 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Localization and Navigation System for Indoor Mobile Robot
Dec 13, 2022
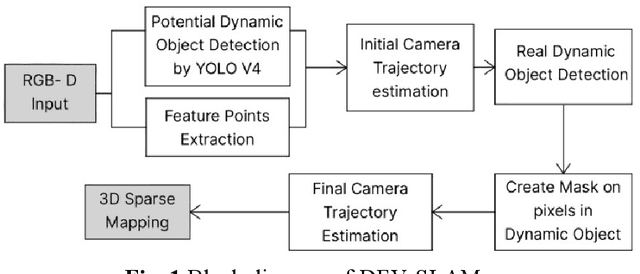

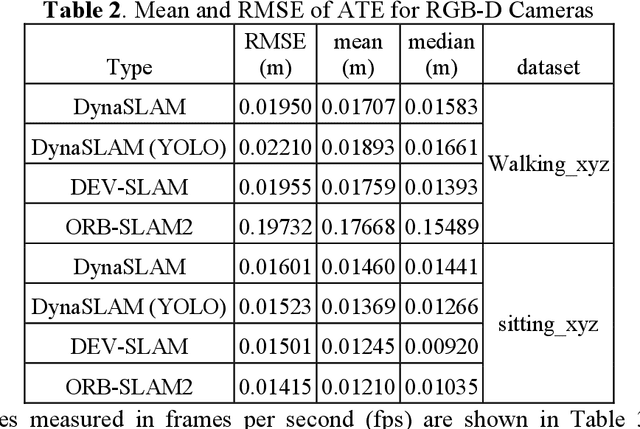

Visually impaired people usually find it hard to travel independently in many public places such as airports and shopping malls due to the problems of obstacle avoidance and guidance to the desired location. Therefore, in the highly dynamic indoor environment, how to improve indoor navigation robot localization and navigation accuracy so that they guide the visually impaired well becomes a problem. One way is to use visual SLAM. However, typical visual SLAM either assumes a static environment, which may lead to less accurate results in dynamic environments or assumes that the targets are all dynamic and removes all the feature points above, sacrificing computational speed to a large extent with the available computational power. This paper seeks to explore marginal localization and navigation systems for indoor navigation robotics. The proposed system is designed to improve localization and navigation accuracy in highly dynamic environments by identifying and tracking potentially moving objects and using vector field histograms for local path planning and obstacle avoidance. The system has been tested on a public indoor RGB-D dataset, and the results show that the new system improves accuracy and robustness while reducing computation time in highly dynamic indoor scenes.
Adversarially Robust Video Perception by Seeing Motion
Dec 13, 2022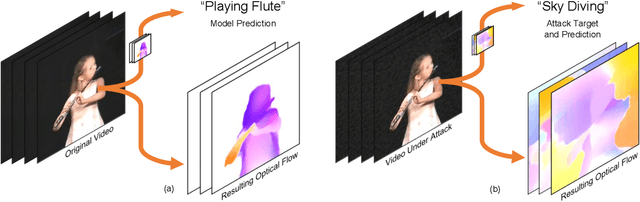
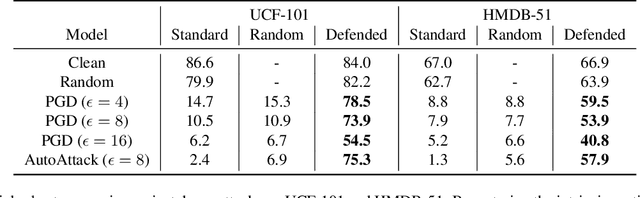
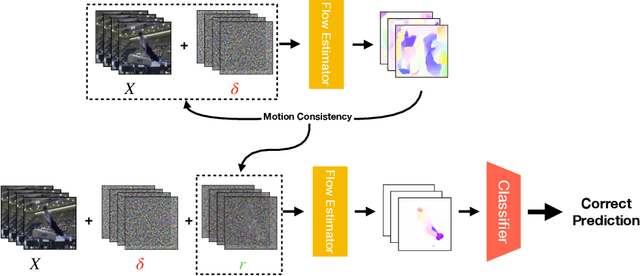
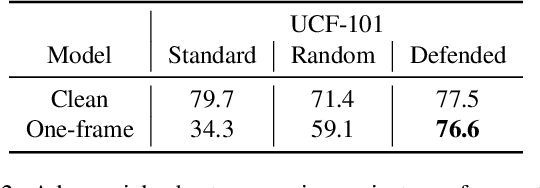
Despite their excellent performance, state-of-the-art computer vision models often fail when they encounter adversarial examples. Video perception models tend to be more fragile under attacks, because the adversary has more places to manipulate in high-dimensional data. In this paper, we find one reason for video models' vulnerability is that they fail to perceive the correct motion under adversarial perturbations. Inspired by the extensive evidence that motion is a key factor for the human visual system, we propose to correct what the model sees by restoring the perceived motion information. Since motion information is an intrinsic structure of the video data, recovering motion signals can be done at inference time without any human annotation, which allows the model to adapt to unforeseen, worst-case inputs. Visualizations and empirical experiments on UCF-101 and HMDB-51 datasets show that restoring motion information in deep vision models improves adversarial robustness. Even under adaptive attacks where the adversary knows our defense, our algorithm is still effective. Our work provides new insight into robust video perception algorithms by using intrinsic structures from the data. Our webpage is available at https://motion4robust.cs.columbia.edu.
