 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How do Authors' Perceptions of their Papers Compare with Co-authors' Perceptions and Peer-review Decisions?
Nov 22, 2022

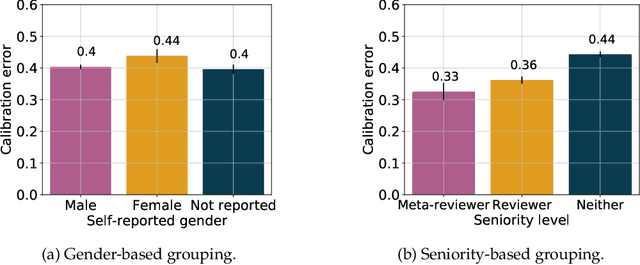
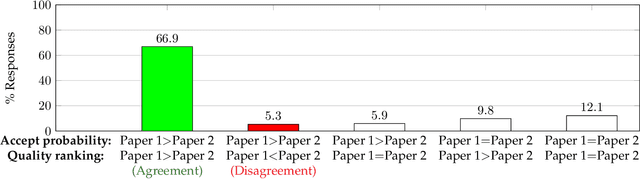
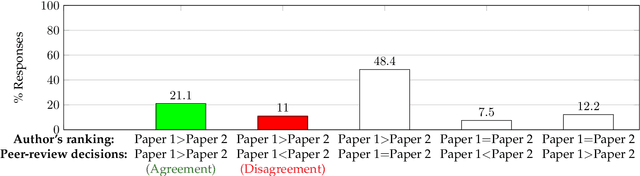
How do author perceptions match up to the outcomes of the peer-review process and perceptions of others? In a top-tier computer science conference (NeurIPS 2021) with more than 23,000 submitting authors and 9,000 submitted papers, we survey the authors on three questions: (i) their predicted probability of acceptance for each of their papers, (ii) their perceived ranking of their own papers based on scientific contribution, and (iii) the change in their perception about their own papers after seeing the reviews. The salient results are: (1) Authors have roughly a three-fold overestimate of the acceptance probability of their papers: The median prediction is 70% for an approximately 25% acceptance rate. (2) Female authors exhibit a marginally higher (statistically significant) miscalibration than male authors; predictions of authors invited to serve as meta-reviewers or reviewers are similarly calibrated, but better than authors who were not invited to review. (3) Authors' relative ranking of scientific contribution of two submissions they made generally agree (93%) with their predicted acceptance probabilities, but there is a notable 7% responses where authors think their better paper will face a worse outcome. (4) The author-provided rankings disagreed with the peer-review decisions about a third of the time; when co-authors ranked their jointly authored papers, co-authors disagreed at a similar rate -- about a third of the time. (5) At least 30% of respondents of both accepted and rejected papers said that their perception of their own paper improved after the review process. The stakeholders in peer review should take these findings into account in setting their expectations from peer review.
