 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pseudo-Riemannian Embedding Models for Multi-Relational Graph Representations
Dec 02, 2022
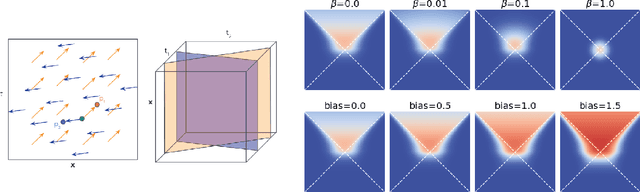
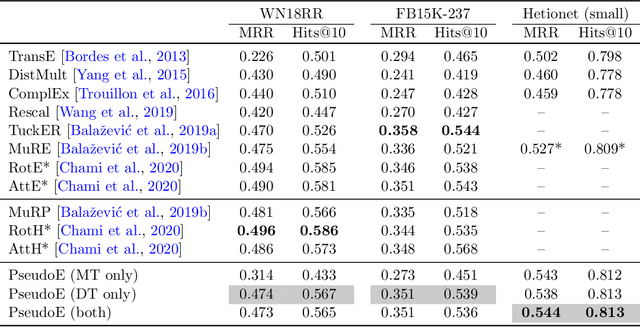
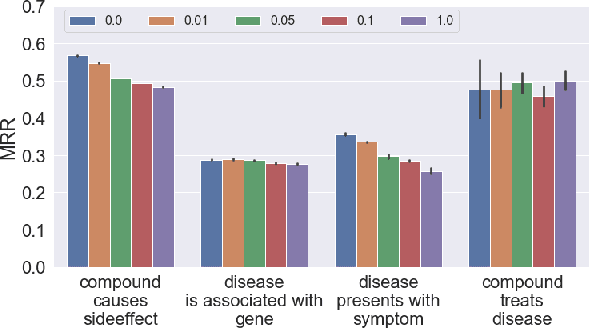
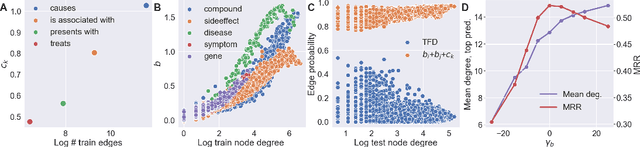
In this paper we generalize single-relation pseudo-Riemannian graph embedding models to multi-relational networks, and show that the typical approach of encoding relations as manifold transformations translates from the Riemannian to the pseudo-Riemannian case. In addition we construct a view of relations as separate spacetime submanifolds of multi-time manifolds, and consider an interpolation between a pseudo-Riemannian embedding model and its Wick-rotated Riemannian counterpart. We validate these extensions in the task of link prediction, focusing on flat Lorentzian manifolds, and demonstrate their use in both knowledge graph completion and knowledge discovery in a biological domain.
* 11 pages, 3 figures, AKBC 2022 conference
Delay Embedded Echo-State Network: A Predictor for Partially Observed Systems
Nov 11, 2022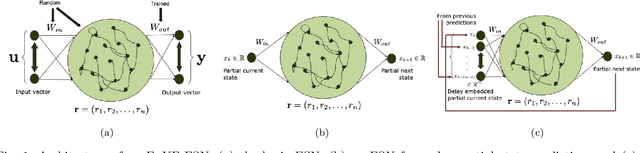

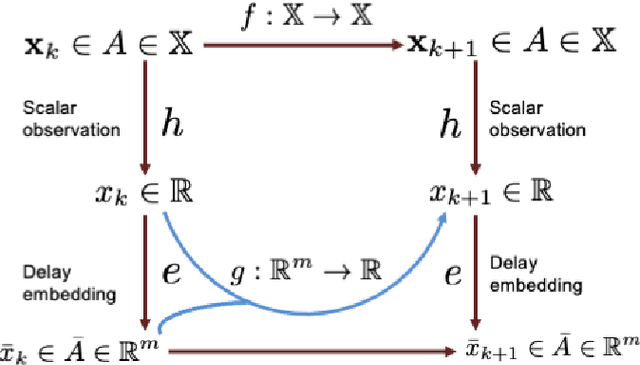
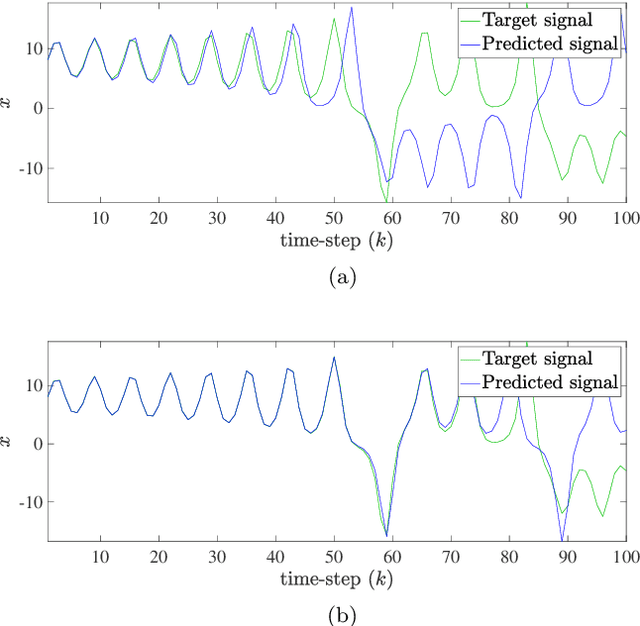
This paper considers the problem of data-driven prediction of partially observed systems using a recurrent neural network. While neural network based dynamic predictors perform well with full-state training data, prediction with partial observation during training phase poses a significant challenge. Here a predictor for partial observations is developed using an echo-state network (ESN) and time delay embedding of the partially observed state. The proposed method is theoretically justified with Taken's embedding theorem and strong observability of a nonlinear system. The efficacy of the proposed method is demonstrated on three systems: two synthetic datasets from chaotic dynamical systems and a set of real-time traffic data.
