 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Enhancing Weakly Supervised 3D Medical Image Segmentation through Probabilistic-aware Learning
Mar 05, 2024
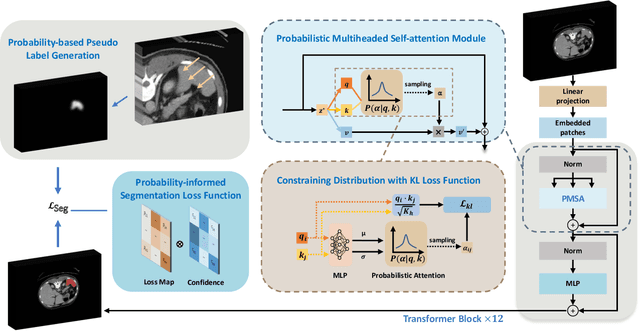
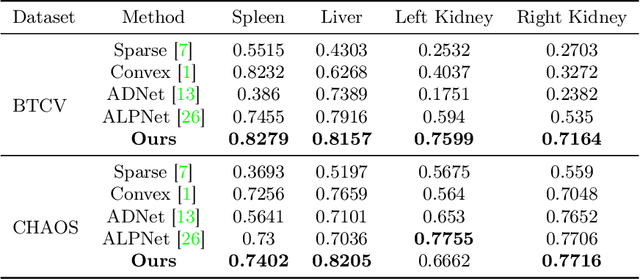
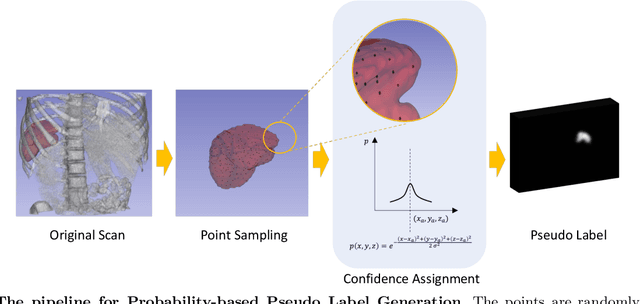
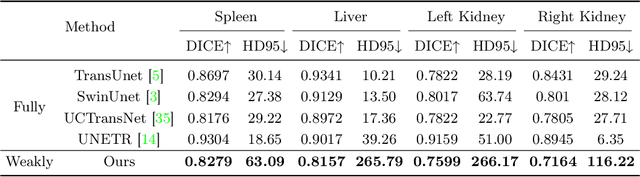
3D medical image segmentation is a challenging task with crucial implications for disease diagnosis and treatment planning. Recent advances in deep learning have significantly enhanced fully supervised medical image segmentation. However, this approach heavily relies on labor-intensive and time-consuming fully annotated ground-truth labels, particularly for 3D volumes. To overcome this limitation, we propose a novel probabilistic-aware weakly supervised learning pipeline, specifically designed for 3D medical imaging. Our pipeline integrates three innovative components: a probability-based pseudo-label generation technique for synthesizing dense segmentation masks from sparse annotations, a Probabilistic Multi-head Self-Attention network for robust feature extraction within our Probabilistic Transformer Network, and a Probability-informed Segmentation Loss Function to enhance training with annotation confidence. Demonstrating significant advances, our approach not only rivals the performance of fully supervised methods but also surpasses existing weakly supervised methods in CT and MRI datasets, achieving up to 18.1% improvement in Dice scores for certain organs. The code is available at https://github.com/runminjiang/PW4MedSeg.
Learning to Defer to a Population: A Meta-Learning Approach
Mar 05, 2024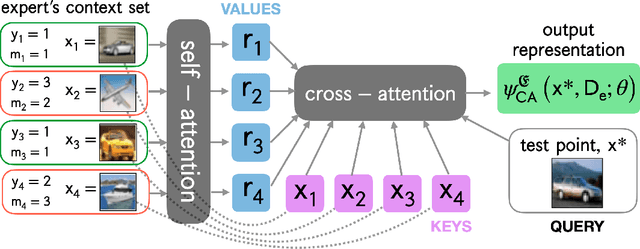



The learning to defer (L2D) framework allows autonomous systems to be safe and robust by allocating difficult decisions to a human expert. All existing work on L2D assumes that each expert is well-identified, and if any expert were to change, the system should be re-trained. In this work, we alleviate this constraint, formulating an L2D system that can cope with never-before-seen experts at test-time. We accomplish this by using meta-learning, considering both optimization- and model-based variants. Given a small context set to characterize the currently available expert, our framework can quickly adapt its deferral policy. For the model-based approach, we employ an attention mechanism that is able to look for points in the context set that are similar to a given test point, leading to an even more precise assessment of the expert's abilities. In the experiments, we validate our methods on image recognition, traffic sign detection, and skin lesion diagnosis benchmarks.
