 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
epsilon-Mesh Attack: A Surface-based Adversarial Point Cloud Attack for Facial Expression Recognition
Mar 11, 2024
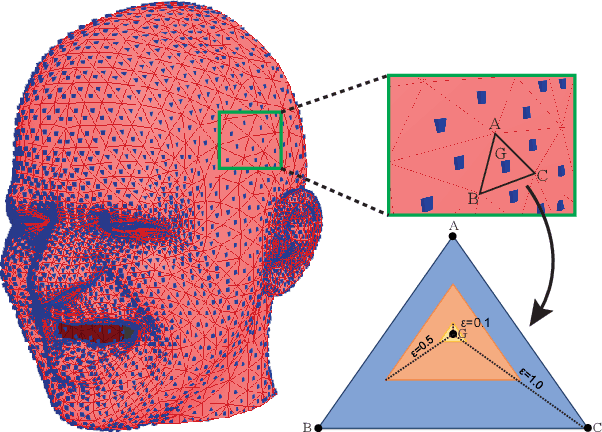
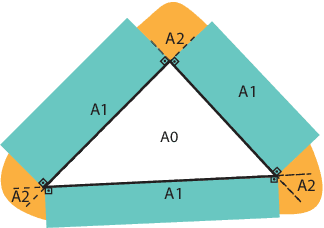
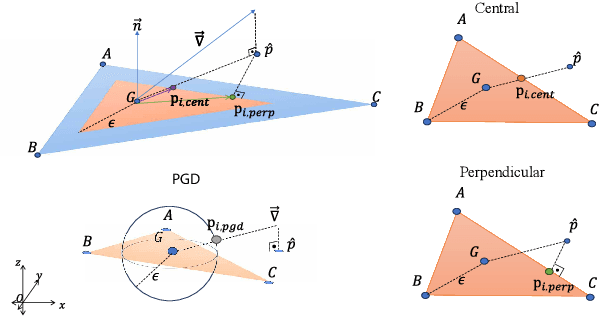
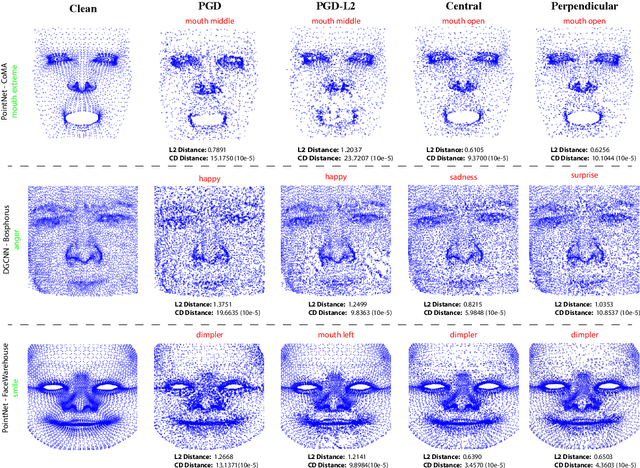
Point clouds and meshes are widely used 3D data structures for many computer vision applications. While the meshes represent the surfaces of an object, point cloud represents sampled points from the surface which is also the output of modern sensors such as LiDAR and RGB-D cameras. Due to the wide application area of point clouds and the recent advancements in deep neural networks, studies focusing on robust classification of the 3D point cloud data emerged. To evaluate the robustness of deep classifier networks, a common method is to use adversarial attacks where the gradient direction is followed to change the input slightly. The previous studies on adversarial attacks are generally evaluated on point clouds of daily objects. However, considering 3D faces, these adversarial attacks tend to affect the person's facial structure more than the desired amount and cause malformation. Specifically for facial expressions, even a small adversarial attack can have a significant effect on the face structure. In this paper, we suggest an adversarial attack called $\epsilon$-Mesh Attack, which operates on point cloud data via limiting perturbations to be on the mesh surface. We also parameterize our attack by $\epsilon$ to scale the perturbation mesh. Our surface-based attack has tighter perturbation bounds compared to $L_2$ and $L_\infty$ norm bounded attacks that operate on unit-ball. Even though our method has additional constraints, our experiments on CoMA, Bosphorus and FaceWarehouse datasets show that $\epsilon$-Mesh Attack (Perpendicular) successfully confuses trained DGCNN and PointNet models $99.72\%$ and $97.06\%$ of the time, with indistinguishable facial deformations. The code is available at https://github.com/batuceng/e-mesh-attack.