Space, Time, and Interaction: A Taxonomy of Corner Cases in Trajectory Datasets for Automated Driving
Oct 17, 2022
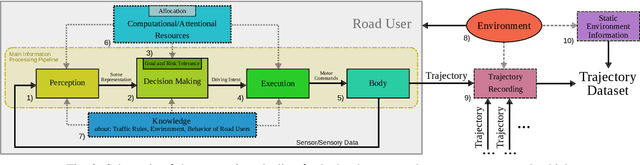
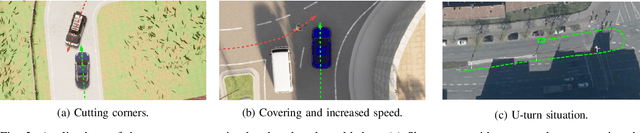
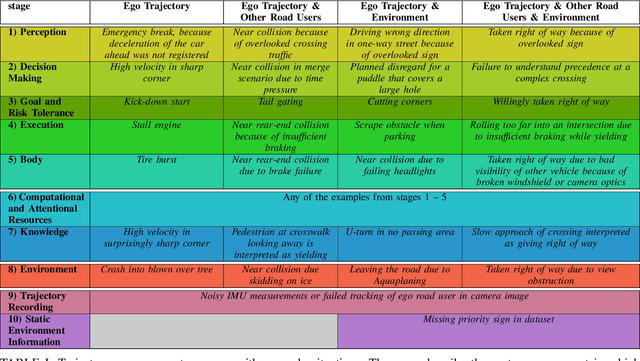
Trajectory data analysis is an essential component for highly automated driving. Complex models developed with these data predict other road users' movement and behavior patterns. Based on these predictions - and additional contextual information such as the course of the road, (traffic) rules, and interaction with other road users - the highly automated vehicle (HAV) must be able to reliably and safely perform the task assigned to it, e.g., moving from point A to B. Ideally, the HAV moves safely through its environment, just as we would expect a human driver to do. However, if unusual trajectories occur, so-called trajectory corner cases, a human driver can usually cope well, but an HAV can quickly get into trouble. In the definition of trajectory corner cases, which we provide in this work, we will consider the relevance of unusual trajectories with respect to the task at hand. Based on this, we will also present a taxonomy of different trajectory corner cases. The categorization of corner cases into the taxonomy will be shown with examples and is done by cause and required data sources. To illustrate the complexity between the machine learning (ML) model and the corner case cause, we present a general processing chain underlying the taxonomy.
