 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Graph Regularized Point Process Model For Event Propagation Sequence
Nov 21, 2022
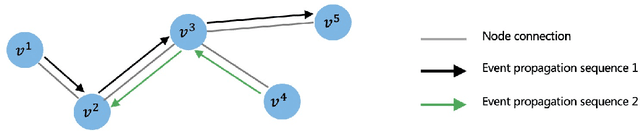
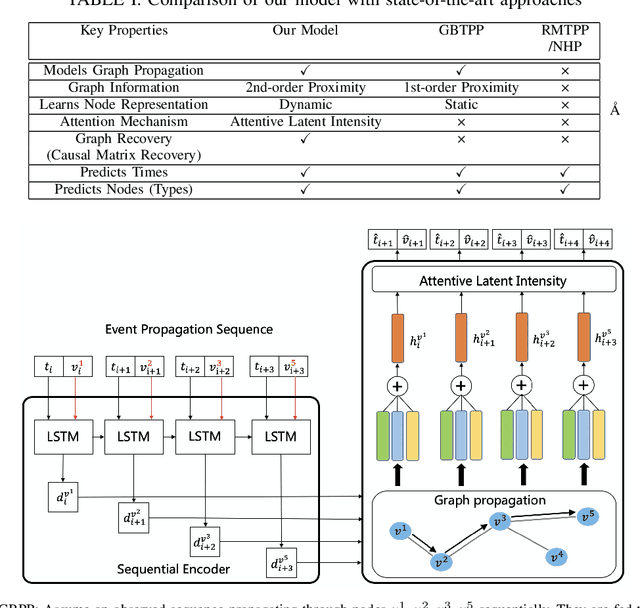
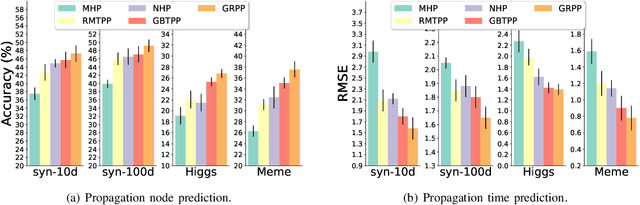
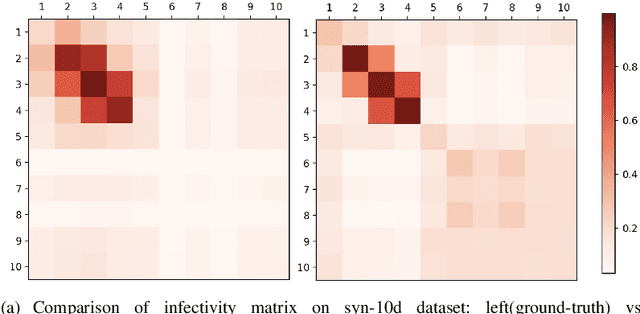
Point process is the dominant paradigm for modeling event sequences occurring at irregular intervals. In this paper we aim at modeling latent dynamics of event propagation in graph, where the event sequence propagates in a directed weighted graph whose nodes represent event marks (e.g., event types). Most existing works have only considered encoding sequential event history into event representation and ignored the information from the latent graph structure. Besides they also suffer from poor model explainability, i.e., failing to uncover causal influence across a wide variety of nodes. To address these problems, we propose a Graph Regularized Point Process (GRPP) that can be decomposed into: 1) a graph propagation model that characterizes the event interactions across nodes with neighbors and inductively learns node representations; 2) a temporal attentive intensity model, whose excitation and time decay factors of past events on the current event are constructed via the contextualization of the node embedding. Moreover, by applying a graph regularization method, GRPP provides model interpretability by uncovering influence strengths between nodes. Numerical experiments on various datasets show that GRPP outperforms existing models on both the propagation time and node prediction by notable margins.