Shapley Values-Powered Framework for Fair Reward Split in Content Produced by GenAI
Mar 05, 2024



It is evident that, currently, generative models are surpassed in quality by human professionals. However, with the advancements in Artificial Intelligence, this gap will narrow, leading to scenarios where individuals who have dedicated years of their lives to mastering a skill become obsolete due to their high costs, which are inherently linked to the time they require to complete a task -- a task that AI could accomplish in minutes or seconds. To avoid future social upheavals, we must, even now, contemplate how to fairly assess the contributions of such individuals in training generative models and how to compensate them for the reduction or complete loss of their incomes. In this work, we propose a method to structure collaboration between model developers and data providers. To achieve this, we employ Shapley Values to quantify the contribution of artist(s) in an image generated by the Stable Diffusion-v1.5 model and to equitably allocate the reward among them.
TaylorShift: Shifting the Complexity of Self-Attention from Squared to Linear (and Back) using Taylor-Softmax
Mar 05, 2024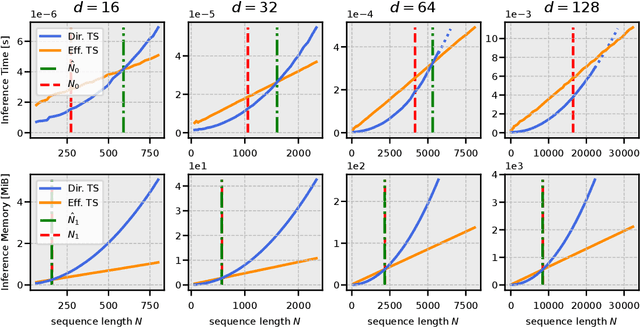
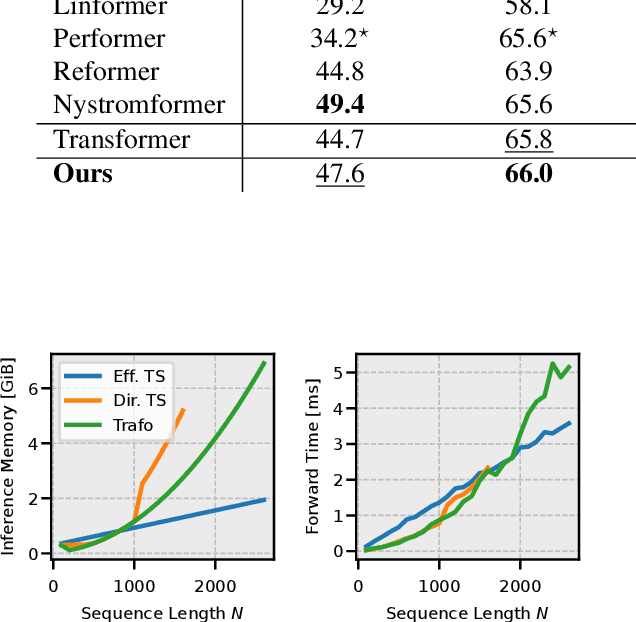
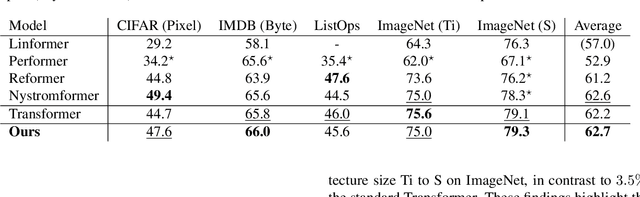
The quadratic complexity of the attention mechanism represents one of the biggest hurdles for processing long sequences using Transformers. Current methods, relying on sparse representations or stateful recurrence, sacrifice token-to-token interactions, which ultimately leads to compromises in performance. This paper introduces TaylorShift, a novel reformulation of the Taylor softmax that enables computing full token-to-token interactions in linear time and space. We analytically determine the crossover points where employing TaylorShift becomes more efficient than traditional attention, aligning closely with empirical measurements. Specifically, our findings demonstrate that TaylorShift enhances memory efficiency for sequences as short as 800 tokens and accelerates inference for inputs of approximately 1700 tokens and beyond. For shorter sequences, TaylorShift scales comparably with the vanilla attention. Furthermore, a classification benchmark across five tasks involving long sequences reveals no degradation in accuracy when employing Transformers equipped with TaylorShift. For reproducibility, we provide access to our code under https://github.com/tobna/TaylorShift.
