 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CountingMOT: Joint Counting, Detection and Re-Identification for Multiple Object Tracking
Dec 12, 2022
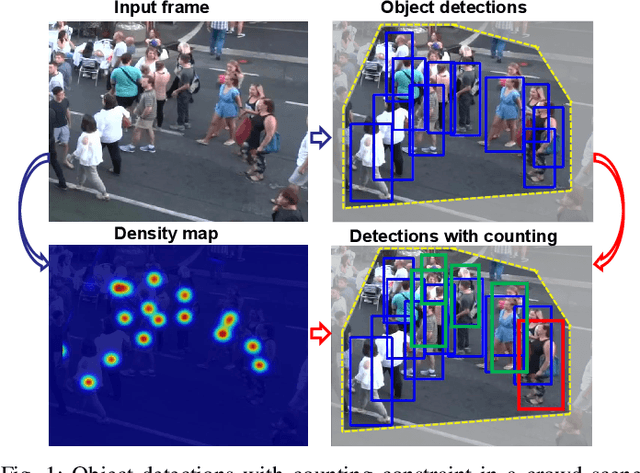
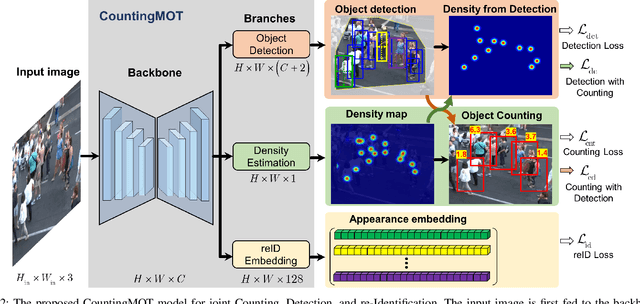


The recent trend in multiple object tracking (MOT) is jointly solving detection and tracking, where object detection and appearance feature (or motion) are learned simultaneously. Despite competitive performance, in crowded scenes, joint detection and tracking usually fail to find accurate object associations due to missed or false detections. In this paper, we jointly model counting, detection and re-identification in an end-to-end framework, named CountingMOT, tailored for crowded scenes. By imposing mutual object-count constraints between detection and counting, the CountingMOT tries to find a balance between object detection and crowd density map estimation, which can help it to recover missed detections or reject false detections. Our approach is an attempt to bridge the gap of object detection, counting, and re-Identification. This is in contrast to prior MOT methods that either ignore the crowd density and thus are prone to failure in crowded scenes, or depend on local correlations to build a graphical relationship for matching targets. The proposed MOT tracker can perform online and real-time tracking, and achieves the state-of-the-art results on public benchmarks MOT16 (MOTA of 77.6), MOT17 (MOTA of 78.0%) and MOT20 (MOTA of 70.2%).
Deep learning-based Subtyping of Atypical and Normal Mitoses using a Hierarchical Anchor-Free Object Detector
Dec 12, 2022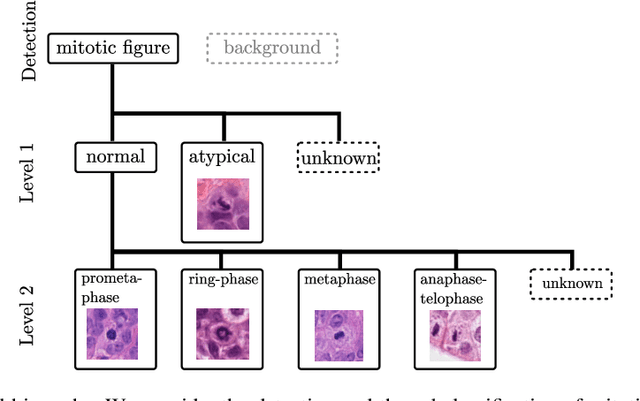
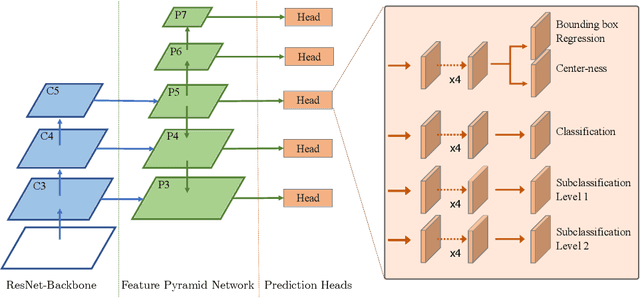
Mitotic activity is key for the assessment of malignancy in many tumors. Moreover, it has been demonstrated that the proportion of abnormal mitosis to normal mitosis is of prognostic significance. Atypical mitotic figures (MF) can be identified morphologically as having segregation abnormalities of the chromatids. In this work, we perform, for the first time, automatic subtyping of mitotic figures into normal and atypical categories according to characteristic morphological appearances of the different phases of mitosis. Using the publicly available MIDOG21 and TUPAC16 breast cancer mitosis datasets, two experts blindly subtyped mitotic figures into five morphological categories. Further, we set up a state-of-the-art object detection pipeline extending the anchor-free FCOS approach with a gated hierarchical subclassification branch. Our labeling experiment indicated that subtyping of mitotic figures is a challenging task and prone to inter-rater disagreement, which we found in 24.89% of MF. Using the more diverse MIDOG21 dataset for training and TUPAC16 for testing, we reached a mean overall average precision score of 0.552, a ROC AUC score of 0.833 for atypical/normal MF and a mean class-averaged ROC-AUC score of 0.977 for discriminating the different phases of cells undergoing mitosis.
