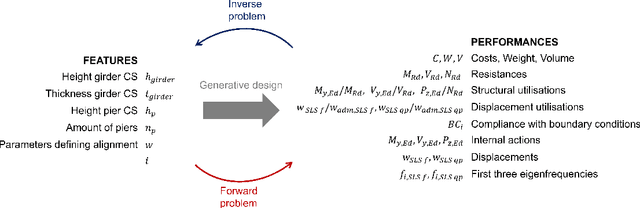
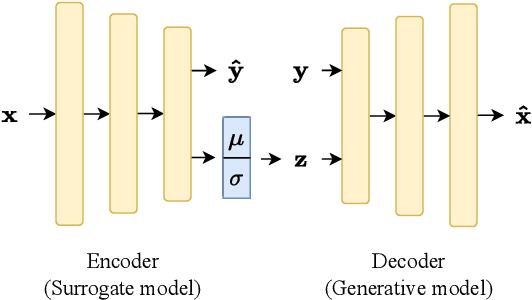
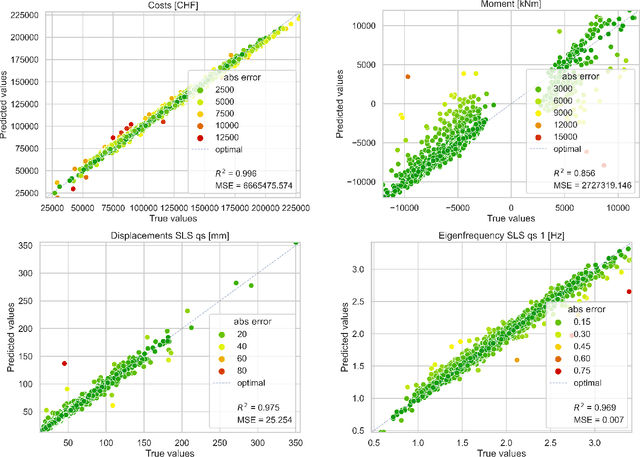
For conceptual design, engineers rely on conventional iterative (often manual) techniques. Emerging parametric models facilitate design space exploration based on quantifiable performance metrics, yet remain time-consuming and computationally expensive. Pure optimisation methods, however, ignore qualitative aspects (e.g. aesthetics or construction methods). This paper provides a performance-driven design exploration framework to augment the human designer through a Conditional Variational Autoencoder (CVAE), which serves as forward performance predictor for given design features as well as an inverse design feature predictor conditioned on a set of performance requests. The CVAE is trained on 18'000 synthetically generated instances of a pedestrian bridge in Switzerland. Sensitivity analysis is employed for explainability and informing designers about (i) relations of the model between features and/or performances and (ii) structural improvements under user-defined objectives. A case study proved our framework's potential to serve as a future co-pilot for conceptual design studies of pedestrian bridges and beyond.
Penalised FTRL With Time-Varying Constraints
Apr 06, 2022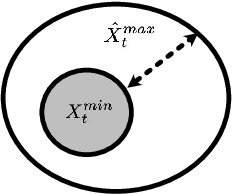
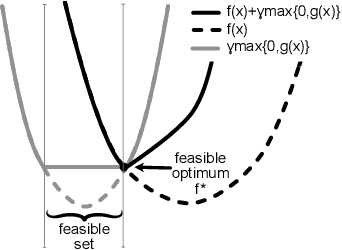
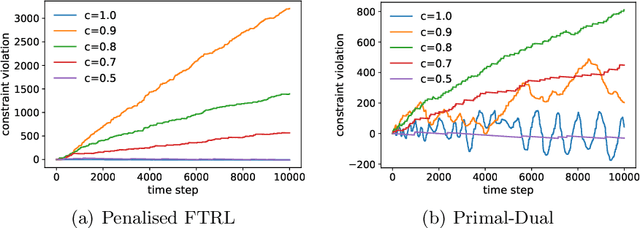
In this paper we extend the classical Follow-The-Regularized-Leader (FTRL) algorithm to encompass time-varying constraints, through adaptive penalization. We establish sufficient conditions for the proposed Penalized FTRL algorithm to achieve $O(\sqrt{t})$ regret and violation with respect to strong benchmark $\hat{X}^{max}_t$. Lacking prior knowledge of the constraints, this is probably the largest benchmark set that we can reasonably hope for. Our sufficient conditions are necessary in the sense that when they are violated there exist examples where $O(\sqrt{t})$ regret and violation is not achieved. Compared to the best existing primal-dual algorithms, Penalized FTRL substantially extends the class of problems for which $O(\sqrt{t})$ regret and violation performance is achievable.
HYDRA: Competing convolutional kernels for fast and accurate time series classification
Mar 25, 2022
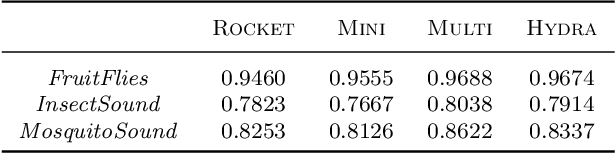
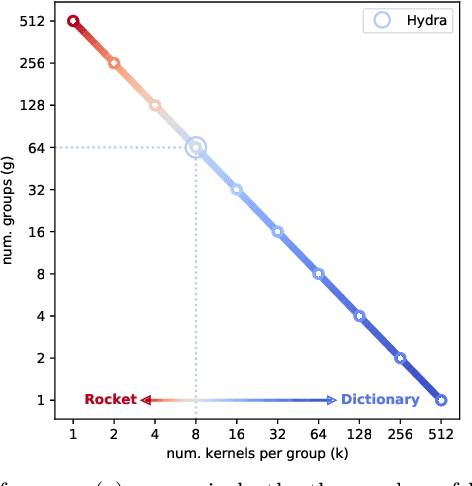
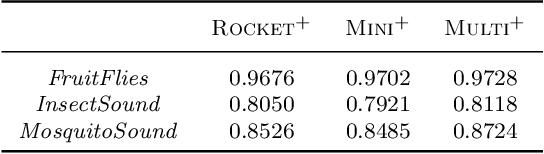
We demonstrate a simple connection between dictionary methods for time series classification, which involve extracting and counting symbolic patterns in time series, and methods based on transforming input time series using convolutional kernels, namely ROCKET and its variants. We show that by adjusting a single hyperparameter it is possible to move by degrees between models resembling dictionary methods and models resembling ROCKET. We present HYDRA, a simple, fast, and accurate dictionary method for time series classification using competing convolutional kernels, combining key aspects of both ROCKET and conventional dictionary methods. HYDRA is faster and more accurate than the most accurate existing dictionary methods, and can be combined with ROCKET and its variants to further improve the accuracy of these methods.