 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deterioration Prediction using Time-Series of Three Vital Signs and Current Clinical Features Amongst COVID-19 Patients
Oct 12, 2022
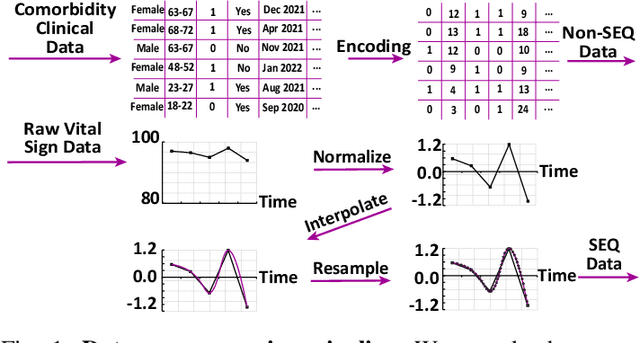
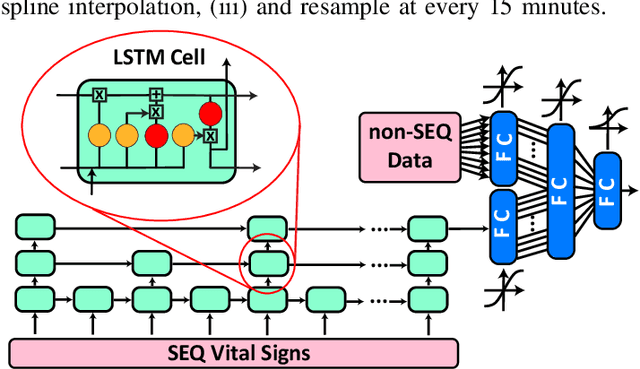
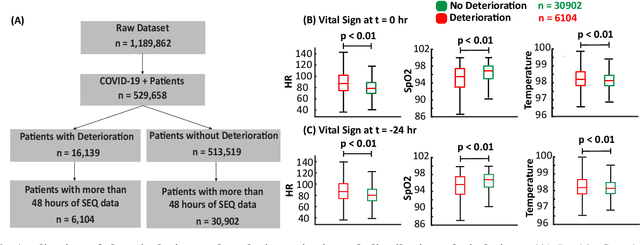
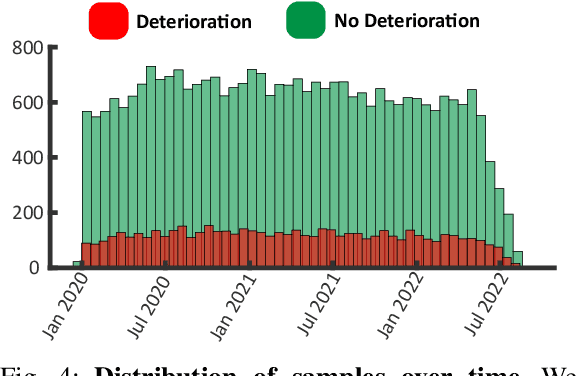
Unrecognized patient deterioration can lead to high morbidity and mortality. Most existing deterioration prediction models require a large number of clinical information, typically collected in hospital settings, such as medical images or comprehensive laboratory tests. This is infeasible for telehealth solutions and highlights a gap in deterioration prediction models that are based on minimal data, which can be recorded at a large scale in any clinic, nursing home, or even at the patient's home. In this study, we propose and develop a prognostic model that predicts if a patient will experience deterioration in the forthcoming 3-24 hours. The model sequentially processes routine triadic vital signs: (a) oxygen saturation, (b) heart rate, and (c) temperature. The model is also provided with basic patient information, including sex, age, vaccination status, vaccination date, and status of obesity, hypertension, or diabetes. We train and evaluate the model using data collected from 37,006 COVID-19 patients at NYU Langone Health in New York, USA. The model achieves an area under the receiver operating characteristic curve (AUROC) of 0.808-0.880 for 3-24 hour deterioration prediction. We also conduct occlusion experiments to evaluate the importance of each input feature, where the results reveal the significance of continuously monitoring the variations of the vital signs. Our results show the prospect of accurate deterioration forecast using a minimum feature set that can be relatively easily obtained using wearable devices and self-reported patient information.
