 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
NRTR: Neuron Reconstruction with Transformer from 3D Optical Microscopy Images
Dec 08, 2022
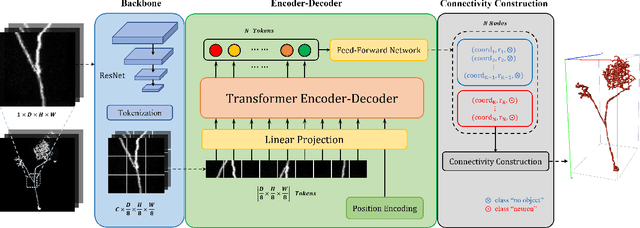
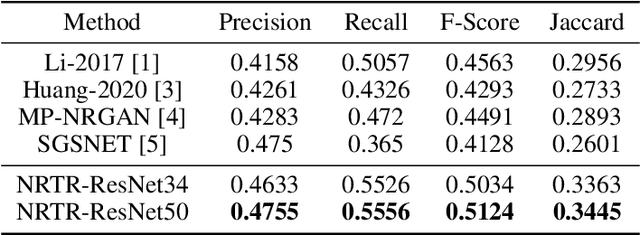
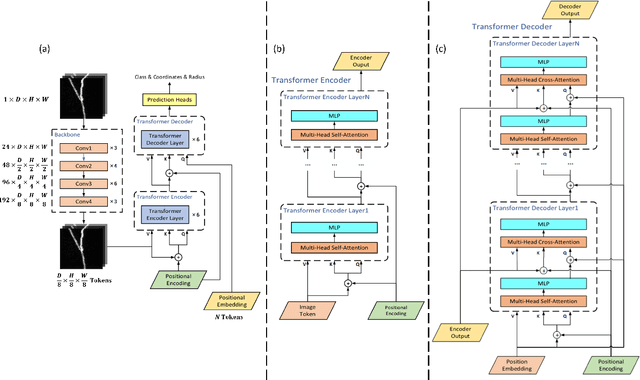
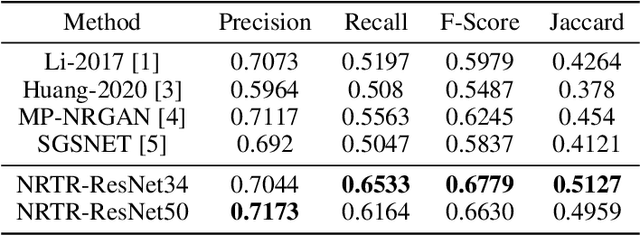
The neuron reconstruction from raw Optical Microscopy (OM) image stacks is the basis of neuroscience. Manual annotation and semi-automatic neuron tracing algorithms are time-consuming and inefficient. Existing deep learning neuron reconstruction methods, although demonstrating exemplary performance, greatly demand complex rule-based components. Therefore, a crucial challenge is designing an end-to-end neuron reconstruction method that makes the overall framework simpler and model training easier. We propose a Neuron Reconstruction Transformer (NRTR) that, discarding the complex rule-based components, views neuron reconstruction as a direct set-prediction problem. To the best of our knowledge, NRTR is the first image-to-set deep learning model for end-to-end neuron reconstruction. In experiments using the BigNeuron and VISoR-40 datasets, NRTR achieves excellent neuron reconstruction results for comprehensive benchmarks and outperforms competitive baselines. Results of extensive experiments indicate that NRTR is effective at showing that neuron reconstruction is viewed as a set-prediction problem, which makes end-to-end model training available.
