 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
QVIP: An ILP-based Formal Verification Approach for Quantized Neural Networks
Dec 10, 2022

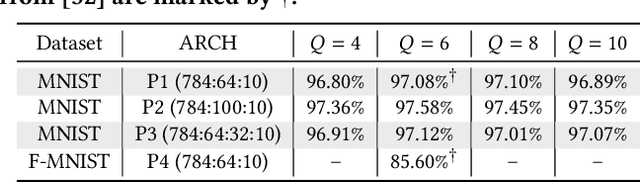

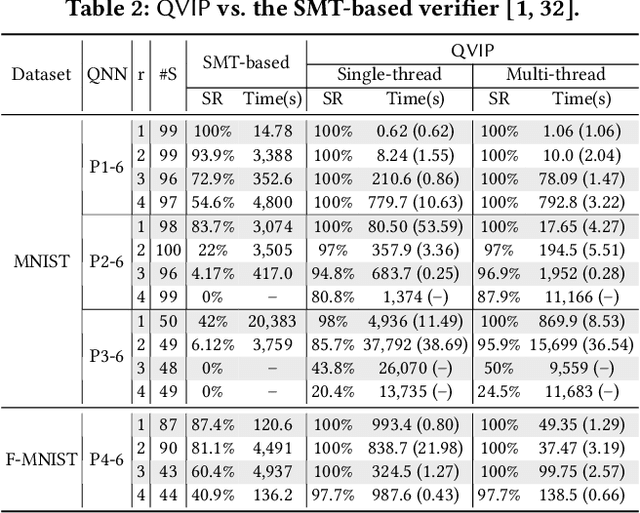
Deep learning has become a promising programming paradigm in software development, owing to its surprising performance in solving many challenging tasks. Deep neural networks (DNNs) are increasingly being deployed in practice, but are limited on resource-constrained devices owing to their demand for computational power. Quantization has emerged as a promising technique to reduce the size of DNNs with comparable accuracy as their floating-point numbered counterparts. The resulting quantized neural networks (QNNs) can be implemented energy-efficiently. Similar to their floating-point numbered counterparts, quality assurance techniques for QNNs, such as testing and formal verification, are essential but are currently less explored. In this work, we propose a novel and efficient formal verification approach for QNNs. In particular, we are the first to propose an encoding that reduces the verification problem of QNNs into the solving of integer linear constraints, which can be solved using off-the-shelf solvers. Our encoding is both sound and complete. We demonstrate the application of our approach on local robustness verification and maximum robustness radius computation. We implement our approach in a prototype tool QVIP and conduct a thorough evaluation. Experimental results on QNNs with different quantization bits confirm the effectiveness and efficiency of our approach, e.g., two orders of magnitude faster and able to solve more verification tasks in the same time limit than the state-of-the-art methods.
Hyperbolic Cosine Transformer for LiDAR 3D Object Detection
Nov 10, 2022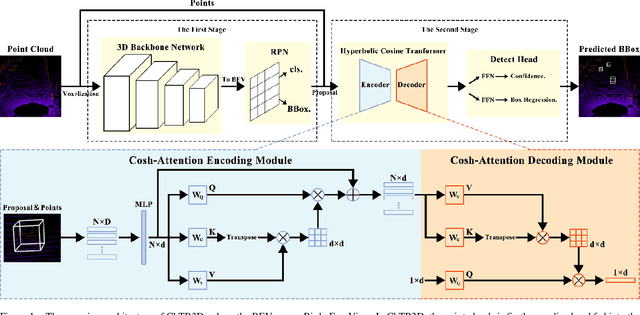
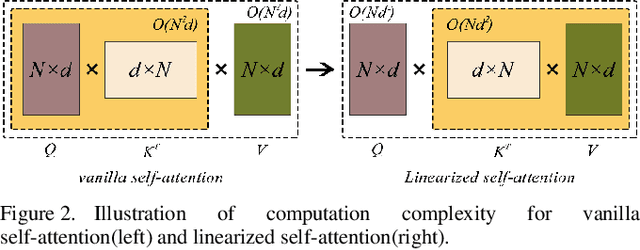
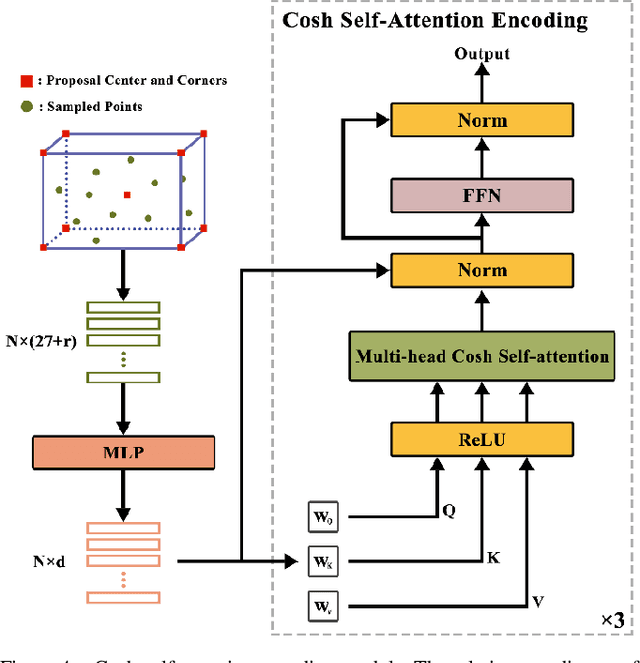
