 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pangu-Weather: A 3D High-Resolution Model for Fast and Accurate Global Weather Forecast
Nov 03, 2022
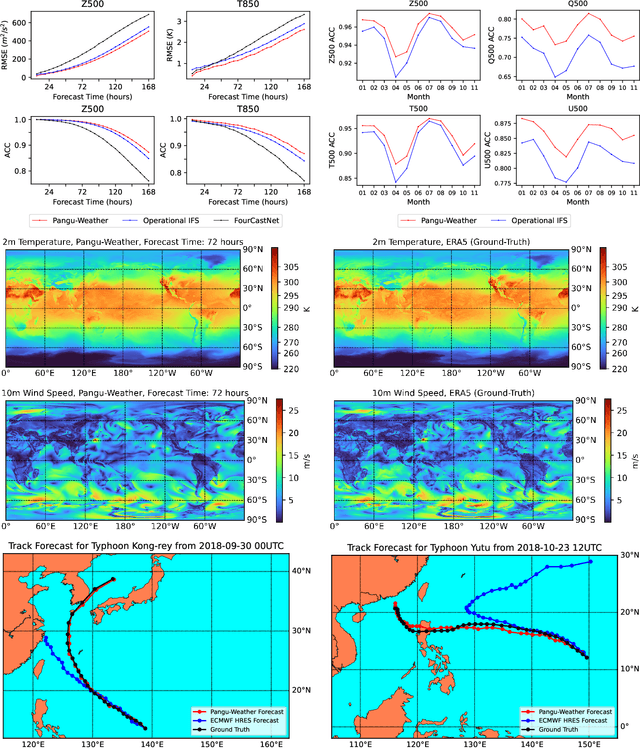
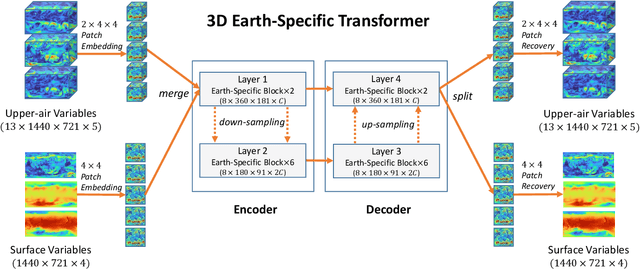
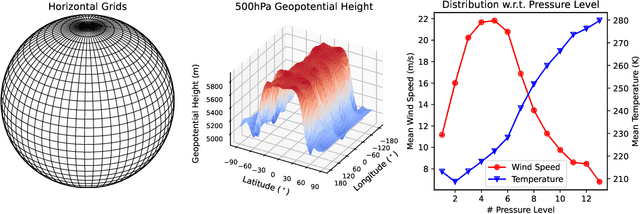
In this paper, we present Pangu-Weather, a deep learning based system for fast and accurate global weather forecast. For this purpose, we establish a data-driven environment by downloading $43$ years of hourly global weather data from the 5th generation of ECMWF reanalysis (ERA5) data and train a few deep neural networks with about $256$ million parameters in total. The spatial resolution of forecast is $0.25^\circ\times0.25^\circ$, comparable to the ECMWF Integrated Forecast Systems (IFS). More importantly, for the first time, an AI-based method outperforms state-of-the-art numerical weather prediction (NWP) methods in terms of accuracy (latitude-weighted RMSE and ACC) of all factors (e.g., geopotential, specific humidity, wind speed, temperature, etc.) and in all time ranges (from one hour to one week). There are two key strategies to improve the prediction accuracy: (i) designing a 3D Earth Specific Transformer (3DEST) architecture that formulates the height (pressure level) information into cubic data, and (ii) applying a hierarchical temporal aggregation algorithm to alleviate cumulative forecast errors. In deterministic forecast, Pangu-Weather shows great advantages for short to medium-range forecast (i.e., forecast time ranges from one hour to one week). Pangu-Weather supports a wide range of downstream forecast scenarios, including extreme weather forecast (e.g., tropical cyclone tracking) and large-member ensemble forecast in real-time. Pangu-Weather not only ends the debate on whether AI-based methods can surpass conventional NWP methods, but also reveals novel directions for improving deep learning weather forecast systems.