* IJCNN 2021
Towards Automated Polyp Segmentation Using Weakly- and Semi-Supervised Learning and Deformable Transformers
Nov 21, 2022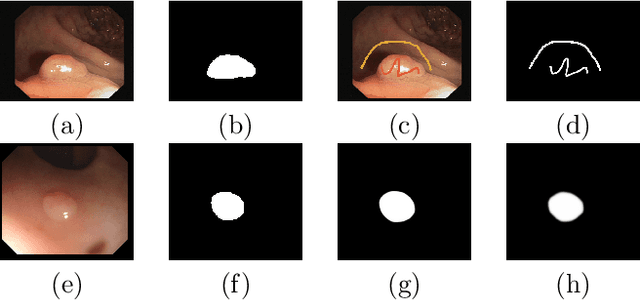
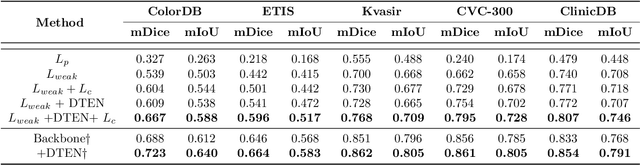


Polyp segmentation is a crucial step towards computer-aided diagnosis of colorectal cancer. However, most of the polyp segmentation methods require pixel-wise annotated datasets. Annotated datasets are tedious and time-consuming to produce, especially for physicians who must dedicate their time to their patients. We tackle this issue by proposing a novel framework that can be trained using only weakly annotated images along with exploiting unlabeled images. To this end, we propose three ideas to address this problem, more specifically our contributions are: 1) a novel sparse foreground loss that suppresses false positives and improves weakly-supervised training, 2) a batch-wise weighted consistency loss utilizing predicted segmentation maps from identical networks trained using different initialization during semi-supervised training, 3) a deformable transformer encoder neck for feature enhancement by fusing information across levels and flexible spatial locations. Extensive experimental results demonstrate the merits of our ideas on five challenging datasets outperforming some state-of-the-art fully supervised models. Also, our framework can be utilized to fine-tune models trained on natural image segmentation datasets drastically improving their performance for polyp segmentation and impressively demonstrating superior performance to fully supervised fine-tuning.
Simultaneously Updating All Persistence Values in Reinforcement Learning
Nov 21, 2022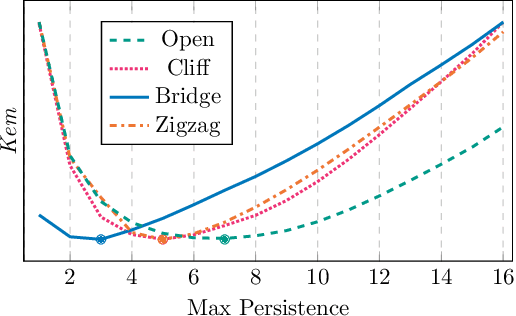
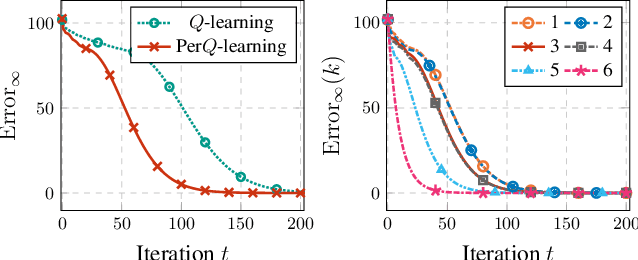
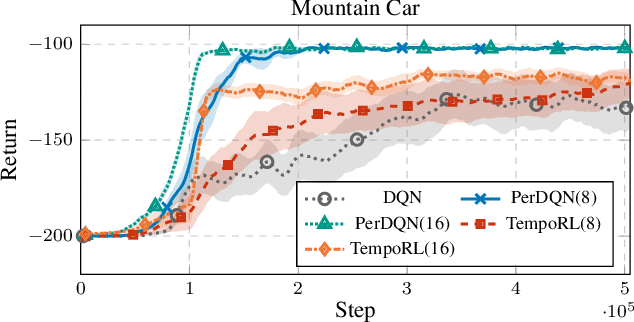
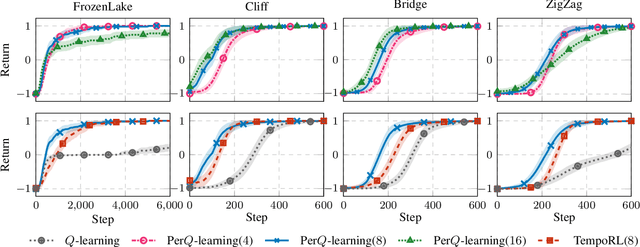
In reinforcement learning, the performance of learning agents is highly sensitive to the choice of time discretization. Agents acting at high frequencies have the best control opportunities, along with some drawbacks, such as possible inefficient exploration and vanishing of the action advantages. The repetition of the actions, i.e., action persistence, comes into help, as it allows the agent to visit wider regions of the state space and improve the estimation of the action effects. In this work, we derive a novel All-Persistence Bellman Operator, which allows an effective use of both the low-persistence experience, by decomposition into sub-transition, and the high-persistence experience, thanks to the introduction of a suitable bootstrap procedure. In this way, we employ transitions collected at any time scale to update simultaneously the action values of the considered persistence set. We prove the contraction property of the All-Persistence Bellman Operator and, based on it, we extend classic Q-learning and DQN. After providing a study on the effects of persistence, we experimentally evaluate our approach in both tabular contexts and more challenging frameworks, including some Atari games.
