 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
NRTR: Neuron Reconstruction with Transformer from 3D Optical Microscopy Images
Dec 08, 2022
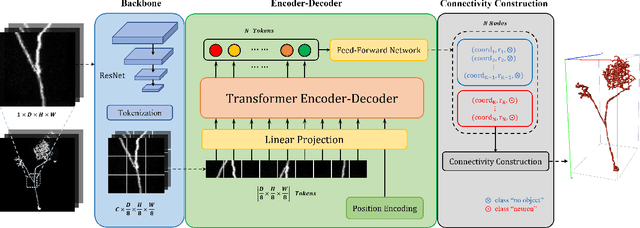
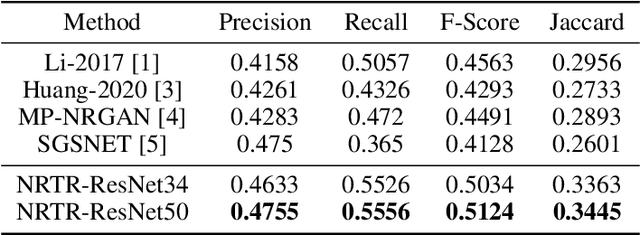
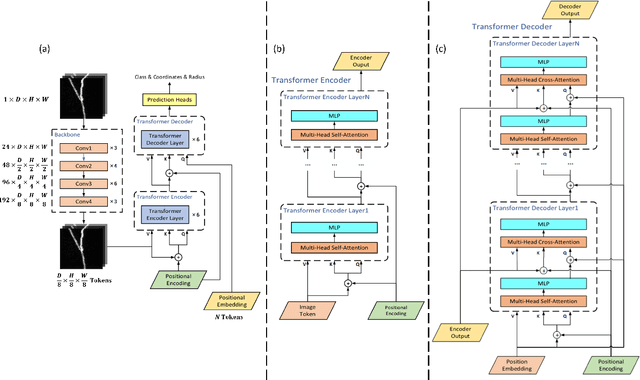
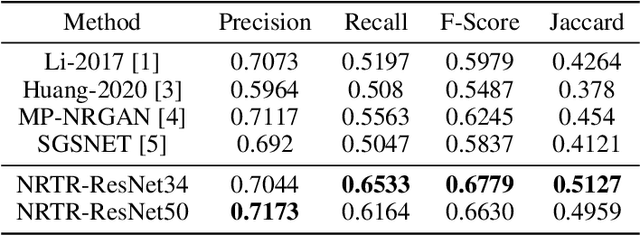
The neuron reconstruction from raw Optical Microscopy (OM) image stacks is the basis of neuroscience. Manual annotation and semi-automatic neuron tracing algorithms are time-consuming and inefficient. Existing deep learning neuron reconstruction methods, although demonstrating exemplary performance, greatly demand complex rule-based components. Therefore, a crucial challenge is designing an end-to-end neuron reconstruction method that makes the overall framework simpler and model training easier. We propose a Neuron Reconstruction Transformer (NRTR) that, discarding the complex rule-based components, views neuron reconstruction as a direct set-prediction problem. To the best of our knowledge, NRTR is the first image-to-set deep learning model for end-to-end neuron reconstruction. In experiments using the BigNeuron and VISoR-40 datasets, NRTR achieves excellent neuron reconstruction results for comprehensive benchmarks and outperforms competitive baselines. Results of extensive experiments indicate that NRTR is effective at showing that neuron reconstruction is viewed as a set-prediction problem, which makes end-to-end model training available.
Parameterisation of Reasoning on Temporal Markov Logic Networks
Nov 29, 2022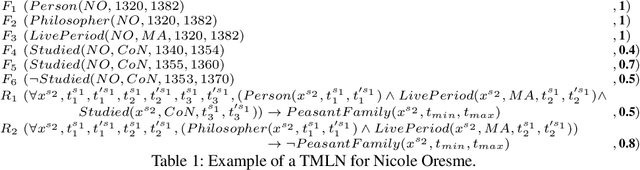
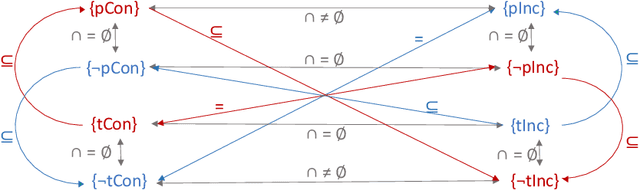
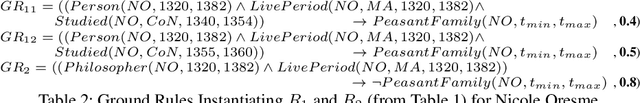

We aim at improving reasoning on inconsistent and uncertain data. We focus on knowledge-graph data, extended with time intervals to specify their validity, as regularly found in historical sciences. We propose principles on semantics for efficient Maximum A-Posteriori inference on the new Temporal Markov Logic Networks (TMLN) which extend the Markov Logic Networks (MLN) by uncertain temporal facts and rules. We examine total and partial temporal (in)consistency relations between sets of temporal formulae. Then we propose a new Temporal Parametric Semantics, which may combine several sub-functions, allowing to use different assessment strategies. Finally, we expose the constraints that semantics must respect to satisfy our principles.