Recently, Transformer has achieved great success in computer vision. However, it is constrained because the spatial and temporal complexity grows quadratically with the number of large points in 3D object detection applications. Previous point-wise methods are suffering from time consumption and limited receptive fields to capture information among points. In this paper, we propose a two-stage hyperbolic cosine transformer (ChTR3D) for 3D object detection from LiDAR point clouds. The proposed ChTR3D refines proposals by applying cosh-attention in linear computation complexity to encode rich contextual relationships among points. The cosh-attention module reduces the space and time complexity of the attention operation. The traditional softmax operation is replaced by non-negative ReLU activation and hyperbolic-cosine-based operator with re-weighting mechanism. Extensive experiments on the widely used KITTI dataset demonstrate that, compared with vanilla attention, the cosh-attention significantly improves the inference speed with competitive performance. Experiment results show that, among two-stage state-of-the-art methods using point-level features, the proposed ChTR3D is the fastest one.
In-Flight Energy-Driven Composition of Drone Swarm Services
Oct 28, 2022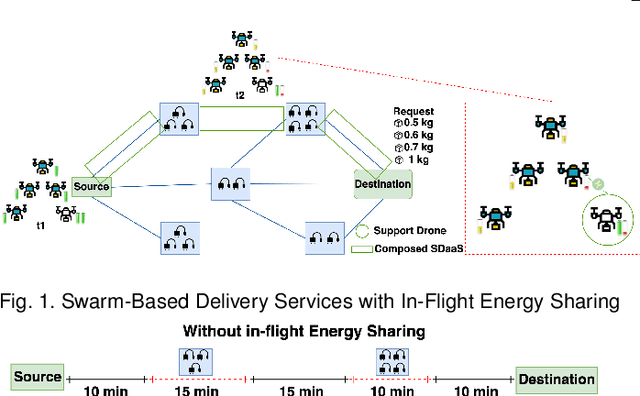

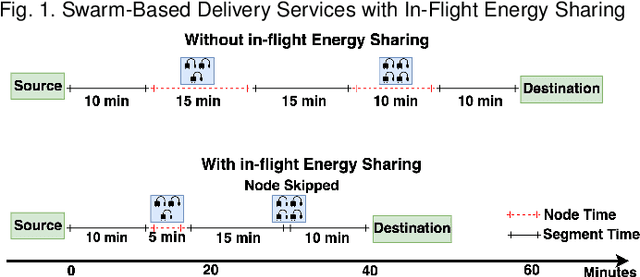

We propose a novel framework for swarm-based drone delivery services with in-flight energy recharging. The framework aims to enhance the delivery time of multiple packages by reducing the number of stops and recharging times at intermediate stations. The proposed framework considers various intrinsic and extrinsic delivery constraints. We propose to use support drones whose sole purpose is to recharge other drones in the swarm during their flight. In this respect, we compute the optimal set of optimal support drones to minimize the probability of delivery services and recharging time at the next stations. We also use two settings to position the support drones in a flight formation for comparative purposes. Two novel energy sharing methods are proposed, namely, Priority-based and Fairness-based methods. A re-ordering method of the delivery drones is presented to facilitate the in-flight energy composition process. An enhanced A* algorithm is implemented to compose the optimal services in terms of delivery time. Experimental results prove the efficiency of our proposed approach.
