 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Emergent Behaviors in Multi-Agent Target Acquisition
Dec 15, 2022
Only limited studies and superficial evaluations are available on agents' behaviors and roles within a Multi-Agent System (MAS). We simulate a MAS using Reinforcement Learning (RL) in a pursuit-evasion (a.k.a predator-prey pursuit) game, which shares task goals with target acquisition, and we create different adversarial scenarios by replacing RL-trained pursuers' policies with two distinct (non-RL) analytical strategies. Using heatmaps of agents' positions (state-space variable) over time, we are able to categorize an RL-trained evader's behaviors. The novelty of our approach entails the creation of an influential feature set that reveals underlying data regularities, which allow us to classify an agent's behavior. This classification may aid in catching the (enemy) targets by enabling us to identify and predict their behaviors, and when extended to pursuers, this approach towards identifying teammates' behavior may allow agents to coordinate more effectively.
* This article appeared in the news at: https://www.army.mil/article/258408/u_s_army_scientists_invent_a_method_to_characterize_ai_behavior
Data Dimension Reduction makes ML Algorithms efficient
Nov 17, 2022
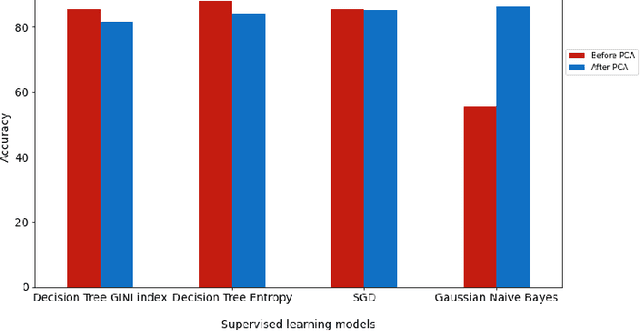
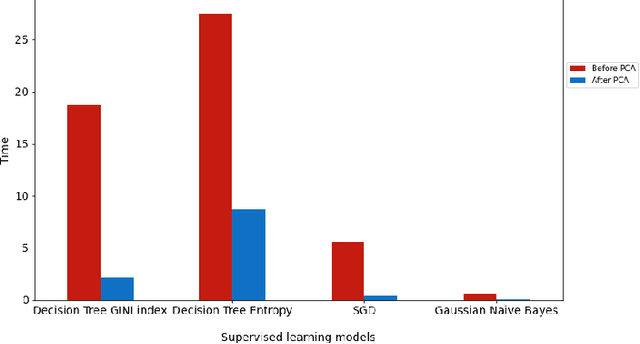
Data dimension reduction (DDR) is all about mapping data from high dimensions to low dimensions, various techniques of DDR are being used for image dimension reduction like Random Projections, Principal Component Analysis (PCA), the Variance approach, LSA-Transform, the Combined and Direct approaches, and the New Random Approach. Auto-encoders (AE) are used to learn end-to-end mapping. In this paper, we demonstrate that pre-processing not only speeds up the algorithms but also improves accuracy in both supervised and unsupervised learning. In pre-processing of DDR, first PCA based DDR is used for supervised learning, then we explore AE based DDR for unsupervised learning. In PCA based DDR, we first compare supervised learning algorithms accuracy and time before and after applying PCA. Similarly, in AE based DDR, we compare unsupervised learning algorithm accuracy and time before and after AE representation learning. Supervised learning algorithms including support-vector machines (SVM), Decision Tree with GINI index, Decision Tree with entropy and Stochastic Gradient Descent classifier (SGDC) and unsupervised learning algorithm including K-means clustering, are used for classification purpose. We used two datasets MNIST and FashionMNIST Our experiment shows that there is massive improvement in accuracy and time reduction after pre-processing in both supervised and unsupervised learning.