Joint Direction-of-Arrival and Time-of-Arrival Estimation with Ultra-wideband Elliptical Arrays
Jul 26, 2022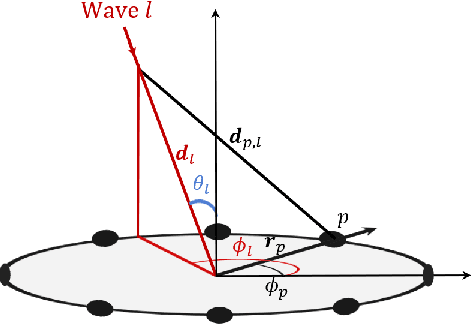
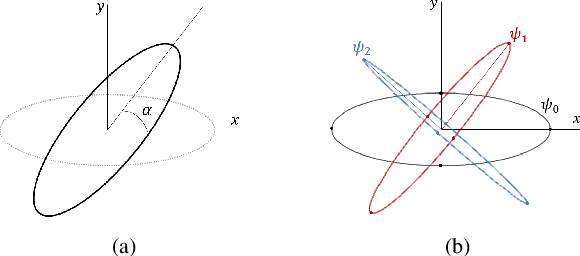
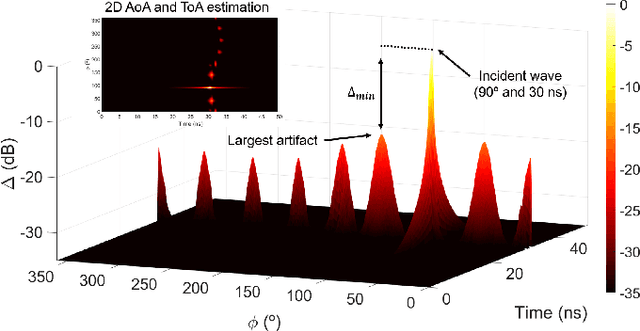
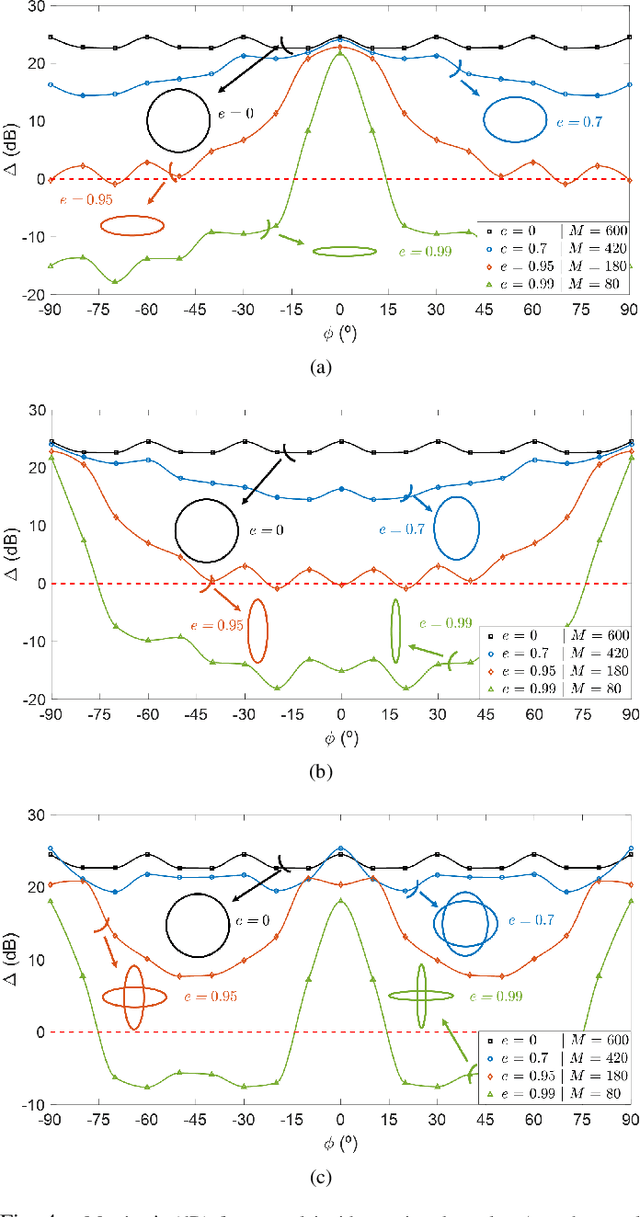
This paper presents a general technique for the joint Direction-of-Arrival (DoA) and Time-of-Arrival (ToA) estimation in multipath environments. The proposed ultra-wideband technique is based on phase-mode expansions and the use of nearly frequency-invariant elliptical arrays. New possibilities open with the present approach, as not only elliptical, but also circular and linear arrays can be considered with the same implementation. Systematic selection/rejection of signals-of-interest/signals-not-of-interest in smart wireless environments is possible, unlike with previous approaches based on circular arrays. Concentric elliptical arrays of many sizes and eccentricities can be jointly considered, with the subsequent improvement that entails in DoA and ToA detection. This leads to the realization of pseudo-random array patterns; namely, quasi-arbitrary geometries created from the superposition of multiple elliptical arrays. Some simulation and experimental tests (measurements in an anechoic chamber) are carried out for several frequency bands to check the correct performance of the method. The method is proven to give accurate estimations in all tested scenarios, and to be robust against noise, channel nonidealities, position uncertainty in sensor placement and interferences.
