 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ChatCite: LLM Agent with Human Workflow Guidance for Comparative Literature Summary
Mar 05, 2024
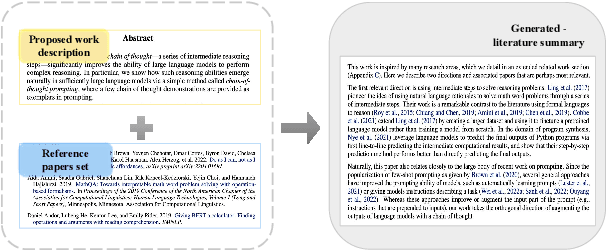
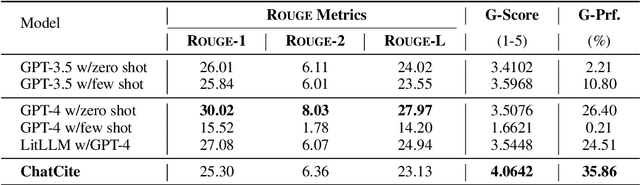
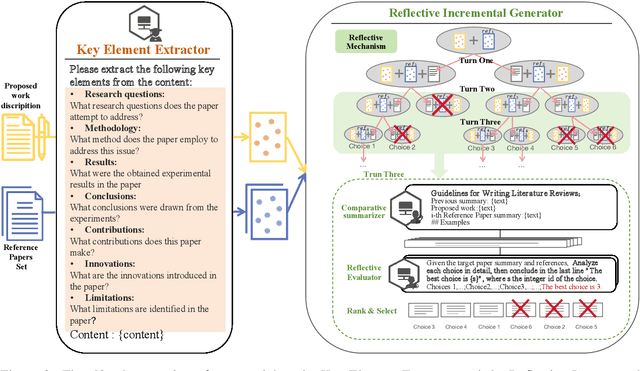
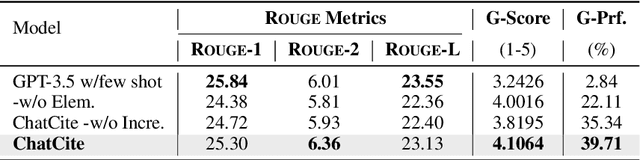
The literature review is an indispensable step in the research process. It provides the benefit of comprehending the research problem and understanding the current research situation while conducting a comparative analysis of prior works. However, literature summary is challenging and time consuming. The previous LLM-based studies on literature review mainly focused on the complete process, including literature retrieval, screening, and summarization. However, for the summarization step, simple CoT method often lacks the ability to provide extensive comparative summary. In this work, we firstly focus on the independent literature summarization step and introduce ChatCite, an LLM agent with human workflow guidance for comparative literature summary. This agent, by mimicking the human workflow, first extracts key elements from relevant literature and then generates summaries using a Reflective Incremental Mechanism. In order to better evaluate the quality of the generated summaries, we devised a LLM-based automatic evaluation metric, G-Score, in refer to the human evaluation criteria. The ChatCite agent outperformed other models in various dimensions in the experiments. The literature summaries generated by ChatCite can also be directly used for drafting literature reviews.
Online Learning of Human Constraints from Feedback in Shared Autonomy
Mar 05, 2024
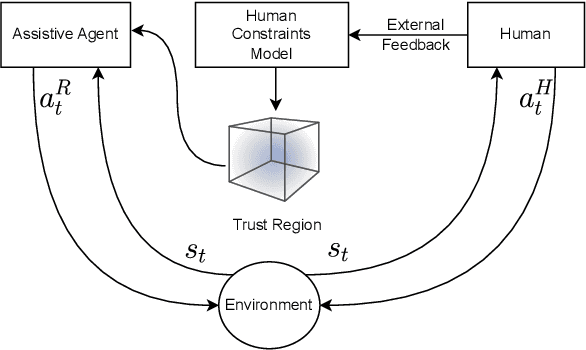

Real-time collaboration with humans poses challenges due to the different behavior patterns of humans resulting from diverse physical constraints. Existing works typically focus on learning safety constraints for collaboration, or how to divide and distribute the subtasks between the participating agents to carry out the main task. In contrast, we propose to learn a human constraints model that, in addition, considers the diverse behaviors of different human operators. We consider a type of collaboration in a shared-autonomy fashion, where both a human operator and an assistive robot act simultaneously in the same task space that affects each other's actions. The task of the assistive agent is to augment the skill of humans to perform a shared task by supporting humans as much as possible, both in terms of reducing the workload and minimizing the discomfort for the human operator. Therefore, we propose an augmentative assistant agent capable of learning and adapting to human physical constraints, aligning its actions with the ergonomic preferences and limitations of the human operator.