Early Time-Series Classification Algorithms: An Empirical Comparison
Mar 03, 2022
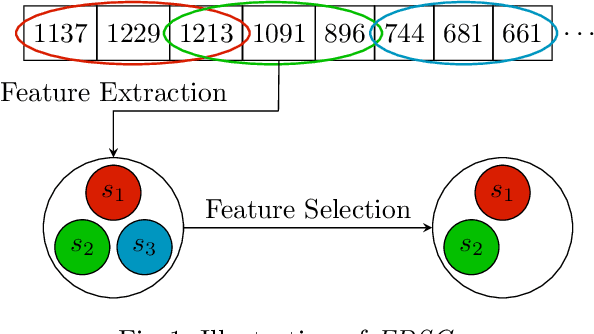
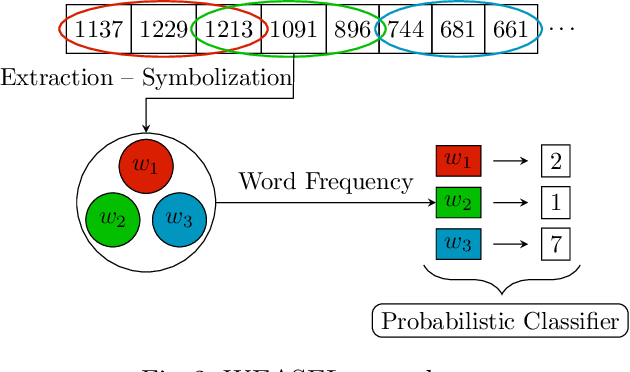
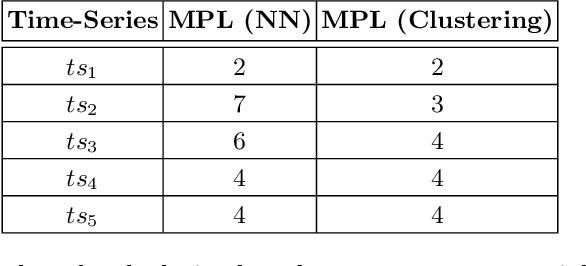
Early Time-Series Classification (ETSC) is the task of predicting the class of incoming time-series by observing as few measurements as possible. Such methods can be employed to obtain classification forecasts in many time-critical applications. However, available techniques are not equally suitable for every problem, since differentiations in the data characteristics can impact algorithm performance in terms of earliness, accuracy, F1-score, and training time. We evaluate six existing ETSC algorithms on publicly available data, as well as on two newly introduced datasets originating from the life sciences and maritime domains. Our goal is to provide a framework for the evaluation and comparison of ETSC algorithms and to obtain intuition on how such approaches perform on real-life applications. The presented framework may also serve as a benchmark for new related techniques.