Multivariate Powered Dirichlet Hawkes Process
Dec 13, 2022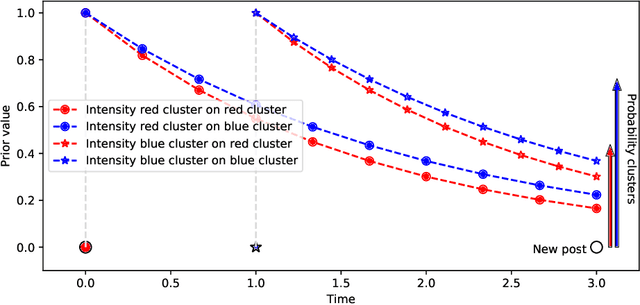
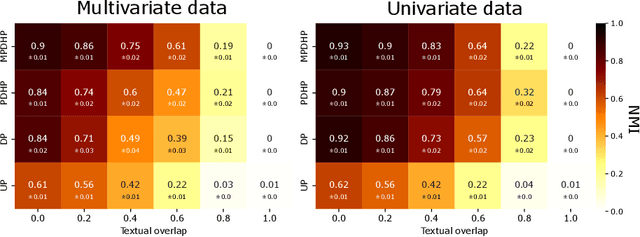
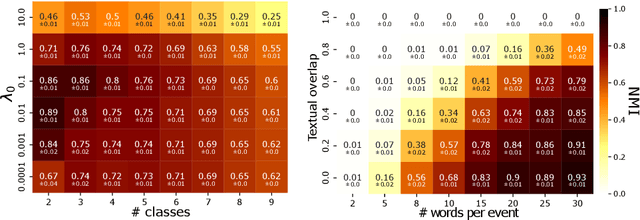
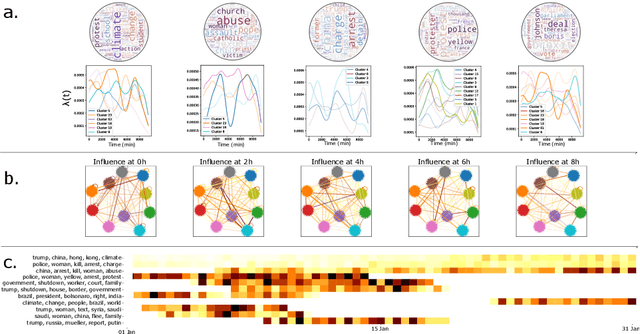
The publication time of a document carries a relevant information about its semantic content. The Dirichlet-Hawkes process has been proposed to jointly model textual information and publication dynamics. This approach has been used with success in several recent works, and extended to tackle specific challenging problems --typically for short texts or entangled publication dynamics. However, the prior in its current form does not allow for complex publication dynamics. In particular, inferred topics are independent from each other --a publication about finance is assumed to have no influence on publications about politics, for instance. In this work, we develop the Multivariate Powered Dirichlet-Hawkes Process (MPDHP), that alleviates this assumption. Publications about various topics can now influence each other. We detail and overcome the technical challenges that arise from considering interacting topics. We conduct a systematic evaluation of MPDHP on a range of synthetic datasets to define its application domain and limitations. Finally, we develop a use case of the MPDHP on Reddit data. At the end of this article, the interested reader will know how and when to use MPDHP, and when not to.