MDL-based Compressing Sequential Rules
Dec 20, 2022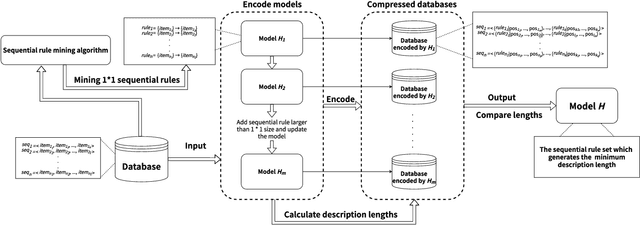
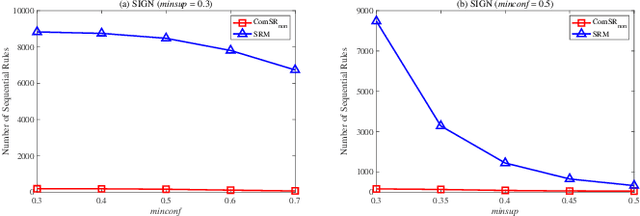
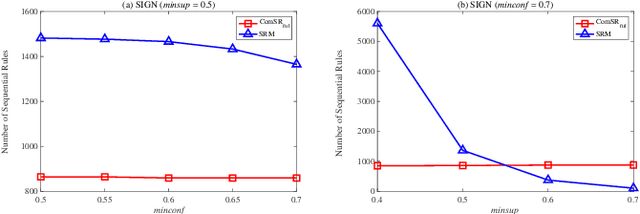
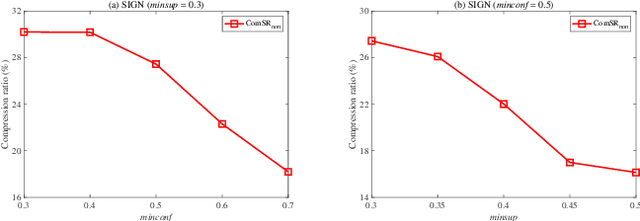
Nowadays, with the rapid development of the Internet, the era of big data has come. The Internet generates huge amounts of data every day. However, extracting meaningful information from massive data is like looking for a needle in a haystack. Data mining techniques can provide various feasible methods to solve this problem. At present, many sequential rule mining (SRM) algorithms are presented to find sequential rules in databases with sequential characteristics. These rules help people extract a lot of meaningful information from massive amounts of data. How can we achieve compression of mined results and reduce data size to save storage space and transmission time? Until now, there has been little research on the compression of SRM. In this paper, combined with the Minimum Description Length (MDL) principle and under the two metrics (support and confidence), we introduce the problem of compression of SRM and also propose a solution named ComSR for MDL-based compressing of sequential rules based on the designed sequential rule coding scheme. To our knowledge, we are the first to use sequential rules to encode an entire database. A heuristic method is proposed to find a set of compact and meaningful sequential rules as much as possible. ComSR has two trade-off algorithms, ComSR_non and ComSR_ful, based on whether the database can be completely compressed. Experiments done on a real dataset with different thresholds show that a set of compact and meaningful sequential rules can be found. This shows that the proposed method works.
An ensemble neural network approach to forecast Dengue outbreak based on climatic condition
Dec 20, 2022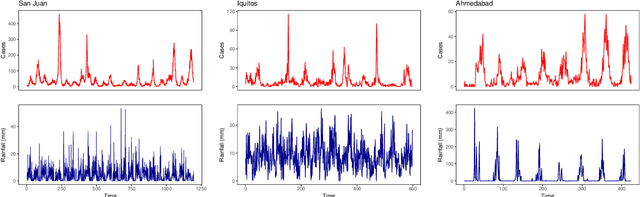
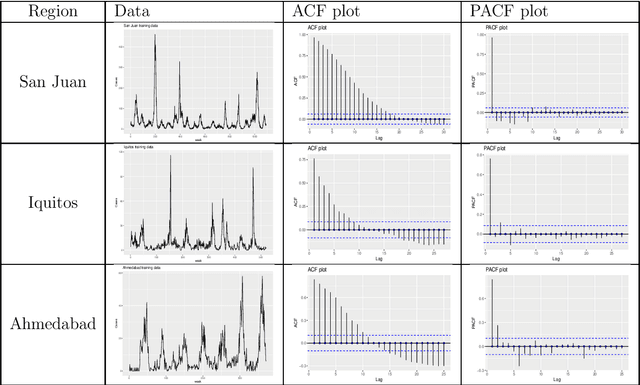
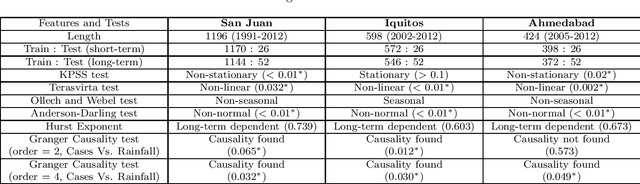

Dengue fever is a virulent disease spreading over 100 tropical and subtropical countries in Africa, the Americas, and Asia. This arboviral disease affects around 400 million people globally, severely distressing the healthcare systems. The unavailability of a specific drug and ready-to-use vaccine makes the situation worse. Hence, policymakers must rely on early warning systems to control intervention-related decisions. Forecasts routinely provide critical information for dangerous epidemic events. However, the available forecasting models (e.g., weather-driven mechanistic, statistical time series, and machine learning models) lack a clear understanding of different components to improve prediction accuracy and often provide unstable and unreliable forecasts. This study proposes an ensemble wavelet neural network with exogenous factor(s) (XEWNet) model that can produce reliable estimates for dengue outbreak prediction for three geographical regions, namely San Juan, Iquitos, and Ahmedabad. The proposed XEWNet model is flexible and can easily incorporate exogenous climate variable(s) confirmed by statistical causality tests in its scalable framework. The proposed model is an integrated approach that uses wavelet transformation into an ensemble neural network framework that helps in generating more reliable long-term forecasts. The proposed XEWNet allows complex non-linear relationships between the dengue incidence cases and rainfall; however, mathematically interpretable, fast in execution, and easily comprehensible. The proposal's competitiveness is measured using computational experiments based on various statistical metrics and several statistical comparison tests. In comparison with statistical, machine learning, and deep learning methods, our proposed XEWNet performs better in 75% of the cases for short-term and long-term forecasting of dengue incidence.