Doubly Contrastive End-to-End Semantic Segmentation for Autonomous Driving under Adverse Weather
Nov 21, 2022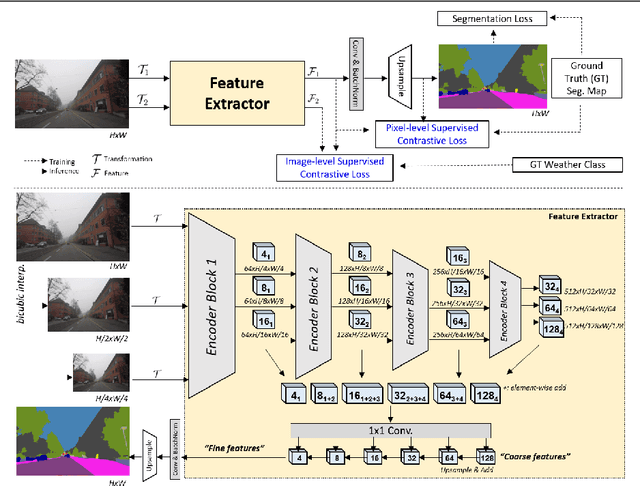
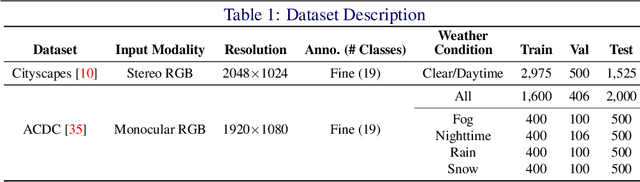
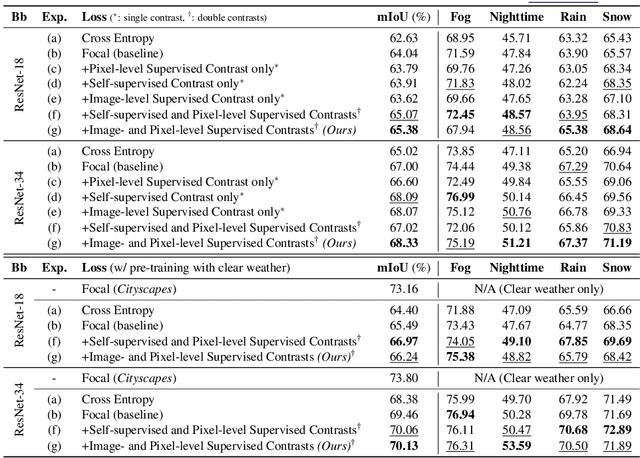

Road scene understanding tasks have recently become crucial for self-driving vehicles. In particular, real-time semantic segmentation is indispensable for intelligent self-driving agents to recognize roadside objects in the driving area. As prior research works have primarily sought to improve the segmentation performance with computationally heavy operations, they require far significant hardware resources for both training and deployment, and thus are not suitable for real-time applications. As such, we propose a doubly contrastive approach to improve the performance of a more practical lightweight model for self-driving, specifically under adverse weather conditions such as fog, nighttime, rain and snow. Our proposed approach exploits both image- and pixel-level contrasts in an end-to-end supervised learning scheme without requiring a memory bank for global consistency or the pretraining step used in conventional contrastive methods. We validate the effectiveness of our method using SwiftNet on the ACDC dataset, where it achieves up to 1.34%p improvement in mIoU (ResNet-18 backbone) at 66.7 FPS (2048x1024 resolution) on a single RTX 3080 Mobile GPU at inference. Furthermore, we demonstrate that replacing image-level supervision with self-supervision achieves comparable performance when pre-trained with clear weather images.