Monitoring Time Series With Missing Values: a Deep Probabilistic Approach
Mar 09, 2022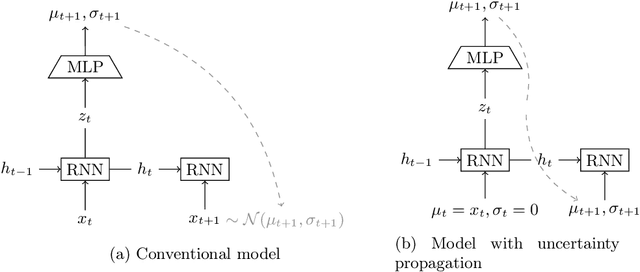
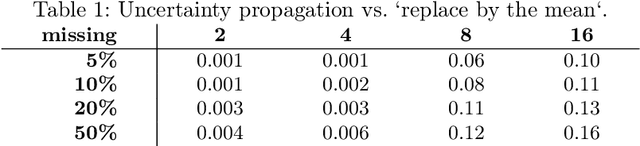

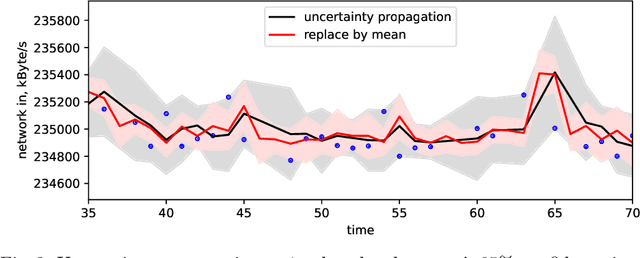
Systems are commonly monitored for health and security through collection and streaming of multivariate time series. Advances in time series forecasting due to adoption of multilayer recurrent neural network architectures make it possible to forecast in high-dimensional time series, and identify and classify novelties early, based on subtle changes in the trends. However, mainstream approaches to multi-variate time series predictions do not handle well cases when the ongoing forecast must include uncertainty, nor they are robust to missing data. We introduce a new architecture for time series monitoring based on combination of state-of-the-art methods of forecasting in high-dimensional time series with full probabilistic handling of uncertainty. We demonstrate advantage of the architecture for time series forecasting and novelty detection, in particular with partially missing data, and empirically evaluate and compare the architecture to state-of-the-art approaches on a real-world data set.
Co-evolving morphology and control of soft robots using a single genome
Dec 22, 2022
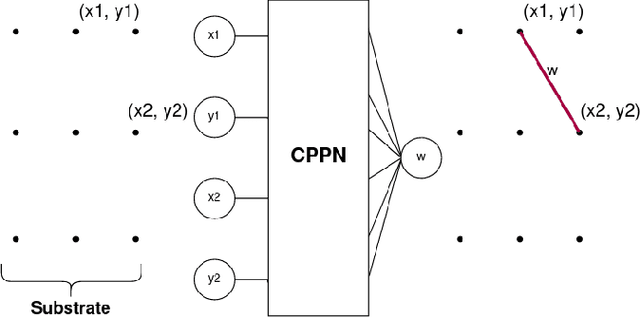
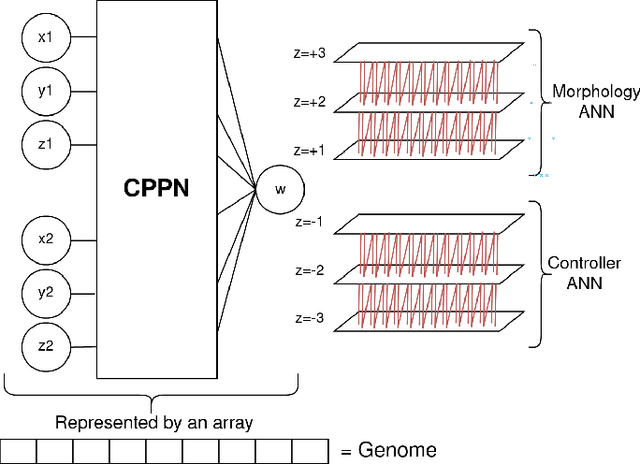
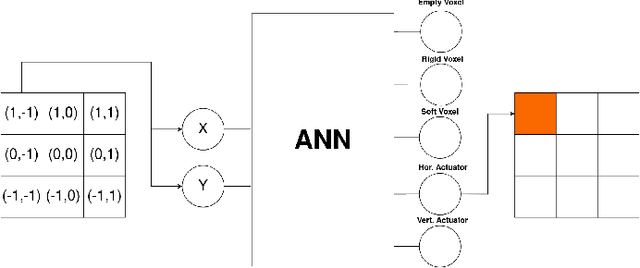
When simulating soft robots, both their morphology and their controllers play important roles in task performance. This paper introduces a new method to co-evolve these two components in the same process. We do that by using the hyperNEAT algorithm to generate two separate neural networks in one pass, one responsible for the design of the robot body structure and the other for the control of the robot. The key difference between our method and most existing approaches is that it does not treat the development of the morphology and the controller as separate processes. Similar to nature, our method derives both the "brain" and the "body" of an agent from a single genome and develops them together. While our approach is more realistic and doesn't require an arbitrary separation of processes during evolution, it also makes the problem more complex because the search space for this single genome becomes larger and any mutation to the genome affects "brain" and the "body" at the same time. Additionally, we present a new speciation function that takes into consideration both the genotypic distance, as is the standard for NEAT, and the similarity between robot bodies. By using this function, agents with very different bodies are more likely to be in different