A New Deep Boosted CNN and Ensemble Learning based IoT Malware Detection
Dec 15, 2022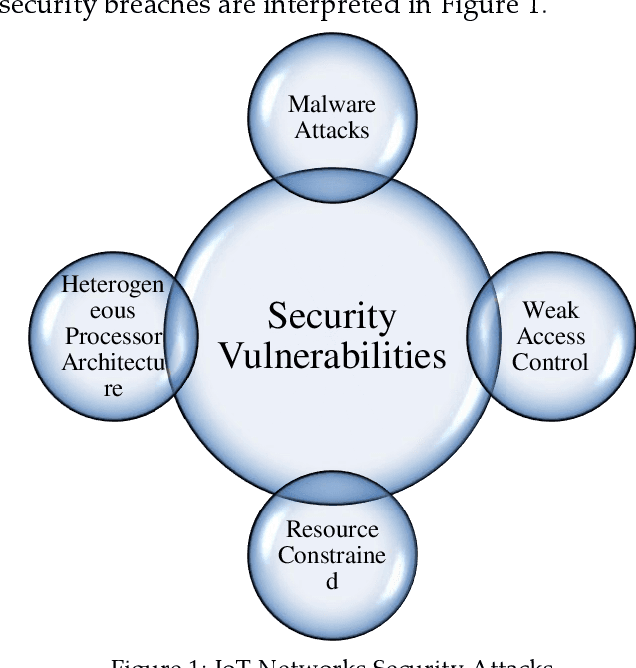
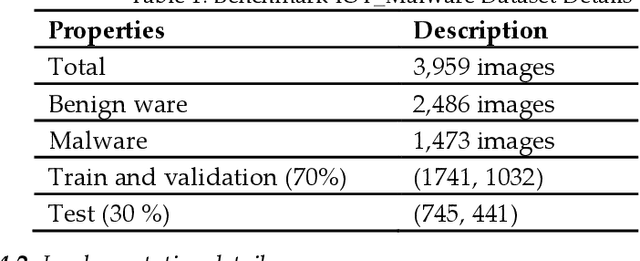
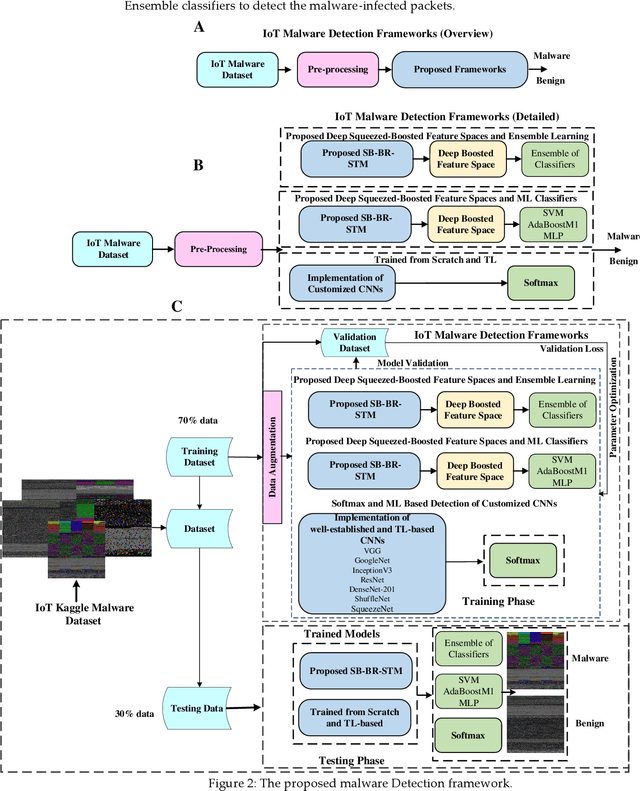
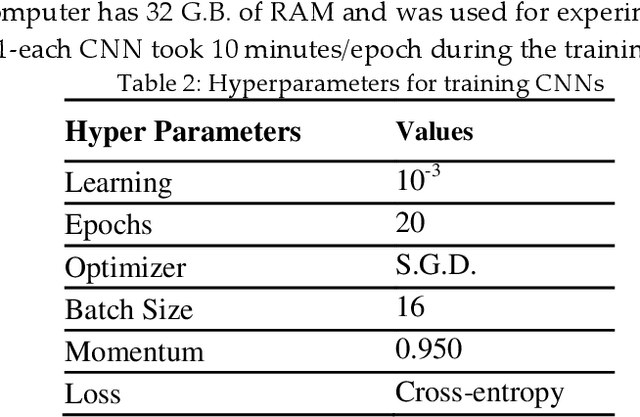
Security issues are threatened in various types of networks, especially in the Internet of Things (IoT) environment that requires early detection. IoT is the network of real-time devices like home automation systems and can be controlled by open-source android devices, which can be an open ground for attackers. Attackers can access the network, initiate a different kind of security breach, and compromises network control. Therefore, timely detecting the increasing number of sophisticated malware attacks is the challenge to ensure the credibility of network protection. In this regard, we have developed a new malware detection framework, Deep Squeezed-Boosted and Ensemble Learning (DSBEL), comprised of novel Squeezed-Boosted Boundary-Region Split-Transform-Merge (SB-BR-STM) CNN and ensemble learning. The proposed S.T.M. block employs multi-path dilated convolutional, Boundary, and regional operations to capture the homogenous and heterogeneous global malicious patterns. Moreover, diverse feature maps are achieved using transfer learning and multi-path-based squeezing and boosting at initial and final levels to learn minute pattern variations. Finally, the boosted discriminative features are extracted from the developed deep SB-BR-STM CNN and provided to the ensemble classifiers (SVM, M.L.P., and AdaboostM1) to improve the hybrid learning generalization. The performance analysis of the proposed DSBEL framework and SB-BR-STM CNN against the existing techniques have been evaluated by the IOT_Malware dataset on standard performance measures. Evaluation results show progressive performance as 98.50% accuracy, 97.12% F1-Score, 91.91% MCC, 95.97 % Recall, and 98.42 % Precision. The proposed malware analysis framework is helpful for the timely detection of malicious activity and suggests future strategies.
