 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Localizing Scan Targets from Human Pose for Autonomous Lung Ultrasound Imaging
Dec 15, 2022
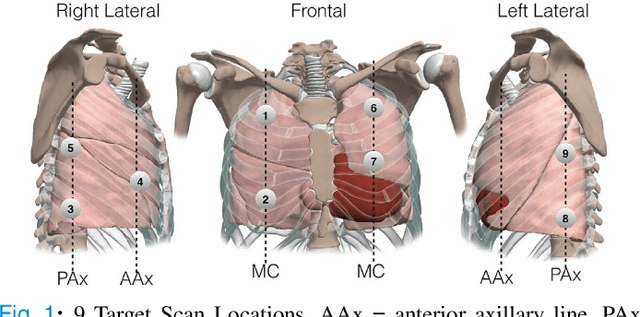
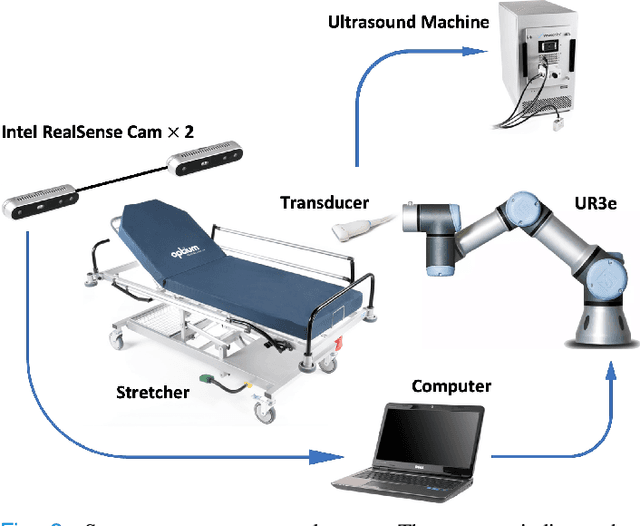
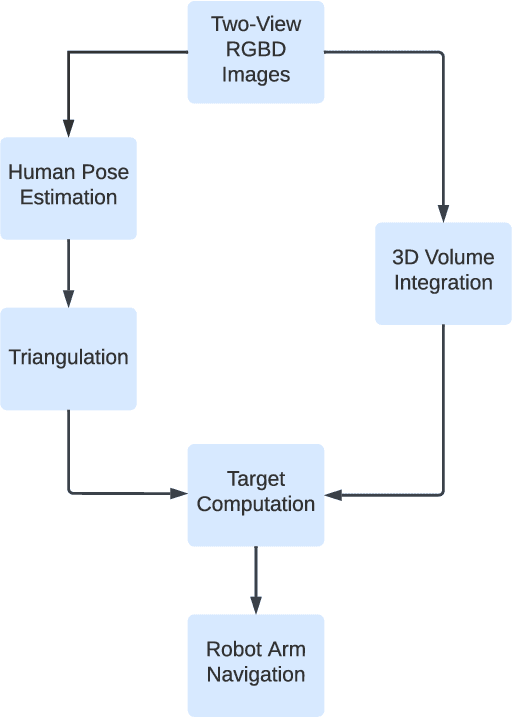
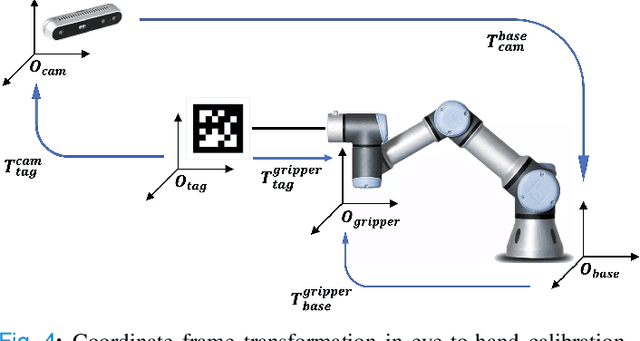
Ultrasound is progressing toward becoming an affordable and versatile solution to medical imaging. With the advent of COVID-19 global pandemic, there is a need to fully automate ultrasound imaging as it requires trained operators in close proximity to patients for long period of time. In this work, we investigate the important yet seldom-studied problem of scan target localization, under the setting of lung ultrasound imaging. We propose a purely vision-based, data driven method that incorporates learning-based computer vision techniques. We combine a human pose estimation model with a specially designed regression model to predict the lung ultrasound scan targets, and deploy multiview stereo vision to enhance the consistency of 3D target localization. While related works mostly focus on phantom experiments, we collect data from 30 human subjects for testing. Our method attains an accuracy level of 15.52 (9.47) mm for probe positioning and 4.32 (3.69){\deg} for probe orientation, with a success rate above 80% under an error threshold of 25mm for all scan targets. Moreover, our approach can serve as a general solution to other types of ultrasound modalities. The code for implementation has been released.