A Simple Framework Uniting Visual In-context Learning with Masked Image Modeling to Improve Ultrasound Segmentation
Mar 08, 2024Conventional deep learning models deal with images one-by-one, requiring costly and time-consuming expert labeling in the field of medical imaging, and domain-specific restriction limits model generalizability. Visual in-context learning (ICL) is a new and exciting area of research in computer vision. Unlike conventional deep learning, ICL emphasizes the model's ability to adapt to new tasks based on given examples quickly. Inspired by MAE-VQGAN, we proposed a new simple visual ICL method called SimICL, combining visual ICL pairing images with masked image modeling (MIM) designed for self-supervised learning. We validated our method on bony structures segmentation in a wrist ultrasound (US) dataset with limited annotations, where the clinical objective was to segment bony structures to help with further fracture detection. We used a test set containing 3822 images from 18 patients for bony region segmentation. SimICL achieved an remarkably high Dice coeffient (DC) of 0.96 and Jaccard Index (IoU) of 0.92, surpassing state-of-the-art segmentation and visual ICL models (a maximum DC 0.86 and IoU 0.76), with SimICL DC and IoU increasing up to 0.10 and 0.16. This remarkably high agreement with limited manual annotations indicates SimICL could be used for training AI models even on small US datasets. This could dramatically decrease the human expert time required for image labeling compared to conventional approaches, and enhance the real-world use of AI assistance in US image analysis.
Dynamics of Moral Behavior in Heterogeneous Populations of Learning Agents
Mar 08, 2024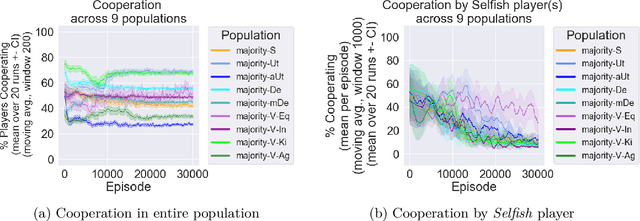

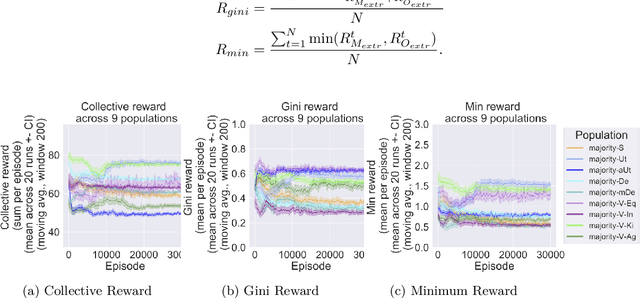

Growing concerns about safety and alignment of AI systems highlight the importance of embedding moral capabilities in artificial agents. A promising solution is the use of learning from experience, i.e., Reinforcement Learning. In multi-agent (social) environments, complex population-level phenomena may emerge from interactions between individual learning agents. Many of the existing studies rely on simulated social dilemma environments to study the interactions of independent learning agents. However, they tend to ignore the moral heterogeneity that is likely to be present in societies of agents in practice. For example, at different points in time a single learning agent may face opponents who are consequentialist (i.e., caring about maximizing some outcome over time) or norm-based (i.e., focusing on conforming to a specific norm here and now). The extent to which agents' co-development may be impacted by such moral heterogeneity in populations is not well understood. In this paper, we present a study of the learning dynamics of morally heterogeneous populations interacting in a social dilemma setting. Using a Prisoner's Dilemma environment with a partner selection mechanism, we investigate the extent to which the prevalence of diverse moral agents in populations affects individual agents' learning behaviors and emergent population-level outcomes. We observe several types of non-trivial interactions between pro-social and anti-social agents, and find that certain classes of moral agents are able to steer selfish agents towards more cooperative behavior.