Walking Noise: Understanding Implications of Noisy Computations on Classification Tasks
Dec 20, 2022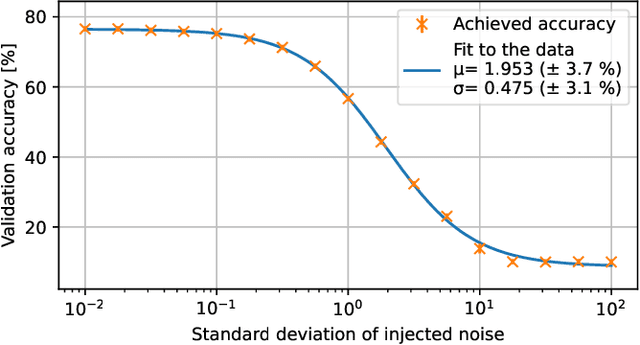
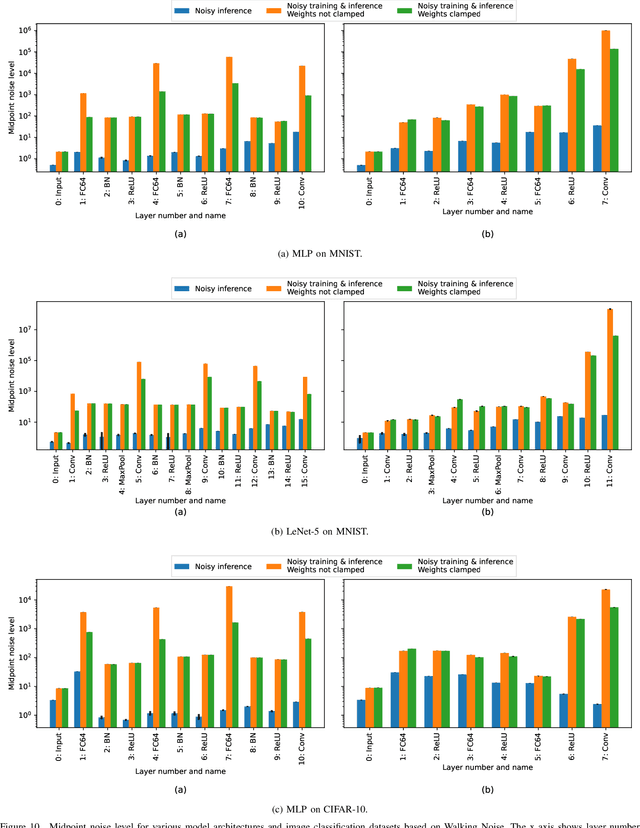
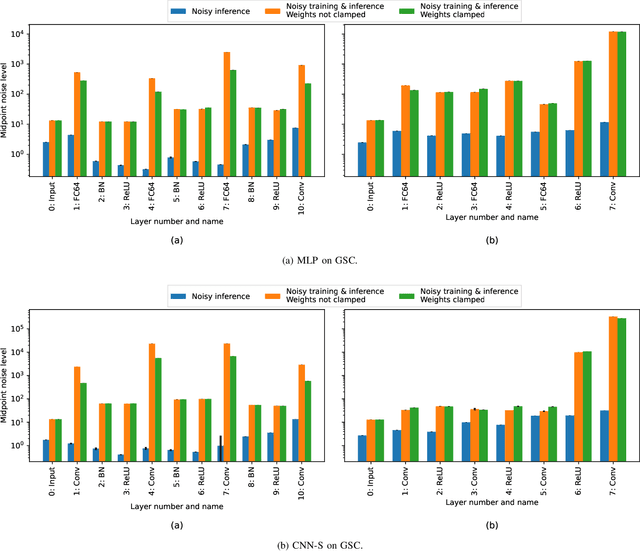

Machine learning methods like neural networks are extremely successful and popular in a variety of applications, however, they come at substantial computational costs, accompanied by high energy demands. In contrast, hardware capabilities are limited and there is evidence that technology scaling is stuttering, therefore, new approaches to meet the performance demands of increasingly complex model architectures are required. As an unsafe optimization, noisy computations are more energy efficient, and given a fixed power budget also more time efficient. However, any kind of unsafe optimization requires counter measures to ensure functionally correct results. This work considers noisy computations in an abstract form, and gears to understand the implications of such noise on the accuracy of neural-network-based classifiers as an exemplary workload. We propose a methodology called "Walking Noise" that allows to assess the robustness of different layers of deep architectures by means of a so-called "midpoint noise level" metric. We then investigate the implications of additive and multiplicative noise for different classification tasks and model architectures, with and without batch normalization. While noisy training significantly increases robustness for both noise types, we observe a clear trend to increase weights and thus increase the signal-to-noise ratio for additive