Predicting Autonomous Vehicle Collision Injury Severity Levels for Ethical Decision Making and Path Planning
Dec 16, 2022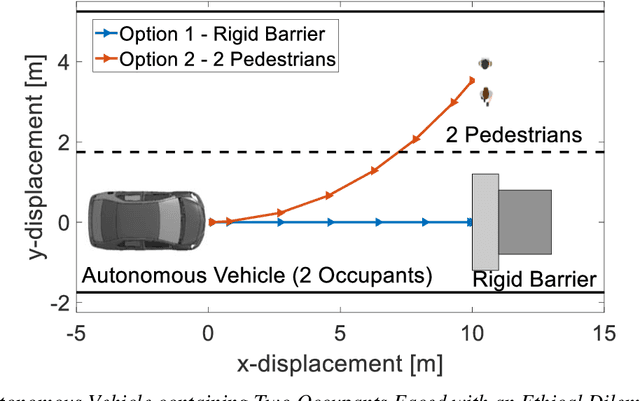
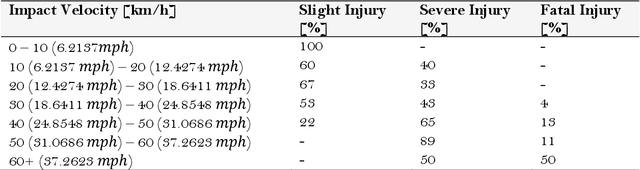
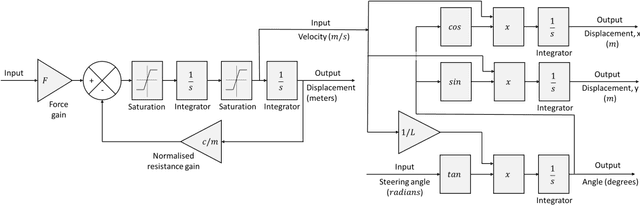
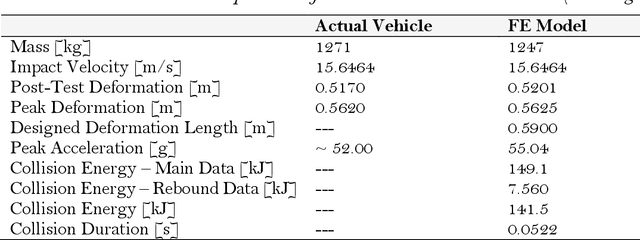
Developments in autonomous vehicles (AVs) are rapidly advancing and will in the next 20 years become a central part to our society. However, especially in the early stages of deployment, there is expected to be incidents involving AVs. In the event of AV incidents, decisions will need to be made that require ethical decisions, e.g., deciding between colliding into a group of pedestrians or a rigid barrier. For an AV to undertake such ethical decision making and path planning, simulation models of the situation will be required that are used in real-time on-board the AV. These models will enable path planning and ethical decision making to be undertaken based on predetermined collision injury severity levels. In this research, models are developed for the path planning and ethical decision making that predetermine knowledge regarding the possible collision injury severities, i.e., peak deformation of the AV colliding into the rigid barrier or the impact velocity of the AV colliding into a pedestrian. Based on such knowledge and using fuzzy logic, a novel nonlinear weighted utility cost function for the collision injury severity levels is developed. This allows the model-based predicted collision outcomes arising from AV peak deformation and AV-pedestrian impact velocity to be examined separately via weighted utility cost functions with a common structure. The general form of the weighted utility cost function exploits a fuzzy sets approach, thus allowing common utility costs from the two separate utility cost functions to be meaningfully compared. A decision-making algorithm, which makes use of a utilitarian ethical approach, ensures that the AV will always steer onto the path which represents the lowest injury severity level, hence utility cost to society.