Optimal Planning of Hybrid Energy Storage Systems using Curtailed Renewable Energy through Deep Reinforcement Learning
Dec 12, 2022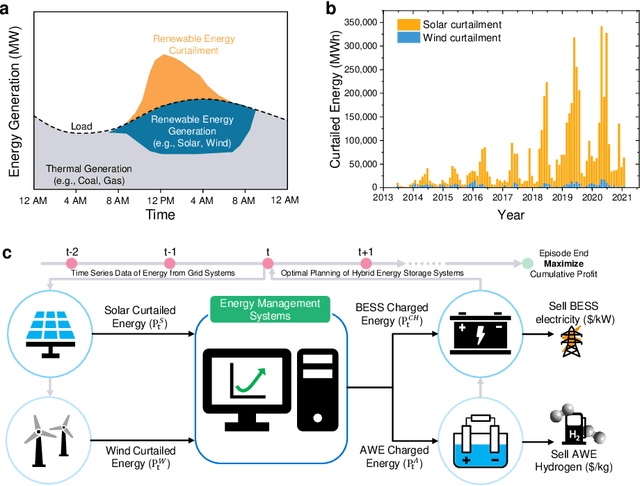

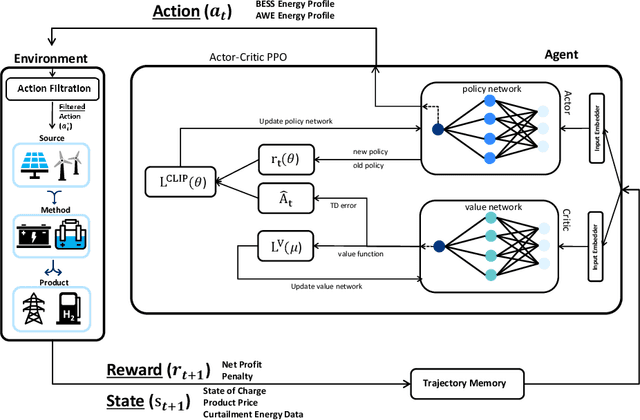
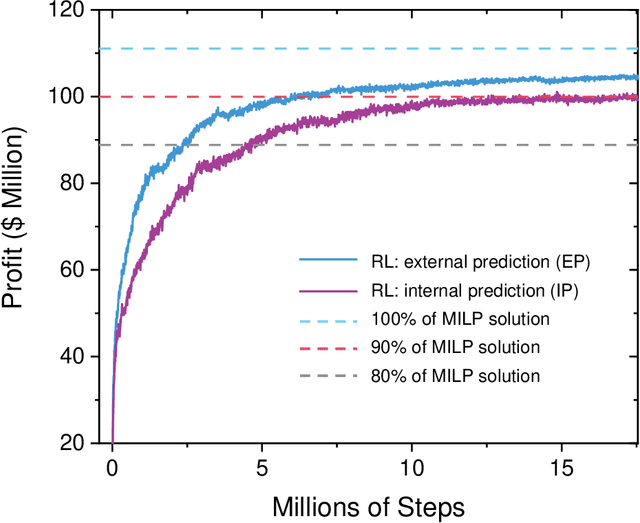
Energy management systems (EMS) are becoming increasingly important in order to utilize the continuously growing curtailed renewable energy. Promising energy storage systems (ESS), such as batteries and green hydrogen should be employed to maximize the efficiency of energy stakeholders. However, optimal decision-making, i.e., planning the leveraging between different strategies, is confronted with the complexity and uncertainties of large-scale problems. Here, we propose a sophisticated deep reinforcement learning (DRL) methodology with a policy-based algorithm to realize the real-time optimal ESS planning under the curtailed renewable energy uncertainty. A quantitative performance comparison proved that the DRL agent outperforms the scenario-based stochastic optimization (SO) algorithm, even with a wide action and observation space. Owing to the uncertainty rejection capability of the DRL, we could confirm a robust performance, under a large uncertainty of the curtailed renewable energy, with a maximizing net profit and stable system. Action-mapping was performed for visually assessing the action taken by the DRL agent according to the state. The corresponding results confirmed that the DRL agent learns the way like what a human expert would do, suggesting reliable application of the proposed methodology.