Motion-Corrected Moving Average: Including Post-Hoc Temporal Information for Improved Video Segmentation
Mar 05, 2024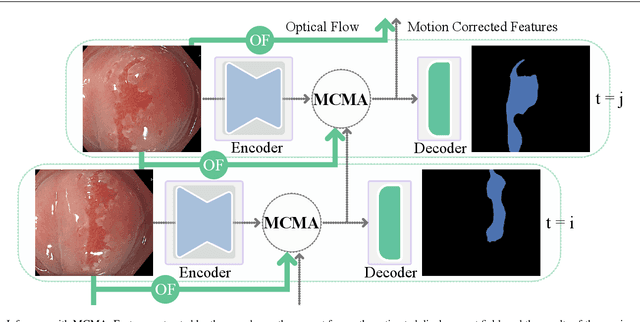
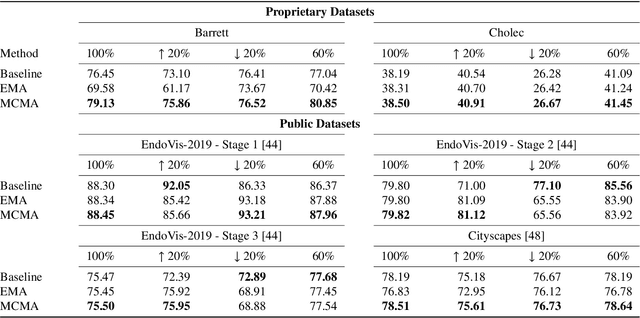
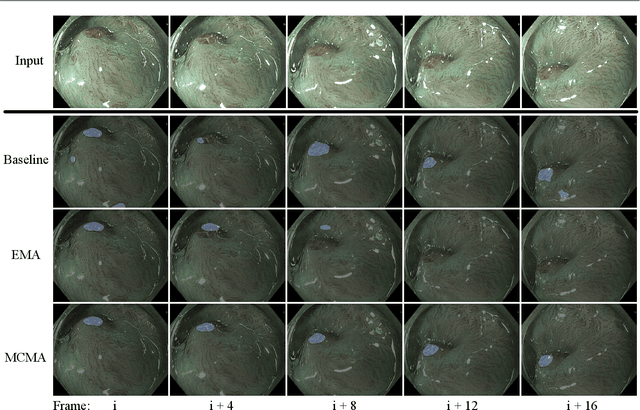
Real-time computational speed and a high degree of precision are requirements for computer-assisted interventions. Applying a segmentation network to a medical video processing task can introduce significant inter-frame prediction noise. Existing approaches can reduce inconsistencies by including temporal information but often impose requirements on the architecture or dataset. This paper proposes a method to include temporal information in any segmentation model and, thus, a technique to improve video segmentation performance without alterations during training or additional labeling. With Motion-Corrected Moving Average, we refine the exponential moving average between the current and previous predictions. Using optical flow to estimate the movement between consecutive frames, we can shift the prior term in the moving-average calculation to align with the geometry of the current frame. The optical flow calculation does not require the output of the model and can therefore be performed in parallel, leading to no significant runtime penalty for our approach. We evaluate our approach on two publicly available segmentation datasets and two proprietary endoscopic datasets and show improvements over a baseline approach.