Audio-based AI classifiers show no evidence of improved COVID-19 screening over simple symptoms checkers
Dec 15, 2022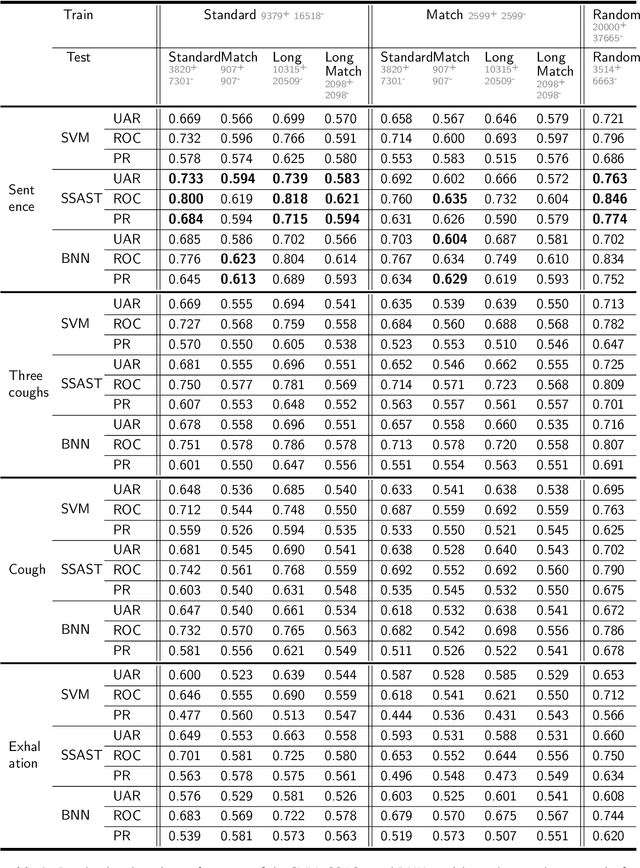
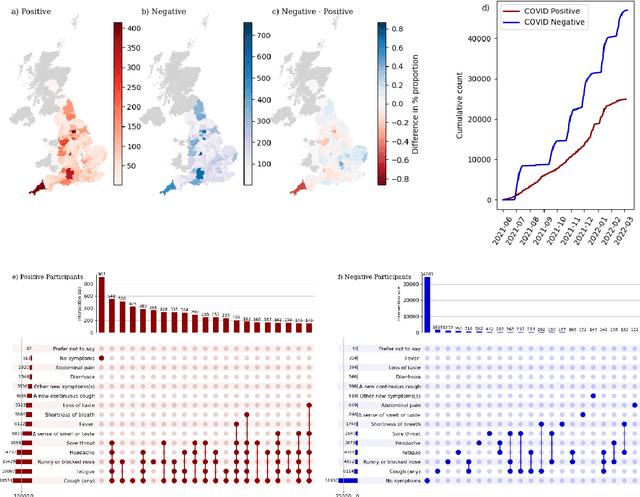
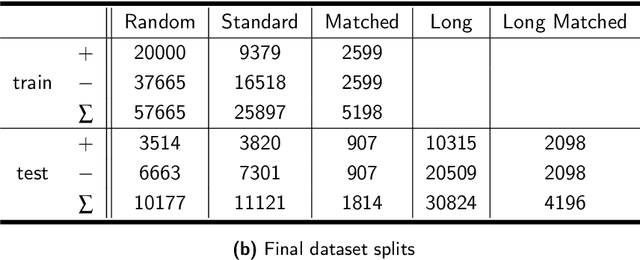

Recent work has reported that AI classifiers trained on audio recordings can accurately predict severe acute respiratory syndrome coronavirus 2 (SARSCoV2) infection status. Here, we undertake a large scale study of audio-based deep learning classifiers, as part of the UK governments pandemic response. We collect and analyse a dataset of audio recordings from 67,842 individuals with linked metadata, including reverse transcription polymerase chain reaction (PCR) test outcomes, of whom 23,514 tested positive for SARS CoV 2. Subjects were recruited via the UK governments National Health Service Test-and-Trace programme and the REal-time Assessment of Community Transmission (REACT) randomised surveillance survey. In an unadjusted analysis of our dataset AI classifiers predict SARS-CoV-2 infection status with high accuracy (Receiver Operating Characteristic Area Under the Curve (ROCAUC) 0.846 [0.838, 0.854]) consistent with the findings of previous studies. However, after matching on measured confounders, such as age, gender, and self reported symptoms, our classifiers performance is much weaker (ROC-AUC 0.619 [0.594, 0.644]). Upon quantifying the utility of audio based classifiers in practical settings, we find them to be outperformed by simple predictive scores based on user reported symptoms.