FFSTC: Fongbe to French Speech Translation Corpus
Mar 08, 2024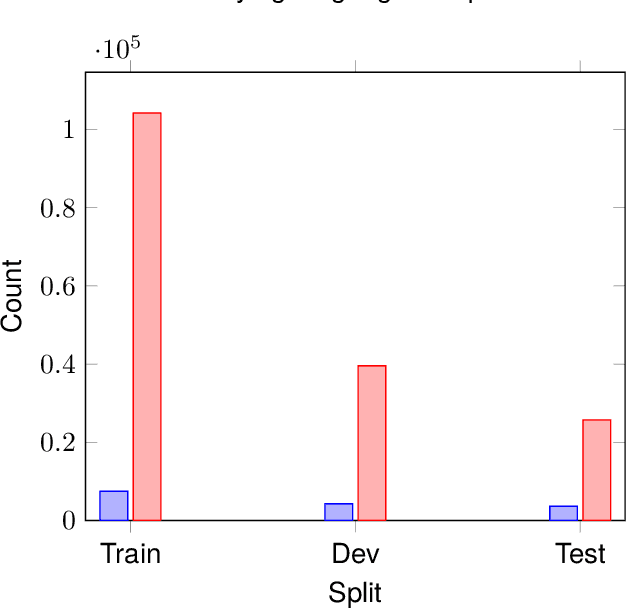
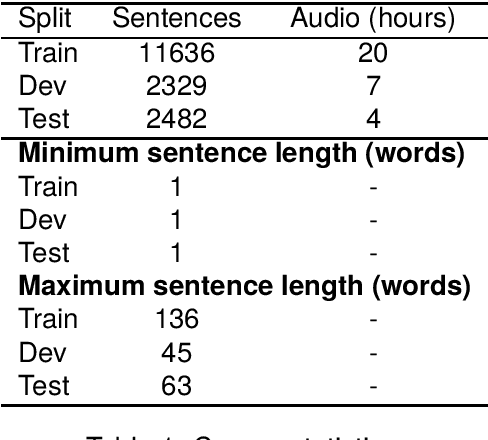
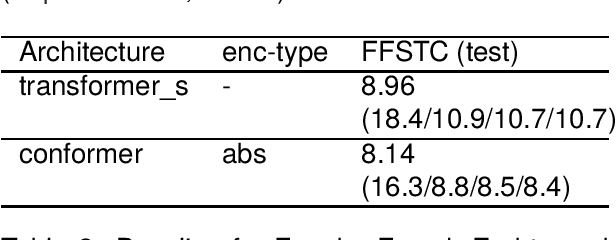
In this paper, we introduce the Fongbe to French Speech Translation Corpus (FFSTC) for the first time. This corpus encompasses approximately 31 hours of collected Fongbe language content, featuring both French transcriptions and corresponding Fongbe voice recordings. FFSTC represents a comprehensive dataset compiled through various collection methods and the efforts of dedicated individuals. Furthermore, we conduct baseline experiments using Fairseq's transformer_s and conformer models to evaluate data quality and validity. Our results indicate a score of 8.96 for the transformer_s model and 8.14 for the conformer model, establishing a baseline for the FFSTC corpus.