HyperPredict: Estimating Hyperparameter Effects for Instance-Specific Regularization in Deformable Image Registration
Mar 04, 2024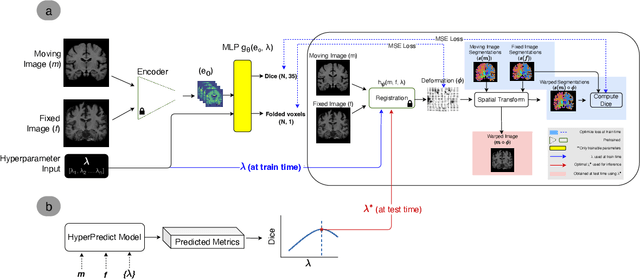

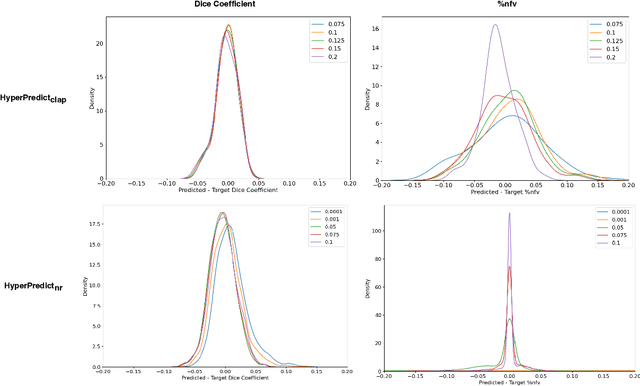
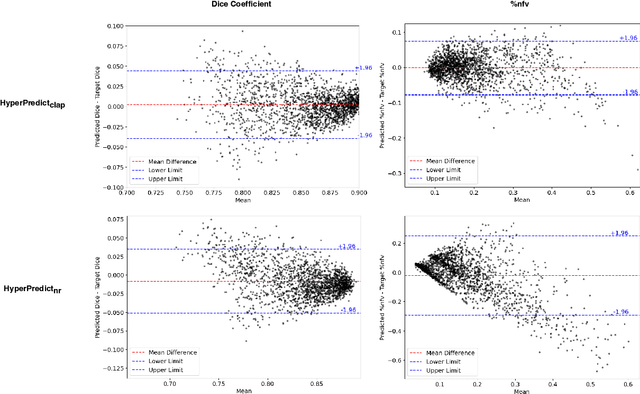
Methods for medical image registration infer geometric transformations that align pairs/groups of images by maximising an image similarity metric. This problem is ill-posed as several solutions may have equivalent likelihoods, also optimising purely for image similarity can yield implausible transformations. For these reasons regularization terms are essential to obtain meaningful registration results. However, this requires the introduction of at least one hyperparameter often termed {\lambda}, that serves as a tradeoff between loss terms. In some situations, the quality of the estimated transformation greatly depends on hyperparameter choice, and different choices may be required depending on the characteristics of the data. Analyzing the effect of these hyperparameters requires labelled data, which is not commonly available at test-time. In this paper, we propose a method for evaluating the influence of hyperparameters and subsequently selecting an optimal value for given image pairs. Our approach which we call HyperPredict, implements a Multi-Layer Perceptron that learns the effect of selecting particular hyperparameters for registering an image pair by predicting the resulting segmentation overlap and measure of deformation smoothness. This approach enables us to select optimal hyperparameters at test time without requiring labelled data, removing the need for a one-size-fits-all cross-validation approach. Furthermore, the criteria used to define optimal hyperparameter is flexible post-training, allowing us to efficiently choose specific properties. We evaluate our proposed method on the OASIS brain MR dataset using a recent deep learning approach(cLapIRN) and an algorithmic method(Niftyreg). Our results demonstrate good performance in predicting the effects of regularization hyperparameters and highlight the benefits of our image-pair specific approach to hyperparameter selection.
