 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Predicting Human Mobility via Self-supervised Disentanglement Learning
Nov 17, 2022
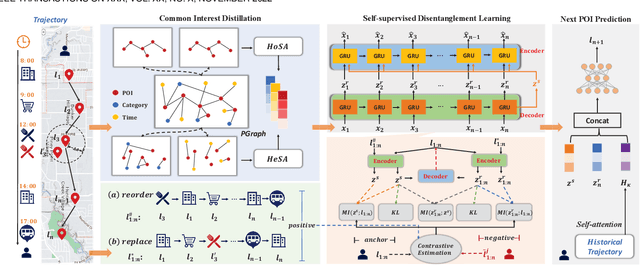
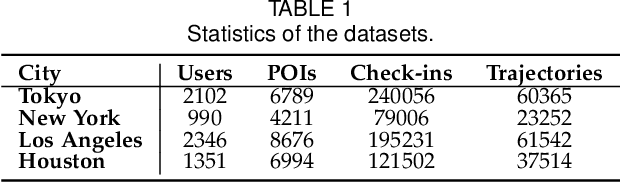
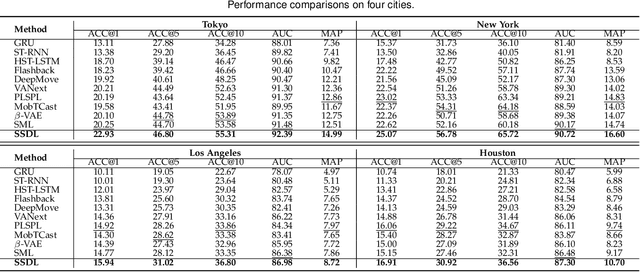

Deep neural networks have recently achieved considerable improvements in learning human behavioral patterns and individual preferences from massive spatial-temporal trajectories data. However, most of the existing research concentrates on fusing different semantics underlying sequential trajectories for mobility pattern learning which, in turn, yields a narrow perspective on comprehending human intrinsic motions. In addition, the inherent sparsity and under-explored heterogeneous collaborative items pertaining to human check-ins hinder the potential exploitation of human diverse periodic regularities as well as common interests. Motivated by recent advances in disentanglement learning, in this study we propose a novel disentangled solution called SSDL for tackling the next POI prediction problem. SSDL primarily seeks to disentangle the potential time-invariant and time-varying factors into different latent spaces from massive trajectories data, providing an interpretable view to understand the intricate semantics underlying human diverse mobility representations. To address the data sparsity issue, we present two realistic trajectory augmentation approaches to enhance the understanding of both the human intrinsic periodicity and constantly-changing intents. In addition, we devise a POI-centric graph structure to explore heterogeneous collaborative signals underlying historical check-ins. Extensive experiments conducted on four real-world datasets demonstrate that our proposed SSDL significantly outperforms the state-of-the-art approaches -- for example, it yields up to 8.57% improvements on ACC@1.
A Dynamic Meta-Learning Model for Time-Sensitive Cold-Start Recommendations
Apr 03, 2022
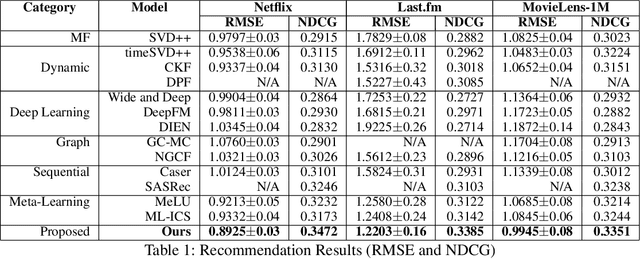
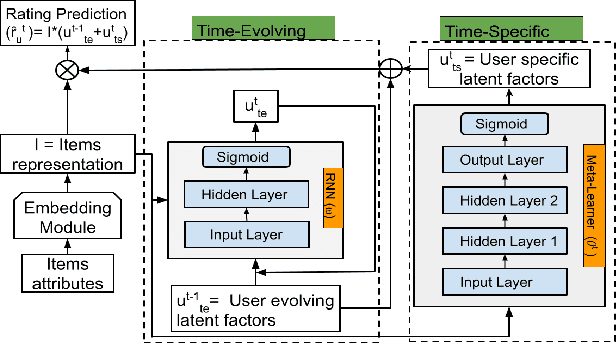
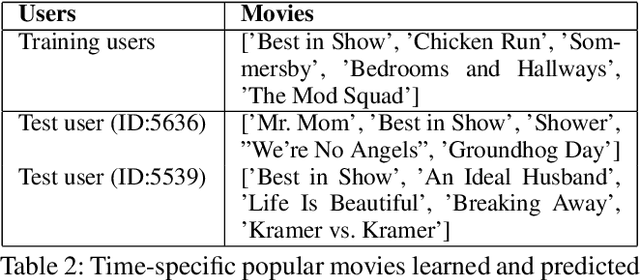