RSTT: Real-time Spatial Temporal Transformer for Space-Time Video Super-Resolution
Mar 27, 2022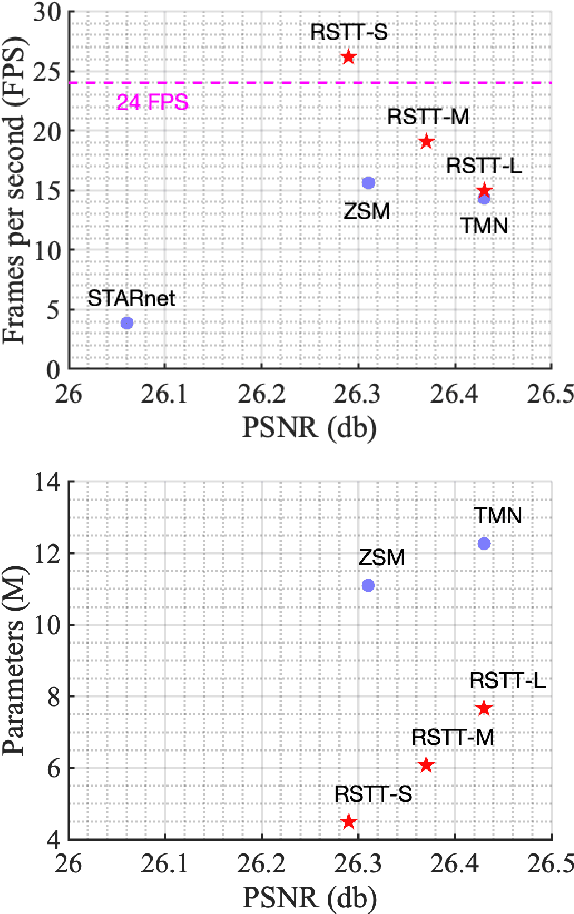
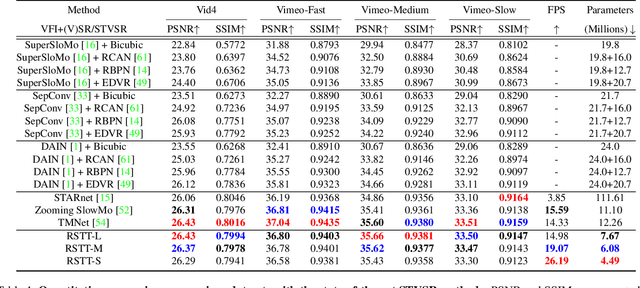
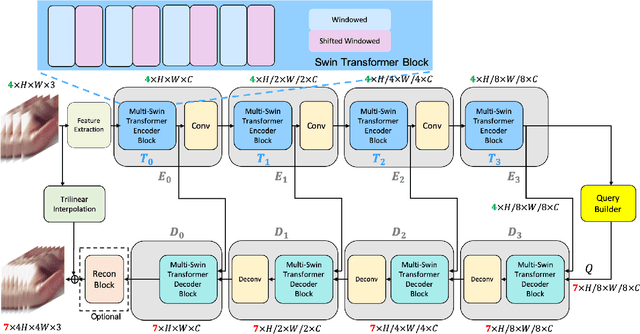

Space-time video super-resolution (STVSR) is the task of interpolating videos with both Low Frame Rate (LFR) and Low Resolution (LR) to produce High-Frame-Rate (HFR) and also High-Resolution (HR) counterparts. The existing methods based on Convolutional Neural Network~(CNN) succeed in achieving visually satisfied results while suffer from slow inference speed due to their heavy architectures. We propose to resolve this issue by using a spatial-temporal transformer that naturally incorporates the spatial and temporal super resolution modules into a single model. Unlike CNN-based methods, we do not explicitly use separated building blocks for temporal interpolations and spatial super-resolutions; instead, we only use a single end-to-end transformer architecture. Specifically, a reusable dictionary is built by encoders based on the input LFR and LR frames, which is then utilized in the decoder part to synthesize the HFR and HR frames. Compared with the state-of-the-art TMNet \cite{xu2021temporal}, our network is $60\%$ smaller (4.5M vs 12.3M parameters) and $80\%$ faster (26.2fps vs 14.3fps on $720\times576$ frames) without sacrificing much performance. The source code is available at https://github.com/llmpass/RSTT.