Evaluating Digital Agriculture Recommendations with Causal Inference
Nov 30, 2022

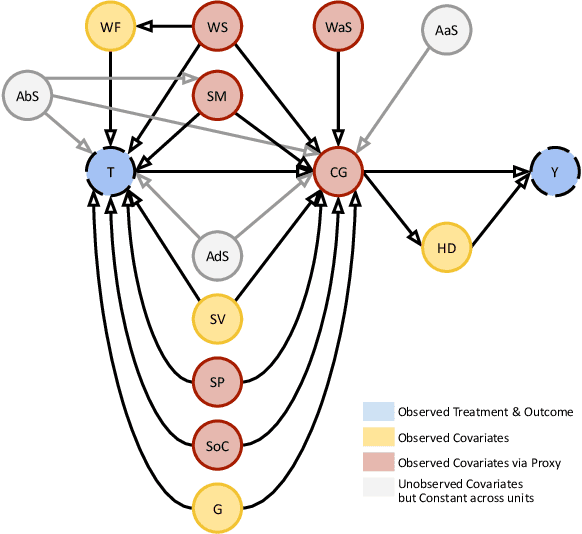
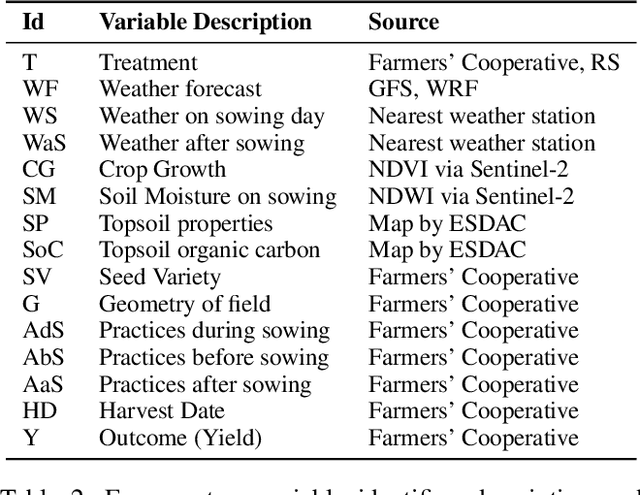
In contrast to the rapid digitalization of several industries, agriculture suffers from low adoption of smart farming tools. While AI-driven digital agriculture tools can offer high-performing predictive functionalities, they lack tangible quantitative evidence on their benefits to the farmers. Field experiments can derive such evidence, but are often costly, time consuming and hence limited in scope and scale of application. To this end, we propose an observational causal inference framework for the empirical evaluation of the impact of digital tools on target farm performance indicators (e.g., yield in this case). This way, we can increase farmers' trust via enhancing the transparency of the digital agriculture market and accelerate the adoption of technologies that aim to secure farmer income resilience and global agricultural sustainability. As a case study, we designed and implemented a recommendation system for the optimal sowing time of cotton based on numerical weather predictions, which was used by a farmers' cooperative during the growing season of 2021. We then leverage agricultural knowledge, collected yield data, and environmental information to develop a causal graph of the farm system. Using the back-door criterion, we identify the impact of sowing recommendations on the yield and subsequently estimate it using linear regression, matching, inverse propensity score weighting and meta-learners. The results reveal that a field sown according to our recommendations exhibited a statistically significant yield increase that ranged from 12% to 17%, depending on the method. The effect estimates were robust, as indicated by the agreement among the estimation methods and four successful refutation tests. We argue that this approach can be implemented for decision support systems of other fields, extending their evaluation beyond a performance assessment of internal functionalities.