Combining information-seeking exploration and reward maximization: Unified inference on continuous state and action spaces under partial observability
Dec 15, 2022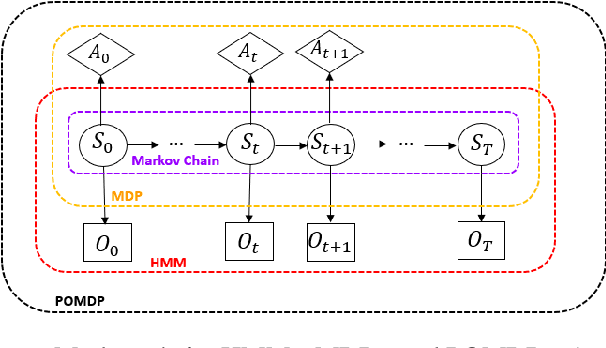

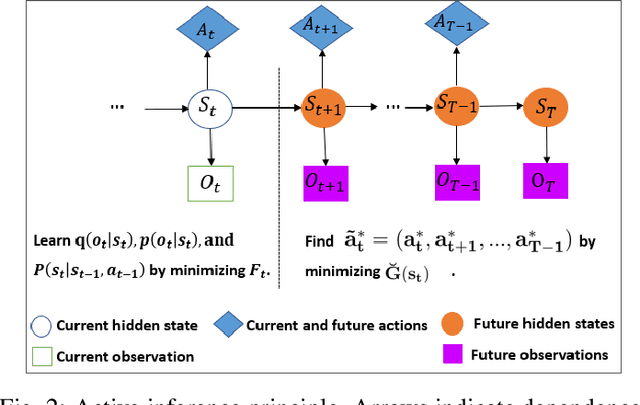

Reinforcement learning (RL) gained considerable attention by creating decision-making agents that maximize rewards received from fully observable environments. However, many real-world problems are partially or noisily observable by nature, where agents do not receive the true and complete state of the environment. Such problems are formulated as partially observable Markov decision processes (POMDPs). Some studies applied RL to POMDPs by recalling previous decisions and observations or inferring the true state of the environment from received observations. Nevertheless, aggregating observations and decisions over time is impractical for environments with high-dimensional continuous state and action spaces. Moreover, so-called inference-based RL approaches require large number of samples to perform well since agents eschew uncertainty in the inferred state for the decision-making. Active inference is a framework that is naturally formulated in POMDPs and directs agents to select decisions by minimising expected free energy (EFE). This supplies reward-maximising (exploitative) behaviour in RL, with an information-seeking (exploratory) behaviour. Despite this exploratory behaviour of active inference, its usage is limited to discrete state and action spaces due to the computational difficulty of the EFE. We propose a unified principle for joint information-seeking and reward maximization that clarifies a theoretical connection between active inference and RL, unifies active inference and RL, and overcomes their aforementioned limitations. Our findings are supported by strong theoretical analysis. The proposed framework's superior exploration property is also validated by experimental results on partial observable tasks with high-dimensional continuous state and action spaces. Moreover, the results show that our model solves reward-free problems, making task reward design optional.