Fast Non-Rigid Radiance Fields from Monocularized Data
Dec 02, 2022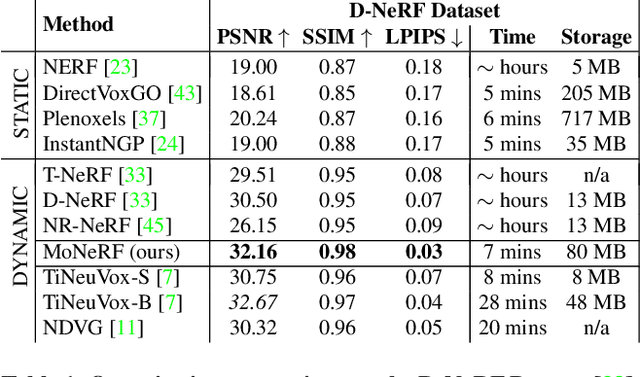
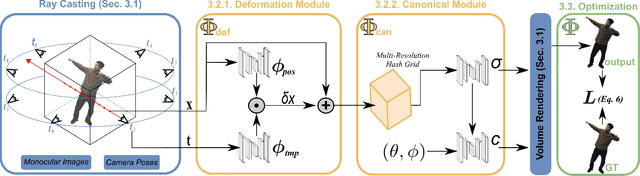
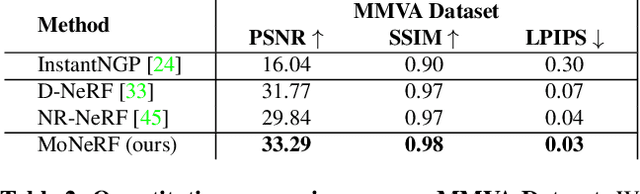

3D reconstruction and novel view synthesis of dynamic scenes from collections of single views recently gained increased attention. Existing work shows impressive results for synthetic setups and forward-facing real-world data, but is severely limited in the training speed and angular range for generating novel views. This paper addresses these limitations and proposes a new method for full 360{\deg} novel view synthesis of non-rigidly deforming scenes. At the core of our method are: 1) An efficient deformation module that decouples the processing of spatial and temporal information for acceleration at training and inference time; and 2) A static module representing the canonical scene as a fast hash-encoded neural radiance field. We evaluate the proposed approach on the established synthetic D-NeRF benchmark, that enables efficient reconstruction from a single monocular view per time-frame randomly sampled from a full hemisphere. We refer to this form of inputs as monocularized data. To prove its practicality for real-world scenarios, we recorded twelve challenging sequences with human actors by sampling single frames from a synchronized multi-view rig. In both cases, our method is trained significantly faster than previous methods (minutes instead of days) while achieving higher visual accuracy for generated novel views. Our source code and data is available at our project page https://graphics.tu-bs.de/publications/kappel2022fast.
Infinite-Dimensional Adaptive Boundary Observer for Inner-Domain Temperature Estimation of 3D Electrosurgical Processes using Surface Thermography Sensing
Nov 01, 2022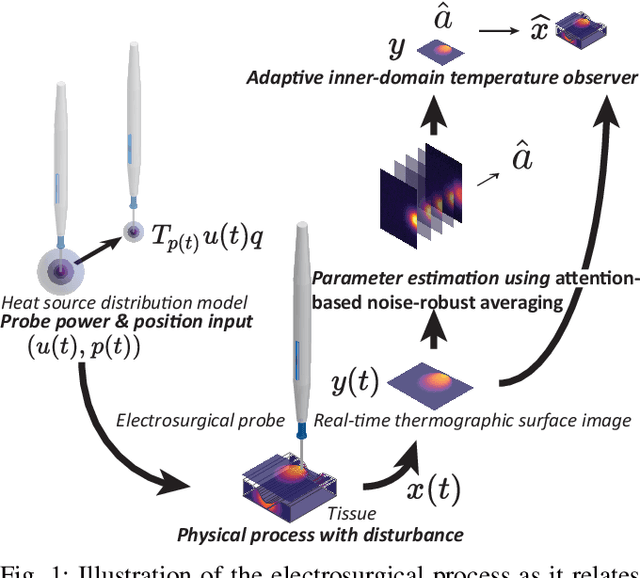
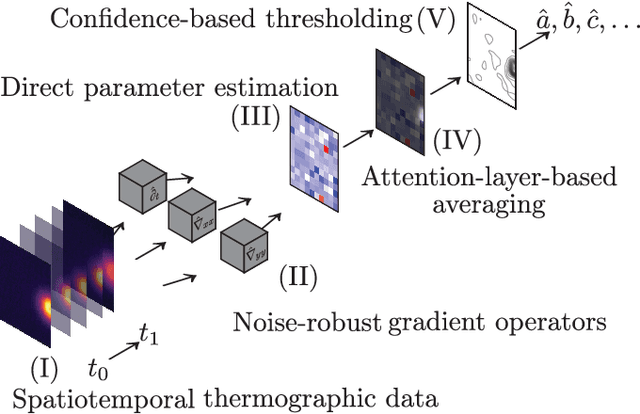
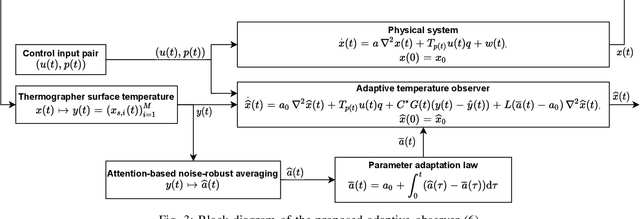

We present a novel 3D adaptive observer framework for use in the determination of subsurface organic tissue temperatures in electrosurgery. The observer structure leverages pointwise 2D surface temperature readings obtained from a real-time infrared thermographer for both parameter estimation and temperature field observation. We introduce a novel approach to decoupled parameter adaptation and estimation, wherein the parameter estimation can run in real-time, while the observer loop runs on a slower time scale. To achieve this, we introduce a novel parameter estimation method known as attention-based noise-robust averaging, in which surface thermography time series are used to directly estimate the tissue's diffusivity. Our