species, this allows robots with different morphologies to have more specialized controllers since they won't crossover with other robots that are too different from them. We evaluate the presented methods on four tasks and observe that even if the search space was larger, having a single genome makes the evolution process converge faster when compared to having separated genomes for body and control. The agents in our population also show morphologies with a high degree of regularity and controllers capable of coordinating the voxels to produce the necessary movements.
Response to Moffat's Comment on "Towards Meaningful Statements in IR Evaluation: Mapping Evaluation Measures to Interval Scales"
Dec 22, 2022

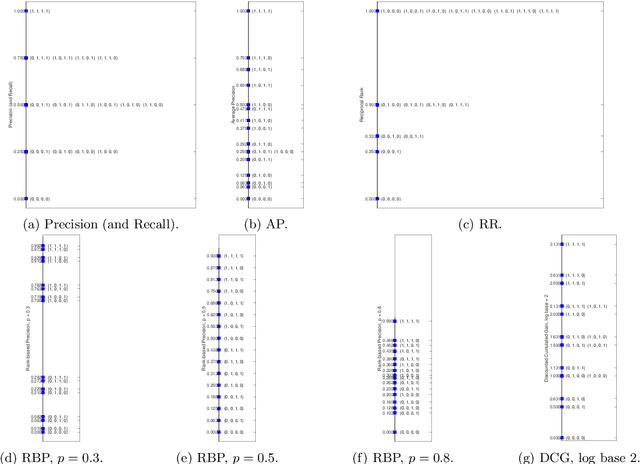
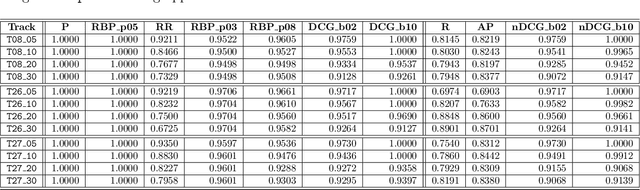
Moffat recently commented on our previous work. Our work focused on how laying the foundations of our evaluation methodology into the theory of measurement can improve our knowledge and understanding of the evaluation measures we use in IR and how it can shed light on the different types of scales adopted by our evaluation measures; we also provided evidence, through extensive experimentation, on the impact of the different types of scales on the statistical analyses, as well as on the impact of departing from their assumptions. Moreover, we investigated, for the first time in IR, the concept of meaningfulness, i.e. the invariance of the experimental statements and inferences you draw, and proposed it as a way to ensure more valid and generalizabile results. Moffat's comments build on: (i) misconceptions about the representational theory of measurement, such as what an interval scale actually is and what axioms it has to comply with; (ii) they totally miss the central concept of meaningfulness. Therefore, we reply to Moffat's comments by properly framing them in the representational theory of measurement and in the concept of meaningfulness. All in all, we can only reiterate what we said several times: the goal of this research line is to theoretically ground our evaluation methodology - and IR is a field where it is extremely challenging to perform any theoretical advances - in order to aim for more robust and generalizable inferences - something we currently lack in the field. Possibly there are other and better ways to achieve this objective and these proposals could emerge from an open discussion in the field and from the work of others. On the other hand, reducing everything to a contrast on what is (or pretend to be) an interval scale or whether all or none evaluation measures are interval scales may be more a barrier from than a help in progressing towards this goal.
