 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Perfect Match: RIS-enabled MIMO Channel Estimation Using Tensor Decomposition
Nov 18, 2022
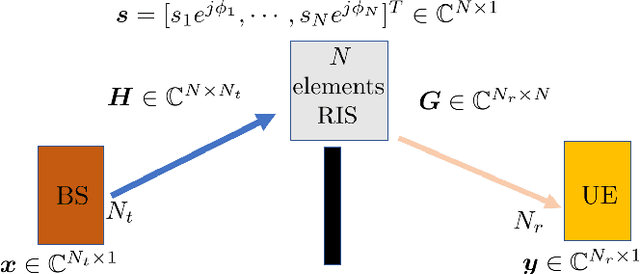
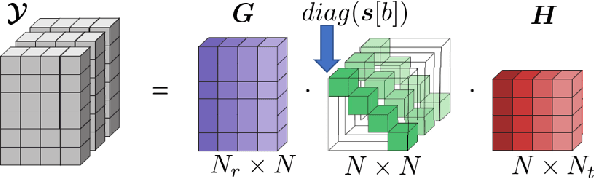
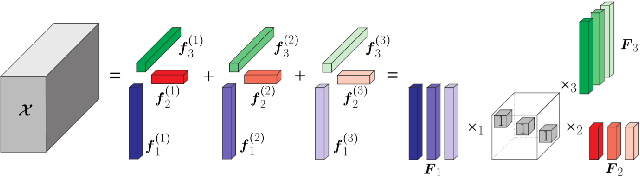

The deployment of reconfigurable intelligent surfaces (RISs) in a communication system provides control over the propagation environment, which facilitates the augmentation of a multitude of communication objectives. As these performance gains are highly dependent on the applied phase shifts at the RIS, accurate channel state information at the transceivers is imperative. However, not only do RISs traditionally lack signal processing capabilities, but their end-to-end channels also consist of multiple components. Hence, conventional channel estimation (CE) algorithms become incompatible with RIS-aided communication systems as they fail to provide the necessary information about the channel components, which are essential for a beneficial RIS configuration. To enable the full potential of RISs, we propose to use tensor-decomposition-based CE, which facilitates smart configuration of the RIS by providing the required channel components. We use canonical polyadic (CP) decomposition, that exploits a structured time domain pilot sequence. Compared to other state-of-the-art decomposition methods, the proposed Semi-Algebraic CP decomposition via Simultaneous Matrix Diagonalization (SECSI) algorithm is more time efficient as it does not require an iterative process. The benefits of SECSI for RIS-aided networks are validated with numerical results, which show the improved individual and end-to-end CE accuracy of SECSI.
Adaptive De-noising of Photoacoustic Signal and Image based on Modified Kalman Filter
Nov 18, 2022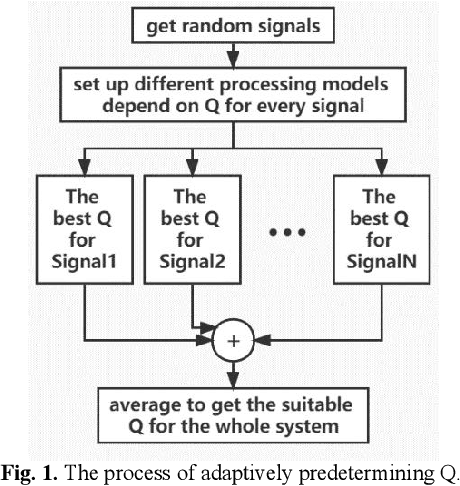
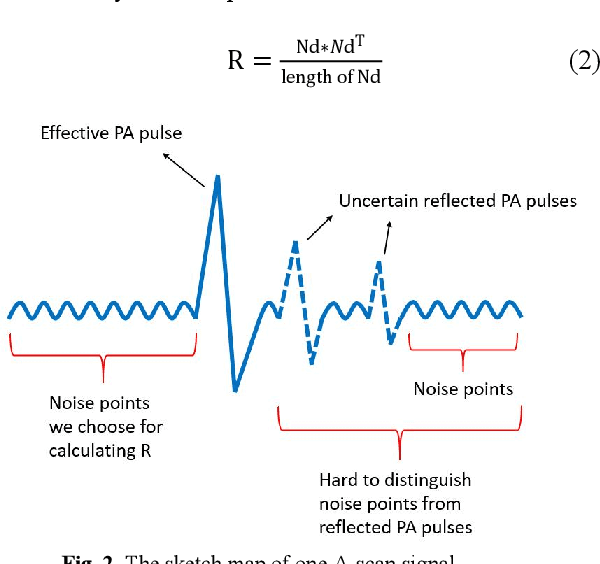
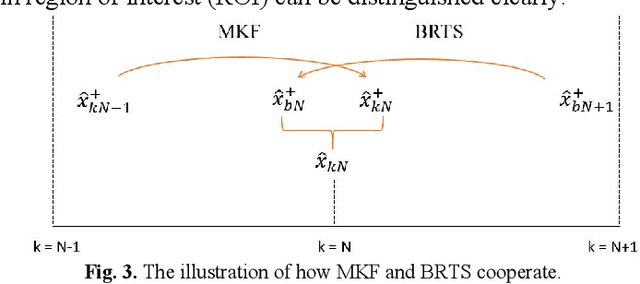
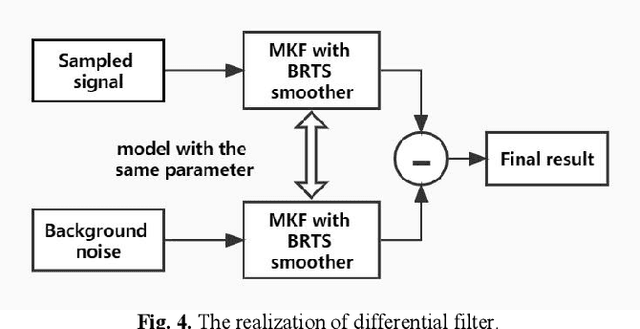
As a burgeoning medical imaging method based on hybrid fusion of light and ultrasound, photoacoustic imaging (PAI) has demonstrated high potential in various biomedical applications recently, especially in revealing the functional and molecular information to improve diagnostic accuracy. However, stemming from weak amplitude and unavoidable random noise, caused by limited laser