Inductive Attention for Video Action Anticipation
Dec 17, 2022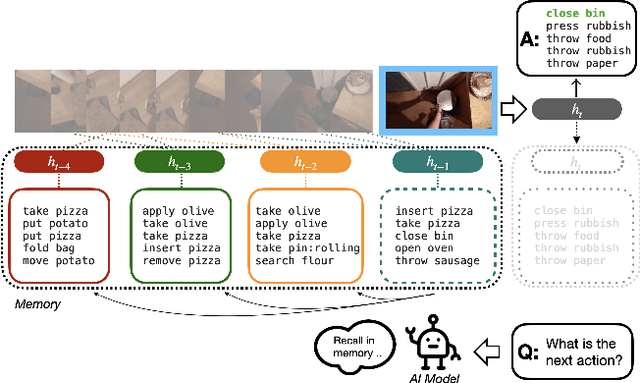
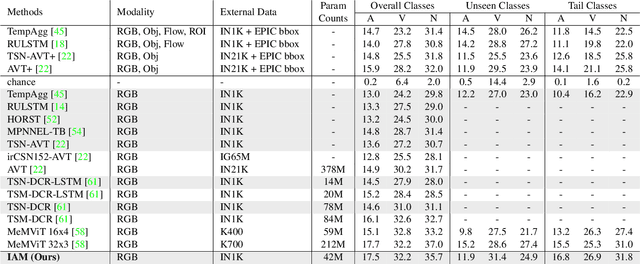
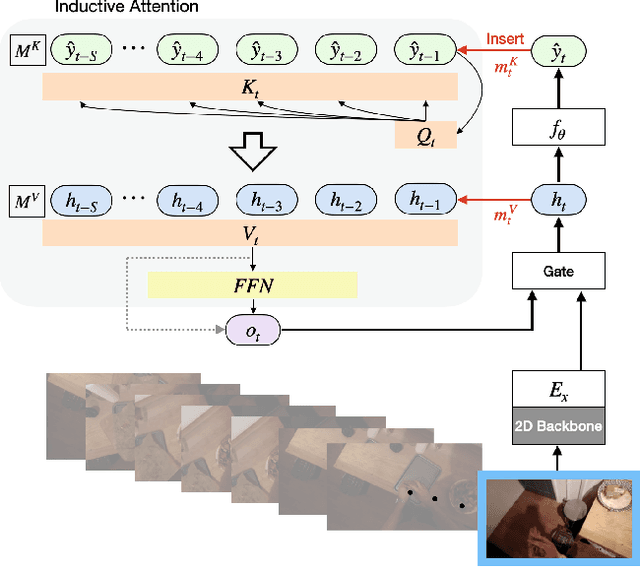
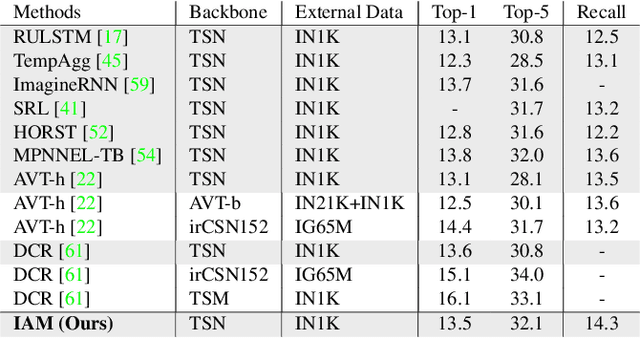
Anticipating future actions based on video observations is an important task in video understanding, which would be useful for some precautionary systems that require response time to react before an event occurs. Since the input in action anticipation is only pre-action frames, models do not have enough information about the target action; moreover, similar pre-action frames may lead to different futures. Consequently, any solution using existing action recognition models can only be suboptimal. Recently, researchers have proposed using a longer video context to remedy the insufficient information in pre-action intervals, as well as the self-attention to query past relevant moments to address the anticipation problem. However, the indirect use of video input features as the query might be inefficient, as it only serves as the proxy to the anticipation goal. To this end, we propose an inductive attention model, which transparently uses prior prediction as the query to derive the anticipation result by induction from past experience. Our method naturally considers the uncertainty of multiple futures via the many-to-many association. On the large-scale egocentric video datasets, our model not only shows consistently better performance than state of the art using the same backbone, and is competitive to the methods that employ a stronger backbone, but also superior efficiency in less model parameters.