We present a novel dynamic recommendation model that focuses on users who have interactions in the past but turn relatively inactive recently. Making effective recommendations to these time-sensitive cold-start users is critical to maintain the user base of a recommender system. Due to the sparse recent interactions, it is challenging to capture these users' current preferences precisely. Solely relying on their historical interactions may also lead to outdated recommendations misaligned with their recent interests. The proposed model leverages historical and current user-item interactions and dynamically factorizes a user's (latent) preference into time-specific and time-evolving representations that jointly affect user behaviors. These latent factors further interact with an optimized item embedding to achieve accurate and timely recommendations. Experiments over real-world data help demonstrate the effectiveness of the proposed time-sensitive cold-start recommendation model.
Establishment of Neural Networks Robust to Label Noise
Dec 04, 2022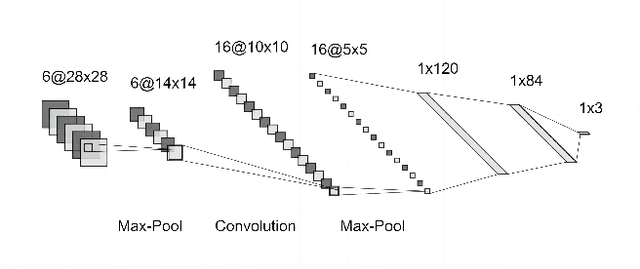


Label noise is a significant obstacle in deep learning model training. It can have a considerable impact on the performance of image classification models, particularly deep neural networks, which are especially susceptible because they have a strong propensity to memorise noisy labels. In this paper, we have examined the fundamental concept underlying related label noise approaches. A transition matrix estimator has been created, and its effectiveness against the actual transition matrix has been demonstrated. In addition, we examined the label noise robustness of two convolutional neural network classifiers with LeNet and AlexNet designs. The two FashionMINIST datasets have revealed the robustness of both models. We are not efficiently able to demonstrate the influence of the transition matrix noise correction on robustness enhancements due to our inability to correctly tune the complex convolutional neural network model due to time and computing resource constraints. There is a need for additional effort to fine-tune the neural network model and explore the precision of the estimated transition model in future research.
Speech MOS multi-task learning and rater bias correction
Dec 04, 2022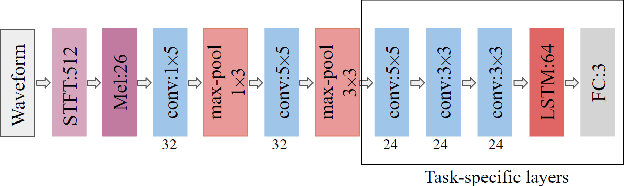

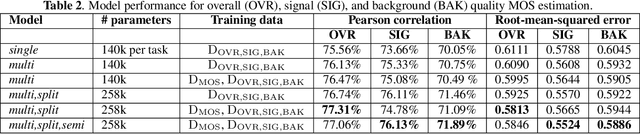
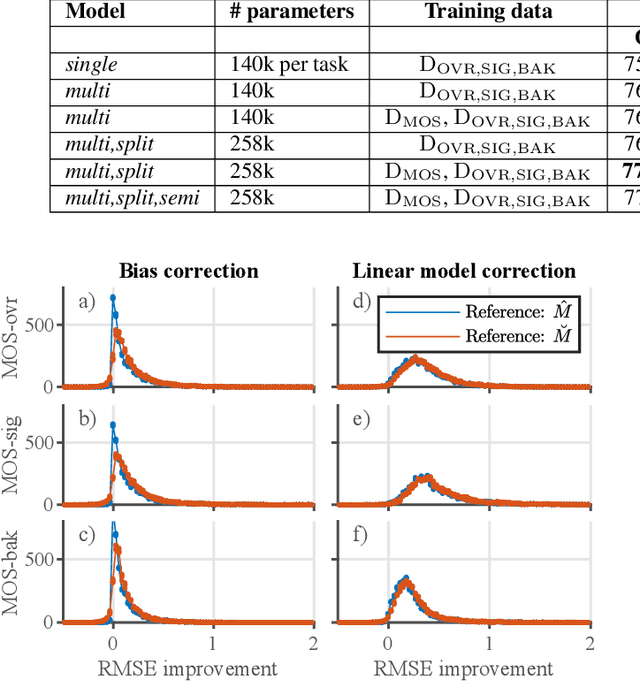
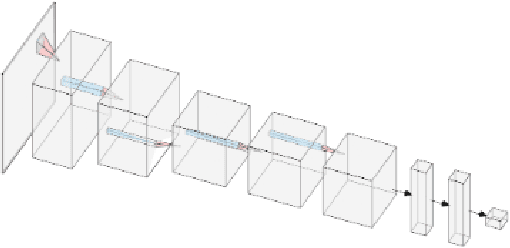