Asynchronous Training Schemes in Distributed Learning with Time Delay
Aug 28, 2022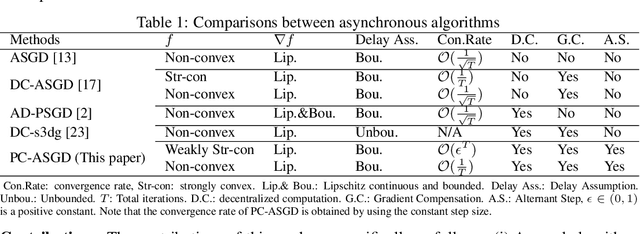
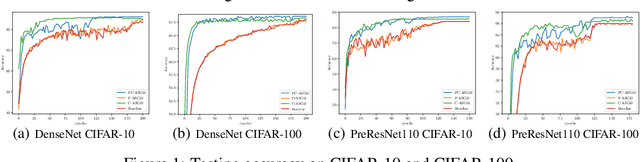

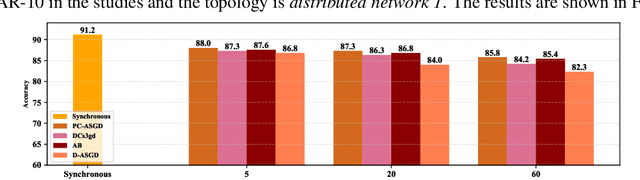
In the context of distributed deep learning, the issue of stale weights or gradients could result in poor algorithmic performance. This issue is usually tackled by delay tolerant algorithms with some mild assumptions on the objective functions and step sizes. In this paper, we propose a different approach to develop a new algorithm, called $\textbf{P}$redicting $\textbf{C}$lipping $\textbf{A}$synchronous $\textbf{S}$tochastic $\textbf{G}$radient $\textbf{D}$escent (aka, PC-ASGD). Specifically, PC-ASGD has two steps - the $\textit{predicting step}$ leverages the gradient prediction using Taylor expansion to reduce the staleness of the outdated weights while the $\textit{clipping step}$ selectively drops the outdated weights to alleviate their negative effects. A tradeoff parameter is introduced to balance the effects between these two steps. Theoretically, we present the convergence rate considering the effects of delay of the proposed algorithm with constant step size when the smooth objective functions are weakly strongly-convex and nonconvex. One practical variant of PC-ASGD is also proposed by adopting a condition to help with the determination of the tradeoff parameter. For empirical validation, we demonstrate the performance of the algorithm with two deep neural network architectures on two benchmark datasets.
Large Scale Time-Series Representation Learning via Simultaneous Low and High Frequency Feature Bootstrapping
Apr 24, 2022


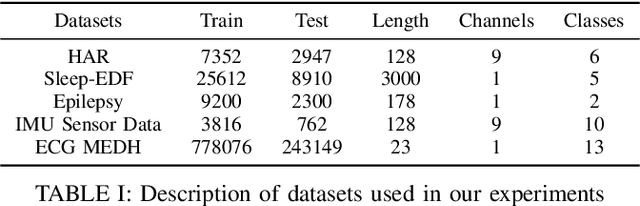
Learning representation from unlabeled time series data is a challenging problem. Most existing self-supervised and unsupervised approaches in the time-series domain do not capture low and high-frequency features at the same time. Further, some of these methods employ large scale models like transformers or rely on computationally expensive techniques such as contrastive learning. To tackle these problems, we propose a non-contrastive self-supervised learning approach efficiently captures low and high-frequency time-varying features in a cost-effective manner. Our method takes raw time series data as input and creates two different augmented views for two branches of the model, by randomly sampling the augmentations from same family. Following the terminology of BYOL, the two branches are called online and target network which allows bootstrapping of the latent representation. In contrast to BYOL, where a backbone encoder is followed by multilayer perceptron (MLP) heads, the proposed model contains additional temporal convolutional network (TCN) heads. As the augmented views are passed through large kernel convolution blocks of the encoder, the subsequent combination of MLP and TCN enables an effective representation of low as well as high-frequency time-varying features due to the varying receptive fields. The two modules (MLP and TCN) act in a complementary manner. We train an online network where each module learns to predict the outcome of the respective module of target network branch. To demonstrate the robustness of our model we performed extensive experiments and ablation studies on five real-world time-series datasets. Our method achieved state-of-art performance on all five real-world datasets.