Self-Supervised Audio-Visual Speech Representations Learning By Multimodal Self-Distillation
Dec 06, 2022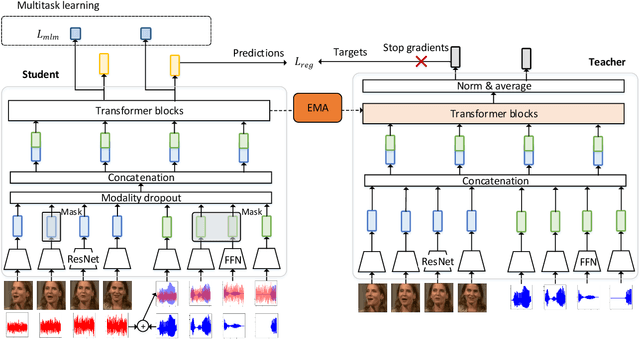
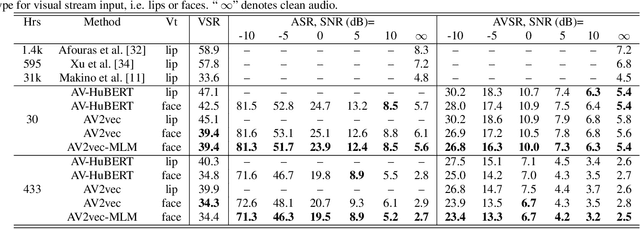
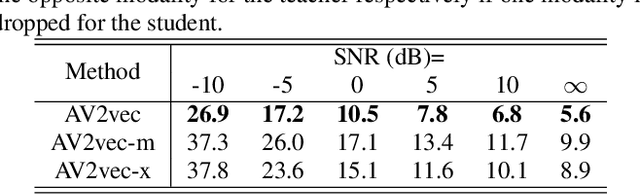
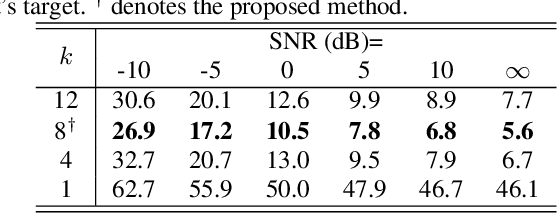
In this work, we present a novel method, named AV2vec, for learning audio-visual speech representations by multimodal self-distillation. AV2vec has a student and a teacher module, in which the student performs a masked latent feature regression task using the multimodal target features generated online by the teacher. The parameters of the teacher model are a momentum update of the student. Since our target features are generated online, AV2vec needs no iteration step like AV-HuBERT and the total training time cost is reduced to less than one-fifth. We further propose AV2vec-MLM in this study, which augments AV2vec with a masked language model (MLM)-style loss using multitask learning. Our experimental results show that AV2vec achieved comparable performance to the AV-HuBERT baseline. When combined with an MLM-style loss, AV2vec-MLM outperformed baselines and achieved the best performance on the downstream tasks.
Explainability as statistical inference
Dec 06, 2022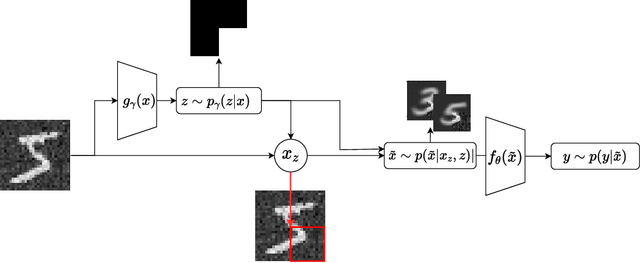

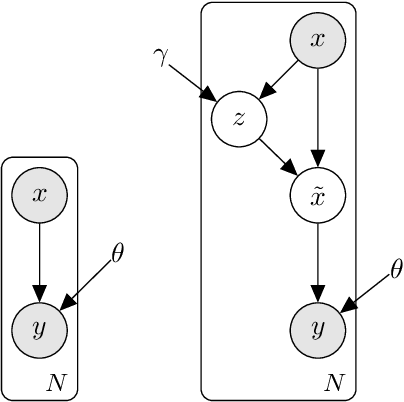
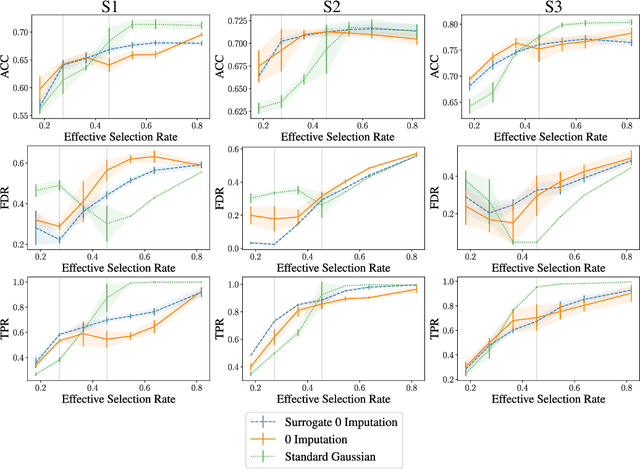
A wide variety of model explanation approaches have been proposed in recent years, all guided by very different rationales and heuristics. In this paper, we take a new route and cast interpretability as a statistical inference problem. We propose a general deep probabilistic model designed to produce interpretable predictions. The model parameters can be learned via maximum likelihood, and the method can be adapted to any predictor network architecture and any type of prediction problem. Our method is a case of amortized interpretability models, where a neural network is used as a selector to allow for fast interpretation at inference time. Several popular interpretability methods are shown to be particular cases of regularised maximum likelihood for our general model. We propose new datasets with ground truth selection which allow for the evaluation of the features importance map. Using these datasets, we show experimentally that using multiple imputation provides more reasonable interpretations.