Soft-Output Signal Detection for Cetacean Vocalizations Using Spectral Entropy, K-Means Clustering and the Continuous Wavelet Transform
Nov 22, 2022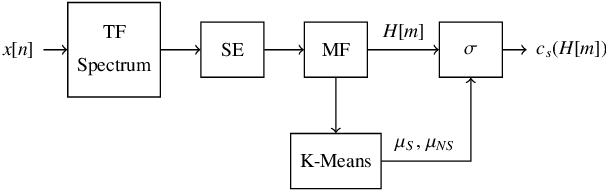
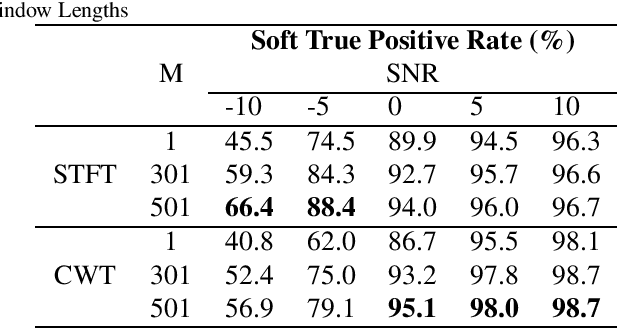
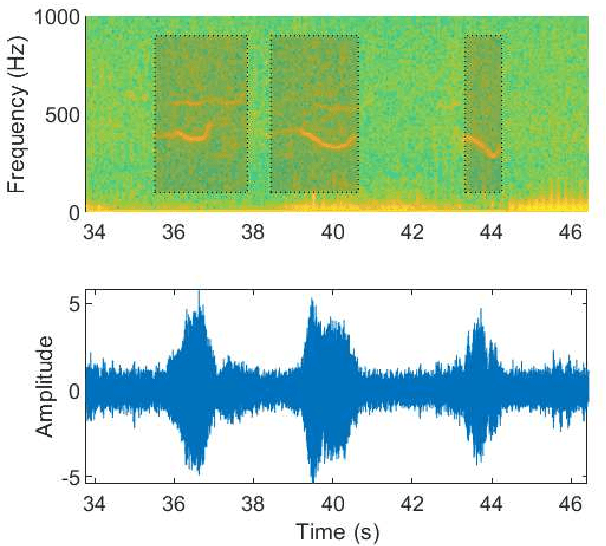
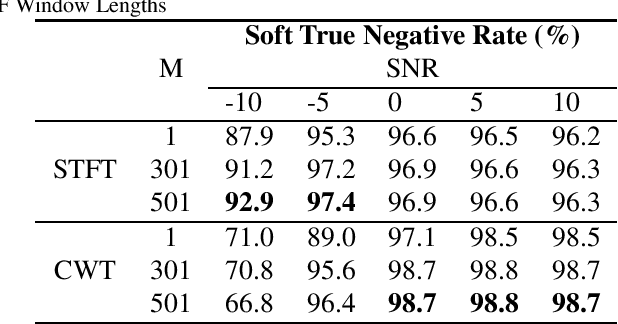
Underwater acoustic monitoring systems record many hours of audio data for marine research, making fast and reliable non-causal signal detection paramount. Such detectors assist in reducing the amount of labor required for signal annotations, which often contain large portions devoid of signals. Cetacean vocalization detection based on spectral entropy is investigated as a means of vocalization discovery. Previous techniques using spectral entropy (SE) mostly consider time-frequency enhancement of the entropy measure, and utilize the STFT as its time-frequency (TF) decomposition. SE methods also requires the user to set a detection threshold manually, which call for knowledge of the produced entropy measures. This paper considers median filtering as a simple, effective way to provide temporal stabilization to the entropy measure, and considers the CWT as an alternative TF decomposition. K-means clustering is used to determine the threshold required to accurately separate the signal/no-signal entropy measures, resulting in a one-dimensional, two-class classification problem. The class means are used to perform pseudo-probabilistic soft class assignment, which is a useful metric in algorithmic development. The effect of median filtering, signal-to-noise ratio and the chosen TF decomposition are investigated. The proposed method shows a significant improvement in detection accuracy and specificity, while also providing a more interpretable detection threshold setting via soft class assignment.