Visually-augmented pretrained language models for NLP tasks without images
Dec 15, 2022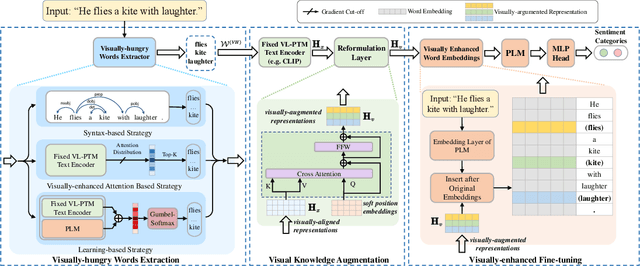
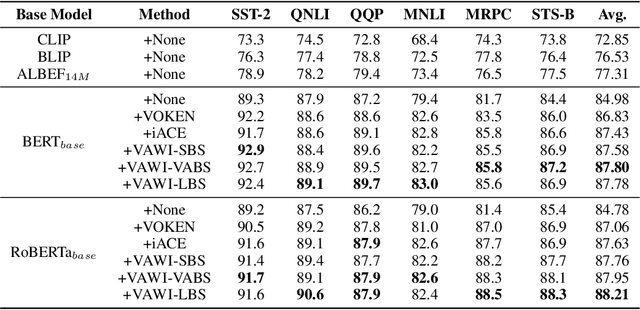
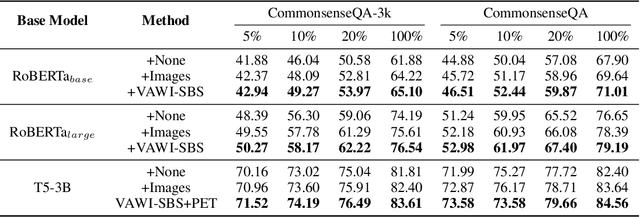
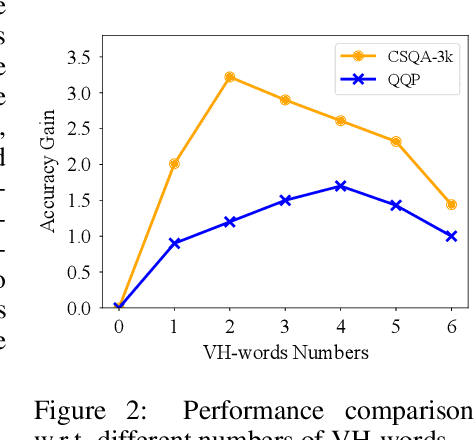
Although pre-trained language models (PLMs) have shown impressive performance by text-only self-supervised training, they are found lack of visual semantics or commonsense, e.g., sizes, shapes, and colors of commonplace objects. Existing solutions often rely on explicit images for visual knowledge augmentation (requiring time-consuming retrieval or generation), and they also conduct the augmentation for the whole input text, without considering whether it is actually needed in specific inputs or tasks. To address these issues, we propose a novel visually-augmented fine-tuning approach that can be generally applied to various PLMs or NLP tasks, without using any retrieved or generated images, namely VAWI. Specifically, we first identify the visually-hungry words (VH-words) from input text via a token selector, where three different methods have been proposed, including syntax-, attention- and learning-based strategies. Then, we adopt a fixed CLIP text encoder to generate the visually-augmented representations of these VH-words. As it has been pre-trained by vision-language alignment task on the large-scale corpus, it is capable of injecting visual semantics into the aligned text representations. Finally, the visually-augmented features will be fused and transformed into the pre-designed visual prompts based on VH-words, which can be inserted into PLMs to enrich the visual semantics in word representations. We conduct extensive experiments on ten NLP tasks, i.e., GLUE benchmark, CommonsenseQA, CommonGen, and SNLI-VE. Experimental results show that our approach can consistently improve the performance of BERT, RoBERTa, BART, and T5 at different scales, and outperform several competitive baselines significantly. Our codes and data are publicly available at~\url{https://github.com/RUCAIBox/VAWI}.