On the Complexity of Representation Learning in Contextual Linear Bandits
Dec 19, 2022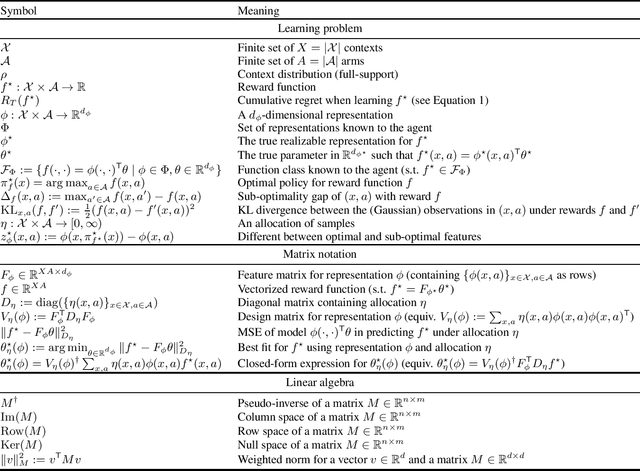
In contextual linear bandits, the reward function is assumed to be a linear combination of an unknown reward vector and a given embedding of context-arm pairs. In practice, the embedding is often learned at the same time as the reward vector, thus leading to an online representation learning problem. Existing approaches to representation learning in contextual bandits are either very generic (e.g., model-selection techniques or algorithms for learning with arbitrary function classes) or specialized to particular structures (e.g., nested features or representations with certain spectral properties). As a result, the understanding of the cost of representation learning in contextual linear bandit is still limited. In this paper, we take a systematic approach to the problem and provide a comprehensive study through an instance-dependent perspective. We show that representation learning is fundamentally more complex than linear bandits (i.e., learning with a given representation). In particular, learning with a given set of representations is never simpler than learning with the worst realizable representation in the set, while we show cases where it can be arbitrarily harder. We complement this result with an extensive discussion of how it relates to existing literature and we illustrate positive instances where representation learning is as complex as learning with a fixed representation and where sub-logarithmic regret is achievable.