power and severe attenuation in deep tissue imaging, PA signals are usually of low signal-to-noise ratio (SNR), and reconstructed PA images are of low quality. Despite that conventional Kalman Filter (KF) can remove Gaussian noise in time domain, it lacks adaptability in real-time estimating condition due to its fixed model. Moreover, KF-based de-noising algorithm has not been applied in PAI before. In this paper, we propose an adaptive Modified Kalman Filter (MKF) targeted at PAI de-noising by tuning system noise matrix Q and measurement noise matrix R in the conventional KF model. Additionally, in order to compensate the signal skewing caused by KF, we cascade the backward part of Rauch-Tung-Striebel smoother (BRTS), which also utilizes the newly determined Q. Finally, as a supplement, we add a commonly used differential filter to remove in-band reflection artifacts. Experimental results using phantom and ex vivo colorectal tissue are provided to prove the validity of the algorithm.
Is Conditional Generative Modeling all you need for Decision-Making?
Dec 07, 2022
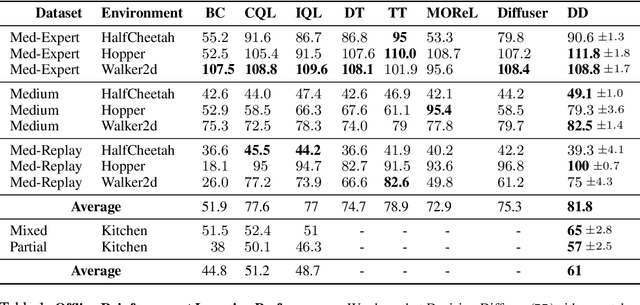
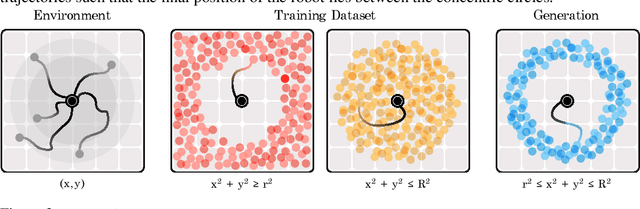

Recent improvements in conditional generative modeling have made it possible to generate high-quality images from language descriptions alone. We investigate whether these methods can directly address the problem of sequential decision-making. We view decision-making not through the lens of reinforcement learning (RL), but rather through conditional generative modeling. To our surprise, we find that our formulation leads to policies that can outperform existing offline RL approaches across standard benchmarks. By modeling a policy as a return-conditional diffusion model, we illustrate how we may circumvent the need for dynamic programming and subsequently eliminate many of the complexities that come with traditional offline RL. We further demonstrate the advantages of modeling policies as conditional diffusion models by considering two other conditioning variables: constraints and skills. Conditioning on a single constraint or skill during training leads to behaviors at test-time that can satisfy several constraints together or demonstrate a composition of skills. Our results illustrate that conditional generative modeling is a powerful tool for decision-making.