Sequential Kernelized Independence Testing
Dec 14, 2022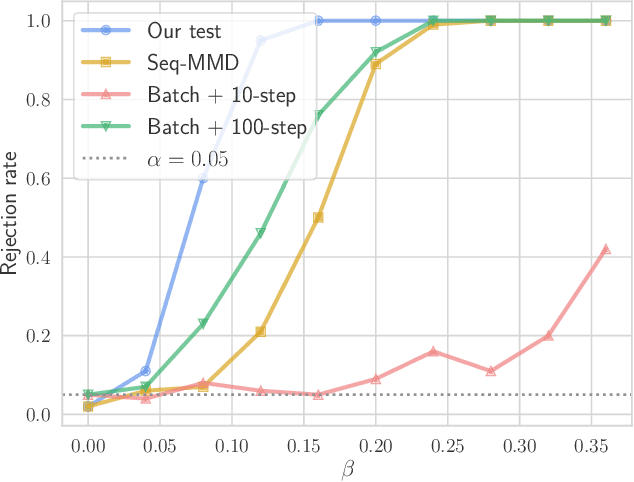
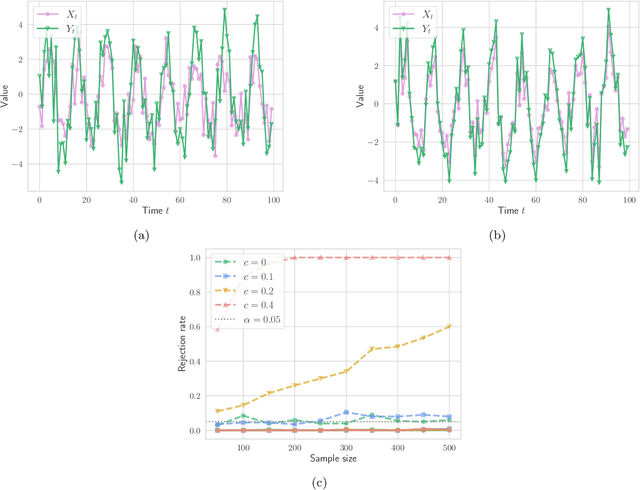
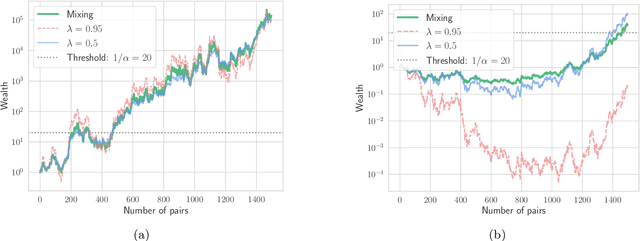
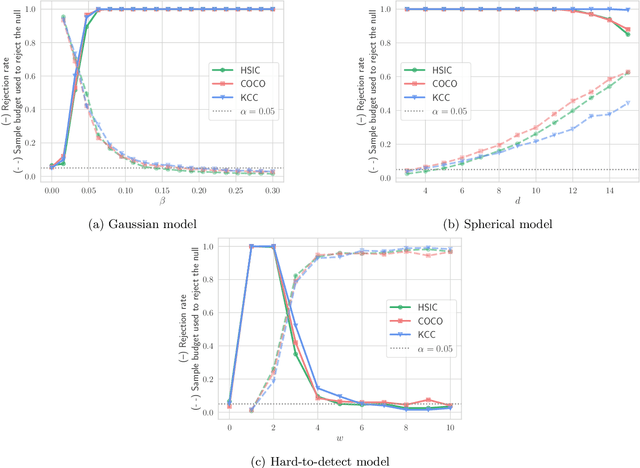
Independence testing is a fundamental and classical statistical problem that has been extensively studied in the batch setting when one fixes the sample size before collecting data. However, practitioners often prefer procedures that adapt to the complexity of a problem at hand instead of setting sample size in advance. Ideally, such procedures should (a) allow stopping earlier on easy tasks (and later on harder tasks), hence making better use of available resources, and (b) continuously monitor the data and efficiently incorporate statistical evidence after collecting new data, while controlling the false alarm rate. It is well known that classical batch tests are not tailored for streaming data settings, since valid inference after data peeking requires correcting for multiple testing, but such corrections generally result in low power. In this paper, we design sequential kernelized independence tests (SKITs) that overcome such shortcomings based on the principle of testing by betting. We exemplify our broad framework using bets inspired by kernelized dependence measures such as the Hilbert-Schmidt independence criterion (HSIC) and the constrained-covariance criterion (COCO). Importantly, we also generalize the framework to non-i.i.d. time-varying settings, for which there exist no batch tests. We demonstrate the power of our approaches on both simulated and real data.