Synaptic Dynamics Realize First-order Adaptive Learning and Weight Symmetry
Dec 01, 2022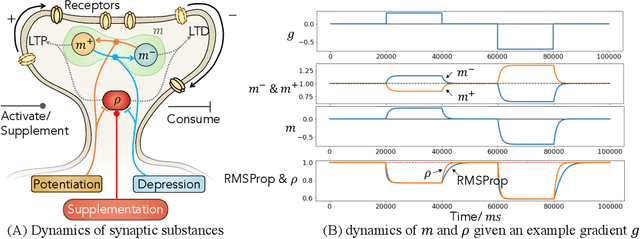
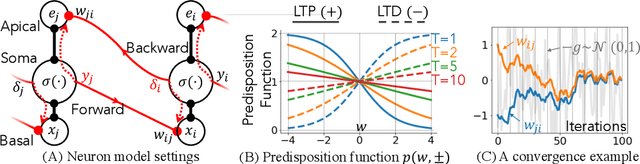
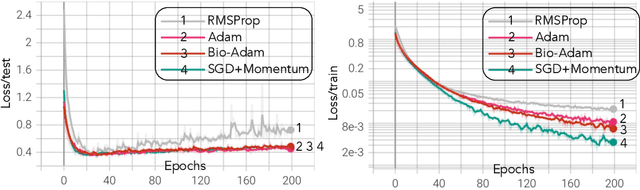
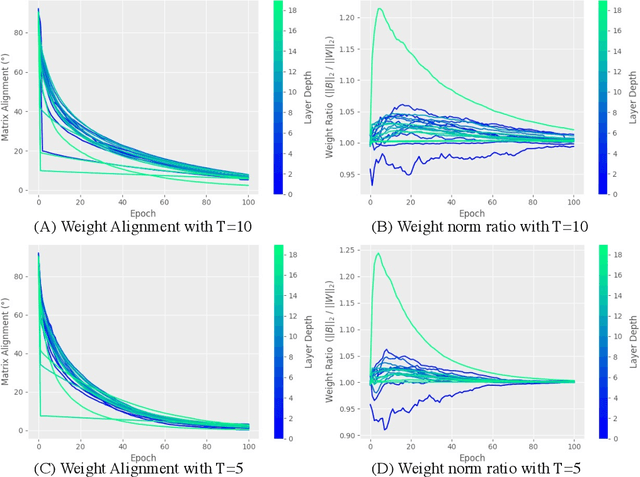
Gradient-based first-order adaptive optimization methods such as the Adam optimizer are prevalent in training artificial networks, achieving the state-of-the-art results. This work attempts to answer the question whether it is viable for biological neural systems to adopt such optimization methods. To this end, we demonstrate a realization of the Adam optimizer using biologically-plausible mechanisms in synapses. The proposed learning rule has clear biological correspondence, runs continuously in time, and achieves performance to comparable Adam's. In addition, we present a new approach, inspired by the predisposition property of synapses observed in neuroscience, to circumvent the biological implausibility of the weight transport problem in backpropagation (BP). With only local information and no separate training phases, this method establishes and maintains weight symmetry in the forward and backward signaling paths, and is applicable to the proposed biologically plausible Adam learning rule. These mechanisms may shed light on the way in which biological synaptic dynamics facilitate learning.
GMM-IL: Image Classification using Incrementally Learnt, Independent Probabilistic Models for Small Sample Sizes
Dec 01, 2022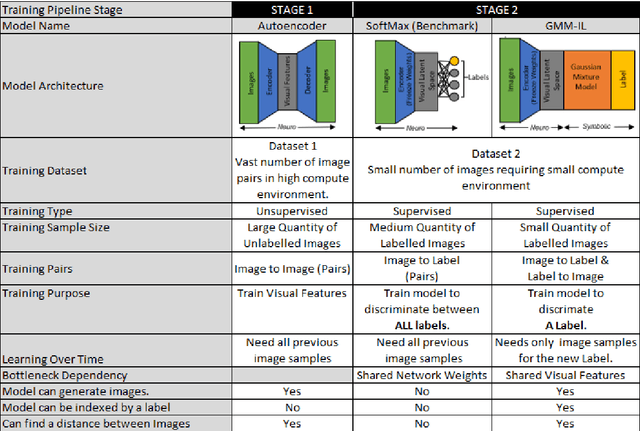
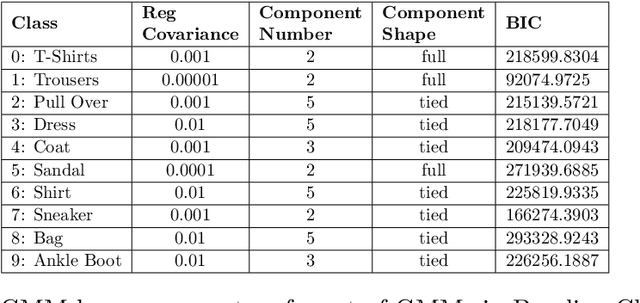
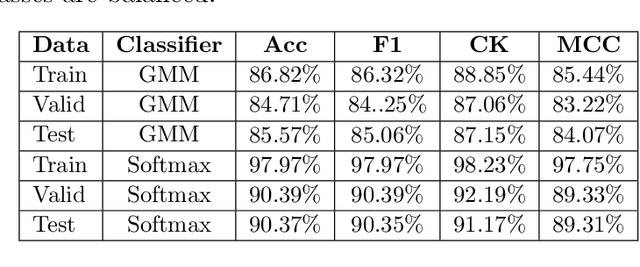
Current deep learning classifiers, carry out supervised learning and store class discriminatory information in a set of shared network weights. These weights cannot be easily altered to incrementally learn additional classes, since the classification weights all require retraining to prevent old class information from being lost and also require the previous training data to