Self-Supervised Geometry-Aware Encoder for Style-Based 3D GAN Inversion
Dec 15, 2022
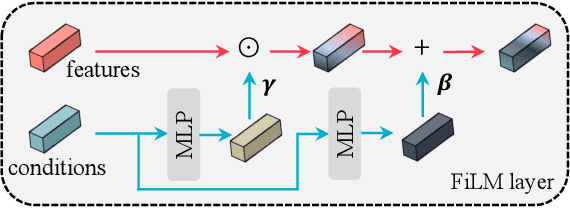

StyleGAN has achieved great progress in 2D face reconstruction and semantic editing via image inversion and latent editing. While studies over extending 2D StyleGAN to 3D faces have emerged, a corresponding generic 3D GAN inversion framework is still missing, limiting the applications of 3D face reconstruction and semantic editing. In this paper, we study the challenging problem of 3D GAN inversion where a latent code is predicted given a single face image to faithfully recover its 3D shapes and detailed textures. The problem is ill-posed: innumerable compositions of shape and texture could be rendered to the current image. Furthermore, with the limited capacity of a global latent code, 2D inversion methods cannot preserve faithful shape and texture at the same time when applied to 3D models. To solve this problem, we devise an effective self-training scheme to constrain the learning of inversion. The learning is done efficiently without any real-world 2D-3D training pairs but proxy samples generated from a 3D GAN. In addition, apart from a global latent code that captures the coarse shape and texture information, we augment the generation network with a local branch, where pixel-aligned features are added to faithfully reconstruct face details. We further consider a new pipeline to perform 3D view-consistent editing. Extensive experiments show that our method outperforms state-of-the-art inversion methods in both shape and texture reconstruction quality. Code and data will be released.
NAWQ-SR: A Hybrid-Precision NPU Engine for Efficient On-Device Super-Resolution
Dec 15, 2022
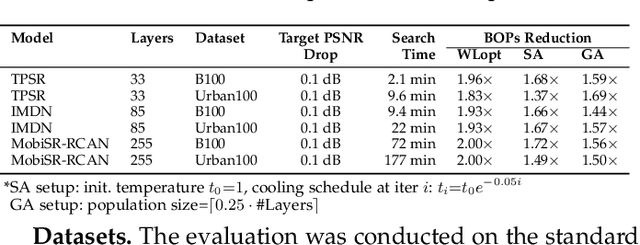
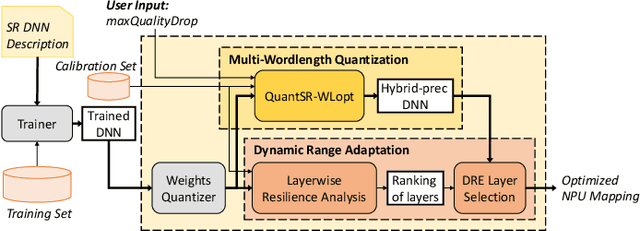
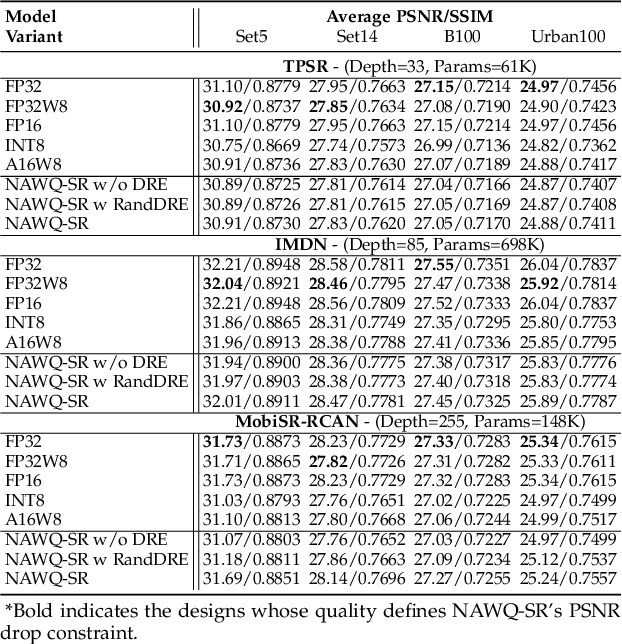
In recent years, image and video delivery systems have begun integrating deep learning super-resolution (SR) approaches, leveraging their unprecedented visual enhancement capabilities while reducing reliance on networking conditions. Nevertheless, deploying these solutions on mobile devices still remains an active challenge as SR