Simplicity in Complexity
Mar 05, 2024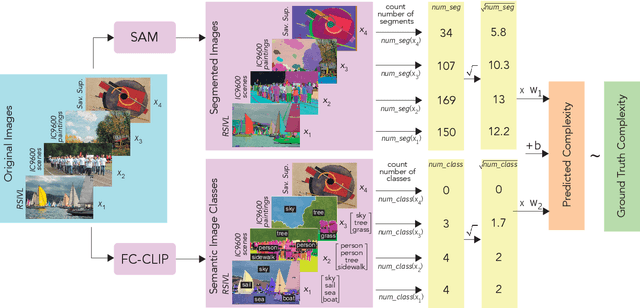
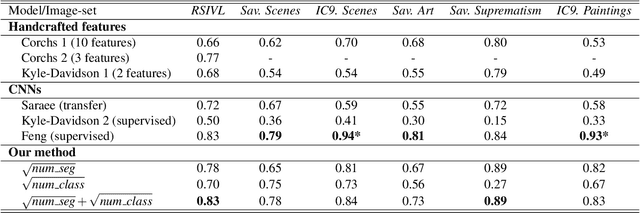
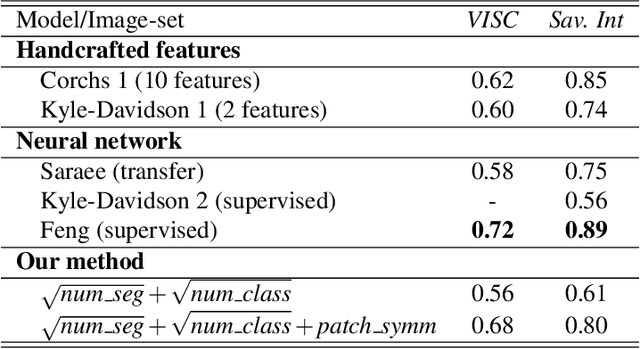

The complexity of visual stimuli plays an important role in many cognitive phenomena, including attention, engagement, memorability, time perception and aesthetic evaluation. Despite its importance, complexity is poorly understood and ironically, previous models of image complexity have been quite \textit{complex}. There have been many attempts to find handcrafted features that explain complexity, but these features are usually dataset specific, and hence fail to generalise. On the other hand, more recent work has employed deep neural networks to predict complexity, but these models remain difficult to interpret, and do not guide a theoretical understanding of the problem. Here we propose to model complexity using segment-based representations of images. We use state-of-the-art segmentation models, SAM and FC-CLIP, to quantify the number of segments at multiple granularities, and the number of classes in an image respectively. We find that complexity is well-explained by a simple linear model with these two features across six diverse image-sets of naturalistic scene and art images. This suggests that the complexity of images can be surprisingly simple.
Explain Variance of Prediction in Variational Time Series Models for Clinical Deterioration Prediction
Feb 15, 2024Missingness and measurement frequency are two sides of the same coin. How frequent should we measure clinical variables and conduct laboratory tests? It depends on many factors such as the stability of patient conditions, diagnostic process, treatment plan and measurement costs. The utility of measurements varies disease by disease, patient by patient. In this study we propose a novel view of clinical variable measurement frequency from a predictive modeling perspective, namely the measurements of clinical variables reduce uncertainty in model predictions. To achieve this goal, we propose variance SHAP with variational time series models, an application of Shapley Additive Expanation(SHAP) algorithm to attribute epistemic prediction uncertainty. The prediction variance is estimated by sampling the conditional hidden space in variational models and can be approximated deterministically by delta's method. This approach works with variational time series models such as variational recurrent neural networks and variational transformers. Since SHAP values are additive, the variance SHAP of binary data imputation masks can be directly interpreted as the contribution to prediction variance by measurements. We tested our ideas on a public ICU dataset with deterioration prediction task and study the relation between variance SHAP and measurement time intervals.
Arbitrary Discrete Fourier Analysis and Its Application in Replayed Speech Detection
Mar 02, 2024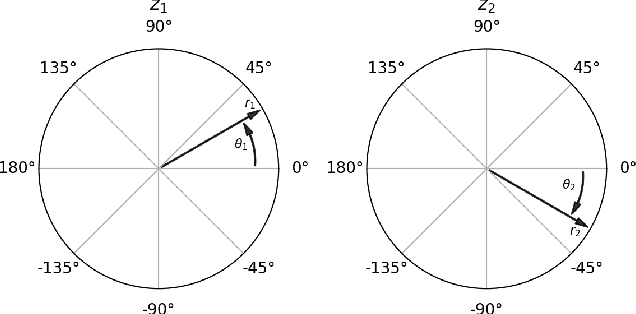
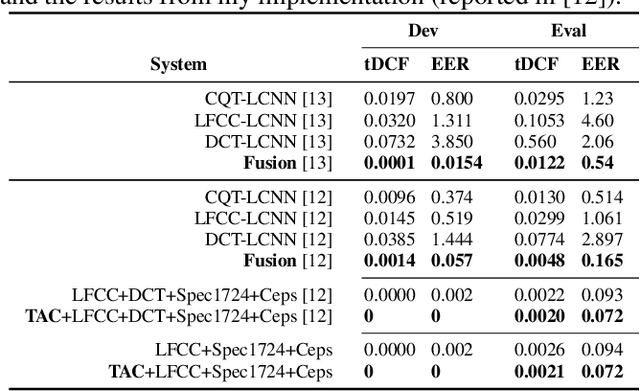
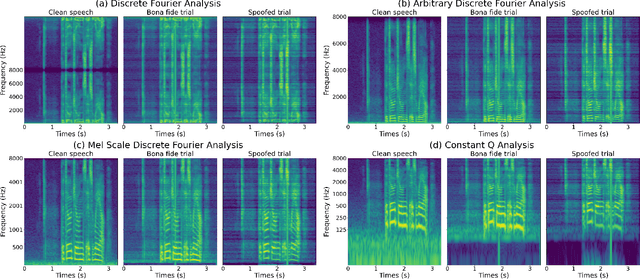
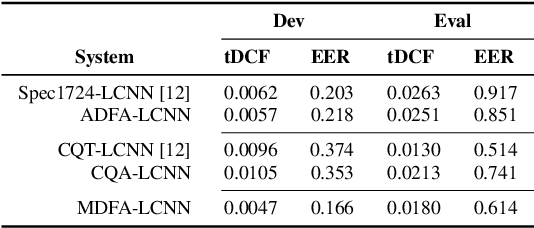