Beyond S-curves: Recurrent Neural Networks for Technology Forecasting
Nov 28, 2022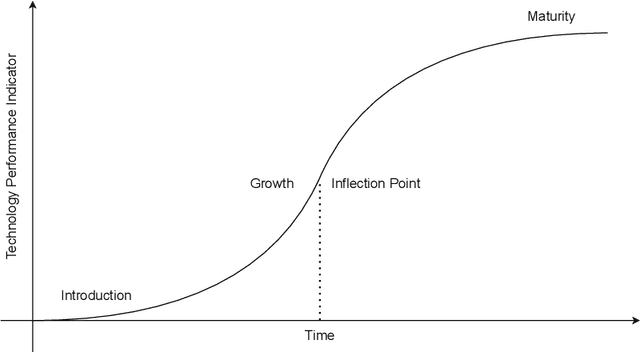
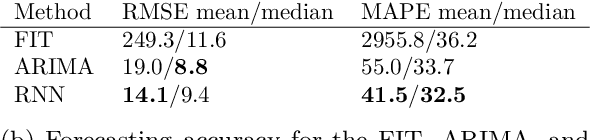
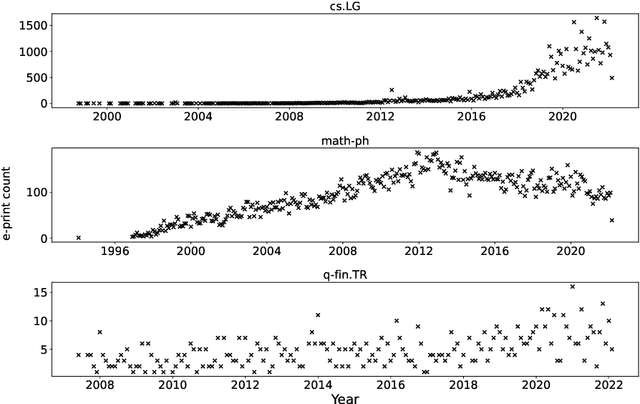

Because of the considerable heterogeneity and complexity of the technological landscape, building accurate models to forecast is a challenging endeavor. Due to their high prevalence in many complex systems, S-curves are a popular forecasting approach in previous work. However, their forecasting performance has not been directly compared to other technology forecasting approaches. Additionally, recent developments in time series forecasting that claim to improve forecasting accuracy are yet to be applied to technological development data. This work addresses both research gaps by comparing the forecasting performance of S-curves to a baseline and by developing an autencoder approach that employs recent advances in machine learning and time series forecasting. S-curves forecasts largely exhibit a mean average percentage error (MAPE) comparable to a simple ARIMA baseline. However, for a minority of emerging technologies, the MAPE increases by two magnitudes. Our autoencoder approach improves the MAPE by 13.5% on average over the second-best result. It forecasts established technologies with the same accuracy as the other approaches. However, it is especially strong at forecasting emerging technologies with a mean MAPE 18% lower than the next best result. Our results imply that a simple ARIMA model is preferable over the S-curve for technology forecasting. Practitioners looking for more accurate forecasts should opt for the presented autoencoder approach.