noise injection. For the multiplicative case, we find that some networks, with suitably simple tasks, automatically learn an internal binary representation, hence becoming extremely robust. Overall this work proposes a method to measure the layer-specific robustness and shares first insights on how networks learn to compensate injected noise, and thus, contributes to understand robustness against noisy computations.
GreenMO: Virtualized User-proportionate MIMO
Nov 29, 2022
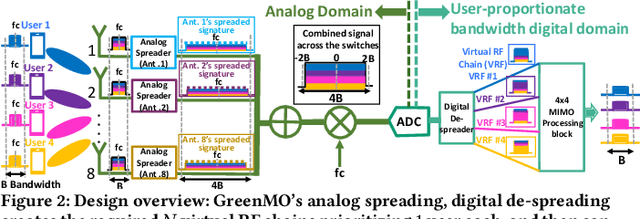
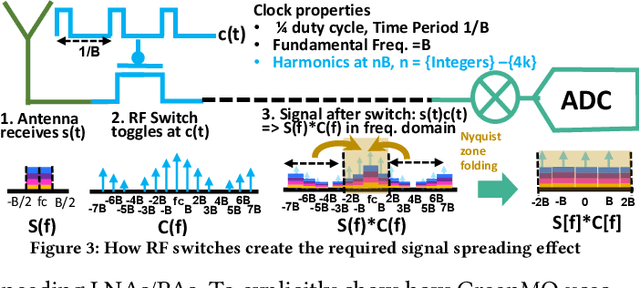
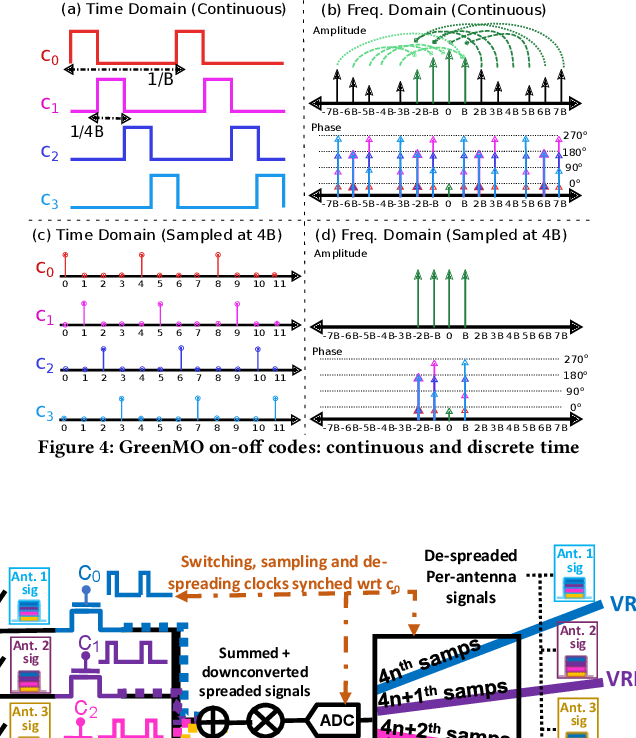
With the turn of new decade, wireless communications face a major challenge on connecting many more new users and devices, at the same time being energy efficient and minimizing its carbon footprint. However, the current approaches to address the growing number of users and spectrum demands, like traditional fully digital architectures for Massive MIMO, demand exorbitant energy consumption. The reason is that traditionally MIMO requires a separate RF chain per antenna, so the power consumption scales with number of antennas, instead of number of users, hence becomes energy inefficient. Instead, GreenMO creates a new massive MIMO architecture which is able to use many more antennas while keeping power consumption to user-proportionate numbers. To achieve this GreenMO introduces for the first time, the concept of virtualization of the RF chain hardware. Instead of laying the RF chains physically to each antenna, GreenMO creates these RF chains virtually in digital domain. This also enables GreenMO to be