Time-coded Spiking Fourier Transform in Neuromorphic Hardware
Mar 31, 2022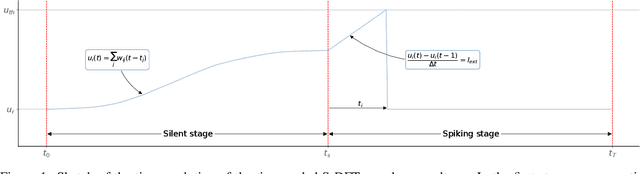

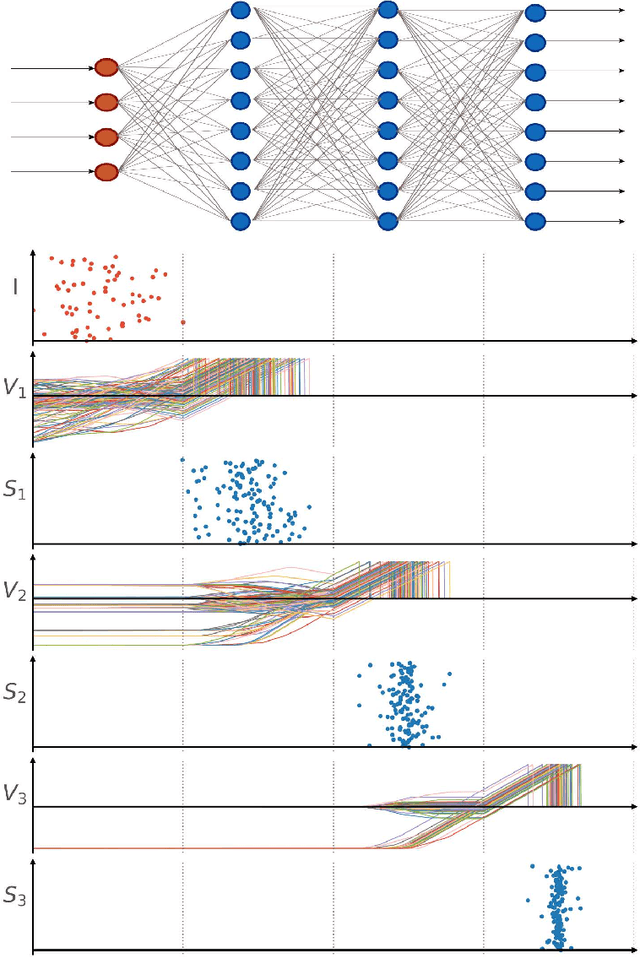

After several decades of continuously optimizing computing systems, the Moore's law is reaching itsend. However, there is an increasing demand for fast and efficient processing systems that can handlelarge streams of data while decreasing system footprints. Neuromorphic computing answers thisneed by creating decentralized architectures that communicate with binary events over time. Despiteits rapid growth in the last few years, novel algorithms are needed that can leverage the potential ofthis emerging computing paradigm and can stimulate the design of advanced neuromorphic chips.In this work, we propose a time-based spiking neural network that is mathematically equivalent tothe Fourier transform. We implemented the network in the neuromorphic chip Loihi and conductedexperiments on five different real scenarios with an automotive frequency modulated continuouswave radar. Experimental results validate the algorithm, and we hope they prompt the design of adhoc neuromorphic chips that can improve the efficiency of state-of-the-art digital signal processorsand encourage research on neuromorphic computing for signal processing.
