 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Stochastic First-Order Learning for Large-Scale Flexibly Tied Gaussian Mixture Model
Dec 11, 2022
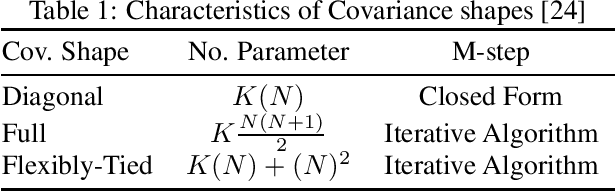
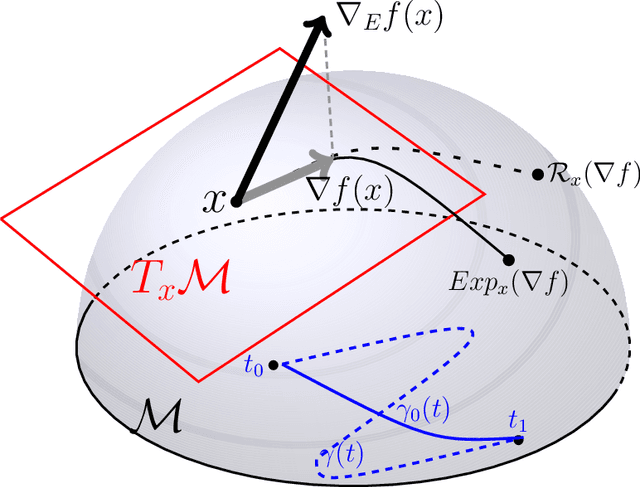
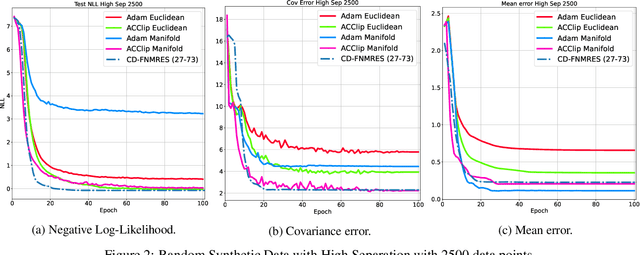
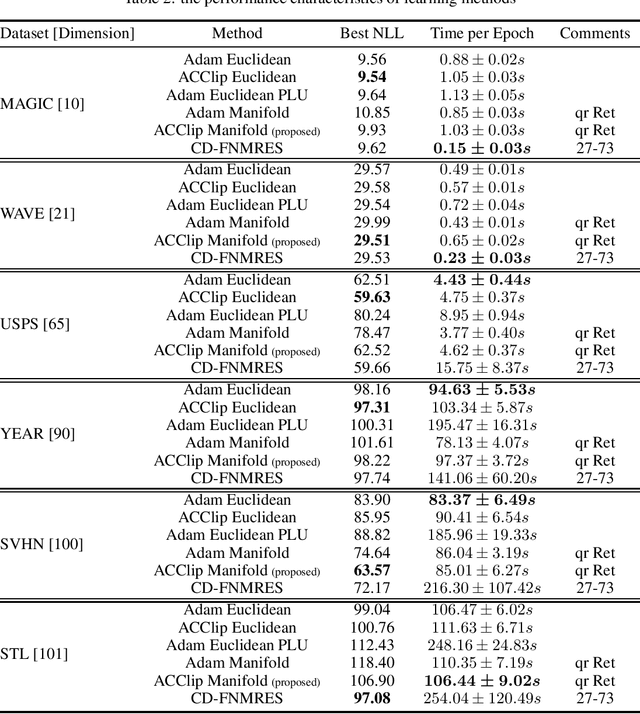
Gaussian Mixture Models (GMM) are one of the most potent parametric density estimators based on the kernel model that finds application in many scientific domains. In recent years, with the dramatic enlargement of data sources, typical machine learning algorithms, e.g. Expectation Maximization (EM), encounters difficulty with high-dimensional and streaming data. Moreover, complicated densities often demand a large number of Gaussian components. This paper proposes a fast online parameter estimation algorithm for GMM by using first-order stochastic optimization. This approach provides a framework to cope with the challenges of GMM when faced with high-dimensional streaming data and complex densities by leveraging the flexibly-tied factorization of the covariance matrix. A new stochastic Manifold optimization algorithm that preserves the orthogonality is introduced and used along with the well-known Euclidean space numerical optimization. Numerous empirical results on both synthetic and real datasets justify the effectiveness of our proposed stochastic method over EM-based methods in the sense of better-converged maximum for likelihood function, fewer number of needed epochs for convergence, and less time consumption per epoch.