Establishing a stronger baseline for lightweight contrastive models
Dec 14, 2022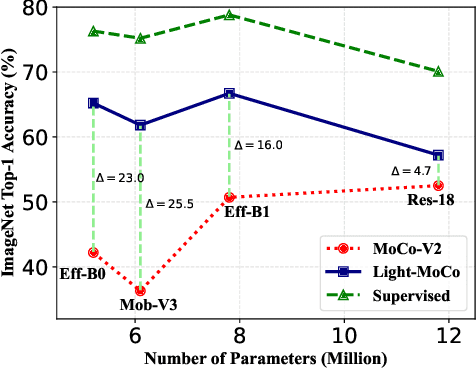
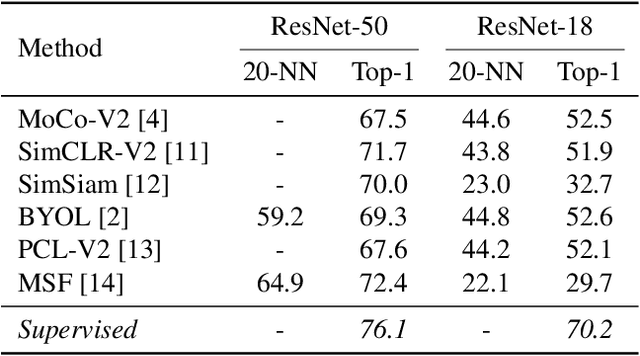
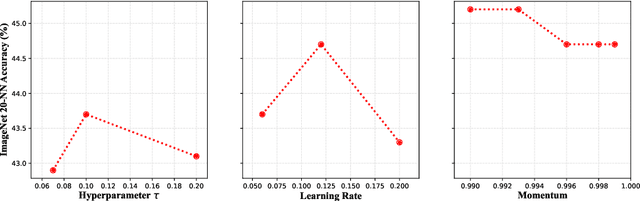
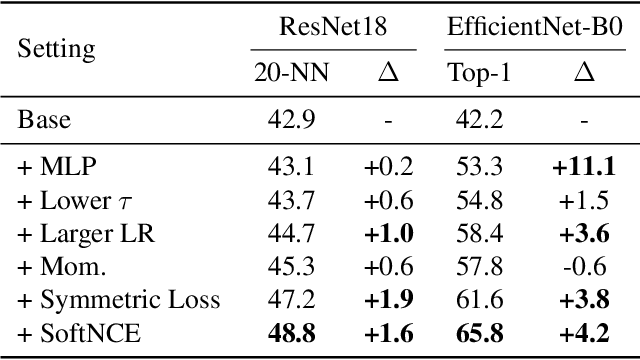
Recent research has reported a performance degradation in self-supervised contrastive learning for specially designed efficient networks, such as MobileNet and EfficientNet. A common practice to address this problem is to introduce a pretrained contrastive teacher model and train the lightweight networks with distillation signals generated by the teacher. However, it is time and resource consuming to pretrain a teacher model when it is not available. In this work, we aim to establish a stronger baseline for lightweight contrastive models without using a pretrained teacher model. Specifically, we show that the optimal recipe for efficient models is different from that of larger models, and using the same training settings as ResNet50, as previous research does, is inappropriate. Additionally, we observe a common issu e in contrastive learning where either the positive or negative views can be noisy, and propose a smoothed version of InfoNCE loss to alleviate this problem. As a result, we successfully improve the linear evaluation results from 36.3\% to 62.3\% for MobileNet-V3-Large and from 42.2\% to 65.8\% for EfficientNet-B0 on ImageNet, closing the accuracy gap to ResNet50 with $5\times$ fewer parameters. We hope our research will facilitate the usage of lightweight contrastive models.