Real-time Dual-channel 2 * 2 MIMO Fiber-THz-Fiber Seamless Integration System at 385 GHz and 435 GHz
Jun 24, 2022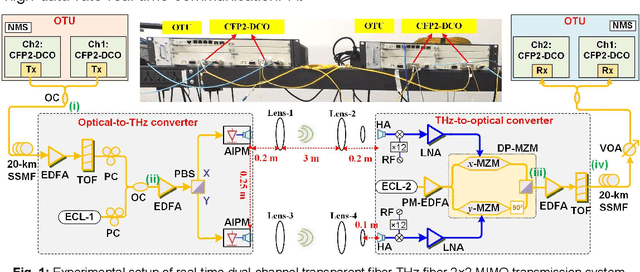
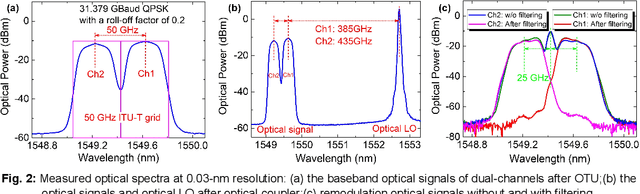
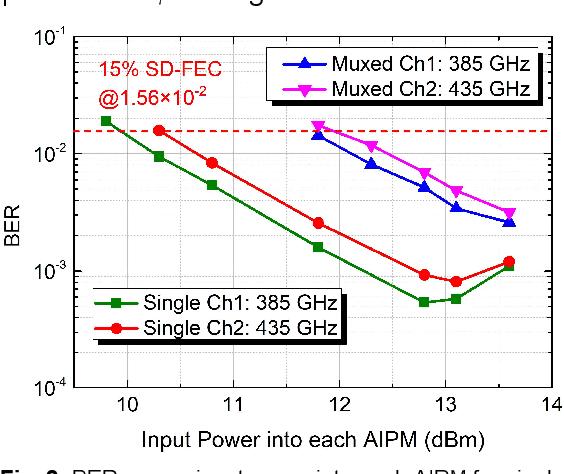
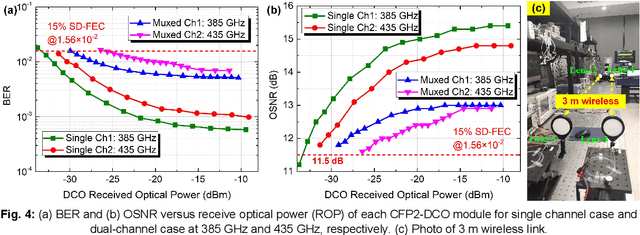
We demonstrate the first practical real-time dual-channel fiber-THz-fiber 2 * 2 MIMO seamless integration system with a record net data rate of 2 * 103.125 Gb/s at 385 GHz and 435 GHz over two spans of 20 km SSMF and 3 m wireless link.
Breaking trade-offs in speech separation with sparsely-gated mixture of experts
Nov 11, 2022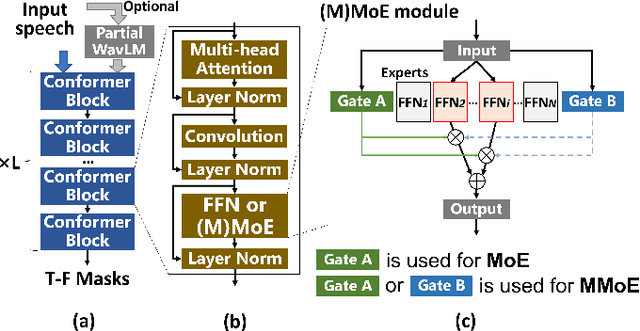
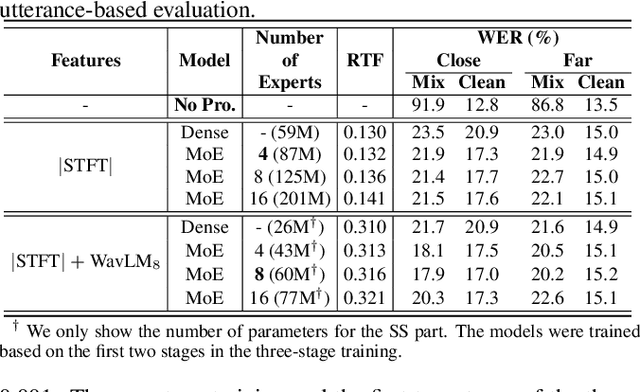
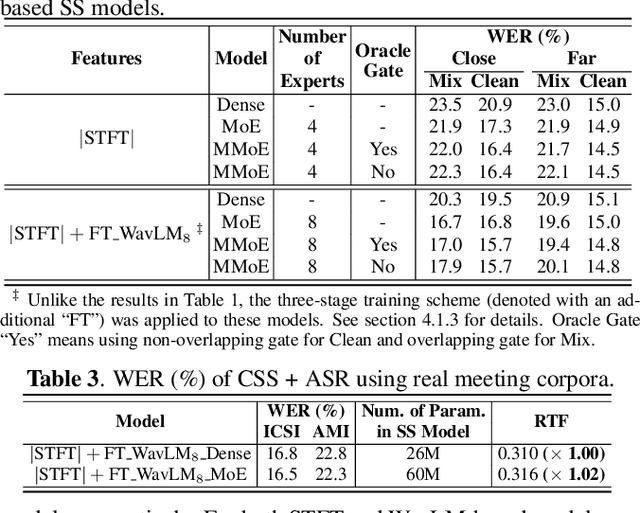
Several trade-offs need to be balanced when employing monaural speech separation (SS) models in conversational automatic speech recognition (ASR) systems. A larger SS model generally achieves better output quality at an expense of higher computation, meanwhile, a better SS model for overlapping speech often produces distorted output for non-overlapping speech. This paper addresses these trade-offs with a sparsely-gated mixture-of-experts (MoE). The sparsely-gated MoE architecture allows the separation models to be enlarged without compromising the run-time efficiency, which also helps achieve a better separation-distortion trade-off. To further reduce the speech distortion without compromising the SS capability, a multi-gate MoE framework is also explored, where different gates handle non-overlapping and overlapping frames differently. ASR experiments are conducted by using a simulated dataset for measuring both the speech separation accuracy and the speech distortion. Two advanced SS models, Conformer and WavLM-based models, are used as baselines. The