Federated Best Arm Identification with Heterogeneous Clients
Oct 17, 2022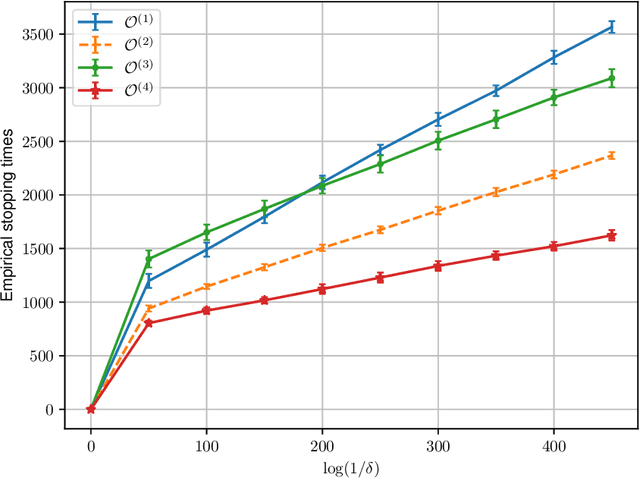
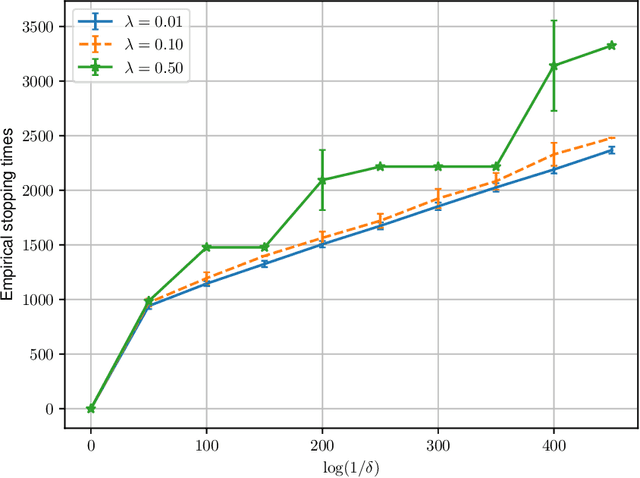
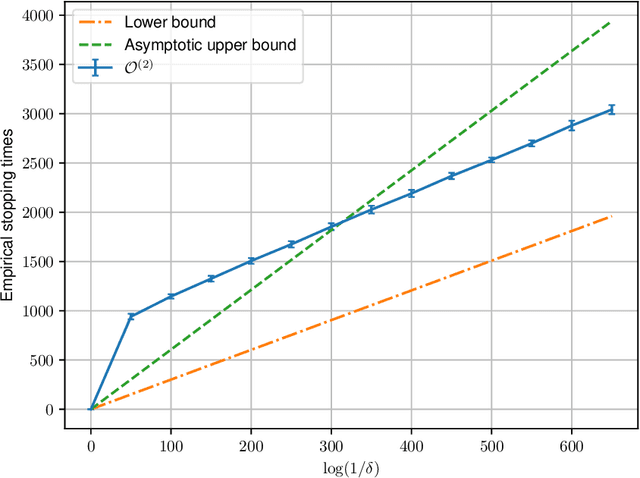
We study best arm identification in a federated multi-armed bandit setting with a central server and multiple clients, when each client has access to a {\em subset} of arms and each arm yields independent Gaussian observations. The {\em reward} from an arm at any given time is defined as the average of the observations generated at this time across all the clients that have access to the arm. The end goal is to identify the best arm (the arm with the largest mean reward) of each client with the least expected stopping time, subject to an upper bound on the error probability (i.e., the {\em fixed-confidence regime}). We provide a lower bound on the growth rate of the expected time to find the best arm of each client. Furthermore, we show that for any algorithm whose upper bound on the expected time to find the best arms matches with the lower bound up to a multiplicative constant, the ratio of any two consecutive communication time instants must be bounded, a result that is of independent interest. We then provide the first-known lower bound on the expected number of {\em communication rounds} required to find the best arms. We propose a novel algorithm based on the well-known {\em Track-and-Stop} strategy that communicates only at exponential time instants, and derive asymptotic upper bounds on its expected time to find the best arms and the expected number of communication rounds, where the asymptotics is one of vanishing error probabilities.