Safety-quantifiable Line Feature-based Monocular Visual Localization with 3D Prior Map
Nov 28, 2022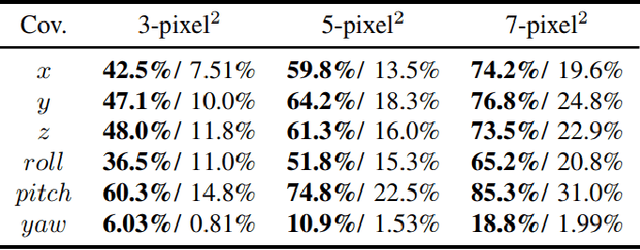
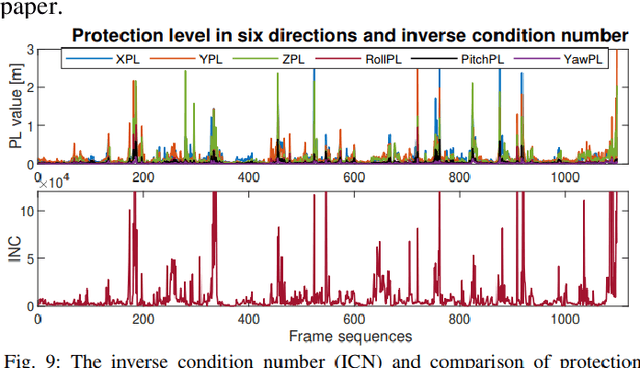
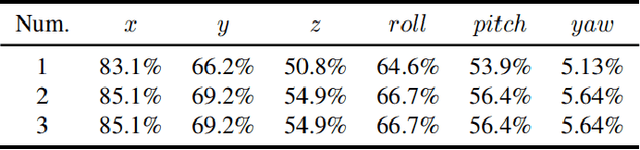
Accurate and safety-quantifiable localization is of great significance for safety-critical autonomous systems, such as unmanned ground vehicles (UGV) and unmanned aerial vehicles (UAV). The visual odometry-based method can provide accurate positioning in a short period but is subjected to drift over time. Moreover, the quantification of the safety of the localization solution (the error is bounded by a certain value) is still a challenge. To fill the gaps, this paper proposes a safety-quantifiable line feature-based visual localization method with a prior map. The visual-inertial odometry provides a high-frequency local pose estimation which serves as the initial guess for the visual localization. By obtaining a visual line feature pair association, a foot point-based constraint is proposed to construct the cost function between the 2D lines extracted from the real-time image and the 3D lines extracted from the high-precision prior 3D point cloud map. Moreover, a global navigation satellite systems (GNSS) receiver autonomous integrity monitoring (RAIM) inspired method is employed to quantify the safety of the derived localization solution. Among that, an outlier rejection (also well-known as fault detection and exclusion) strategy is employed via the weighted sum of squares residual with a Chi-squared probability distribution. A protection level (PL) scheme considering multiple outliers is derived and utilized to quantify the potential error bound of the localization solution in both position and rotation domains. The effectiveness of the proposed safety-quantifiable localization system is verified using the datasets collected in the UAV indoor and UGV outdoor environments.