Perceptual speech quality is an important performance metric for teleconferencing applications. The mean opinion score (MOS) is standardized for the perceptual evaluation of speech quality and is obtained by asking listeners to rate the quality of a speech sample. Recently, there has been increasing research interest in developing models for estimating MOS blindly. Here we propose a multi-task framework to include additional labels and data in training to improve the performance of a blind MOS estimation model. Experimental results indicate that the proposed model can be trained to jointly estimate MOS, reverberation time (T60), and clarity (C50) by combining two disjoint data sets in training, one containing only MOS labels and the other containing only T60 and C50 labels. Furthermore, we use a semi-supervised framework to combine two MOS data sets in training, one containing only MOS labels (per ITU-T Recommendation P.808), and the other containing separate scores for speech signal, background noise, and overall quality (per ITU-T Recommendation P.835). Finally, we present preliminary results for addressing individual rater bias in the MOS labels.
A kinetic approach to consensus-based segmentation of biomedical images
Nov 08, 2022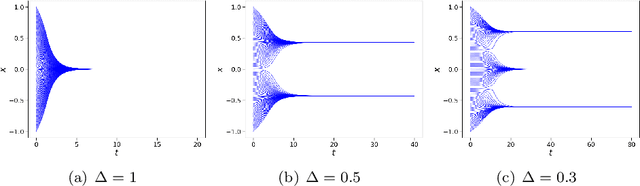
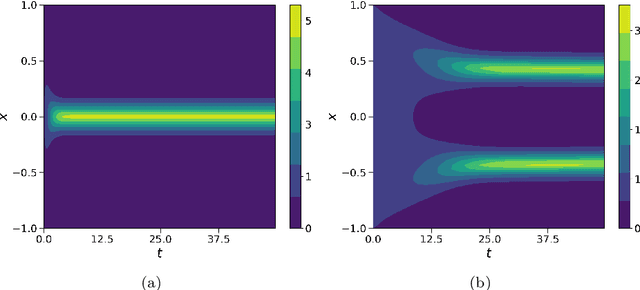
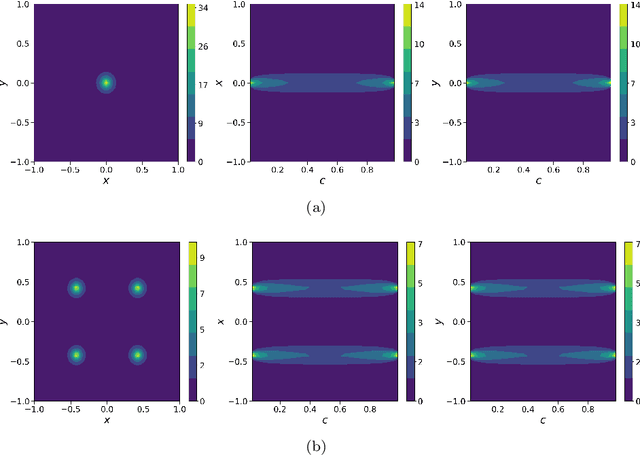
In this work, we apply a kinetic version of a bounded confidence consensus model to biomedical segmentation problems. In the presented approach, time-dependent information on the microscopic state of each particle/pixel includes its space position and a feature representing a static characteristic of the system, i.e. the gray level of each pixel. From the introduced microscopic model we derive a kinetic formulation of the model. The large time behavior of the system is then computed with the aid of a surrogate Fokker-Planck approach that can be obtained in the quasi-invariant scaling. We exploit the computational efficiency of direct simulation Monte Carlo methods for the obtained Boltzmann-type description of the problem for parameter identification tasks. Based on a suitable loss function measuring the distance between the ground truth segmentation mask and the evaluated mask, we minimize the introduced segmentation metric for a relevant set of 2D gray-scale images. Applications to biomedical segmentation concentrate on different imaging research contexts.