MABSplit: Faster Forest Training Using Multi-Armed Bandits
Dec 14, 2022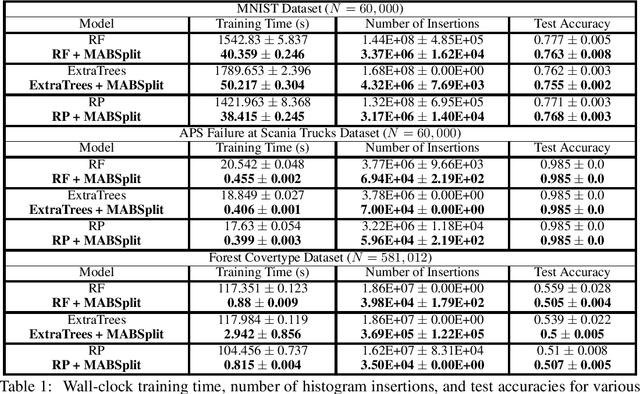
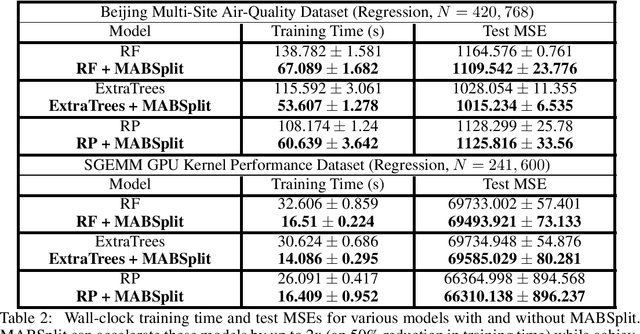
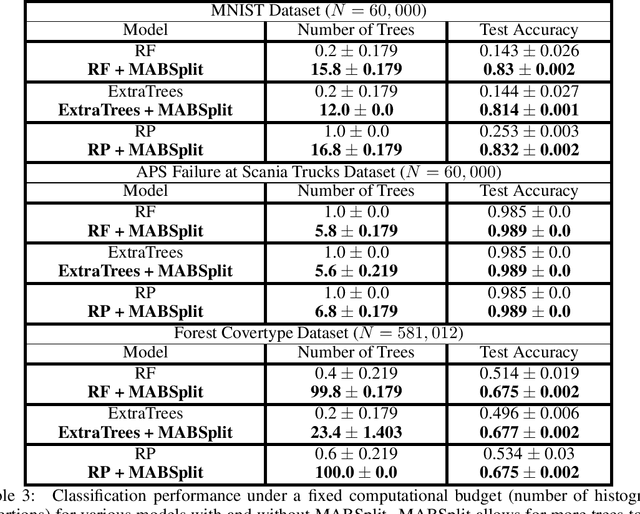
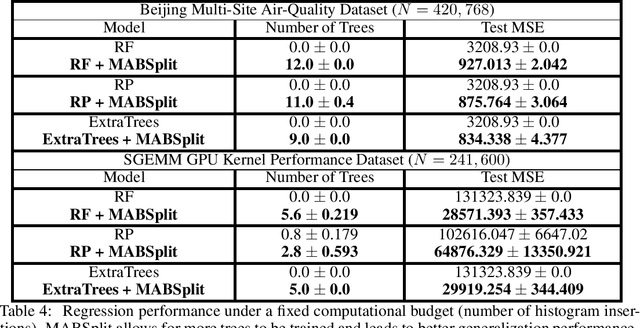
Random forests are some of the most widely used machine learning models today, especially in domains that necessitate interpretability. We present an algorithm that accelerates the training of random forests and other popular tree-based learning methods. At the core of our algorithm is a novel node-splitting subroutine, dubbed MABSplit, used to efficiently find split points when constructing decision trees. Our algorithm borrows techniques from the multi-armed bandit literature to judiciously determine how to allocate samples and computational power across candidate split points. We provide theoretical guarantees that MABSplit improves the sample complexity of each node split from linear to logarithmic in the number of data points. In some settings, MABSplit leads to 100x faster training (an 99% reduction in training time) without any decrease in generalization performance. We demonstrate similar speedups when MABSplit is used across a variety of forest-based variants, such as Extremely Random Forests and Random Patches. We also show our algorithm can be used in both classification and regression tasks. Finally, we show that MABSplit outperforms existing methods in generalization performance and feature importance calculations under a fixed computational budget. All of our experimental results are reproducible via a one-line script at https://github.com/ThrunGroup/FastForest.