Walking Noise: Understanding Implications of Noisy Computations on Classification Tasks
Dec 20, 2022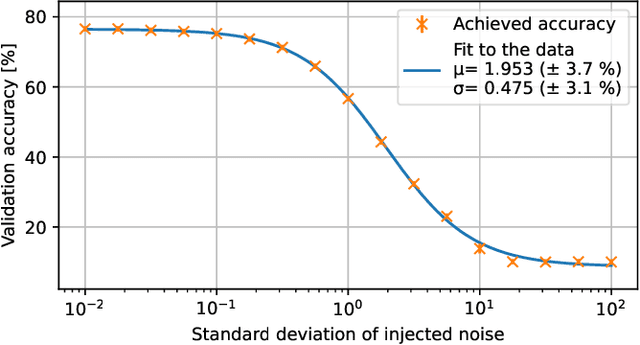
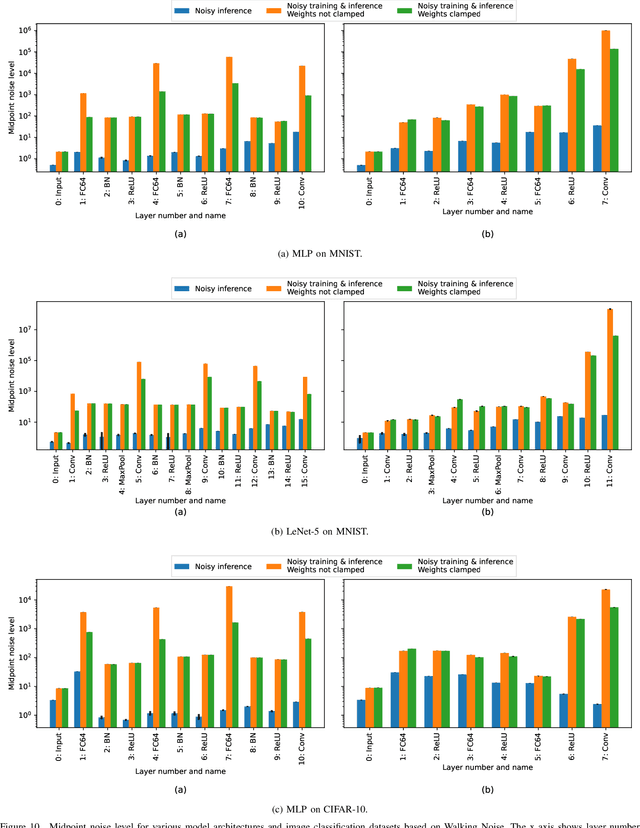
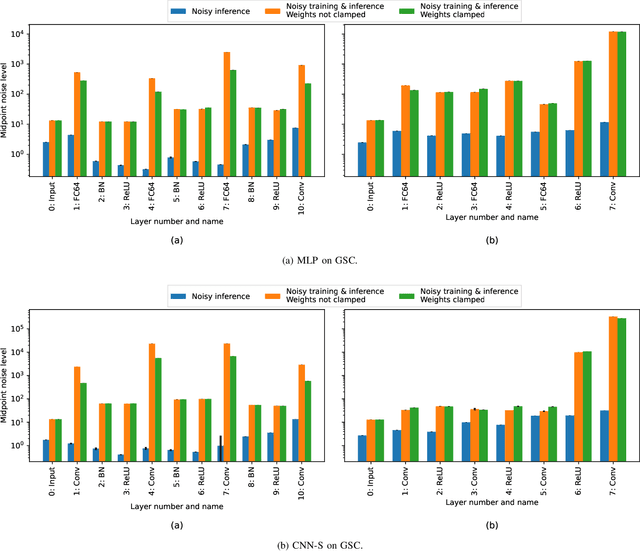

Machine learning methods like neural networks are extremely successful and popular in a variety of applications, however, they come at substantial computational costs, accompanied by high energy demands. In contrast, hardware capabilities are limited and there is evidence that technology scaling is stuttering, therefore, new approaches to meet the performance demands of increasingly complex model architectures are required. As an unsafe optimization, noisy computations are more energy efficient, and given a fixed power budget also more time efficient. However, any kind of unsafe optimization requires counter measures to ensure functionally correct results. This work considers noisy computations in an abstract form, and gears to understand the implications of such noise on the accuracy of neural-network-based classifiers as an exemplary workload. We propose a methodology called "Walking Noise" that allows to assess the robustness of different layers of deep architectures by means of a so-called "midpoint noise level" metric. We then investigate the implications of additive and multiplicative noise for different classification tasks and model architectures, with and without batch normalization. While noisy training significantly increases robustness for both noise types, we observe a clear trend to increase weights and thus increase the signal-to-noise ratio for additive noise injection. For the multiplicative case, we find that some networks, with suitably simple tasks, automatically learn an internal binary representation, hence becoming extremely robust. Overall this work proposes a method to measure the layer-specific robustness and shares first insights on how networks learn to compensate injected noise, and thus, contributes to understand robustness against noisy computations.