be present. We present a novel two stage architecture which couples visual feature learning with probabilistic models to represent each class in the form of a Gaussian Mixture Model. By using these independent class representations within our classifier, we outperform a benchmark of an equivalent network with a Softmax head, obtaining increased accuracy for sample sizes smaller than 12 and increased weighted F1 score for 3 imbalanced class profiles in that sample range. When learning new classes our classifier exhibits no catastrophic forgetting issues and only requires the new classes' training images to be present. This enables a database of growing classes over time which can be visually indexed and reasoned over.
Navigating an Ocean of Video Data: Deep Learning for Humpback Whale Classification in YouTube Videos
Dec 01, 2022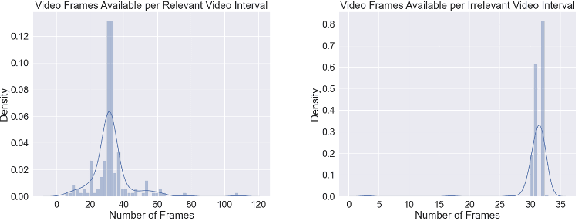
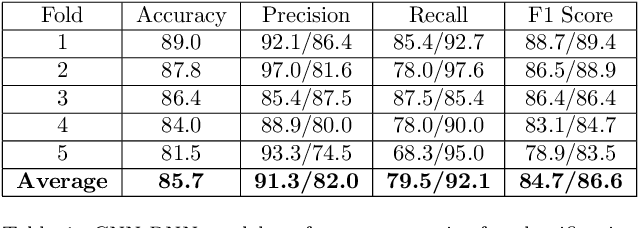
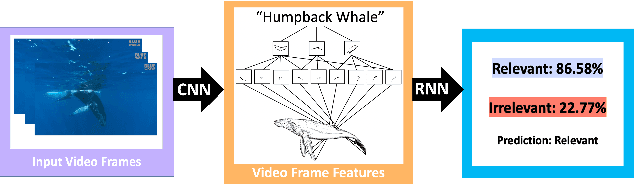

Image analysis technologies empowered by artificial intelligence (AI) have proved images and videos to be an opportune source of data to learn about humpback whale (Megaptera novaeangliae) population sizes and dynamics. With the advent of social media, platforms such as YouTube present an abundance of video data across spatiotemporal contexts documenting humpback whale encounters from users worldwide. In our work, we focus on automating the classification of YouTube videos as relevant or irrelevant based on whether they document a true humpback whale encounter or not via deep learning. We use a CNN-RNN architecture pretrained on the ImageNet dataset for classification of YouTube videos as relevant or irrelevant. We achieve an average 85.7% accuracy, and 84.7% (irrelevant)/ 86.6% (relevant) F1 scores using five-fold cross validation for evaluation on the dataset. We show that deep learning can be used as a time-efficient step to make social media a viable source of image and video data for biodiversity assessments.