Neuro-Symbolic Spatio-Temporal Reasoning
Nov 28, 2022


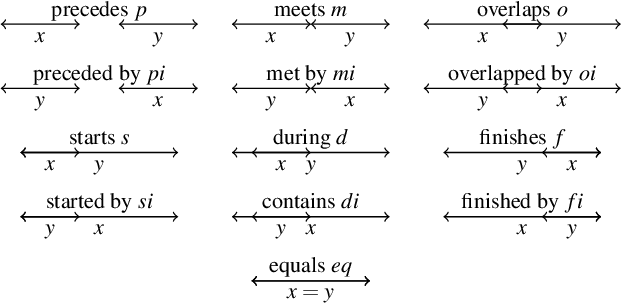
Knowledge about space and time is necessary to solve problems in the physical world: An AI agent situated in the physical world and interacting with objects often needs to reason about positions of and relations between objects; and as soon as the agent plans its actions to solve a task, it needs to consider the temporal aspect (e.g., what actions to perform over time). Spatio-temporal knowledge, however, is required beyond interacting with the physical world, and is also often transferred to the abstract world of concepts through analogies and metaphors (e.g., "a threat that is hanging over our heads"). As spatial and temporal reasoning is ubiquitous, different attempts have been made to integrate this into AI systems. In the area of knowledge representation, spatial and temporal reasoning has been largely limited to modeling objects and relations and developing reasoning methods to verify statements about objects and relations. On the other hand, neural network researchers have tried to teach models to learn spatial relations from data with limited reasoning capabilities. Bridging the gap between these two approaches in a mutually beneficial way could allow us to tackle many complex real-world problems, such as natural language processing, visual question answering, and semantic image segmentation. In this chapter, we view this integration problem from the perspective of Neuro-Symbolic AI. Specifically, we propose a synergy between logical reasoning and machine learning that will be grounded on spatial and temporal knowledge. Describing some successful applications, remaining challenges, and evaluation datasets pertaining to this direction is the main topic of this contribution.
An Adaptive Simulated Annealing-Based Machine Learning Approach for Developing an E-Triage Tool for Hospital Emergency Operations
Dec 22, 2022

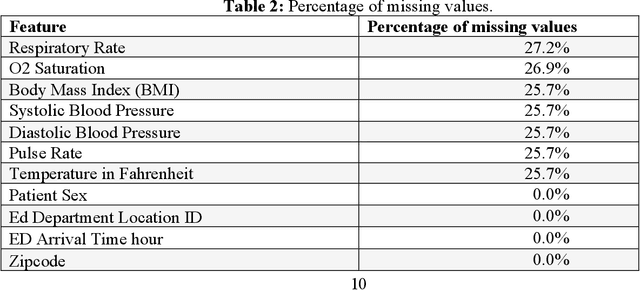
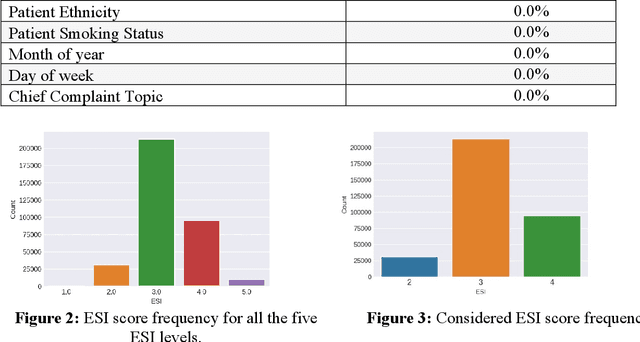
Patient triage at emergency departments (EDs) is necessary to prioritize care for patients with critical and time-sensitive conditions. Different tools are used for patient triage and one of the most common ones is the emergency severity index (ESI), which has a scale of five levels, where level 1 is the most urgent and level 5 is the least urgent. This paper proposes a framework for utilizing machine learning to develop an e-triage tool that can be used at EDs. A large retrospective dataset of ED patient visits is obtained from the electronic health record of a healthcare provider in the Midwest of the US for three years. However, the main challenge of using machine learning algorithms is that most of them have many parameters and without optimizing these parameters, developing a high-performance model is not possible. This paper proposes an approach to optimize the hyperparameters of machine learning. The metaheuristic optimization algorithms simulated annealing (SA) and adaptive simulated annealing (ASA) are proposed to optimize the parameters of extreme gradient boosting (XGB) and categorical boosting (CaB). The newly proposed algorithms are SA-XGB, ASA-XGB, SA-CaB, ASA-CaB. Grid search (GS), which is a traditional approach used for machine learning fine-tunning is also used to fine-tune the parameters of XGB and CaB, which are named GS-XGB and GS-CaB. The six algorithms are trained and tested using eight data groups obtained from the feature selection phase. The results show ASA-CaB outperformed all the proposed algorithms with accuracy, precision, recall, and f1 of 83.3%, 83.2%, 83.3%, 83.2%, respectively.