GARNN: An Interpretable Graph Attentive Recurrent Neural Network for Predicting Blood Glucose Levels via Multivariate Time Series
Feb 26, 2024Accurate prediction of future blood glucose (BG) levels can effectively improve BG management for people living with diabetes, thereby reducing complications and improving quality of life. The state of the art of BG prediction has been achieved by leveraging advanced deep learning methods to model multi-modal data, i.e., sensor data and self-reported event data, organised as multi-variate time series (MTS). However, these methods are mostly regarded as ``black boxes'' and not entirely trusted by clinicians and patients. In this paper, we propose interpretable graph attentive recurrent neural networks (GARNNs) to model MTS, explaining variable contributions via summarizing variable importance and generating feature maps by graph attention mechanisms instead of post-hoc analysis. We evaluate GARNNs on four datasets, representing diverse clinical scenarios. Upon comparison with twelve well-established baseline methods, GARNNs not only achieve the best prediction accuracy but also provide high-quality temporal interpretability, in particular for postprandial glucose levels as a result of corresponding meal intake and insulin injection. These findings underline the potential of GARNN as a robust tool for improving diabetes care, bridging the gap between deep learning technology and real-world healthcare solutions.
A Survey on Applications of Reinforcement Learning in Spatial Resource Allocation
Mar 07, 2024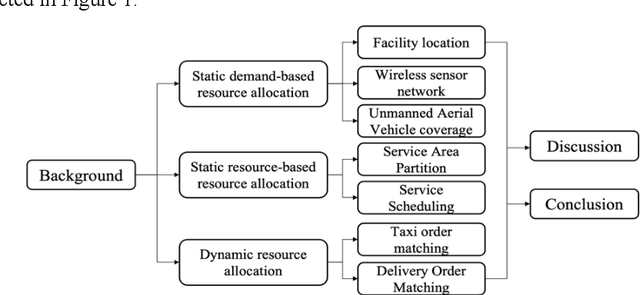
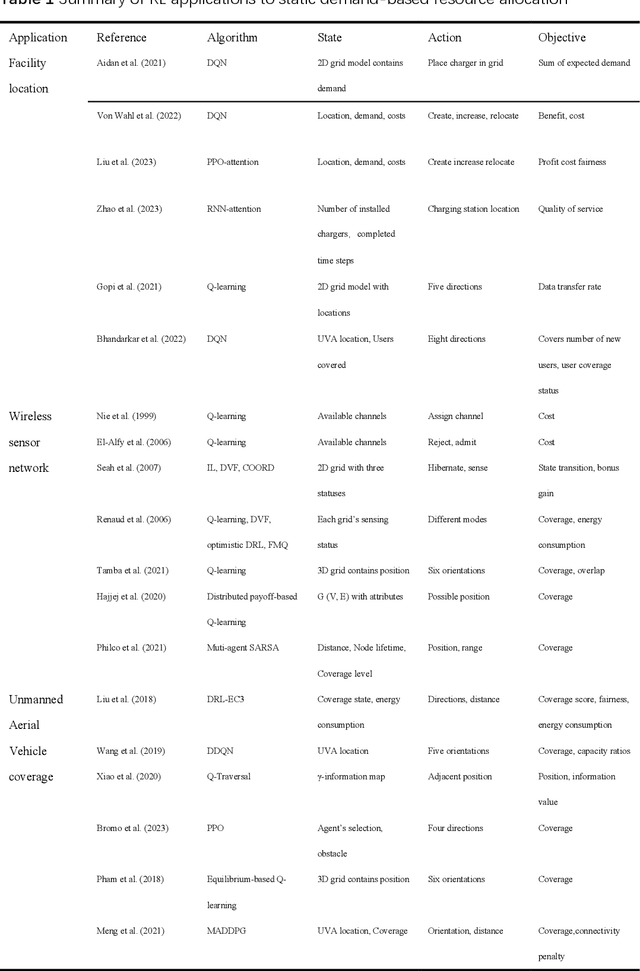
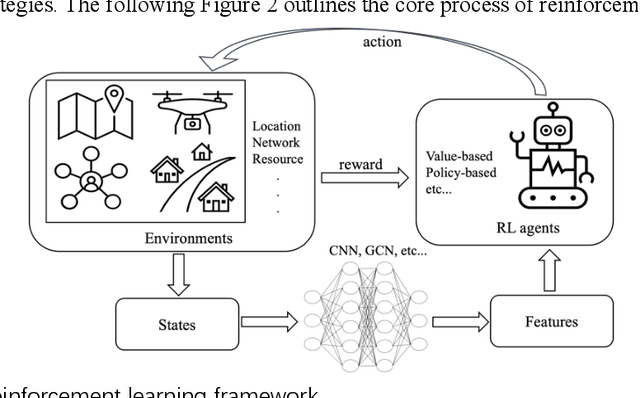
The challenge of spatial resource allocation is pervasive across various domains such as transportation, industry, and daily life. As the scale of real-world issues continues to expand and demands for real-time solutions increase, traditional algorithms face significant computational pressures, struggling to achieve optimal efficiency and real-time capabilities. In recent years, with the escalating computational power of computers, the