Higher-order Knowledge Transfer for Dynamic Community Detection with Great Changes
Nov 28, 2022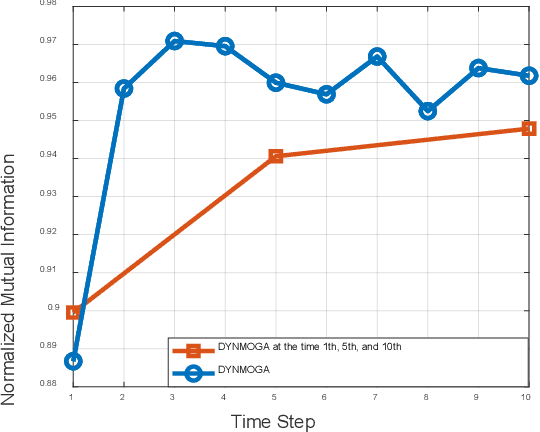
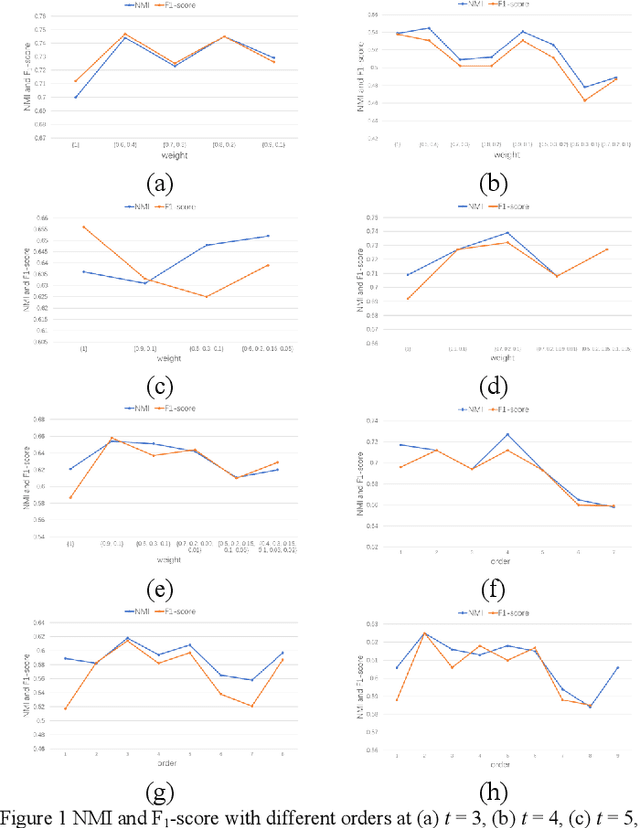
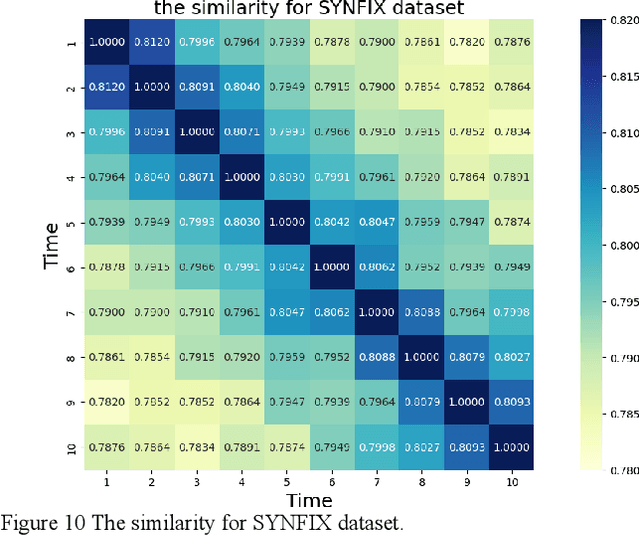
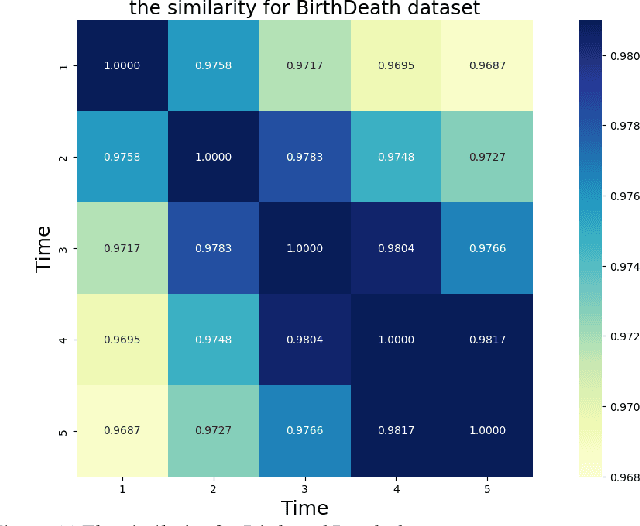
Network structure evolves with time in the real world, and the discovery of changing communities in dynamic networks is an important research topic that poses challenging tasks. Most existing methods assume that no significant change in the network occurs; namely, the difference between adjacent snapshots is slight. However, great change exists in the real world usually. The great change in the network will result in the community detection algorithms are difficulty obtaining valuable information from the previous snapshot, leading to negative transfer for the next time steps. This paper focuses on dynamic community detection with substantial changes by integrating higher-order knowledge from the previous snapshots to aid the subsequent snapshots. Moreover, to improve search efficiency, a higher-order knowledge transfer strategy is designed to determine first-order and higher-order knowledge by detecting the similarity of the adjacency matrix of snapshots. In this way, our proposal can better keep the advantages of previous community detection results and transfer them to the next task. We conduct the experiments on four real-world networks, including the networks with great or minor changes. Experimental results in the low-similarity datasets demonstrate that higher-order knowledge is more valuable than first-order knowledge when the network changes significantly and keeps the advantage even if handling the high-similarity datasets. Our proposal can also guide other dynamic optimization problems with great changes.