TaDaa: real time Ticket Assignment Deep learning Auto Advisor for customer support, help desk, and issue ticketing systems
Jul 18, 2022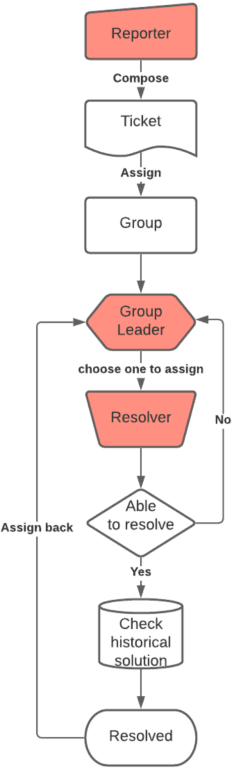
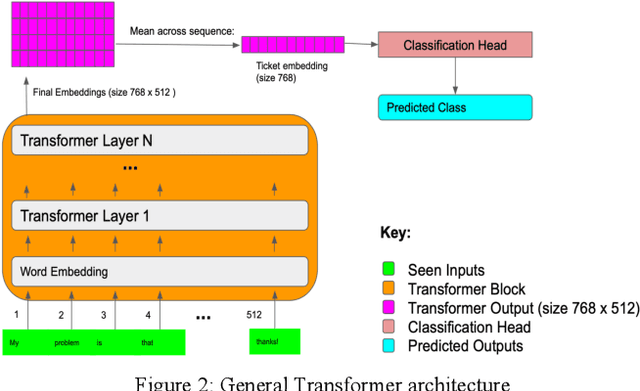
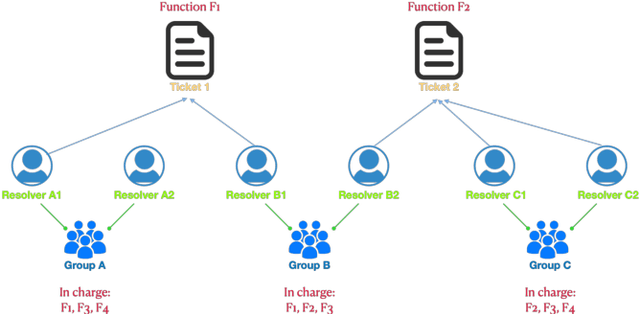
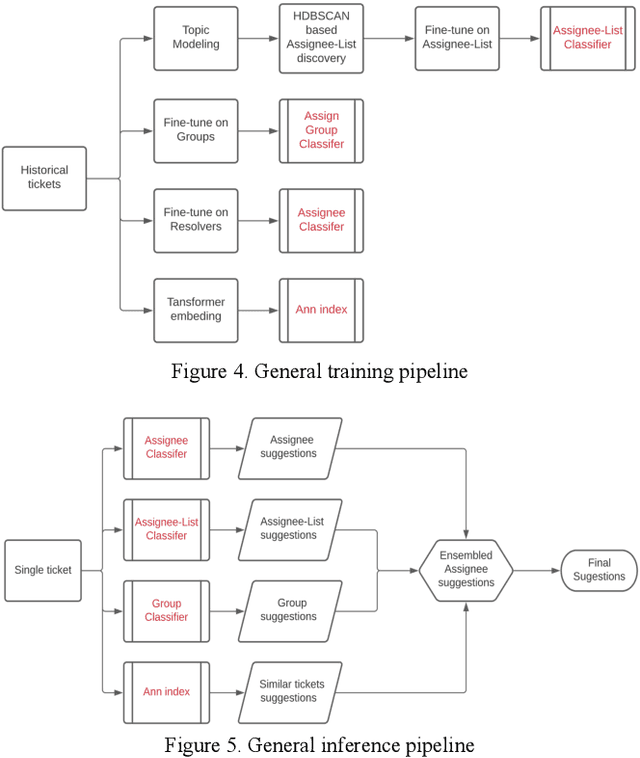
This paper proposes TaDaa: Ticket Assignment Deep learning Auto Advisor, which leverages the latest Transformers models and machine learning techniques quickly assign issues within an organization, like customer support, help desk and alike issue ticketing systems. The project provides functionality to 1) assign an issue to the correct group, 2) assign an issue to the best resolver, and 3) provide the most relevant previously solved tickets to resolvers. We leverage one ticketing system sample dataset, with over 3k+ groups and over 10k+ resolvers to obtain a 95.2% top 3 accuracy on group suggestions and a 79.0% top 5 accuracy on resolver suggestions. We hope this research will greatly improve average issue resolution time on customer support, help desk, and issue ticketing systems.