User-Conditioned Neural Control Policies for Mobile Robotics
Nov 22, 2022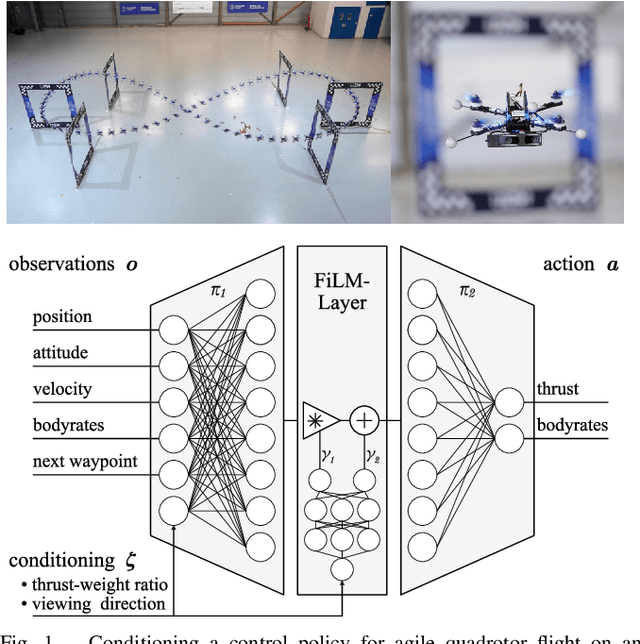



Recently, learning-based controllers have been shown to push mobile robotic systems to their limits and provide the robustness needed for many real-world applications. However, only classical optimization-based control frameworks offer the inherent flexibility to be dynamically adjusted during execution by, for example, setting target speeds or actuator limits. We present a framework to overcome this shortcoming of neural controllers by conditioning them on an auxiliary input. This advance is enabled by including a feature-wise linear modulation layer (FiLM). We use model-free reinforcement-learning to train quadrotor control policies for the task of navigating through a sequence of waypoints in minimum time. By conditioning the policy on the maximum available thrust or the viewing direction relative to the next waypoint, a user can regulate the aggressiveness of the quadrotor's flight during deployment. We demonstrate in simulation and in real-world experiments that a single control policy can achieve close to time-optimal flight performance across the entire performance envelope of the robot, reaching up to 60 km/h and 4.5g in acceleration. The ability to guide a learned controller during task execution has implications beyond agile quadrotor flight, as conditioning the control policy on human intent helps safely bringing learning based systems out of the well-defined laboratory environment into the wild.