A Comparative Study of Rapidly-exploring Random Tree Algorithms Applied to Ship Trajectory Planning and Behavior Generation
Mar 02, 2024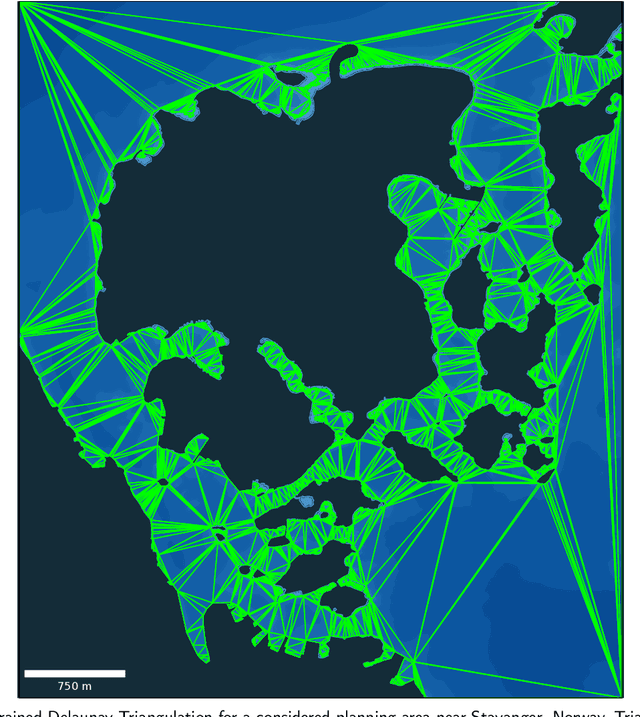
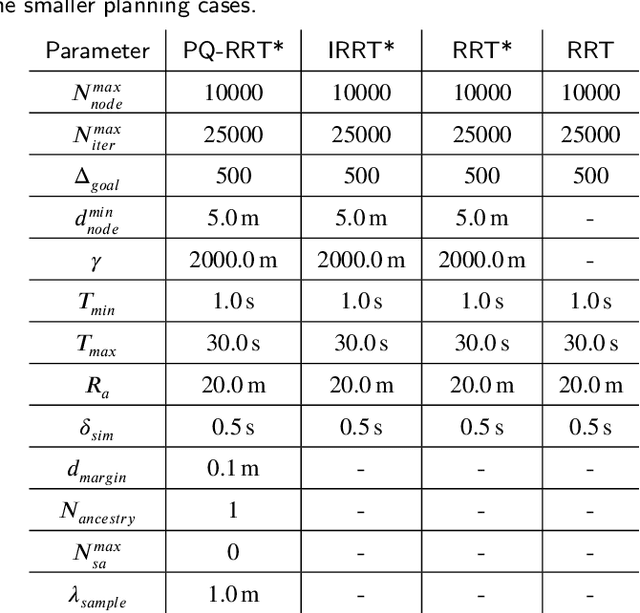
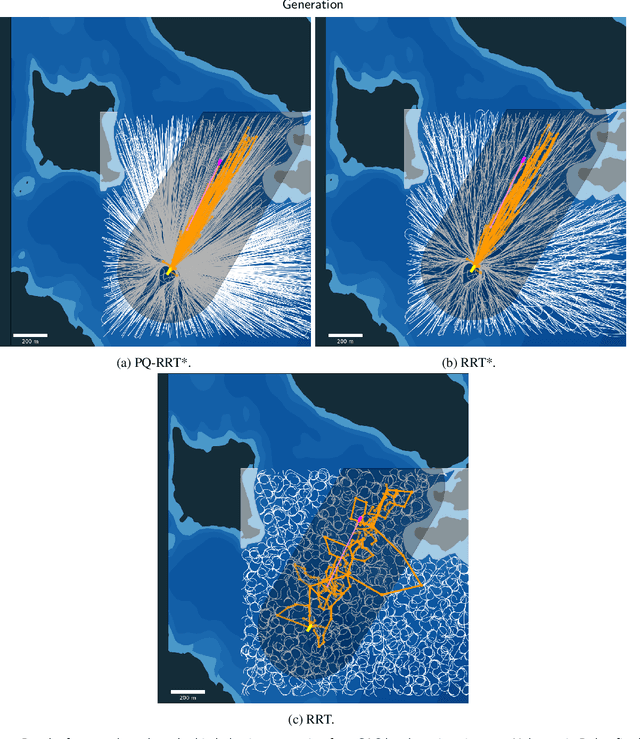
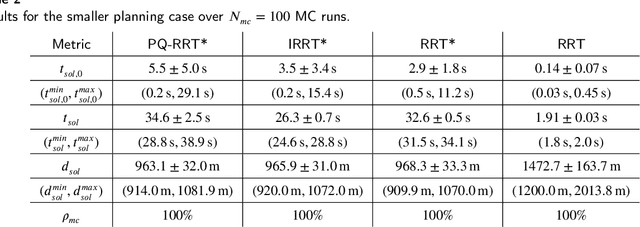
Rapidly Exploring Random Tree (RRT) algorithms are popular for sampling-based planning for nonholonomic vehicles in unstructured environments. However, we argue that previous work does not illuminate the challenges when employing such algorithms. Thus, in this article, we do a first comparison study of the performance of the following previously proposed RRT algorithm variants; Potential-Quick RRT* (PQ-RRT*), Informed RRT* (IRRT*), RRT* and RRT, for single-query nonholonomic motion planning over several cases in the unstructured maritime environment. The practicalities of employing such algorithms in the maritime domain are also discussed. On the side, we contend that these algorithms offer value not only for Collision Avoidance Systems (CAS) trajectory planning, but also for the verification of CAS through vessel behavior generation. Naturally, optimal RRT variants yield more distance-optimal paths at the cost of increased computational time due to the tree wiring process with nearest neighbor consideration. PQ-RRT* achieves marginally