Neural representation of a time optimal, constant acceleration rendezvous
Mar 29, 2022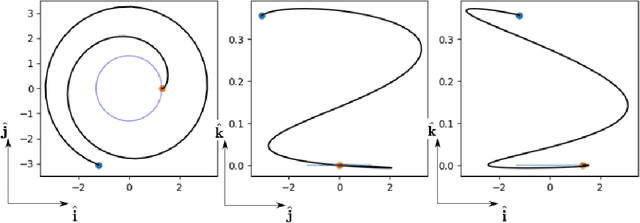
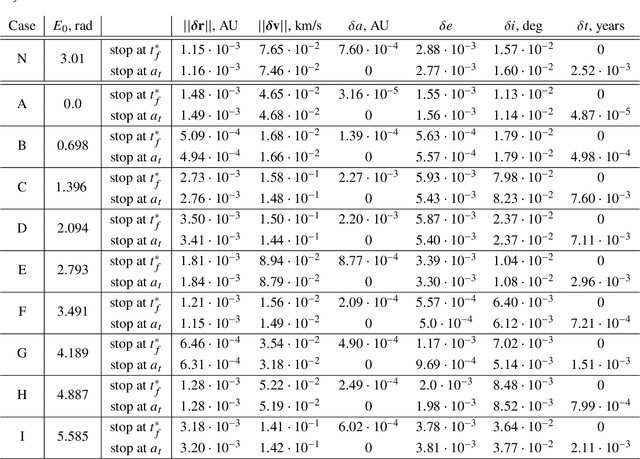
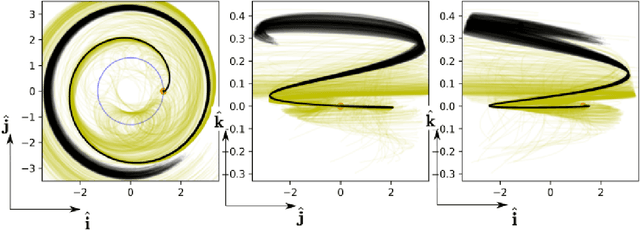
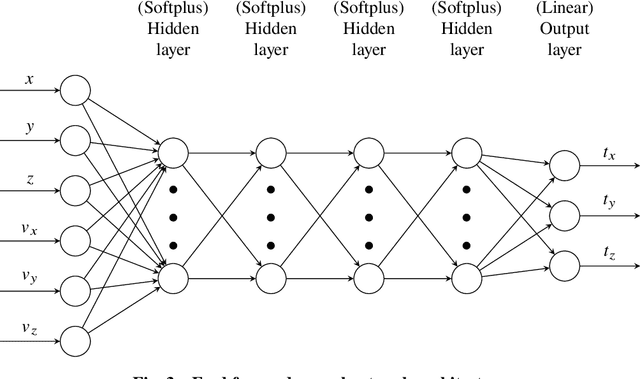
We train neural models to represent both the optimal policy (i.e. the optimal thrust direction) and the value function (i.e. the time of flight) for a time optimal, constant acceleration low-thrust rendezvous. In both cases we develop and make use of the data augmentation technique we call backward generation of optimal examples. We are thus able to produce and work with large dataset and to fully exploit the benefit of employing a deep learning framework. We achieve, in all cases, accuracies resulting in successful rendezvous (simulated following the learned policy) and time of flight predictions (using the learned value function). We find that residuals as small as a few m/s, thus well within the possibility of a spacecraft navigation $\Delta V$ budget, are achievable for the velocity at rendezvous. We also find that, on average, the absolute error to predict the optimal time of flight to rendezvous from any orbit in the asteroid belt to an Earth-like orbit is small (less than 4\%) and thus also of interest for practical uses, for example, during preliminary mission design phases.