In this paper, a signal analysis concept is derived when revisiting how a specific frequency component in spectrum is analyzed in Fourier analysis. Three signal analysis methods are then developed based on the derived concept, namely Arbitrary Discrete Fourier Analysis (ADFA), Mel-scale Discrete Fourier Analysis (MDFA), and constant Q Analysis (CQA). I validate the effectiveness of these three signal analysis methods by testing their performance on a replayed speech detection benchmark (i.e., the ASVspoof 2019 Physical Access) along with a state-of-the-art model. Experimental results show that the performance of these three signal analysis methods is comparable to the best reported systems. At the same time, it is show that the computation time of the developed method CQA is much shorter than the convention method constant Q Transform, which is commonly used in spoofed and fake speech detection and music processing.
A Deep-Learning Technique to Locate Cryptographic Operations in Side-Channel Traces
Feb 29, 2024Side-channel attacks allow extracting secret information from the execution of cryptographic primitives by correlating the partially known computed data and the measured side-channel signal. However, to set up a successful side-channel attack, the attacker has to perform i) the challenging task of locating the time instant in which the target cryptographic primitive is executed inside a side-channel trace and then ii)the time-alignment of the measured data on that time instant. This paper presents a novel deep-learning technique to locate the time instant in which the target computed cryptographic operations are executed in the side-channel trace. In contrast to state-of-the-art solutions, the proposed methodology works even in the presence of trace deformations obtained through random delay insertion techniques. We validated our proposal through a successful attack against a variety of unprotected and protected cryptographic primitives that have been executed on an FPGA-implemented system-on-chip featuring a RISC-V CPU.
Time Series Diffusion in the Frequency Domain
Feb 08, 2024Fourier analysis has been an instrumental tool in the development of signal processing. This leads us to wonder whether this framework could similarly benefit generative modelling. In this paper, we explore this question through the scope of time series diffusion models. More specifically, we analyze whether representing time series in the frequency domain is a useful inductive bias for score-based diffusion models. By starting from the canonical SDE formulation of diffusion in the time domain, we show that a dual diffusion process occurs in the frequency domain with an important nuance: Brownian motions are replaced by what we call mirrored Brownian motions, characterized by mirror symmetries among their components. Building on this insight, we show how to adapt the denoising score matching approach to implement diffusion models in the frequency domain. This results in frequency diffusion models, which we compare to canonical time diffusion models. Our empirical evaluation on real-world datasets, covering various domains like healthcare and finance, shows that frequency diffusion models better capture the training distribution than time diffusion models. We explain this observation by showing that time series from these datasets tend to be more localized in the frequency domain than in the time domain, which makes them easier to model in the former case. All our observations point towards impactful synergies between Fourier analysis and diffusion models.