remarkable achievements of reinforcement learning in domains like Go and robotics have demonstrated its robust learning and sequential decision-making capabilities. Given these advancements, there has been a surge in novel methods employing reinforcement learning to tackle spatial resource allocation problems. These methods exhibit advantages such as rapid solution convergence and strong model generalization abilities, offering a new perspective on resolving spatial resource allocation problems. Therefore, this paper aims to summarize and review recent theoretical methods and applied research utilizing reinforcement learning to address spatial resource allocation problems. It provides a summary and comprehensive overview of its fundamental principles, related methodologies, and applied research. Additionally, it highlights several unresolved issues that urgently require attention in this direction for the future.
E2USD: Efficient-yet-effective Unsupervised State Detection for Multivariate Time Series
Feb 21, 2024We propose E2USD that enables efficient-yet-accurate unsupervised MTS state detection. E2USD exploits a Fast Fourier Transform-based Time Series Compressor (FFTCompress) and a Decomposed Dual-view Embedding Module (DDEM) that together encode input MTSs at low computational overhead. Additionally, we propose a False Negative Cancellation Contrastive Learning method (FNCCLearning) to counteract the effects of false negatives and to achieve more cluster-friendly embedding spaces. To reduce computational overhead further in streaming settings, we introduce Adaptive Threshold Detection (ADATD). Comprehensive experiments with six baselines and six datasets offer evidence that E2USD is capable of SOTA accuracy at significantly reduced computational overhead. Our code is available at https://github.com/AI4CTS/E2Usd.
Multimodal deep learning approach to predicting neurological recovery from coma after cardiac arrest
Mar 09, 2024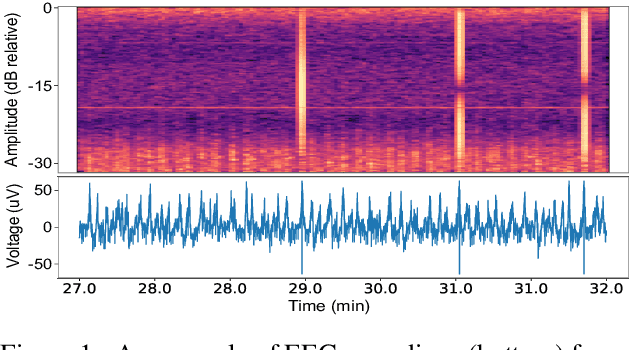
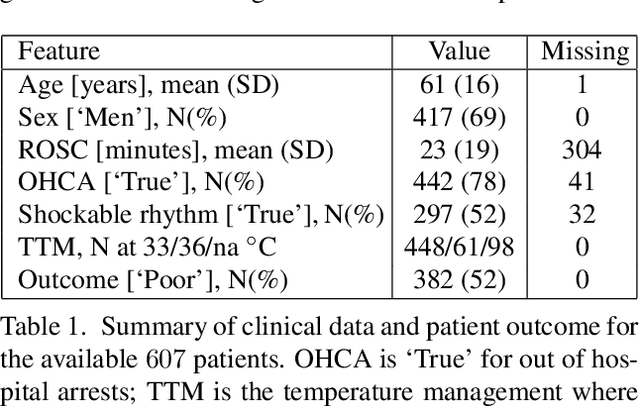
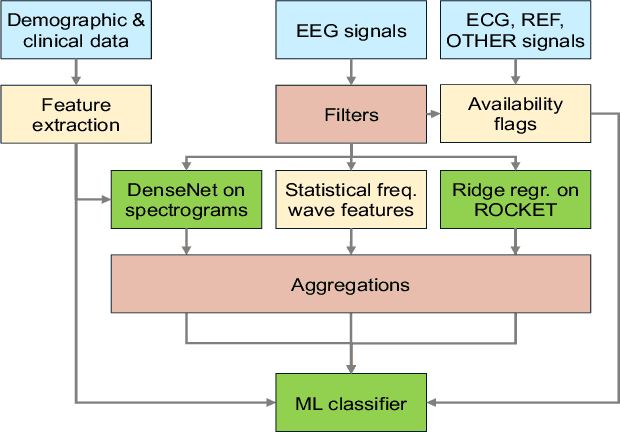