Three-stage binarization of color document images based on discrete wavelet transform and generative adversarial networks
Dec 17, 2022
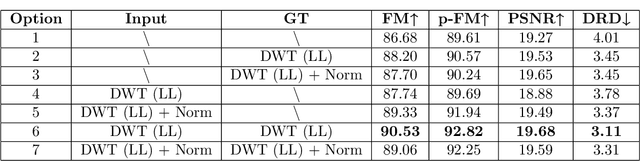
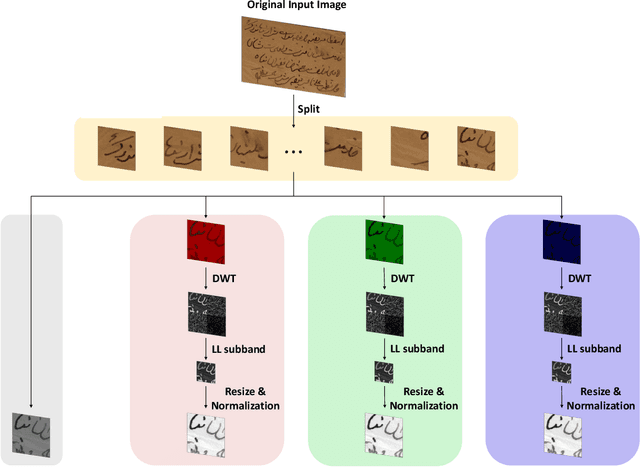
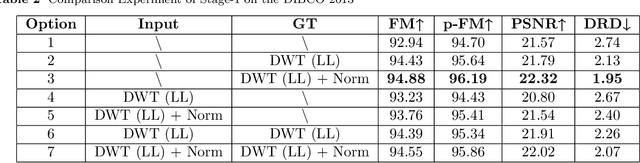
The efficient segmentation of foreground text information from the background in degraded color document images is a hot research topic. Due to the imperfect preservation of ancient documents over a long period of time, various types of degradation, including staining, yellowing, and ink seepage, have seriously affected the results of image binarization. In this paper, a three-stage method is proposed for image enhancement and binarization of degraded color document images by using discrete wavelet transform (DWT) and generative adversarial network (GAN). In Stage-1, we use DWT and retain the LL subband images to achieve the image enhancement. In Stage-2, the original input image is split into four (Red, Green, Blue and Gray) single-channel images, each of which trains the independent adversarial networks. The trained adversarial network models are used to extract the color foreground information from the images. In Stage-3, in order to combine global and local features, the output image from Stage-2 and the original input image are used to train the independent adversarial networks for document binarization. The experimental results demonstrate that our proposed method outperforms many classical and state-of-the-art (SOTA) methods on the Document Image Binarization Contest (DIBCO) dataset. We release our implementation code at https://github.com/abcpp12383/ThreeStageBinarization.
Domain Generalization via Selective Consistency Regularization for Time Series Classification
Jun 16, 2022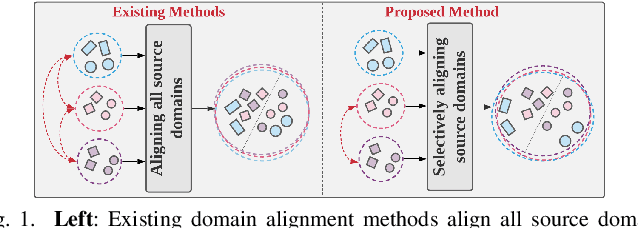
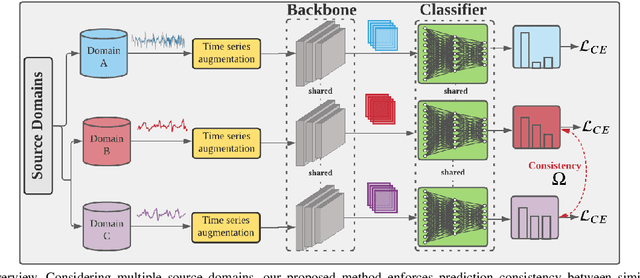
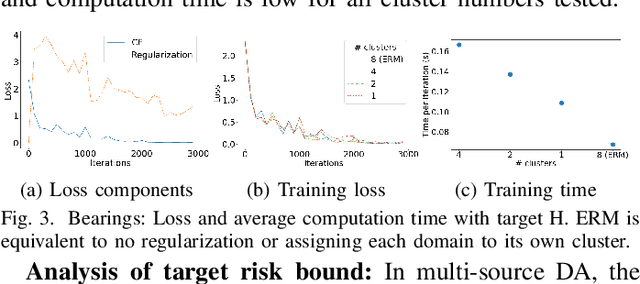
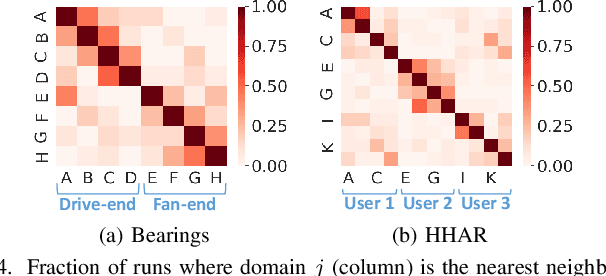
Domain generalization methods aim to learn models robust to domain shift with data from a limited number of source domains and without access to target domain samples during training. Popular domain alignment methods for domain generalization seek to extract domain-invariant features by minimizing the discrepancy between feature distributions across all domains, disregarding inter-domain relationships. In this paper, we instead propose a novel representation learning methodology that selectively enforces prediction consistency between source domains estimated to be closely-related. Specifically, we hypothesize that domains share different class-informative representations, so instead of aligning all domains which can cause negative transfer, we only regularize the discrepancy between closely-related domains. We apply our method to time-series classification tasks and conduct comprehensive experiments on three public real-world datasets. Our method significantly improves over the baseline and achieves better or competitive performance in comparison with state-of-the-art methods in terms of both accuracy and model calibration.