Multi-Agent Deep Reinforcement Learning for Efficient Passenger Delivery in Urban Air Mobility
Nov 13, 2022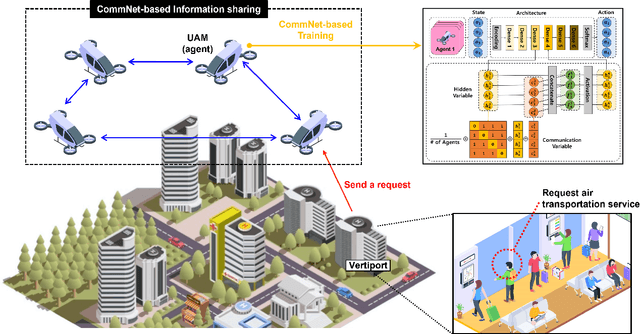
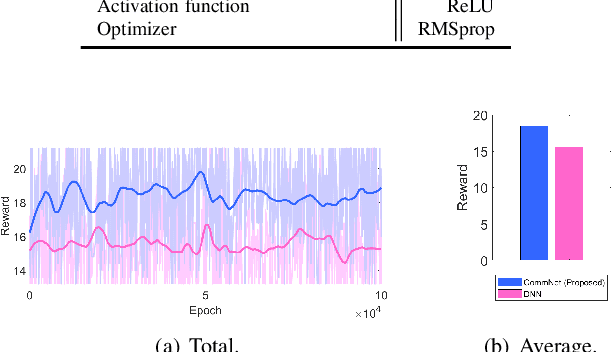
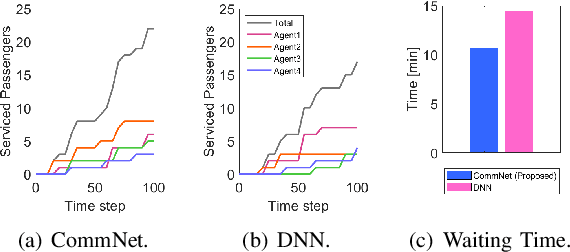

It has been considered that urban air mobility (UAM), also known as drone-taxi or electrical vertical takeoff and landing (eVTOL), will play a key role in future transportation. By putting UAM into practical future transportation, several benefits can be realized, i.e., (i) the total travel time of passengers can be reduced compared to traditional transportation and (ii) there is no environmental pollution and no special labor costs to operate the system because electric batteries will be used in UAM system. However, there are various dynamic and uncertain factors in the flight environment, i.e., passenger sudden service requests, battery discharge, and collision among UAMs. Therefore, this paper proposes a novel cooperative MADRL algorithm based on centralized training and distributed execution (CTDE) concepts for reliable and efficient passenger delivery in UAM networks. According to the performance evaluation results, we confirm that the proposed algorithm outperforms other existing algorithms in terms of the number of serviced passengers increase (30%) and the waiting time per serviced passenger decrease (26%)
Learning Label Initialization for Time-Dependent Harmonic Extension
May 03, 2022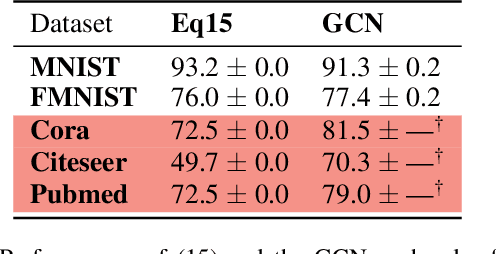
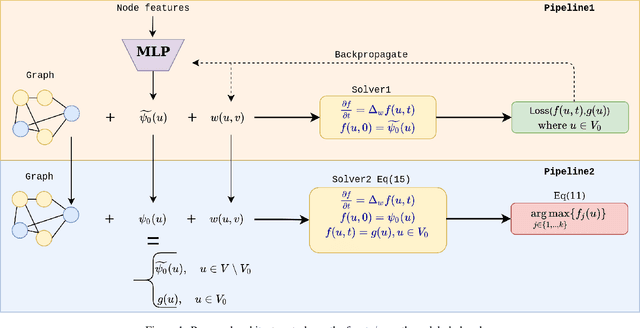
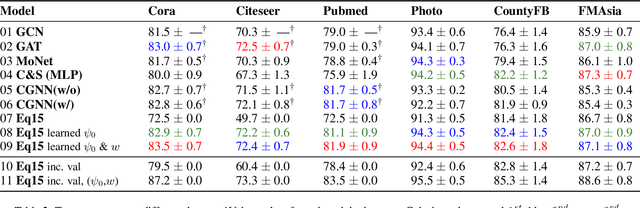
Node classification on graphs can be formulated as the Dirichlet problem on graphs where the signal is given at the labeled nodes, and the harmonic extension is done on the unlabeled nodes. This paper considers a time-dependent version of the Dirichlet problem on graphs and shows how to improve its solution by learning the proper initialization vector on the unlabeled nodes. Further, we show that the improved solution is at par with state-of-the-art methods used for node classification. Finally, we conclude this paper by discussing the importance of parameter t, pros, and future directions.