This work showcases our team's (The BEEGees) contributions to the 2023 George B. Moody PhysioNet Challenge. The aim was to predict neurological recovery from coma following cardiac arrest using clinical data and time-series such as multi-channel EEG and ECG signals. Our modelling approach is multimodal, based on two-dimensional spectrogram representations derived from numerous EEG channels, alongside the integration of clinical data and features extracted directly from EEG recordings. Our submitted model achieved a Challenge score of $0.53$ on the hidden test set for predictions made $72$ hours after return of spontaneous circulation. Our study shows the efficacy and limitations of employing transfer learning in medical classification. With regard to prospective implementation, our analysis reveals that the performance of the model is strongly linked to the selection of a decision threshold and exhibits strong variability across data splits.
Unveiling Ancient Maya Settlements Using Aerial LiDAR Image Segmentation
Mar 09, 2024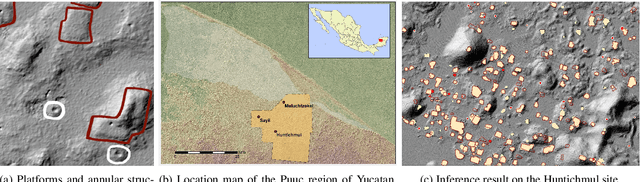

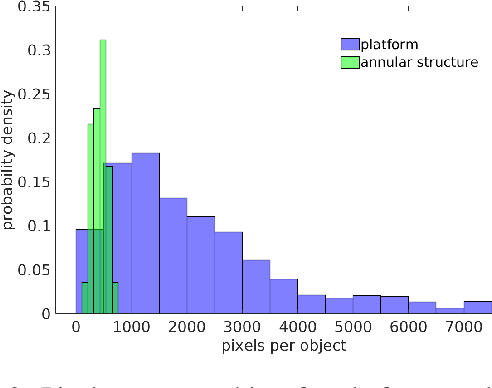
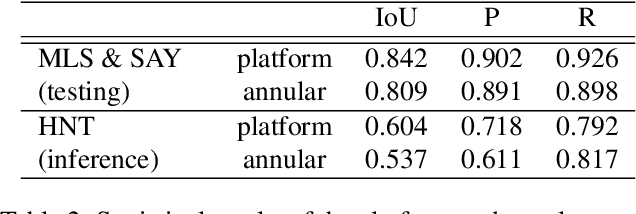
Manual identification of archaeological features in LiDAR imagery is labor-intensive, costly, and requires archaeological expertise. This paper shows how recent advancements in deep learning (DL) present efficient solutions for accurately segmenting archaeological structures in aerial LiDAR images using the YOLOv8 neural network. The proposed approach uses novel pre-processing of the raw LiDAR data and dataset augmentation methods to produce trained YOLOv8 networks to improve accuracy, precision, and recall for the segmentation of two important Maya structure types: annular structures and platforms. The results show an IoU performance of 0.842 for platforms and 0.809 for annular structures which outperform existing approaches. Further, analysis via domain experts considers the topological consistency of segmented regions and performance vs. area providing important insights. The approach automates time-consuming LiDAR image labeling which significantly accelerates accurate analysis of historical landscapes.