the first flexible massive MIMO architecture. Since GreenMO's virtual RF chains are created on the fly digitally, it can tune the number of these virtual chains according to the user load, hence always flexibly consume user-proportionate power. Thus, GreenMO paves the way for green and flexible massive MIMO. We prototype GreenMO on a PCB with eight antennas and evaluate it with a WARPv3 SDR platform in an office environment. The results demonstrate that GreenMO is 3x more power-efficient than traditional Massive MIMO and 4x more spectrum-efficient than traditional OFDMA systems, while multiplexing 4 users, and can save upto 40% power in modern 5G NR base stations.
Parameterisation of Reasoning on Temporal Markov Logic Networks
Nov 29, 2022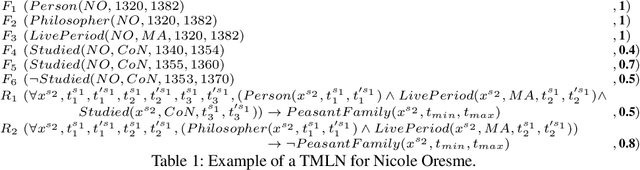
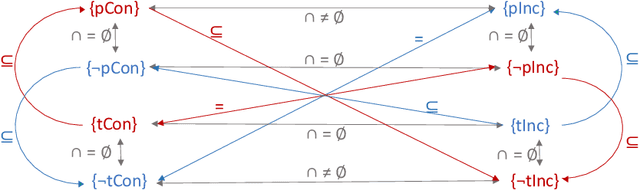
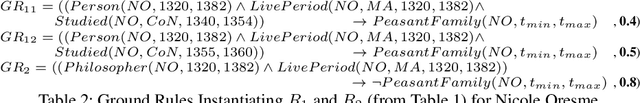

We aim at improving reasoning on inconsistent and uncertain data. We focus on knowledge-graph data, extended with time intervals to specify their validity, as regularly found in historical sciences. We propose principles on semantics for efficient Maximum A-Posteriori inference on the new Temporal Markov Logic Networks (TMLN) which extend the Markov Logic Networks (MLN) by uncertain temporal facts and rules. We examine total and partial temporal (in)consistency relations between sets of temporal formulae. Then we propose a new Temporal Parametric Semantics, which may combine several sub-functions, allowing to use different assessment strategies. Finally, we expose the constraints that semantics must respect to satisfy our principles.