sparsely-gated MoE models show a superior SS capability with less speech distortion, meanwhile marginally increasing the run-time computational cost. Experimental results using real conversation recordings are also presented, showing MoE's effectiveness in an end-to-end evaluation setting.
Bi-Level Optimization Augmented with Conditional Variational Autoencoder for Autonomous Driving in Dense Traffic
Dec 05, 2022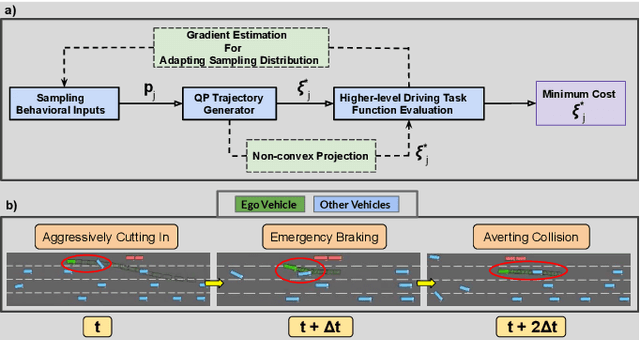
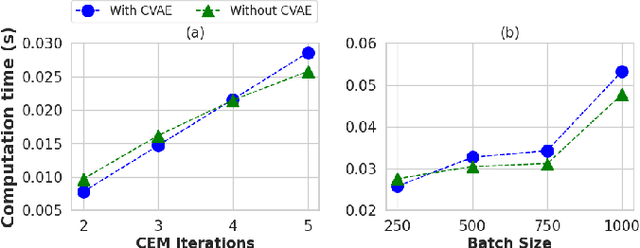

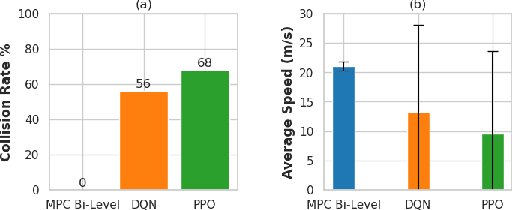
Autonomous driving has a natural bi-level structure. The goal of the upper behavioural layer is to provide appropriate lane change, speeding up, and braking decisions to optimize a given driving task. However, this layer can only indirectly influence the driving efficiency through the lower-level trajectory planner, which takes in the behavioural inputs to produce motion commands. Existing sampling-based approaches do not fully exploit the strong coupling between the behavioural and planning layer. On the other hand, end-to-end Reinforcement Learning (RL) can learn a behavioural layer while incorporating feedback from the lower-level planner. However, purely data-driven approaches often fail in safety metrics in unseen environments. This paper presents a novel alternative; a parameterized bi-level optimization that jointly computes the optimal behavioural decisions and the resulting downstream trajectory. Our approach runs in real-time using a custom GPU-accelerated batch optimizer, and a Conditional Variational Autoencoder learnt warm-start strategy. Extensive simulations show that our approach outperforms state-of-the-art model predictive control and RL approaches in terms of collision rate while being competitive in driving efficiency.