Using multimodal learning and deep generative models for corporate bankruptcy prediction
Nov 21, 2022
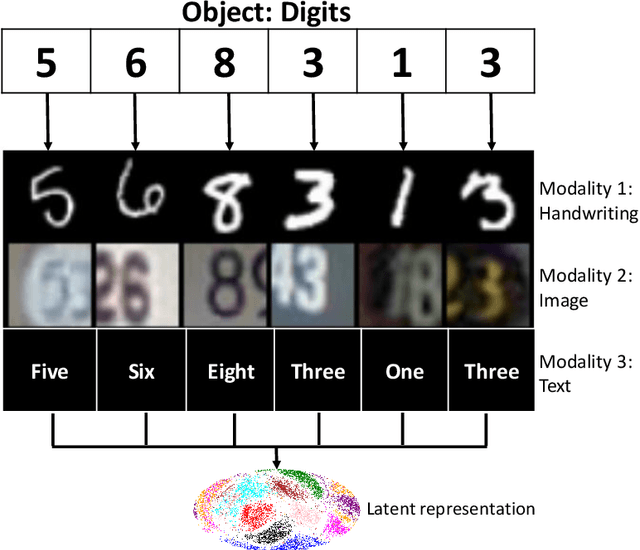
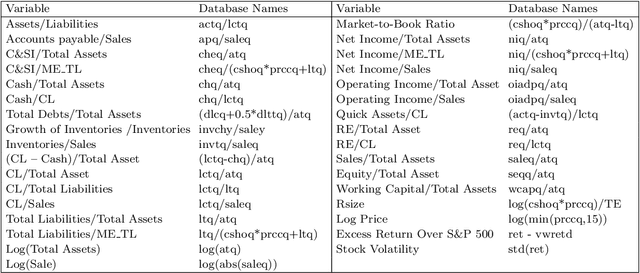
This research introduces for the first time, to the best of our knowledge, the concept of multimodal learning in bankruptcy prediction models. We use the Conditional Multimodal Discriminative (CMMD) model to learn multimodal representations that embed information from accounting, market, and textual modalities. The CMMD model needs a sample with all data modalities for model training. At test time, the CMMD model only needs access to accounting and market modalities to generate multimodal representations, which are further used to make bankruptcy predictions. This fact makes the use of bankruptcy prediction models using textual data realistic and possible, since accounting and market data are available for all companies unlike textual data. The empirical results in this research show that the classification performance of our proposed methodology is superior compared to that of a large number of traditional classifier models. We also show that our proposed methodology solves the limitation of previous bankruptcy models using textual data, as they can only make predictions for a small proportion of companies. Finally, based on multimodal representations, we introduce an index that is able to capture the uncertainty of the financial situation of companies during periods of financial distress.