Routine Outcome Monitoring in Psychotherapy Treatment using Sentiment-Topic Modelling Approach
Dec 08, 2022
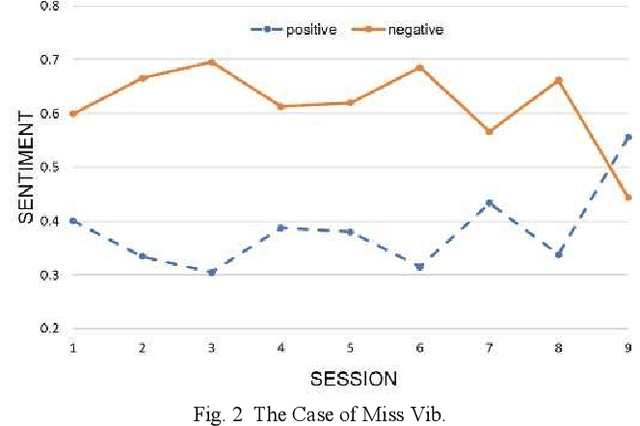
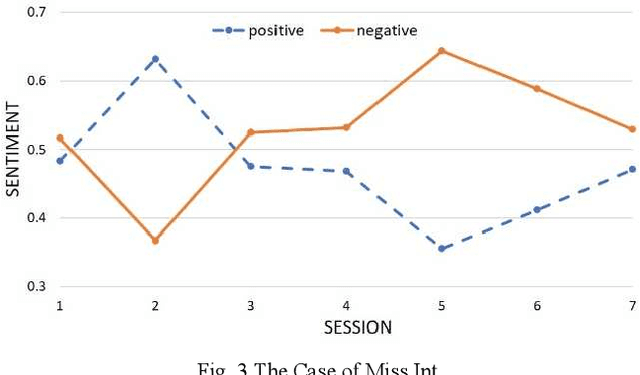
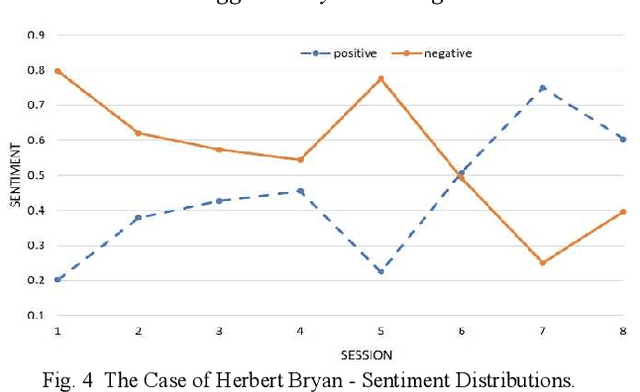
Despite the importance of emphasizing the right psychotherapy treatment for an individual patient, assessing the outcome of the therapy session is equally crucial. Evidence showed that continuous monitoring patient's progress can significantly improve the therapy outcomes to an expected change. By monitoring the outcome, the patient's progress can be tracked closely to help clinicians identify patients who are not progressing in the treatment. These monitoring can help the clinician to consider any necessary actions for the patient's treatment as early as possible, e.g., recommend different types of treatment, or adjust the style of approach. Currently, the evaluation system is based on the clinical-rated and self-report questionnaires that measure patients' progress pre- and post-treatment. While outcome monitoring tends to improve the therapy outcomes, however, there are many challenges in the current method, e.g. time and financial burden for administering questionnaires, scoring and analysing the results. Therefore, a computational method for measuring and monitoring patient progress over the course of treatment is needed, in order to enhance the likelihood of positive treatment outcome. Moreover, this computational method could potentially lead to an inexpensive monitoring tool to evaluate patients' progress in clinical care that could be administered by a wider range of health-care professionals.