An Adaptive Simulated Annealing-Based Machine Learning Approach for Developing an E-Triage Tool for Hospital Emergency Operations
Dec 22, 2022

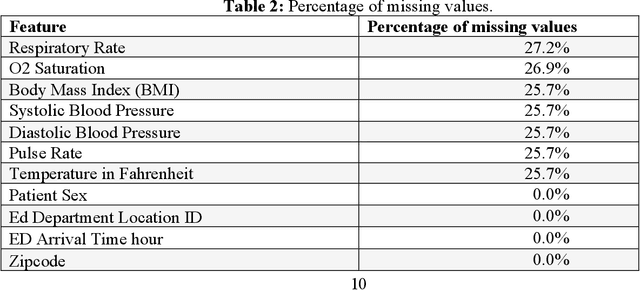
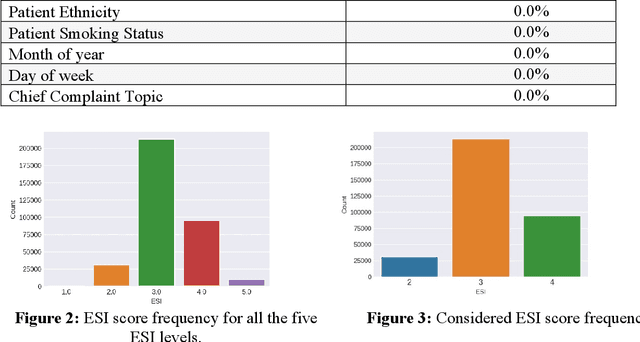
Patient triage at emergency departments (EDs) is necessary to prioritize care for patients with critical and time-sensitive conditions. Different tools are used for patient triage and one of the most common ones is the emergency severity index (ESI), which has a scale of five levels, where level 1 is the most urgent and level 5 is the least urgent. This paper proposes a framework for utilizing machine learning to develop an e-triage tool that can be used at EDs. A large retrospective dataset of ED patient visits is obtained from the electronic health record of a healthcare provider in the Midwest of the US for three years. However, the main challenge of using machine learning algorithms is that most of them have many parameters and without optimizing these parameters, developing a high-performance model is not possible. This paper proposes an approach to optimize the hyperparameters of machine learning. The metaheuristic optimization algorithms simulated annealing (SA) and adaptive simulated annealing (ASA) are proposed to optimize the parameters of extreme gradient boosting (XGB) and categorical boosting (CaB). The newly proposed algorithms are SA-XGB, ASA-XGB, SA-CaB, ASA-CaB. Grid search (GS), which is a traditional approach used for machine learning fine-tunning is also used to fine-tune the parameters of XGB and CaB, which are named GS-XGB and GS-CaB. The six algorithms are trained and tested using eight data groups obtained from the feature selection phase. The results show ASA-CaB outperformed all the proposed algorithms with accuracy, precision, recall, and f1 of 83.3%, 83.2%, 83.3%, 83.2%, respectively.
Enhancing Indic Handwritten Text Recognition Using Global Semantic Information
Dec 15, 2022Handwritten Text Recognition (HTR) is more interesting and challenging than printed text due to uneven variations in the handwriting style of the writers, content, and time. HTR becomes more challenging for the Indic languages because of (i) multiple characters combined to form conjuncts which increase the number of characters of respective languages, and (ii) near to 100 unique basic Unicode characters in each Indic script. Recently, many recognition methods based on the encoder-decoder framework have been proposed to handle such problems. They still face many challenges, such as image blur and incomplete characters due to varying writing styles and ink density. We argue that most encoder-decoder methods are based on local visual features without explicit global semantic information. In this work, we enhance the performance of Indic handwritten text recognizers using global semantic information. We use a semantic module in an encoder-decoder framework for extracting global semantic information to recognize the Indic handwritten texts. The semantic information is used in both the encoder for supervision and the decoder for initialization. The semantic information is predicted from the word embedding of a pre-trained language model. Extensive experiments demonstrate that the proposed framework achieves state-of-the-art results on handwritten texts of ten Indic languages.