Domain Generalization Strategy to Train Classifiers Robust to Spatial-Temporal Shift
Dec 06, 2022
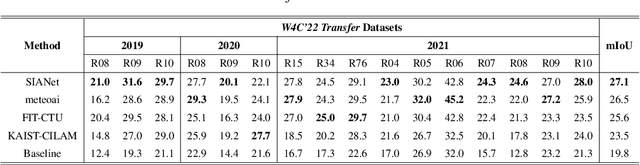
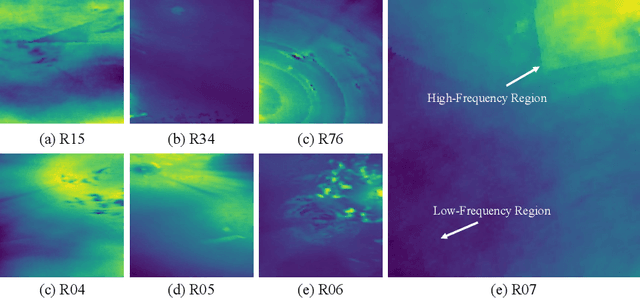
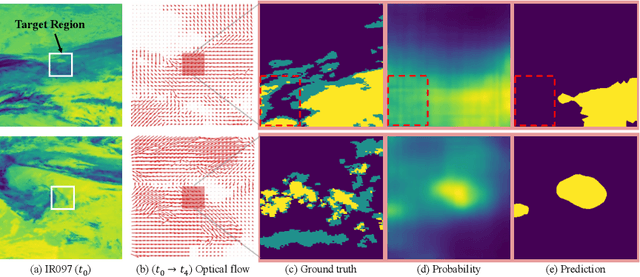
Deep learning-based weather prediction models have advanced significantly in recent years. However, data-driven models based on deep learning are difficult to apply to real-world applications because they are vulnerable to spatial-temporal shifts. A weather prediction task is especially susceptible to spatial-temporal shifts when the model is overfitted to locality and seasonality. In this paper, we propose a training strategy to make the weather prediction model robust to spatial-temporal shifts. We first analyze the effect of hyperparameters and augmentations of the existing training strategy on the spatial-temporal shift robustness of the model. Next, we propose an optimal combination of hyperparameters and augmentation based on the analysis results and a test-time augmentation. We performed all experiments on the W4C22 Transfer dataset and achieved the 1st performance.
Implications of Regret on Stability of Linear Dynamical Systems
Nov 14, 2022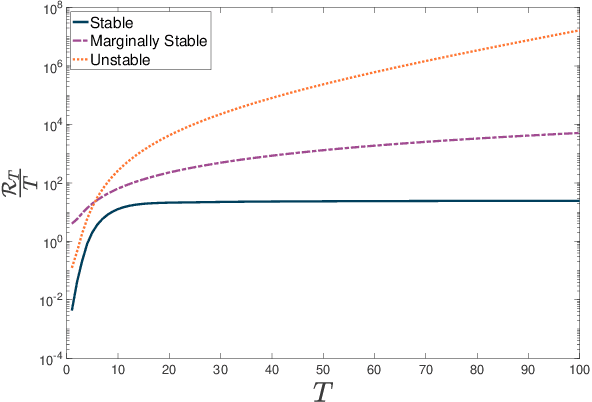
The setting of an agent making decisions under uncertainty and under dynamic constraints is common for the fields of optimal control, reinforcement learning and recently also for online learning. In the online learning setting, the quality of an agent's decision is often quantified by the concept of regret, comparing the performance of the chosen decisions to the best possible ones in hindsight. While regret is a useful performance measure, when dynamical systems are concerned, it is important to also assess the stability of the closed-loop system for a chosen policy. In this work, we show that for linear state feedback policies and linear systems subject to adversarial disturbances, linear regret implies asymptotic stability in both time-varying and time-invariant settings. Conversely, we also show that bounded input bounded state (BIBS) stability and summability of the state transition matrices imply linear regret.