observer contains a real-time parameter adaptation component based on this diffusivity adaptation law, as well as a Luenberger-type corrector based on the sensed surface temperature. In this work, we also present a novel model structure adapted to the setting of robotic surgery, wherein we model the electrosurgical heat distribution as a compactly supported magnitude- and velocity-controlled heat source involving a new nonlinear input mapping. We demonstrate satisfactory performance of the adaptive observer in simulation, using real-life experimental ex vivo porcine tissue data.
Autonomous Driving Simulator based on Neurorobotics Platform
Dec 31, 2022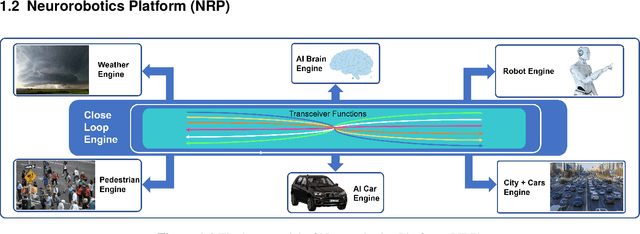


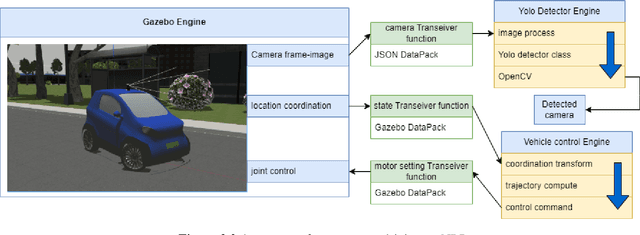
There are many artificial intelligence algorithms for autonomous driving, but directly installing these algorithms on vehicles is unrealistic and expensive. At the same time, many of these algorithms need an environment to train and optimize. Simulation is a valuable and meaningful solution with training and testing functions, and it can say that simulation is a critical link in the autonomous driving world. There are also many different applications or systems of simulation from companies or academies such as SVL and Carla. These simulators flaunt that they have the closest real-world simulation, but their environment objects, such as pedestrians and other vehicles around the agent-vehicle, are already fixed programmed. They can only move along the pre-setting trajectory, or random numbers determine their movements. What is the situation when all environmental objects are also installed by Artificial Intelligence, or their behaviors are like real people or natural reactions of other drivers? This problem is a blind spot for most of the simulation applications, or these applications cannot be easy to solve this problem. The Neurorobotics Platform from the TUM team of Prof. Alois Knoll has the idea about "Engines" and "Transceiver Functions" to solve the multi-agents problem. This report will start with a little research on the Neurorobotics Platform and analyze the potential and possibility of developing a new simulator to achieve the true real-world simulation goal. Then based on the NRP-Core Platform, this initial development aims to construct an initial demo experiment. The consist of this report starts with the basic knowledge of NRP-Core and its installation, then focus on the explanation of the necessary components for a simulation experiment, at last, about the details of constructions for the autonomous driving system, which is integrated object detection and autonomous control.