GlueFL: Reconciling Client Sampling and Model Masking for Bandwidth Efficient Federated Learning
Dec 03, 2022
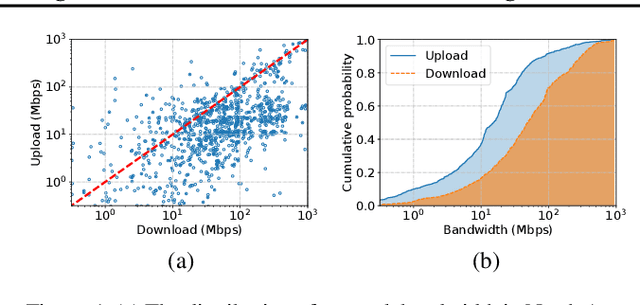
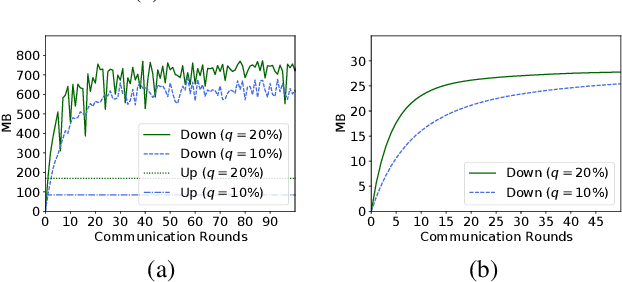
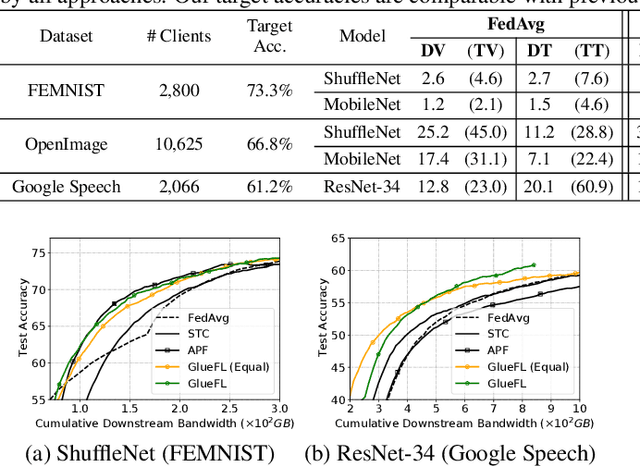
Federated learning (FL) is an effective technique to directly involve edge devices in machine learning training while preserving client privacy. However, the substantial communication overhead of FL makes training challenging when edge devices have limited network bandwidth. Existing work to optimize FL bandwidth overlooks downstream transmission and does not account for FL client sampling. In this paper we propose GlueFL, a framework that incorporates new client sampling and model compression algorithms to mitigate low download bandwidths of FL clients. GlueFL prioritizes recently used clients and bounds the number of changed positions in compression masks in each round. Across three popular FL datasets and three state-of-the-art strategies, GlueFL reduces downstream client bandwidth by 27% on average and reduces training time by 29% on average.
Inductive Attention for Video Action Anticipation
Dec 17, 2022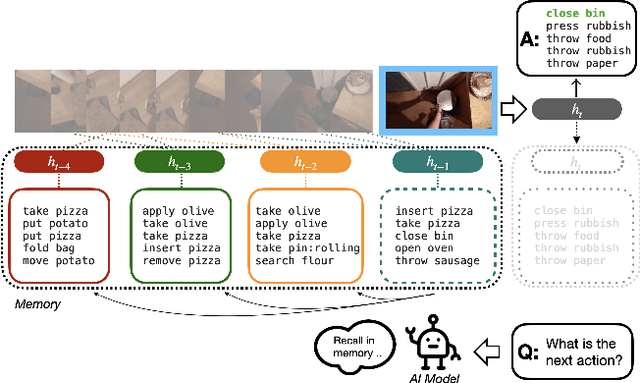
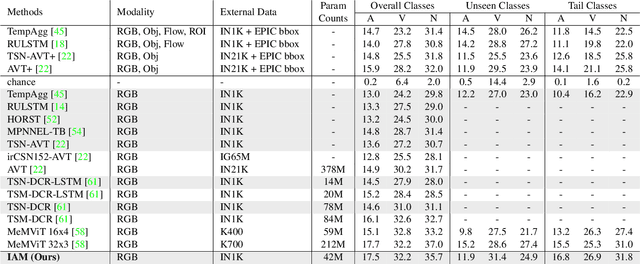
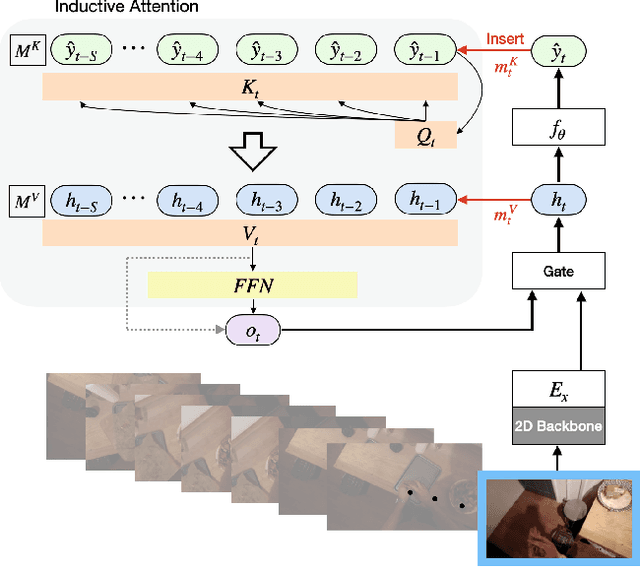
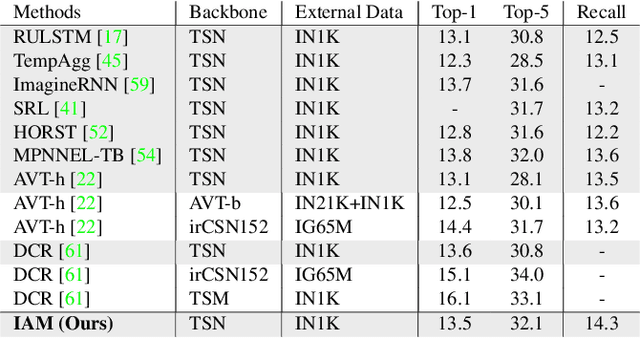
Anticipating future actions based on video observations is an important task in video understanding, which would be useful for some precautionary systems that require response time to react before an event occurs. Since the input in action anticipation is only pre-action frames, models do not have enough information about the target action; moreover, similar pre-action frames may lead to different futures. Consequently, any solution using existing action recognition models can only be suboptimal. Recently, researchers have proposed using a longer video context to remedy the insufficient information in pre-action intervals, as well as the self-attention to query past relevant moments to address the anticipation problem. However, the indirect use of video input features as the query might be inefficient, as it only serves