better results than IRRT* and RRT*, at the cost of higher tuning complexity and increased wiring time. Based on the results, we argue that for time-critical applications the considered RRT algorithms are, as stand-alone planners, more suitable for use in smaller problems or problems with low obstacle congestion ratio. This is attributed to the curse of dimensionality, and trade-off with available memory and computational resources.
Transformer for Times Series: an Application to the S&P500
Mar 04, 2024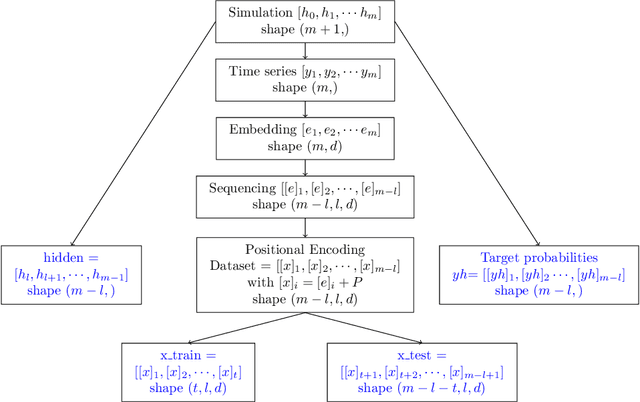

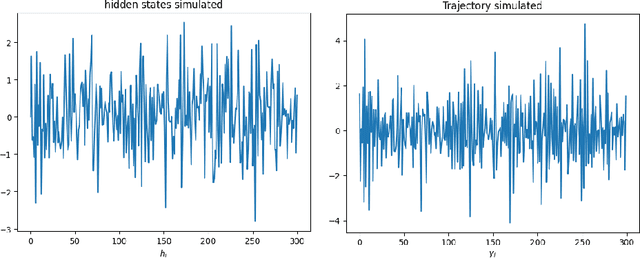
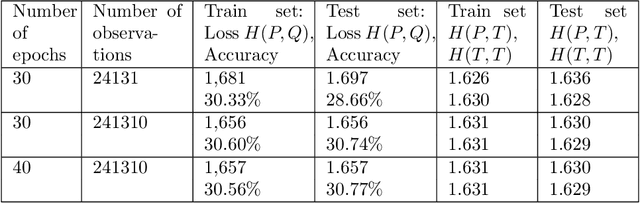
The transformer models have been extensively used with good results in a wide area of machine learning applications including Large Language Models and image generation. Here, we inquire on the applicability of this approach to financial time series. We first describe the dataset construction for two prototypical situations: a mean reverting synthetic Ornstein-Uhlenbeck process on one hand and real S&P500 data on the other hand. Then, we present in detail the proposed Transformer architecture and finally we discuss some encouraging results. For the synthetic data we predict rather accurately the next move, and for the S&P500 we get some interesting results related to quadratic variation and volatility prediction.