Generalizing LTL Instructions via Future Dependent Options
Dec 15, 2022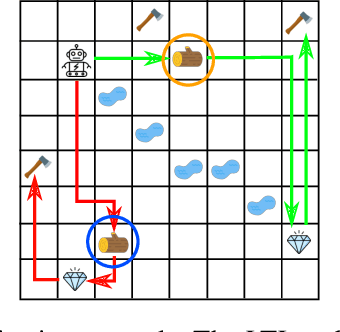
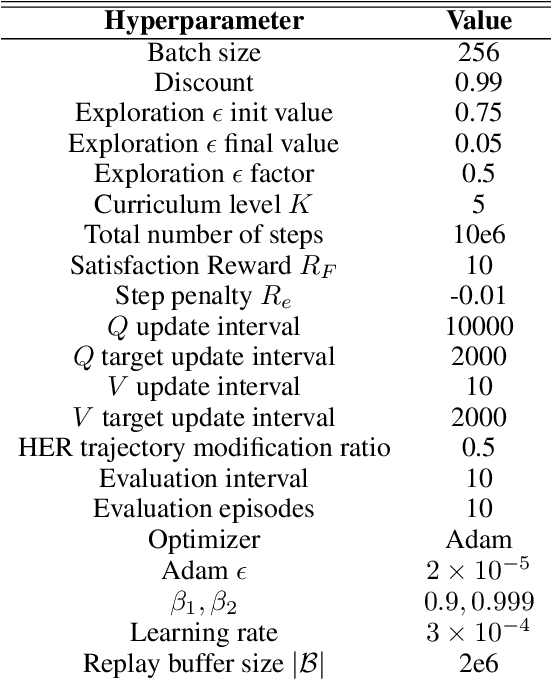

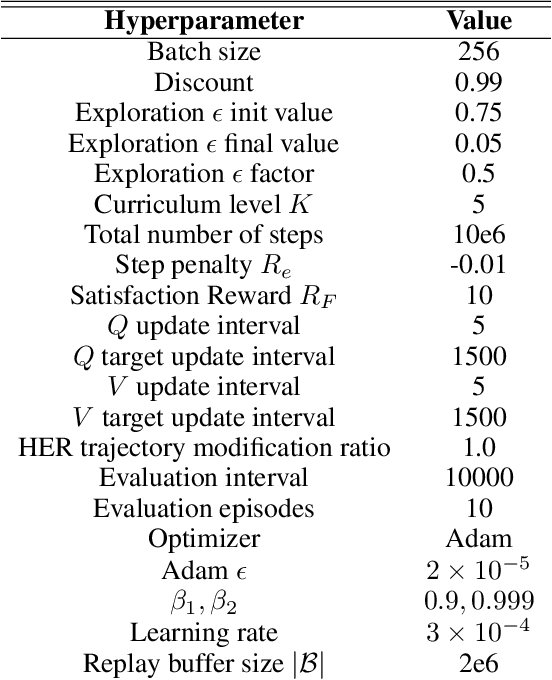
In many real-world applications of control system and robotics, linear temporal logic (LTL) is a widely-used task specification language which has a compositional grammar that naturally induces temporally extended behaviours across tasks, including conditionals and alternative realizations. An important problem in RL with LTL tasks is to learn task-conditioned policies which can zero-shot generalize to new LTL instructions not observed in the training. However, because symbolic observation is often lossy and LTL tasks can have long time horizon, previous works can suffer from issues such as training sampling inefficiency and infeasibility or sub-optimality of the found solutions. In order to tackle these issues, this paper proposes a novel multi-task RL algorithm with improved learning efficiency and optimality. To achieve the global optimality of task completion, we propose to learn options dependent on the future subgoals via a novel off-policy approach. In order to propagate the rewards of satisfying future subgoals back more efficiently, we propose to train a multi-step value function conditioned on the subgoal sequence which is updated with Monte Carlo estimates of multi-step discounted returns. In experiments on three different domains, we evaluate the LTL generalization capability of the agent trained by the proposed method, showing its advantage over previous representative methods.