as the proxy to the anticipation goal. To this end, we propose an inductive attention model, which transparently uses prior prediction as the query to derive the anticipation result by induction from past experience. Our method naturally considers the uncertainty of multiple futures via the many-to-many association. On the large-scale egocentric video datasets, our model not only shows consistently better performance than state of the art using the same backbone, and is competitive to the methods that employ a stronger backbone, but also superior efficiency in less model parameters.
Turning Silver into Gold: Domain Adaptation with Noisy Labels for Wearable Cardio-Respiratory Fitness Prediction
Nov 20, 2022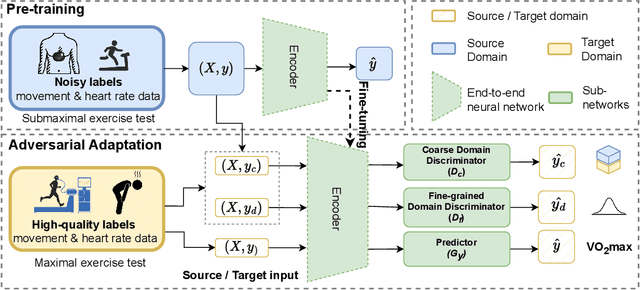

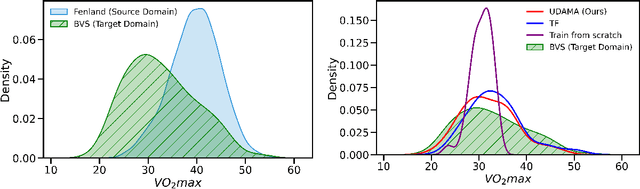
Deep learning models have shown great promise in various healthcare applications. However, most models are developed and validated on small-scale datasets, as collecting high-quality (gold-standard) labels for health applications is often costly and time-consuming. As a result, these models may suffer from overfitting and not generalize well to unseen data. At the same time, an extensive amount of data with imprecise labels (silver-standard) is starting to be generally available, as collected from inexpensive wearables like accelerometers and electrocardiography sensors. These currently underutilized datasets and labels can be leveraged to produce more accurate clinical models. In this work, we propose UDAMA, a novel model with two key components: Unsupervised Domain Adaptation and Multi-discriminator Adversarial training, which leverage noisy data from source domain (the silver-standard dataset) to improve gold-standard modeling. We validate our framework on the challenging task of predicting lab-measured maximal oxygen consumption (VO$_{2}$max), the benchmark metric of cardio-respiratory fitness, using free-living wearable sensor data from two cohort studies as inputs. Our experiments show that the proposed framework achieves the best performance of corr = 0.665 $\pm$ 0.04, paving the way for accurate fitness estimation at scale.