models are excessively demanding with respect to workload and memory footprint. Despite recent progress on on-device SR frameworks, existing systems either penalize visual quality, lead to excessive energy consumption or make inefficient use of the available resources. This work presents NAWQ-SR, a novel framework for the efficient on-device execution of SR models. Through a novel hybrid-precision quantization technique and a runtime neural image codec, NAWQ-SR exploits the multi-precision capabilities of modern mobile NPUs in order to minimize latency, while meeting user-specified quality constraints. Moreover, NAWQ-SR selectively adapts the arithmetic precision at run time to equip the SR DNN's layers with wider representational power, improving visual quality beyond what was previously possible on NPUs. Altogether, NAWQ-SR achieves an average speedup of 7.9x, 3x and 1.91x over the state-of-the-art on-device SR systems that use heterogeneous processors (MobiSR), CPU (SplitSR) and NPU (XLSR), respectively. Furthermore, NAWQ-SR delivers an average of 3.2x speedup and 0.39 dB higher PSNR over status-quo INT8 NPU designs, but most importantly mitigates the negative effects of quantization on visual quality, setting a new state-of-the-art in the attainable quality of NPU-based SR.
Meta-Learned Kernel For Blind Super-Resolution Kernel Estimation
Dec 15, 2022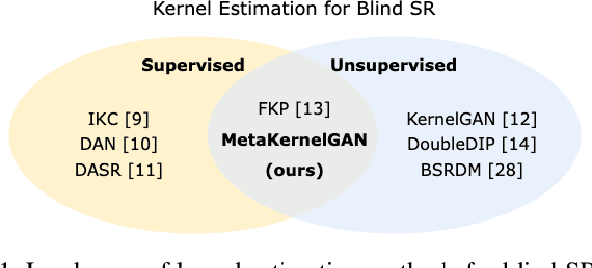
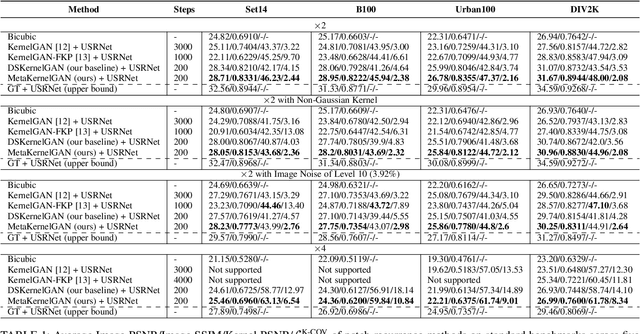
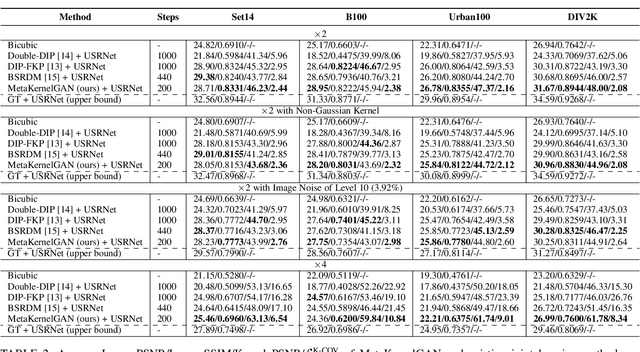
Recent image degradation estimation methods have enabled single-image super-resolution (SR) approaches to better upsample real-world images. Among these methods, explicit kernel estimation approaches have demonstrated unprecedented performance at handling unknown degradations. Nonetheless, a number of limitations constrain their efficacy when used by downstream SR models. Specifically, this family of methods yields i) excessive inference time due to long per-image adaptation times and ii) inferior image fidelity due to kernel mismatch. In this work, we introduce a learning-to-learn approach that meta-learns from the information contained in a distribution of images, thereby