Universal Generative Modeling in Dual-domain for Dynamic MR Imaging
Dec 15, 2022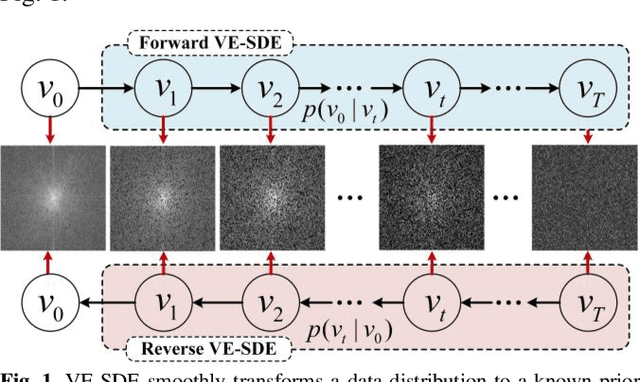
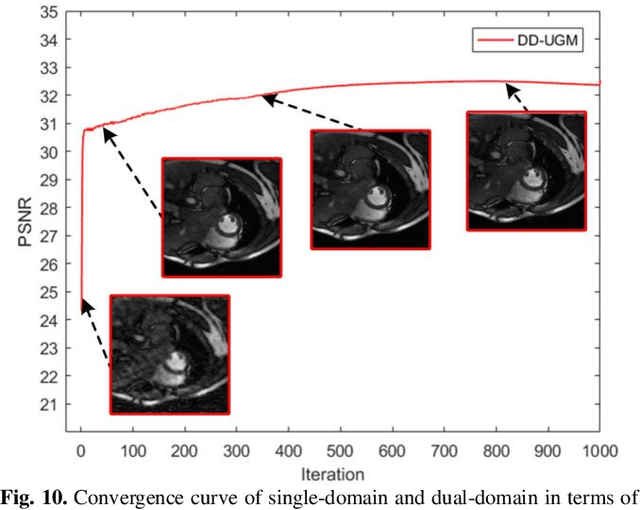
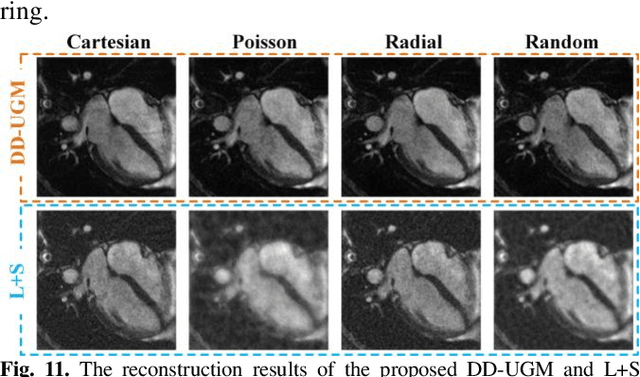
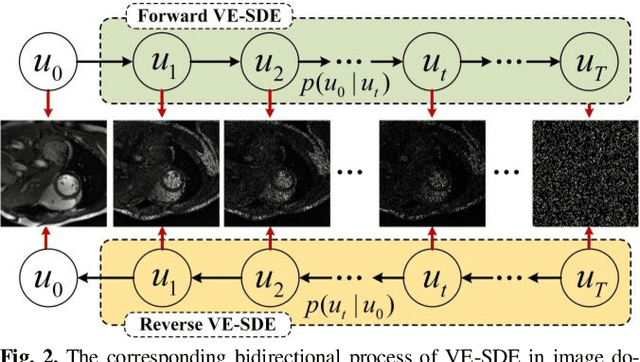
Dynamic magnetic resonance image reconstruction from incomplete k-space data has generated great research interest due to its capability to reduce scan time. Never-theless, the reconstruction problem is still challenging due to its ill-posed nature. Recently, diffusion models espe-cially score-based generative models have exhibited great potential in algorithm robustness and usage flexi-bility. Moreover, the unified framework through the variance exploding stochastic differential equation (VE-SDE) is proposed to enable new sampling methods and further extend the capabilities of score-based gener-ative models. Therefore, by taking advantage of the uni-fied framework, we proposed a k-space and image Du-al-Domain collaborative Universal Generative Model (DD-UGM) which combines the score-based prior with low-rank regularization penalty to reconstruct highly under-sampled measurements. More precisely, we extract prior components from both image and k-space domains via a universal generative model and adaptively handle these prior components for faster processing while maintaining good generation quality. Experimental comparisons demonstrated the noise reduction and detail preservation abilities of the proposed method. Much more than that, DD-UGM can reconstruct data of differ-ent frames by only training a single frame image, which reflects the flexibility of the proposed model.