Heterogeneous Hidden Markov Models for Sleep Activity Recognition from Multi-Source Passively Sensed Data
Nov 08, 2022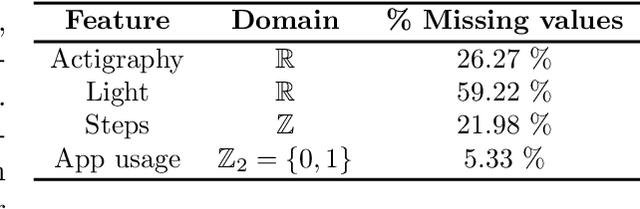
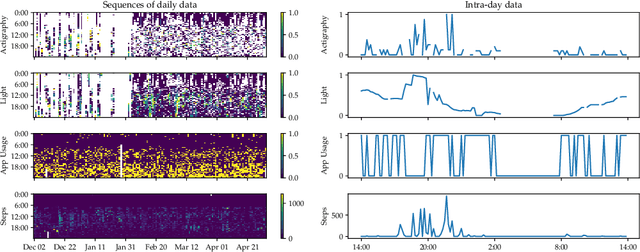
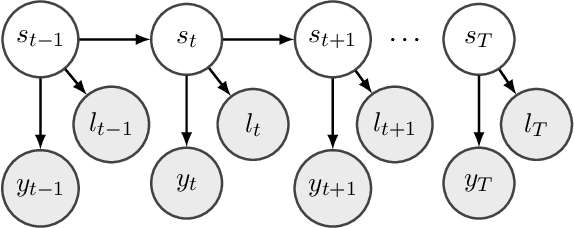
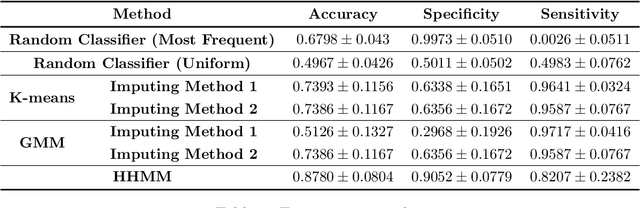
Psychiatric patients' passive activity monitoring is crucial to detect behavioural shifts in real-time, comprising a tool that helps clinicians supervise patients' evolution over time and enhance the associated treatments' outcomes. Frequently, sleep disturbances and mental health deterioration are closely related, as mental health condition worsening regularly entails shifts in the patients' circadian rhythms. Therefore, Sleep Activity Recognition constitutes a behavioural marker to portray patients' activity cycles and to detect behavioural changes among them. Moreover, mobile passively sensed data captured from smartphones, thanks to these devices' ubiquity, constitute an excellent alternative to profile patients' biorhythm. In this work, we aim to identify major sleep episodes based on passively sensed data. To do so, a Heterogeneous Hidden Markov Model is proposed to model a discrete latent variable process associated with the Sleep Activity Recognition task in a self-supervised way. We validate our results against sleep metrics reported by clinically tested wearables, proving the effectiveness of the proposed approach.