Multi-scale Anomaly Detection for Big Time Series of Industrial Sensors
Apr 18, 2022
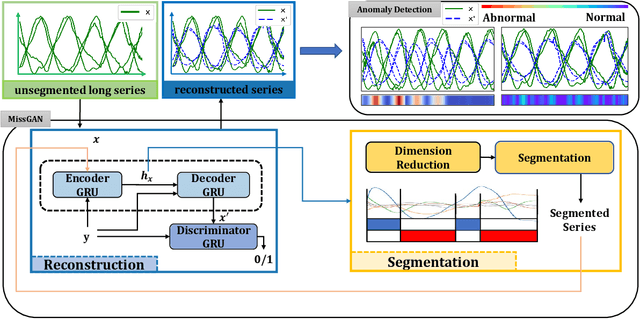
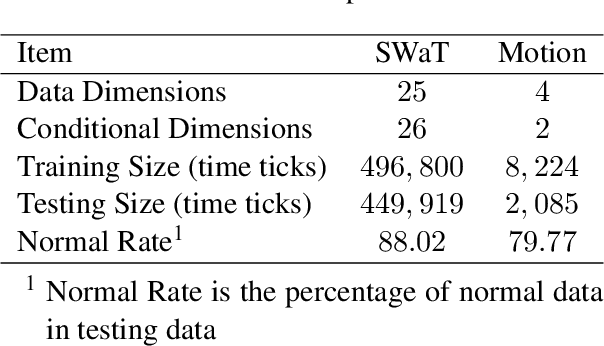
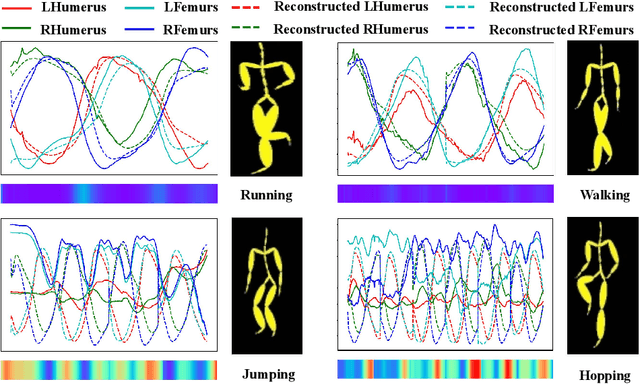
Given a multivariate big time series, can we detect anomalies as soon as they occur? Many existing works detect anomalies by learning how much a time series deviates away from what it should be in the reconstruction framework. However, most models have to cut the big time series into small pieces empirically since optimization algorithms cannot afford such a long series. The question is raised: do such cuts pollute the inherent semantic segments, like incorrect punctuation in sentences? Therefore, we propose a reconstruction-based anomaly detection method, MissGAN, iteratively learning to decode and encode naturally smooth time series in coarse segments, and finding out a finer segment from low-dimensional representations based on HMM. As a result, learning from multi-scale segments, MissGAN can reconstruct a meaningful and robust time series, with the help of adversarial regularization and extra conditional states. MissGAN does not need labels or only needs labels of normal instances, making it widely applicable. Experiments on industrial datasets of real water network sensors show our MissGAN outperforms the baselines with scalability. Besides, we use a case study on the CMU Motion dataset to demonstrate that our model can well distinguish unexpected gestures from a given conditional motion.