Neural representation of a time optimal, constant acceleration rendezvous
Mar 29, 2022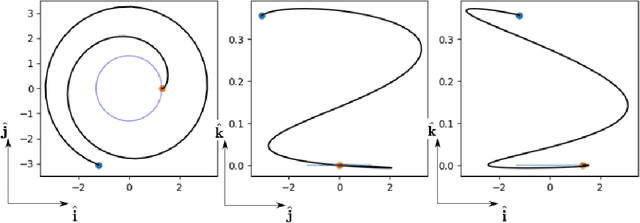
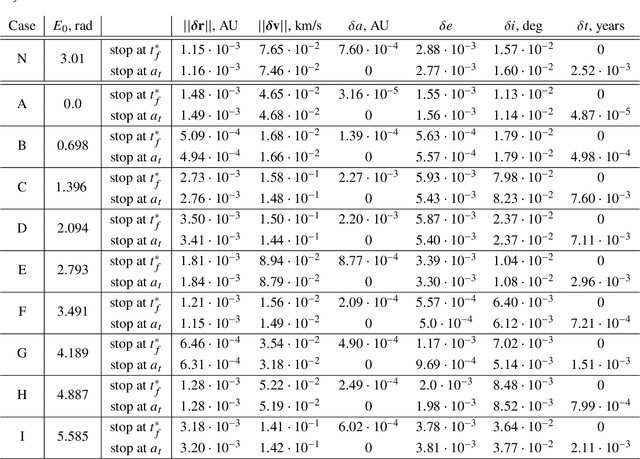
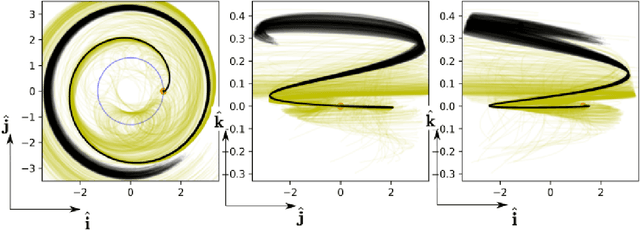
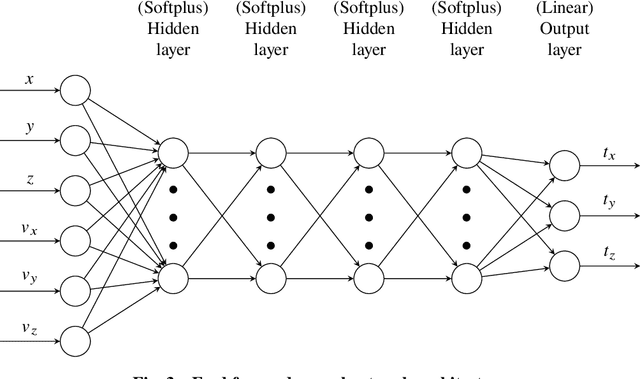
We train neural models to represent both the optimal policy (i.e. the optimal thrust direction) and the value function (i.e. the time of flight) for a time optimal, constant acceleration low-thrust rendezvous. In both cases we develop and make use of the data augmentation technique we call backward generation of optimal examples. We are thus able to produce and work with large dataset and to fully exploit the benefit of employing a deep learning framework. We achieve, in all cases, accuracies resulting in successful rendezvous (simulated following the learned policy) and time of flight predictions (using the learned value function). We find that residuals as small as a few m/s, thus well within the possibility of a spacecraft navigation $\Delta V$ budget, are achievable for the velocity at rendezvous. We also find that, on average, the absolute error to predict the optimal time of flight to rendezvous from any orbit in the asteroid belt to an Earth-like orbit is small (less than 4\%) and thus also of interest for practical uses, for example, during preliminary mission design phases.
A Permutation-Free Kernel Independence Test
Dec 18, 2022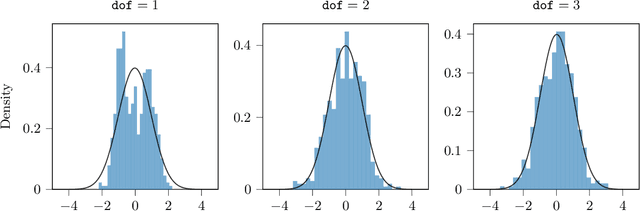
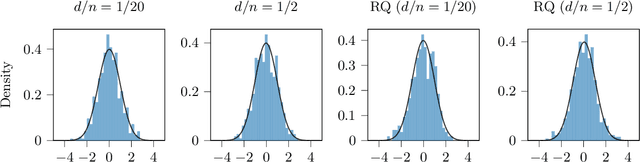
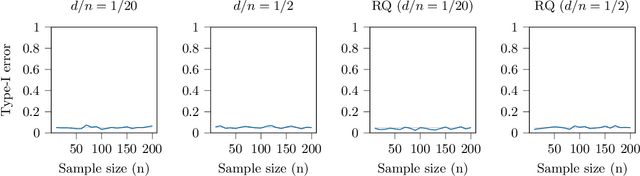
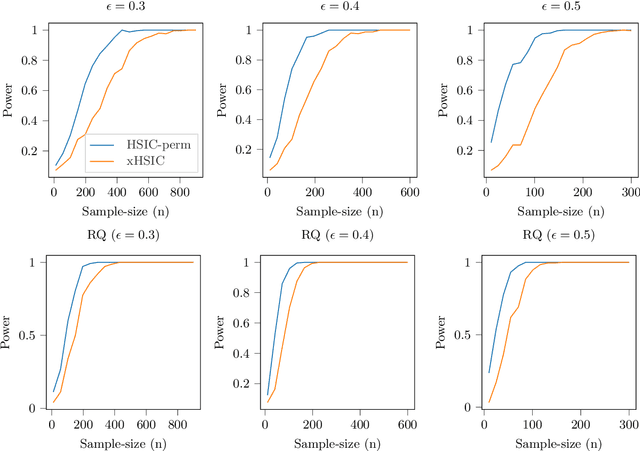
In nonparametric independence testing, we observe i.i.d.\ data $\{(X_i,Y_i)\}_{i=1}^n$, where $X \in \mathcal{X}, Y \in \mathcal{Y}$ lie in any general spaces, and we wish to test the null that $X$ is independent of $Y$. Modern test statistics such as the kernel Hilbert-Schmidt Independence Criterion (HSIC) and Distance Covariance (dCov) have intractable null distributions due to the degeneracy of the underlying U-statistics. Thus, in practice, one often resorts to using permutation testing, which