IDANI: Inference-time Domain Adaptation via Neuron-level Interventions
Jun 01, 2022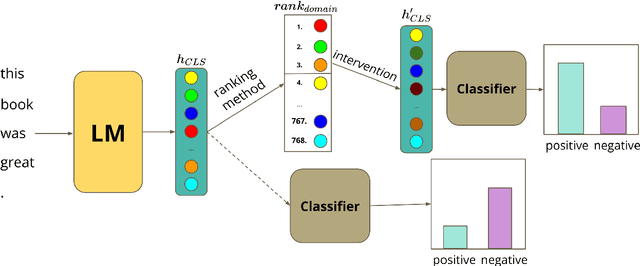
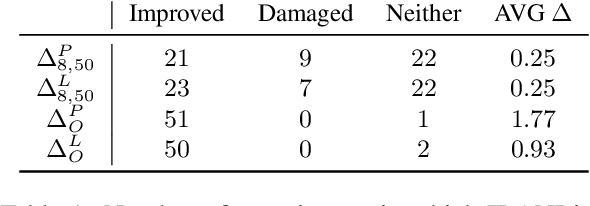
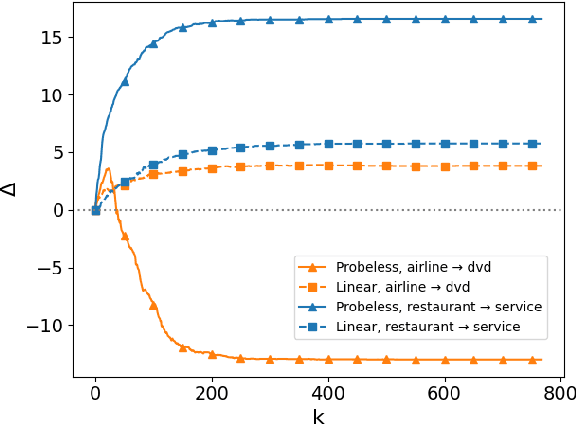

Large pre-trained models are usually fine-tuned on downstream task data, and tested on unseen data. When the train and test data come from different domains, the model is likely to struggle, as it is not adapted to the test domain. We propose a new approach for domain adaptation (DA), using neuron-level interventions: We modify the representation of each test example in specific neurons, resulting in a counterfactual example from the source domain, which the model is more familiar with. The modified example is then fed back into the model. While most other DA methods are applied during training time, ours is applied during inference only, making it more efficient and applicable. Our experiments show that our method improves performance on unseen domains.