Monitoring the Dynamic Networks of Stock Returns
Oct 29, 2022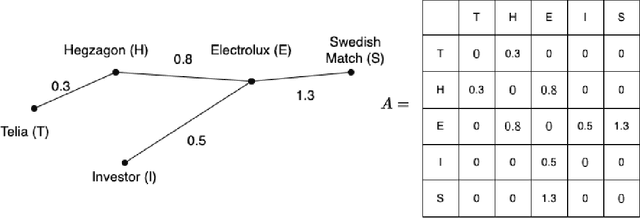
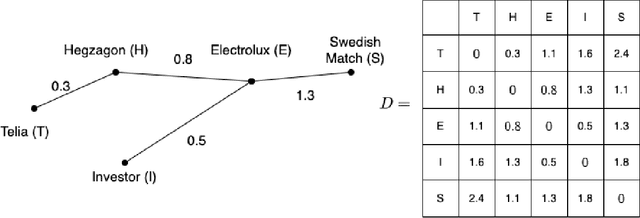
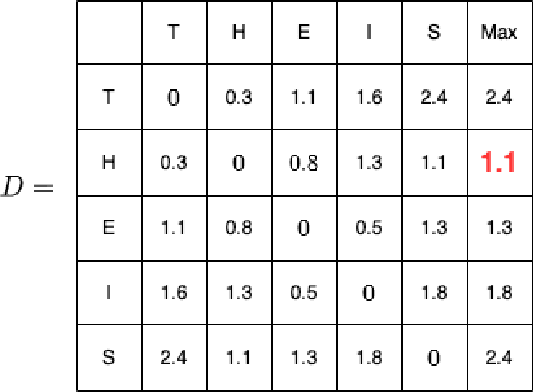
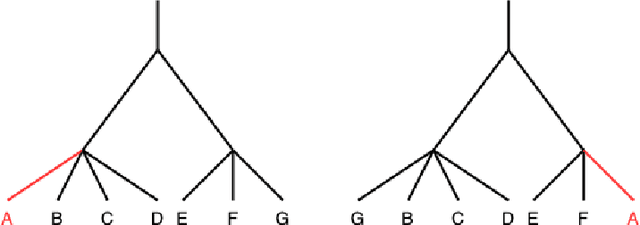
In this paper, we study the connection between the companies in the Swedish capital market. We consider 28 companies included in the determination of the market index OMX30. The network structure of the market is constructed using different methods to determine the distance between the companies. We use hierarchical clustering methods to find the relation among the companies in each window. Next, we obtain one-dimensional time series of the distances between the clustering trees that reflect the changes in the relationship between the companies in the market over time. The method of statistical process control, namely the Shewhart control chart, is applied to those time series to detect abnormal changes in the financial market.