Control Barrier Functionals: Safety-critical Control for Time Delay Systems
Jun 16, 2022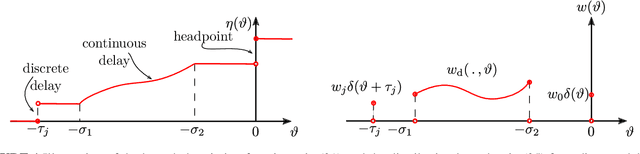

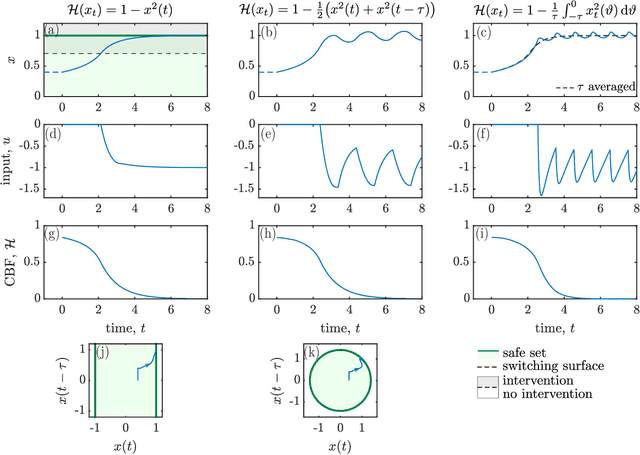
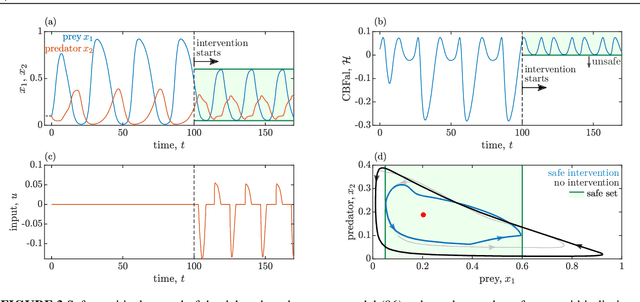
This work presents a theoretical framework for the safety-critical control of time delay systems. The theory of control barrier functions, that provides formal safety guarantees for delay-free systems, is extended to systems with state delay. The notion of control barrier functionals is introduced to attain formal safety guarantees, by enforcing the forward invariance of safe sets defined in the infinite dimensional state space. The proposed framework is able to handle multiple delays and distributed delays both in the dynamics and in the safety condition, and provides an affine constraint on the control input that yields provable safety. This constraint can be incorporated into optimization problems to synthesize pointwise optimal and provable safe controllers. The applicability of the proposed method is demonstrated by numerical simulation examples.