Lightweight Object Detection: A Study Based on YOLOv7 Integrated with ShuffleNetv2 and Vision Transformer
Mar 04, 2024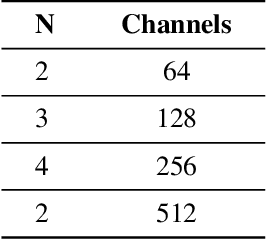
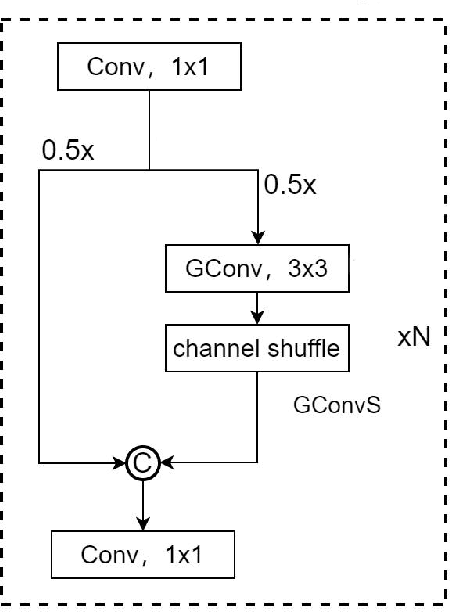
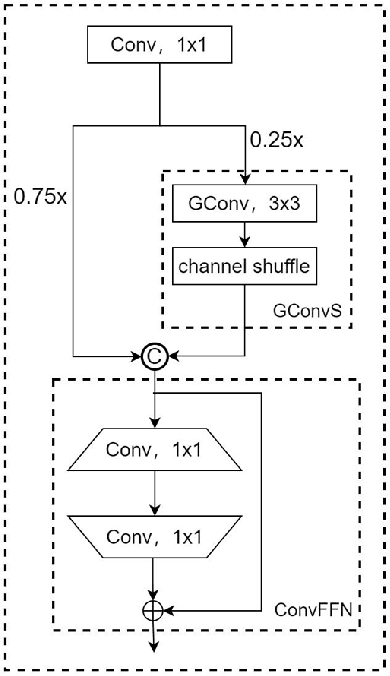

As mobile computing technology rapidly evolves, deploying efficient object detection algorithms on mobile devices emerges as a pivotal research area in computer vision. This study zeroes in on optimizing the YOLOv7 algorithm to boost its operational efficiency and speed on mobile platforms while ensuring high accuracy. Leveraging a synergy of advanced techniques such as Group Convolution, ShuffleNetV2, and Vision Transformer, this research has effectively minimized the model's parameter count and memory usage, streamlined the network architecture, and fortified the real-time object detection proficiency on resource-constrained devices. The experimental outcomes reveal that the refined YOLO model demonstrates exceptional performance, markedly enhancing processing velocity while sustaining superior detection accuracy.
IMBUE: Improving Interpersonal Effectiveness through Simulation and Just-in-time Feedback with Human-Language Model Interaction
Feb 19, 2024Navigating certain communication situations can be challenging due to individuals' lack of skills and the interference of strong emotions. However, effective learning opportunities are rarely accessible. In this work, we conduct a human-centered study that uses language models to simulate bespoke communication training and provide just-in-time feedback to support the practice and learning of interpersonal effectiveness skills. We apply the interpersonal effectiveness framework from Dialectical Behavioral Therapy (DBT), DEAR MAN, which focuses on both conversational and emotional skills. We present IMBUE, an interactive training system that provides feedback 25% more similar to experts' feedback, compared to that generated by GPT-4. IMBUE is the first to focus on communication skills and emotion management simultaneously, incorporate experts' domain knowledge in providing feedback, and be grounded in psychology theory. Through a randomized trial of 86 participants, we find that IMBUE's simulation-only variant significantly improves participants' self-efficacy (up to 17%) and reduces negative emotions (up to 25%). With IMBUE's additional just-in-time feedback, participants demonstrate 17% improvement in skill mastery, along with greater enhancements in self-efficacy (27% more) and reduction of negative emotions (16% more) compared to simulation-only. The improvement in skill mastery is the only measure that is transferred to new and more difficult situations; situation specific training is necessary for improving self-efficacy and emotion reduction.