Unraveling the Mystery of Scaling Laws: Part I
Mar 11, 2024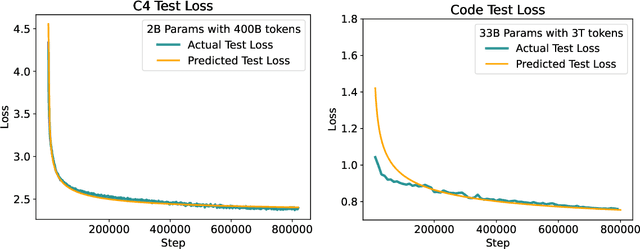
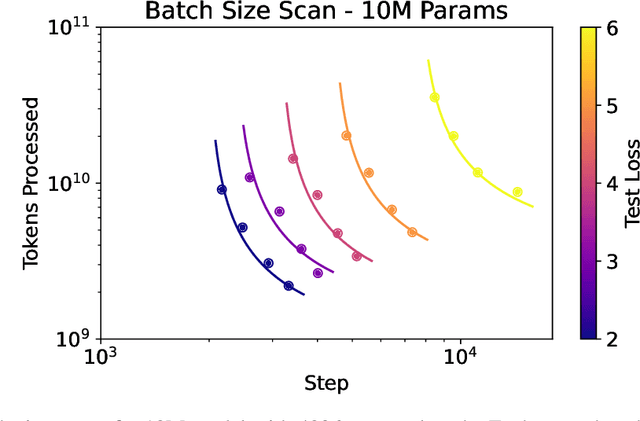
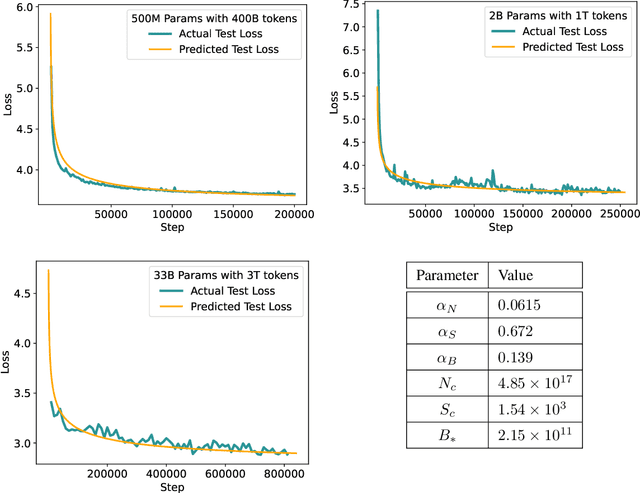
Scaling law principles indicate a power-law correlation between loss and variables such as model size, dataset size, and computational resources utilized during training. These principles play a vital role in optimizing various aspects of model pre-training, ultimately contributing to the success of large language models such as GPT-4, Llama and Gemini. However, the original scaling law paper by OpenAI did not disclose the complete details necessary to derive the precise scaling law formulas, and their conclusions are only based on models containing up to 1.5 billion parameters. Though some subsequent works attempt to unveil these details and scale to larger models, they often neglect the training dependency of important factors such as the learning rate, context length and batch size, leading to their failure to establish a reliable formula for predicting the test loss trajectory. In this technical report, we confirm that the scaling law formulations proposed in the original OpenAI paper remain valid when scaling the model size up to 33 billion, but the constant coefficients in these formulas vary significantly with the experiment setup. We meticulously identify influential factors and provide transparent, step-by-step instructions to estimate all constant terms in scaling-law formulas by training on models with only 1M~60M parameters. Using these estimated formulas, we showcase the capability to accurately predict various attributes for models with up to 33B parameters before their training, including (1) the minimum possible test loss; (2) the minimum required training steps and processed tokens to achieve a specific loss; (3) the critical batch size with an optimal time/computation trade-off at any loss value; and (4) the complete test loss trajectory with arbitrary batch size.