Selecting and Composing Learning Rate Policies for Deep Neural Networks
Oct 24, 2022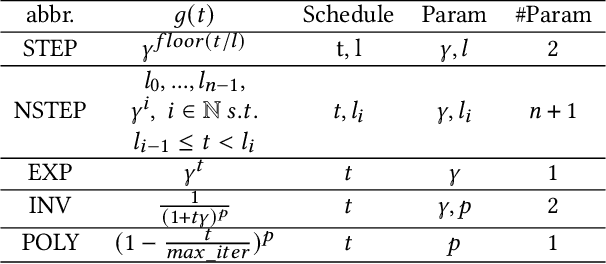


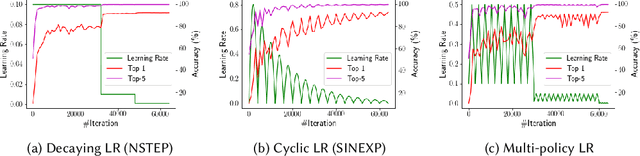
The choice of learning rate (LR) functions and policies has evolved from a simple fixed LR to the decaying LR and the cyclic LR, aiming to improve the accuracy and reduce the training time of Deep Neural Networks (DNNs). This paper presents a systematic approach to selecting and composing an LR policy for effective DNN training to meet desired target accuracy and reduce training time within the pre-defined training iterations. It makes three original contributions. First, we develop an LR tuning mechanism for auto-verification of a given LR policy with respect to the desired accuracy goal under the pre-defined training time constraint. Second, we develop an LR policy recommendation system (LRBench) to select and compose good LR policies from the same and/or different LR functions through dynamic tuning, and avoid bad choices, for a given learning task, DNN model and dataset. Third, we extend LRBench by supporting different DNN optimizers and show the significant mutual impact of different LR policies and different optimizers. Evaluated using popular benchmark datasets and different DNN models (LeNet, CNN3, ResNet), we show that our approach can effectively deliver high DNN test accuracy, outperform the existing recommended default LR policies, and reduce the DNN training time by 1.6$\sim$6.7$\times$ to meet a targeted model accuracy.
Federated NLP in Few-shot Scenarios
Dec 12, 2022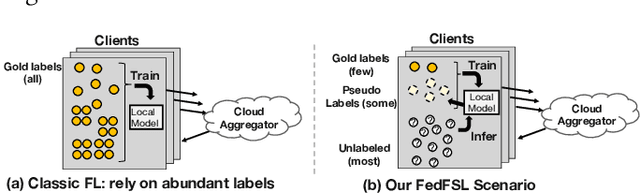
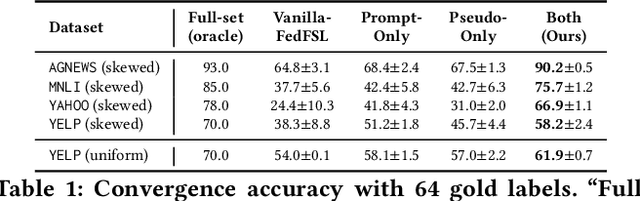
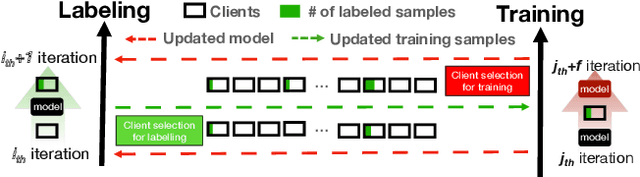
Natural language processing (NLP) sees rich mobile applications. To support various language understanding tasks, a foundation NLP model is often fine-tuned in a federated, privacy-preserving setting (FL). This process currently relies on at least hundreds of thousands of labeled training samples from mobile clients; yet mobile users often lack willingness or knowledge to label their data. Such an inadequacy of data labels is known as a few-shot scenario; it becomes the key blocker for mobile NLP applications. For the first time, this work investigates federated NLP in the few-shot scenario (FedFSL). By retrofitting algorithmic advances of pseudo labeling and prompt learning, we first establish a training pipeline that delivers competitive accuracy when only 0.05% (fewer than 100) of the training data is labeled and the remaining is unlabeled. To instantiate the workflow, we further present a system FFNLP, addressing the high execution cost with novel designs. (1) Curriculum pacing, which injects pseudo labels to the training workflow at a rate commensurate to the learning progress; (2) Representational diversity, a mechanism for selecting the most learnable data, only for which pseudo labels will be generated; (3) Co-planning of a model's training depth and layer capacity. Together, these designs reduce the training delay, client energy, and network traffic by up to 46.0$\times$, 41.2$\times$ and 3000.0$\times$, respectively. Through algorithm/system co-design, FFNLP demonstrates that FL can apply to challenging settings where most training samples are unlabeled.