Dynamics of Social Networks: Multi-agent Information Fusion, Anticipatory Decision Making and Polling
Dec 26, 2022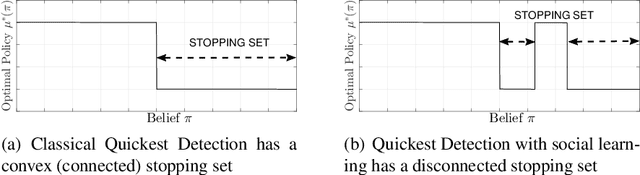
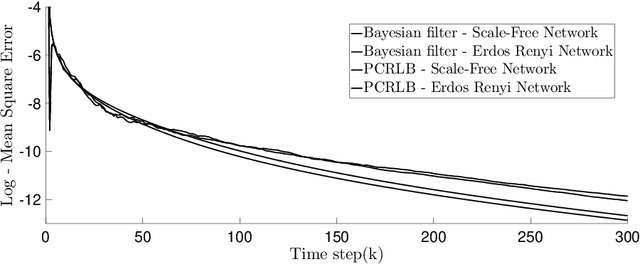
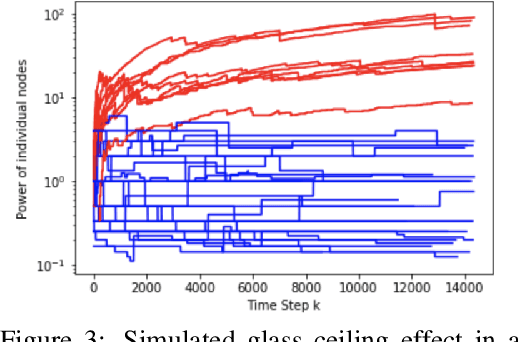
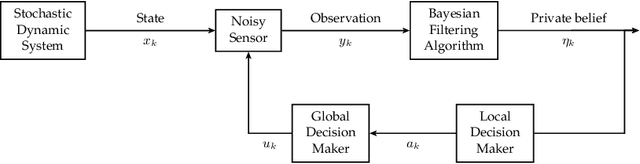
This paper surveys mathematical models, structural results and algorithms in controlled sensing with social learning in social networks. Part 1, namely Bayesian Social Learning with Controlled Sensing addresses the following questions: How does risk averse behavior in social learning affect quickest change detection? How can information fusion be priced? How is the convergence rate of state estimation affected by social learning? The aim is to develop and extend structural results in stochastic control and Bayesian estimation to answer these questions. Such structural results yield fundamental bounds on the optimal performance, give insight into what parameters affect the optimal policies, and yield computationally efficient algorithms. Part 2, namely, Multi-agent Information Fusion with Behavioral Economics Constraints generalizes Part 1. The agents exhibit sophisticated decision making in a behavioral economics sense; namely the agents make anticipatory decisions (thus the decision strategies are time inconsistent and interpreted as subgame Bayesian Nash equilibria). Part 3, namely {\em Interactive Sensing in Large Networks}, addresses the following questions: How to track the degree distribution of an infinite random graph with dynamics (via a stochastic approximation on a Hilbert space)? How can the infected degree distribution of a Markov modulated power law network and its mean field dynamics be tracked via Bayesian filtering given incomplete information obtained by sampling the network? We also briefly discuss how the glass ceiling effect emerges in social networks. Part 4, namely \emph{Efficient Network Polling} deals with polling in large scale social networks. In such networks, only a fraction of nodes can be polled to determine their decisions. Which nodes should be polled to achieve a statistically accurate estimates?
Multimodal Emotion Recognition among Couples from Lab Settings to Daily Life using Smartwatches
Dec 21, 2022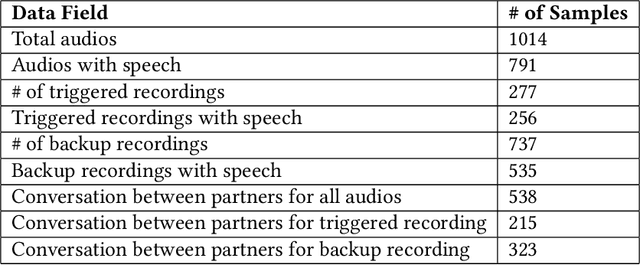
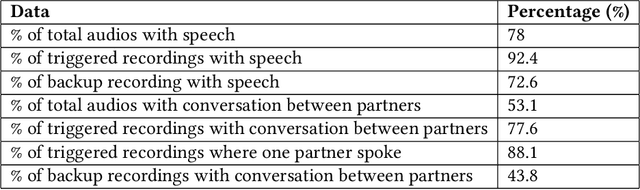
Couples generally manage chronic diseases together and the management takes an emotional toll on both patients and their romantic partners. Consequently, recognizing the emotions of each partner in daily life could provide an insight into their emotional well-being in chronic disease management. The emotions of partners are currently inferred in the lab and daily life using self-reports which are not practical for continuous emotion assessment or observer reports which are manual, time-intensive, and costly. Currently, there exists no comprehensive overview of works on emotion recognition among couples. Furthermore, approaches for emotion recognition among couples have (1) focused on English-speaking couples in the U.S., (2) used data collected from the lab, and (3) performed recognition using observer ratings rather than partner's self-reported / subjective emotions. In this body of work contained in this thesis (8 papers - 5 published and 3 currently under review in various journals), we fill the current literature gap on couples' emotion recognition, develop emotion recognition systems using 161 hours of data from a total of 1,051 individuals, and make contributions towards taking couples' emotion recognition from the lab which is the status quo, to daily life. This thesis contributes toward building automated emotion recognition systems that would eventually enable partners to monitor their emotions in daily life and enable the delivery of interventions to improve their emotional well-being.