MDL-based Compressing Sequential Rules
Dec 20, 2022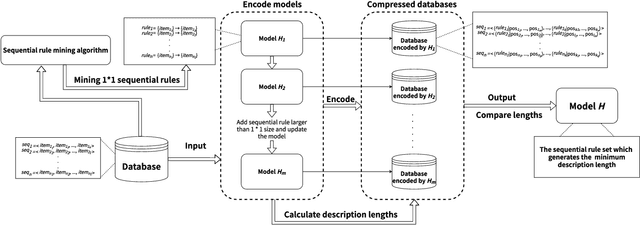
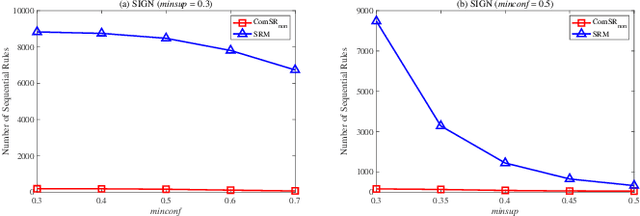
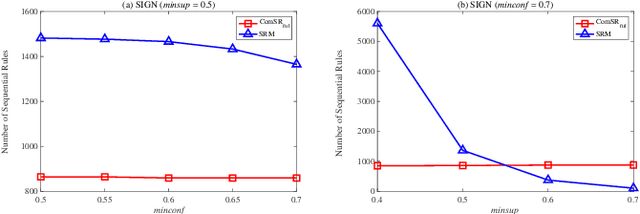
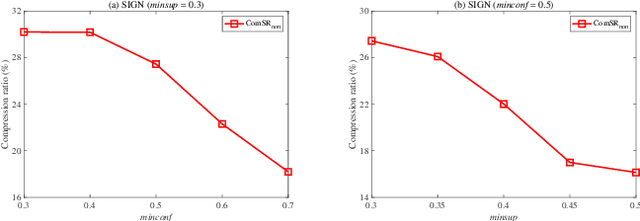
Nowadays, with the rapid development of the Internet, the era of big data has come. The Internet generates huge amounts of data every day. However, extracting meaningful information from massive data is like looking for a needle in a haystack. Data mining techniques can provide various feasible methods to solve this problem. At present, many sequential rule mining (SRM) algorithms are presented to find sequential rules in databases with sequential characteristics. These rules help people extract a lot of meaningful information from massive amounts of data. How can we achieve compression of mined results and reduce data size to save storage space and transmission time? Until now, there has been little research on the compression of SRM. In this paper, combined with the Minimum Description Length (MDL) principle and under the two metrics (support and confidence), we introduce the problem of compression of SRM and also propose a solution named ComSR for MDL-based compressing of sequential rules based on the designed sequential rule coding scheme. To our knowledge, we are the first to use sequential rules to encode an entire database. A heuristic method is proposed to find a set of compact and meaningful sequential rules as much as possible. ComSR has two trade-off algorithms, ComSR_non and ComSR_ful, based on whether the database can be completely compressed. Experiments done on a real dataset with different thresholds show that a set of compact and meaningful sequential rules can be found. This shows that the proposed method works.
An ensemble neural network approach to forecast Dengue outbreak based on climatic condition
Dec 20, 2022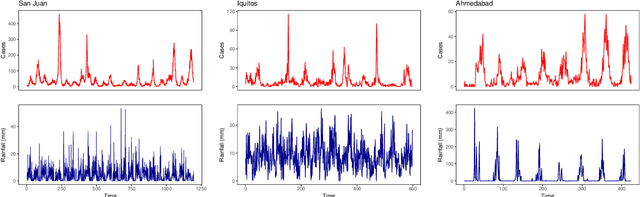
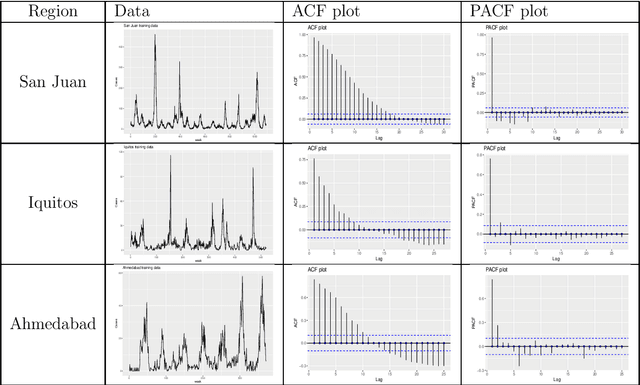
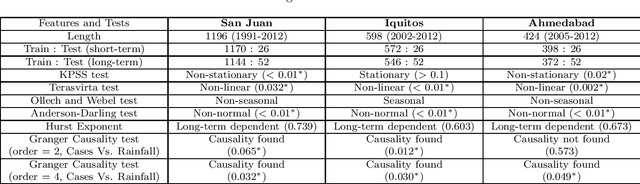

Dengue fever is a virulent disease spreading over 100 tropical and subtropical countries in Africa, the Americas, and Asia. This arboviral disease affects around 400 million people globally, severely distressing the healthcare systems. The unavailability of a specific drug and ready-to-use vaccine makes the situation worse. Hence, policymakers must rely on early warning systems to control intervention-related decisions. Forecasts routinely provide critical information for dangerous epidemic events. However, the available forecasting models (e.g., weather-driven mechanistic, statistical time series, and machine learning models) lack a clear understanding of different components to improve prediction accuracy and often provide unstable and unreliable forecasts. This study proposes an ensemble wavelet neural network with exogenous factor(s) (XEWNet) model that can produce reliable estimates for dengue outbreak prediction for three geographical regions, namely San Juan, Iquitos, and Ahmedabad. The proposed XEWNet model is flexible and can easily incorporate exogenous climate variable(s) confirmed by statistical causality tests in its scalable framework. The proposed model is an integrated approach that uses wavelet transformation into an ensemble neural network framework that helps in generating more reliable long-term forecasts. The proposed XEWNet allows complex non-linear relationships between the dengue incidence cases and rainfall; however, mathematically interpretable, fast in execution, and easily comprehensible. The proposal's competitiveness is measured using computational experiments based on various statistical metrics and several statistical comparison tests. In comparison with statistical, machine learning, and deep learning methods, our proposed XEWNet performs better in 75% of the cases for short-term and long-term forecasting of dengue incidence.