Synthesizing Programs with Continuous Optimization
Nov 02, 2022
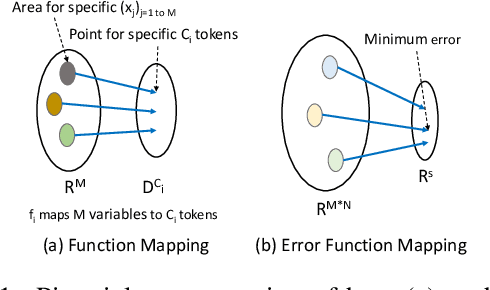
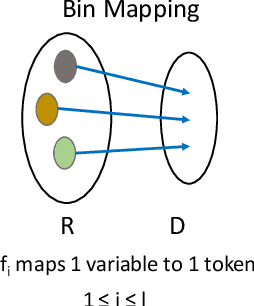

Automatic software generation based on some specification is known as program synthesis. Most existing approaches formulate program synthesis as a search problem with discrete parameters. In this paper, we present a novel formulation of program synthesis as a continuous optimization problem and use a state-of-the-art evolutionary approach, known as Covariance Matrix Adaptation Evolution Strategy to solve the problem. We then propose a mapping scheme to convert the continuous formulation into actual programs. We compare our system, called GENESYS, with several recent program synthesis techniques (in both discrete and continuous domains) and show that GENESYS synthesizes more programs within a fixed time budget than those existing schemes. For example, for programs of length 10, GENESYS synthesizes 28% more programs than those existing schemes within the same time budget.
A Grid-based Sensor Floor Platform for Robot Localization using Machine Learning
Dec 09, 2022

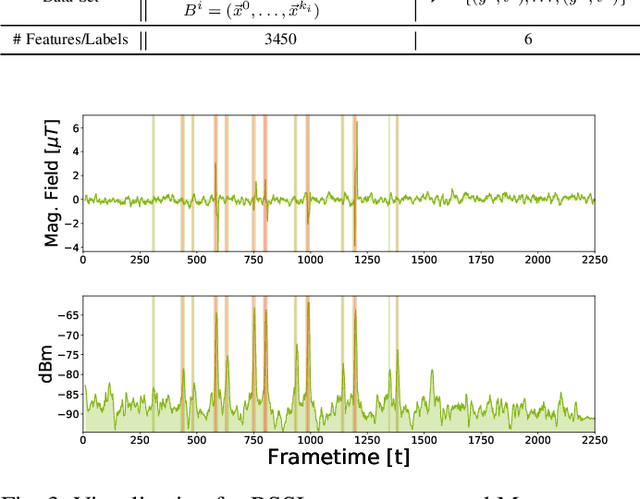
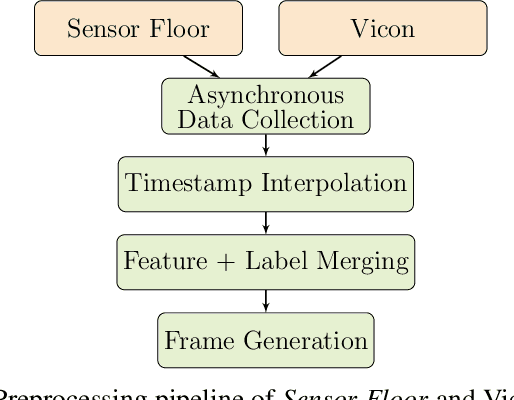
Wireless Sensor Network (WSN) applications reshape the trend of warehouse monitoring systems allowing them to track and locate massive numbers of logistic entities in real-time. To support the tasks, classic Radio Frequency (RF)-based localization approaches (e.g. triangulation and trilateration) confront challenges due to multi-path fading and signal loss in noisy warehouse environment. In this paper, we investigate machine learning methods using a new grid-based WSN platform called Sensor Floor that can overcome the issues. Sensor Floor consists of 345 nodes installed across the floor of our logistic research hall with dual-band RF and Inertial Measurement Unit (IMU) sensors. Our goal is to localize all logistic entities, for this study we use a mobile robot. We record distributed sensing measurements of Received Signal Strength Indicator (RSSI) and IMU values as the dataset and position tracking from Vicon system as the ground truth. The asynchronous collected data is pre-processed and trained using Random Forest and Convolutional Neural Network (CNN). The CNN model with regularization outperforms the Random Forest in terms of localization accuracy with aproximate 15 cm. Moreover, the CNN architecture can be configured flexibly depending on the scenario in the warehouse. The hardware, software and the CNN architecture of the Sensor Floor are open-source under https://github.com/FLW-TUDO/sensorfloor.