Spatial-Temporal Synchronous Graph Transformer network (STSGT) for COVID-19 forecasting
Oct 31, 2022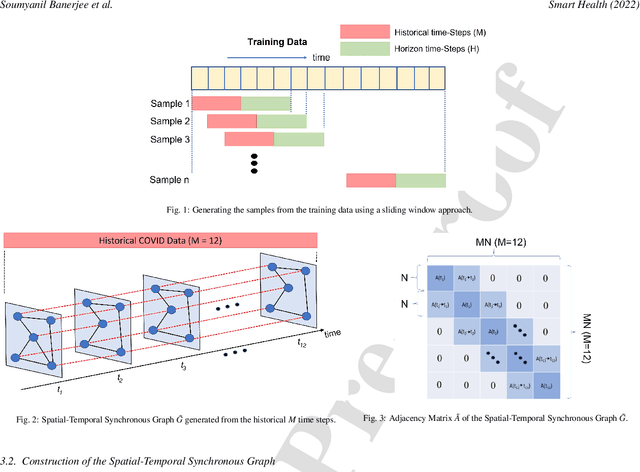
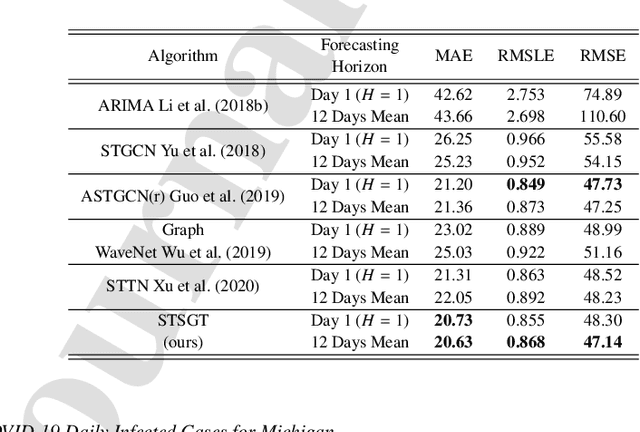
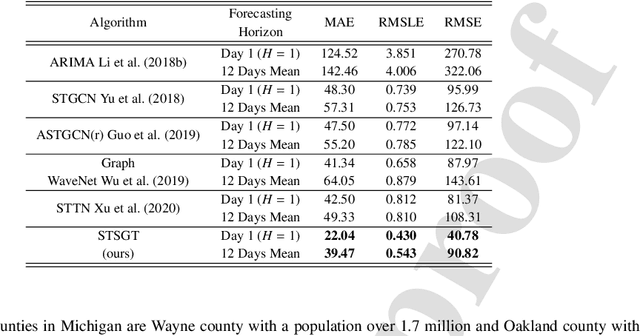
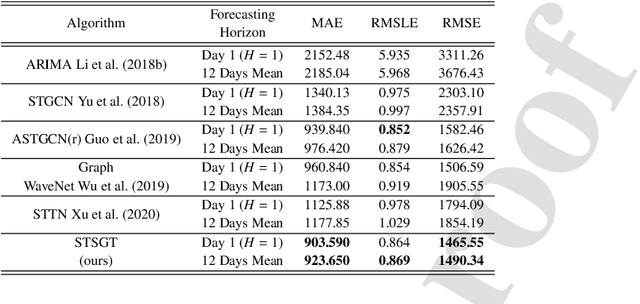
COVID-19 has become a matter of serious concern over the last few years. It has adversely affected numerous people around the globe and has led to the loss of billions of dollars of business capital. In this paper, we propose a novel Spatial-Temporal Synchronous Graph Transformer network (STSGT) to capture the complex spatial and temporal dependency of the COVID-19 time series data and forecast the future status of an evolving pandemic. The layers of STSGT combine the graph convolution network (GCN) with the self-attention mechanism of transformers on a synchronous spatial-temporal graph to capture the dynamically changing pattern of the COVID time series. The spatial-temporal synchronous graph simultaneously captures the spatial and temporal dependencies between the vertices of the graph at a given and subsequent time-steps, which helps capture the heterogeneity in the time series and improve the forecasting accuracy. Our extensive experiments on two publicly available real-world COVID-19 time series datasets demonstrate that STSGT significantly outperforms state-of-the-art algorithms that were designed for spatial-temporal forecasting tasks. Specifically, on average over a 12-day horizon, we observe a potential improvement of 12.19% and 3.42% in Mean Absolute Error(MAE) over the next best algorithm while forecasting the daily infected and death cases respectively for the 50 states of US and Washington, D.C. Additionally, STSGT also outperformed others when forecasting the daily infected cases at the state level, e.g., for all the counties in the State of Michigan. The code and models are publicly available at https://github.com/soumbane/STSGT.