Generalizing LTL Instructions via Future Dependent Options
Dec 08, 2022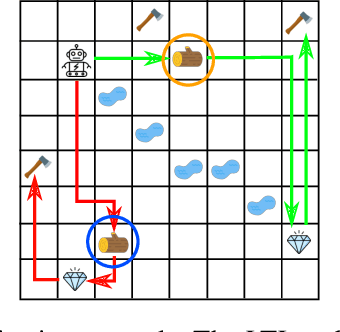
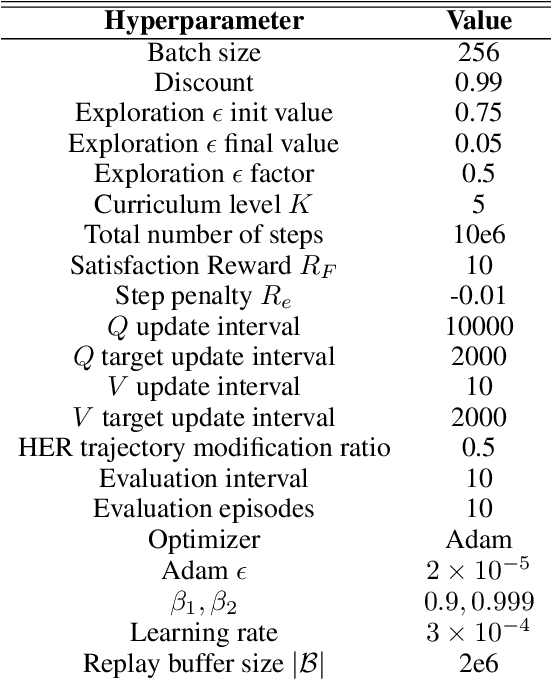

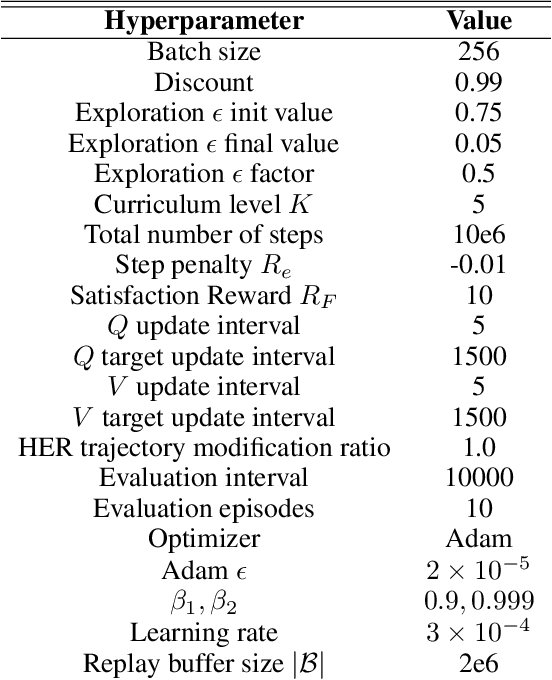
Linear temporal logic (LTL) is a widely-used task specification language which has a compositional grammar that naturally induces temporally extended behaviours across tasks, including conditionals and alternative realizations. An important problem i RL with LTL tasks is to learn task-conditioned policies which can zero-shot generalize to new LTL instructions not observed in the training. However, because symbolic observation is often lossy and LTL tasks can have long time horizon, previous works can suffer from issues such as training sampling inefficiency and infeasibility or sub-optimality of the found solutions. In order to tackle these issues, this paper proposes a novel multi-task RL algorithm with improved learning efficiency and optimality. To achieve the global optimality of task completion, we propose to learn options dependent on the future subgoals via a novel off-policy approach. In order to propagate the rewards of satisfying future subgoals back more efficiently, we propose to train a multi-step value function conditioned on the subgoal sequence which is updated with Monte Carlo estimates of multi-step discounted returns. In experiments on three different domains, we evaluate the LTL generalization capability of the agent trained by the proposed method, showing its advantage over previous representative methods.
Lie detection algorithms attract few users but vastly increase accusation rates
Dec 08, 2022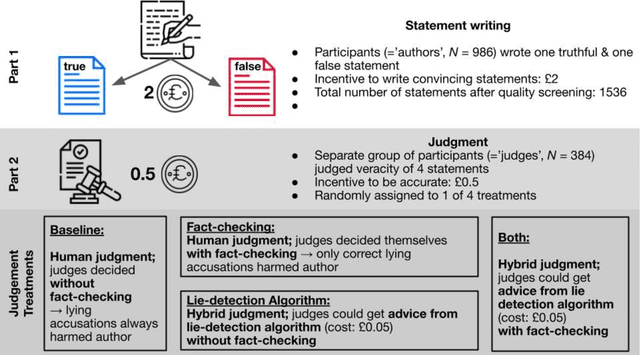
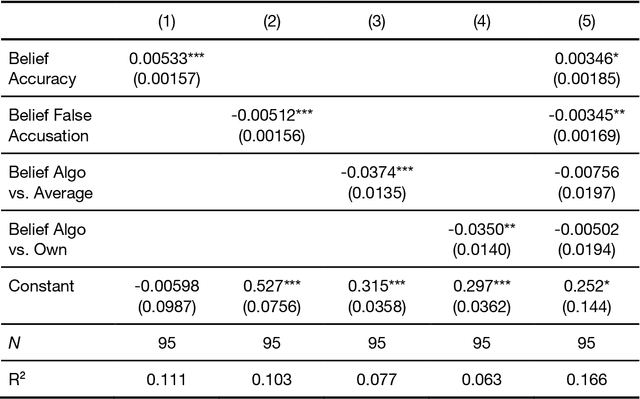
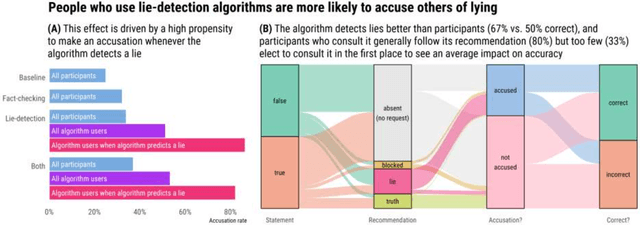
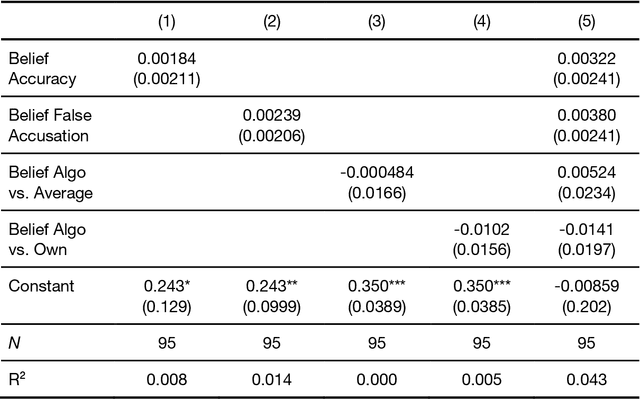