Synthetic Data for Object Classification in Industrial Applications
Dec 09, 2022
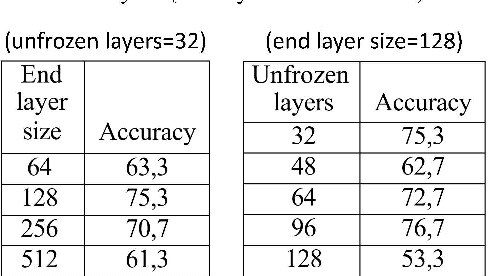

One of the biggest challenges in machine learning is data collection. Training data is an important part since it determines how the model will behave. In object classification, capturing a large number of images per object and in different conditions is not always possible and can be very time-consuming and tedious. Accordingly, this work explores the creation of artificial images using a game engine to cope with limited data in the training dataset. We combine real and synthetic data to train the object classification engine, a strategy that has shown to be beneficial to increase confidence in the decisions made by the classifier, which is often critical in industrial setups. To combine real and synthetic data, we first train the classifier on a massive amount of synthetic data, and then we fine-tune it on real images. Another important result is that the amount of real images needed for fine-tuning is not very high, reaching top accuracy with just 12 or 24 images per class. This substantially reduces the requirements of capturing a great amount of real data.
The Platform for non-metallic pipes defects recognition. Design and Implementation
Dec 09, 2022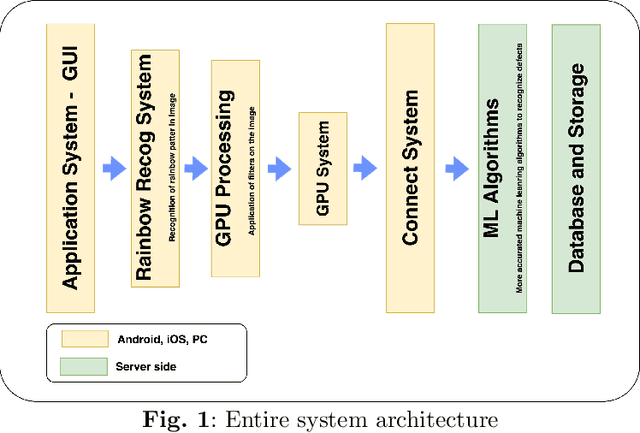
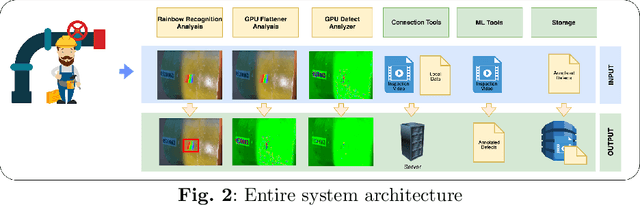
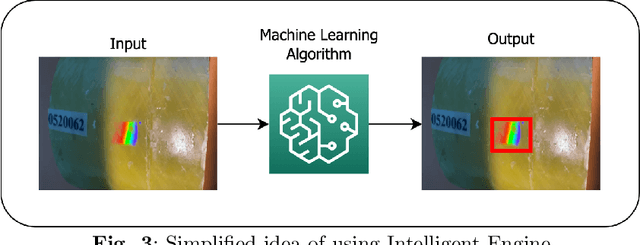
This paper describes a prototype software and hardware platform to provide support to field operators during the inspection of surface defects of non-metallic pipes. Inspection is carried out by video filming defects created on the same surface in real-time using a "smart" helmet device and other mobile devices. The work focuses on the detection and recognition of the defects which appears as colored iridescence of reflected light caused by the diffraction effect arising from the presence of internal stresses in the inspected material. The platform allows you to carry out preliminary analysis directly on the device in offline mode, and, if a connection to the network is established, the received data is transmitted to the server for post-processing to extract information about possible defects that were not detected at the previous stage. The paper presents a description of the stages of design, formal description, and implementation details of the platform. It also provides descriptions of the models used to recognize defects and examples of the result of the work.