provides a nonasymptotic guarantee at the expense of recalculating the quadratic-time statistics (say) a few hundred times. This paper provides a simple but nontrivial modification of HSIC and dCov (called xHSIC and xdCov, pronounced ``cross'' HSIC/dCov) so that they have a limiting Gaussian distribution under the null, and thus do not require permutations. This requires building on the newly developed theory of cross U-statistics by Kim and Ramdas (2020), and in particular developing several nontrivial extensions of the theory in Shekhar et al. (2022), which developed an analogous permutation-free kernel two-sample test. We show that our new tests, like the originals, are consistent against fixed alternatives, and minimax rate optimal against smooth local alternatives. Numerical simulations demonstrate that compared to the full dCov or HSIC, our variants have the same power up to a $\sqrt 2$ factor, giving practitioners a new option for large problems or data-analysis pipelines where computation, not sample size, could be the bottleneck.
Efficient Image Captioning for Edge Devices
Dec 18, 2022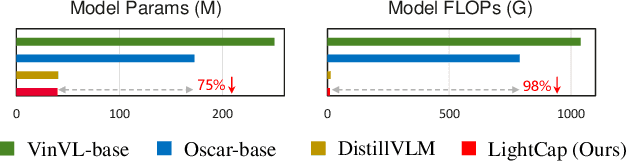
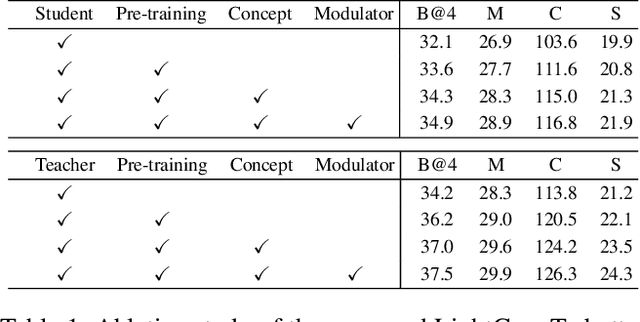
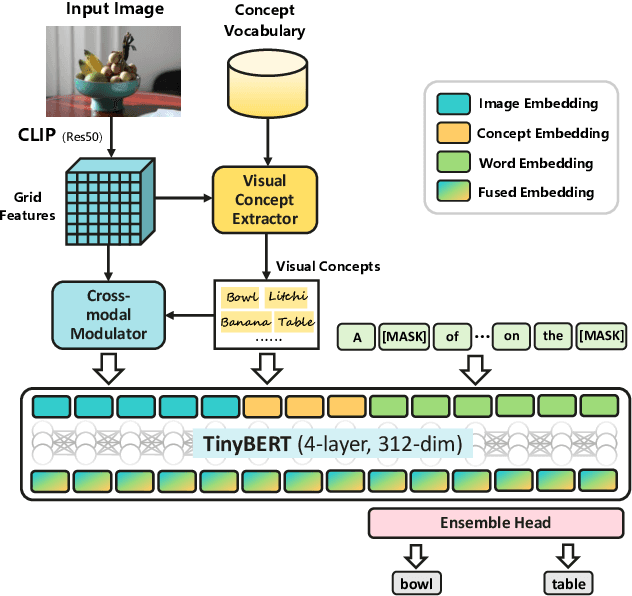
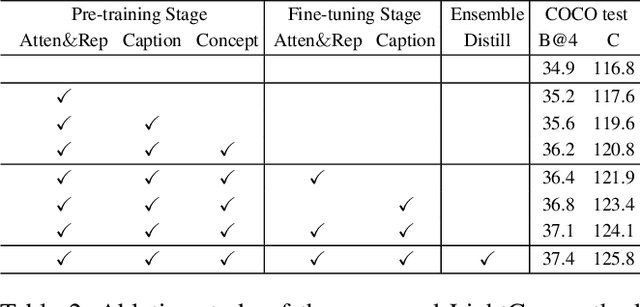
Recent years have witnessed the rapid progress of image captioning. However, the demands for large memory storage and heavy computational burden prevent these captioning models from being deployed on mobile devices. The main obstacles lie in the heavyweight visual feature extractors (i.e., object detectors) and complicated cross-modal fusion networks. To this end, we propose LightCap, a lightweight image captioner for resource-limited devices. The core design is built on the recent CLIP model for efficient image captioning. To be specific, on the one hand, we leverage the CLIP model to extract the compact grid features without relying on the time-consuming object detectors. On the other hand, we transfer the image-text retrieval design of CLIP to image captioning scenarios by devising a novel