Elastic Product Quantization for Time Series
Jan 04, 2022
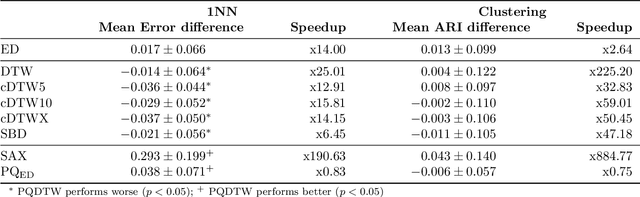


Analyzing numerous or long time series is difficult in practice due to the high storage costs and computational requirements. Therefore, techniques have been proposed to generate compact similarity-preserving representations of time series, enabling real-time similarity search on large in-memory data collections. However, the existing techniques are not ideally suited for assessing similarity when sequences are locally out of phase. In this paper, we propose the use of product quantization for efficient similarity-based comparison of time series under time warping. The idea is to first compress the data by partitioning the time series into equal length sub-sequences which are represented by a short code. The distance between two time series can then be efficiently approximated by pre-computed elastic distances between their codes. The partitioning into sub-sequences forces unwanted alignments, which we address with a pre-alignment step using the maximal overlap discrete wavelet transform (MODWT). To demonstrate the efficiency and accuracy of our method, we perform an extensive experimental evaluation on benchmark datasets in nearest neighbors classification and clustering applications. Overall, the proposed solution emerges as a highly efficient (both in terms of memory usage and computation time) replacement for elastic measures in time series applications.
Breadth-First Pipeline Parallelism
Nov 11, 2022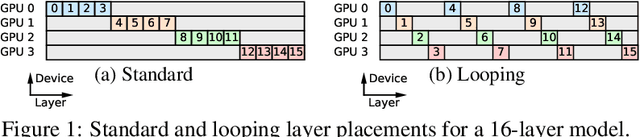
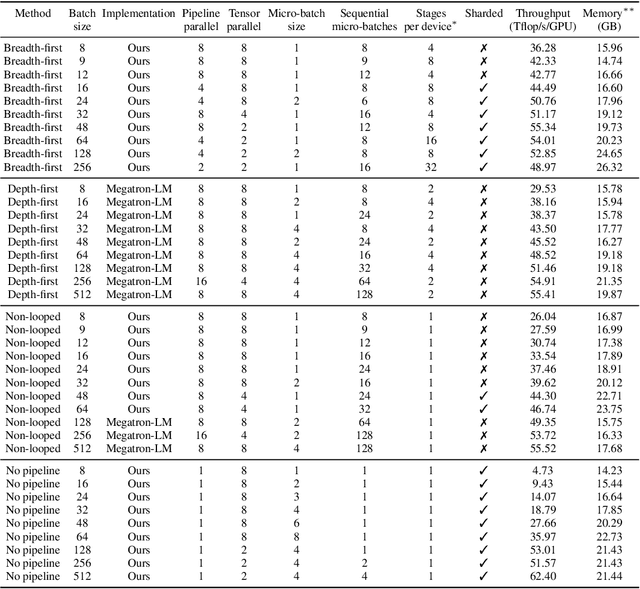

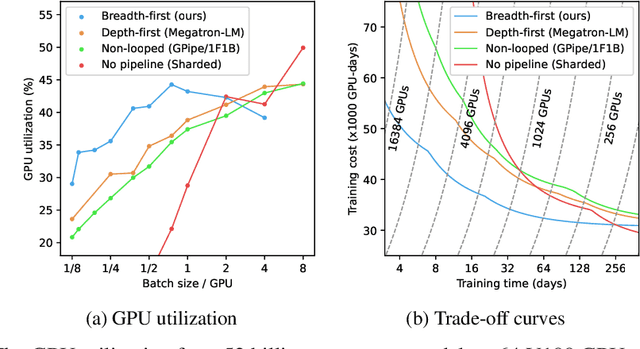
We introduce Breadth-First Pipeline Parallelism, a novel training schedule which optimizes the combination of pipeline and data parallelism. Breadth-First Pipeline Parallelism lowers training time, cost and memory usage by combining a high GPU utilization with a small batch size per GPU, and by making use of fully sharded data parallelism. Experimentally, we observed increases of up to 53% in training speed.