A Semi-supervised Learning Approach for B-line Detection in Lung Ultrasound Images
Nov 30, 2022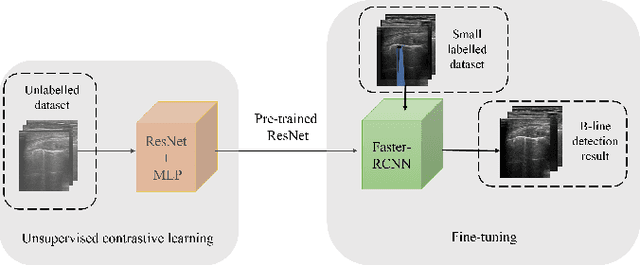
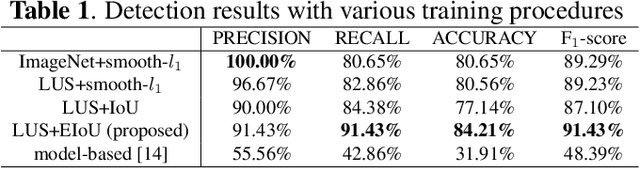
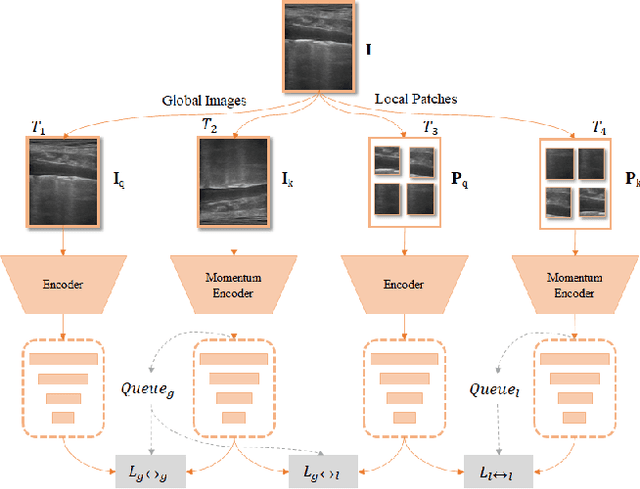
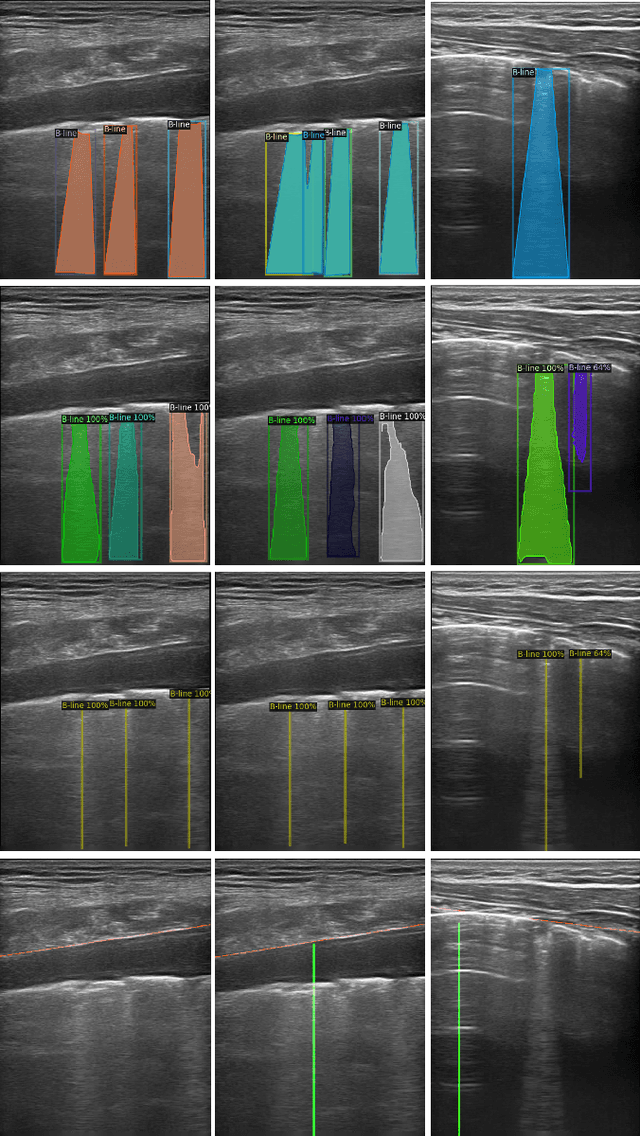
Studies have proved that the number of B-lines in lung ultrasound images has a strong statistical link to the amount of extravascular lung water, which is significant for hemodialysis treatment. Manual inspection of B-lines requires experts and is time-consuming, whilst modelling automation methods is currently problematic because of a lack of ground truth. Therefore, in this paper, we propose a novel semi-supervised learning method for the B-line detection task based on contrastive learning. Through multi-level unsupervised learning on unlabelled lung ultrasound images, the features of the artefacts are learnt. In the downstream task, we introduce a fine-tuning process on a small number of labelled images using the EIoU-based loss function. Apart from reducing the data labelling workload, the proposed method shows a superior performance to model-based algorithm with the recall of 91.43%, the accuracy of 84.21% and the F1 score of 91.43%.