Object-level 3D Semantic Mapping using a Network of Smart Edge Sensors
Nov 21, 2022

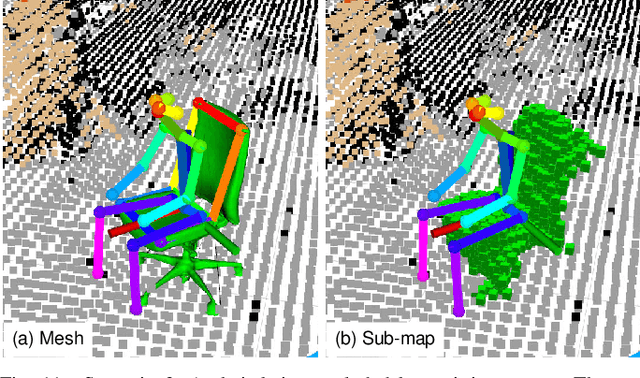

Autonomous robots that interact with their environment require a detailed semantic scene model. For this, volumetric semantic maps are frequently used. The scene understanding can further be improved by including object-level information in the map. In this work, we extend a multi-view 3D semantic mapping system consisting of a network of distributed smart edge sensors with object-level information, to enable downstream tasks that need object-level input. Objects are represented in the map via their 3D mesh model or as an object-centric volumetric sub-map that can model arbitrary object geometry when no detailed 3D model is available. We propose a keypoint-based approach to estimate object poses via PnP and refinement via ICP alignment of the 3D object model with the observed point cloud segments. Object instances are tracked to integrate observations over time and to be robust against temporary occlusions. Our method is evaluated on the public Behave dataset where it shows pose estimation accuracy within a few centimeters and in real-world experiments with the sensor network in a challenging lab environment where multiple chairs and a table are tracked through the scene online, in real time even under high occlusions.
ZigZag: Universal Sampling-free Uncertainty Estimation Through Two-Step Inference
Nov 21, 2022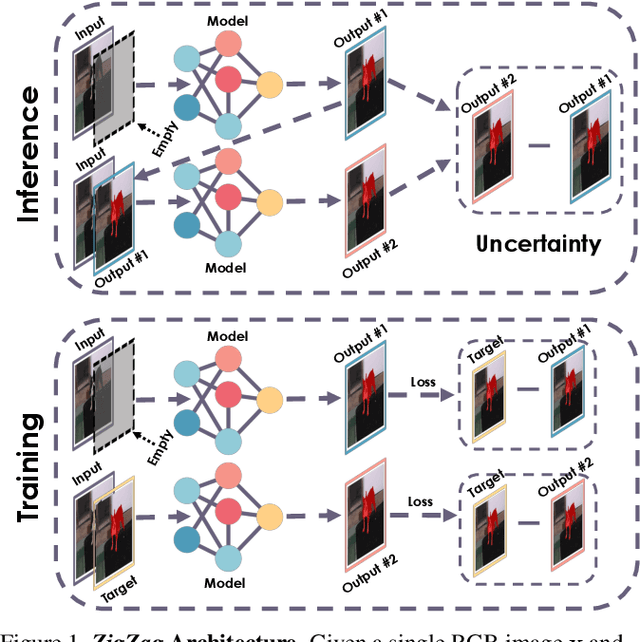
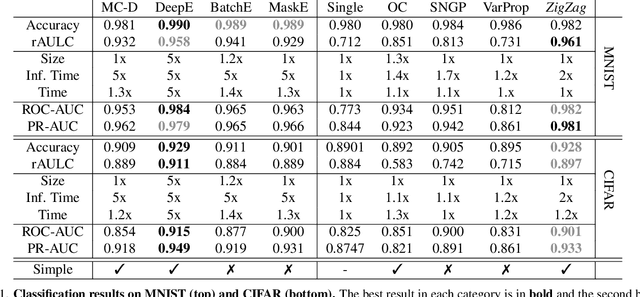
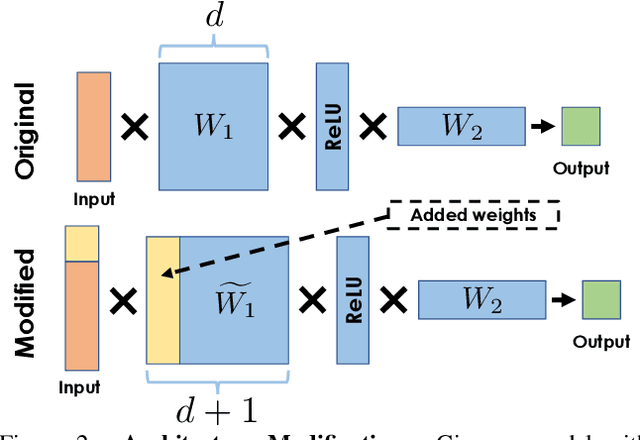
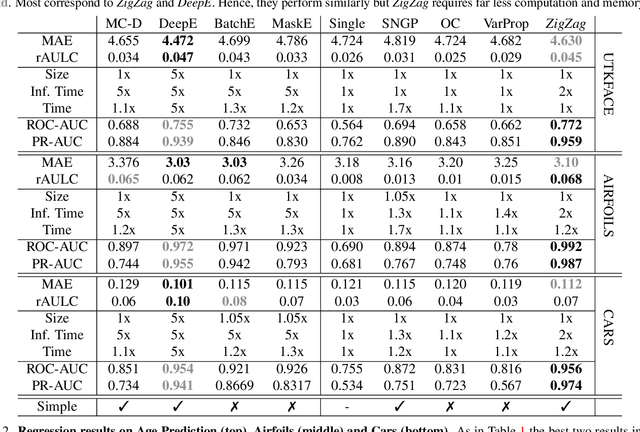