Deep subspace encoders for continuous-time state-space identification
Apr 20, 2022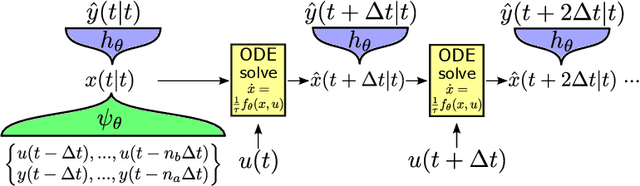
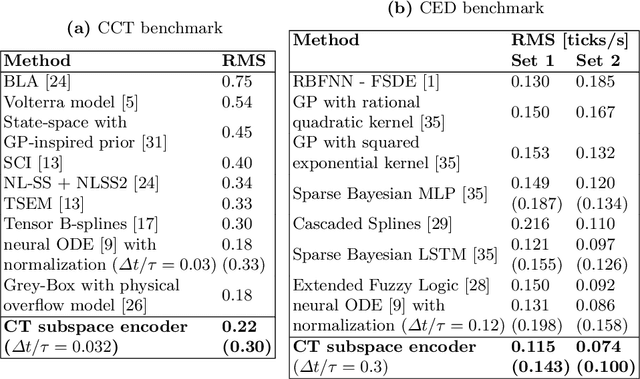
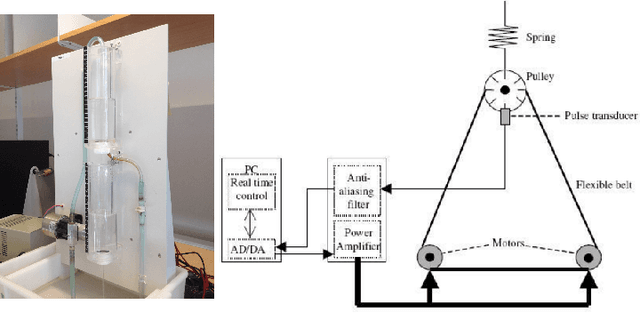
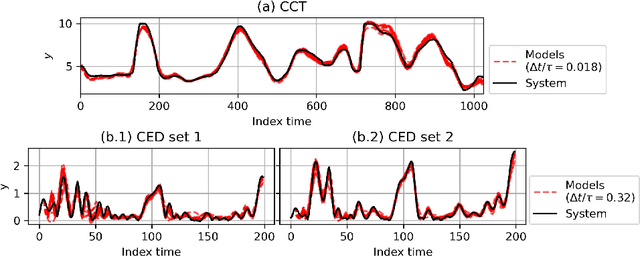
Continuous-time (CT) models have shown an improved sample efficiency during learning and enable ODE analysis methods for enhanced interpretability compared to discrete-time (DT) models. Even with numerous recent developments, the multifaceted CT state-space model identification problem remains to be solved in full, considering common experimental aspects such as the presence of external inputs, measurement noise, and latent states. This paper presents a novel estimation method that includes these aspects and that is able to obtain state-of-the-art results on multiple benchmarks where a small fully connected neural network describes the CT dynamics. The novel estimation method called the subspace encoder approach ascertains these results by altering the well-known simulation loss to include short subsections instead, by using an encoder function and a state-derivative normalization term to obtain a computationally feasible and stable optimization problem. This encoder function estimates the initial states of each considered subsection. We prove that the existence of the encoder function has the necessary condition of a Lipschitz continuous state-derivative utilizing established properties of ODEs.