CPGNet: Cascade Point-Grid Fusion Network for Real-Time LiDAR Semantic Segmentation
Apr 27, 2022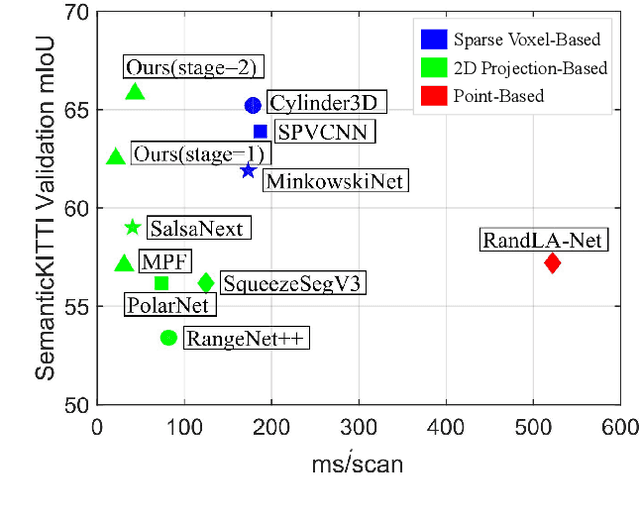
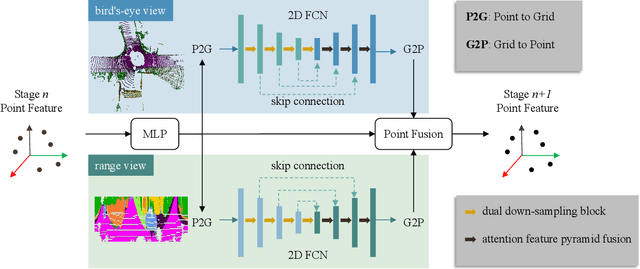
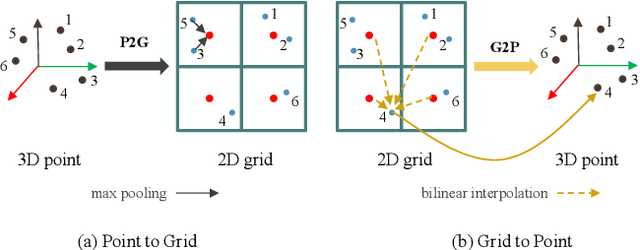
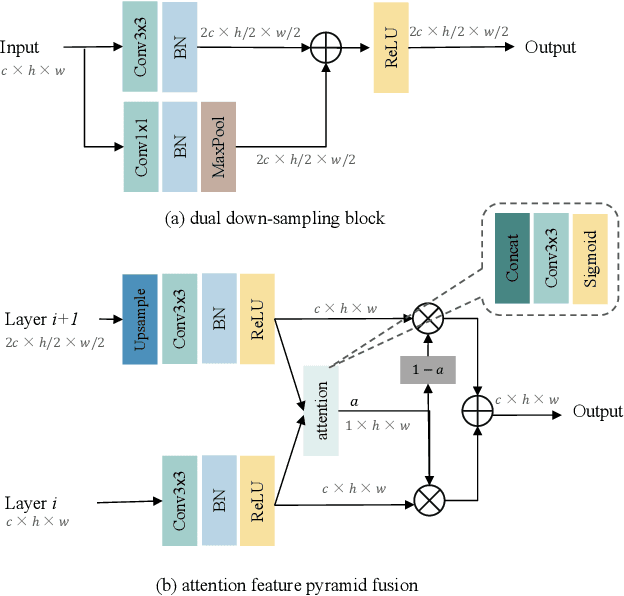
LiDAR semantic segmentation essential for advanced autonomous driving is required to be accurate, fast, and easy-deployed on mobile platforms. Previous point-based or sparse voxel-based methods are far away from real-time applications since time-consuming neighbor searching or sparse 3D convolution are employed. Recent 2D projection-based methods, including range view and multi-view fusion, can run in real time, but suffer from lower accuracy due to information loss during the 2D projection. Besides, to improve the performance, previous methods usually adopt test time augmentation (TTA), which further slows down the inference process. To achieve a better speed-accuracy trade-off, we propose Cascade Point-Grid Fusion Network (CPGNet), which ensures both effectiveness and efficiency mainly by the following two techniques: 1) the novel Point-Grid (PG) fusion block extracts semantic features mainly on the 2D projected grid for efficiency, while summarizes both 2D and 3D features on 3D point for minimal information loss; 2) the proposed transformation consistency loss narrows the gap between the single-time model inference and TTA. The experiments on the SemanticKITTI and nuScenes benchmarks demonstrate that the CPGNet without ensemble models or TTA is comparable with the state-of-the-art RPVNet, while it runs 4.7 times faster.