Whereas the ability of deep networks to produce useful predictions on many kinds of data has been amply demonstrated, estimating the reliability of these predictions remains challenging. Sampling approaches such as MC-Dropout and Deep Ensembles have emerged as the most popular ones for this purpose. Unfortunately, they require many forward passes at inference time, which slows them down. Sampling-free approaches can be faster but suffer from other drawbacks, such as lower reliability of uncertainty estimates, difficulty of use, and limited applicability to different types of tasks and data. In this work, we introduce a sampling-free approach that is generic and easy to deploy, while producing reliable uncertainty estimates on par with state-of-the-art methods at a significantly lower computational cost. It is predicated on training the network to produce the same output with and without additional information about that output. At inference time, when no prior information is given, we use the network's own prediction as the additional information. We prove that the difference between the two predictions is an accurate uncertainty estimate and demonstrate our approach on various types of tasks and applications.
Improving trajectory localization accuracy via direction-of-arrival estimation
Dec 07, 2022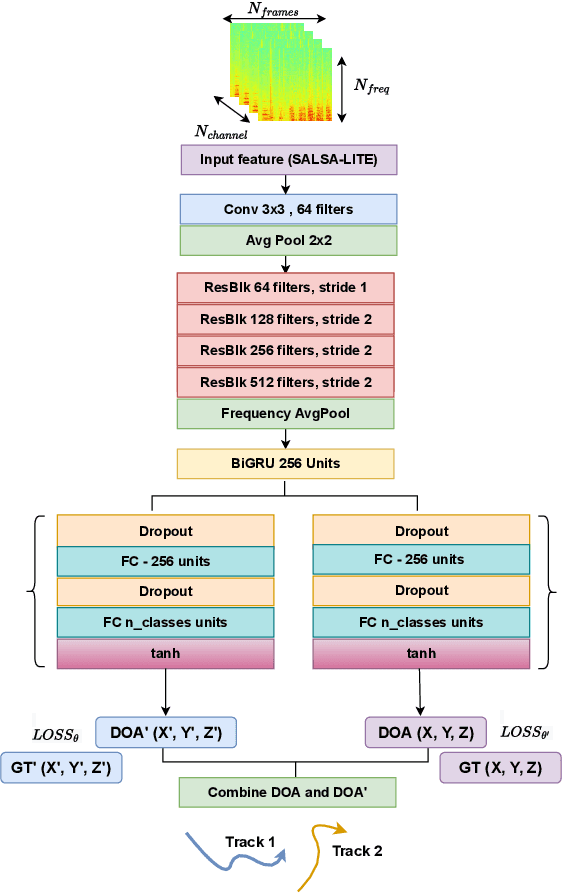
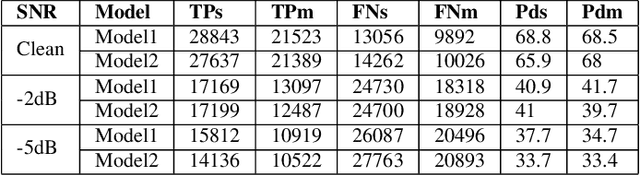
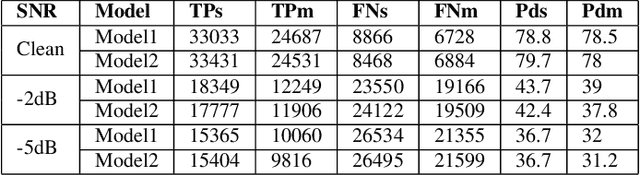
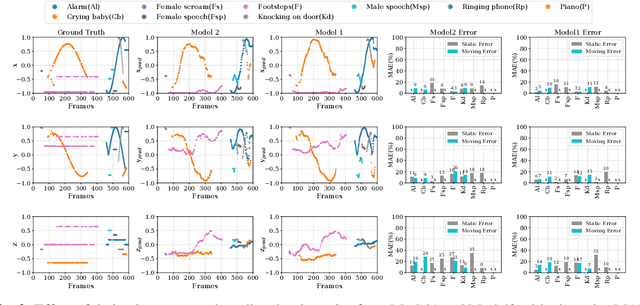
Sound source localization is crucial in acoustic sensing and monitoring-related applications. In this paper, we do a comprehensive analysis of improvement in sound source localization by combining the direction of arrivals (DOAs) with their derivatives which quantify the changes in the positions of sources over time. This study uses the SALSA-Lite feature with a