Certifying Safety in Reinforcement Learning under Adversarial Perturbation Attacks
Dec 28, 2022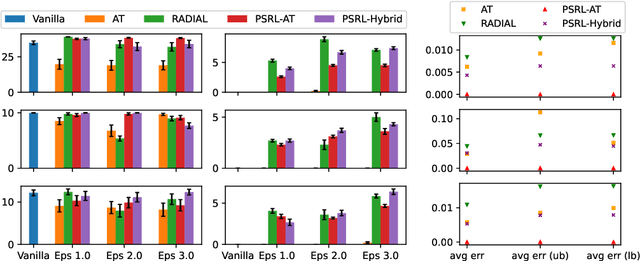
Function approximation has enabled remarkable advances in applying reinforcement learning (RL) techniques in environments with high-dimensional inputs, such as images, in an end-to-end fashion, mapping such inputs directly to low-level control. Nevertheless, these have proved vulnerable to small adversarial input perturbations. A number of approaches for improving or certifying robustness of end-to-end RL to adversarial perturbations have emerged as a result, focusing on cumulative reward. However, what is often at stake in adversarial scenarios is the violation of fundamental properties, such as safety, rather than the overall reward that combines safety with efficiency. Moreover, properties such as safety can only be defined with respect to true state, rather than the high-dimensional raw inputs to end-to-end policies. To disentangle nominal efficiency and adversarial safety, we situate RL in deterministic partially-observable Markov decision processes (POMDPs) with the goal of maximizing cumulative reward subject to safety constraints. We then propose a partially-supervised reinforcement learning (PSRL) framework that takes advantage of an additional assumption that the true state of the POMDP is known at training time. We present the first approach for certifying safety of PSRL policies under adversarial input perturbations, and two adversarial training approaches that make direct use of PSRL. Our experiments demonstrate both the efficacy of the proposed approach for certifying safety in adversarial environments, and the value of the PSRL framework coupled with adversarial training in improving certified safety while preserving high nominal reward and high-quality predictions of true state.
Accelerated Continuous-Time Approximate Dynamic Programming via Data-Assisted Hybrid Control
Apr 27, 2022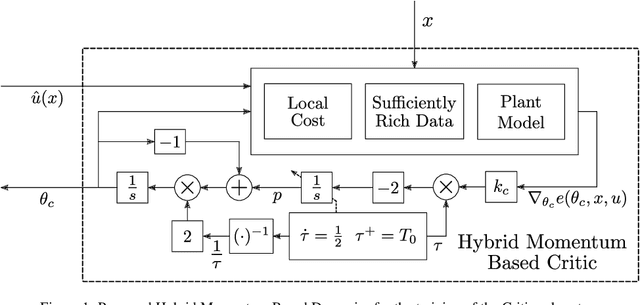
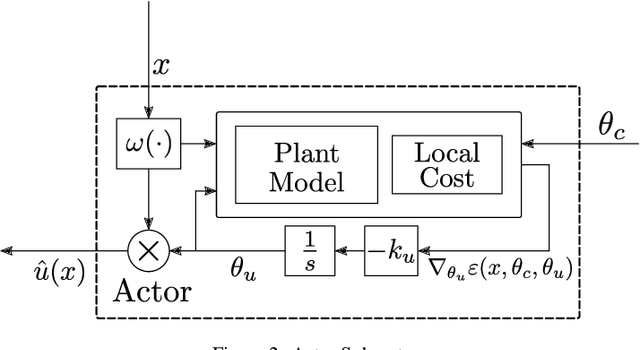
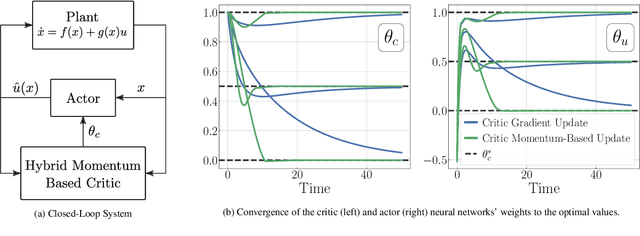
We introduce a new closed-loop architecture for the online solution of approximate optimal control problems in the context of continuous-time systems. Specifically, we introduce the first algorithm that incorporates dynamic momentum in actor-critic structures to control continuous-time dynamic plants with an affine structure in the input. By incorporating dynamic momentum in our algorithm, we are able to accelerate the convergence properties of the closed-loop system, achieving superior transient performance compared to traditional gradient-descent based techniques. In addition, by leveraging the existence of past recorded data with sufficiently rich information properties, we dispense with the persistence of excitation condition traditionally imposed on the regressors of the critic and the actor. Given that our continuous-time momentum-based dynamics also incorporate periodic discrete-time resets that emulate restarting techniques used in the machine learning literature, we leverage tools from hybrid dynamical systems theory to establish asymptotic stability properties for the closed-loop system. We illustrate our results with a numerical example.