Join the High Accuracy Club on ImageNet with A Binary Neural Network Ticket
Dec 13, 2022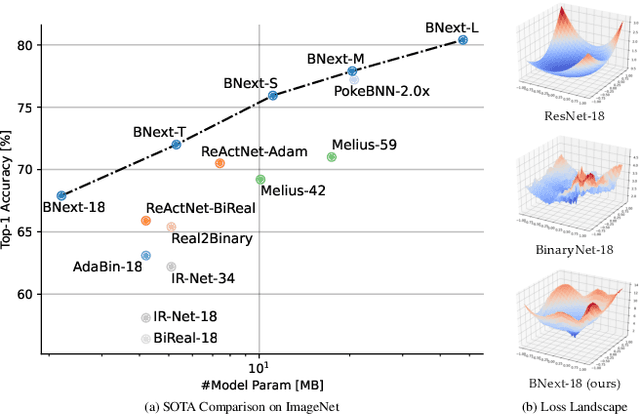
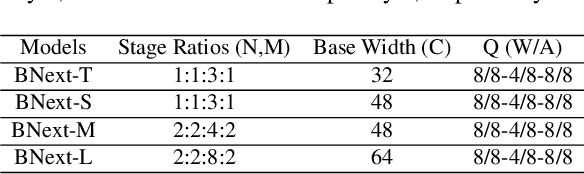

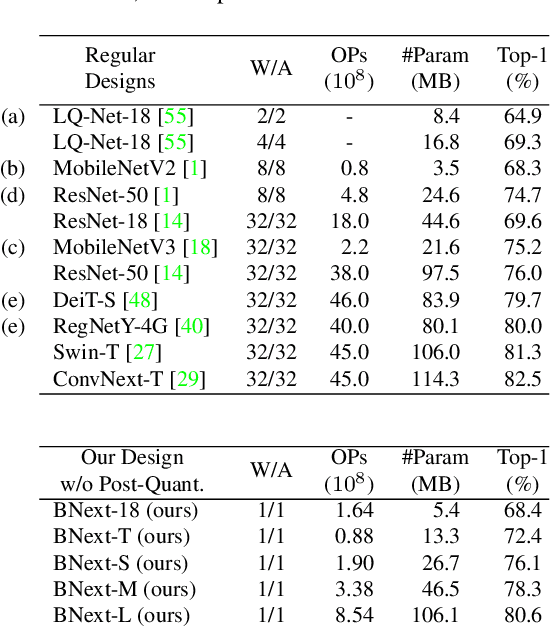
Binary neural networks are the extreme case of network quantization, which has long been thought of as a potential edge machine learning solution. However, the significant accuracy gap to the full-precision counterparts restricts their creative potential for mobile applications. In this work, we revisit the potential of binary neural networks and focus on a compelling but unanswered problem: how can a binary neural network achieve the crucial accuracy level (e.g., 80%) on ILSVRC-2012 ImageNet? We achieve this goal by enhancing the optimization process from three complementary perspectives: (1) We design a novel binary architecture BNext based on a comprehensive study of binary architectures and their optimization process. (2) We propose a novel knowledge-distillation technique to alleviate the counter-intuitive overfitting problem observed when attempting to train extremely accurate binary models. (3) We analyze the data augmentation pipeline for binary networks and modernize it with up-to-date techniques from full-precision models. The evaluation results on ImageNet show that BNext, for the first time, pushes the binary model accuracy boundary to 80.57% and significantly outperforms all the existing binary networks. Code and trained models are available at: https://github.com/hpi-xnor/BNext.git.