convolutional recurrent neural network (CRNN) model for predicting DOAs and their first-order derivatives. An update rule is introduced to combine the predicted DOAs with the estimated derivatives to obtain the final DOAs. The experimental validation is done using TAU-NIGENS Spatial Sound Events (TNSSE) 2021 dataset. We compare the performance of the networks predicting DOAs with derivative vs. the one predicting only the DOAs at low SNR levels. The results show that combining the derivatives with the DOAs improves the localization accuracy of moving sources.
A Temporal Graph Neural Network for Cyber Attack Detection and Localization in Smart Grids
Dec 07, 2022
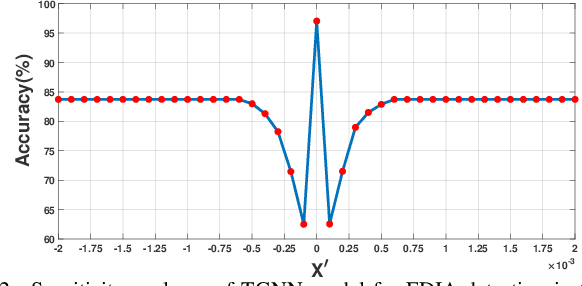
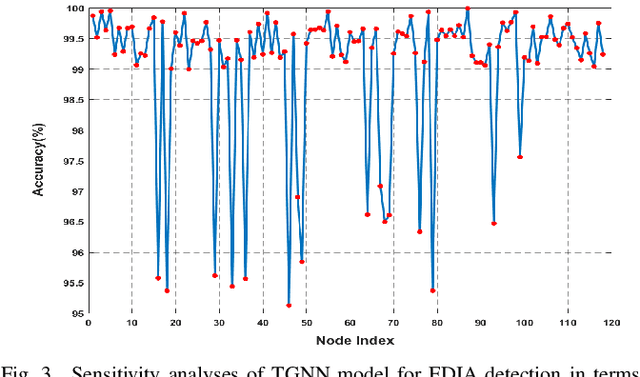
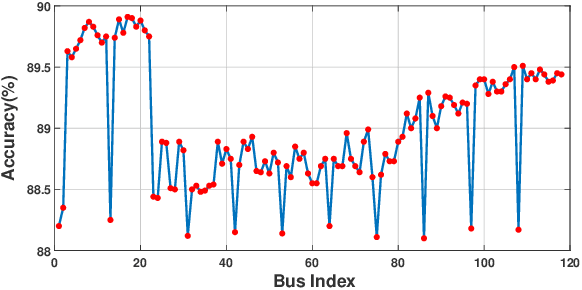
This paper presents a Temporal Graph Neural Network (TGNN) framework for detection and localization of false data injection and ramp attacks on the system state in smart grids. Capturing the topological information of the system through the GNN framework along with the state measurements can improve the performance of the detection mechanism. The problem is formulated as a classification problem through a GNN with message passing mechanism to identify abnormal measurements. The residual block used in the aggregation process of message passing and the gated recurrent unit can lead to improved computational time and performance. The performance of the proposed model has been evaluated through extensive simulations of power system states and attack scenarios showing promising performance. The sensitivity of the model to intensity and location of the attacks and model's detection delay versus detection accuracy have also been evaluated.