Semi-Supervised Semantic Segmentation Based on Pseudo-Labels: A Survey
Mar 04, 2024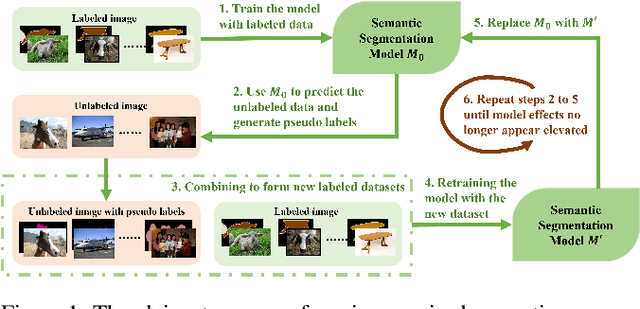
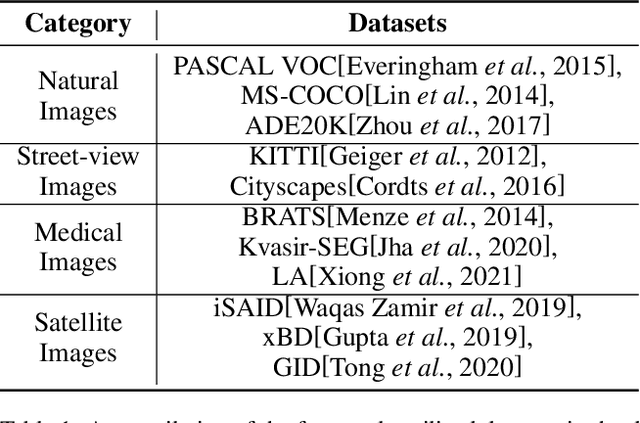
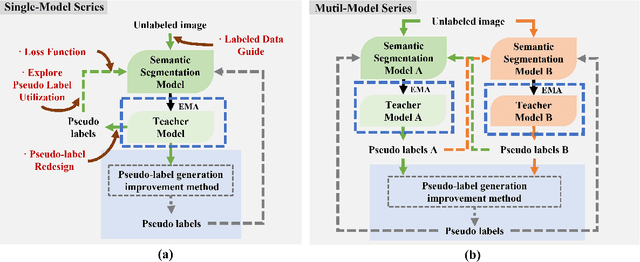
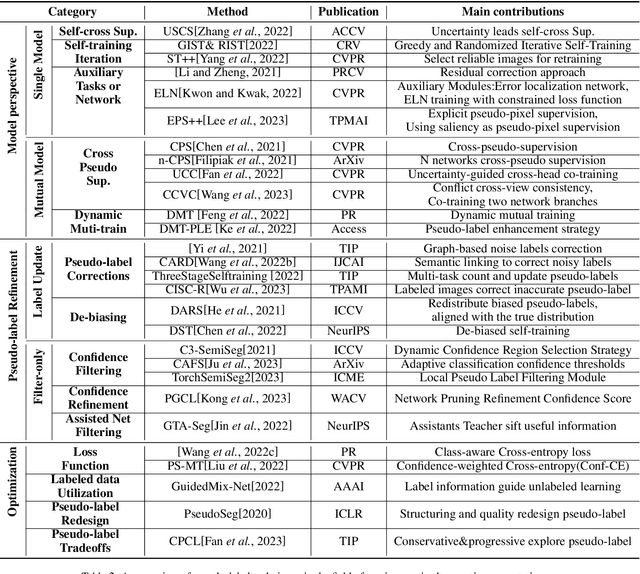
Semantic segmentation is an important and popular research area in computer vision that focuses on classifying pixels in an image based on their semantics. However, supervised deep learning requires large amounts of data to train models and the process of labeling images pixel by pixel is time-consuming and laborious. This review aims to provide a first comprehensive and organized overview of the state-of-the-art research results on pseudo-label methods in the field of semi-supervised semantic segmentation, which we categorize from different perspectives and present specific methods for specific application areas. In addition, we explore the application of pseudo-label technology in medical and remote-sensing image segmentation. Finally, we also propose some feasible future research directions to address the existing challenges.