Generalised agent for solving higher board states of tic tac toe using Reinforcement Learning
Dec 23, 2022
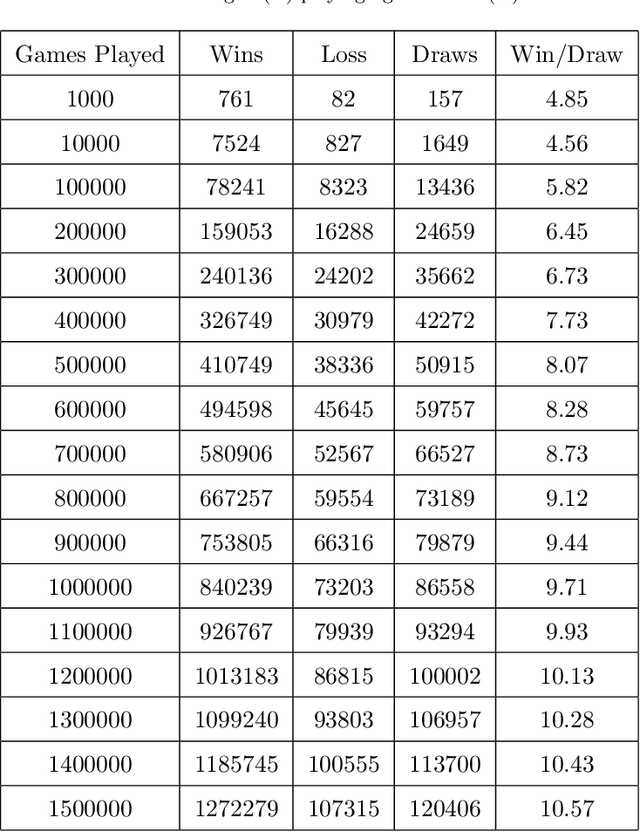
Tic Tac Toe is amongst the most well-known games. It has already been shown that it is a biased game, giving more chances to win for the first player leaving only a draw or a loss as possibilities for the opponent, assuming both the players play optimally. Thus on average majority of the games played result in a draw. The majority of the latest research on how to solve a tic tac toe board state employs strategies such as Genetic Algorithms, Neural Networks, Co-Evolution, and Evolutionary Programming. But these approaches deal with a trivial board state of 3X3 and very little research has been done for a generalized algorithm to solve 4X4,5X5,6X6 and many higher states. Even though an algorithm exists which is Min-Max but it takes a lot of time in coming up with an ideal move due to its recursive nature of implementation. A Sample has been created on this link \url{https://bk-tic-tac-toe.herokuapp.com/} to prove this fact. This is the main problem that this study is aimed at solving i.e providing a generalized algorithm(Approximate method, Learning-Based) for higher board states of tic tac toe to make precise moves in a short period. Also, the code changes needed to accommodate higher board states will be nominal. The idea is to pose the tic tac toe game as a well-posed learning problem. The study and its results are promising, giving a high win to draw ratio with each epoch of training. This study could also be encouraging for other researchers to apply the same algorithm to other similar board games like Minesweeper, Chess, and GO for finding efficient strategies and comparing the results.