Connected Cruise and Traffic Control for Pairs of Connected Automated Vehicles
Dec 04, 2022
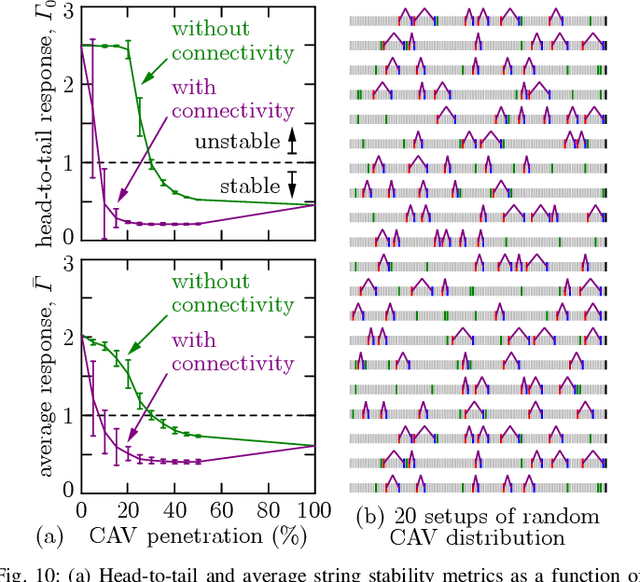
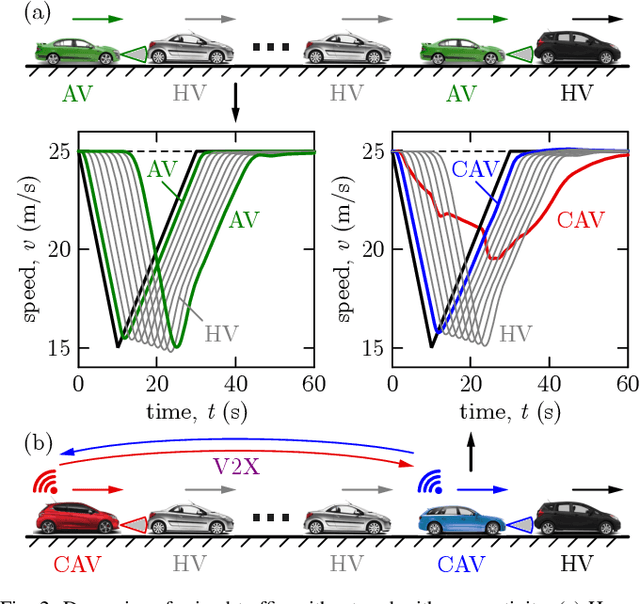
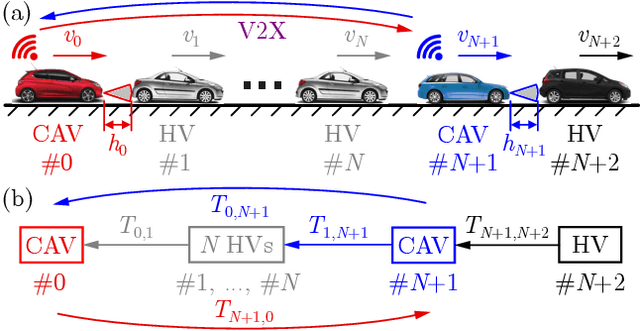
This paper considers mixed traffic consisting of connected automated vehicles equipped with vehicle-to-everything (V2X) connectivity and human-driven vehicles. A control strategy is proposed for communicating pairs of connected automated vehicles, where the two vehicles regulate their longitudinal motion by responding to each other, and, at the same time, stabilize the human-driven traffic between them. Stability analysis is conducted to find stabilizing controllers, and simulations are used to show the efficacy of the proposed approach. The impact of the penetration of connectivity and automation on the string stability of traffic is quantified. It is shown that, even with moderate penetration, connected automated vehicle pairs executing the proposed controllers achieve significant benefits compared to when these vehicles are disconnected and controlled independently.