RIS-Enabled and Access-Point-Free Simultaneous Radio Localization and Mapping
Dec 14, 2022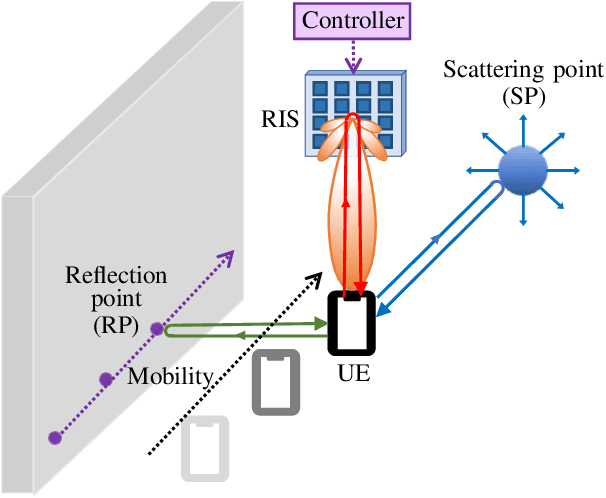
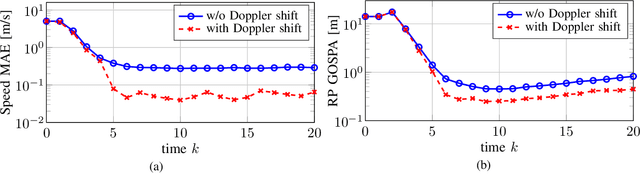
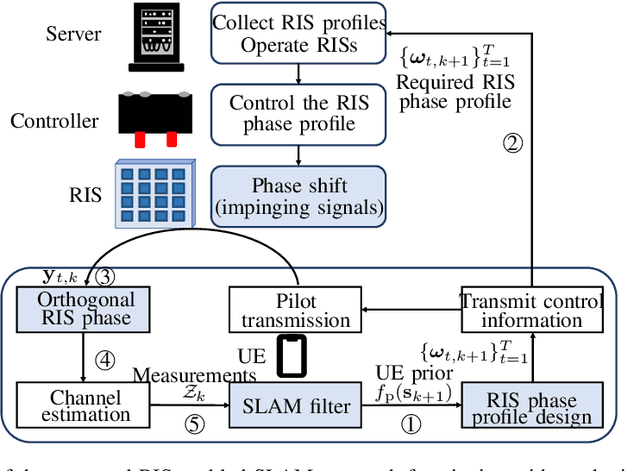
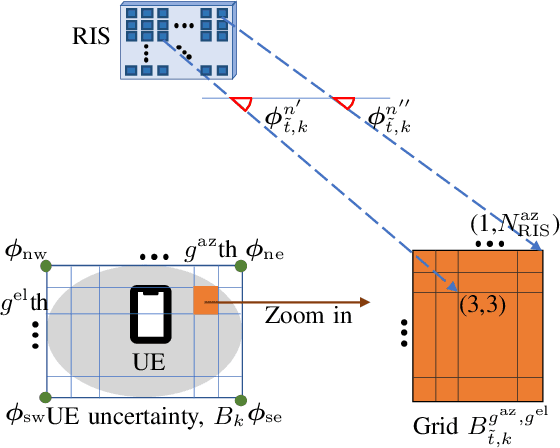
In the upcoming sixth generation (6G) of wireless communication systems, reconfigurable intelligent surfaces~(RISs) are regarded as one of the promising technological enablers, which can provide programmable signal propagation. Therefore, simultaneous radio localization and mapping(SLAM) with RISs appears as an emerging research direction within the 6G ecosystem. In this paper, we propose a novel framework of RIS-enabled radio SLAM for wireless operation without the intervention of access points (APs). We first design the RIS phase profiles leveraging prior information for the user equipment~(UE), such that they uniformly illuminate the angular sector where the UE is probabilistically located. Second, we modify the marginal Poisson multi-Bernoulli SLAM filter and estimate the UE state and landmarks, which enables efficient mapping of the radio propagation environment. Third, we derive the theoretical Cram\'er-Rao lower bounds on the estimators for the channel parameters and the UE state. We finally evaluate the performance of the proposed method under scenarios with a limited number of transmissions, taking into account the channel coherence time. Our results demonstrate that the RIS enables solving the radio SLAM problem with zero APs, and that the consideration of the Doppler shift contributes to improving the UE speed estimates.