Parallel Context Windows Improve In-Context Learning of Large Language Models
Dec 21, 2022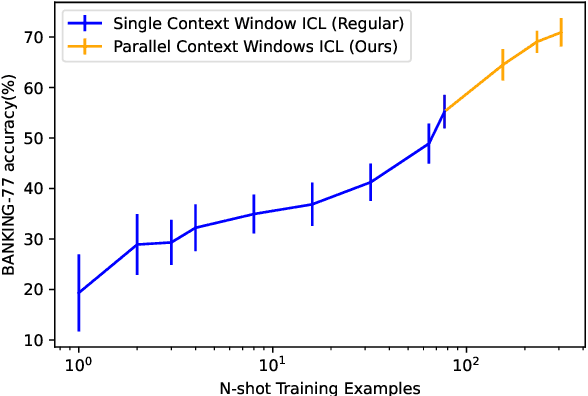
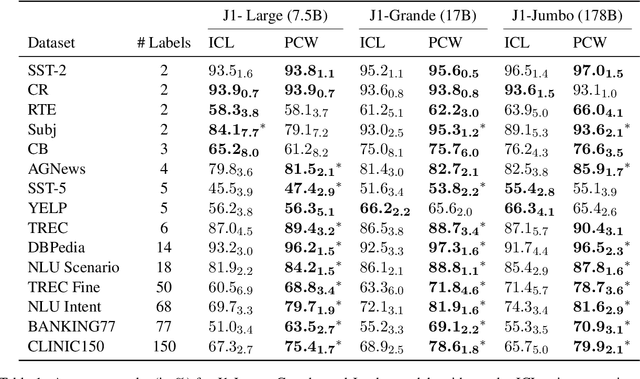
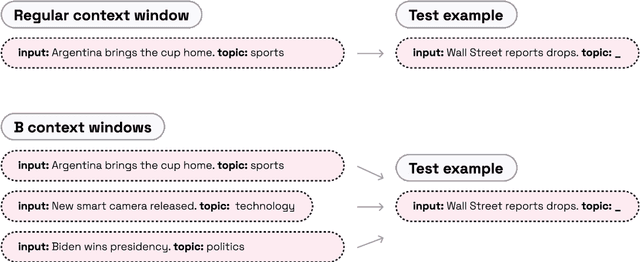
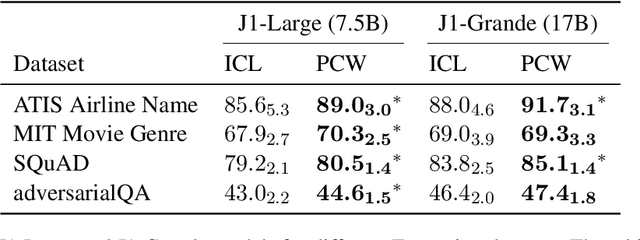
For applications that require processing large amounts of text at inference time, Large Language Models (LLMs) are handicapped by their limited context windows, which are typically 2048 tokens. In-context learning, an emergent phenomenon in LLMs in sizes above a certain parameter threshold, constitutes one significant example because it can only leverage training examples that fit into the context window. Existing efforts to address the context window limitation involve training specialized architectures, which tend to be smaller than the sizes in which in-context learning manifests due to the memory footprint of processing long texts. We present Parallel Context Windows (PCW), a method that alleviates the context window restriction for any off-the-shelf LLM without further training. The key to the approach is to carve a long context into chunks (``windows'') that fit within the architecture, restrict the attention mechanism to apply only within each window, and re-use the positional embeddings among the windows. We test the PCW approach on in-context learning with models that range in size between 750 million and 178 billion parameters, and show substantial improvements for tasks with diverse input and output spaces. Our results motivate further investigation of Parallel Context Windows as a method for applying off-the-shelf LLMs in other settings that require long text sequences.