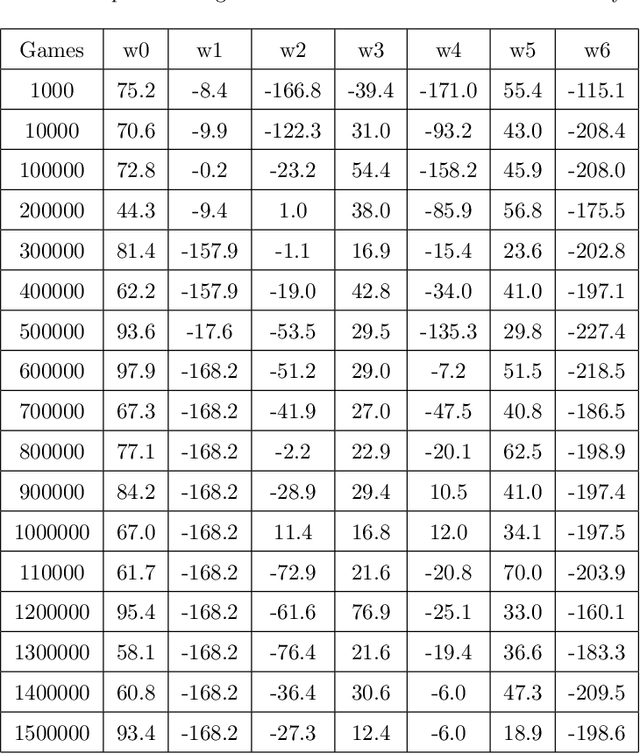
Efficient Generalization Improvement Guided by Random Weight Perturbation
Nov 21, 2022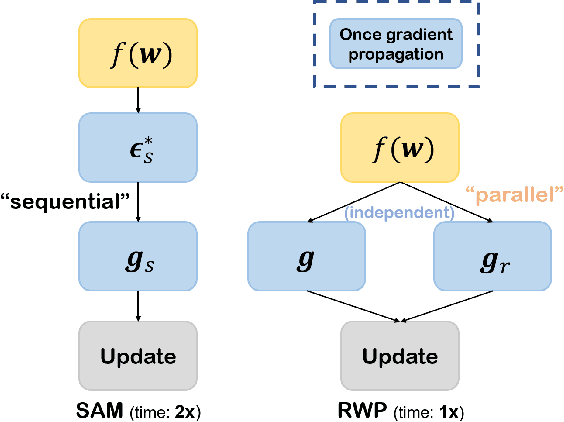
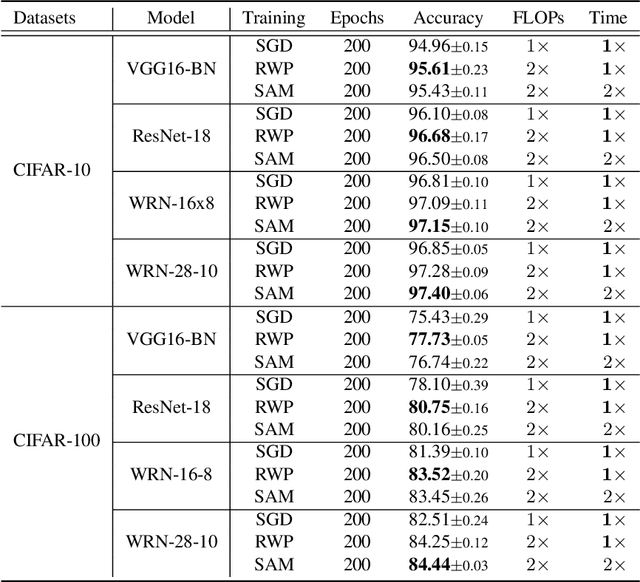
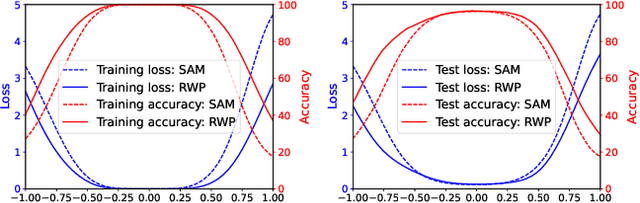
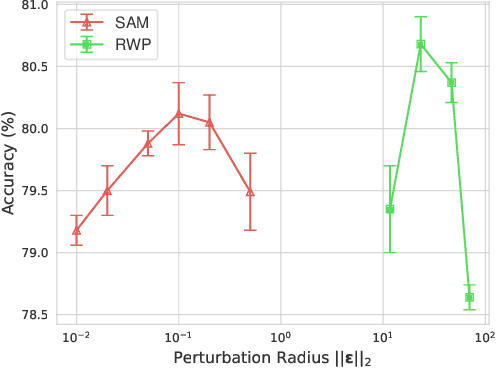
To fully uncover the great potential of deep neural networks (DNNs), various learning algorithms have been developed to improve the model's generalization ability. Recently, sharpness-aware minimization (SAM) establishes a generic scheme for generalization improvements by minimizing the sharpness measure within a small neighborhood and achieves state-of-the-art performance. However, SAM requires two consecutive gradient evaluations for solving the min-max problem and inevitably doubles the training time. In this paper, we resort to filter-wise random weight perturbations (RWP) to decouple the nested gradients in SAM. Different from the small adversarial perturbations in SAM, RWP is softer and allows a much larger magnitude of perturbations. Specifically, we jointly optimize the loss function with random perturbations and the original loss function: the former guides the network towards a wider flat region while the latter helps recover the necessary local information. These two loss terms are complementary to each other and mutually independent. Hence, the corresponding gradients can be efficiently computed in parallel, enabling nearly the same training speed as regular training. As a result, we achieve very competitive performance on CIFAR and remarkably better performance on ImageNet (e.g. $\mathbf{ +1.1\%}$) compared with SAM, but always require half of the training time. The code is released at https://github.com/nblt/RWP.