visual concept extractor and a cross-modal modulator. We further optimize the cross-modal fusion model and parallel prediction heads via sequential and ensemble distillations. With the carefully designed architecture, our model merely contains 40M parameters, saving the model size by more than 75% and the FLOPs by more than 98% in comparison with the current state-of-the-art methods. In spite of the low capacity, our model still exhibits state-of-the-art performance on prevalent datasets, e.g., 136.6 CIDEr on COCO Karpathy test split. Testing on the smartphone with only a single CPU, the proposed LightCap exhibits a fast inference speed of 188ms per image, which is ready for practical applications.
Neural Bandits for Data Mining: Searching for Dangerous Polypharmacy
Dec 10, 2022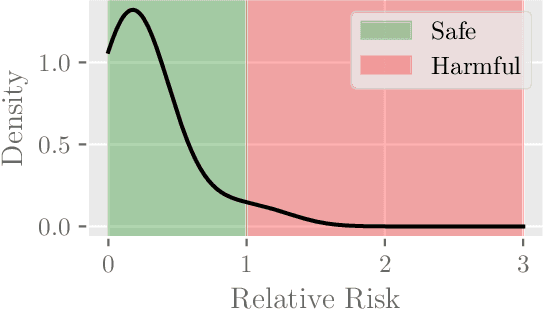

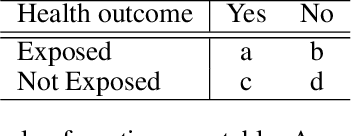
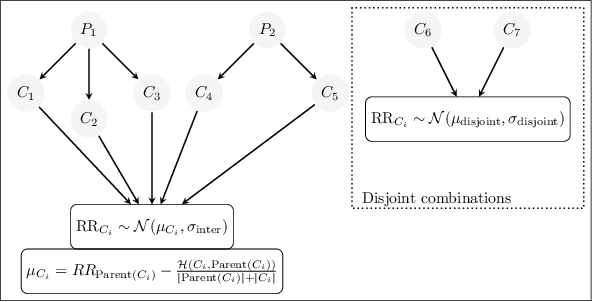
Polypharmacy, most often defined as the simultaneous consumption of five or more drugs at once, is a prevalent phenomenon in the older population. Some of these polypharmacies, deemed inappropriate, may be associated with adverse health outcomes such as death or hospitalization. Considering the combinatorial nature of the problem as well as the size of claims database and the cost to compute an exact association measure for a given drug combination, it is impossible to investigate every possible combination of drugs. Therefore, we propose to optimize the search for potentially inappropriate polypharmacies (PIPs). To this end, we propose the OptimNeuralTS strategy, based on Neural Thompson Sampling and differential evolution, to efficiently mine claims datasets and build a predictive model of the association between drug combinations and health outcomes. We benchmark our method using two datasets generated by an internally developed simulator of polypharmacy data containing 500 drugs and 100 000 distinct combinations. Empirically, our method can detect up to 33\% of PIPs while maintaining an average precision score of 99\% using 10 000 time steps.