Directional dark field retrieval with single-grid x-ray imaging
Nov 21, 2022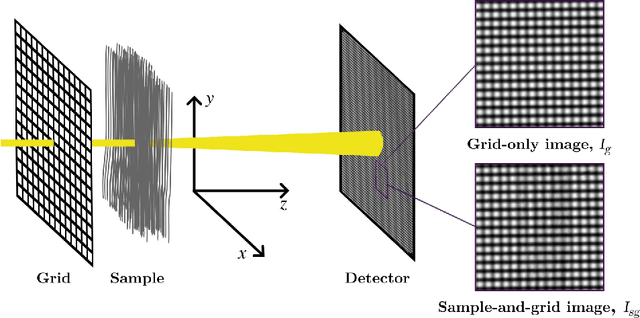
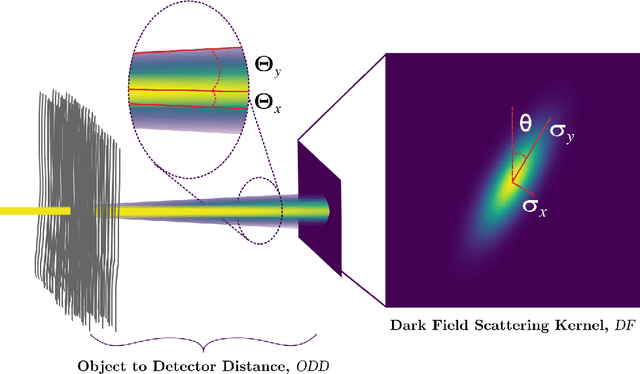
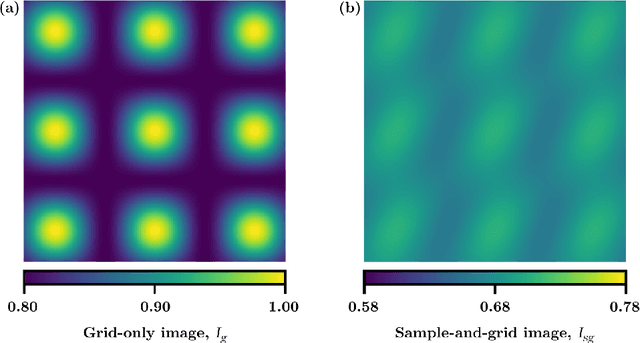
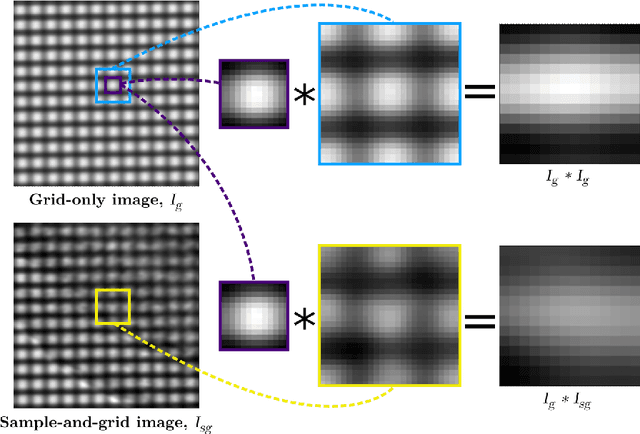
Directional dark-field imaging is an emerging x-ray modality that is sensitive to unresolved anisotropic scattering from sub-pixel sample microstructures. A single-grid imaging set-up can be used to capture dark-field images by looking at changes in a grid pattern projected upon the sample. By creating analytical models for the experiment, we have developed a single-grid directional dark field retrieval algorithm that can extract dark-field parameters such as the dominant scattering direction, and the semi-major and -minor scattering angles. We show that this method is effective even in the presence of high image noise, allowing for low dose and time sequence imaging.