Rethinking Clustered Federated Learning in NOMA Enhanced Wireless Networks
Mar 05, 2024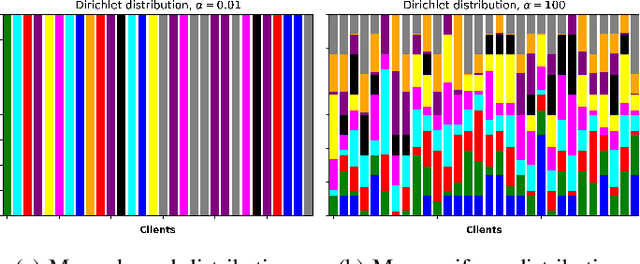
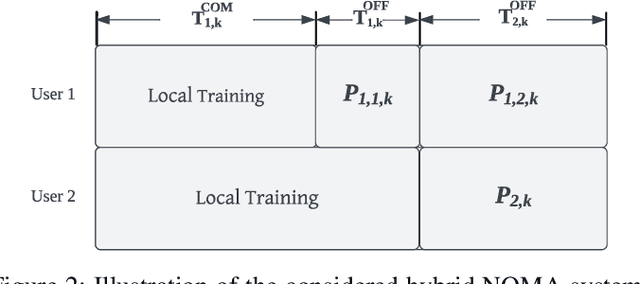
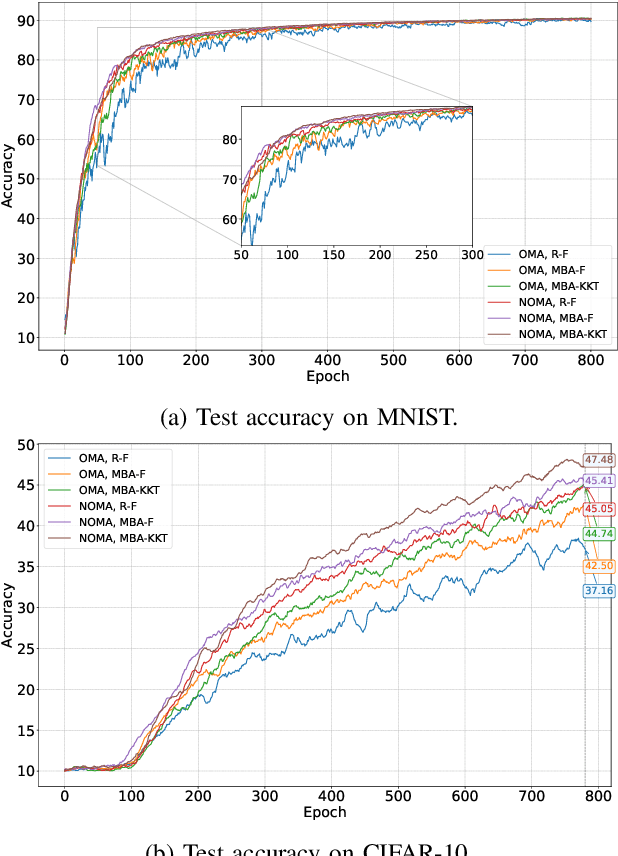
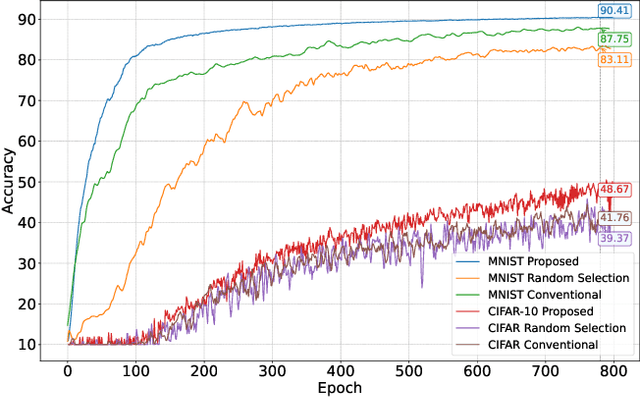
This study explores the benefits of integrating the novel clustered federated learning (CFL) approach with non-orthogonal multiple access (NOMA) under non-independent and identically distributed (non-IID) datasets, where multiple devices participate in the aggregation with time limitations and a finite number of sub-channels. A detailed theoretical analysis of the generalization gap that measures the degree of non-IID in the data distribution is presented. Following that, solutions to address the challenges posed by non-IID conditions are proposed with the analysis of the properties. Specifically, users' data distributions are parameterized as concentration parameters and grouped using spectral clustering, with Dirichlet distribution serving as the prior. The investigation into the generalization gap and convergence rate guides the design of sub-channel assignments through the matching-based algorithm, and the power allocation is achieved by Karush-Kuhn-Tucker (KKT) conditions with the derived closed-form solution. The extensive simulation results show that the proposed cluster-based FL framework can outperform FL baselines in terms of both test accuracy and convergence rate. Moreover, jointly optimizing sub-channel and power allocation in NOMA-enhanced networks can lead to a significant improvement.