Task Attribute Distance for Few-Shot Learning: Theoretical Analysis and Applications
Mar 06, 2024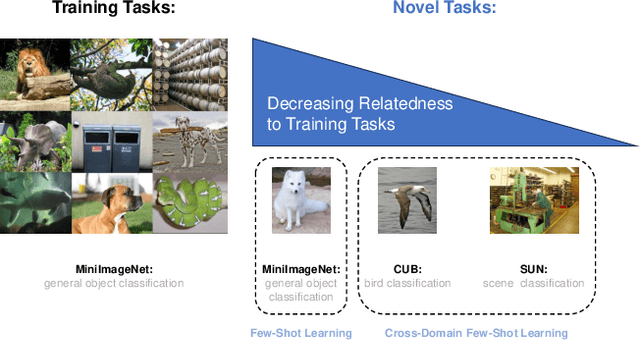
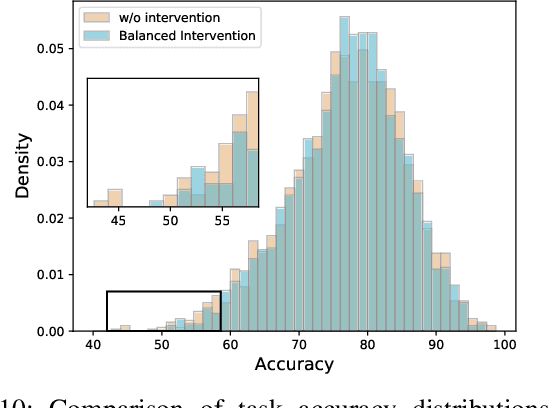
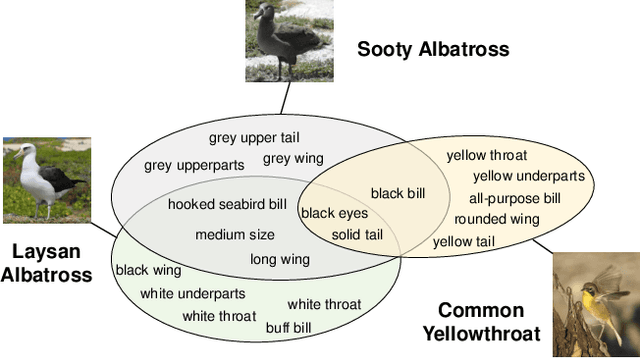
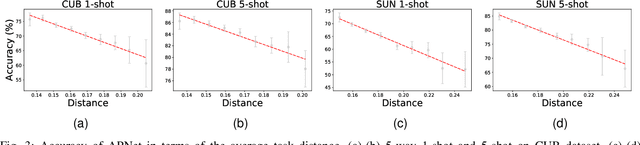
Few-shot learning (FSL) aims to learn novel tasks with very few labeled samples by leveraging experience from \emph{related} training tasks. In this paper, we try to understand FSL by delving into two key questions: (1) How to quantify the relationship between \emph{training} and \emph{novel} tasks? (2) How does the relationship affect the \emph{adaptation difficulty} on novel tasks for different models? To answer the two questions, we introduce Task Attribute Distance (TAD) built upon attributes as a metric to quantify the task relatedness. Unlike many existing metrics, TAD is model-agnostic, making it applicable to different FSL models. Then, we utilize TAD metric to establish a theoretical connection between task relatedness and task adaptation difficulty. By deriving the generalization error bound on a novel task, we discover how TAD measures the adaptation difficulty on novel tasks for FSL models. To validate our TAD metric and theoretical findings, we conduct experiments on three benchmarks. Our experimental results confirm that TAD metric effectively quantifies the task relatedness and reflects the adaptation difficulty on novel tasks for various FSL methods, even if some of them do not learn attributes explicitly or human-annotated attributes are not available. Finally, we present two applications of the proposed TAD metric: data augmentation and test-time intervention, which further verify its effectiveness and general applicability. The source code is available at https://github.com/hu-my/TaskAttributeDistance.