enabling significantly faster adaptation to new images with substantially improved performance in both kernel estimation and image fidelity. Specifically, we meta-train a kernel-generating GAN, named MetaKernelGAN, on a range of tasks, such that when a new image is presented, the generator starts from an informed kernel estimate and the discriminator starts with a strong capability to distinguish between patch distributions. Compared with state-of-the-art methods, our experiments show that MetaKernelGAN better estimates the magnitude and covariance of the kernel, leading to state-of-the-art blind SR results within a similar computational regime when combined with a non-blind SR model. Through supervised learning of an unsupervised learner, our method maintains the generalizability of the unsupervised learner, improves the optimization stability of kernel estimation, and hence image adaptation, and leads to a faster inference with a speedup between 14.24 to 102.1x over existing methods.
Versatile Real-Time Motion Synthesis via Kino-Dynamic MPC with Hybrid-Systems DDP
Sep 28, 2022
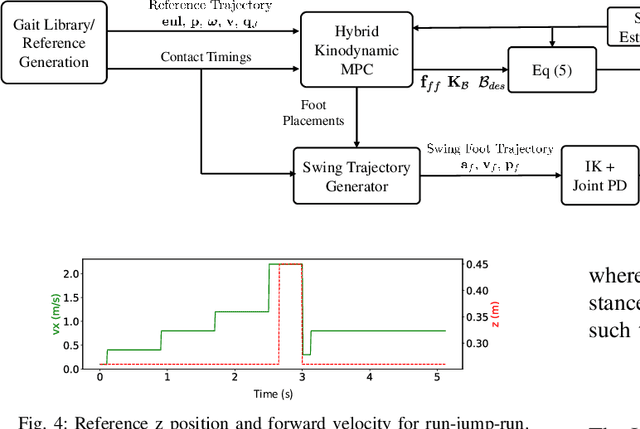
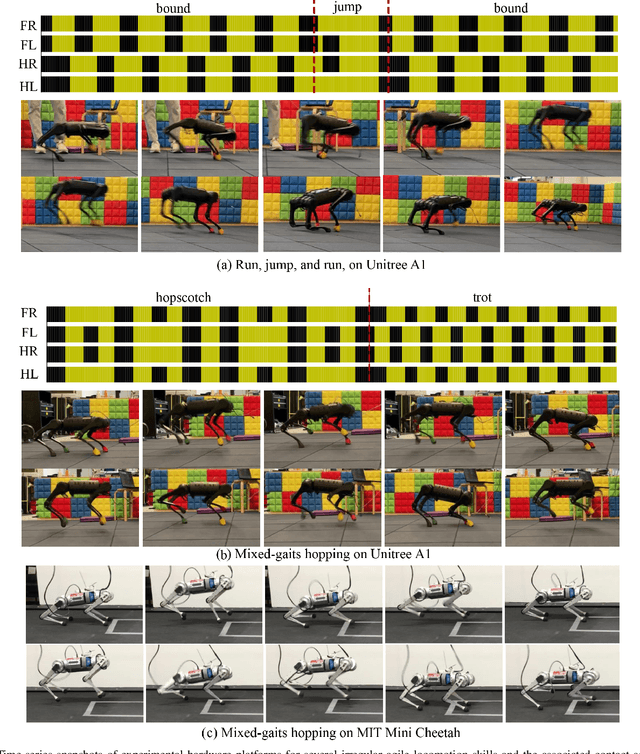
Specialized motions such as jumping are often achieved on quadruped robots by solving a trajectory optimization problem once and executing the trajectory using a tracking controller. This approach is in parallel with Model Predictive Control (MPC) strategies that commonly control regular gaits via online re-planning. In this work, we present a nonlinear MPC (NMPC) technique that unlocks on-the-fly re-planning of specialized motion skills and regular locomotion within a unified framework. The NMPC reasons about a hybrid kinodynamic model, and is solved using a variant of a constrained Differential Dynamic Programming (DDP) solver. The proposed NMPC enables the robot to perform a variety of agile skills like jumping, bounding, and trotting, and the rapid transition between these skills. We evaluated the proposed algorithm with three challenging motion sequences that combine multiple agile skills, on two quadruped platforms, Unitree A1, and MIT Mini Cheetah, showing its effectiveness and generality.