SLAM for Visually Impaired People: A Survey
Dec 09, 2022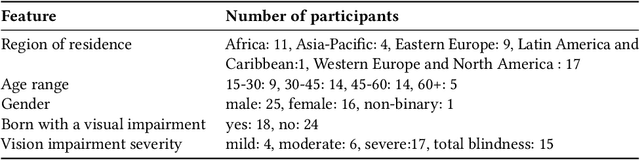
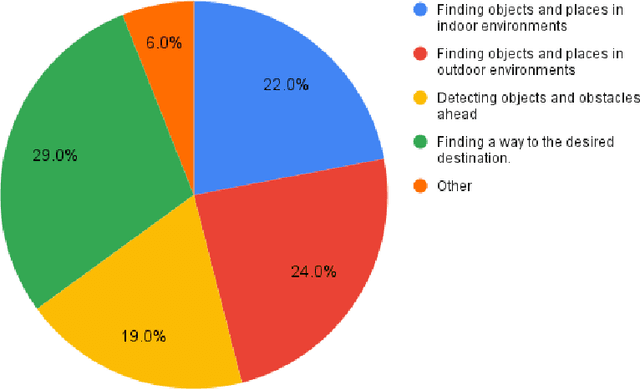
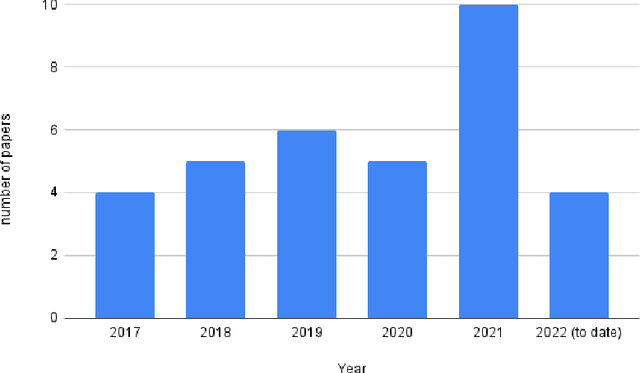
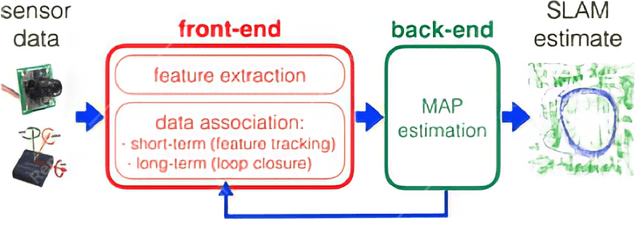
In recent decades, several assistive technologies for visually impaired and blind (VIB) people have been developed to improve their ability to navigate independently and safely. At the same time, simultaneous localization and mapping (SLAM) techniques have become sufficiently robust and efficient to be adopted in the development of assistive technologies. In this paper, we first report the results of an anonymous survey conducted with VIB people to understand their experience and needs; we focus on digital assistive technologies that help them with indoor and outdoor navigation. Then, we present a literature review of assistive technologies based on SLAM. We discuss proposed approaches and indicate their pros and cons. We conclude by presenting future opportunities and challenges in this domain.
An Approach for Improving Automatic Mouth Emotion Recognition
Dec 12, 2022The study proposes and tests a technique for automated emotion recognition through mouth detection via Convolutional Neural Networks (CNN), meant to be applied for supporting people with health disorders with communication skills issues (e.g. muscle wasting, stroke, autism, or, more simply, pain) in order to recognize emotions and generate real-time feedback, or data feeding supporting systems. The software system starts the computation identifying if a face is present on the acquired image, then it looks for the mouth location and extracts the corresponding features. Both tasks are carried out using Haar Feature-based Classifiers, which guarantee fast execution and promising performance. If our previous works focused on visual micro-expressions for personalized training on a single user, this strategy aims to train the system also on generalized faces data sets.