A Data Source Dependency Analysis Framework for Large Scale Data Science Projects
Dec 15, 2022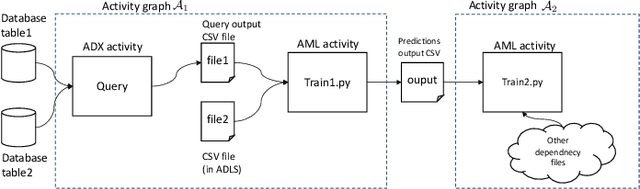

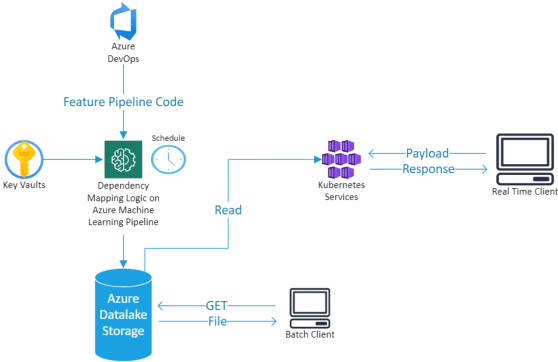
Dependency hell is a well-known pain point in the development of large software projects and machine learning (ML) code bases are not immune from it. In fact, ML applications suffer from an additional form, namely, "data source dependency hell". This term refers to the central role played by data and its unique quirks that often lead to unexpected failures of ML models which cannot be explained by code changes. In this paper, we present an automated dependency mapping framework that allows MLOps engineers to monitor the whole dependency map of their models in a fast paced engineering environment and thus mitigate ahead of time the consequences of any data source changes (e.g., re-train model, ignore data, set default data etc.). Our system is based on a unified and generic approach, employing techniques from static analysis, from which data sources can be identified reliably for any type of dependency on a wide range of source languages and artefacts. The dependency mapping framework is exposed as a REST web API where the only input is the path to the Git repository hosting the code base. Currently used by MLOps engineers at Microsoft, we expect such dependency map APIs to be adopted more widely by MLOps engineers in the future.
A Study on the Intersection of GPU Utilization and CNN Inference