Photonics-based short-time Fourier transform without high-frequency electronic devices and equipment
Jul 04, 2022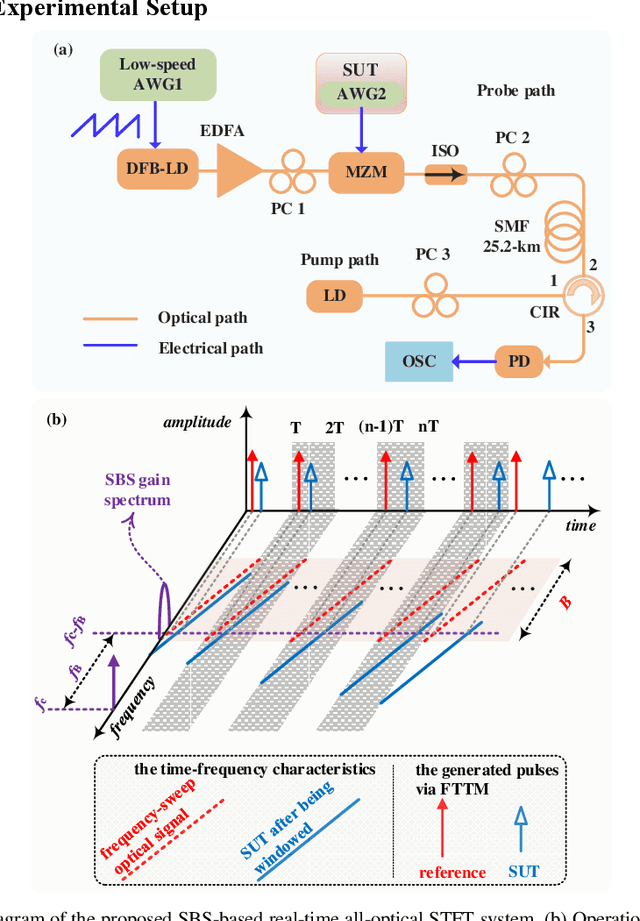
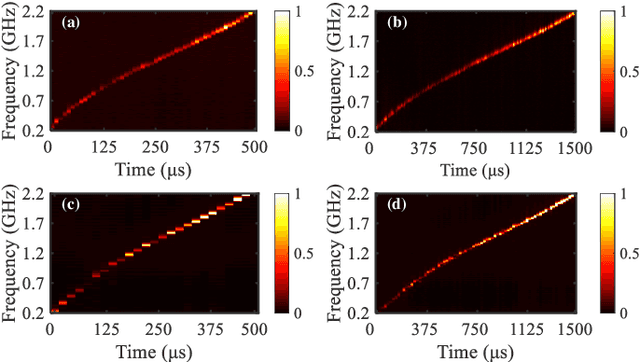
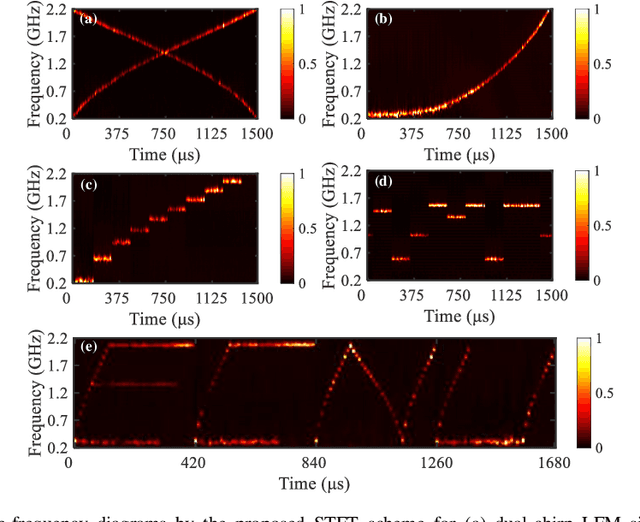
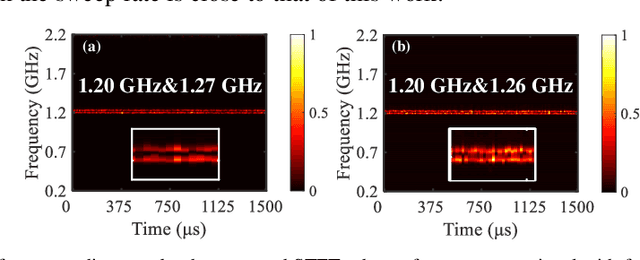
A photonics-based short-time Fourier transform (STFT) system is proposed and experimentally demonstrated based on stimulated Brillouin scattering (SBS) without using high-frequency electronic devices and equipment. The wavelength of a distributed feedback laser diode is periodically swept by using a low-speed periodic sawtooth/triangular driving current. The periodic frequency-sweep optical signal is modulated by the signal under test (SUT) and then injected into a section of SBS medium. The optical signal from another laser diode as the pump wave is reversely injected into the SBS medium. After simply detecting the forward transmission optical signals in a low-speed photodetector, the STFT of the SUT can be implemented. The system is characterized by the absence of any high-frequency electronic devices or equipment. An experiment is performed. The STFT of a variety of RF signals is carried out in a 4-GHz bandwidth. The dynamic frequency resolution is demonstrated to be around 60 MHz.
Galaxy classification: a deep learning approach for classifying Sloan Digital Sky Survey images
Nov 01, 2022
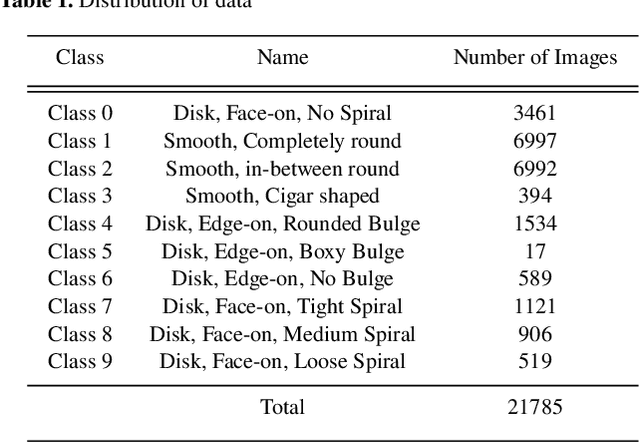
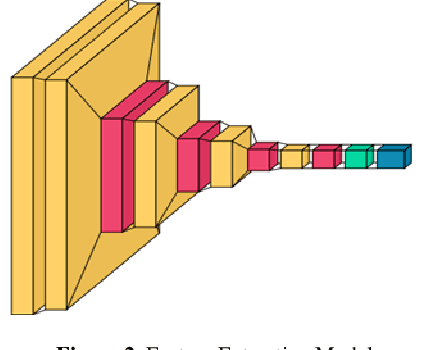
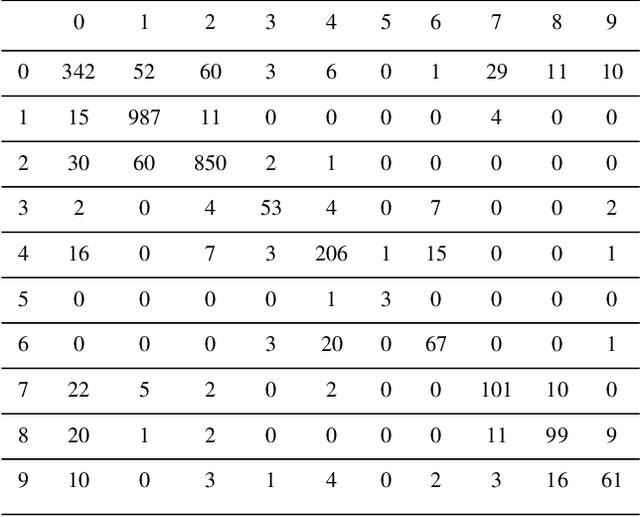
In recent decades, large-scale sky surveys such as Sloan Digital Sky Survey (SDSS) have resulted in generation of tremendous amount of data. The classification of this enormous amount of data by astronomers is time consuming. To simplify this process, in 2007 a volunteer-based citizen science project called Galaxy Zoo was introduced, which has reduced the time for classification by a good extent. However, in this modern era of deep learning, automating this classification task is highly beneficial as it reduces the time for classification. For the last few years, many algorithms have been proposed which happen to do a phenomenal job in classifying galaxies into multiple classes. But all these algorithms tend to classify galaxies into less than six classes. However, after considering the minute information which we know about galaxies, it is necessary to classify galaxies into more than eight classes. In this study, a neural network model is proposed so as to classify SDSS data into 10 classes from an extended Hubble Tuning Fork. Great care is given to disc edge and disc face galaxies, distinguishing between a variety of substructures and minute features which are associated with each class. The proposed model consists of convolution layers to extract features making this method fully automatic. The achieved test accuracy is 84.73 per cent which happens to be promising after considering such minute details in classes. Along with convolution layers, the proposed model has three more layers responsible for classification, which makes the algorithm consume less time.