Satellite Image Time Series Analysis for Big Earth Observation Data
Apr 24, 2022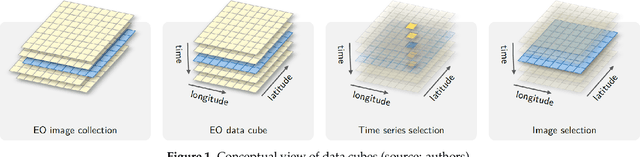
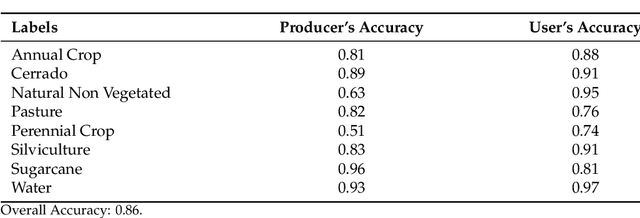

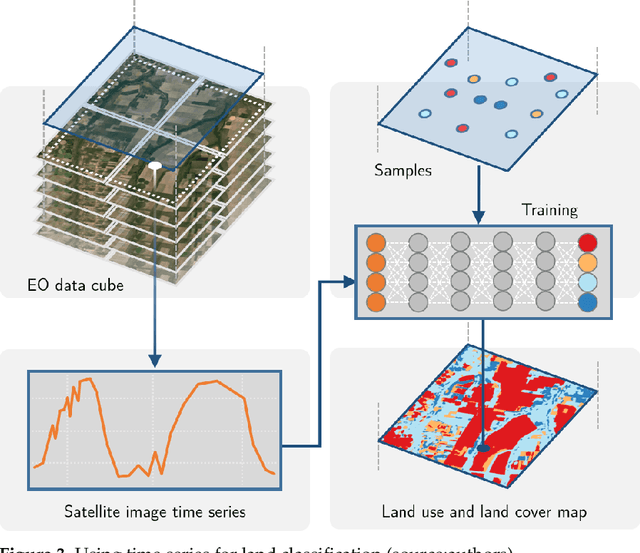
The development of analytical software for big Earth observation data faces several challenges. Designers need to balance between conflicting factors. Solutions that are efficient for specific hardware architectures can not be used in other environments. Packages that work on generic hardware and open standards will not have the same performance as dedicated solutions. Software that assumes that its users are computer programmers are flexible but may be difficult to learn for a wide audience. This paper describes sits, an open-source R package for satellite image time series analysis using machine learning. To allow experts to use satellite imagery to the fullest extent, sits adopts a time-first, space-later approach. It supports the complete cycle of data analysis for land classification. Its API provides a simple but powerful set of functions. The software works in different cloud computing environments. Satellite image time series are input to machine learning classifiers, and the results are post-processed using spatial smoothing. Since machine learning methods need accurate training data, sits includes methods for quality assessment of training samples. The software also provides methods for validation and accuracy measurement. The package thus comprises a production environment for big EO data analysis. We show that this approach produces high accuracy for land use and land cover maps through a case study in the Cerrado biome, one of the world's fast moving agricultural frontiers for the year 2018.