Dec 15, 2022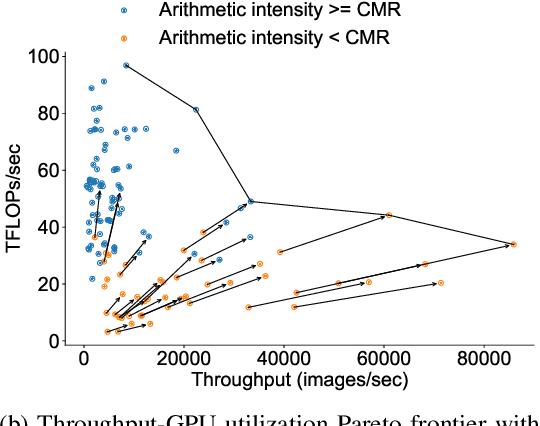
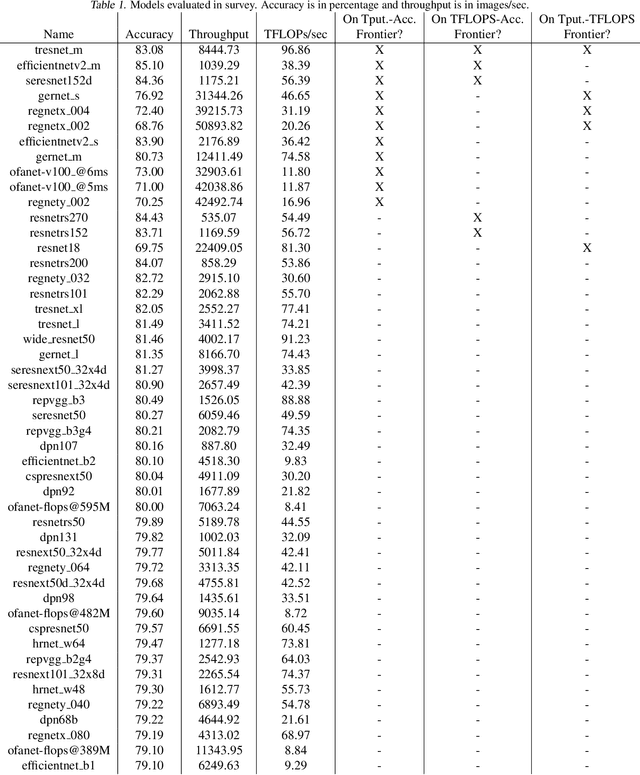
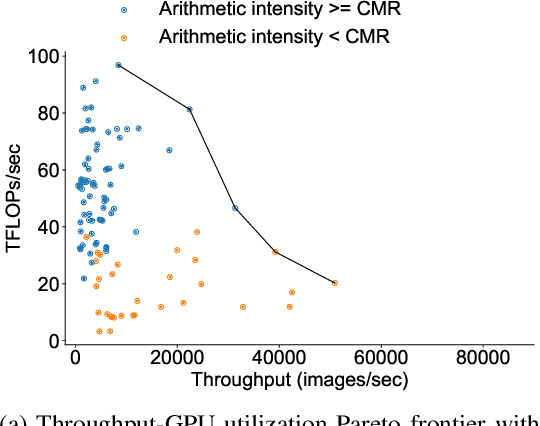
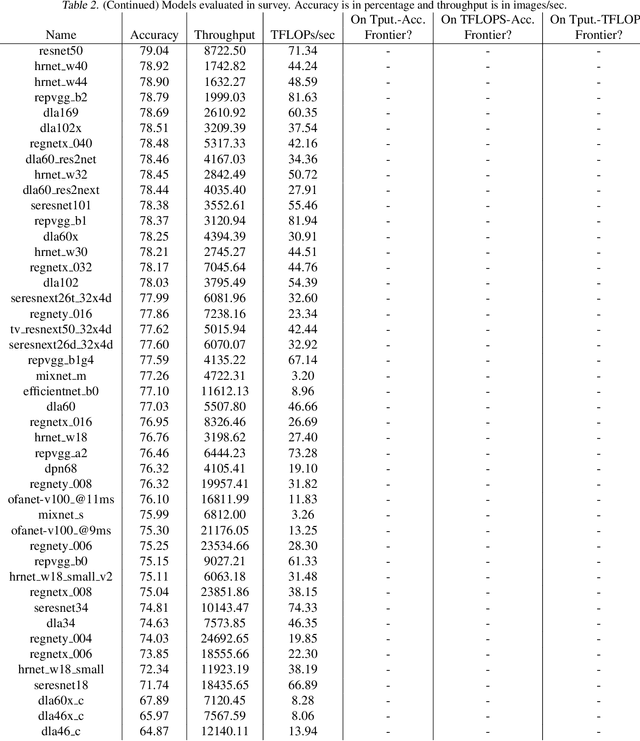
There has been significant progress in developing neural network architectures that both achieve high predictive performance and that also achieve high application-level inference throughput (e.g., frames per second). Another metric of increasing importance is GPU utilization during inference: the measurement of how well a deployed neural network uses the computational capabilities of the GPU on which it runs. Achieving high GPU utilization is critical to increasing application-level throughput and ensuring a good return on investment for deploying GPUs. This paper analyzes the GPU utilization of convolutional neural network (CNN) inference. We first survey the GPU utilization of CNNs to show that there is room to improve the GPU utilization of many of these CNNs. We then investigate the GPU utilization of networks within a neural architecture search (NAS) search space, and explore how using GPU utilization as a metric could potentially be used to accelerate NAS itself. Our study makes the case that there is room to improve the inference-time GPU utilization of CNNs and that knowledge of GPU utilization has the potential to benefit even applications that do not target utilization itself. We hope that the results of this study will spur future innovation in designing GPU-efficient neural networks.