* Published in MNRAS
A Reliable and Low Latency Synchronizing Middleware for Co-simulation of a Heterogeneous Multi-Robot Systems
Nov 10, 2022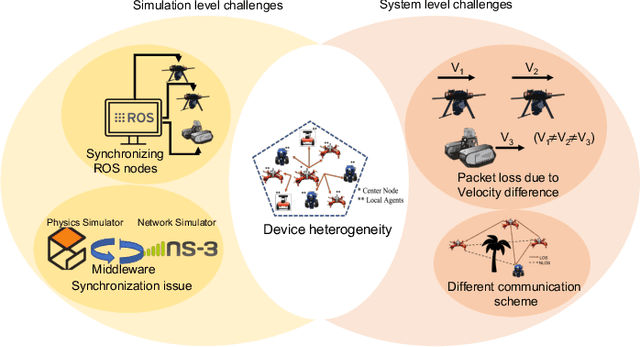
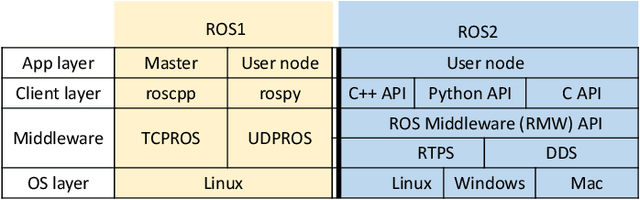

Search and rescue, wildfire monitoring, and flood/hurricane impact assessment are mission-critical services for recent IoT networks. Communication synchronization, dependability, and minimal communication jitter are major simulation and system issues for the time-based physics-based ROS simulator, event-based network-based wireless simulator, and complex dynamics of mobile and heterogeneous IoT devices deployed in actual environments. Simulating a heterogeneous multi-robot system before deployment is difficult due to synchronizing physics (robotics) and network simulators. Due to its master-based architecture, most TCP/IP-based synchronization middlewares use ROS1. A real-time ROS2 architecture with masterless packet discovery synchronizes robotics and wireless network simulations. A velocity-aware Transmission Control Protocol (TCP) technique for ground and aerial robots using Data Distribution Service (DDS) publish-subscribe transport minimizes packet loss, synchronization, transmission, and communication jitters. Gazebo and NS-3 simulate and test. Simulator-agnostic middleware. LOS/NLOS and TCP/UDP protocols tested our ROS2-based synchronization middleware for packet loss probability and average latency. A thorough ablation research replaced NS-3 with EMANE, a real-time wireless network simulator, and masterless ROS2 with master-based ROS1. Finally, we tested network synchronization and jitter using one aerial drone (Duckiedrone) and two ground vehicles (TurtleBot3 Burger) on different terrains in masterless (ROS2) and master-enabled (ROS1) clusters. Our middleware shows that a large-scale IoT infrastructure with a diverse set of stationary and robotic devices can achieve low-latency communications (12% and 11% reduction in simulation and real) while meeting mission-critical application reliability (10% and 15% packet loss reduction) and high-fidelity requirements.