HARL: Hierarchical Adaptive Reinforcement Learning Based Auto Scheduler for Neural Networks
Nov 21, 2022
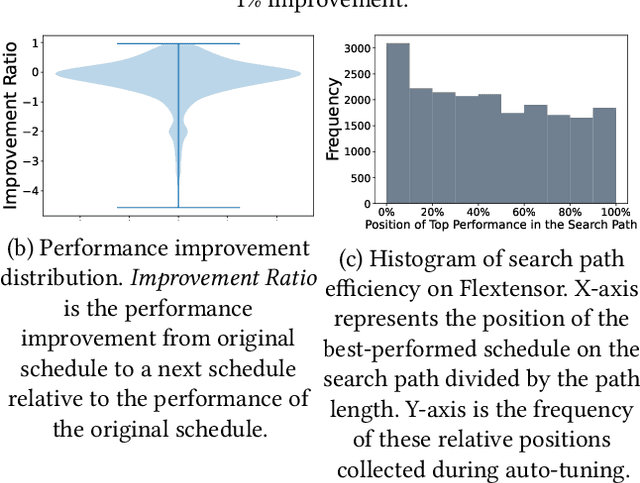
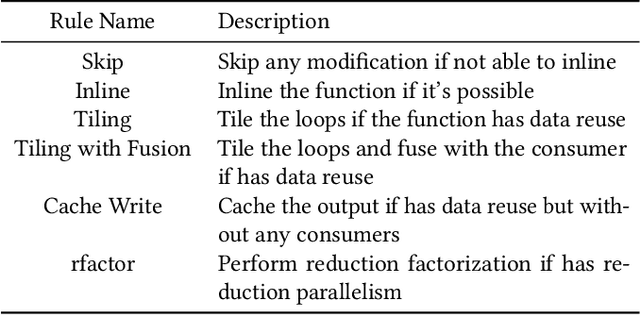
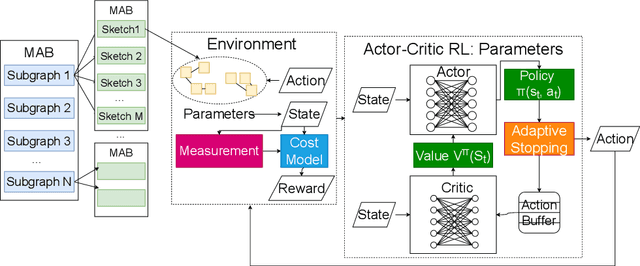
To efficiently perform inference with neural networks, the underlying tensor programs require sufficient tuning efforts before being deployed into production environments. Usually, enormous tensor program candidates need to be sufficiently explored to find the one with the best performance. This is necessary to make the neural network products meet the high demand of real-world applications such as natural language processing, auto-driving, etc. Auto-schedulers are being developed to avoid the need for human intervention. However, due to the gigantic search space and lack of intelligent search guidance, current auto-schedulers require hours to days of tuning time to find the best-performing tensor program for the entire neural network. In this paper, we propose HARL, a reinforcement learning (RL) based auto-scheduler specifically designed for efficient tensor program exploration. HARL uses a hierarchical RL architecture in which learning-based decisions are made at all different levels of search granularity. It also automatically adjusts exploration configurations in real-time for faster performance convergence. As a result, HARL improves the tensor operator performance by 22% and the search speed by 4.3x compared to the state-of-the-art auto-scheduler. Inference performance and search speed are also significantly improved on end-to-end neural networks.