People are not very good at detecting lies, which may explain why they refrain from accusing others of lying, given the social costs attached to false accusations - both for the accuser and the accused. Here we consider how this social balance might be disrupted by the availability of lie-detection algorithms powered by Artificial Intelligence. Will people elect to use lie detection algorithms that perform better than humans, and if so, will they show less restraint in their accusations? We built a machine learning classifier whose accuracy (67\%) was significantly better than human accuracy (50\%) in a lie-detection task and conducted an incentivized lie-detection experiment in which we measured participants' propensity to use the algorithm, as well as the impact of that use on accusation rates. We find that the few people (33\%) who elect to use the algorithm drastically increase their accusation rates (from 25\% in the baseline condition up to 86% when the algorithm flags a statement as a lie). They make more false accusations (18pp increase), but at the same time, the probability of a lie remaining undetected is much lower in this group (36pp decrease). We consider individual motivations for using lie detection algorithms and the social implications of these algorithms.
Evaluating the Perceived Safety of Urban City via Maximum Entropy Deep Inverse Reinforcement Learning
Nov 27, 2022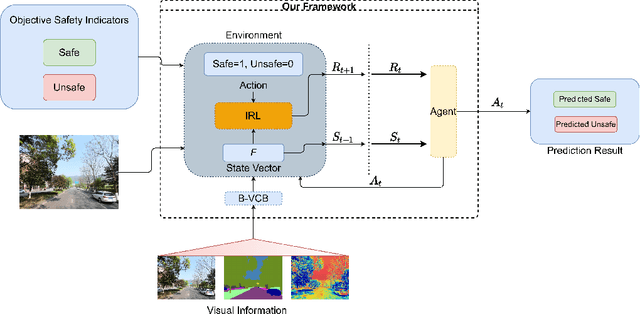


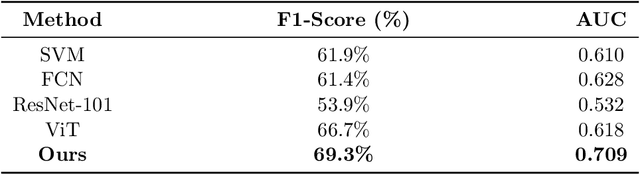
Inspired by expert evaluation policy for urban perception, we proposed a novel inverse reinforcement learning (IRL) based framework for predicting urban safety and recovering the corresponding reward function. We also presented a scalable state representation method to model the prediction problem as a Markov decision process (MDP) and use reinforcement learning (RL) to solve the problem. Additionally, we built a dataset called SmallCity based on the crowdsourcing method to conduct the research. As far as we know, this is the first time the IRL approach has been introduced to the urban safety perception and planning field to help experts quantitatively analyze perceptual features. Our results showed that IRL has promising prospects in this field. We will later open-source the crowdsourcing data collection site and the model proposed in this paper.